Lesson 7: Practical Deep Learning for Coders
00:00:00.000 | This is week 7 of 7, although in a sense it's week 7 of 14.
00:00:09.380 | No pressure and no commitment, but how many of you are thinking you might want to come
00:00:14.880 | back for part 2 next year?
00:00:17.100 | That's great.
00:00:18.100 | When we started this, I thought if 1 in 5 people come back for part 2, I'd be happy.
00:00:26.200 | So that's the best thing I've ever seen, thank you so much.
00:00:31.140 | In that case, that's perfect because today I'm going to show you, and I think you'll
00:00:39.480 | be surprised and maybe a little overwhelmed, at what you can do with this little set of
00:00:45.260 | tools you've learned already.
00:00:47.600 | So this is going to be part 1 of this lesson, it's going to be a whirlwind tour of a bunch
00:00:55.720 | of different architectures, and different architectures are not just different because
00:01:00.840 | some of them will be better at doing what they're doing, but some of them will be doing
00:01:05.680 | different things.
00:01:07.880 | And I want to set your expectations and say that looking at an architecture and understanding
00:01:17.040 | how it does what it does is something that took me quite a few weeks to just get an intuitive
00:01:22.280 | feel for it, so don't feel bad, because as you'll see, it's like unprogrammed, it's like
00:01:28.920 | we're going to describe something we would think would be great if the model knew how
00:01:34.040 | to do it, and then we'll say fit, and suddenly the model knows how to do it, and we'll look
00:01:38.920 | at it and decide how they're going to do that.
00:01:42.720 | The other thing I want to mention is, having said that, everything we're about to see uses
00:01:47.920 | only the things we've done. In fact, in the first half we're only going to use CNNs. There's
00:01:53.360 | going to be no cropping of images, there's going to be no filtering, there's going to
00:01:58.760 | be nothing hand-tuned, it's just going to be a bunch of convolutional ordains, but we're
00:02:04.920 | going to put them together in some interesting ways.
00:02:10.720 | So let me start with one of the most important developments of the last year or two, which
00:02:19.720 | is called ResNet. ResNet won the 2015 ImageNet competition. I was delighted that it won it
00:02:29.240 | because it's an incredibly simple and intuitively understandable concept, and it's very simple
00:02:37.440 | to implement. In fact, what I would like to do is to show you.
00:02:49.200 | So let me describe as best as I can how ResNet works. In fact, before I describe how it works,
00:02:57.460 | I will show you why you should care that it works. So let's for now just put aside the
00:03:04.080 | idea that there's a thing called ResNet. It's another architecture, a lot like VGG, that's
00:03:08.580 | used for image classification or other CNN type things. It's actually broader than just
00:03:15.840 | image classification. And we use it just the same way as we use the VGG-16 class you're
00:03:20.080 | familiar with. We just say create something in ResNet, and again there's different size
00:03:29.080 | of ResNet. I'm going to use 50 because it's the smallest one and it works super well.
00:03:34.640 | I've started adding a parameter to my versions of these networks. I've added it to the new
00:03:40.240 | VGG as well, which is include_top. It's actually the same as the Keras author who started doing
00:03:45.960 | his models. Basically the idea is that if you say include_top = false, you don't have
00:03:52.360 | to go model.pop afterwards to remove the layers if you want to fine-tune. Include_top = false
00:03:58.280 | means only include the convolutional layers basically, and I'm going to stick my own final
00:04:07.640 | classification layers on top of that. So when I do this, it's not going to give me the last
00:04:14.080 | few layers. Maybe the best way to explain that is to show you when I create this network,
00:04:24.320 | I've got this thing at the end that says if include_top, and if so then we add the last
00:04:29.760 | few layers with this last dense fully connected layer that makes it just image net things
00:04:33.860 | that's from your thousand categories. If we're not include_top, then don't add these additional
00:04:38.400 | layers. So this is just a thing which means you can load in a model which is specifically
00:04:45.700 | designed for fine-tuning. It's a little shortcut. And as you'll see shortly, it has some really
00:04:50.160 | helpful properties. We're in the Cats and Dogs competition here. The winner of the Cats and
00:04:58.600 | Dogs competition had an accuracy of 0.985 on the private leaderboard and 0.989 on the
00:05:04.840 | private leaderboard. We use this ResNet model in the same way as usual. We grab our batches,
00:05:11.560 | we can pre-compute some features. And in fact, every single CNN model I'm going to show you,
00:05:17.600 | we're always going to pre-compute the convolutional features. So everything we see today will
00:05:22.040 | be things you can do without retraining any of the convolutional layers. So you'll see
00:05:26.720 | pretty much everything I train will train in a small number of seconds. And that's because
00:05:32.160 | in my experience when you're working with photos, it's almost never helpful to retrain
00:05:37.560 | the convolutional layers.
00:05:40.640 | So we can stick something on top of our ResNet in the usual way. And we can say go ahead
00:05:50.760 | and compile and fit it. And in 48 seconds, it's created a model with a 0.986 accuracy,
00:05:59.840 | which is the winner of the private leaderboard or the second winner of the private leaderboard.
00:06:05.380 | So that's pretty impressive. I'm going to show you how this works in a moment. ResNet's actually
00:06:12.740 | designed to not be used with a standard bunch of dense layers, but it's designed to be used
00:06:18.400 | with something called a global average pooling layer, which I'm about to describe to you.
00:06:23.340 | So for now, let me just show you what happens if instead of the previous model, I use this
00:06:27.160 | model, which has 3 layers, and compile and fit it, I get 0.9875 in 3 seconds. In fact,
00:06:40.400 | I can even tell it that I don't want to use 224x224 images but I want to use 400x400 images.
00:06:50.740 | And if I do that, and then I get batches, I say I want to create 400x400 images, and
00:06:58.220 | create those features, compile and fit, I get 99.3. So this is kind of off the charts
00:07:06.040 | to go from somewhere around 98.5 to 99.3, we're reducing the amount of error by 3rd to 1/2.
00:07:15.780 | So this is why you should be interested in ResNet. It's incredibly accurate. We're using
00:07:22.260 | it for the thing it's best at, which was originally, this ResNet was trained on ImageNet and the
00:07:30.540 | Dogs and Cats competition looks a lot like ImageNet images. They're single pictures of
00:07:35.420 | a single thing that's kind of reasonably large in the picture, they're not very big images
00:07:40.020 | on the whole. So this is something which this ResNet approach is particularly good for.
00:07:47.180 | So I do actually want to show you how it works, because I think it's fascinating and awesome.
