Intro to Machine Learning: Lesson 2
Chapters
0:0 Intro0:45 Fast AI
5:30 Evaluation Metric
10:0 Formulas
23:42 Training vs Validation
27:7 Root Mean Square Error
29:17 Run Time
31:52 Simple Model
32:57 Decision Tree
34:17 Data
39:2 Test all possible splits
43:55 Clarification
45:42 Summary
46:59 Random Forest
50:22 Random Forest Regression
00:00:00.000 | So, from here, the next 2 or 3 lessons, we're going to be really diving deep into random
00:00:06.840 | forests.
00:00:07.840 | So far, all we've learned is there's a thing called random forests.
00:00:13.360 | For some particular datasets, they seem to work really really well without too much trouble.
00:00:19.200 | But we don't really know yet how do they actually work, what do we do if they don't work properly,
00:00:25.520 | what are their pros and cons, what can we tune, and so forth.
00:00:29.080 | So we're going to look at all that, and then after that we're going to look at how do we
00:00:33.160 | interpret the results of random forests to get not just predictions, but to actually
00:00:38.040 | deeply understand our data in a model-driven way.
00:00:41.600 | So that's where we're going to go from here.
00:00:45.160 | So let's just review where we're up to.
00:00:48.880 | So we learned that there's this library called FastAI, and the FastAI library is a highly
00:00:57.600 | opinionated library, which is to say we spend a lot of time researching what are the best
00:01:04.160 | techniques to get state-of-the-art results, and then we take those techniques and package
00:01:09.320 | them into pieces of code so that you can use the state-of-the-art results yourself.
00:01:15.280 | And so where possible, we wrap or provide things on top of existing code.
00:01:24.960 | And so in particular for the kind of structured data analysis we're doing, scikit-learn has
00:01:30.160 | a lot of really great code.
00:01:32.020 | So most of the stuff that we're showing you from FastAI is stuff to help us get stuff
00:01:36.720 | into scikit-learn and then interpret stuff out from scikit-learn.
00:01:43.760 | The FastAI library, the way it works in our environment here is that our notebooks are
00:01:59.440 | inside fastai-repo/courses and then /ml1 and dl1, and then inside there, there's a symlink
00:02:10.020 | to the parent of the parent FastAI.
00:02:14.360 | So this is a symlink to a directory containing a bunch of modules.
00:02:22.480 | So if you want to use the FastAI library in your own code, there's a number of things
00:02:29.040 | you can do.
00:02:30.200 | One is to put your notebooks or scripts in the same directory as ml1 or dl1, where there's
00:02:35.720 | already the symlink, and just import it just like I do.
00:02:39.800 | You could copy this directory into somewhere else and use it, or you could symlink it just
00:02:50.460 | like I have from here to wherever you want to use it.
00:02:54.740 | So notice it's mildly confusing.
00:02:57.240 | There's a github-repo called fastai, and inside the github-repo called fastai, which looks
00:03:03.980 | like this, there is a folder called fastai.
00:03:08.960 | So the fastai folder in the fastai-repo contains the fastai library.
00:03:15.200 | And it's that library when we go from fastai.imports import* then that's looking inside the fastai
00:03:22.800 | folder for a file called imports.py and importing everything from that.
00:03:33.800 | And just as a clarifying question, for the symlink it's just the ln thing that you talked
00:03:51.320 | about last class?
00:03:52.320 | Yeah, so a symlink is something you can create by typing ln-s, and then the path to the source,
00:04:00.280 | which in this case would be dot dot dot dot fastai, could be relative or it could be absolute,
00:04:05.760 | and then the name of the destination.
00:04:07.480 | If you just put the current directory at the destination, it'll use the same name as it
00:04:11.640 | comes from, like an alias on the Mac or a shortcut on Windows.
00:04:19.520 | I don't think I've created the symlink anywhere in the workbooks.
00:04:48.960 | The symlink actually lives inside the GitHub repo.
00:04:53.800 | I created some symlinks in the deep learning notebook to some data, that was different.
00:05:02.800 | At the top of Tim Lee's workbook from the last class, there was import sys then append
00:05:09.440 | the fastai.
00:05:10.440 | Oh yeah, don't do that probably.
00:05:13.480 | You can, but I think this is better.
00:05:17.540 | This way you can go from fastai imports, and regardless of how you got it there, it's going
00:05:24.120 | to work.
00:05:29.480 | So then we had all of our data for bluebooks to bulldozers competition in data/bulldozers,
00:05:36.000 | and here it is.
00:05:40.360 | We were able to read that CSV file, the only thing we really had to do was say which columns
00:05:46.540 | were dates, and having done that, we were able to take a look at a few of the examples
00:05:52.880 | of the rows of the data.
00:05:59.280 | And so we also noted that it's very important to deeply understand the evaluation metric
00:06:09.360 | for this project.
00:06:11.400 | And so for Kaggle, they tell you what the evaluation metric is, and in this case it was
00:06:16.120 | the root mean squared log error.
00:06:21.040 | So that is the sum of the actuals minus the predictions, but it's the log of the actuals
00:06:41.880 | minus the log of the predictions squared.
00:06:50.640 | So if we replace actuals with log actuals and replace log predictions, then it's just
00:06:58.800 | the same as root mean squared error.
00:07:03.380 | So that's what we did, we replaced sale price with log of sale price, and so now if we optimize
00:07:11.120 | for root mean squared error, we're actually optimizing for the root mean squared error
00:07:16.560 | of the logs.
00:07:20.340 | So then we learned that we need all of our columns to be numbers, and so the first way
00:07:26.880 | we did that was to take the date column and remove it, and instead replace it with a whole
00:07:33.800 | bunch of different columns, such as is that date the start of a quarter, is it the end
00:07:45.880 | of a year, how many days are elapsed since January 1st, 1970, what's the year, what's
00:07:52.200 | the month, what's the day of week, and so forth.
00:07:55.320 | So they're all numbers.
00:07:59.180 | Then we learned that we can use train_cats to replace all of the strings with categories.
00:08:07.800 | Now when you do that, it doesn't look like you've done anything different, they still
00:08:12.480 | look like strings.
00:08:15.620 | But if you actually take a deeper look, you'll see that the data type is not string but category.
00:08:27.180 | And category is a pandas class where you can then go dot cat dot and find a whole bunch
00:08:36.000 | of different attributes, such as cat dot categories to find a list of all of the possible categories,
00:08:42.680 | and this says high is going to become 0, low will become 1, medium will become 2, so we
00:08:47.520 | can then get codes to actually get the numbers.
00:08:52.640 | So then what we need to do to actually use this data set to turn it into numbers is take
00:08:58.020 | every categorical column and replace it with cat dot codes, and so we did that using proc
00:09:08.540 | df.
00:09:12.200 | So how do I get the source code for proc df?
00:09:24.100 | If I scroll down, I go through each column and I numericalize it.
00:09:33.980 | That's actually the one I want, so I'm going to now have to look up numericalize.
00:09:41.320 | So tab to complete it.
00:09:45.040 | If it's not numeric, then replace the data frames field with that columns dot cat dot
00:09:51.740 | codes plus 1, because otherwise unknown is -1, we want unknown to be 0.
00:09:58.200 | So that's how we turn the strings into numbers.
00:10:04.360 | They get replaced with a unique basically arbitrary index.
00:10:09.000 | It's actually based on the alphabetical order of the feature names.
00:10:14.120 | The other thing proc df did remember was continuous columns that had missing values.
00:10:21.500 | The missing got replaced with the median, and we added an additional column called column
00:10:26.120 | name_na, which is a Boolean column, told you if that particular item was missing or not.
00:10:34.960 | So once we did that, we were able to call random forest regressor dot fit and get the
00:10:43.620 | dot score, and it turns out we have an R^2 of 0.98.
00:10:50.920 | Can anybody tell me what an R^2 is?
00:10:57.240 | So R^2 essentially shows how much variance is explained by the model.
00:11:20.080 | This is the relation of SSR, which is like trying to remember the exact formula.
00:11:35.360 | I mean roughly intuitively?
00:11:37.800 | Intuitively, it's how much the model explains how much it accounts for the variance in the
00:11:44.800 | data.
00:11:45.800 | Okay, good.
00:11:46.800 | So let's talk about the formula.
00:11:50.720 | With formulas, the idea is not to learn the formula and remember it, but to learn what
00:11:55.400 | the formula does and understand it.
00:11:59.780 | So here's the formula.
00:12:03.360 | It's 1 minus something divided by something else.
00:12:08.340 | So what's the something else on the bottom?
00:12:11.080 | SS_tot.
00:12:13.400 | So what this is saying is we've got some actual data, some y_i's, we've got some actual data
00:12:23.080 | - 3, 2, 4, 1.
00:12:28.440 | And then we've got some average.
00:12:34.940 | So our top bit, this SS_tot, is the sum of h of these minus that.
00:12:48.020 | So in other words, it's telling us how much does this data vary, but perhaps more interestingly
00:12:54.200 | is remember when we talked about last week, what's the simplest non-stupid model you could
00:13:01.140 | come up with?
00:13:02.140 | I think the simplest non-stupid model we came up with was create a column of the mean.
00:13:07.360 | Just copy the mean a bunch of times and submit that to Kaggle.
00:13:11.640 | If you did that, then your root mean squared error would be this.
00:13:18.920 | So this is the root mean squared error of the most naive non-stupid model.
00:13:26.640 | The model is just predict the mean.
00:13:30.620 | On the top, we have SS_res, which is here, which is that we're now going to add a column
00:13:38.280 | of predictions.
00:13:50.200 | And so now what we do is rather than taking the y_i minus y_mean, we're going to take
00:13:56.300 | y_i minus f_i.
00:14:01.680 | And so now instead of saying what's the root mean squared error of our naive model, we're
00:14:06.660 | saying what's the root mean squared error of the actual model that we're interested
00:14:09.640 | in.
