Building makemore Part 5: Building a WaveNet
Chapters
0:0 intro1:40 starter code walkthrough
6:56 let’s fix the learning rate plot
9:16 pytorchifying our code: layers, containers, torch.nn, fun bugs
17:11 overview: WaveNet
19:33 dataset bump the context size to 8
19:55 re-running baseline code on block_size 8
21:36 implementing WaveNet
37:41 training the WaveNet: first pass
38:50 fixing batchnorm1d bug
45:21 re-training WaveNet with bug fix
46:7 scaling up our WaveNet
46:58 experimental harness
47:44 WaveNet but with “dilated causal convolutions”
51:34 torch.nn
52:28 the development process of building deep neural nets
54:17 going forward
55:26 improve on my loss! how far can we improve a WaveNet on this data?
00:00:00.000 | Hi everyone. Today we are continuing our implementation of MakeMore,
00:00:03.760 | our favorite character-level language model. Now, you'll notice that the background behind
00:00:08.000 | me is different. That's because I am in Kyoto and it is awesome. So I'm in a hotel room here.
00:00:12.560 | Now, over the last few lectures we've built up to this architecture that is a multi-layer
00:00:18.160 | perceptron character-level language model. So we see that it receives three previous characters
00:00:22.720 | and tries to predict the fourth character in a sequence using a very simple multi-layer
00:00:26.720 | perceptron using one hidden layer of neurons with tenational neurities.
00:00:30.720 | So what I'd like to do now in this lecture is I'd like to complexify this architecture.
00:00:34.880 | In particular, we would like to take more characters in a sequence as an input, not just
00:00:39.440 | three. And in addition to that, we don't just want to feed them all into a single hidden layer
00:00:44.720 | because that squashes too much information too quickly. Instead, we would like to make a deeper
00:00:49.200 | model that progressively fuses this information to make its guess about the next character in
00:00:54.160 | a sequence. And so we'll see that as we make this architecture more complex, we're actually
00:00:59.680 | going to arrive at something that looks very much like a WaveNet. So WaveNet is this paper
00:01:04.800 | published by DeKind in 2016, and it is also a language model basically, but it tries to predict
00:01:12.000 | audio sequences instead of character-level sequences or word-level sequences. But fundamentally,
00:01:17.600 | the modeling setup is identical. It is an autoregressive model and it tries to predict
00:01:23.120 | the next character in a sequence. And the architecture actually takes this interesting
00:01:27.520 | hierarchical sort of approach to predicting the next character in a sequence with this tree-like
00:01:33.440 | structure. And this is the architecture, and we're going to implement it in the course of this video.
00:01:38.960 | So let's get started. So the story code for part five is very similar to where we ended up in
00:01:44.400 | part three. Recall that part four was the manual backpropagation exercise that is kind of an aside.
00:01:50.160 | So we are coming back to part three, copy-pasting chunks out of it, and that is our starter code
00:01:54.400 | for part five. I've changed very few things otherwise. So a lot of this should look familiar
00:01:58.720 | to you if you've gone through part three. So in particular, very briefly, we are doing imports.
00:02:03.760 | We are reading our data set of words, and we are processing the data set of words into individual
00:02:10.480 | examples, and none of this data generation code has changed. And basically, we have lots and lots
00:02:15.200 | of examples. In particular, we have 182,000 examples of three characters trying to predict
00:02:22.000 | the fourth one. And we've broken up every one of these words into little problems of given three
00:02:27.520 | characters, predict the fourth one. So this is our data set, and this is what we're trying to get the
00:02:31.120 | neural net to do. Now, in part three, we started to develop our code around these layer modules
00:02:38.480 | that are, for example, a class linear. And we're doing this because we want to think of these
00:02:43.440 | modules as building blocks and like a Lego building block bricks that we can sort of like
00:02:48.960 | stack up into neural networks. And we can feed data between these layers and stack them up into
00:02:54.240 | sort of graphs. Now, we also developed these layers to have APIs and signatures very similar
00:03:01.280 | to those that are found in PyTorch. So we have torch.nn, and it's got all these layer building
00:03:06.160 | blocks that you would use in practice. And we were developing all of these to mimic the APIs of
00:03:10.720 | these. So for example, we have linear. So there will also be a torch.nn.linear, and its signature
00:03:17.360 | will be very similar to our signature, and the functionality will be also quite identical as far
00:03:21.680 | as I'm aware. So we have the linear layer with the batch norm 1D layer and the 10H layer that we
00:03:27.200 | developed previously. And linear just does a matrix multiply in the forward pass of this module.
00:03:33.600 | Batch norm, of course, is this crazy layer that we developed in the previous lecture. And what's
00:03:38.880 | crazy about it is, well, there's many things. Number one, it has these running mean and
00:03:44.080 | variances that are trained outside of back propagation. They are trained using exponential
00:03:49.840 | moving average inside this layer, what we call the forward pass. In addition to that,
00:03:55.600 | there's this training flag because the behavior of batch norm is different during train time
00:04:00.400 | and evaluation time. And so suddenly, we have to be very careful that batch norm is in its
00:04:04.160 | correct state, that it's in the evaluation state or training state. So that's something to now keep
00:04:08.560 | track of, something that sometimes introduces bugs because you forget to put it into the right mode.
00:04:13.840 | And finally, we saw that batch norm couples the statistics or the activations across the examples
00:04:20.240 | in the batch. So normally, we thought of the batch as just an efficiency thing. But now,
00:04:25.360 | we are coupling the computation across batch elements, and it's done for the purposes of
00:04:30.880 | controlling the activation statistics as we saw in the previous video. So it's a very weird layer,
00:04:36.320 | at least a lot of bugs, partly, for example, because you have to modulate the training and
00:04:41.280 | eval phase and so on. In addition, for example, you have to wait for the mean and the variance
00:04:48.720 | to settle and to actually reach a steady state. And so you have to make sure that you... Basically,
00:04:54.400 | there's state in this layer, and state is harmful, usually. Now, I brought out the generator object.
00:05:02.640 | Previously, we had a generator equals G and so on inside these layers. I've discarded that in
00:05:07.600 | favor of just initializing the torch RNG outside here just once globally, just for simplicity.
00:05:15.840 | And then here, we are starting to build out some of the neural network elements. This should look
00:05:20.480 | very familiar. We have our embedding table C, and then we have a list of layers. And it's a linear,
00:05:27.120 | feeds to batch or feeds to 10H, and then a linear output layer. And its weights are scaled down,
00:05:33.040 | so we are not confidently wrong at initialization. We see that this is about 12,000 parameters.
00:05:38.400 | We're telling PyTorch that the parameters require gradients. The optimization is, as far as I'm
00:05:44.320 | aware, identical and should look very, very familiar. Nothing changed here. Lost function
00:05:50.480 | looks very crazy. We should probably fix this. And that's because 32 batch elements are too few.
00:05:57.120 | And so you can get very lucky or unlucky in any one of these batches, and it creates a very thick
00:06:02.560 | loss function. So we're going to fix that soon. Now, once we want to evaluate the trained neural
00:06:08.560 | network, we need to remember, because of the batch norm layers, to set all the layers to
00:06:12.560 | be training equals false. This only matters for the batch norm layer so far. And then we evaluate.
