fastai v2 walk-thru #2
Chapters
0:03:7 Pipeline Functions
4:3 Decode from Pipeline
6:50 Transform Data Source
12:48 Data Sauce
31:23 Get Files
38:44 Functions That Return Functions
39:58 Creating Splits
42:2 Labeling
48:58 Category Map
53:30 Merge Conflicts
68:27 Did Swift Ai Influence the Design of V2
79:15 Delegates Decorator
81:53 Contexts
83:56 Documentation
00:00:00.000 | Okay, hi everybody, can you see me, hear me okay?
00:00:26.960 | [BLANK_AUDIO]
00:00:36.960 | Okay, this will be an interesting experiment.
00:00:59.960 | [BLANK_AUDIO]
00:01:06.960 | And everybody in the forum looks okay, great.
00:01:10.960 | [BLANK_AUDIO]
00:01:12.960 | And I am recording, so that's good too.
00:01:16.960 | [BLANK_AUDIO]
00:01:24.960 | So I'm going to go back to SDI dev, dev.
00:01:31.960 | [BLANK_AUDIO]
00:01:34.960 | We were looking at, wait.
00:01:36.960 | [BLANK_AUDIO]
00:01:46.960 | All right, so we need to make sure we get Paul.
00:01:56.960 | [BLANK_AUDIO]
00:01:59.960 | As we're always changing stuff.
00:02:00.960 | [BLANK_AUDIO]
00:02:03.960 | And restart.
00:02:04.960 | [BLANK_AUDIO]
00:02:13.960 | Okay, so where we're up to is we learn how to create basically a function.
00:02:20.960 | But actually something that derives from transform.
00:02:23.960 | But it just, it looks exactly like a function.
00:02:25.960 | So you pass it an argument.
00:02:27.960 | Transform will send that off to the encodes method.
00:02:30.960 | Kind of like how nn.module in PyTorch passes it off to a forward method.
00:02:36.960 | And it will calculate the result of the function and return it.
00:02:42.960 | And then we also learned that something which works that way.
00:02:46.960 | You can also optionally add a decodes.
00:02:49.960 | Which will, basically something that you undo that transform.
00:02:54.960 | Or at least enough that you can display it.
00:02:56.960 | And so that has to return something which has a show method.
00:03:00.960 | But that's just a function basically.
00:03:04.960 | And then we learned that you can pipeline functions.
00:03:08.960 | Which basically just means that you are composing functions together.
00:03:16.960 | Or transforms.
00:03:18.960 | And the interesting thing in this one is that when you return a tuple.
00:03:24.960 | [BLANK_AUDIO]
00:03:27.960 | It will.
00:03:28.960 | [BLANK_AUDIO]
00:03:31.960 | Then let you, things after that.
00:03:33.960 | You can make them tuple transforms.
00:03:36.960 | And it will apply the function only to those items in the tuple individually.
00:03:41.960 | That are of this requested type.
00:03:45.960 | I think we have one unnecessary annotation here.
00:03:48.960 | Let me check.
00:03:50.960 | [BLANK_AUDIO]
00:03:59.960 | Yep.
00:04:00.960 | Okay.
00:04:01.960 | So.
00:04:02.960 | Yes.
00:04:03.960 | You can decode from pipeline.
00:04:04.960 | That's kind of the whole point really.
00:04:06.960 | Is that a pipeline that encodes can also decode.
00:04:13.960 | So you can see here.
00:04:16.960 | For instance.
00:04:18.960 | So we could go.
00:04:22.960 | T equals pipe zero.
00:04:26.960 | And so there's T.
00:04:27.960 | Which is a tuple with a boolean and a tensor.
00:04:35.960 | [BLANK_AUDIO]
00:04:38.960 | Make sure I've already called that one.
00:04:40.960 | [BLANK_AUDIO]
00:04:50.960 | Oh, sorry.
00:04:51.960 | They're doing Siamese.
00:04:52.960 | So it's two images and a bool.
00:04:55.960 | So we could say.
00:04:58.960 | Decoded T equals pipe dot decode.
00:05:01.960 | [BLANK_AUDIO]
00:05:05.960 | T.
00:05:06.960 | [BLANK_AUDIO]
00:05:11.960 | And.
00:05:13.960 | There it is.
00:05:14.960 | And so now.
00:05:15.960 | [BLANK_AUDIO]
00:05:17.960 | That is.
00:05:19.960 | [BLANK_AUDIO]
00:05:23.960 | Let's see.
00:05:24.960 | Pipe dot decode.
00:05:28.960 | So that's going to.
00:05:31.960 | Actually, none of these have a decode in them.
00:05:33.960 | So that's a pretty boring example.
00:05:35.960 | Let's go back to the previous one.
00:05:40.960 | Oh, that's not a pipeline.
00:05:44.960 | We'll come back to it.
00:05:45.960 | We'll see one later.
00:05:46.960 | But basically, yeah.
00:05:47.960 | So none of these have a decode.
00:05:48.960 | We don't have to decode Siamese image.
00:05:50.960 | Siamese image tuples.
00:05:52.960 | But yes, if you say pipe dot decode.
00:05:55.960 | Then it will.
00:05:57.960 | Pipeline through all of the steps.
00:05:59.960 | Calling decode on each.
00:06:02.960 | And actually.
00:06:03.960 | Pipe dot show.
00:06:05.960 | Is an interesting one.
00:06:07.960 | Because to show a pipeline.
00:06:09.960 | It's going to.
00:06:12.960 | Decode every part of the tuple.
00:06:14.960 | Because normally the last step is a tuple.
00:06:18.960 | And it will keep decoding it.
00:06:20.960 | But it'll stop.
00:06:22.960 | As soon as it gets to a type.
00:06:26.960 | Which has a show method defined.
00:06:28.960 | So.
00:06:30.960 | In this case actually.
00:06:32.960 | The output type of pipe is a Siamese image.
00:06:36.960 | And the Siamese image has a show method defined.
00:06:40.960 | So when we call dot show.
00:06:42.960 | It doesn't really need to decode at all.
00:06:45.960 | But for other types it does need to decode.
00:06:50.960 | So then transform data source.
00:06:52.960 | Is something where we give it.
00:06:54.960 | Arrays of transforms or functions.
00:06:58.960 | Each one will be turned into a pipeline.
00:07:00.960 | And each one of those pipelines.
00:07:02.960 | Will be applied to each item.
00:07:04.960 | And that will then give us a tuple.
00:07:13.960 | Which was not working yesterday.
00:07:15.960 | But is working now.
00:07:18.960 | So you can see.
00:07:20.960 | Actually this is a good example of decode.
00:07:22.960 | Like a.
00:07:23.960 | Sorry.
00:07:24.960 | Transformed data set.
00:07:26.960 | Can decode.
00:07:28.960 | And what that's going to do.
00:07:29.960 | Is it's going to take.
00:07:33.960 | Our.
00:07:35.960 | Cario image and our number.
00:07:38.960 | And it's going to decode each part of the tuple.
00:07:41.960 | By decoding each of the pipelines.
00:07:44.960 | And then you end up with as you see.
00:07:48.960 | The correct name in this case of the pet breed.
00:07:52.960 | And so show again will decode.
00:07:55.960 | Each part of that tuple up into the point where it finds a show method.
00:08:00.960 | And then it will show it.
00:08:10.960 | Ah now I don't think.