00:14:11.240 | And then we take the ratio.
00:14:15.660 | So in other words, if we actually were exactly as effective as just predicting the mean,
00:14:25.840 | then this top and bottom would be the same, that would be 1, 1 minus 1 would be 0.
00:14:33.360 | If we were perfect, so f_i minus y_i was always 0, then that's 0 divided by something, 1 minus
00:14:40.400 | that is 1.
00:14:44.080 | So what is the possible range of values of R^2?
00:14:50.640 | Okay, I heard a lot of 0 to 1.
00:14:55.200 | Does anybody want to give me an alternative?
00:15:06.360 | Anything less than 1, there's the right answer, let's find out why.
00:15:24.160 | So why is any number less than 1?
00:15:26.200 | Because you can make a model as crap as you want, and you're just subtracting from 1 in
00:15:39.040 | the formula.
00:15:40.040 | So interestingly, I was talking to our computer science professor, Terrence, who was talking
00:15:42.220 | to a statistics professor, who told him that the possible range of values of R^2 was 0 to
00:15:47.840 | 1.
00:15:48.840 | That is totally not true.
00:15:50.520 | If you predict every row, then you're going to have infinity for every residual, and so
00:15:58.520 | you're going to have 1 minus infinity.
00:16:01.160 | So the possible range of values is less than 1, that's all we know.
00:16:06.360 | And this will happen, you will get negative values sometimes in your R^2.
00:16:10.640 | And when that happens, it's not a mistake, it's not like a bug, it means your model is
00:16:16.440 | worse than predicting the mean, which suggests it's not great.
00:16:23.000 | So that's R^2.
00:16:29.780 | It's not necessarily what you're actually trying to optimize, but the nice thing about
00:16:37.520 | it is that it's a number that you can use for every model.
00:16:43.040 | And so you can kind of start to get a feel of what does 0.8 look like, what does 0.9
00:16:47.560 | look like.
00:16:48.560 | So something I find interesting is to create some different synthetic data sets, just two
00:16:54.880 | dimensions, with different amounts of random noise, and see what they look like on a scatter
00:17:00.240 | plot and see what their R^2 are, just to get a feel for what does an R^2 look like.
00:17:05.480 | So is an R^2 0.9 close or not?
00:17:13.960 | So I think R^2 is a useful number to have a familiarity with, and you don't need to
00:17:19.800 | remember the formula if you remember the meaning, which is what's the ratio between how good
00:17:25.760 | your model is, where it means good error, versus how good is the naive mean model for
00:17:30.640 | its good error.
00:17:31.640 | In our case, 0.98, it's saying it's a very good model, however it might be a very good
00:17:39.600 | model because it looks like this, and this would be called overfitting.
00:17:45.360 | So we may well have created a model which is very good at running through the points
00:17:49.320 | that we gave it, but it's not going to be very good at running through points that we
00:17:53.560 | didn't give it.
00:17:55.200 | So that's why we always want to have a validation set.
00:18:01.720 | Creating your validation set is the most important thing that I think you need to do when you're
00:18:09.080 | doing a machine learning project, at least in the actual modeling part.
00:18:18.740 | Because what you need to do is come up with a dataset where the score of your model on
00:18:24.800 | that dataset is going to be representative of how well your model is going to do in the
00:18:30.680 | real world, like in Kaggle on the leaderboard or off Kaggle when you actually use it in
00:18:35.800 | production.
00:18:38.300 | I very very very often hear people in industry say, "I don't trust machine learning, I tried
00:18:47.240 | modeling once, it looked great, we put it in production, it didn't work."
00:18:52.860 | Whose fault is that?
00:18:54.880 | That means their validation set was not representative.
00:18:59.440 | So here's a very simple thing which generally speaking Kaggle is pretty good about doing.
00:19:04.520 | If your data has a time piece in it, as happens in Bluebook for bulldozers, in Bluebook for
00:19:11.680 | bulldozers we're talking about the sale price of a piece of industrial equipment on a particular
00:19:18.360 | date.
00:19:20.040 | So the startup doing this competition wanted to create a model that wouldn't predict last
00:19:25.480 | February's prices, but would predict next month's prices.
00:19:29.640 | So what they did was they gave us data representing a particular date range in the training set,
00:19:35.320 | and then the test set represented a future set of dates that wasn't represented in the
00:19:40.520 | training set.
00:19:42.360 | So that's pretty good.
00:19:43.760 | That means that if we're doing well on this model, we've built something which can actually
00:19:48.400 | predict the future, or at least it could predict the future then, assuming things haven't changed
00:19:54.000 | dramatically.
00:19:56.220 | So that's the test set we have.
00:19:58.160 | So we need to create a validation set that has the same properties.
00:20:02.260 | So the test set had 12,000 rows in, so let's create a validation set that has 12,000 rows,
00:20:09.200 | and then let's split the data set into the first n-12,000 rows for the training set and
00:20:19.920 | the last 12,000 rows for the validation set.
00:20:23.040 | And so we've now got something which hopefully looks like Kaggle's test set, close enough
00:20:30.000 | that when we actually try and use this validation set, we're going to get some reasonably accurate
00:20:36.160 | scores.
00:20:37.160 | The reason we want this is because on Kaggle, you can only submit so many times, and if
00:20:42.680 | you submit too often, you'll end up opening to the leaderboard anyway, and in real life,
00:20:47.080 | you actually want to build a model that's going to work in real life.
00:20:50.080 | Did you have a question?
00:20:51.080 | Can we help the green box?
00:20:54.400 | Can you explain the difference between a validation set and a test set?
00:21:04.080 | Absolutely.
00:21:05.080 | What we're going to learn today is how to set hyperparameters.
00:21:09.960 | Hyperparameters are like tuning parameters that are going to change how your model behaves.
00:21:14.400 | Now if you just have one holdout set, so one set of data that you're not using to train
00:21:19.720 | with, and we use that to decide which set of hyperparameters to use, if we try a thousand
00:21:25.160 | different sets of hyperparameters, we may end up overfitting to that holdout set.
00:21:30.400 | That is to say we'll find something which only accidentally worked.
00:21:34.480 | So what we actually want to do is we really want to have a second holdout set where we
00:21:39.280 | can say, okay, I'm finished, I've done the best I can, and now just once right at the
00:21:46.600 | end I'm going to see whether it works.
00:21:51.920 | This is something which almost nobody in industry does correctly.
00:21:58.800 | You really actually need to remove that holdout set, and that's called the test set.
00:22:03.320 | Remove it from the data, give it to somebody else, and tell them do not let me look at
00:22:08.280 | this data until I promise you I'm finished.
00:22:10.960 | It's so hard otherwise not to look at it.
00:22:13.560 | For example, in the world of psychology and sociology you might have heard about this
00:22:16.960 | replication crisis.
00:22:18.960 | This is basically because people in these fields have accidentally or intentionally
00:22:24.040 | maybe been p-hacking, which means they've been basically trying lots of different variations
00:22:29.840 | until they find something that works.
00:22:32.000 | And then it turns out when they try to replicate it, in other words it's like somebody creates
00:22:35.800 | a test set.
00:22:36.800 | Somebody says okay, this study which shows the impact of whether you eat marshmallows
00:22:41.440 | on your tenacity later in life, I'm going to rerun it, and over half the time they're
00:22:47.760 | finding the effect turns out not to exist.
00:22:50.300 | So that's why we want to have a test set.
00:22:54.680 | I've seen a lot of models where we convert categorical data into different columns using
00:23:08.760 | one-hot encoding, so which approach to use in which model?
00:23:13.160 | Yeah we're going to tackle that today, it's a great question.
00:23:19.240 | So I'm splitting my data into validation and training sets, and so you can see now that
00:23:27.480 | my validation set is 12,000 by 66, whereas my training set is 389,000 by 66.
00:23:36.760 | So we're going to use this set of data to train a model and this set of data to see
00:23:40.800 | how well it's working.
00:23:43.440 | So when we then tried that last week, we found out that our model, which had 0.982r^2 on
00:23:51.880 | the training set, only had 0.887 on the validation set, which makes us think that we're overfitting
00:23:59.000 | quite badly.
00:24:00.000 | But it turned out it wasn't too badly because the root mean squared error on the logs of
00:24:05.400 | the prices actually would have put us in the top 25% of the competition anyway.
00:24:10.240 | So even though we're overfitting, it wasn't the end of the world.
00:24:13.640 | Could you pass the microphone to Marcia please?
00:24:19.600 | In terms of dividing the set into training and validation, it seems like you simply take
00:24:26.740 | the first and train observations of the dataset and set them aside.
00:24:32.120 | Why don't you randomly pick up the observations?
00:24:37.600 | Because if I did that, I wouldn't be replicating the test set.
00:24:41.400 | So Kaggle has a test set that when you actually look at the dates in the test set, they are
00:24:46.480 | a set of dates that are more recent than any date in the training set.
00:24:52.620 | So if we used a validation set that was a random sample, that is much easier because
00:24:57.660 | we're predicting options like what's the value of this piece of industrial equipment on this
00:25:02.340 | day when we actually already have some observations from that day.
00:25:06.900 | So in general, any time you're building a model that has a time element, you want your
00:25:13.680 | test set to be a separate time period, and therefore you really need your validation
00:25:19.000 | set to be a separate time period as well.
00:25:20.840 | In this case, the data was already sorted, so that's why this works.
00:25:24.040 | So let's say we have the training set where we train the data and then we have the validation
00:25:36.480 | set against which we are trying to find the R-square.
00:25:41.020 | In case our R-square turns out to be really bad, we would want to tune our parameters
00:25:46.560 | and run it again.
00:25:47.980 | So wouldn't that be eventually overfitting on the overall training set?
00:25:52.700 | Yeah, so actually that's the issue.
00:25:55.020 | So that would eventually have the possibility of overfitting on the validation set, and
00:25:59.320 | then when we try it on the test set or we submit it to Kaggle, it turns out not to be
00:26:03.440 | very good.