00:07:51.920 | And I'm going to stick to the same approach that we've used so far when we've talked about
00:07:58.300 | architectures, which is that we have any shape represents a matrix of activations, and any
00:08:14.100 | arrow represents a layer operation. So that is a convolution or a dense layer with an activation
00:08:21.300 | function. ResNet looks a lot like VGG. So I've mentioned that there's some part of the model
00:08:32.340 | down here that we're not going to worry about too much. We're kind of halfway through the
00:08:37.020 | model and there's some hidden activation layer that we've got too. With VGG, the approach
00:08:46.020 | is generally to go, the layers are basically a 3x3 conv, that gives you some activations,
00:08:55.540 | another 3x3 conv, that gives you some activations, another 3x3 conv, that gives you some activations,
00:09:01.220 | and then from time to time, it also does a max pulling. So each of these is representing
00:09:09.220 | a conv layer. ResNet looks a lot like this. In fact, it has exactly that path, which is
00:09:18.820 | a bunch of conv and values on top of each other. But it does something else, which is
00:09:25.980 | this bit that comes out, and remember, when we have two arrows coming into a shape, that
00:09:38.220 | means we're adding things.
00:09:40.100 | You'll notice here, in fact, there's no shapes anywhere on the way here. In fact, this arrow
00:09:49.940 | does not represent a conv, it does not represent a dense layer, it actually represents identity.
00:09:56.060 | In other words, we do nothing at all. And this whole thing here is called a ResNet block.
00:10:08.700 | And so ResNet, basically if we represented a ResNet block as a square, ResNet is just
00:10:13.460 | a whole bunch of these blocks basically stacked on top of each other. And then there's an
00:10:19.300 | input which is the input data, and then the output, of course it's yet.
00:10:26.980 | Another way of looking at this is just to look at the code. I think the code is nice
00:10:32.500 | and kind of intuitive to understand. Let's take a look at this thing, they call it an
00:10:41.140 | identity block. So here's the code for what I just described, it's here. You might notice
00:10:49.180 | that everything I just selected here looks like a totally standard VGG block. I've got
00:10:55.660 | a conv2d, a batch normalization, and an activation function. I guess it looks like our improved
00:11:02.740 | VGG because it's got batch normalization. Another conv2d, another batch norm, but then this
00:11:12.580 | is the magic that makes it ResNet, this single line of code. And it does something incredibly
00:11:17.340 | simple. It takes the result, all those 3 convolutions, and it adds it to our original input.
00:11:29.100 | So normally, we have the output of some block is equal to a convolution of some input to
00:11:50.500 | that block. But we're doing something different. We're saying the output to a block, so let's
00:12:00.500 | call this "hidden state at time t + 1" is equal to the convolutions of hidden state
00:12:08.380 | at time t plus the hidden state at time t. That is the magic which makes it ResNet.
00:12:19.860 | So why is it that that can give us this huge improvement in the state of the art in such
00:12:28.820 | a short period of time? And this is actually interestingly something that is somewhat controversial.
00:12:38.020 | The authors of this paper that originally developed this describe it a number of ways.
00:12:45.060 | They basically gave 2 main reasons. The first is they claim that you can create much deeper
00:12:50.700 | networks this way, because when you're backpropagating the weights, backpropagating through an identity
00:12:57.060 | is easy. You're never going to have an explosion of gradients or an explosion of activations.
00:13:03.940 | And indeed, this did turn out to be true. The authors created a ResNet with over a thousand
00:13:10.860 | layers and got very good results. But it also turned out to be a bit of a red herring. A
00:13:18.420 | few months ago, some other folks created a ResNet which was not at all deep. It had like
00:13:25.500 | 40 or 50 layers, but instead it's very wide and had a lot of activations. And that did
00:13:30.460 | even better. So it's one of these funny things that seems even the original authors might
00:13:36.020 | have been wrong about why they built what they built.
00:13:39.140 | The second reason why they built what they built seems to have stood the test of time,
00:13:44.180 | which is that if we take this equation and rejig it, let's subtract that from both sides.
00:13:51.180 | And that gives us h(t) + 1 - h(t). So the hidden activations at the next time period
00:13:59.620 | minus the hidden activations the previous time period equals (and I'm going to replace
00:14:04.380 | all this with R for ResNet block) a convolution of convolution of convolution applied to the
00:14:13.740 | previous hidden state.
00:14:15.460 | When you write it like that, it might make you realize something, which is all of the
00:14:26.420 | weights we're learning are here. So we're learning a bunch of weights which allow us
00:14:31.740 | to make our previous guess as to the predictions a little bit better. We're basically saying
00:14:40.140 | let's take the previous predictions we've got, however we got to them, and try and build
00:14:44.980 | a set of things which makes them a little bit better.
00:14:47.980 | In statistics, this thing is called the residual. The residual is the difference between the
00:14:53.420 | thing you're trying to predict and your actions. So what we basically did here was they did
00:15:01.700 | design an architecture which without us having to do anything special automatically learns
00:15:07.740 | how to model the residuals. It learns how to build a bunch of layers which continually
00:15:12.420 | slightly improve the previous answer.
00:15:14.780 | For those of you who have more of a machine learning background, you would recognize this
00:15:20.420 | as essentially being boosting. Boosting refers to the idea of having a bunch of models where
00:15:28.420 | each model tries to predict the errors of the previous model. If you have a whole chain
00:15:33.240 | of those, you can then predict the errors on top of the errors, and add them all together,
00:15:38.460 | and boosting is a way of getting much improved ensembles.
00:15:43.780 | So this ResNet is not manually doing boosting, it's not manually doing anything. It's just
00:15:50.300 | this single one extra line of code. It's all in the architecture.
00:15:58.660 | A question about dimensionality. I would have assumed that by the time we were close to
00:16:04.980 | output, the dimensions would be so different that element-wise addition wouldn't be possible
00:16:09.960 | between the last layer and the first layer.
00:16:11.980 | It's important to note that this input tensor is the input tensor to the block. So you'll
00:16:19.940 | see there's no max pooling inside here, so the dimensionality remains constant throughout
00:16:27.820 | all of these lines of code, so we can add them up. And then we can do our strides or
00:16:32.580 | max pooling, and then we do another identity block. So we're only adding that to the input
00:16:37.780 | of the block, not the input of the original image.
00:16:40.900 | And that's what we want. We want to say the input to each block is our best prediction
00:16:47.820 | so far is effectively what it's doing.