00:06:18.480 | We see that currently we have a validation loss of 2.10, which is fairly good, but there's still
00:06:25.760 | a ways to go. But even at 2.10, we see that when we sample from the model, we actually get relatively
00:06:31.520 | name-like results that do not exist in a training set. So for example, Yvonne, Kilo, Pras, Alaya,
00:06:40.640 | et cetera. So certainly not unreasonable, I would say, but not amazing. And we can still push this
00:06:48.560 | validation loss even lower and get much better samples that are even more name-like. So let's
00:06:53.760 | improve this model now. OK, first, let's fix this graph, because it is daggers in my eyes,
00:06:59.520 | and I just can't take it anymore. So loss_i, if you recall, is a Python list of floats. So for
00:07:07.040 | example, the first 10 elements look like this. Now, what we'd like to do basically is we need
00:07:12.480 | to average up some of these values to get a more representative value along the way.
00:07:19.520 | So one way to do this is the following. In PyTorch, if I create, for example, a tensor of
00:07:25.680 | the first 10 numbers, then this is currently a one-dimensional array. But recall that I can view
00:07:30.880 | this array as two-dimensional. So for example, I can view it as a 2x5 array, and this is a 2D
00:07:36.560 | tensor now, 2x5. And you see what PyTorch has done is that the first row of this tensor is the first
00:07:42.800 | five elements, and the second row is the second five elements. I can also view it as a 5x2,
00:07:48.560 | as an example. And then recall that I can also use -1 in place of one of these numbers,
00:07:55.360 | and PyTorch will calculate what that number must be in order to make the number of elements work
00:08:00.400 | out. So this can be this, or like that. Both will work. Of course, this would not work.
00:08:06.800 | Okay, so this allows it to spread out some of the consecutive values into rows. So that's very
00:08:14.240 | helpful, because what we can do now is, first of all, we're going to create a Torch.tensor
00:08:18.800 | out of the list of floats. And then we're going to view it as whatever it is, but we're going to
00:08:26.560 | stretch it out into rows of 1,000 consecutive elements. So the shape of this now becomes
00:08:32.480 | 200 by 1,000, and each row is 1,000 consecutive elements in this list. So that's very helpful,
00:08:40.320 | because now we can do a mean along the rows, and the shape of this will just be 200.
00:08:46.000 | And so we've taken basically the mean on every row. So plt.plot of that should be something nicer.
00:08:52.320 | Much better. So we see that we've basically made a lot of progress. And then here, this is the
00:08:58.720 | learning rate decay. So here we see that the learning rate decay subtracted a ton of energy
00:09:03.680 | out of the system, and allowed us to settle into the local minimum in this optimization.
00:09:09.280 | So this is a much nicer plot. Let me come up and delete the monster, and we're going to be
00:09:15.040 | using this going forward. Now, next up, what I'm bothered by is that you see our forward pass is
00:09:20.640 | a little bit gnarly, and takes way too many lines of code. So in particular, we see that
00:09:25.680 | we've organized some of the layers inside the layers list, but not all of them for no reason.
00:09:31.120 | So in particular, we see that we still have the embedding table special case outside of the layers.
00:09:36.800 | And in addition to that, the viewing operation here is also outside of our layers.
00:09:40.880 | So let's create layers for these, and then we can add those layers to just our list.
00:09:45.360 | So in particular, the two things that we need is here, we have this embedding table,
00:09:51.200 | and we are indexing at the integers inside the batch xb, inside the tensor xb.
00:09:57.520 | So that's an embedding table lookup just done with indexing. And then here we see that we
00:10:03.440 | have this view operation, which if you recall from the previous video, simply rearranges the
00:10:08.320 | character embeddings and stretches them out into a row. And effectively, what that does is the
00:10:15.040 | concatenation operation, basically, except it's free because viewing is very cheap in PyTorch.
00:10:20.480 | And no memory is being copied. We're just re-representing how we view that tensor.
00:10:25.280 | So let's create modules for both of these operations, the embedding operation and the
00:10:32.000 | flattening operation. So I actually wrote the code just to save some time. So we have a module
00:10:39.600 | embedding and a module flatten, and both of them simply do the indexing operation in a forward
00:10:45.200 | pass and the flattening operation here. And this c now will just become a self.weight inside an
00:10:54.800 | embedding module. And I'm calling these layers specifically embedding and flatten because it
00:10:59.920 | turns out that both of them actually exist in PyTorch. So in PyTorch, we have n and dot embedding,
00:11:05.520 | and it also takes the number of embeddings and the dimensionality of the embedding, just like
00:11:09.440 | we have here. But in addition, PyTorch takes in a lot of other keyword arguments that we are not
00:11:14.240 | using for our purposes yet. And for flatten, that also exists in PyTorch, and it also takes
00:11:21.360 | additional keyword arguments that we are not using. So we have a very simple flatten.
00:11:26.560 | But both of them exist in PyTorch, they're just a bit more simpler. And now that we have these,
00:11:31.360 | we can simply take out some of these special cased things. So instead of c, we're just going
00:11:40.000 | to have an embedding and a vocab size and n embed. And then after the embedding, we are going to
00:11:47.120 | flatten. So let's construct those modules. And now I can take out this c. And here, I don't have to
00:11:54.080 | special case it anymore, because now c is the embedding's weight, and it's inside layers.
00:12:00.160 | So this should just work. And then here, our forward pass simplifies substantially,
00:12:07.600 | because we don't need to do these now outside of these layer, outside and explicitly. They're now
00:12:13.600 | inside layers, so we can delete those. But now to kick things off, we want this little x, which
00:12:20.960 | in the beginning is just xb, the tensor of integers specifying the identities of these
00:12:25.760 | characters at the input. And so these characters can now directly feed into the first layer,
00:12:30.720 | and this should just work. So let me come here and insert a break, because I just want to make
00:12:36.000 | sure that the first iteration of this runs and that there's no mistake. So that ran properly.
00:12:40.720 | And basically, we've substantially simplified the forward pass here. Okay, I'm sorry,
00:12:45.520 | I changed my microphone. So hopefully, the audio is a little bit better. Now,
00:12:50.320 | one more thing that I would like to do in order to PyTorchify our code in further
00:12:53.840 | is that right now, we are maintaining all of our modules in a naked list of layers.
00:12:57.520 | And we can also simplify this, because we can introduce the concept of PyTorch containers.
00:13:03.920 | So in torch.nn, which we are basically rebuilding from scratch here, there's a concept of containers.
00:13:08.400 | And these containers are basically a way of organizing layers into lists or dicts and so on.
00:13:15.520 | So in particular, there's a sequential, which maintains a list of layers, and is a module
00:13:21.040 | class in PyTorch. And it basically just passes a given input through all the layers sequentially,
00:13:26.400 | exactly as we are doing here. So let's write our own sequential. I've written a code here.
00:13:31.920 | And basically, the code for sequential is quite straightforward. We pass in a list of layers,
00:13:37.520 | which we keep here. And then given any input in a forward pass, we just call the layers
00:13:42.080 | sequentially and return the result. And in terms of the parameters, it's just all the parameters
00:13:46.240 | of the child modules. So we can run this. And we can again simplify this substantially. Because
00:13:52.480 | we don't maintain this naked list of layers. We now have a notion of a model, which is a module.
00:13:57.920 | And in particular, is a sequential of all these layers. And now, parameters are simply
00:14:06.880 | just model.parameters. And so that list comprehension now lives here. And then here
00:14:14.320 | we are doing all the things we used to do. Now here, the code again simplifies substantially.