00:26:04.440 | And this happens in Kaggle competitions all the time.
00:26:07.160 | Kaggle actually has a fourth dataset which is called the Private Leaderboard set.
00:26:13.480 | And every time you submit to Kaggle, you actually only get feedback on how well it does on something
00:26:18.680 | called the Public Leaderboard set, and you don't know which rows they are.
00:26:22.760 | And at the end of the competition, you actually get judged on a different dataset entirely
00:26:26.820 | called the Private Leaderboard set.
00:26:28.960 | So the only way to avoid this is to actually be a good machine learning practitioner and
00:26:35.520 | know how to set these parameters as effectively as possible, which we're going to be doing
00:26:40.680 | partly today and over the next few weeks.
00:26:46.040 | Can you get the -- actually, why don't you throw it to me?
00:26:53.800 | Is it too early or late to ask what's the difference between a hyperparameter and a
00:26:59.000 | parameter?
00:27:00.000 | Sure.
00:27:01.000 | Okay.
00:27:02.000 | Okay.
00:27:03.000 | So let's start tracking things on root name spread error.
00:27:14.600 | So here is root mean squared error in a line of code.
00:27:19.080 | And you can see here, this is one of these examples where I'm not writing this the way
00:27:24.760 | a proper software engineer would write this, right?
00:27:26.960 | So a proper software engineer would be a number of things differently.
00:27:29.560 | They would have it on a different line.
00:27:31.920 | They would use longer variable names.
00:27:40.520 | They would have documentation, blah, blah, blah.
00:27:45.520 | But I really think, for me, I really think that being able to look at something in one
00:27:58.080 | go with your eyes and over time learn to immediately see what's going on has a lot of value.
00:28:06.120 | And also to consistently use particular letters that mean particular things or abbreviations,
00:28:13.960 | I think works really well in data science.
00:28:18.880 | If you're doing a take-home interview test or something, you should write your code according
00:28:27.140 | to PEP8 standards.
00:28:29.760 | So PEP8 is the style guide for Python code and you should know it and use it because
00:28:36.200 | a lot of software engineers are super anal about this kind of thing.
00:28:41.120 | But for your own work, I think this works well for me.
00:28:48.440 | So I just wanted to make you aware, a) that you shouldn't necessarily use this as a role
00:28:52.460 | model for dealing with software engineers, but b) that I actually think this is a reasonable
00:28:59.360 | approach.
00:29:00.360 | So there's our root-mean-squared error, and then from time to time we're just going to
00:29:03.840 | print out the score which will give us the RMSE of the predictions on the training versus
00:29:08.920 | the actual, the predictions on the valid versus the actual RMSE, the R-squared for the training
00:29:14.560 | and the R-squared for the valid.
00:29:15.920 | And we'll come back to OOV in a moment.
00:29:18.200 | So when we ran that, we found that this RMSE was in the top 25% and it's like, okay, there's
00:29:24.060 | a good start.
00:29:25.340 | Now this took 8 seconds of wall time, so 8 actual seconds.
00:29:33.520 | If you put %time, it'll tell you how long things took.
00:29:37.960 | And luckily I've got quite a few cores, quite a few CPUs in this computer because it actually
00:29:42.140 | took over a minute of compute time, so it parallelized that across cores.
00:29:47.880 | If your dataset was bigger or you had less cores, you could well find that this took
00:29:55.260 | a few minutes to run or even a few hours.
00:29:58.040 | My rule of thumb is that if something takes more than 10 seconds to run, it's too long
00:30:05.240 | for me to do interactive analysis with it.
00:30:09.520 | I want to be able to run something, wait a moment, and then continue.
00:30:15.540 | So what we do is we try to make sure that things can run in a reasonable time.
00:30:22.000 | And then when we're finished at the end of the day, we can then say, okay, this feature
00:30:27.100 | engineering, these hyperparameters, whatever, these are all working well, and I'll now rerun
00:30:31.360 | it the big, slow, precise way.
00:30:36.320 | So one way to speed things up is to pass in the subset parameter to proc df, and that
00:30:42.400 | will randomly sample my data.
00:30:46.600 | And so here I'm going to randomly sample 30,000 rows.
00:30:49.640 | Now when I do that, I still need to be careful to make sure that my validation set doesn't
00:30:57.360 | change and that my training set doesn't overlap with the dates, otherwise I'm cheating.
00:31:03.320 | So I call split_valves again to do this split_by_dates.
00:31:09.840 | And you'll also see I'm using, rather than putting it into a validation set, I'm putting
00:31:13.960 | it into a variable called _. This is kind of a standard approach in Python is to use
00:31:18.680 | a variable called _ if you want to throw something away, because I don't want to change my validation
00:31:23.320 | set.
00:31:24.320 | Like no matter what different models I build, I want to be able to compare them all to each
00:31:27.840 | other, so I want to keep my validation set the same all the time.
00:31:31.840 | So all I'm doing here is I'm resampling my training set into the first 20,000 out of
00:31:38.080 | a 30,000 subset.
00:31:41.160 | So I now can run that, and it runs in 621 milliseconds, so I can really zip through
00:31:47.400 | things now, try things out.
00:31:51.600 | So with that, let's use this subset to build a model that is so simple that we can actually
00:31:59.640 | take a look at it.
00:32:01.080 | And so we're going to build a forest that's made of trees.
00:32:06.220 | And so before we look at the forest, we'll look at the trees.
00:32:10.000 | In scikit-learn, they don't call them trees, they call them estimators.
00:32:14.200 | So we're going to pass in the parameter number of estimators equals 1 to create a forest with
00:32:19.760 | just one tree in.
00:32:22.160 | And then we're going to make a small tree, so we pass in maximum depth equals 3.
00:32:27.400 | And a random forest, as we're going to learn, randomizes a whole bunch of things.
00:32:31.960 | We want to turn that off.
00:32:33.360 | So to turn that off, you say bootstrap equals false.
00:32:36.180 | So if I pass in these parameters, it creates a small deterministic tree.
00:32:43.160 | So if I fit it and say printScore, my R^2 has gone down from 0.85 to 0.4.
00:32:50.760 | So this is not a good model.
00:32:52.680 | It's better than the mean model, this is better than 0, it's not a good model.
00:32:57.400 | But it's a model that we can draw.
00:33:01.840 | So let's learn about what it's built.
00:33:05.160 | So a tree consists of a sequence of binary decisions, of binary splits.
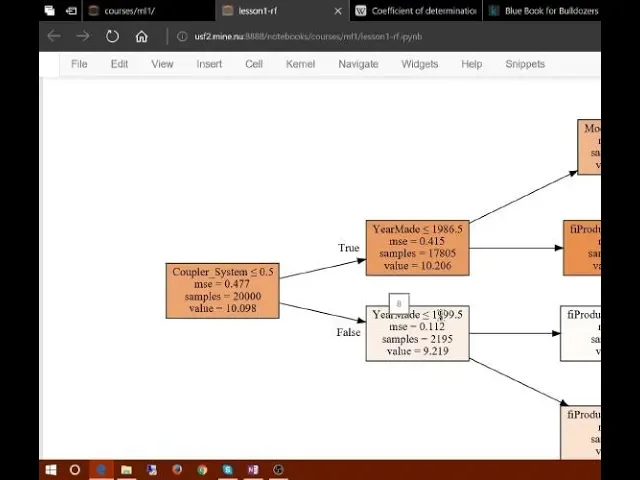
00:33:14.800 | So it first of all decided to split on coupler system greater than or less than 0.5.
00:33:20.800 | That's a Boolean variable, so it's actually true or false.
00:33:24.080 | And then within the group where a coupler system was true, it decided to split into
00:33:28.200 | yearmade greater than or less than 0.987.
00:33:31.640 | And then where a coupler system was true and yearmade was less than or equal to 0.986,
00:33:36.960 | it used fi_product_class_desk is less than or equal to 0.75, and so forth.
00:33:43.840 | So right at the top, we have 20,000 samples, 20,000 rows.
00:33:50.440 | And the reason for that is because that's what we asked for here when we split our data
00:33:55.980 | in the sample.
00:34:02.760 | I just want to double check that for your decision tree that you have there, that the
00:34:07.240 | coloration was whether it's true or false, so it gets darker, it's true for the next
00:34:13.480 | one, not the...
00:34:15.280 | Darker is a higher value, we'll get to that in a moment.
00:34:19.000 | So let's look at these numbers here.
00:34:21.240 | So in the whole data set, our sample that we're using, there are 20,000 rows.
00:34:28.520 | The average of the log of price is 10.1.
00:34:33.080 | And if we built a model where we just used that average all the time, then the mean squared
00:34:38.360 | error would be 0.477.
00:34:43.160 | So this is, in other words, the denominator of an R^2.
00:34:49.320 | This is like the most basic model is a tree with zero splits, which is just predict the
00:34:54.400 | average.
00:34:56.000 | So the best single binary split we can make turns out to be splitting by whether the coupler
00:35:03.680 | system is less than or equal to or greater than 0.5, in other words whether it's true
00:35:08.760 | or false.
00:35:09.760 | And it turns out if we do that, the mean squared error of coupler system is less than 0.5,
00:35:16.000 | so it's false, goes down from 0.477 to 0.11.
00:35:22.280 | So it's really improved the error a lot.
00:35:25.400 | In the other group, it's only improved it a bit, it's gone from 0.47 to 0.41.
00:35:31.160 | And so we can see that the coupler system equals false group has a pretty small percentage,
00:35:37.360 | it's only got 2200 of the 20,000, whereas this other group has a much larger percentage,
00:35:45.240 | but it hasn't improved it as much.
00:35:48.400 | So let's say you wanted to create a tree with just one split.
00:35:54.840 | So you're just trying to find what is the very best single binary decision you can make
00:36:02.440 | for your data.
00:36:05.320 | How much you'd be able to do that?