00:16:50.740 | Then qualitatively, how does this compare to dropout?
00:16:53.780 | In some ways, in most ways, it's unrelated to dropout. And indeed you can add dropout
00:17:02.180 | to ResNet. At the end of a ResNet block, after this merge, you can add dropout. So ResNet
00:17:09.420 | is not a regularization technique per se. Having said that, it does seem to have excellent
00:17:17.580 | generalization characteristics, and if memory serves correctly, I just searched this entire
00:17:24.180 | code base for dropout, and it didn't appear. So the image network didn't use any dropout,
00:17:29.140 | they didn't find it as necessary. But this is very problem-dependent. If you have only
00:17:34.900 | a small amount of data, you may well need dropout. And I explained another reason that
00:17:40.700 | we don't need dropout for this in just a moment.
00:17:43.580 | In fact, I'll do that right now, which is, remember what I did here at the end was I
00:17:51.180 | created a model which had a special kind of layer called a global average boolean layer.
00:18:00.140 | This is the next key thing I teach you about today. It's a really important concept, it's
00:18:04.900 | going to come up a couple more times during today's class.
00:18:09.820 | Let's describe what this is. It's actually very simple. Here is the output of the pre-computed
00:18:23.460 | resume. On the 224x224, the pre-computed residual blocks give us a 13x13 output with 2048.
00:18:49.100 | One way of thinking about this would be to say, well, each of these 13x13 blocks could
00:18:57.180 | potentially try to say how catty or how doggy edge one of those 13 blocks.
00:19:03.940 | And so rather than max pooling, which is take the maximum of that grid, we could do average
00:19:10.980 | pooling. Across those 13x13 areas, what is the average amount of doggyness in each one,
00:19:20.100 | what is the average amount of cattyness in each one?
00:19:25.300 | And that's actually what global average pooling does. What global average pooling does is it's
00:19:29.980 | identical to average pooling 13x13 because the input to it is 13x13. So in other words,
00:19:49.060 | whatever the input to a global average pooling layer is, it will take all of the x and all
00:19:55.020 | of the y coordinates and just take the average for every one of these 2048 georges.
00:20:02.960 | So let's take a look here. So what this is doing is it's taking an input of 2048 by 13x13
00:20:17.860 | and it's going to return an output which is just a single vector of 2048. And that vector
00:20:24.460 | is, on average, how much does this whole image have of each of those 2048 features.
00:20:33.740 | And because ResNet was originally trained with global average pooling 2D, so you can
00:20:39.900 | see that this is the ResNet code. In fact, it's 7x7. So this was actually written before
00:20:57.740 | the global average pooling 2D layer existed, so they just did it manually, they just put
00:21:02.660 | an average pooling 7x7 here. So because ResNet was trained originally with this layer here,
00:21:16.300 | that means that it was trained such that the last identity block was basically creating
00:21:22.180 | features that were designed to be average together. And so that means that when we used
00:21:28.720 | this tiny little architecture, we got the best results because that was how ResNet was
00:21:35.700 | originally designed to be used.
00:21:38.220 | If you had a wider network without the input fed forward to the output activation, couldn't
00:21:43.500 | you get the same result? The extra activations in the wider network could pass the input
00:21:48.620 | all the way through all the layers.
00:21:50.740 | Well, you can in theory have convolutional filters that don't do anything, but the point
00:22:03.620 | is having to learn that is learning lots and lots of filters designed to learn that. And
00:22:11.260 | so maybe the best way I can describe this is everything I'm telling you about architectures
00:22:18.180 | is in some ways irrelevant. You could create nothing but dense layers at every level of
00:22:23.900 | your model. And dense layers have every input connected to every output, so every architecture
00:22:31.660 | I'm telling you about is just a simplified version of that, we're just deleting some
00:22:36.540 | of those.
00:22:39.220 | But it's really helpful to do that. It's really helpful to help our SGD optimizer by giving
00:22:47.660 | it, by making it so that the default thing it can do is the thing we want. So yes, in
00:22:54.460 | theory, a convNet or a native fully connected net could learn to do the same thing that
00:22:59.540 | ResNet does. In practice, it would take a lot of parameters for it to do so, and time to
00:23:08.180 | do so, and so this is why we care about architectures. In practice, having a good architecture makes
00:23:14.980 | a huge difference. That's a good question, very good question.
00:23:22.180 | Another question, would it be fair to say that if VGG was trained with average pooling,
00:23:27.340 | it would yield better results?
00:23:29.500 | I'm not sure, so let's talk about that a little bit. One of the reasons, or maybe the main
00:23:38.900 | reason that ResNet didn't need to drop out is because we're using global average pooling,
00:23:44.940 | there's a hell of a lot less parameters in this model. Remember, the vast majority of
00:23:51.940 | the parameters in the model are in the dense layers, because if you've got 'm' inputs and
00:23:56.700 | 'm' outputs, you have 'n' times 'm' connections.
00:24:00.560 | So in VGG, I can't quite remember, but that first dense layer has something like 300 million
00:24:06.780 | inputs, because it had every possible feature of the convolutional layer by each of the
00:24:16.060 | 3, by each convolutional layer by every one of the 4,006 outputs, so it just created a
00:24:21.020 | lot of features and made it very easy to fit.
00:24:25.540 | With global average pooling and indeed not having any dense layers, we have a lot less
00:24:31.460 | parameters, so it's going to generalize better. It also generalizes better because we're treating
00:24:37.420 | every one of those 7x7 or 13x13 areas in the same way. We're saying how doggy or catty
00:24:46.540 | are each of these, we're just averaging them. It turns out that these global average pooling
00:24:53.760 | layer models do seem to generalize very well, and we're going to be seeing more of that in
00:24:58.260 | a moment.
00:24:59.260 | Why do we use global average pooling instead of max pooling?
00:25:04.620 | You wouldn't want to max pool over, well, it depends. You can try both. In this case, the
00:25:31.920 | same thing is the same thing. The same thing is the same thing. On the other hand, the
00:25:45.800 | fisheries competition, the fish is generally a very small part of each image. So maybe in
00:25:52.780 | the fisheries competition you should use a global max pooling layer, give it a try and
00:25:58.620 | tell us how it goes. Because in that case, you actually don't care about all the parts
00:26:02.700 | of the image, which have nothing to do with fish. So that would be a very interesting thing
00:26:08.460 | to try.
00:26:11.900 | ResNet is very powerful, but it has not been studied much at all for transfer learning.