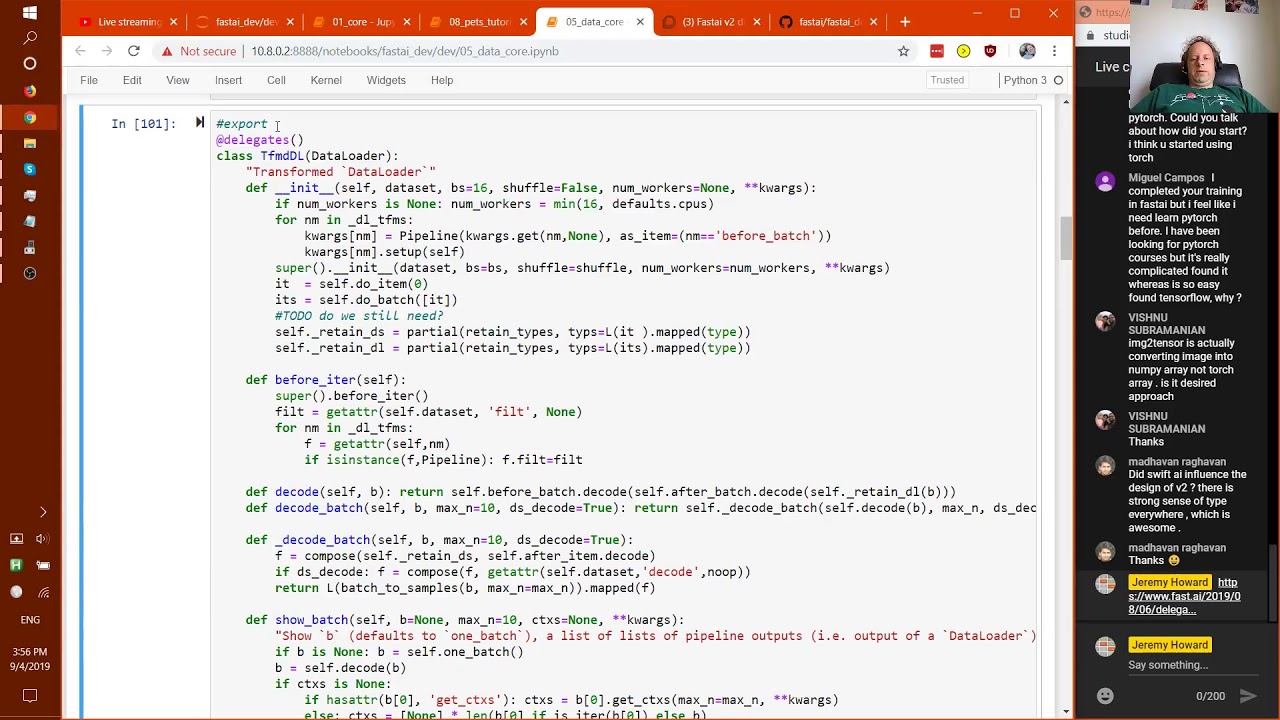
00:08:13.960 | We got as far as TwfmDL yesterday.
00:08:17.960 | No I guess we couldn't have because.
00:08:20.960 | It wasn't working.
00:08:21.960 | So TwfmDL is a data loader.
00:08:27.960 | Which understands.
00:08:31.960 | Fast AI version 2 stuff.
00:08:33.960 | And specifically it understands two pieces of stuff.
00:08:37.960 | One is that it understands how to maintain types.
00:08:42.960 | So if it makes sure that.
00:08:46.960 | You know transform or pillow image subtypes are maintained.
00:08:51.960 | And it understands decoding.
00:08:55.960 | So basically it's it lets you have transforms in a transform data loader.
00:09:00.960 | And they will behave the same way as transformed in a transform data set.
00:09:06.960 | So here.
00:09:07.960 | What we're going to do is we're going to do the same thing we had before.
00:09:10.960 | Let's just copy it down so we remember.
00:09:14.960 | So this was how we did pets.
00:09:16.960 | Last time.
00:09:20.960 | So previously our first pipeline was image dot create resize to tensor byte float tensor.
00:09:26.960 | And our second pipeline was labeler and categorize.
00:09:32.960 | And just to remind you labeler was a regex labeler function.
00:09:37.960 | This time the labeling pipeline is the same.
00:09:41.960 | But the image pipeline is just PIO image dot create.
00:09:47.960 | So what's PIO image.
00:09:51.960 | PIO image is simply a.
00:10:00.960 | It is.
00:10:01.960 | Oh yeah here it is.
00:10:03.960 | Is this.
00:10:04.960 | It's one line of code.
00:10:06.960 | And it's just a thing that inherits from PIO base.
00:10:10.960 | And PIO base.
00:10:16.960 | Is something which inherits from PIO image.
00:10:23.960 | And there's a bit more information than we need here but the key thing to recognize about
00:10:27.960 | this is that it has a create method and a show method.
00:10:30.960 | Which are the things that we need for it to be able to work in our transform pipelines.
00:10:37.960 | And the create is static.
00:10:39.960 | So PIO image dot create is simply going to call load image which is the thing that opens
00:10:46.960 | the PIO image in the usual way.
00:10:52.960 | Okay so that's that.
00:10:57.960 | So why are we able to get rid of all of these things from our image pipeline.
00:11:04.960 | And the reason is that we've moved them into our data loader transformation pipeline.
00:11:15.960 | Which is going to turn out to be pretty handy in this case it doesn't make much of a difference
00:11:21.960 | but basically what's going to happen now is we'll learn a bit more about the data loaders
00:11:27.960 | today.
00:11:28.960 | But basically the data loaders also have places you can add transform pipelines and in this
00:11:34.520 | case after creating the data set it's going to call these on inside the actual data loader
00:11:43.240 | itself.
00:11:45.760 | One thing to recognize is that image resize and byte to float tensor don't make sense
00:11:53.200 | for categories.
00:11:56.160 | But that's okay because image resizer only defines encodes for PIO image and PIO mask.
00:12:06.200 | It doesn't define them for anything else so it'll just ignore the categories.
00:12:12.200 | And byte to float tensor is the same.
00:12:17.840 | It's defined on tensor image encodes and tensor mask encodes and nothing else.
00:12:25.160 | So it won't change our categories.
00:12:30.360 | So that is why that works.
00:12:34.520 | So there it is.
00:12:39.800 | So the last kind of piece of this part of the API is data source and so each thing is
00:12:50.400 | going to build on each other thing.
00:12:51.600 | So data source is basically a transformed data set but with the ability to create separate
00:12:58.840 | training and validation sets and in fact to create as many subsets as you like.
00:13:06.760 | So if you're having trouble with code not running, best place to ask is on the forum
00:13:32.400 | because I can't debug it while we go, but feel free to ask on the forum.
00:13:44.720 | So what we're going to do now is we're going to use this thing that looks a lot like a
00:13:49.520 | TwfimDs, a transformed data source, but it's going to allow us to separate training and
00:13:56.000 | validation sets.
00:13:57.640 | And so if you look at how TwfimDs was defined, here it is here.
00:14:05.460 | So when we created our TwfimDs we passed in items and transforms.
00:14:10.600 | This time we're going to pass in items and transforms and the indices of our splits.
00:14:18.040 | So remember split_idx was something with two arrays in it and the arrays just had lists
00:14:27.000 | of IDs for the training validation set.
00:14:38.560 | So by passing the data source this extra piece of information, we'll end up with something
00:14:44.520 | that you can use exactly the same way as TwfimDs.
00:14:48.120 | So you can still just ask for an element from it.
00:14:50.580 | So this is kind of a superset of the functionality of TwfimDs.
00:14:54.560 | But you can also ask for a subset.
00:14:59.240 | So the zeroth subset will be all the things that were in split_idx[0] and the first subset
00:15:04.600 | will be all the things in split_idx[1].
00:15:08.420 | So in other words, pets.subset[1] is the validation set.
00:15:14.200 | And so there is indeed a shortcut for that, which is pets.valid.
00:15:19.080 | So you'll find that there is a pets.valid.
00:15:22.680 | Hi Joseph, just to remind you again, if you have bugs in the code, please ask on the forums,
00:15:35.080 | not on the live chat, because I won't be able to answer them here.
00:15:40.280 | So the validation set, for example, and the training set, for example.
00:15:48.160 | And so pets.valid is exactly the same as pets.subset[1], and the training set is exactly the same as
00:16:00.240 | pets.subset[0].