00:36:06.720 | How could you do it?
00:36:08.040 | I'm going to give it to Ford.
00:36:16.520 | But you're writing, you don't have a random forest, right?
00:36:20.760 | How are you going to write, what's an algorithm, a simple algorithm which you could use?
00:36:26.680 | Sure.
00:36:28.520 | So we want to start building a random forest from scratch.
00:36:32.080 | So the first step is to create a tree.
00:36:34.840 | The first step to create a tree is to create the first binary decision.
00:36:39.840 | How are you going to do it?
00:36:40.840 | I'm going to give it to Chris, maybe in two steps.
00:36:49.760 | So isn't this simply trying to find the best predictor based on maybe linear regression?
00:36:56.680 | You could use a linear regression, but could you do something much simpler and more complete?
00:37:03.560 | We're trying not to use any statistical assumptions here.
00:37:06.880 | Can we just take just one variable, if it is true, give it the true thing, and if it
00:37:21.480 | is false?
00:37:23.680 | So which variable are we going to choose?
00:37:25.400 | So at each binary point we have to choose a variable and something to split on.
00:37:31.840 | How are we going to do that?
00:37:32.840 | We're going to pass it over there.
00:37:33.840 | How do I pronounce your name?
00:37:38.520 | Shikhar.
00:37:39.520 | So the variable to choose could be like which divides the population into two groups, which
00:37:46.600 | are kind of heterogeneous to each other and homogeneous within themselves, like having
00:37:52.040 | the same quality within themselves, and they're very different.
00:37:56.080 | Could you be more specific?
00:37:57.680 | In terms of the target variable maybe, let's say we have two groups after split, so one
00:38:04.720 | has a different price altogether from the second group, but internally they have similar
00:38:09.880 | prices.
00:38:10.880 | Okay, that's good.
00:38:11.880 | So to simplify things a little bit, we're saying find a variable that we could split
00:38:17.320 | into such that the two groups are as different to each other as possible.
00:38:25.040 | And how would you pick which variable and which split point?
00:38:29.240 | That's the question.
00:38:38.400 | What's your first cut?
00:38:39.400 | Which variable and which split point?
00:38:47.760 | We're making a tree from scratch, we want to create our own tree.
00:38:51.160 | Does that make sense?
00:38:52.760 | We've got somebody over here, Maisley?
00:39:03.960 | Can we test all of the possible splits and see which one has the smallest RMSE?
00:39:09.480 | That sounds good.
00:39:10.480 | Okay, so let's dig into this.
00:39:12.080 | So when you say test all of the possible splits, what does that mean?
00:39:16.920 | How do we enumerate all of the possible splits?
00:39:29.960 | For each variable, you could put one aside and then put a second aside and compare the
00:39:37.520 | two and if it was better.
00:39:39.280 | Okay, so for each variable, for each possible value of that variable, see whether it's better.
00:39:48.080 | Now give it back to Maisley because I want to dig into the better.
00:39:50.760 | When you said see if the RMSE is better, what does that mean though?
00:39:54.800 | Because after a split, you've got two RMSEs, you've got two groups.
00:40:00.900 | So you're just going to fit with that one variable comparing to the other's not.
00:40:05.960 | So what I mean here is that before we decided to split on coupler system, we had a remove
00:40:11.680 | the mean squared of 0.477, and after we've got two groups, one with a mean squared error
00:40:16.680 | of 0.1, another with a mean squared error of 0.4.
00:40:21.200 | So you treat each individual model separately.
00:40:25.080 | So for the first split, you're just going to compare between each variable themselves.
00:40:29.640 | And then you move on to the next node with the remaining variable.
00:40:32.280 | But even the first node, so the model with zero splits has a single root mean squared
00:40:39.400 | error.
00:40:40.560 | The model with one split, so the very first thing we tried, we've now got two groups with
00:40:46.360 | two mean squared errors.
00:40:47.360 | Do you want to give it to Daniel?
00:40:52.080 | Do you pick the one that gets them as different as they can be?
00:40:55.440 | Well, okay, that would be one idea.
00:40:58.240 | Get the two mean squared errors as different as possible, but why might that not work?
00:41:04.620 | What might be a problem with that?
00:41:07.460 | Sample size.
00:41:08.460 | Go on.
00:41:09.460 | Because you could just literally leave one point out.
00:41:11.840 | Yeah, so we could have like year made is less than 1950, and it might have a single sample
00:41:18.280 | with a low price, and that's not a great split, is it?
00:41:22.800 | Because the other group is actually not going to be very interesting at all.
00:41:27.700 | Can you improve it a bit?
00:41:29.400 | Can Jason improve it a bit?
00:41:33.400 | Could you take a weighted average?
00:41:36.000 | Yeah, a weighted average.
00:41:38.280 | So we could take 0.41 times 17,000 plus 0.1 times 2,000.
00:41:43.960 | That's good, right?
00:41:45.400 | And that would be the same as actually saying I've got a model, the model is a single binary
00:41:51.760 | decision, and I'm going to say for everybody with year made less than 986.5, I'm going
00:41:56.960 | to fill in 10.2.
00:42:00.040 | For everybody else, I'm going to fill in 9.2, and then I'm going to calculate the root mean
00:42:04.400 | squared error of this crappy model.
00:42:08.400 | And that will give exactly the same as the weighted average that you're suggesting.
00:42:14.120 | So we now have a single number that represents how good a split is, which is the weighted
00:42:20.920 | average of the mean squared errors of the two groups it creates.
00:42:25.200 | And thanks to Jake, we have a way to find the best split, which is to try every variable
00:42:32.400 | and to try every possible value of that variable and see which variable and which value gives
00:42:37.280 | us the split with the best score.
00:42:41.000 | That make sense?
00:42:42.000 | What's your name?
00:42:43.000 | Sorry?
00:42:44.000 | Can somebody give Natalie the box?
00:42:59.400 | When you say every possible number for every possible variable, are you saying here we
00:43:05.600 | have 0.5 as our criteria to split the tree, are you saying we're trying out every single
00:43:15.440 | number for?
00:43:17.640 | Every possible value.
00:43:19.400 | So a couple of system only has two values, true and false.
00:43:23.640 | So there's only one way of splitting, which is trues and falses.
00:43:27.440 | Year made is an integer which varies between 1960 and 2010, so we can just say what are
00:43:33.200 | all the possible unique values of year made, and try them all.
00:43:37.440 | So we're trying all the possible split points.
00:43:40.120 | Can you pass that back to Daniel, or pass it to me and I'll pass it to Daniel?
00:43:56.440 | So I just want to clarify again for the first split.
00:44:01.120 | Why did we split on coupler system, true or false to start with?
00:44:05.720 | Because what we did was we used Jake's technique.
00:44:08.520 | We tried every variable, for every variable we tried every possible split.
00:44:14.600 | For each one, we noted down, I think it was Jason's idea, which was the weighted average
00:44:20.320 | mean squared error of the two groups we created.
00:44:23.520 | We found which one had the best mean squared error and we picked it, and it turned out
00:44:29.000 | it was coupler system, true or false.
00:44:31.880 | Does that make sense?
00:44:34.720 | I guess my question is more like, so coupler system is one of the best indicators, I guess?
00:44:43.520 | It's the best.
00:44:44.880 | We tried every variable and every possible level.
00:44:48.280 | So each level after that, it gets less and less?
00:44:51.320 | Everything else it tried wasn't as good.
00:44:53.440 | And then you do that each time you split?
00:44:55.200 | Right.
00:44:56.200 | So on that, we now take this group here, everybody who's got coupler system equals true, and
00:45:02.160 | we do it again.
00:45:03.240 | For every possible variable, for every possible level, for people where coupler system equals
00:45:08.320 | true, what's the best possible split?
00:45:11.600 | And then are there circumstances when it's not just like binary?
00:45:16.600 | You split it into three groups, for example, year made?
00:45:20.280 | So I'm going to make a claim, and then I'm going to see if you can justify it.
00:45:23.760 | I'm going to claim that it's never necessary to do more than one split at a level.
00:45:30.320 | Because you can just split it again.
00:45:31.880 | Because you can just split it again, exactly.
00:45:34.260 | So you can get exactly the same result by splitting twice.
00:45:40.880 | So that is the entirety of creating a decision tree.
00:45:47.160 | You stop either when you hit some limit that was requested, so we had a limit where we
00:45:53.680 | said max depth equals 3.
00:45:55.920 | So that's one way to stop, would be you ask to stop at some point, and so we stop.
00:46:00.840 | Otherwise you stop when your leaf nodes, these things at the end are called leaf nodes, when
00:46:06.680 | your leaf nodes only have one thing in them.
00:46:09.120 | That's a decision tree.
00:46:12.400 | That is how we grow a decision tree.
00:46:15.160 | And this decision tree is not very good because it's got a validation R squared of 0.4.
00:46:20.720 | So we could try to make it better by removing max depth equals 3 and creating a deeper tree.
00:46:27.520 | So it's going to go all the way down, it's going to keep splitting these things further
00:46:31.040 | until every leaf node only has one thing in it.
00:46:35.040 | And if we do that, the training R squared is, of course, 1, because we can exactly predict
00:46:43.200 | every training element because it's in a leaf node all on its own.
00:46:48.360 | But the validation R squared is not one.
00:46:51.800 | It's actually better than a really shallow tree, but it's not as good as we'd like.
00:46:59.560 | So we want to find some other way of making these trees better.
00:47:06.360 | And the way we're going to do it is to create a forest.
00:47:11.000 | So what's a forest?
00:47:12.820 | To create a forest, we're going to use a statistical technique called bagging.
00:47:18.400 | And you can bag any kind of model.
00:47:22.100 | In fact, Michael Jordan, who is one of the speakers at the recent Data Institute conference
00:47:26.340 | here at the University of San Francisco, developed a technique called the Bag of Little Bootstraps,
00:47:34.720 | in which he shows how to use bagging for absolutely any kind of model to make it more robust and
00:47:41.160 | also to give you confidence intervals.