00:26:26.540 | This is not to say it won't work well for transfer learning, I just literally haven't
00:26:30.740 | found a single paper yet where somebody has analyzed its effectiveness for transfer learning.
00:26:37.580 | And to me, 99.9999% of what you will work on will be transfer learning. Because if you're
00:26:44.700 | not using transfer learning, it means you're looking at a data set that is so different
00:26:48.180 | to anything that anybody has looked at before that none of the pictures in any model was
00:26:52.420 | remotely helpful for you, which is going to be rare.
00:27:02.220 | Particularly all of the work I've seen on transfer learning, both in terms of capital winners
00:27:07.180 | and in terms of papers, uses VGG. And I think one of the reasons for that is, as we talked
00:27:12.620 | about in lesson 1, the VGG architecture really is designed to create layers of gradually
00:27:23.980 | increasing semantic complexity. All the work I've seen on visualizing layers tends to use
00:27:30.980 | VGG or something similar to that as well, like that Matt Seiler stuff we saw, or those
00:27:35.260 | Joseph Nusinski videos we saw. And so we've seen how the VGG network, those kinds of networks,
00:27:42.540 | create gradually more complex representations, which is exactly what we want to transfer.
00:27:48.660 | Because let's just say, how different is this new domain to the previous domain, and then
00:27:55.580 | we can pick a layer far enough back, we can try a few that the features seem to work well.
00:28:03.260 | So for that reason, we're going to go back to looking at VGG for the rest of these architectures.
00:28:09.980 | And I'm going to look at the fisheries competition. The fisheries competition is actually very
00:28:17.300 | interesting. The pictures are from a dozen boats, and each one of these boats has a fixed
00:28:26.940 | camera, and they can do daytime and nighttime shots. And so every picture has the same basic
00:28:35.540 | shape and structure for each of the 12 boats, because it's a fixed camera. And then somewhere
00:28:40.500 | in there, most of the time, there's one or more fish. And your job is to say what kind
00:28:45.340 | of fish is it? The fish are pretty small.
00:28:51.020 | And so one of the things that makes this interesting is that this is the kind of somewhat weird,
00:28:58.540 | kind of complex, different thing to ImageNet, which is exactly the kind of stuff that you're
00:29:04.260 | going to have to deal with any time you're doing some kind of computer vision problem
00:29:08.180 | or any kind of CNN problem. It's very likely that the thing you're doing won't be quite
00:29:12.980 | the same as what other academics have been looking at. So trying to figure out how to
00:29:16.300 | do a good job of the fisheries competition is a great example.
00:29:23.080 | So when I started on the fisheries competition, I just did the usual thing, which was to create
00:29:26.580 | a VGG-16 model, fine-tuned it to have just 8 outputs, because we had to say which of
00:29:32.260 | 8 types of fish do we see in it. And then I, as per usual, pre-computed the convolutional
00:29:41.740 | layers using the pre-trained VGG network, and then everything after that I just used
00:29:46.760 | those pre-computed convolutional layers. And as per usual, the first thing I did was to
00:29:51.380 | stick a few dense layers on top and see how that goes.
00:29:56.740 | So the nice thing about this is you can see each epoch takes less than a second to run.
00:30:02.340 | So when people talk about needing lots of data or lots of time, it's not really true
00:30:08.140 | because for most stuff you do in real life, you're only using pre-computed convolutional
00:30:12.260 | features. And in our validation set, we get an accuracy of 96.2%, a percentage loss of
00:30:20.420 | 0.18. That's pretty good, which seems to be recognising the fish pretty well.
00:30:28.060 | But here's the problem. There is all kinds of data leakage going on, and this is one
00:30:35.380 | of the most important concepts to understand when it comes to building any kind of model
00:30:45.020 | or any kind of machine learning project leakage.
00:30:51.780 | There was a paper, I think it actually won the KDD Best Paper Award a couple of years
00:30:57.420 | ago from Claudia Prerich and some of her colleagues, which studied data leakage. Data leakage occurs
00:31:05.500 | when something about the target you're trying to predict is encoded in the things that you're
00:31:12.980 | predicting with, but that information is either not going to be available or it won't be helpful
00:31:19.140 | in practice when you're going to use the model.
00:31:22.740 | For example, in the fisheries competition, different boats fish in different parts of
00:31:29.380 | the sea. Different parts of the sea have different fish in them, and so in the fisheries competition,
00:31:36.820 | if you just use something representing which boat did the image come from, you can get
00:31:43.340 | a pretty good, accurate validation set result. What I mean by that, for example, is here's
00:31:52.060 | something which is very cheeky. This is a list of the size of each photo, along with
00:32:00.780 | how many times that appears. You can see it's gone through every photo and opened it using
00:32:08.020 | PIL, which is the Python imaging library, and greater the size. You can see that there's
00:32:13.540 | basically a small number of sizes that appear.
00:32:16.580 | It turns out that if you create a simple linear model that says any image of size 1192 x 670,
00:32:27.080 | what kind of fish is that? Anything with 1280 x 720, what kind of fish is that? You get
00:32:31.700 | a pretty accurate model because these are the different ships. The different ships have
00:32:37.820 | different cameras and different cameras have different resolutions. This isn't helpful
00:32:41.860 | in practice because what the fisheries people actually wanted to do was to use this to find
00:32:46.460 | out when people are illegally or accidentally overfishing or fishing in the wrong way. So
00:32:54.060 | if they're bringing up dolphins or something, they wouldn't know about it.
00:32:58.260 | So any model that says I know what kind of fish this is because I know what the boat
00:33:02.500 | is is entirely useless. So this is an example of leakage. In this particular paper I mentioned,
00:33:14.260 | the authors looked at machine learning competitions and discovered that over 50% of them had some
00:33:20.300 | kind of data leakage. I spoke to Claudia after she presented that paper, and I asked her
00:33:28.500 | if she thought that regular machine learning projects in inside companies would have more
00:33:33.700 | or less leakage than that, and she said a lot more. In competitions, people have tried
00:33:44.100 | really hard to clean up the data ahead of time because they know that lots and lots of
00:33:47.140 | people are going to be looking at it. And if there is leakage, you're almost certain
00:33:50.900 | that somebody's going to find it because it's a competition. Whereas if you have leakage
00:33:55.260 | in your data set, it's very likely you won't even know about it until you try to put the
00:34:00.580 | model into production and discover that it doesn't work as well as you thought it would.
00:34:04.820 | Oh, and I was just going to add that it might not even help you in the competition if your
00:34:11.460 | test set is brand new boats that weren't in your training set.