00:16:02.000 | So one of the nice things here is that we're not just limited to just a train set and a
00:16:09.040 | validation set.
00:16:10.040 | You can actually have as many data sets as you like.
00:16:13.000 | You can have multiple validation sets, you can include a test set, and so forth.
00:16:17.440 | So it's kind of a bit more flexible here than fast.aiv1.
00:16:24.360 | OK, so now we've got something, so basically these training and validation sets act pretty
00:16:32.600 | much exactly like a tfmds.
00:16:36.240 | The type is something, is in fact a tfmds, as you can see, so that makes it nice and
00:16:48.000 | easy.
00:16:49.000 | All right, so because these things are just tfmds, you can decode them just like before,
00:16:55.520 | as you can see.
00:17:02.360 | And yeah, we can show them just like before.
00:17:09.840 | So here is something even more interesting, which is, we've seen already tfmdl after item.
00:17:22.800 | That's going to run, that's going to be a transform that runs on each individual tuple
00:17:29.600 | that comes out of the transform pipelines.
00:17:31.960 | But then there's another one called after batch, and that's going to run after the tuples
00:17:39.500 | have been collated together by the PyTorch data loader into a single batch.
00:17:44.540 | And what that means is that we can put transforms in here that we can run on a whole batch at
00:17:52.400 | a time, and that means we have the ability to easily run GPU transforms.
00:17:59.880 | So in this case, the most obvious GPU transform to do, of course, or the most obvious batch
00:18:05.160 | transform to do is CUDA, which will simply move it onto the GPU if you have one.
00:18:12.500 | And then we can convert it from byte to float on the GPU.
00:18:16.520 | Now that might seem like a pretty minor thing, but actually converting a byte to a float
00:18:21.520 | is really slow for two reasons.
00:18:23.960 | The first is that floats are much bigger than bytes, so it's taking up a lot of memory to
00:18:28.040 | transfer it to your GPU as floats.
00:18:30.480 | And the second is that converting from a byte to a float actually takes a non-trivial amount
00:18:34.520 | of time on the CPU.
00:18:36.440 | It actually does take up quite a lot of time.
00:18:42.720 | So here's the first example of something that was very, very hard to do before, which is
00:18:48.660 | to actually do computation on the GPU.
00:18:52.360 | And the nice thing is that the GPU transforms often don't even need to be written in a different
00:19:02.680 | way.
00:19:03.680 | If you look at a float tensor, for instance, you can see that "encodes" simply goes "o.float/255".
00:19:16.740 | So thanks to broadcast tensor computations and stuff, we don't normally have to write
00:19:23.040 | it at all differently to make it work at a batch level.
00:19:28.600 | So often you'll be able to just transparently move your transformations onto the GPU, and
00:19:34.640 | suddenly things will just run much faster.
00:19:37.040 | So I think that's one of the pretty exciting things here.
00:19:41.040 | So now we're getting pretty close to having something which looks like what you would
00:19:46.680 | actually train with.
00:19:49.140 | It's something which is categorizing our pet types.
00:19:58.460 | We have separate training and validation sets.
00:20:01.660 | It's converting them into batches, and we can even go "train_dl.show_batch" and it will
00:20:12.260 | actually give us a full set of these.
00:20:14.340 | So this is kind of really getting everything together nicely.
00:20:18.340 | One of the very neat subtleties of DataSource is that DataSource - well, it's not really
00:20:32.300 | DataSource, it's really Categorize.
00:20:34.980 | So we're using Categorize here, and what happens - we'll learn more about this shortly - but
00:20:49.380 | what happens when Pipeline first gets its DataSource is it calls a special method in
00:20:55.620 | a transform called "setup", if you have one.
00:20:58.940 | And you can see here that what we actually do is we try to grab, if there is one, the
00:21:03.740 | "training" subset of the DataSource.
00:21:07.580 | So one of the cool things here is that automatically this stuff will ensure that your Categorize
00:21:15.540 | vocab is only done on the "training" set.
00:21:20.140 | So these are the kind of things that are very easy to mess up.
00:21:25.380 | So the questions here - does "byteToFloat" normalize?
00:21:28.180 | No it doesn't.
00:21:29.180 | As you'll see, there is a separate "normalize" function, however it does have an optional
00:21:43.380 | "div" argument which will divide it by 255, so that'll give you between 0 and 1, so not
00:21:48.820 | quite normalized, but at least it's on the right track.
00:21:52.140 | But yeah, there's also, as we'll see later, a "normalize" transform.
00:22:00.980 | Text transformations are rarely done lazily, they're normally done once pre-processing
00:22:06.780 | style, so they're not generally a great - so kind of such a good match for the GPU.
00:22:14.380 | But if there are - there's nothing to stop you from doing text transformations on the
00:22:17.980 | GPU.
00:22:18.980 | But as you'll see, we've actually - text transformations are a lot faster now anyway.
00:22:24.580 | And then, "any reason we don't do all transforms on GPU?"
00:22:28.140 | Yes, there is, Molly.
00:22:31.340 | The issue is basically - and that's a great question - the issue is basically, have a
00:22:34.780 | look here.
00:22:38.500 | If you want to be able to easily process things on the GPU, then you need a batch.
00:22:44.220 | And if you have a batch, that means you need a tensor, and if you have a tensor, that means
00:22:48.780 | that all of the items in the batch have to have the same shape.
00:22:52.180 | So if we didn't have this image resizer here, then the images would all be different shapes,
00:22:57.260 | and so we wouldn't be able to collate them into a batch.
00:23:00.580 | So specifically, the things that you probably want to do on the CPU are load the JPEG, in
00:23:08.740 | some way make sure that all of the things are the same size, and then convert them into
00:23:14.660 | a tensor.
00:23:16.060 | So those are basically the three things you have to do, at least for vision on the CPU.
00:23:27.320 | Having said that, there is a project by NVIDIA called DALI, which we'll endeavor to provide
00:23:35.500 | some support for, as once it stabilizes a bit, it's still pre-release.
00:23:40.720 | And they've actually written the custom codec kernels to do stuff on things that aren't
00:23:46.400 | all the same size, so there might be possibilities to do some stuff there.
00:23:54.240 | So images can absolutely be rectangular, it doesn't have to be 128x128, we'll see more
00:23:59.400 | of that later.
00:24:01.720 | And hopefully I've already answered the question about what's best on the GPU, I would say
00:24:04.600 | everything on the GPU that you can.
00:24:10.080 | So I would say try to do everything on the GPU that you can, but specifically, turning
00:24:17.200 | everything into something of the same size so that they can be plated into a batch has
00:24:20.980 | to happen before it goes on the GPU, so that would be my rule of thumb.
00:24:30.800 | So let's look at another example.
00:24:33.880 | There's no new things I'm going to show you, I'm just going to show you another example,
00:24:36.360 | which is segmentation.
00:24:40.740 | So let's grab a subset of Canvid, get those image files, create a random splitter, create
00:24:50.640 | the split indexes, create the labeling function.
00:24:59.200 | So the transforms are basically the same as we had before, except that for the Y we first
00:25:09.520 | of all call cvLabel, so that's the thing that's going to grab the name of the mask file from
00:25:15.120 | the image file, and then we're going to call pilMask.create, and pilMask, as you can see,
00:25:30.560 | is just a single line of code, and really the only reason it exists, or the main reason
00:25:37.080 | exists is so that we can do stuff like we did back here, where we had separate encodes
00:25:49.600 | for images and masks.
00:25:51.280 | So by giving things different types, it allows us to give different functionality.
00:25:55.120 | In this case it ensures that when we resize things, we're going to use nearest neighbors
00:26:00.160 | instead of bilinear.
00:26:03.600 | So that's a pretty interesting trick, and so as you can see, the amount of code necessary
00:26:09.920 | to do segmentation, even though we haven't got any data blocks API yet, is pretty tiny.
00:26:15.600 | So the idea here, and it all looks almost identical to PETS, even though it's a very
00:26:20.360 | very different task.