00:47:44.360 | The random forest is simply a way of bagging trees.
00:47:48.960 | So what is bagging?
00:47:52.160 | Bagging is a really interesting idea, which is what if we created five different models,
00:47:59.680 | each of which was only somewhat predictive, but the models weren't at all correlated with
00:48:04.920 | each other.
00:48:05.920 | They gave predictions that weren't correlated with each other.
00:48:08.680 | That would mean that the five models would have to have found different insights into
00:48:14.360 | the relationships in the data.
00:48:16.840 | And so if you took the average of those five models, then you're effectively bringing in
00:48:22.240 | the insights from each of them.
00:48:25.260 | And so this idea of averaging models is a technique for ensembling, which is really
00:48:33.160 | important.
00:48:35.760 | Now let's come up with a more specific idea of how to do this ensembling.
00:48:40.240 | What if we created a whole lot of these trees, big, deep, massively overfit trees.
00:48:50.240 | But each one, let's say we only pick a random one-tenth of the data.
00:48:56.500 | So we pick one out of every ten rows at random, build a deep tree, which is perfect on that
00:49:04.640 | subset and kind of crappy on the rest.
00:49:08.880 | Let's say we do that 100 times, a different random sample every time.
00:49:13.760 | So all of the trees are going to be better than nothing because they do actually have
00:49:17.360 | a real random subset of the data and so they found some insight, but they're also overfitting
00:49:21.720 | terribly.
00:49:22.720 | But they're all using different random samples, so they all overfit in different ways on different
00:49:27.240 | things.
00:49:28.240 | So in other words, they all have errors, but the errors are random.
00:49:34.920 | What is the average of a bunch of random errors?
00:49:39.320 | Zero.
00:49:40.960 | So in other words, if we take the average of these trees, each of which have been trained
00:49:45.720 | on a different random subset, the errors will average out to zero, and what's left is the
00:49:51.000 | true relationship.
00:49:53.400 | And that's the random forest.
00:49:55.520 | So there's the technique.
00:49:58.080 | We've got a whole bunch of rows of data.
00:50:01.520 | We grab a few at random, put them into a smaller data set, and build a tree based on that.
00:50:12.200 | And then we put that tree aside and do it again with a different random subset, and
00:50:17.800 | do it again with a different random subset.
00:50:20.440 | Do it a whole bunch of times, and then for each one we can then make predictions by running
00:50:26.480 | our test data through the tree to get to the leaf node, take the average in that leaf node
00:50:32.360 | for all the trees, and average them all together.
00:50:37.360 | So to do that, we simply call random forest regressor, and by default it creates 10 what
00:50:44.880 | scikit-learn calls estimators.
00:50:47.000 | An estimator is a tree.
00:50:49.840 | So this is going to create 10 trees.
00:50:54.800 | And so we go ahead and train it.
00:51:11.240 | So create our 10 trees, and we're just doing this on our little random subset of 20,000.
00:51:17.880 | And so let's take a look at one example.
00:51:22.000 | When you pass the box to Devin.
00:51:25.920 | Just to make sure I'm understanding this, you're saying we take 10 kind of crappy models.
00:51:31.160 | We average 10 crappy models, and we get a good model.
00:51:34.240 | Exactly.
00:51:35.240 | Because the crappy models are based on different random subsets, and so their errors are not
00:51:40.480 | correlated with each other.
00:51:42.340 | If the errors work correlated with each other, this isn't going to work.
00:51:46.320 | So the key insight here is to construct multiple models which are better than nothing, and
00:51:52.500 | where the errors are as much as possible, not correlated with each other.
00:51:58.060 | So is there like a certain number of trees that we need that in order to be valid?
00:52:02.240 | There's always this thing that's valid or invalid.
00:52:05.760 | There's like, has a good validation set, RMSE, or not.
00:52:11.880 | And so that's what we're going to look at, is how to make that metric higher.
00:52:15.760 | And so this is the first of our hyperparameters, and we're going to learn about how to tune
00:52:21.240 | hyperparameters.
00:52:22.240 | And the first one is going to be the number of trees, and we're about to look at that
00:52:25.200 | now.
00:52:26.200 | Yes, Maisly.
00:52:27.200 | The subset that you're selecting, are they exclusive?
00:52:33.560 | Can you have overlapping over them?
00:52:35.040 | Yes, so I mentioned one approach would be to pick out a 10th at random, but actually
00:52:41.240 | what Scikit-learn does by default is for n rows, it picks out n rows with replacement.
00:52:49.680 | And that's called bootstrapping.
00:52:51.480 | And if memory serves me correctly, that gets you an average 63.2% of the rows will be represented,
00:52:58.760 | and a bunch of them will be represented multiple times.
00:53:05.880 | So rather than just picking out like a 10th of the rows at random, instead we're going
00:53:10.800 | to pick out of an n row data set, we're going to pick out n rows with replacement, which
00:53:17.160 | on average gets about 63, I think 63.2% of the rows will be represented, many of those
00:53:24.120 | rows will appear multiple times.
00:53:26.440 | I think there's a question behind you.
00:53:33.000 | In essence, what this model is doing is, if I understand correctly, is just picking out
00:53:37.200 | the data points that look most similar to the one you're looking at.
00:53:41.360 | Yeah, that's a great insight.
00:53:43.320 | So what a tree is kind of doing, there would be other ways of assessing similarity.
00:53:51.640 | There are other ways of assessing similarity, but what's interesting about this way is it's
00:53:55.880 | doing it in tree space.
00:53:59.720 | So we're basically saying, in this case, for this little tree, what are the 593 samples
00:54:05.200 | closest to this one, and what's their average closest in tree space.
00:54:09.360 | So other ways of doing that would be like, and we'll learn later on in this course about
00:54:13.200 | k nearest neighbors, you could use Euclidean distance.
00:54:19.440 | But here's the thing, the whole point of machine learning is to identify which variables actually
00:54:27.080 | matter the most, and how do they relate to each other and your dependent variable together.
00:54:33.840 | So imagine a synthetic dataset where you create 5 variables that add together to create your
00:54:40.960 | dependent variable, and 95 variables which are entirely random and don't impact your
00:54:46.040 | dependent variable.
00:54:47.280 | And then if you do like a k nearest neighbors in Euclidean space, you're going to get meaningless
00:54:52.040 | nearest neighbors because most of your columns are actually meaningless.
00:54:56.080 | Or imagine your actual relationship is that your dependent variable equals x_1 times x_2.
00:55:02.840 | And you'll actually need to find this interaction.
00:55:06.400 | So you don't actually care about how close it is to x_1 and how close to x_2, but how
00:55:10.240 | close to the product.
00:55:11.800 | So the entire purpose of modeling in machine learning is to find a model which tells you
00:55:18.020 | which variables are important and how do they interact together to drive your dependent
00:55:21.720 | variable.
00:55:23.600 | And so you'll find in practice the difference between using tree space, or random forest
00:55:30.520 | space to find your nearest neighbors, versus Euclidean space is the difference between
00:55:35.560 | a model that makes good predictions and a model that makes meaningless predictions.
00:55:42.160 | In general, a machine learning model which is effective is one which is accurate when
00:56:07.600 | you look at the training data, it's accurate at actually finding the relationships in that
00:56:14.280 | training data, and then it generalizes well to new data.
00:56:19.320 | And so in bagging, that means that each of your individual estimators, each of your individual
00:56:26.240 | trees, you want to be as predictive as possible, but the predictions of your individual trees
00:56:32.920 | to be as uncorrelated as possible.
00:56:35.400 | And so the inventor of random forests talks about this at length in his original paper
00:56:39.360 | that introduced this in the late 90s, this idea of trying to come up with predictive
00:56:44.960 | but poorly correlated trees.
00:56:48.000 | The research community in recent years has generally found that the more important thing
00:56:56.240 | seems to be creating uncorrelated trees rather than more accurate trees.
00:57:02.040 | So more recent advances tend to create trees which are less predictive on their own, but
00:57:07.960 | also less correlated with each other.
00:57:10.000 | So for example, in scikit-learn there's another class you can use called extra-trees-aggressor,
00:57:17.000 | or extra-trees-classifier with exactly the same API, you can try it tonight, just replace
00:57:21.360 | my random forest-aggressor with that, that's called an extremely randomized trees model.
00:57:28.120 | And what that does is exactly the same as what we just discussed, but rather than trying
00:57:32.160 | every split of every variable, it randomly tries a few splits of a few variables.
00:57:39.080 | So it's much faster to train, it has more randomness, but then with that time you can
00:57:45.640 | build more trees and therefore get better generalization.
00:57:50.880 | So in practice, if you've got crappy individual models you just need more trees to get a good
00:57:56.560 | end-up model.
00:57:57.560 | Okay, so could you pass that over to Devin?
00:58:00.760 | Could you talk a little bit more about what you mean by uncorrelated trees?
00:58:10.860 | If I build a thousand trees, each one on just 10 data points, then it's quite likely that
00:58:19.960 | the 10 data points for every tree are going to be totally different, and so it's quite
00:58:23.720 | likely that those 1000 trees are going to give totally different answers to each other.
00:58:30.200 | So the correlation between the predictions of tree 1 and tree 2 is going to be very small,
00:58:35.400 | between tree 1 and tree 3 very small, and so forth.
00:58:38.400 | On the other hand, if I create a thousand trees where each time I use the entire data
00:58:43.600 | set with just one element removed, all those trees are going to be nearly identical, i.e.
00:58:49.760 | their predictions will be highly correlated.
00:58:52.480 | And so in the latter case, it's probably not going to generalize very well.
00:58:56.680 | Whereas in the former case, the individual trees are not going to be very predictive.
00:59:01.120 | So I need to find some nice in-between.
00:59:08.920 | I'm just trying to understand how this random forest actually makes sense for continuous
00:59:37.720 | variables.