00:34:17.940 | So let's talk about that. So trying to win a Kaggle competition and trying to do a good
00:34:28.580 | job is somewhat independent. So when I'm working on Kaggle, I focus on trying to win a Kaggle
00:34:34.740 | competition. I have a clear metric and I try to optimize the metric. And sometimes that
00:34:39.620 | means finding leakage and taking advantage of it.
00:34:43.220 | So in this case, step number 1 for me in the fisheries competition was to say, "Can I take
00:34:48.580 | advantage of this leakage?" I want to be very clear. This is the exact opposite of what
00:34:53.820 | you would want to do if you were actually trying to help the fisheries people create
00:34:57.060 | a good model. Having said that, there's $150,000 at stake and I could donate that to the Fred
00:35:02.660 | Hollis Foundation and get lots of people their site back. So winning this would be good.
00:35:08.020 | So let me show you how I try to take advantage of this leakage, which is totally legal in
00:35:13.660 | a Kaggle competition and see what happened. And then I'll talk more about Rachel's issue
00:35:21.160 | after that.
00:35:22.260 | So the first thing I did was I made a list for every file of how big it was and what
00:35:27.380 | the image dimensions were. And I did that for the validation of the training set. I
00:35:33.180 | normalized them by subtracting the main, divided by the standard deviation. And then I created
00:35:38.260 | an almost exact copy of the previous model I showed you, this one. But this time, rather
00:35:45.820 | than using the sequential API, I used the functional API. But other than that, this is almost identical.
00:35:52.620 | The only difference is in this line, what I've done is I've taken not just the input which
00:36:03.700 | is the output of the last convolutional layer of my BGG model, but I have a second input.
00:36:11.300 | And the second input is what size image is it. I should mention I have one-hot encoded
00:36:22.420 | those image sizes, so they're treated as categories.
00:36:27.660 | So I now have an additional input. One is the output of the BGG convolutional layer.
00:36:33.620 | One is the one-hot encoded image size. I batch-monolized that, obviously. And then right at the very
00:36:41.660 | last step, I can catenate the two together. So my model is basically a standard last few
00:36:51.740 | layers of BGG model, so three dense layers. And then I have my input, and then I have
00:37:04.180 | another input. It ended up being something I think I catenated, and that creates an output.
00:37:13.900 | So what this can do now is that the last dense layer can learn to combine the image features
00:37:22.340 | along with this metadata. This is useful for all kinds of things other than taking advantage
00:37:29.860 | in a dastardly way of linkage. For example, if you were doing a collaborative free model,
00:37:36.740 | you might have information about the user, such as their age, their gender, their favorite
00:37:44.300 | genres, and they asked for a survey. This is how you incorporate that kind of metadata
00:37:51.020 | into a standard neural layer.
00:37:55.820 | So I batch the two together and run it. Initially it's looking encouraging. If we go back and
00:38:02.580 | look at the standard model, we've got 0.84, 0.94, 0.95. This multi-input model is a little
00:38:14.300 | better, 0.86, 0.95, 0.96. So that's encouraging. But interestingly, the model without using
00:38:25.420 | the leakage gets somewhere around 96.5, 97.5, maybe 98. It's kind of all over the place,
00:38:34.860 | which isn't a great sign, but let's say somewhere around 97, 97.5. This multi-input model, on
00:38:42.420 | the other hand, does not get better than that. It's best is also around 97.5. Why is that?
00:38:52.820 | This is very common when people try and utilize metadata in deep learning models. It often
00:38:58.420 | turns out that the main thing you're looking at, in this case the image, already encodes
00:39:04.100 | everything that your metadata has anyway. In this case, yeah, the size of the image
00:39:08.980 | tells us what bode comes from, but you can't just look at the picture and see what bode
00:39:12.020 | comes from. So by the later epochs, the convolutional model has learnt already to figure out what
00:39:17.340 | bode comes from, so the linkage actually turned out not to be helpful anyway.
00:39:22.740 | So it's amazing how often people assume they need to find metadata and incorporate it into
00:39:31.920 | their model, and how often it turns out to be a waste of time. Because the raw, real
00:39:37.820 | data or the audio or the pictures or the language or whatever turns out to encode all of that
00:39:44.540 | in it. Finally, I wanted to go back to what Rachel was talking about, which is what would
00:39:54.380 | have happened if this did work. Let's say that actually this gave us a much better validation
00:40:00.380 | result than the non-linkage model. If I then submitted it to Kaggle and my leaderboard
00:40:07.740 | result was great, that would tell me that I have found leakage, that the Kaggle competition
00:40:13.980 | administrators didn't, and I'm possibly not aware of any competition. Having said that,
00:40:20.140 | the Kaggle competition administrators first and foremost try to avoid leakage, and indeed
00:40:26.860 | if you do try and submit this to the leaderboard, you'll find it doesn't do that great. I haven't
00:40:33.260 | really looked into it yet, but somehow the competition administrators have simplified
00:40:38.540 | some attempt to remove the leakage. The kind of ways that we did that when I was at Kaggle
00:40:45.020 | would be to do things like some kind of stratified sampling where it would say there's way more
00:40:50.300 | alcohol from this ship than this ship. Let's enforce that every ship has to have the same
00:40:56.700 | number, same kind of fish, or something like that. But honestly, it's a very difficult
00:41:06.620 | thing to do, and this impacts a lot more than just machine learning competitions. Every one
00:41:11.820 | of your real-world projects, you're going to have to think long and hard about how can
00:41:17.020 | you replicate real-world conditions in your test set. Maybe the best example I can come
00:41:23.740 | up with is when you put your model into production, it will probably be a few months after you
00:41:29.980 | grabbed the data and trained it. How much has the world changed? Therefore, wouldn't it
00:41:36.780 | be great if instead you could create a test set that had data from a few months later
00:41:41.820 | that you're trying to set? And again, you're really trying to replicate the situation that
00:41:48.140 | you actually have when you put your model into production.
00:41:51.420 | Two questions. One is just a note that they're releasing another test set later on in the
00:41:57.340 | fishery competition. Question, did you do two classifications, one for the boats and one
00:42:04.060 | for the fish? Is that a waste of time?
00:42:08.900 | I have two inputs, not two outputs. My input is the one hot encoded size of the image,
00:42:17.980 | which I assumed is a proxy for the boat ID. Some discussion on the Kaggle forum suggested
00:42:26.220 | that's a really small assumption. We're going to look at multi-output in a moment. In fact,
00:42:32.620 | we're going to do it now.