00:26:23.160 | In fact, even things like the DL transforms are literally identical, so we didn't have
00:26:27.440 | to redefine them.
00:26:30.280 | So the idea of this intermediate API, that's halfway between data blocks and the lowest
00:26:36.040 | level stuff, is to make it super simple, to make it really easy to do custom stuff, and
00:26:48.440 | my guess is that people doing a lot of Kaggle competitions, or more advanced stuff that's
00:26:55.200 | a little bit different to the things we show in the lessons or whatever, is that you'll
00:26:59.160 | probably use this level of the API a lot, because it just doesn't require much thinking
00:27:04.120 | and it's all pretty transparent and easy to understand.
00:27:08.720 | And then, as you'll see, the stuff that is in data blocks and stuff is all built on top
00:27:12.480 | of this and takes very little code.
00:27:16.120 | So Jacob asks how to profile code to see where the bottlenecks are.
00:27:21.920 | I'd have to say I'm not terribly good at that, or at least I'm not terribly smart about it.
00:27:28.960 | If I want to know where bottlenecks are in training, I'll just check htop to see if all
00:27:34.040 | the CPUs are being used 100%, and I'll check NVIDIA_SMI to see if my GPUs are being used
00:27:45.080 | 100%.
00:27:48.320 | So if you haven't done that before, you basically go NVIDIA_SMI_DEMON, and it starts spitting
00:27:58.440 | out stuff like this.
00:28:00.160 | And the key column that you're going to care about is this one here, SM.
00:28:05.320 | When you're training something, that should be basically saying above 90, and preferably
00:28:09.000 | around 100 all the time.
00:28:10.900 | That means your GPUs are being well used.
00:28:13.240 | If it's less than that, then it probably means that your CPUs are being overtaxed.
00:28:21.240 | And so that would be kind of step one, and if it's then your CPUs are overtaxed, then
00:28:25.360 | you can just use the normal Python profilers to find out why.
00:28:30.320 | If your GPU is being overtaxed, then that's probably just basically a good thing.
00:28:36.080 | It's using your GPUs effectively most of the time.
00:28:41.000 | Okay, so that's 08.
00:28:45.760 | So I thought from here, maybe we'll take a look at tifmdl, which is in 05.
00:29:05.000 | And by the way, there's a file called local_notebook_index.txt, which is automatically generated, which tells
00:29:16.240 | you which notebook everything's in, although the easier way to quickly jump there is you
00:29:23.760 | can just go, let's just import some local_notebook_show.inputs there.
00:29:40.600 | You can go source_link tifmdl, and as you can see, you'll get a link.
00:29:53.720 | Straight there!
00:30:03.480 | And as you can see, it's got an anchor, so it's going to jump straight to this right
00:30:07.760 | section once we wait.
00:30:09.320 | There we go.
00:30:10.320 | Okay, so that's a nice, fast way to go to the right notebook on the right part of a
00:30:16.800 | notebook.
00:30:17.800 | That was source_link.
00:30:19.800 | Okay, so here is 05.data_core, and we may as well look at the whole thing from the top
00:30:32.760 | while we're here.
00:30:35.160 | So basically, what we're going to learn is how get_files works, and get_image_files,
00:30:46.740 | get_splitter, get_labeler, get_categorize, get_multi_categorize, and then we'll put all
00:31:00.680 | that together with mnist, and then we'll see tifmdl.
00:31:05.840 | Okay, so let's start.
00:31:10.840 | So as you can see here, the first bits are kind of three major data-box-ish components,
00:31:15.800 | get_splitter and label.
00:31:17.560 | So the basic get thing we use, same as in Fast.ai version 1, is get_files.
00:31:25.980 | So get_files is going to take one, two, three, four parameters, the path that we're going
00:31:38.160 | to look for files in, which extensions to look for, whether we want to do it recursively,
00:31:43.880 | and whether there's just some subset of folders to include.
00:31:48.720 | So we have, in this notebook, we're using mnist, and so it's important to know here
00:31:56.600 | that this notebook is not just a tutorial notebook, this is a notebook that actually
00:32:00.400 | defines the module called data.core.
00:32:03.300 | So we're going to end up with something called data.core.
00:32:09.360 | Okay so this is the thing that we're building.
00:32:14.200 | You can see we've got get_image_files, get_files, and so forth.
00:32:24.040 | You'll notice that it's automatically creating a thunderall array, so that's created automatically
00:32:31.560 | by the Fast.ai notebook functionality.
00:32:34.720 | This is the thing that Python uses to decide what to import, if you say import *. In most
00:32:42.280 | Python libraries, people don't bother creating this, and that's one of the reasons that people
00:32:46.460 | normally say don't use import *, is because if you don't bother to create this and it's
00:32:51.000 | actually going to import also everything that is imported recursively, it gets really awful.
00:32:57.520 | But since we're super careful about what gets exported and how things are structured, you'll
00:33:02.860 | very rarely have problems if you use import *, so we try to make it as kind of REPL-friendly,
00:33:07.840 | interactive-friendly as possible.
00:33:09.600 | And so particularly because this is created automatically, it's a really, really handy
00:33:14.800 | thing.
00:33:17.800 | So that's why you'll see it in the Python module, but you won't see it in the notebook
00:33:21.320 | because it's automatic.
00:33:23.720 | So yeah, so this is kind of our first deep dive into literate programming, because we're
00:33:28.680 | actually building the data.core module, but as you can see, we have pros along the way.
00:33:36.280 | So the first step is to get a list of items, and an item is, can be kind of anything you
00:33:48.280 | like.
00:33:49.280 | An item list can be anything you like.
00:33:52.720 | So for stuff with vision, it's normally a list of paths, but an item list could be a
00:34:03.080 | data frame, could be a connection to a database, could be a network, pipe, as you see, you'll
00:34:10.680 | be able to do pretty much anything.
00:34:15.800 | But for now, for these ones, we're going to be using paths, and we'll be looking at using
00:34:20.780 | data frames later.
00:34:26.840 | So we grab our path, we're going to be, so get_files is going to be calling _get_files,
00:34:38.460 | so that's what this is, and you'll see _get_files, if we search for it here, _get_files, it did
00:34:49.360 | not appear in Thunderall, and the reason for that is that by default, anything that starts
00:34:54.420 | with an underscore is not exported by Fast.ai.
00:34:59.480 | Okay, so this is just a little function that will, let's see, we're being passed a bunch
00:35:14.800 | of files to look at, and so we're just going to turn them into pathlib.path objects.
00:35:22.680 | We don't include things that start with dot, because we're hidden.
00:35:26.200 | We also make sure that the extension appears in the extensions list, or that you didn't
00:35:31.840 | include an extension list, because if you didn't include an extension list, it means
00:35:34.720 | we don't care.
00:35:38.000 | Then get_files, the key thing is to understand how os.walk works, which we briefly mentioned
00:35:46.080 | in the Fast.ai courses, so look it up if you want some details, but basically os.walk is
00:35:52.000 | a ridiculously fast Python API for very, very, very rapidly looking for things on your file
00:35:58.780 | system, and get_files, we spent a lot of time optimizing this, and get_files can run on
00:36:04.960 | the entirety of ImageNet to grab, you know, all 1.3 million files in just a few seconds,
00:36:10.080 | I think it was like 8 seconds or something.
00:36:13.800 | There's no limit on how many files that can be, except of course the memory on your computer.
00:36:23.560 | So remember then that the way we kind of demonstrate functionality in the documentation is generally
00:36:31.080 | through tests.
00:36:36.280 | So the test here is we're going to grab all of the png files in train/3, in mnist, and
00:36:46.520 | in 3, and in 7, in the mnist sample that's the entirety of the images that we have, so
00:36:53.040 | we'll do things like make sure that the number of images in the parent when you use recursion
00:37:01.000 | is equal to both of the child children, stuff like that.