00:59:38.720 | I mean, I'm assuming that you build a tree structure, and the last final nodes you'd
00:59:42.720 | be saying like maybe this node represents maybe a category A or a category B, but how
00:59:48.160 | does it make sense for a continuous target?
00:59:50.320 | So this is actually what we have here, and so the value here is the average.
00:59:56.480 | So this is the average log of price for this subgroup, and that's all we do.
01:00:02.640 | The prediction is the average of the value of the dependent variable in that leaf node.
01:00:17.600 | So a couple of things to remember, the first is that by default, we're actually going to
01:00:20.800 | train the tree all the way down until the leaf nodes are size 1, which means for a data
01:00:27.280 | set with n rows, we're going to have n leaf nodes.
01:00:30.920 | And then we're going to have multiple trees, which we averaged together.
01:00:35.120 | So in practice, we're going to have lots of different possible values.
01:00:40.720 | There's a question behind you?
01:00:45.360 | So for the continuous variable, how do we decide which value to split out because there
01:00:49.400 | can be many values?
01:00:50.520 | We try every possible value of that in the training set.
01:00:55.480 | Won't it be computationally?
01:00:58.440 | Computationally expensive.
01:00:59.440 | This is where it's very good to remember that your CPU's performance is measured in gigahertz,
01:01:05.600 | which is billions of clock cycles per second, and it has multiple cores.
01:01:10.480 | And each core has something called SIMD, single instruction multiple data, where it can direct
01:01:15.840 | up to 8 computations per core at once.
01:01:19.460 | And then if you do it on the GPU, the performance is measured in teraflops, so trillions of floating
01:01:26.920 | point operations per second.
01:01:28.560 | And so this is where when it comes to designing algorithms, it's very difficult for us mere
01:01:35.000 | humans to realize how stupid algorithms should be, given how fast today's computers are.
01:01:42.520 | So yeah, it's quite a few operations, but at trillions per second, you hardly notice
01:01:48.520 | it.
01:01:49.520 | Marcia?
01:01:50.520 | I have a question.
01:01:53.680 | So essentially, at each mode, we make a decision like which category, which variable to use.
01:02:01.920 | And which checkpoint?
01:02:02.920 | Yes.
01:02:03.920 | Yeah, but one thing I can't understand.
01:02:06.800 | So we have MSE calculated for each node, right?
01:02:11.800 | So this is kind of one of the decision criteria.
01:02:14.720 | But this MSE, it is calculated for which model?
01:02:18.200 | Like which model underlies the field?
01:02:21.960 | The model is, for the initial root mode, is what if we just predicted the average, right?
01:02:30.720 | Which here is 10.098, and just the average.
01:02:35.200 | And then the next model is what if we predicted the average of those people with Kepler system
01:02:40.640 | equals false, and for those people with Kepler system equals true.
01:02:45.760 | And then the next is, what if we predicted the average of Kepler system equals true,
01:02:49.840 | EMA less than 1986?
01:02:52.200 | Is it always average, or we can use median, or we can even run linear regression?
01:02:58.040 | There's all kinds of things we could do.
01:02:59.640 | In practice, the average works really well.
01:03:05.000 | There are types of, they're not called random forests, but there are kinds of trees where
01:03:08.960 | the leaf nodes are independent linear regressions.
01:03:12.240 | They're not terribly widely used, but there are certainly researchers who have worked
01:03:16.320 | on them.
01:03:17.320 | Pass it back over there to Ford, and then to Jacob.
01:03:25.520 | So this tree has a depth of 3, and then on one of the next commands we get rid of the
01:03:32.160 | max depth.
01:03:33.360 | The tree without the max depth, does that contain the tree with the depth of 3?
01:03:40.320 | Yeah, except in this case we've added randomness, but if you turn bootstrapping off, the deeper
01:03:48.280 | tree will, the less deep tree would be how it would start, and then it just keeps spinning.
01:04:00.320 | So you have many trees, you're going to have different leaf nodes across trees, hopefully
01:04:05.840 | that's what we want.
01:04:07.280 | So how do you average leaf nodes across different trees?
01:04:11.980 | So we just take the first row in the validation set, we run it through the first tree, we
01:04:18.240 | find its average, 9.28.
01:04:21.000 | Then do it through the next tree, find its average in the second tree, 9.95, and so forth.
01:04:26.280 | And we're about to do that, so you'll see it.
01:04:29.200 | So let's try it.
01:04:31.360 | So after you've built a random forest, each tree is stored in this attribute called estimators_.
01:04:40.880 | So one of the things that you guys need to be very comfortable with is using list comprehensions,
01:04:47.760 | so I hope you've all been practicing.
01:04:49.720 | So here I'm using a list comprehension to go through each tree in my model, I'm going
01:04:54.280 | to call predict on it with my validation set, and so that's going to give me a list of arrays
01:05:02.360 | of predictions.
01:05:04.880 | So each array will be all of the predictions for that tree, and I have 10 trees.
01:05:11.200 | np.stack concatenates them together on a new axis.
01:05:16.120 | So after I run this and call .shape, you can see I now have the first axis 10, which means
01:05:25.600 | I have my 10 different sets of predictions, and for each one my validation set is a size
01:05:30.760 | of 12,000, so here are my 12,000 predictions for each of the 10 trees.
01:05:37.400 | So let's take the first row of that and print it out, and so here are 10 predictions, one
01:05:47.880 | from each tree.
01:05:50.160 | And so then if we say take the mean of that, here is the mean of those 10 predictions,
01:05:57.180 | and then what was the actual?
01:05:59.120 | The actual was 9.1, our prediction was 9.07.
01:06:03.020 | So you see how none of our individual trees had very good predictions, but the mean of
01:06:08.320 | them was actually pretty good.
01:06:10.920 | And so when I talk about experimenting, like Jupyter Notebook is great for experimenting,
01:06:16.720 | this is the kind of stuff I mean.
01:06:18.320 | Dig inside these objects and look at them, plot them, take your own averages, cross-check
01:06:23.720 | to make sure that they work the way you thought they did, write your own implementation of
01:06:27.720 | R^2, make sure it's the same as a scikit-learn version, plot it.
01:06:32.240 | Here's an interesting plot I did.
01:06:34.320 | Let's go through each of the 10 trees and then take the mean of all of the predictions
01:06:41.800 | up to the i-th tree.
01:06:44.840 | So let's start by predicting just based on the first tree, then the first 2 trees, then
01:06:49.920 | the first 3 trees, and let's then plot the R^2.
01:06:55.080 | So here's the R^2 of just the first tree.
01:06:57.800 | It's the R^2 of the first 2 trees, 3 trees, 4 trees, up to 10 trees.
01:07:03.400 | And so not surprisingly R^2 keeps improving because the more estimators we have, the more
01:07:10.760 | bagging that we're doing, the more it's going to generalize.
01:07:15.920 | And you should find that that number there, a bit under 0.86, should match this number
01:07:22.920 | here.
01:07:23.920 | So again, these are all the cross checks you can do, the things you can visualize to deepen
01:07:34.660 | your understanding.
01:07:36.480 | So as we add more trees, our R^2 improves, it seems to flatten out after a while.
01:07:42.460 | So we might guess that if we increase the number of estimators to 20, it's maybe not
01:07:47.360 | going to be that much better.
01:07:53.720 | So let's see, we've got 0.862 versus 0.860, so doubling the number of trees didn't help
01:08:01.880 | very much.
01:08:02.960 | But double it again, 0.867, double it again, 0.869.
01:08:09.080 | So you can see there's some point at which you're going to not want to add more trees,
01:08:15.200 | not because it's never going to get worse, because every tree is giving you more semi-random
01:08:23.120 | models to bag together, but it's going to stop improving things much.
01:08:28.880 | So this is like the first hyperparameter you'd learn to set is number of estimators, and
01:08:33.880 | the method for setting is as many as you have time to fit and that actually seem to be helping.
01:08:44.960 | Now in practice, we're going to learn to set a few more hyperparameters, adding more trees
01:08:50.780 | slows it down.
01:08:53.040 | But with less trees, you can still get the same insights.
01:08:56.920 | So I build most of my models in practice with like 20 to 30 trees, and it's only like then
01:09:03.660 | at the end of the project, or maybe at the end of the day's work, I'll then try doing
01:09:07.640 | like a thousand trees and run it overnight.
01:09:11.040 | Was there a question?
01:09:12.040 | Yes, can we pass that to Prince?
01:09:18.680 | So each tree might have different estimators, different combinations of estimators.
01:09:22.820 | Each tree is an estimator, so this is a synonym.
01:09:24.960 | So in scikit-learn, when they say estimator, they mean tree.
01:09:28.800 | So I mean features, each tree might have different breakpoints on different columns.
01:09:34.720 | But if at the end we want to look at the important features?
01:09:39.000 | We'll get to that.
01:09:41.340 | So after we finish with setting hyperparameters, the next stage of the course will be learning
01:09:49.040 | about what it tells us about the data.
01:09:52.320 | If you need to know it now, for your projects, feel free to look ahead.
01:09:57.240 | There's a lesson to RF interpretation is where we can see it.
01:10:05.440 | So that's our first hyperparameter.
01:10:08.600 | I want to talk next about out-of-bag score.
01:10:12.120 | Sometimes your data set will be kind of small, and you want to pull out a validation set.
01:10:18.880 | Because doing so means you now don't have enough data to build a good model.
01:10:22.680 | What do you do?
01:10:24.560 | There's a cool trick which is pretty much unique to random forests, and it's this.
01:10:30.280 | What we could do is recognize that some of our rows didn't get used.
01:10:43.480 | So what we could do would be to pass those rows through the first tree and treat it as
01:10:50.920 | a validation set.
01:10:53.640 | And then for the second tree, we could pass through the rows that weren't used for the
01:10:57.640 | second tree through it to create a validation set for that.