00:42:39.660 | Another question, can you find a good way of isolating the fish on the images and then
00:42:44.420 | do the classification on that?
00:42:46.860 | Let's do that now, shall we? This is my lunch. All right, multi-output. There's a lot of
00:43:06.420 | nice things about our Kaggle competitions are structured, and one of the things I really
00:43:09.820 | like is that in most of them you can create or find your own data sources as long as you
00:43:17.580 | share them with the community. So one of the people in the fisheries competition has gone
00:43:22.500 | through and by hand put a little square around every fish, which is called annotating the
00:43:29.500 | dataset. Specifically, this kind of annotation is called a bounding box. The bounding box
00:43:36.060 | is a box in which your object only is. Because of the rules of Kaggle, you had to make that
00:43:42.860 | available to everybody in the Kaggle community, which he provided a link on the Kaggle forum.
00:43:48.580 | So I'm going to go ahead and download those. There are a bunch of JSON files that basically
00:43:52.460 | look like this. So for each image, for each fish in that image, it had the height, width,
00:43:58.540 | and x and y. So the details of the code don't matter too much, but I basically just went
00:44:04.620 | and found the largest fish in each image and created a list of them. So I've got now my
00:44:14.580 | training bounding boxes and my validation bounding boxes. For things that didn't have a fish,
00:44:19.260 | I just had 0, 0, 0, 0. This is my empty bounding box here.
00:44:25.060 | So as always, when I want to understand new data, the first thing to do is to look at
00:44:28.900 | it. When we're doing computer vision problems, it's very easy to look at data because it's
00:44:32.420 | pictures. So I went ahead and created this little show bounding box thing, and I tried
00:44:38.980 | it on an image, and here is the fish, and here is the bounding box.
00:44:44.660 | There are two questions, although I didn't know if you wanted to get to a good stopping
00:44:50.300 | point on your thought. One is, adding metadata, is that not useful for both CNNs and RNNs
00:44:58.940 | or just for CNNs? And the other one is, VGG required images all the same size and training.
00:45:08.300 | In the fisheries case, are there different sized images being used for training and how
00:45:13.220 | do you train a model on images with different dimensions?
00:45:16.740 | Regarding whether metadata is useful for RNNs or CNNs, it's got nothing to do with the architecture.
00:45:28.580 | It's entirely about the semantics of the data. If your text or audio or whatever unstructured
00:45:34.940 | data in some way kind of encodes the same information that is in the metadata, the metadata
00:45:41.220 | is unlikely to be helpful. For example, in the Netflix prize, in the early stages of
00:45:47.260 | the competition, people found that it was helpful to link to IMDb and bring in information
00:45:53.500 | about the movies. In later stages, they found it wasn't. The reason why is because in later
00:45:59.500 | stages they had figured out how to extrapolate from the ratings themselves, they basically
00:46:06.580 | contained implicitly all the same information.
00:46:12.180 | How do we deal with different sized images? I'm about to show you some tricks, but so
00:46:17.780 | far throughout this course, we have always resized everything to 224x224. Whenever you
00:46:25.140 | use get matches, I default to resizing into 224x224 because that's what ImageNet did,
00:46:31.260 | with the exception that in my previous ResNet model, I showed you resizing to 400x400 instead.
00:46:39.740 | So far, and in fact everything we're doing this year, we're going to resize everything
00:46:46.200 | to be the same size.
00:46:49.220 | So I had a question about the 400x400, is that because there are two different ResNet
00:46:56.620 | models?
00:46:57.620 | Two different ResNet models? No, it's not. I'll show you how that happened in a moment.
00:47:03.020 | We're going to get to that. It's kind of a little sneak peek at what we're coming to.
00:47:10.700 | So now that we've got these bounding boxes, here is a complexity, both a practical one
00:47:17.140 | and a kaggle one. The kaggle complexity is the rules say you're not allowed to manually
00:47:21.660 | annotate the test set, so we can't put bounding boxes on the test set. So if, for example,
00:47:26.780 | we want to go through and crop out just the fish in every image and just train on them,
00:47:33.340 | this is not enough to do that because we can't do that on the test set because we don't have
00:47:37.860 | bounding boxes.
00:47:38.860 | The practical meaning of this is in practice, they're trying to create an automatic warning
00:47:44.580 | system to let them know if somebody is taking the wrong kind of fish, they don't want to
00:47:50.260 | have somebody drawing a box in every one. So what we're going to do is build a model
00:47:56.620 | that can find these bounding boxes automatically. And how do we do that? It may surprise you
00:48:02.140 | to know we use exactly the same techniques that we've always used. Here is the exact
00:48:08.220 | same model again. This time, as well as having something at the end which has 8 softmax outputs,
00:48:17.900 | we also have something which has 4 linear outputs, i.e. 4 outputs with no activation
00:48:24.500 | function. What this is saying, and then what we're going to do is when we train this model,
00:48:31.140 | we now have 2 outputs, so when we compile it, we're going to say this model has 2 outputs.
00:48:37.700 | One is the 4 outputs with no activation function, one is the 8 softmax. When I compile it, the
00:48:46.060 | first of those I want you to optimize for mean squared error, and the second of those
00:48:50.820 | I want you to optimize for cross entropy loss. And the first of them I want you to multiply
00:48:56.940 | the loss by 0.001 because the mean squared error of finding the location of an image
00:49:04.700 | is going to be a much bigger number than the categorical cross entropy, so it's making
00:49:08.620 | them about the same size. And then when you train it, I want you to use the bounding boxes
00:49:14.500 | as the labels for the first output and the fish types as the labels for the second output.
00:49:22.260 | And so what this is going to have to do is it's going to have to figure out how to come
00:49:25.260 | up with a bunch of dense layers which is capable of doing these 2 things simultaneously. So
00:49:32.500 | in other words, we now have something that looks like this, 2 outputs, 1 input. And notice
00:49:56.820 | that the 2 outputs, you don't have to do it this way, but in the way I've got it, the
00:50:01.460 | outputs both come out, both are just their own dense layer. It would be possible to do
00:50:09.980 | it like this instead. That is to say, each of the 2 outputs could have 2 dense layers
00:50:30.460 | of their own before. In this case though, we're going to talk about the pros and cons.