00:14:20.880 | Because we don't have to do this forwarding here. Instead, we just call the model on the
00:14:25.200 | input data. And the input data here are the integers inside xb. So we can simply do logits,
00:14:31.040 | which are the outputs of our model, are simply the model called on xb. And then the cross entropy
00:14:38.080 | here takes the logits and the targets. So this simplifies substantially. And then this looks
00:14:45.280 | good. So let's just make sure this runs. That looks good. Now here, we actually have some work
00:14:50.960 | to do still here, but I'm going to come back later. For now, there's no more layers. There's
00:14:55.040 | a model that layers, but it's not easy to access attributes of these classes directly. So we'll
00:15:00.880 | come back and fix this later. And then here, of course, this simplifies substantially as well,
00:15:05.680 | because logits are the model called on x. And then these logits come here.
00:15:11.840 | So we can evaluate the train and validation loss, which currently is terrible because we just
00:15:18.400 | initialized the neural net. And then we can also sample from the model. And this simplifies
00:15:22.480 | dramatically as well, because we just want to call the model onto the context and outcome logits.
00:15:29.280 | And then these logits go into Softmax and get the probabilities, etc.
00:15:34.240 | So we can sample from this model. What did I screw up?
00:15:38.880 | Okay, so I fixed the issue and we now get the result that we expect,
00:15:45.520 | which is gibberish because the model is not trained because we reinitialize it from scratch.
00:15:50.560 | The problem was that when I fixed this cell to be modeled out layers instead of just layers,
00:15:54.960 | I did not actually run the cell. And so our neural net was in a training mode.
00:15:59.360 | And what caused the issue here is the batch norm layer, as batch norm layer often likes to do,
00:16:04.160 | because batch norm was in the training mode. And here we are passing in an input,
00:16:08.880 | which is a batch of just a single example made up of the context.
00:16:12.080 | And so if you are trying to pass in a single example into a batch norm that is in the training
00:16:16.800 | mode, you're going to end up estimating the variance using the input. And the variance of
00:16:21.280 | a single number is not a number, because it is a measure of a spread. So for example,
00:16:26.560 | the variance of just a single number five, you can see is not a number. And so that's what happened.
00:16:31.760 | And batch norm basically caused an issue. And then that polluted all of the further processing.
00:16:37.040 | So all that we had to do was make sure that this runs. And we basically made the issue of,
00:16:45.120 | again, we didn't actually see the issue with the loss. We could have evaluated the loss,
00:16:48.560 | but we got the wrong result because batch norm was in the training mode.
00:16:51.360 | And so we still get a result, it's just the wrong result, because it's using the
00:16:56.080 | sample statistics of the batch. Whereas we want to use the running mean and running variance inside
00:17:01.600 | the batch norm. And so again, an example of introducing a bug inline, because we did not
00:17:08.800 | properly maintain the state of what is training or not. Okay, so I re-run everything. And here's
00:17:13.600 | where we are. As a reminder, we have the training loss of 2.05 and validation 2.10.
00:17:18.000 | Now, because these losses are very similar to each other, we have a sense that we are not
00:17:22.960 | overfitting too much on this task. And we can make additional progress in our performance by scaling
00:17:28.160 | up the size of the neural network and making everything bigger and deeper. Now, currently,
00:17:33.200 | we are using this architecture here, where we are taking in some number of characters,
00:17:36.800 | going into a single hidden layer, and then going to the prediction of the next character.
00:17:41.200 | The problem here is, we don't have a naive way of making this bigger in a productive way. We could,
00:17:47.360 | of course, use our layers, sort of building blocks and materials to introduce additional layers here
00:17:53.360 | and make the network deeper. But it is still the case that we are crushing all of the characters
00:17:57.440 | into a single layer all the way at the beginning. And even if we make this a bigger layer and add
00:18:02.960 | neurons, it's still kind of like silly to squash all that information so fast in a single step.
00:18:09.760 | So we'd like to do instead is we'd like our network to look a lot more like this in the
00:18:13.520 | WaveNet case. So you see in the WaveNet, when we are trying to make the prediction for the next
00:18:17.840 | character in the sequence, it is a function of the previous characters that feed in. But not
00:18:24.400 | all of these different characters are not just crushed to a single layer, and then you have a
00:18:28.640 | sandwich. They are crushed slowly. So in particular, we take two characters and we fuse
00:18:34.640 | them into sort of like a bigram representation. And we do that for all these characters consecutively.
00:18:40.160 | And then we take the bigrams and we fuse those into four character level chunks. And then we
00:18:47.120 | fuse that again. And so we do that in this like tree-like hierarchical manner. So we fuse the
00:18:52.720 | information from the previous context slowly into the network as it gets deeper. And so this is the
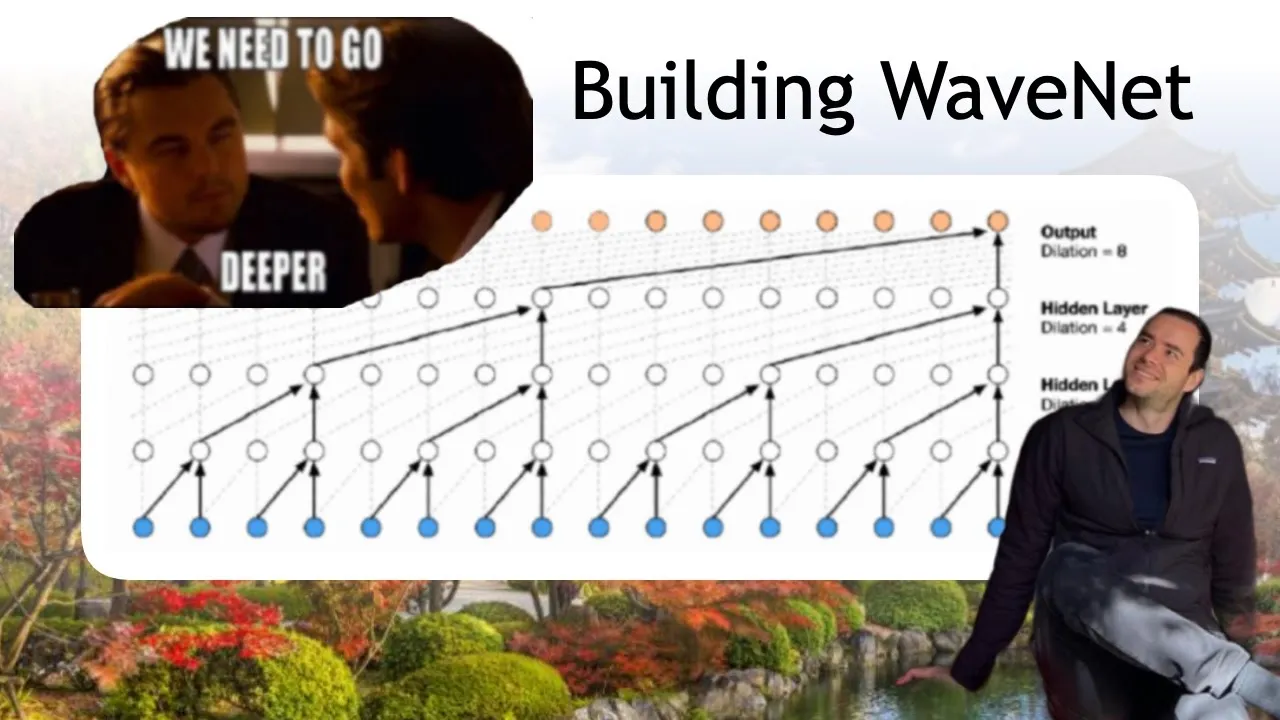
00:18:58.560 | kind of architecture that we want to implement. Now, in the WaveNet's case, this is a visualization
00:19:03.200 | of a stack of dilated causal convolution layers. And this makes it sound very scary, but actually
00:19:08.480 | the idea is very simple. And the fact that it's a dilated causal convolution layer is really just
00:19:13.360 | an implementation detail to make everything fast. We're going to see that later. But for now,
00:19:17.680 | let's just keep the basic idea of it, which is this progressive fusion. So we want to make the
00:19:22.240 | network deeper. And at each level, we want to fuse only two consecutive elements, two characters,
00:19:28.000 | then two bigrams, then two fourgrams, and so on. So let's implement this.