01:11:01.480 | And so effectively, we would have a different validation set for each tree.
01:11:06.560 | And so now to calculate our prediction, we would average all of the trees where that
01:11:14.160 | row was not used for training.
01:11:17.640 | So for tree number 1, we would have the ones I've marked in blue here, and then maybe for
01:11:23.520 | tree number 2, it turned out it was like this one, this one, this one, and this one, and
01:11:30.320 | so forth.
01:11:31.480 | So as long as you've got enough trees, every row is going to appear in the out-of-bag sample
01:11:37.520 | for one of them, at least.
01:11:39.040 | So you'll be averaging hopefully a few trees.
01:11:42.760 | So if you've got 100 trees, it's very likely that all of the rows are going to appear many
01:11:50.820 | times in these out-of-bag samples.
01:11:53.280 | So what you can do is you can create an out-of-bag prediction by averaging all of the trees you
01:11:58.000 | didn't use to train each individual row.
01:12:01.160 | And then you can calculate your root mean squared error, R squared, etc. on that.
01:12:06.920 | If you pass oobscore = true to scikit-learn, it will do that for you, and it will create
01:12:14.680 | an attribute called oobscore_ and so my little printScore function here, if that attribute
01:12:25.500 | exists it adds it to the print.
01:12:29.340 | So if you take a look here, oobscore = true, we've now got one extra number, and it's R
01:12:38.480 | squared, that is the R squared for the oob sample, it's R squared is very similar, the
01:12:44.280 | R squared and the validation set, which is what we hoped for.
01:12:52.100 | Is it the case that the prediction for the oobscore must be mathematically lower than
01:12:59.320 | the one for our entire forest?
01:13:00.840 | Certainly it's not true that the prediction is lower, it's possible that the accuracy
01:13:06.080 | is lower.
01:13:09.360 | It's not mathematically necessary that it's true, but it's going to be true on average
01:13:13.680 | because each row appears in less trees in the oob samples than it does in the full set
01:13:20.560 | of trees.
01:13:21.560 | So as you see here, it's a little less good.
01:13:25.760 | So in general, the OOB R squared will slightly underestimate how generalizable the model
01:13:34.640 | is.
01:13:35.640 | The more trees you add, the less serious that underestimation is.
01:13:40.080 | And for me in practice, I find it's totally good enough in practice.
01:13:48.560 | So this OOB score is super handy, and one of the things it's super handy for is you're
01:13:58.760 | going to see there's quite a few hyperparameters that we're going to set, and we would like
01:14:03.740 | to find some automated way to set them.
01:14:07.920 | And one way to do that is to do what's called a grid search.
01:14:10.280 | A grid search is where there's a scikit-learn function called grid search, and you pass
01:14:16.020 | in the list of all of the hyperparameters that you want to tune, you pass in for each
01:14:20.840 | one a list of all of the values of that hyperparameter you want to try, and it runs your model on
01:14:27.160 | every possible combination of all of those hyperparameters and tells you which one is
01:14:32.000 | the best.
01:14:33.320 | And OOB score is a great choice for getting it to tell you which one is best in terms
01:14:40.640 | of OOB score.
01:14:42.200 | That's an example of something you can do with OOB which works well.
01:14:52.560 | If you think about it, I kind of did something pretty dumb earlier, which is I took a subset
01:15:00.080 | of 30,000 rows of the data and it built all my models of that, which means every tree
01:15:06.480 | in my random forest is a different subset of that subset of 30,000.
01:15:13.560 | Why do that?
01:15:14.840 | Why not pick a totally different subset of 30,000 each time?
01:15:22.080 | So in other words, let's leave the entire 300,000 records as is, and if I want to make
01:15:27.320 | things faster, pick a different subset of 30,000 each time.
01:15:31.880 | So rather than bootstrapping the entire set of rows, let's just randomly sample a subset
01:15:37.880 | of the data.
01:15:39.480 | And so we can do that.
01:15:41.880 | So let's go back and recall property F without the subset parameter to get all of our data
01:15:46.920 | again.
01:15:47.920 | So to remind you, that is 400,000 in the whole data frame of which we have 389,000 in our
01:16:01.640 | training set.
01:16:03.760 | And instead we're going to go set RF_samples 20,000.
01:16:09.000 | Remember that was the site of the 30,000, we used 20,000 of them in our training set.
01:16:13.680 | If I do this, then now when I run a random forest, it's not going to bootstrap an entire
01:16:20.360 | set of 391,000 rows, it's going to just grab a subset of 20,000 rows.
01:16:28.480 | And so now if I run this, it will still run just as quickly as if I had originally done
01:16:35.520 | a random sample of 20,000, but now every tree can have access to the whole data set.
01:16:42.560 | So if I do enough estimators, enough trees, eventually it's going to see everything.
01:16:49.600 | So in this case, with 10 trees, which is the default, I get an R^2 of 0.86, which is actually
01:16:57.880 | about the same as my R^2 with the 20,000 subset.
01:17:03.640 | And that's because I haven't used many estimators yet.
01:17:06.400 | But if I increase the number of estimators, it's going to make more of a difference.
01:17:11.200 | So if I increase the number of estimators to 40, it's going to take a little bit longer
01:17:19.920 | to run, but it's going to be able to see a larger subset of the data set.
01:17:26.200 | And so as you can see, the R^2 has gone up from 0.86 to 0.876.
01:17:31.960 | So this is actually a great approach.
01:17:33.960 | And for those of you who are doing the groceries competition, that's got something like 120
01:17:38.480 | million rows.
01:17:39.480 | There's no way you would want to create a random forest using 128 million rows in every
01:17:45.960 | tree.
01:17:46.960 | It's going to take forever.
01:17:49.080 | So what you could do is use this set of samples to do 100,000 or a million.
01:17:53.840 | We'll play around with it.
01:17:55.860 | So the trick here is that with a random forest using this technique, no data set is too big.
01:18:01.360 | I don't care if it's got 100 billion rows.
01:18:05.080 | You can create a bunch of trees, each one of the different random subsets.
01:18:09.280 | Can somebody pass the-- actually, I can pass it.
01:18:20.720 | So my question was, for the OLB scores and these ones, does it take only for the ones
01:18:35.960 | from the sample, or does it take from all the--
01:18:38.560 | That's a great question.
01:18:41.120 | So unfortunately, scikit-learn does not support this functionality out of the box, so I had
01:18:47.280 | to write this.
01:18:49.920 | And it's kind of a horrible hack, because we'd much rather be passing in like a sample-sized
01:18:55.640 | parameter rather than doing this kind of setting up here.
01:18:58.580 | So what I actually do is, if you look at the source code, is I'm actually-- this is the
01:19:05.680 | internal function I looked at the source code that they call, and I've replaced it with
01:19:10.160 | a lambda function that has the behavior we want.
01:19:13.600 | Unfortunately, the current version is not changing how OOB is calculated.
01:19:20.040 | So currently, OOB scores and setRF samples are not compatible with each other, so you
01:19:29.080 | need to turn OOB equals false if you use this approach.
01:19:35.440 | Which I hope to fix, but at this stage it's not fixed.
01:19:40.000 | So if you want to turn it off, you just call resetRFSamples, and that returns it back to
01:19:46.440 | what it was.
01:19:53.220 | So in practice, when I'm doing interactive machine learning using random forests in order
01:20:03.380 | to explore my model, explore hyperparameters, the stuff we're going to learn in the future
01:20:07.880 | lesson where we actually analyze feature importance and partial dependence and so forth, I generally
01:20:13.440 | use subsets and reasonably small forests because all the insights that I'm going to get are
01:20:22.120 | exactly the same as the big ones, but I can run it in like 3 or 4 seconds rather than
01:20:27.800 | hours.
01:20:30.040 | So this is one of the biggest tips I can give you, and very few people in industry or academia
01:20:36.920 | actually do this.
01:20:38.560 | Most people run all of their models on all of the data all of the time using their best
01:20:43.400 | possible parameters, which is just pointless.
01:20:46.540 | If you're trying to find out which features are important and how are they related to
01:20:49.440 | each other and so forth, having that fourth decimal place of accuracy isn't going to change
01:20:54.860 | any of your insights at all.
01:20:56.800 | So I would say do most of your models on a large enough sample size that your accuracy
01:21:03.360 | is reasonable, when I say reasonable it's like within a reasonable distance of the best
01:21:10.000 | accuracy you can get, and it's taking a small number of seconds to train so that you can
01:21:16.680 | interactively do your analysis.
01:21:19.760 | So there's a couple more parameters I wanted to talk about, so I'm going to call reset_rf_samples
01:21:23.720 | to get back to our full data set, because in this case, at least on this computer, it's
01:21:28.040 | actually running in less than 10 seconds.
01:21:32.480 | So here's our baseline, we're going to do a baseline with 40 estimators, and so each
01:21:40.520 | of those 40 estimators is going to train all the way down until the leaf nodes just have
01:21:45.960 | one sample in them.
01:21:51.800 | So that's going to take a few seconds to run, here we go.
01:21:55.320 | So that gets us a 0.898r^2 on the validation set, or 0.908 on the OOB.
01:22:05.000 | In this case, the OOB is better.
01:22:06.840 | Why is it better?
01:22:07.840 | Well that's because remember our validation set is not a random sample, our validation
01:22:11.800 | set is a different time period, so it's actually much harder to predict a different time period
01:22:19.360 | than this one, which is just predicting random.
01:22:22.180 | So that's why this is not the way around we expected.
01:22:27.360 | The first parameter we can try fiddling with is min_samples_leaf, and so min_samples_leaf
01:22:32.400 | says stop training the tree further when your leaf node has three or less samples in.
01:22:43.720 | So rather than going all the way down until there's one, we're going to go down until there's
01:22:49.200 | three.
01:22:50.200 | So in practice, this means there's going to be like one or two less levels of decision
01:22:54.160 | being made, which means we've got like half the number of actual decision criteria we
01:22:59.760 | have to do, so it's going to train more quickly.