00:37:05.440 | And then we also just print out a few examples, and as you can see like most things in Fast.ai,
00:37:11.640 | we're getting back a capital L, an L object, so you can see how big it is, and it shows
00:37:17.380 | you a subset of some of the paths that are in it.
00:37:24.480 | So sometimes we kind of have additional checks that probably aren't that interesting for
00:37:33.160 | documentation purposes, but are just useful as tests, and when that happens we add #hide
00:37:38.520 | to the top of our cell, and that'll cause it not to be included in the docs.
00:37:45.880 | So let's have a look, dev.fast.ai, data, core, so if we have a look at files, so you can
00:37:59.800 | see here's the output, the html output of what we were just seeing, this is the most
00:38:05.160 | general way, blah blah blah, this is the most general way, blah blah blah, ok, and you can
00:38:10.600 | see that the first set of tests and stuff is shown here, the output is shown here, but
00:38:16.760 | the #hide version is not shown.
00:38:23.240 | Ok, as we've discussed before, in order to kind of easily get partial functions, we sometimes
00:38:34.520 | define things which, that's a bit smaller, we sometimes define functions that return
00:38:45.840 | functions, so here's a nice easy way to say, oh, this is going to create a function that
00:38:51.880 | non-recursively searches all png files, for instance.
00:38:56.220 | So then its behavior is just like what we saw.
00:39:00.500 | So this is really doing something very similar to just doing a partial function in Python.
00:39:09.520 | To get image files, we just call get_files, passing in image_extensions, which is everything
00:39:17.960 | in MIME types that starts with image, ok, so then we can test that one, so image_getter
00:39:35.220 | is the same as a file_getter, but we get image_files, test that one, and so there you go.
00:39:42.780 | So there's the whole of the functionality that currently exists for getting items, and
00:39:50.800 | I can imagine we'll add more of those over time, but that's a good start.
00:39:57.140 | So the second thing we need is functions for creating splits, and these are just things
00:40:01.260 | that return two lists, the list of stuff in the training set and the list of stuff in
00:40:07.780 | the validation set.
00:40:08.780 | So for example a random splitter is something which returns a function, optionally you can
00:40:15.940 | set the seed, and it's just going to randomly permute all of your indexes, and then cut
00:40:24.540 | it at wherever you asked for, and then return those two halves.
00:40:31.860 | So there you can see, and so some simple tests of that, grandparent_splitter is something
00:40:44.380 | which looks at the parent of the parent, so like an MNIST or an ImageNet, that would be
00:40:50.980 | where the path would be valid or train, so that's that.
00:41:02.840 | And so that all works the way you expect.
00:41:04.260 | So as you can see, these functions are super tiny, and so generally if you want to know
00:41:09.980 | more detail about how something works, and we should add more documentation obviously
00:41:14.660 | to some of this stuff as well, it's still early days, feel free to send in PRs with
00:41:20.660 | Docs if you're interested.
00:41:23.500 | So good question from Kevin about what if you wanted to get audio files for instance,
00:41:33.060 | I think you know I would probably put that in an audio module, yeah I don't feel super
00:41:42.800 | strongly about it though, it would probably make more sense to get image files actually
00:41:47.220 | to be in vision.core now I think about it, but yeah, probably better to have everything
00:41:56.600 | for an application in an application module.
00:42:02.840 | Okay so labeling is the thing which will for example take a path and pull the label out
00:42:08.040 | of it, so parent_label for instance will just label it with the name of the parent.
00:42:16.760 | So there's nothing to customize in this case, so we don't need a capital letter thing that
00:42:20.160 | returns a function, we can just call it directly, whereas regex_labeler, we actually need to
00:42:26.920 | pass in a pattern for what regex to label with, so that's why it's a capital thing which
00:42:32.240 | returns a function, so here's what regex_labeler looks like.
00:42:37.560 | So remember if you want to really understand how these things work, if any of them are
00:42:40.560 | confusing, open up the notebook and just like we do in the fast.ai lessons, experiment,
00:42:47.400 | try some other tests, add some cells to the docs and try things out, so like oh what's
00:42:54.760 | in items, and there they all are, and it's like oh so what if we f item0, lots of experimenting,
00:43:06.000 | lots of debugging, all that kind of stuff.
00:43:09.400 | Alright so there's the three basic steps, get_split_label, they're all very easy functions.
00:43:17.920 | So categorize is the thing that we have already used in 08, so to remind you, and so we're
00:43:27.840 | going to create something called category.create which is simply categorize, so when you see
00:43:32.560 | category.create, that's actually creating a categorize object, so for instance if we
00:43:39.440 | create a transform data set which goes cat_dog_cat, there's little items in it, and the transforms
00:43:46.880 | is this categorize, and then here we can test its behavior, so the vocabulary from those
00:43:58.120 | items should be cat_dog, for instance, the transformed version of cat should be 0, the
00:44:06.480 | decoded version of 1 should be dog, and so on.
00:44:11.320 | So everyone's question is should there be a hash_test, nope, we don't need hash_test,
00:44:15.480 | as you can see, they just appear directly, so we don't need to add anything to say this
00:44:19.440 | is a test, we just include tests.
00:44:22.240 | If a test doesn't pass, let's make one that doesn't pass, dog_dog, then you get an error.
00:44:38.680 | And as we mentioned last time, in fastai_dev, in the readme, here's the line that will run
00:44:49.800 | the notebooks in parallel, and if any of them fail, in fact I just ran it before and one
00:44:54.600 | of them failed, so I can show you, here we are, if one of them fails it looks like this,
00:45:01.640 | exception in blah blah blah dot ipymb, and then it'll show you the stack trace, and then
00:45:09.120 | it'll show you the error.
00:45:13.520 | So that's how tests work, tests are just regular cells which happen to have something which
00:45:20.160 | has an assertion in basically, that's all test_ec is, we'll get to the 00_test notebook
00:45:27.320 | eventually.
00:45:29.240 | And so how do we get coverage tests?
00:45:33.280 | No idea, it's not something I've thought about, that would be an interesting question to look
00:45:38.620 | at.
00:45:42.720 | It's not something I've cared about so much though I must say, because the tests always
00:45:46.160 | sit right next to the thing that they're testing, so it's really hard to have functionality
00:45:51.360 | that's not tested, it tends to be pretty obvious because you're kind of staring at it on the
00:45:55.320 | same screen.
00:46:00.400 | So a categorize is a transform, so therefore it has an encodes and a decodes.
00:46:10.480 | So when you create it, so let's just call it categorize, it's just a normal Python object
00:46:20.280 | here, so it's done to init, it works in the usual way, so you can actually create it with
00:46:25.800 | a predefined vocab if you like, and if so it'll assign it.
00:46:30.200 | If not, then it's going to use this special setup method.
00:46:38.080 | When does setup get called?
00:46:39.880 | Well you can see here when we create a `tifmds`, we're saying this is the list of items that
00:46:47.120 | we want to use with these transforms.
00:46:50.360 | So `tifmds` is going to, let's see, I'll just show you this, actually it's going to create
00:47:06.360 | a number of `tifmd_lists`, so we want to look at `tifmd_list`, and so here you can see `tifmd_list`
00:47:15.040 | in init will call `self.setup`, and `self.setup` will set up your transforms, and so that's
00:47:24.120 | the thing which is going to call `setup`, which in this case will set your vocab to
00:47:32.600 | a `category_map`, we'll look at it in a moment, that's just a method of vocab of categories,
00:47:37.960 | and it will use, this is a nice little idiom, it will use `dsource.train` if `dsource` has
00:47:44.640 | a `train` attribute, if it doesn't it'll just use `dsource`, it'll use your training set
00:47:50.520 | if there's a training set to find, otherwise it'll just use the whole data source.
00:47:57.240 | So that's a super important idea, this setup thing, we'll see more details of that when
00:48:01.920 | we look at the code of the pipeline and `tifm_ds` and `tifm_list`.