00:50:36.820 | Both of my last layers are both going to have to use the same set of features to generate
00:50:42.940 | both the bounding boxes and the fish classes. So let's have this go. We'll just go fit as
00:50:50.540 | usual, but now that we have 2 outputs, we get a lot more information. We get the bounding
00:50:56.020 | box loss, we get the fishy classification loss, we get the total loss, which is equal
00:51:04.060 | to 0.001 x bounding box, because you can see this is over 1000 times bigger than this,
00:51:09.020 | so you can see why I've got 0.001. So that's the 2 added together with that way. Then we
00:51:15.660 | get the validation loss, total bounding box loss, and the validation classification loss.
00:51:23.520 | So here is something pretty interesting. The first thing I want to point out is that after
00:51:27.380 | I thin it a little bit, we actually get a much better accuracy. Now maybe this is counter-intuitive,
00:51:38.020 | because we're now saying our model has exactly the same capacity as before. Our previous
00:51:43.100 | dense layer is of size 512. And before, that last layer only had to do one thing, which
00:51:49.060 | is to tell us what kind of fish it was. Now it has to do 2 things. It has to tell us where
00:51:53.580 | the fish is and what kind of fish it is. But yet it's still done better. Why is it done
00:52:01.540 | better? Well the reason it's done better is because by telling it we want you to use those
00:52:06.300 | features to figure out where the fish is, we've given it a hint about what to look for.
00:52:12.540 | We've really given it more information about what to work on. So interestingly, even if
00:52:17.860 | we didn't use the bounding box for anything else, and just threw it away at this point,
00:52:22.300 | we already have a much better model. And do you notice also the model is much more stable
00:52:26.860 | - 97.8, 98, 98, 98.2 - before our loss was all over the place. So by having multiple
00:52:34.840 | outputs, we've created a much more stable, resilient and accurate classification model.
00:52:42.900 | And we also have bounding boxes. The best way to look at how accurate the bounding boxes
00:52:49.980 | are is to look at a picture.
00:52:53.460 | So I do a prediction for the first 10 validation examples. Support to use the validation set
00:53:00.500 | anytime you're looking at how good your model is. This time I slightly increased the function
00:53:07.740 | to show the bounding boxes to now create a yellow box for my prediction and a default
00:53:13.180 | red box for my actual. So I just want to make it very clear here. We haven't done anything
00:53:23.300 | clever. We didn't do anything to program this. We just said there is an output which we have
00:53:33.540 | for outputs that has no activation function. And I want you to use mean squared error to
00:53:41.100 | find a set of weights that would optimize those weights such that the bounding boxes
00:53:46.860 | and your predictions are as close as possible. And somehow it has done that.
00:53:55.740 | So that is to say, very often if you're trying to get a neural net to do something, your
00:54:03.380 | first step before you create some complex programming heuristic thing is just ask the
00:54:08.900 | neural net to do it, and very often it does.
00:54:13.180 | Why do both in the same fitting instead of training the boxes first and feeding that
00:54:18.780 | as input to recognize fishes?
00:54:20.900 | Well, we can, right? But the first thing I want to point out is even then I would still
00:54:26.220 | have the first stage do both at the same time because the more compatible tasks you can
00:54:32.860 | give it, so like where is the fish and what kind of fish it is, the more it can create
00:54:38.540 | an internal representation that is as appropriate as possible.
00:54:43.780 | Now if you now want to go away over the next couple of weeks and crop out these fish and
00:54:50.580 | create the second model, I can almost guarantee you will get into the top ten of this competition.
00:55:00.800 | And the reason I can almost guarantee that is because there was quite a similar competition
00:55:03.740 | on Kaggle last year, or maybe earlier this year, which was trying to identify particular
00:55:11.140 | whales and literally saying which individual whale is it, and all of the top three in that
00:55:20.580 | competition did some kind of bounding box prediction and some kind of cropping and then
00:55:24.620 | modeled a second layer on the cropping features.
00:55:28.300 | Are the four bounding box outputs the vertical and horizontal size of the box and the two
00:55:33.820 | coordinates for its center?
00:55:35.980 | It's whatever we were given, which was not quite that, it was the height, width, x and
00:55:43.100 | y.
00:55:44.100 | So how many of the people in this Kaggle competition are using this sort of model? And if you came
00:55:56.980 | up with this with a bit of tinkering, do you think that you would actually stay in the
00:56:05.700 | top ten or would this just be sort of like an obvious thing that people would tend to
00:56:10.700 | do, and so your ranking would basically drop over time as everyone else incorporates this?
00:56:17.980 | So I'm going to show you a few techniques that I used this week, a few techniques I
00:56:31.420 | used this week, but they're all very basic, they're very normal. We're at a point now
00:56:38.620 | in this $150,000 competition where over 500 people have entered, and I am currently 20th.
00:56:47.420 | So no, the stuff that you're learning in this course is not at all well known. There's never
00:56:55.180 | been an applied learning course before. So the people who are above me in the competition
00:57:01.420 | are people who have figured these things out over time and read lots of papers and studied
00:57:09.420 | and whatever else.
00:57:10.420 | So I definitely think that people in this course, particularly if somebody teamed up
00:57:15.420 | together would have a very good chance of winning this competition because it's a perfect fit
00:57:21.340 | for everything we've been talking about, and particularly you can collaborate on the forums
00:57:26.020 | and stuff like that.
00:57:29.420 | I should mention, I haven't done any cropping yet. This is just using the whole image, which
00:57:36.140 | is clearly not the right way to tackle this. I was actually intentionally trying not to
00:57:42.780 | do too well because I'm going to have to release this to everybody on the Kaggle forum and
00:57:48.860 | say I've done this and here's a notebook because it's $150,000. I didn't want to say here's
00:57:54.540 | a way to get in the top 10 because that's not fair to everybody else.
00:57:58.540 | So I think to answer your question, by the end of the competition, to win one of these
00:58:04.420 | things, you've got to do everything right at every point. Every time you fail, you have
00:58:10.380 | to keep trying again. Tenacity is part of winning these things. I know from experience
00:58:14.740 | the feeling of being on top of the leaderboard and waking up the next day and finding that
00:58:19.140 | five people have passed you. But the thing is, you then know they have found something
00:58:25.060 | that is there and you haven't found it. That's part of what makes competing in the Kaggle
00:58:29.780 | competition so different to doing academic papers or looking at old Kaggle competitions
00:58:35.780 | that are long gone. It's a really great test of your own processes and your own grit. What
00:58:45.740 | you'll probably find yourself doing is repeatedly fucking around with hyperparameters and minor
00:58:53.020 | architectural details because it's just so addictive until eventually you go away and
00:58:58.300 | go 'okay, what's a totally different way of thinking about this problem?'