00:19:32.720 | Okay, so first up, let me scroll to where we built the dataset. And let's change the block size from
00:19:36.720 | three to eight. So we're going to be taking eight characters of context to predict the ninth
00:19:42.240 | character. So the dataset now looks like this. We have a lot more context feeding in to predict any
00:19:47.440 | next character in a sequence. And these eight characters are going to be processed in this
00:19:51.440 | tree-like structure. Now, if we scroll here, everything here should just be able to work.
00:19:57.440 | So we should be able to redefine the network. You see that the number of parameters has increased
00:20:01.440 | by 10,000. And that's because the block size has grown. So this first linear layer is much,
00:20:06.800 | much bigger. Our linear layer now takes eight characters into this middle layer. So there's a
00:20:12.800 | lot more parameters there. But this should just run. Let me just break right after the very first
00:20:18.720 | iteration. So you see that this runs just fine. It's just that this network doesn't make too much
00:20:23.120 | sense. We're crushing way too much information way too fast. So let's now come in and see how we
00:20:28.640 | could try to implement the hierarchical scheme. Now, before we dive into the detail of the
00:20:33.520 | reimplementation here, I was just curious to actually run it and see where we are in terms
00:20:38.080 | of the baseline performance of just lazily scaling up the context length. So I let it run. We get a
00:20:43.600 | nice loss curve. And then evaluating the loss, we actually see quite a bit of improvement just from
00:20:48.720 | increasing the context length. So I started a little bit of a performance log here. And
00:20:53.200 | previously where we were is we were getting a performance of 2.10 on the validation loss.
00:20:58.880 | And now simply scaling up the context length from three to eight gives us a performance of 2.02.
00:21:04.160 | So quite a bit of an improvement here. And also, when you sample from the model,
00:21:08.400 | you see that the names are definitely improving qualitatively as well. So we could, of course,
00:21:13.840 | spend a lot of time here tuning things and making it even bigger and scaling up the network further,
00:21:19.840 | even with a simple set up here. But let's continue. And let's implement the hierarchical model
00:21:26.400 | and treat this as just a rough baseline performance. But there's a lot of optimization
00:21:31.680 | left on the table in terms of some of the hyperparameters that you're hopefully getting
00:21:35.200 | a sense of now. OK, so let's scroll up now and come back up. And what I've done here is I've
00:21:41.040 | created a bit of a scratch space for us to just look at the forward pass of the neural net and
00:21:46.560 | inspect the shape of the tensors along the way as the neural net forwards. So here I'm just
00:21:53.040 | temporarily for debugging, creating a batch of just, say, four examples, so four random integers.
00:21:59.040 | Then I'm plucking out those rows from our training set. And then I'm passing into the model the
00:22:04.560 | input xb. Now, the shape of xb here, because we have only four examples, is four by eight. And
00:22:10.880 | this eight is now the current block size. So inspecting xb, we just see that we have four
00:22:17.920 | examples. Each one of them is a row of xb. And we have eight characters here. And this integer
00:22:25.040 | tensor just contains the identities of those characters. So the first layer of our neural net
00:22:30.880 | is the embedding layer. So passing xb, this integer tensor, through the embedding layer
00:22:36.080 | creates an output that is four by eight by 10. So our embedding table has, for each character,
00:22:43.120 | a 10-dimensional vector that we are trying to learn. And so what the embedding layer does here
00:22:48.320 | is it plucks out the embedding vector for each one of these integers and organizes it all in a four
00:22:55.360 | by eight by 10 tensor now. So all of these integers are translated into 10-dimensional vectors inside
00:23:02.000 | this three-dimensional tensor now. Now, passing that through the flattened layer, as you recall,
00:23:07.360 | what this does is it views this tensor as just a four by 80 tensor. And what that effectively does
00:23:14.080 | is that all these 10-dimensional embeddings for all these eight characters just end up being
00:23:18.640 | stretched out into a long row. And that looks kind of like a concatenation operation, basically.
00:23:24.560 | So by viewing the tensor differently, we now have a four by 80. And inside this 80,
00:23:29.920 | it's all the 10-dimensional vectors just concatenated next to each other. And the
00:23:36.400 | linear layer, of course, takes 80 and creates 200 channels just via matrix multiplication.
00:23:42.160 | So, so far, so good. Now I'd like to show you something surprising.
00:23:46.000 | Let's look at the insides of the linear layer and remind ourselves how it works.
00:23:52.480 | The linear layer here in a forward pass takes the input x, multiplies it with a weight,
00:23:57.440 | and then optionally adds a bias. And the weight here is two-dimensional, as defined here,
00:24:01.680 | and the bias is one-dimensional here. So effectively, in terms of the shapes involved,
00:24:07.040 | what's happening inside this linear layer looks like this right now. And I'm using random numbers
00:24:12.000 | here, but I'm just illustrating the shapes and what happens. Basically, a four by 80 input comes
00:24:18.480 | into the linear layer, gets multiplied by this 80 by 200 weight matrix inside, and there's a
00:24:23.200 | plus 200 bias. And the shape of the whole thing that comes out of the linear layer is four by 200,
00:24:28.560 | as we see here. Now, notice here, by the way, that this here will create a four by 200 tensor,
00:24:35.840 | and then plus 200, there's a broadcasting happening here. But four by 200 broadcasts with 200,
00:24:41.600 | so everything works here. So now the surprising thing that I'd like to show you that you may not
00:24:47.120 | expect is that this input here that is being multiplied doesn't actually have to be two-
00:24:52.080 | dimensional. This matrix multiply operator in PyTorch is quite powerful, and in fact,
00:24:57.280 | you can actually pass in higher-dimensional arrays or tensors, and everything works fine.
00:25:01.680 | So for example, this could be four by five by 80, and the result in that case will become
00:25:05.840 | four by five by 200. You can add as many dimensions as you like on the left here.
00:25:10.480 | And so effectively, what's happening is that the matrix multiplication only works on the last
00:25:16.240 | dimension, and the dimensions before it in the input tensor are left unchanged.
00:25:20.800 | So basically, these dimensions on the left are all treated as just a batch dimension.
00:25:30.240 | So we can have multiple batch dimensions, and then in parallel over all those dimensions,
00:25:36.320 | we are doing the matrix multiplication on the last dimension. So this is quite convenient,
00:25:40.800 | because we can use that in our network now. Because remember that we have these eight
00:25:46.160 | characters coming in, and we don't want to now flatten all of it out into a large
00:25:52.800 | eight-dimensional vector, because we don't want to matrix multiply 80 into a weight matrix
00:26:00.560 | multiply immediately. Instead, we want to group these like this. So every consecutive two elements,
00:26:09.680 | one, two, and three, and four, and five, and six, and seven, and eight, all of these should be now
00:26:13.040 | basically flattened out and multiplied by a weight matrix. But all of these four groups here,
00:26:20.320 | we'd like to process in parallel. So it's kind of like a batch dimension that we can introduce.