00:48:12.240 | You'll see that `dcodes` is saying that I want to return something of type `category`,
00:48:20.680 | and that has a `category.create`, and a `category` is pretty tiny, it's inheriting from `show_title`,
00:48:31.160 | which simply has a `show` method, as you would expect.
00:48:41.800 | And `show_title` is going to show passing in the keyword arguments that are in `self._show_args`,
00:48:50.360 | so in this case it's going to label it with the `category`.
00:48:57.280 | So the only other piece here is the `category_map`, and the `category_map` is just simply something
00:49:03.080 | which will grab all of the unique values in your column, optionally sort them.
00:49:18.920 | And then we'll also create the `object_to_int`, which is simply the opposite direction.
00:49:24.260 | So `l` has a `val_to_index`, which is a reverse map.
00:49:32.080 | OK, so that's `category`.
00:49:38.320 | So Hector's question about the videos reminds me to talk about the forum, which is, thanks
00:49:53.880 | to people who contributed notes and other things, I was trying to think about how to
00:49:59.960 | structure this.
00:50:03.040 | What we might do is let's create a `fastai v2_code_walkthrough_2`, use this for `walkthrough_2_notes_questions_and_expressions_object_to_int`.
00:50:27.440 | So, let's make that into a wiki.
00:50:39.840 | And so now that would be a good place to put notes, and so there's a good set of notes
00:50:46.320 | already for number one, thanks to Elena Onigpost.
00:50:50.680 | They're not quite complete yet, so either Elena or somebody else can hopefully finish
00:50:56.800 | off the last bit.
00:50:57.800 | Oh, it looks like maybe they are complete now.
00:50:58.800 | Ah, there you go, she's done some more than since I last looked.
00:51:03.400 | Very nice.
00:51:04.400 | OK, so it is finished, beautiful.
00:51:07.360 | So it's a bit tricky in the forums if multiple people edit the same wiki post at the same
00:51:16.520 | time, you'll get conflicts.
00:51:18.220 | So one thing you could do is you could add notes by replying to this, and then I can
00:51:23.720 | copy and paste them into the wiki, might be one way to avoid conflicts.
00:51:34.720 | Also if you look at the Fast.ai version 2.0 transforms_pipeline_data_blocks, Ian Vijay
00:51:44.200 | was kind enough to start adding some notes, so I've tried to try to give that some structure.
00:51:51.220 | So you can basically create something where you've got second level headings for modules,
00:51:58.800 | third level headings for classes and functions, and then what I did for these was if you click
00:52:08.960 | on this random splitter instance, it will actually take you to the line of code in GitHub.
00:52:16.440 | To do that you can just click on the line of code, like so, and then click on the three
00:52:21.320 | dots and say "copy permalink" and it will actually create a link to that exact line
00:52:31.160 | of code, which is pretty cool.
00:52:36.240 | And so that was for random splitter, so we can then go down here and say "bump" like
00:52:44.760 | so, and so that's a permalink to that line of code.
00:52:50.880 | So that's that, and then in the daily code walkthroughs thread, as I'm sure you've noticed,
00:52:58.680 | I'm going to start putting the video and the notes link just in the list at the top here.
00:53:07.160 | How many walkthroughs are planned, as many as we need.
00:53:11.760 | What is desource, that's just a data source, it could be a data source object, but really
00:53:17.960 | it's anything which can be treated as a list, or anything which works with any transform
00:53:25.360 | you're using, it doesn't even have to be necessarily treated as a list.
00:53:29.000 | Merge conflicts, yeah, as Molly said, once you've run run_after_git_clone, that'll get
00:53:36.400 | rid of a lot of the conflicts because a lot of the metadata is removed and stuff like
00:53:41.280 | that.
00:53:42.280 | Other than that, we just try to push regularly, if we're going to be working on a notebook
00:53:49.600 | for a while that we think somebody else might be working on, we'll let them know.
00:53:54.960 | Yeah, nowadays we don't have too many conflict problems anymore.
00:53:58.440 | And the girl asked, "How did I start using PyTorch?"
00:54:07.320 | I started using it kind of when it was first released, so yeah, I guess I just read the
00:54:14.920 | docs and tutorials.
00:54:18.640 | I think nowadays just using the fast.ai lessons is probably the easiest way to get started.
00:54:24.320 | The further you get into them the more you'll learn about PyTorch.
00:54:27.760 | That would be a good thing to ask other people on the forums too, because there are a lot
00:54:30.920 | of other people that have started using PyTorch more recently than me, who might be better
00:54:34.640 | placed to answer that question.
00:54:41.660 | So as well as the category, we also have multi-category.
00:54:45.880 | The multi-category is something like we have in Planet.
00:54:49.920 | Remember in Planet, each image can have multiple things, like cloudy and primary and road.
00:55:01.000 | So here's an example of items for a multi-category dependent variable.
00:55:07.360 | You can see each one now is a list.
00:55:11.340 | So item number one is labeled with b and c, item number two is labeled with a, item number
00:55:15.960 | three is labeled with a and c.
00:55:19.160 | So the vocab that we get from that should be a, b, c.
00:55:25.400 | And categorizing a, c should give us 0, 2.
00:55:31.960 | So that's what multi-categorize does, and as you can see it looks super similar to what
00:55:41.000 | we had before, except encodes has to do it for everything in the list, and decodes has
00:55:45.960 | to do it for everything in the list as well.
00:55:52.040 | And so multi-category show is a little bit different, because we've now got multiple
00:55:55.760 | things to show, so we have to use the string join in Python.
00:56:06.640 | And so one of the handy test functions that we'll learn more about later is test_stdout,
00:56:13.120 | because the show functions actually print things, and so how do you test whether something
00:56:18.000 | is printed correctly?
00:56:19.000 | Well this will actually test whether this function prints out this thing or not, so
00:56:27.000 | that's a useful little thing to know about.
00:56:37.480 | So normally you need to one-hot encode multi-category stuff, so we've got a one-hot encoding here,
00:56:45.280 | which works the same way that you've seen in PyTorch version 1 in the lessons.
00:56:51.400 | And so here's a transform for that, where the encodes is simply going to call one-hot,
00:57:01.840 | as you see.
00:57:05.680 | And to decode, it does one-hot decode.
00:57:17.680 | I think these return types are unnecessary, yes, looks like they are, let's see if this
00:57:29.280 | still works when I remove them, yep, looks like it does.
00:57:39.840 | Okay, now the way we've done types and dispatching and stuff has changed a little bit over time,
00:57:45.920 | so some of our code still has stuff that's more complex than necessary, I will try to
00:57:49.920 | remove it as I see it.
00:57:51.520 | If you're ever not sure why a type annotation exists, feel free to ask, the answer might
00:57:56.880 | be that it's not needed.
00:58:05.080 | So here's a good little test then, a little mini-integration test of taking a bunch of
00:58:12.360 | items and passing it through a pipeline that contains multi-categorize and one-hot encode.
00:58:22.480 | And so that should, so TDS1, that would be A, should be 1 0 0, and then decode of 0 1
00:58:35.360 | 1 should be B C, and test it out.
00:58:39.920 | Okay, so that is that.
00:58:43.240 | So we can put all this together to do mnist by calling getImageFiles, splitter, and so
00:58:56.320 | notice these aren't being exported because this is DataCore, so we haven't created any
00:59:02.200 | of the Vision application yet, so we don't want to export anything that uses Pillow,
00:59:06.440 | but you can certainly include it in the tests, right?
00:59:09.040 | So for the tests we can bring these basic functions in, something that can open an image,
00:59:17.800 | something that can convert an image into a tensor, so here's our two transform pipelines
00:59:24.680 | that will look pretty similar to what we did in 0.8, and so here's our tifmds that takes
00:59:30.120 | our training set and our transforms, and so then we can grab one item of it, we can decode
00:59:37.320 | it, and showAt will take our tifmds and show the thing at this point, and you can optionally
00:59:51.800 | pass in some parameters that will be passed along to matplotlib, and these kinds of things
01:00:02.760 | we also check that there are some tests, that the title looks right, and that the figure
01:00:08.960 | is actually created.