01:23:02.480 | It means that when we look at an individual tree, rather than just taking one point, we're
01:23:07.120 | taking the average of at least three points, that's where we'd expect the trees to generalize
01:23:11.820 | each one a little bit better, but each tree is probably going to be slightly less powerful
01:23:17.560 | on its own.
01:23:19.720 | So let's try training that.
01:23:22.980 | Possible values of min_samples_leaf, I find ones which work well are 1, 3, 5, 10, 25.
01:23:32.840 | I find that kind of range seems to work well, but sometimes if you've got a really big data
01:23:39.000 | set and you're not using the small samples, you might need a min_samples_leaf of hundreds
01:23:46.240 | or thousands.
01:23:47.400 | So you've kind of got to think about how big are your subsamples going through and try
01:23:52.440 | things out.
01:23:53.440 | In this case, going from the default of 1 to 3 has increased our validations at R squared
01:24:00.240 | from 898 to 902, so it's a slight improvement.
01:24:03.360 | And it's going to train a little faster as well.
01:24:07.560 | Something else you can try, and since this worked, I'm going to leave that in, I'm going
01:24:11.840 | to add in max_features = 0.5.
01:24:14.940 | What does max_features do?
01:24:17.560 | The idea is that the less correlated your trees are with each other, the better.
01:24:24.800 | Now imagine you had one column that was so much better than all of the other columns
01:24:31.680 | of being predictive that every single tree you built, regardless of which subset of rows,
01:24:37.000 | always started with that column.
01:24:39.200 | So the trees are all going to be pretty similar, but you can imagine there might be some interaction
01:24:45.240 | of variables where that interaction is more important than that individual column.
01:24:51.720 | So if every tree always fits on the first thing, the same thing the first time, you're
01:24:57.800 | not going to get much variation in those trees.
01:25:00.400 | So what we do is, in addition to just taking a subset of rows, we then at every single
01:25:09.040 | split point take a different subset of columns.
01:25:13.960 | So it's slightly different to the row sampling.
01:25:16.940 | For the row sampling, each new tree is based on a random set of rows.
01:25:22.720 | For column sampling, every individual binary split we choose from a different subset of
01:25:29.000 | columns.
01:25:30.320 | So in other words, rather than looking at every possible level of every possible column,
01:25:37.600 | we look at every possible level of a random subset of columns.
01:25:43.180 | And each time, each decision point, each binary split, we use a different random subset.
01:25:50.200 | How many?
01:25:51.200 | Well, you get to pick.
01:25:52.800 | Point 5 means randomly choose half of them.
01:25:57.320 | The default is to use all of them.
01:26:00.960 | There's also a couple of special values you can use here.
01:26:07.240 | As you can see in max_features, you can also pass in square root to get square root of
01:26:11.520 | features, or log_2 to get log_2 of features.
01:26:15.140 | So in practice, good values I found are range from 1, 0.5, log_2, or square root.
01:26:24.600 | That's going to give you a nice bit of variation.
01:26:27.880 | Can somebody pass it to Daniel?
01:26:32.320 | So just to clarify, does that just break it up smaller each time it goes through the tree,
01:26:37.840 | or is it just taking half of what's left over and hasn't been touched each time?
01:26:42.240 | There's no such thing as what's left over.
01:26:44.720 | After you've split on year made less than or greater than 1984, year made is still there.
01:26:51.280 | So later on you might then split on year made less than or greater than 1989.
01:26:56.800 | So it's just each time, rather than checking every variable to see where it's best split
01:27:00.920 | is, you just check half of them.
01:27:03.440 | And so the next time you check a different half.
01:27:07.160 | But I mean like in terms as you get further to the leafs, you're going to have less options,
01:27:15.280 | right?
01:27:16.280 | No, you're not.
01:27:17.280 | You never remove the variables.
01:27:18.560 | You can use them again and again and again because you've got lots of different split
01:27:21.720 | points.
01:27:24.440 | So imagine for example that the relationship was just entirely linear between year made
01:27:29.560 | and price.
01:27:30.560 | Then in practice to actually model that, your real relationship is year made versus price.
01:27:40.580 | But the best we could do would be to first of all split here, and then to split here
01:27:46.560 | and here, right?
01:27:48.440 | And like split and split and split.
01:27:49.840 | So even if they're binary, most random forest libraries don't do anything special about
01:27:58.120 | that.
01:27:59.120 | They just kind of go try this variable, oh it turns out there's only one level left.
01:28:03.560 | So yeah, definitely they don't do any clever bookkeeping.
01:28:12.400 | So if we add max_features=0.5, it goes up from 9.01 to 9.06.
01:28:18.880 | So that's better still.
01:28:20.440 | And so as we've been doing this, you've also hopefully noticed that our root mean squared
01:28:23.600 | error of log_price has been dropping on our validation set as well.
01:28:28.560 | And so it's now down to 0.2286.
01:28:33.560 | So how good is that?
01:28:35.320 | So like our totally untuned random forest got us in about the top 25%.
01:28:40.480 | Now remember, our validation set isn't identical to the Kaggle test set, and this competition
01:28:47.200 | unfortunately is old enough that you can't even put in a kind of after-the-time entry
01:28:54.120 | to find out how you would have gone.
01:28:55.480 | So we can only approximate how we could have gone, but generally speaking it's going to
01:28:59.680 | be a pretty good approximation.
01:29:01.460 | So 2286, here is the competition, here's the public leaderboard, 2286, 14th or 15th place.
01:29:16.960 | So roughly speaking, it looks like we would be about in the top 20 of this competition
01:29:23.160 | with basically a totally brainless random forest with some totally brainless minor hyperparameter
01:29:28.880 | tuning.
01:29:33.760 | This is kind of why the random forest is such an important, not just first step, but often
01:29:39.040 | only step in machine learning.
01:29:40.960 | Because it's kind of hard to screw it up, even when we didn't tune the hyperparameters,
01:29:45.840 | we still got a good result.
01:29:47.840 | And then a small amount of hyperparameter tuning got us a much better result.
01:29:51.120 | And so any kind of model, and I'm particularly thinking of linear type models, which have
01:29:58.480 | a whole bunch of statistical assumptions and you have to get a whole bunch of things right
01:30:02.240 | before they start to work at all, can really throw you off track because they give you
01:30:08.000 | totally wrong answers about how accurate the predictions can be.
01:30:11.520 | But also the random forest, generally speaking, they tend to work on most data sets most of
01:30:18.720 | the time with most sets of hyperparameters.
01:30:21.240 | So for example, we did this thing with our categorical variables.
01:30:32.000 | In fact let's take a look at our tree.
01:30:38.480 | Look at this, f_i_product_class_desk < 7.5.
01:30:46.760 | What does that mean?
01:30:48.280 | So f_i_product_class_desk, here are some examples of that column.
01:31:02.480 | So what does it mean to be less than or equal to 7?
01:31:05.640 | Well we'd have to look at .cat.categories to find out.
01:31:12.400 | And so it's 0, 1, 2, 3, 4, 5, 6, 7.
01:31:17.040 | So what it's done is it's created a split where all of the backhoe loaders and these
01:31:22.320 | three types of hydraulic excavator enter in one group and everything else is in the other
01:31:26.840 | group.
01:31:28.400 | So that's weird, like these aren't even in order.
01:31:34.720 | We could have made them in order if we had bothered to say the categories have this order,
01:31:39.800 | but we hadn't.
01:31:41.400 | So how come this even works?
01:31:45.160 | Because when we turn it into codes, this is actually what the random forest sees.
01:32:01.240 | And so imagine, to think about this, the only thing that mattered was whether it was a hydraulic
01:32:07.880 | excavator of 0-2 metric tons and nothing else mattered, so it has to pick out this single
01:32:14.120 | level.
01:32:15.600 | Well it can do that because first of all it could say, okay let's pick out everything less
01:32:20.640 | than 7 versus greater than 7 to create this as one group and this as another group.
01:32:28.520 | And then within this group, it could then pick out everything less than 6 versus greater
01:32:33.040 | than 6, which is going to pick out this one item.
01:32:36.400 | So with two split points, we can pull out a single category.
01:32:41.560 | So this is why it works, because the tree is infinitely flexible, even with a categorical
01:32:48.280 | variable, if there's particular categories which have different levels of price, it can
01:32:54.840 | gradually zoom in on those groups by using multiple splits.
01:32:59.640 | Now you can help it by telling it the order of your categorical variable, but even if
01:33:04.400 | you don't, it's okay, it's just going to take a few more decisions to get there.
01:33:09.840 | And so you can see here it's actually using this product class desk quite a few times.
01:33:17.120 | And as you go deeper down the tree, you'll see it used more and more.
01:33:22.760 | Whereas in a linear model, or almost any kind of other model, certainly any non-tree model
01:33:29.000 | pretty much, encoding a categorical variable like this won't work at all because there's
01:33:34.360 | no linear relationship between totally arbitrary identifiers and anything.
01:33:41.660 | So these are the kinds of things that make random forests very easy to use and very resilient.
01:33:47.640 | And so by using that, we've gotten ourselves a model which is clearly world-class at this
01:33:57.000 | point already.
01:33:58.000 | It's probably well in the top 20 of this Kaggle competition.
01:34:01.620 | And then in our next lesson, we're going to learn about how to analyze that model to learn
01:34:09.680 | more about the data to make it even better.
01:34:13.800 | So this week, try and really experiment.
01:34:18.440 | Have a look inside, try and draw the trees, try and plot the different errors, try maybe
01:34:24.400 | using different data sets to see how they work, really experiment to try and get a sense
01:34:29.800 | and maybe try to replicate things like write your own R^2, write your own versions of some
01:34:36.240 | of these functions, see how much you can really learn about your data set about the random
01:34:41.360 | forest.
01:34:42.360 | Great, see you on Thursday.
01:34:43.840 | Bye.