00:26:25.120 | And then we can in parallel basically process all of these bigram groups in the four batch
00:26:33.760 | dimensions of an individual example, and also over the actual batch dimension of the,
00:26:38.880 | you know, four examples in our example here. So let's see how that works. Effectively,
00:26:43.680 | what we want is right now, we take a 4 by 80, and multiply it by 80 by 200
00:26:49.360 | in the linear layer. This is what happens. But instead, what we want is, we don't want 80
00:26:56.480 | characters or 80 numbers to come in. We only want two characters to come in on the very first layer,
00:27:01.920 | and those two characters should be fused. So in other words, we just want 20 to come in,
00:27:08.000 | right? 20 numbers would come in. And here, we don't want a 4 by 80 to feed into the linear layer.
00:27:14.320 | We actually want these groups of two to feed in. So instead of 4 by 80, we want this to be a 4
00:27:20.000 | by 4 by 20. So these are the four groups of two, and each one of them is 10-dimensional vector.
00:27:28.720 | So what we want is now, is we need to change the flattened layer. So it doesn't output a 4 by 80,
00:27:34.400 | but it outputs a 4 by 4 by 20, where basically, every two consecutive characters are packed in
00:27:44.320 | on the very last dimension. And then these four is the first batch dimension, and this four is the
00:27:50.000 | second batch dimension, referring to the four groups inside every one of these examples.
00:27:54.400 | And then this will just multiply like this. So this is what we want to get to.
00:27:59.280 | So we're going to have to change the linear layer in terms of how many inputs it expects.
00:28:03.280 | It shouldn't expect 80, it should just expect 20 numbers. And we have to change our flattened layer
00:28:08.960 | so it doesn't just fully flatten out this entire example. It needs to create a 4 by 4 by 20 instead
00:28:15.680 | of a 4 by 80. So let's see how this could be implemented. Basically, right now, we have an
00:28:20.800 | input that is a 4 by 8 by 10 that feeds into the flattened layer. And currently, the flattened
00:28:26.480 | layer just stretches it out. So if you remember the implementation of flatten, it takes our x,
00:28:32.800 | and it just views it as whatever the batch dimension is, and then negative 1. So effectively,
00:28:37.840 | what it does right now is it does E.view of 4, negative 1, and the shape of this, of course,
00:28:43.280 | is 4 by 80. So that's what currently happens. And we instead want this to be a 4 by 4 by 20,
00:28:50.560 | where these consecutive 10-dimensional vectors get concatenated.
00:28:53.280 | So you know how in Python, you can take a list of range of 10. So we have numbers from 0 to 9.
00:29:02.880 | And we can index like this to get all the even parts. And we can also index like starting at 1,
00:29:09.040 | and going in steps of 2 to get all the odd parts. So one way to implement this would be as follows.
00:29:16.400 | We can take E, and we can index into it for all the batch elements, and then just even elements
00:29:23.680 | in this dimension. So at indexes 0, 2, 4, and 8. And then all the parts here from this last dimension.
00:29:33.120 | And this gives us the even characters. And then here, this gives us all the odd characters.
00:29:41.440 | And basically, what we want to do is we want to make sure that these get concatenated
00:29:45.280 | in PyTorch. And then we want to concatenate these two tensors along the second dimension.
00:29:51.040 | So this and the shape of it would be 4 by 4 by 20. This is definitely the result we want.
00:29:58.160 | We are explicitly grabbing the even parts and the odd parts. And we're arranging those 4 by 4 by 10
00:30:05.600 | right next to each other and concatenate. So this works. But it turns out that what also works
00:30:11.440 | is you can simply use view again and just request the right shape. And it just so happens that in
00:30:17.440 | this case, those vectors will again end up being arranged exactly the way we want.
00:30:22.560 | So in particular, if we take E, and we just view it as a 4 by 4 by 20, which is what we want,
00:30:28.720 | we can check that this is exactly equal to, let me call this, this is the explicit
00:30:33.760 | concatenation, I suppose. So explicit dot shape is 4 by 4 by 20. If you just view it as 4 by 4 by 20,
00:30:42.080 | you can check that when you compare to explicit, you get a bit, this is element-wise operation.
00:30:48.640 | So making sure that all of them are true, the values to true. So basically, long story short,
00:30:54.160 | we don't need to make an explicit call to concatenate, etc. We can simply take this
00:30:59.200 | input tensor to flatten, and we can just view it in whatever way we want. And in particular,
00:31:06.400 | we don't want to stretch things out with negative one, we want to actually create a three-dimensional
00:31:10.720 | array. And depending on how many vectors that are consecutive, we want to fuse, like for example,
00:31:18.480 | two, then we can just simply ask for this dimension to be 20. And using negative one here,
00:31:25.440 | and PyTorch will figure out how many groups it needs to pack into this additional batch dimension.
00:31:29.840 | So let's now go into flatten and implement this. Okay, so I scrolled up here to flatten.
00:31:35.360 | And what we'd like to do is we'd like to change it now. So let me create a constructor and take
00:31:39.840 | the number of elements that are consecutive that we would like to concatenate now in the last
00:31:44.480 | dimension of the output. So here, we're just going to remember, cell.n equals n. And then I want to
00:31:51.360 | be careful here, because PyTorch actually has a Torch.flatten, and its keyword arguments are
00:31:56.560 | different, and they kind of like function differently. So our flatten is going to start
00:32:00.640 | to depart from PyTorch.flatten. So let me call it flatten consecutive, or something like that,
00:32:06.080 | just to make sure that our APIs are about equal. So this basically flattens only some n
00:32:13.920 | consecutive elements and puts them into the last dimension. Now here, the shape of x is b by t by c.
00:32:21.360 | So let me pop those out into variables and recall that in our example down below, b was 4, t was 8,
00:32:29.440 | and c was 10. Now, instead of doing x.view of b by negative one, right, this is what we had before.
00:32:40.960 | We want this to be b by negative one by, and basically here, we want c times n. That's how
00:32:49.520 | many consecutive elements we want. And here, instead of negative one, I don't super love the
00:32:55.920 | use of negative one, because I like to be very explicit so that you get error messages when
00:32:59.840 | things don't go according to your expectation. So what do we expect here? We expect this to become
00:33:04.480 | t divide n, using integer division here. So that's what I expect to happen. And then one more thing
00:33:11.440 | I want to do here is, remember previously, all the way in the beginning, n was 3, and basically
00:33:18.240 | we're concatenating all the three characters that existed there. So we basically concatenated
00:33:25.120 | everything. And so sometimes that can create a spurious dimension of one here. So if it is the
00:33:30.880 | case that x.shape at one is one, then it's kind of like a spurious dimension. So we don't want to
00:33:38.240 | return a three-dimensional tensor with a one here. We just want to return a two-dimensional tensor
00:33:43.520 | exactly as we did before. So in this case, basically, we will just say x equals x.squeeze,
00:33:49.600 | that is a PyTorch function. And squeeze takes a dimension that it identifies as a three-dimensional
00:33:59.280 | dimension, that it either squeezes out all the dimensions of a tensor that are one, or you can
00:34:05.520 | specify the exact dimension that you want to be squeezed. And again, I like to be as explicit as
00:34:11.520 | possible always. So I expect to squeeze out the first dimension only of this tensor, this
00:34:18.240 | three-dimensional tensor. And if this dimension here is one, then I just want to return b by
00:34:22.960 | n. And so self.out will be x, and then we return self.out. So that's the candidate implementation.