01:00:12.800 | So that's like a good little, you know, this entire thing is pretty self-standing, so this
01:00:27.680 | is pretty self-standing, so it's kind of a good place to get going.
01:00:32.720 | So Miguel says, "Completed the first AI, but you need to learn more PyTorch."
01:00:44.400 | That would be a good thing to ask on the forums, I think.
01:00:49.000 | I mean, if you're doing all the assignments, then by the end of 14 lessons, I would have
01:00:52.280 | thought you'd have to be pretty damn good at PyTorch, because you do have to do a lot
01:00:57.200 | of practice, but yeah, I guess other people might be able to have their own ideas about
01:01:05.760 | that.
01:01:06.760 | So Vishnu said, "I made a mistake about what imageToTensor is doing," that's true, it's
01:01:12.120 | actually creating an array, so I'm glad you asked that question, because this is going
01:01:19.280 | to be turned - okay, so this is actually a great question.
01:01:23.960 | The return type of here is tensorImage, and tensorImage is one of these nifty little things
01:01:31.840 | we've added, which is something which - this is taking a long time - looks like our server's
01:01:43.720 | going slowly - which, as you can see, is simply calling just pass, so it's just something
01:01:50.400 | which we use to mark the type so that we can create transforms that are restricted to that
01:01:58.960 | type.
01:01:59.960 | But it's basically just a tensor, it's a subclass of tensor, in fact.
01:02:06.440 | But you'll notice this is actually not a transform, it's just a function, but the cool thing is
01:02:13.400 | that any time that you create something that's going to be turned into a pipeline, any functions
01:02:22.800 | in there that aren't transforms will be turned into transforms.
01:02:28.680 | So you can actually just go transform imageToTensor, and that creates a transform
01:02:41.400 | object that will run that function, so that's a handy little trick, and we'll learn more
01:02:46.760 | about it when we get to the transform thing.
01:02:49.400 | So because this gets turned into a transform, that means that this will automatically take
01:02:53.720 | our NumPy array and will cast it to a tensor, and it'll also make sure that it only gets
01:03:01.040 | called on images.
01:03:06.960 | Okay, so last thing for today, tifmdl.
01:03:23.520 | So tifmdl is something that inherits from Dataloader, but actually this is not a PyTorch
01:03:32.040 | Dataloader, this is a fastai data.load.dataloader.
01:03:40.100 | So we've actually created our own Dataloader to add a lot of handy extra stuff to PyTorch's
01:03:48.440 | Dataloader, and one of the nice things we've made it is much more inheritable, so we've
01:03:53.480 | inherited from that Dataloader, and what tifmdl does is it turns the Dataloader into something
01:04:00.040 | which understands transforms, as the name suggests.
01:04:08.160 | To fully understand this, we'll need to look at the code for Dataloader, which we can do
01:04:14.060 | next time, but there's a few interesting things to show.
01:04:19.080 | Let's have a look at it in use first of all.
01:04:23.020 | So here's a bunch of familiar looking transforms, so here's a tifmds, which takes our items,
01:04:31.160 | which is the MNIST paths, and transforms them, so it's going to create a pillow image and
01:04:37.420 | labeled categories, and then tifmdl is going to take that dataset and convert the images
01:04:46.980 | to tensors in the Dataloader.
01:04:51.340 | So let's try that, and so we can now see there's a batch, and so this is a batch size of 4,
01:05:06.940 | so we've got 4 labels and 4 images, but one of the really interesting lines of code here
01:05:14.660 | is the test at the bottom, it's testing that the decoded version of the batch, when we
01:05:25.300 | map the function type over it, is that it's going to be tensor image comma category.
01:05:31.260 | So why is that interesting?
01:05:34.420 | Well that's interesting because what this is showing is that fastai knows how to take
01:05:40.260 | a tensor that comes out of a Dataloader, which doesn't generally have types, and will put
01:05:48.220 | the correct types back onto it, and so this is super handy for inference, because what
01:05:54.340 | it means is that in production, your predictions and stuff are going to have proper types,
01:06:03.460 | so you can actually call normal methods and transforms and stuff on them, so it's super
01:06:09.620 | handy for inference, and also for applying stuff to a test set, things like that.
01:06:20.340 | So this is actually an interesting line of code, so let's look at it.
01:06:28.140 | So we're going to start with tdl.decode_batch_b.
01:06:35.220 | So remember b was our batch, it's going to contain four MNIST images and four labels,
01:06:43.180 | so the decoded version of that is nearly the same thing, but now we've got, rather than
01:06:54.500 | two things, we've got four things, because they're four pairs of image and label, and
01:07:01.020 | now you'll see the label's a string, image and label.
01:07:06.540 | So that's what decode_batch is going to do, is it's going to turn it into a form that's
01:07:10.780 | much more ready for showing, and so I think we should be able to go show_titled_image,
01:07:22.580 | and then we could say "show us the zeroth one of those," yep, there it is, OK?
01:07:40.180 | And so then, what I wanted to do was I basically, that contains two things, if I just grab the
01:07:47.020 | first image, it contains the image and the category, and what I really wanted to do was
01:07:54.620 | to say like x,y equals that, and then print out type x,type y, which is a little bit awkward,
01:08:07.060 | so what we can do instead is we can wrap this in an L, and then just call mapped, and that
01:08:14.580 | will map a function over it, and the function I want to map over it is type, and that gives
01:08:20.180 | me exactly the same thing.
01:08:22.260 | So that's what that does.
01:08:24.500 | Madovan asks, "Did Swift AI influence the design of V2?"
01:08:30.820 | Yeah, a bit, I've been using static languages a lot longer than dynamic languages, honestly,
01:08:39.740 | so I don't think the type stuff is particularly from that.
01:08:44.500 | In fact, we're using types in a very, very different way to Swift.
01:08:49.340 | Swift is statically typed, so you can't quite do the same kinds of things with types.
01:08:54.740 | This is kind of like a, to me, really interesting use of dynamic types.
01:09:00.940 | And so like a, I think part of it comes out of saying like, OK, Python has a lot of issues
01:09:08.580 | with performance because it's a dynamically typed language, but we may as well at least
01:09:14.020 | take advantage of the dynamic typing of the language.
01:09:18.580 | So we're kind of trying to take more advantage of Python's foundations, it's kind of part
01:09:26.900 | of what's going on.
01:09:27.900 | But yeah, I think doing the stuff with Swift certainly had some influence, and certainly
01:09:34.260 | talking to Chris Latner had some influence, specifically.
01:09:42.660 | So a "transformDataLoader" has a ".oneBatch" method, which actually you'll see isn't here,
01:09:51.900 | and that's because it's in DataLoader, but we can look at "termDl.oneBatch", and as you
01:10:00.980 | can see, it'll give us the definition even though it's actually in a superclass.
01:10:05.440 | And as you can see, it's just going next, which we do all the time, so we thought we
01:10:09.420 | may as well put it into a method.
01:10:12.380 | It's really something you just use for interactive usage and tests.
01:10:20.140 | So let's look at "termDl" some more.
01:10:24.780 | Here's a transform with encodes and decodes, and so specifically encodes is -x, decodes
01:10:32.420 | is -x, so that makes sense, it's a reversible negative transform.
01:10:40.420 | And these are both things that can be applied to a whole batch at a time, because the negative
01:10:46.580 | operator in Python doesn't care what rank something is.
01:10:51.700 | So we can put that in the after batch, and so if we had cruder as well, then this would
01:10:56.100 | actually run on the GPU.
01:11:01.220 | And these things also all work with more than one worker, so there's no need to do next
01:11:07.940 | in a tdl, we can just do tdl.one_batch.
01:11:17.180 | And in this case, it's actually making sure that, so if we look at train_ds, that's got
01:11:29.260 | an image and a label, and the type of train_ds[0] image is a tensor image, and so one of the
01:11:43.900 | interesting things here is we're checking that the type after going through the transform
01:11:50.140 | is still a tensor image.