00:34:31.040 | And of course, this should be self.in instead of just n. So let's run. And let's come here now
00:34:38.000 | and take it for a spin. So flatten consecutive. And in the beginning, let's just use eight.
00:34:47.680 | So this should recover the previous behavior. So flatten consecutive of eight, which is the
00:34:52.960 | current block size. We can do this. That should recover the previous behavior. So we should be
00:35:00.400 | able to run the model. And here we can inspect. I have a little code snippet here where I iterate
00:35:07.680 | over all the layers. I print the name of this class and the shape. And so we see the shapes
00:35:16.960 | as we expect them after every single layer in its output. So now let's try to restructure it
00:35:22.720 | using our flatten consecutive and do it hierarchically. So in particular,
00:35:27.440 | we want to flatten consecutive not block size, but just two. And then we want to process this
00:35:34.400 | with linear. Now the number of inputs to this linear will not be n embed times block size.
00:35:39.600 | It will now only be n embed times two, 20. This goes through the first layer. And now we can,
00:35:47.040 | in principle, just copy paste this. Now the next linear layer should expect n hidden times two.
00:35:52.800 | And the last piece of it should expect n hidden times two again.
00:35:59.680 | So this is sort of like the naive version of it. So running this, we now have a much,
00:36:07.280 | much bigger model. And we should be able to basically just forward the model.
00:36:11.760 | And now we can inspect the numbers in between. So 4 by 8 by 20 was flattened consecutively into 4
00:36:21.040 | by 4 by 20. This was projected into 4 by 4 by 200. And then Bashorm just worked out of the box. And
00:36:30.160 | we have to verify that Bashorm does the correct thing, even though it takes a three-dimensional
00:36:33.600 | embed instead of two-dimensional embed. Then we have 10h, which is element-wise. Then we crushed
00:36:39.600 | it again. So we flattened consecutively and ended up with a 4 by 2 by 400 now. Then linear brought
00:36:46.000 | it back down to 200, Bashorm 10h. And lastly, we get a 4 by 400. And we see that the flattened
00:36:52.000 | consecutive for the last flattened here, it squeezed out that dimension of one. So we only
00:36:57.520 | ended up with 4 by 400. And then linear Bashorm 10h and the last linear layer to get our logits.
00:37:04.880 | And so the logits end up in the same shape as they were before. But now we actually have a nice
00:37:09.600 | three-layer neural net. And it basically corresponds to-- whoops, sorry. It basically
00:37:14.880 | corresponds exactly to this network now, except only this piece here, because we only have three
00:37:20.080 | layers. Whereas here in this example, there's four layers with a total receptive field size of
00:37:27.440 | 16 characters instead of just eight characters. So the block size here is 16. So this piece of it
00:37:33.920 | is basically implemented here. Now we just have to figure out some good channel numbers to use here.
00:37:41.200 | Now in particular, I changed the number of hidden units to be 68 in this architecture,
00:37:46.240 | because when I use 68, the number of parameters comes out to be 22,000. So that's exactly the
00:37:51.280 | same that we had before. And we have the same amount of capacity at this neural net in terms
00:37:55.760 | of the number of parameters. But the question is whether we are utilizing those parameters in a
00:37:59.600 | more efficient architecture. So what I did then is I got rid of a lot of the debugging cells here,
00:38:05.440 | and I reran the optimization. And scrolling down to the result, we see that we get the identical
00:38:11.360 | performance roughly. So our validation loss now is 2.029, and previously it was 2.027.
00:38:17.600 | So controlling for the number of parameters, changing from the flat to hierarchical is not
00:38:21.200 | giving us anything yet. That said, there are two things to point out. Number one, we didn't really
00:38:27.600 | torture the architecture here very much. This is just my first guess. And there's a bunch of
00:38:32.240 | hyperparameter search that we could do in terms of how we allocate our budget of parameters to
00:38:38.000 | what layers. Number two, we still may have a bug inside the BashNorm1D layer. So let's take a look
00:38:44.480 | at that, because it runs, but does it do the right thing? So I pulled up the layer inspector that we
00:38:53.840 | have here and printed out the shapes along the way. And currently it looks like the BashNorm is
00:38:58.240 | receiving an input that is 32 by 4 by 68. And here on the right, I have the current implementation of
00:39:04.880 | BashNorm that we have right now. Now, this BashNorm assumed, in the way we wrote it and at the time,
00:39:10.400 | that x is two-dimensional. So it was n by d, where n was the batch size. So that's why we only reduced
00:39:17.920 | the mean and the variance over the zeroth dimension. But now x will basically become
00:39:22.000 | three-dimensional. So what's happening inside the BashNorm layer right now, and how come it's
00:39:25.680 | working at all and not giving any errors? The reason for that is basically because everything
00:39:30.000 | broadcasts properly, but the BashNorm is not doing what we want it to do. So in particular,
00:39:36.400 | let's basically think through what's happening inside the BashNorm, looking at what's happening
00:39:41.760 | here. I have the code here. So we're receiving an input of 32 by 4 by 68. And then we are doing
00:39:50.480 | here, x dot mean, here I have e instead of x, but we're doing the mean over zero. And that's
00:39:57.360 | actually given us 1 by 4 by 68. So we're doing the mean only over the very first dimension.
00:40:02.480 | And it's given us a mean and a variance that still maintain this dimension here. So these
00:40:08.240 | means are only taking over 32 numbers in the first dimension. And then when we perform this,
00:40:13.200 | everything broadcasts correctly still. But basically what ends up happening is
00:40:18.480 | when we also look at the running mean,
00:40:22.160 | the shape of it. So I'm looking at the model dot layers at three, which is the first BashNorm
00:40:29.280 | layer, and then looking at whatever the running mean became and its shape. The shape of this
00:40:34.720 | running mean now is 1 by 4 by 68. Instead of it being just a size of dimension, because we have
00:40:43.520 | 68 channels, we expect to have 68 means and variances that we're maintaining. But actually,
00:40:48.800 | we have an array of 4 by 68. And so basically what this is telling us is this BashNorm is currently
00:40:56.320 | working in parallel over 4 times 68 instead of just 68 channels. So basically, we are maintaining
00:41:08.400 | statistics for every one of these four positions individually and independently. And instead,
00:41:14.160 | what we want to do is we want to treat this 4 as a Bash dimension, just like the 0th dimension.
00:41:19.200 | So as far as the BashNorm is concerned, we don't want to average over 32 numbers,
00:41:26.240 | we want to now average over 32 times 4 numbers for every single one of these 68 channels.
00:41:31.760 | So let me now remove this. It turns out that when you look at the documentation of torch.mean,
00:41:40.000 | in one of its signatures, when we specify the dimension,
00:41:53.120 | we see that the dimension here is not just, it can be int or it can also be a tuple of ints.
00:41:57.520 | So we can reduce over multiple integers at the same time, over multiple dimensions at the same
00:42:03.040 | time. So instead of just reducing over 0, we can pass in a tuple, 0, 1, and here 0, 1 as well.
00:42:09.760 | And then what's going to happen is the output, of course, is going to be the same.
00:42:13.040 | But now what's going to happen is because we reduce over 0 and 1, if we look at in mean.shape,
00:42:20.080 | we see that now we've reduced, we took the mean over both the 0th and the 1st dimension.
00:42:25.760 | So we're just getting 68 numbers and a bunch of spurious dimensions here.
00:42:29.840 | So now this becomes 1 by 1 by 68, and the running mean and the running variance,
00:42:35.920 | analogously, will become 1 by 1 by 68. So even though there are the spurious dimensions,
00:42:40.320 | the correct thing will happen in that we are only maintaining means and variances for 68 channels.
00:42:49.520 | And we're now calculating the mean and variance across 32 times 4 dimensions.
00:42:54.080 | So that's exactly what we want. And let's change the implementation of BatchNorm1D that we have
00:42:59.680 | so that it can take in two-dimensional or three-dimensional inputs and perform accordingly.
00:43:05.120 | So at the end of the day, the fix is relatively straightforward. Basically, the dimension we
00:43:09.040 | want to reduce over is either 0 or the tuple 0 and 1, depending on the dimensionality of x.
00:43:15.280 | So if x.ndim is 2, so it's a two-dimensional tensor, then the dimension we want to reduce over
00:43:20.480 | is just the integer 0. If x.ndim is 3, so it's a three-dimensional tensor, then the dims we're
00:43:26.960 | going to assume are 0 and 1 that we want to reduce over. And then here, we just pass in dim.
00:43:32.880 | And if the dimensionality of x is anything else, we'll now get an error, which is good.
00:43:36.640 | So that should be the fix. Now I want to point out one more thing. We're actually departing
00:43:43.200 | from the API of PyTorch here a little bit. Because when you come to BatchNorm1D in PyTorch,
00:43:47.920 | you can scroll down and you can see that the input to this layer can either be n by c,
00:43:53.600 | where n is the batch size and c is the number of features or channels, or it actually does
00:43:57.920 | accept three-dimensional inputs, but it expects it to be n by c by l, where l is, say, the sequence
00:44:04.000 | length or something like that. So this is a problem because you see how c is nested here
00:44:10.160 | in the middle. And so when it gets three-dimensional inputs, this BatchNorm layer will reduce over 0
00:44:16.480 | and 2 instead of 0 and 1. So basically, PyTorch BatchNorm1D layer assumes that c will always be
00:44:24.160 | the first dimension, whereas we assume here that c is the last dimension and there are some number
00:44:31.120 | of batch dimensions beforehand. And so it expects n by c or n by c by l. We expect n by c or n by l
00:44:41.360 | by c. And so it's a deviation. I think it's okay. I prefer it this way, honestly, so this is the way
00:44:49.920 | that we will keep it for our purposes. So I redefined the layers, reinitialized the neural
00:44:54.160 | nut, and did a single forward pass with a break just for one step. Looking at the shapes along
00:44:59.520 | the way, they're of course identical. All the shapes are the same. But the way we see that
00:45:03.520 | things are actually working as we want them to now is that when we look at the BatchNorm layer,
00:45:07.760 | the running mean shape is now 1 by 1 by 68. So we're only maintaining 68 means for every one
00:45:13.440 | of our channels, and we're treating both the 0th and the first dimension as a batch dimension,
00:45:18.640 | which is exactly what we want. So let me retrain the neural net now. Okay, so I've retrained the
00:45:22.240 | neural net with the bug fix. We get a nice curve. And when we look at the validation performance,
00:45:26.240 | we do actually see a slight improvement. So it went from 2.029 to 2.022. So basically,
00:45:31.920 | the bug inside the BatchNorm was holding us back a little bit, it looks like. And we are getting a
00:45:37.680 | tiny improvement now, but it's not clear if this is statistically significant. And the reason we
00:45:43.360 | slightly expect an improvement is because we're not maintaining so many different means and
00:45:47.200 | variances that are only estimated using 32 numbers, effectively. Now we are estimating them using 32
00:45:53.440 | times 4 numbers. So you just have a lot more numbers that go into any one estimate of the
00:45:58.000 | mean and variance. And it allows things to be a bit more stable and less wiggly inside those
00:46:03.360 | estimates of those statistics. So pretty nice. With this more general architecture in place,
00:46:09.280 | we are now set up to push the performance further by increasing the size of the network.
00:46:13.920 | So for example, I've bumped up the number of embeddings to 24 instead of 10, and also increased
00:46:19.280 | the number of hidden units. But using the exact same architecture, we now have 76,000 parameters.
00:46:24.960 | And the training takes a lot longer, but we do get a nice curve. And then when you actually
00:46:29.600 | evaluate the performance, we are now getting validation performance of 1.993. So we've crossed
00:46:34.640 | over the 2.0 sort of territory, and we're at about 1.99. But we are starting to have to
00:46:40.400 | wait quite a bit longer. And we're a little bit in the dark with respect to the correct setting of
00:46:45.920 | the hyperparameters here and the learning rates and so on, because the experiments are starting
00:46:49.200 | to take longer to train. And so we are missing sort of like an experimental harness on which we
00:46:54.400 | could run a number of experiments and really tune this architecture very well. So I'd like to
00:46:58.720 | conclude now with a few notes. We basically improved our performance from a starting of 2.1
00:47:04.160 | down to 1.9. But I don't want that to be the focus, because honestly, we're kind of in the dark,
00:47:08.800 | we have no experimental harness, we're just guessing and checking. And this whole thing is
00:47:12.960 | terrible. We're just looking at the training loss. Normally, you want to look at both the
00:47:16.640 | training and the validation loss together. The whole thing looks different if you're actually
00:47:20.960 | trying to squeeze out numbers. That said, we did implement this architecture from the WaveNet paper.
00:47:27.120 | But we did not implement this specific forward pass of it, where you have a more complicated
00:47:33.760 | linear layer sort of that is this gated linear layer kind of. And there's residual connections
00:47:40.000 | and skip connections and so on. So we did not implement that, we just implemented this structure.
00:47:44.960 | I would like to briefly hint or preview how what we've done here relates to convolutional neural
00:47:49.600 | networks as used in the WaveNet paper. And basically, the use of convolutions is strictly
00:47:54.480 | for efficiency. It doesn't actually change the model we've implemented. So here, for example,
00:48:00.000 | let me look at a specific name to work with an example. So there's a name in our training set,
00:48:05.600 | and it's D'Andrea. And it has seven letters, so that is eight independent examples in our model.
00:48:12.000 | So all these rows here are independent examples of D'Andrea. Now, you can forward, of course,
00:48:17.920 | any one of these rows independently. So I can take my model and call it on any individual index.