01:11:53.960 | Now that's actually not particularly easy to do, because look at this.
01:11:58.380 | What if we say t equals that, and then we'll go t2 equals negative t, so type of t is tensor
01:12:11.380 | image, but type of t2, oh sorry, let's actually just do it a different way, torch.neg(t) is
01:12:27.760 | tensor.
01:12:28.760 | You've got to be a bit careful, and so actually this would be a better test if we used torch.neg(x).
01:12:39.600 | It still passes, even though it looks like it shouldn't pass, and the reason for that
01:12:55.740 | is that all of the transformation pipelines, tf.nds, tf.ndl, stuff like that, all check
01:13:02.260 | after it goes through encodes or decodes that the type doesn't change, and if it does change,
01:13:12.020 | then it will convert the type back to what it used to be, but it only does that in a
01:13:17.260 | specific situation, which is this one, where you end up with a superclass, torch.tensor,
01:13:25.160 | of the input, whereas the input was a subclass of that, so tensor image is a subclass of
01:13:32.120 | tensor.
01:13:33.120 | This is something that happens all the time with like pillow subclasses and tensor subclasses,
01:13:37.240 | that very often the operations will forget what subclass it was, so you don't have to
01:13:42.640 | do anything, it will automatically put back the correct subclass for you.
01:13:51.780 | It's possible to opt out of that behavior by just putting return type of none, and that
01:14:01.680 | tells the transform system not to do that for you.
01:14:08.880 | As you can see, it now doesn't pass, so that's how you can opt out of it.
01:14:13.240 | I don't think I've ever needed it yet though, so far it always has made sense in everything
01:14:19.000 | I've done that you always want to keep the subclass type information, so that all happens
01:14:24.820 | automatically.
01:14:25.820 | Okay, so why is this here?
01:14:26.820 | I don't think this is meant to be here, I think it's in the wrong spot.
01:14:46.380 | Let's double check, I think we've got this over here already.
01:14:55.100 | I think O1 core is getting too big, we might have to split it up.
01:15:14.900 | Oh, that does look different, that's interesting.
01:15:39.620 | Here's another example, we've created a class called capital I int, so the normal int in
01:16:05.060 | Python is small i int, capital I int is a subclass of that, but it's also a subclass
01:16:17.500 | of show_title, so it's a type of int that has a show method, basically.
01:16:22.540 | So we generally, if you want to be able to show an int, then you just put returns a capital
01:16:29.660 | I int.
01:16:36.580 | And so here, let's see, are we doing a different deal, yeah, so here we're just basically checking
01:16:44.940 | that this type annotation works, and we'll learn more about those type annotations once
01:16:50.740 | we look at the transforms notebook, but as you can see, all the types are following through
01:16:59.340 | correctly.
01:17:00.340 | Okay, so some of these other things I want to come back to later, specifically how filters
01:17:10.060 | work, so let's have a bit more of a look at dataloader.
01:17:19.060 | So I'm just going to show you a couple of pieces of tifmdl, and then we'll go back to
01:17:24.460 | dataloader, and then we'll come back to tifmdl.
01:17:28.020 | One thing that's interesting here is that there is a thing called delegates on the top
01:17:34.980 | here, a decorator, which we have, composition, there we go, I have described in more detail
01:17:52.360 | in this article, okay, but I'll give you a quick summary of what's going on, have a look
01:18:06.740 | here.
01:18:07.740 | Basically, tifmdl is a subclass of dataloader, so when we call thunder_init, we basically
01:18:14.060 | want to pass along any keyword arguments that you gave us.
01:18:20.140 | The problem is that normally when you put quags like this, there are a couple of issues.
01:18:27.960 | The first issue is that if we want to use things like shift-tab, and we go to tifmdl,
01:18:37.340 | and then we say shift-tab, rather than seeing the actual list of things that we can pass
01:18:42.060 | in, we would see quags, which is super annoying, but check this out.
01:18:50.220 | That's not what happens here.
01:18:51.900 | We see the actual arguments.
01:18:56.500 | How does that happen?
01:18:57.500 | And it's not just we see them, but we also have all the normal tab completion for them
01:19:02.340 | as well, even though those are actually coming from dataloader.
01:19:14.100 | The reason that's working is because of this delegates decorator, and what the delegates
01:19:19.620 | decorator does is it will replace the signature of a class init or function, depending on
01:19:28.380 | what you put it on, and if you put it on a class, by default it will remove the quags
01:19:35.420 | from the signature and replace them with the arguments of the parent class, and so that's
01:19:45.220 | why this works so nicely.
01:19:48.740 | So we use this kind of stuff quite a lot.
01:19:50.820 | So you'll quite often see quags used in Fast.ai version 2, but you should find in every case
01:19:57.320 | that we've used them, you'll always get proper shift-tab and completion support, and so if
01:20:07.260 | you ever find that's not true, then feel free to let us know, because that would be considered
01:20:10.900 | a bug, generally speaking.
01:20:14.140 | So this really does behave like a dataloader, but it's a dataloader which has a few extra
01:20:23.220 | things, perhaps most interestingly is it has show_batch.
01:20:34.340 | So show_batch is the thing that we saw over here.
01:20:43.140 | We saw it for segmentation, show_batch, and we saw it for pets, show_batch.
01:20:52.900 | So the idea is that you can take a tfmdl and call show_batch, and it will know how to display
01:21:01.280 | whatever's there, and it even knows how to combine the information from multiple data
01:21:06.300 | types, in this case a mask and an image, in this case an image and a category.
01:21:19.180 | You can pass in a batch to show, if you don't it will default to one batch as it says, as
01:21:26.740 | you can see here, and so what it will do is it will first of all decode that batch, and
01:21:35.740 | specifically decode means decode using, decode the after_batch transform, and decode the
01:21:45.020 | before_batch transform, so that's all the stuff that happens after it's collated.
01:21:53.380 | We then have these things called contexts, and contexts is like, it's either the plots,
01:22:00.300 | like in this grid of plots, each one of these will be a different ctx, a different context,
01:22:08.060 | for things that display a data frame, each column I think it is, or maybe it's a row,
01:22:12.980 | is a different context, so here if you don't tell it what context to use, it will actually
01:22:21.900 | ask the type, the object in the batch to provide it for us, we'll learn more about that later,
01:22:34.220 | and it will then attempt to decode the batch using the after_item decode, and it will then
01:22:47.900 | attempt to call .show, which we will see .show in more detail later.
01:23:01.660 | You'll see that we're often using things like compose, so hopefully you've seen that from
01:23:07.320 | previous fast.ai, but basically compose is going to call this function, and then this
01:23:16.620 | function.
01:23:17.620 | This is a really useful idiom, if your dataset has a decode method, then this will get self.dataset.decode,
01:23:29.980 | if it doesn't, it will get no_op, so it does nothing, that's a nice, easy way to do that.
01:23:44.720 | So yeah, that's probably enough for now, that's 90 minutes, oh, the other thing you'll see
01:23:54.620 | is we kind of generally have documentation and examples for the kind of high-level how
01:24:01.340 | the class works first, and then underneath it you'll have a subsection called methods,
01:24:05.860 | where we go through each method and show you how to use each method separately, and again
01:24:12.060 | there's lots of room to add more pros and examples to a lot of these, but every one
01:24:17.620 | of them has at least one example, so you can see how each thing works independently.
01:24:24.860 | Okay, so next time we will at least make sure we go through and finish off the CUDA, byte
01:24:32.380 | to float transform, normalization, and databunch, and I'm not quite sure where we'll go from
01:24:39.020 | there, but we will figure it out.
01:24:41.700 | Okay, thanks everybody for joining in, and thanks also for those of you who have been
01:24:48.020 | so helpful in adding some documentation and notes and stuff on the forums, that is super
01:24:53.020 | cool.
01:24:54.020 | See you next time!
01:24:54.700 | you