00:48:25.520 | Notice, by the way, here, I'm being a little bit tricky. The reason for this is that extra at 7.shape
00:48:31.120 | is just one dimensional array of eight. So you can't actually call the model on it,
00:48:37.840 | you're going to get an error, because there's no batch dimension. So when you do extra at
00:48:44.000 | list of seven, then the shape of this becomes one by eight. So I get an extra batch dimension of
00:48:50.800 | one, and then we can forward the model. So that forwards a single example. And you might imagine
00:48:57.920 | that you actually may want to forward all of these eight at the same time. So pre-allocating
00:49:04.640 | some memory and then doing a for loop eight times and forwarding all of those eight here will give
00:49:10.240 | us all the logits in all these different cases. Now, for us with the model as we've implemented
00:49:15.040 | it right now, this is eight independent calls to our model. But what convolutions allow you to do
00:49:20.400 | is it allow you to basically slide this model efficiently over the input sequence. And so
00:49:26.400 | this for loop can be done not outside in Python, but inside of kernels in CUDA. And so this for
00:49:33.200 | loop gets hidden into the convolution. So the convolution basically, you can think of it as
00:49:37.840 | it's a for loop, applying a little linear filter over space of some input sequence. And in our
00:49:44.480 | case, the space we're interested in is one dimensional, and we're interested in sliding
00:49:47.760 | these filters over the input data. So this diagram actually is fairly good as well. Basically,
00:49:55.760 | what we've done is here they are highlighting in black one single sort of like tree of this
00:50:01.200 | calculation. So just calculating the single output example here. And so this is basically
00:50:08.160 | what we've implemented here. We've implemented a single, this black structure, we've implemented
00:50:13.680 | that and calculated a single output, like a single example. But what convolutions allow you to do is
00:50:18.960 | it allows you to take this black structure and kind of like slide it over the input sequence
00:50:24.640 | here and calculate all of these orange outputs at the same time. Or here that corresponds to
00:50:31.520 | calculating all of these outputs of at all the positions of DeAndre at the same time.
00:50:37.440 | And the reason that this is much more efficient is because number one, as I mentioned, the for loop
00:50:43.920 | is inside the CUDA kernels in the sliding. So that makes it efficient. But number two,
00:50:49.840 | notice the variable reuse here. For example, if we look at this circle, this node here,
00:50:54.400 | this node here is the right child of this node, but it's also the left child of the node here.
00:51:00.240 | And so basically, this node and its value is used twice. And so right now, in this naive way,
00:51:08.000 | we'd have to recalculate it. But here we are allowed to reuse it. So in the convolutional
00:51:13.360 | neural network, you think of these linear layers that we have up above as filters. And we take
00:51:19.040 | these filters, and they're linear filters, and you slide them over input sequence. And we calculate
00:51:24.000 | the first layer, and then the second layer, and then the third layer, and then the output layer
00:51:28.160 | of the sandwich. And it's all done very efficiently using these convolutions. So we're going to cover
00:51:33.280 | that in a future video. The second thing I hope you took away from this video is you've seen me
00:51:37.520 | basically implement all of these layer Lego building blocks or module building blocks.
00:51:43.680 | And I'm implementing them over here. And we've implemented a number of layers together.
00:51:47.600 | And we've also implementing these these containers. And we've overall pytorchified our code quite a
00:51:53.680 | bit more. Now, basically, what we're doing here is we're re-implementing torch.nn, which is the
00:51:59.040 | neural networks library on top of torch.tensor. And it looks very much like this, except it is
00:52:05.520 | much better, because it's in pytorch instead of a janky, lazy, and stupid notebook. So I think
00:52:11.520 | going forward, I will probably have considered us having unlocked torch.nn. We understand roughly
00:52:17.600 | what's in there, how these modules work, how they're nested, and what they're doing on top
00:52:21.840 | of torch.tensor. So hopefully, we'll just switch over and continue and start using torch.nn directly.
00:52:28.080 | The next thing I hope you got a bit of a sense of is what the development process of building
00:52:32.880 | deep neural networks looks like, which I think was relatively representative to some extent.
00:52:37.280 | So number one, we are spending a lot of time in the documentation page of pytorch. And we're
00:52:43.200 | reading through all the layers, looking at documentations, what are the shapes of the
00:52:47.040 | inputs, what can they be, what does the layer do, and so on. Unfortunately, I have to say the
00:52:52.800 | pytorch documentation is not very good. They spend a ton of time on hardcore engineering of all kinds
00:52:59.200 | of distributed primitives, etc. But as far as I can tell, no one is maintaining the documentation.
00:53:04.240 | It will lie to you, it will be wrong, it will be incomplete, it will be unclear. So unfortunately,
00:53:11.440 | it is what it is, and you just kind of do your best with what they've given us. Number two,
00:53:19.120 | the other thing that I hope you got a sense of is there's a ton of trying to make the shapes work.
00:53:25.840 | And there's a lot of gymnastics around these multi-dimensional arrays. And are they two
00:53:29.120 | dimensional, three dimensional, four dimensional? What layers take what shapes? Is it NCL or NLC?
00:53:35.520 | And you're permuting and viewing, and it just can get pretty messy. And so that brings me to number
00:53:41.120 | three. I very often prototype these layers and implementations in Jupyter Notebooks and make
00:53:45.760 | sure that all the shapes work out. And I'm spending a lot of time basically babysitting the shapes and
00:53:50.880 | making sure everything is correct. And then once I'm satisfied with the functionality in a Jupyter
00:53:55.120 | Notebook, I will take that code and copy paste it into my repository of actual code that I'm
00:54:00.240 | training with. And so then I'm working with VS code on the side. So I usually have Jupyter Notebook
00:54:05.440 | and VS code. I develop a Jupyter Notebook, I paste into VS code, and then I kick off experiments from
00:54:10.560 | the repo, of course, from the code repository. So that's roughly some notes on the development
00:54:16.320 | process of working with neural nets. Lastly, I think this lecture unlocks a lot of potential
00:54:20.800 | further lectures, because number one, we have to convert our neural network to actually use
00:54:25.040 | these dilated causal convolutional layers. So implementing the ConvNet. Number two,
00:54:30.960 | I'm potentially starting to get into what this means, where are residual connections and skip
00:54:35.360 | connections and why are they useful? Number three, as I mentioned, we don't have any experimental
00:54:41.520 | harness. So right now I'm just guessing, checking everything. This is not representative of typical
00:54:45.840 | deep learning workflows. You have to set up your evaluation harness, you can kick off experiments,
00:54:50.800 | you have lots of arguments that your script can take, you're kicking off a lot of experimentation,
00:54:55.360 | you're looking at a lot of plots of training and validation losses, and you're looking at what is
00:54:59.360 | working and what is not working. And you're working on this like population level, and you're doing
00:55:03.360 | all these hyperparameter searches. And so we've done none of that so far. So how to set that up
00:55:09.520 | and how to make it good, I think is a whole another topic. And number three, we should probably cover
00:55:15.280 | recurring neural networks, RNNs, LSTMs, GRUs, and of course, transformers. So many places to go,
00:55:22.560 | and we'll cover that in the future. For now, bye. Sorry, I forgot to say that if you are interested,
00:55:29.120 | I think it is kind of interesting to try to beat this number 1.993. Because I really haven't
00:55:34.560 | tried a lot of experimentation here, and there's quite a bit of longing fruit potentially
00:55:38.160 | to still push this further. So I haven't tried any other ways of allocating these channels in
00:55:43.200 | this neural net. Maybe the number of dimensions for the embedding is all wrong. Maybe it's possible
00:55:49.200 | to actually take the original network, which is one hidden layer, and make it big enough and
00:55:53.360 | actually beat my fancy hierarchical network. It's not obvious. That would be kind of embarrassing.
00:55:58.880 | If this did not do better, even once you torture it a little bit. Maybe you can read the WaveNet
00:56:03.680 | paper and try to figure out how some of these layers work and implement them yourselves using
00:56:07.280 | what we have. And of course, you can always tune some of the initialization or some of the
00:56:12.480 | optimization and see if you can improve it that way. So I'd be curious if people can come up with
00:56:17.120 | some ways to beat this. And yeah, that's it for now. Bye.