00:59:03.340 | So I hope some of you will consider seriously investing in putting an hour a day into a
00:59:10.700 | competition because I learned far more doing that than everything else I've ever done in
00:59:16.660 | machine learning. It's totally different to just playing around. And after it, it's something
00:59:25.660 | that every real-world project I've done is greatly better than that experience.
00:59:32.660 | To give you a sense of this, here's number 6. I can't even see that fish, but it's done
00:59:46.260 | a pretty good job. And I think maybe it kind of knows that people tend to float around
00:59:52.220 | where the fish is or something, because it's pretty hard to see. As you can see, this is
00:59:55.860 | just a 224x224 image. So this model is doing a pretty great job, and the amount of time
01:00:02.780 | we took to train was under 10 seconds.
01:00:06.340 | I've got a section here on data augmentation. Before we look at finding things without manually
01:00:32.180 | annotating bounding boxes, I'd like to talk more about different size images.
01:00:36.660 | So let's talk about sizes. Let's specifically talk about in which situations is our model
01:00:46.300 | going to be sensitive to the size of the input, like a pre-trained model with pre-trained weights.
01:00:56.020 | And it's all about what are these layer operations exactly? If it's a dense layer, then there's
01:01:05.420 | a weight going from every input to every output. And so if you have a different sized input,
01:01:14.420 | then that's not going to work at all, because the weight matrix for your dense layer is
01:01:19.020 | just simply of the wrong size. Who knows what it should do. What if it's a convolutional
01:01:26.700 | layer? If it's a convolutional layer, then we have a little set of weights for each 3x3
01:01:37.260 | block for each different feature, and then that 3x3 block is going to be slid over to
01:01:42.060 | create the outputs. If the image is bigger, it doesn't change the number of weights. It
01:01:49.820 | just means that block is going to be slid around more, and the output will be bigger.
01:01:56.300 | A max pooling layer doesn't have any weights. A batch normalization layer simply cares about
01:02:03.340 | the number of weights of the previous layer. So really, when you think about it, the only
01:02:08.700 | layer that really cares about what size your input is is a dense layer. And remember that
01:02:14.820 | with VGG, nearly all of the layers are convolutional layers.
01:02:20.300 | So that's why it is that we can say not only include top = false, we can say not only include
01:02:30.260 | top = false, but we can also choose what size we want. So if you look at my new version
01:02:41.780 | of the VGG model, I've actually got something here that says if size is not equal to 224
01:02:51.740 | then don't try to add the fully connected blocks at all, just return that.
01:03:06.400 | So in other words, if we cut off whatever our architecture is before any dense layers
01:03:12.940 | happen, then we're going to be able to use it on any size input to at least create those
01:03:19.380 | convolutional features.
01:03:30.380 | There's no particular reason it has to be fixed. A dense layer has to be fixed because
01:03:35.380 | a dense layer has a specific weight matrix. And the input to that weight matrix generally
01:03:41.000 | is the flattened out version of the previous convolutional layer, and the size of that
01:03:46.660 | depends on the size of the image. But the convolutional weight matrix simply depends
01:03:53.280 | on the filter size, not on the image size.
01:03:58.540 | So let's try it. And specifically we're going to try building something called a fully convolutional
01:04:06.220 | net, which is going to have no dense layers at all. So the input, as usual, will be the
01:04:12.780 | output of the last VGG convolutional layer. But this time, when we create our VGG 16 model,
01:04:31.660 | we're going to tell it we want it to be 640 by 360.
01:04:35.980 | Now be careful here. When we talk about matrices, we talk about rows by columns. When we talk
01:04:42.880 | about images, we talk about columns by rows. So a 640 by 360 image is a 360 by 640 matrix.
01:04:52.700 | I mention this because I screwed it up. But I knew I screwed it up because I always draw
01:04:57.100 | pictures. So when I drew the picture and saw this little squashed boat, I knew that I'd
01:05:03.340 | screwed it up.
01:05:06.180 | This is the exact same VGG-16 network we've been using since I added batch norm. So nothing's
01:05:16.540 | been changed other than this one piece of code I just showed you which says you can
01:05:21.740 | use different sizes, and if you do, don't add the fully connected layers.
01:05:31.380 | So now that I've got this VGG model which is expecting a 640 by 360 input, I can then
01:05:40.980 | add to it my top layers. And this time, my top layers are going to get in an input which
01:05:49.380 | is of size 22 by 40. So normally, our VGG's final layer is 14 by 14, or if you include
01:05:59.460 | the final max pooling, it's 7 by 7. In this case, it's 22 by 40, and that's because we've
01:06:07.180 | told it we're not going to pass it a 224 by 224, we're going to pass it a 640 by 360.
01:06:13.540 | So this is what happens. We end up with a different output shape. So if we now try to
01:06:18.540 | pass that to the same dense layer we used before, it wouldn't work, so it would be the
01:06:21.900 | wrong size. But we're actually going to do something very different anyway, we're not
01:06:26.620 | going to use any pre-trained fully connected weights. We're instead going to have, in fact,
01:06:34.220 | no dense layers at all. Instead, we're going to go conv.maxpool, conv.maxpool, conv.maxpool,
01:06:44.780 | global average pooling.
01:06:47.100 | So the best way to look at that is to see what's happening to our shape. So it goes
01:06:53.900 | in 22 by 40 until the max pooling, 11 by 20 until the max pooling, 5 by 10. And then because
01:07:01.340 | this is rectangular, the last max pooling I did a 1,2 shape, so that gives me a square
01:07:07.860 | result, so 5 by 5.
01:07:12.740 | Then I do a convolutional layer in which I have just 8 filters. And remember, there are
01:07:19.380 | 8 types of fish. There are no other weights after this. And in fact, even the dropout
01:07:25.020 | is not doing anything because I've set my p value to 0. So ignore that dropout layer.
01:07:31.220 | So we're going straight from a convolutional layer, which is going to be grid size 5 by
01:07:35.700 | 5, and have 8 filters, and then we're going to average across the 5 by 5, and that's going
01:07:42.580 | to give us something of size 8.
01:07:47.780 | So if we now say, please train this model, and please try and make these 8 things equal
01:07:53.420 | to the classes of fish. Now you have to think backwards. How would it do that? If it was
01:07:59.940 | to do that for us, and it will because it's going to use SGD, what would it have to do?
01:08:05.940 | Well it has no ability to use any weights to get to this point, so it has to do everything
01:08:13.300 | by the time it gets to this point. Which means this convolution2D layer is going to have
01:08:18.380 | to have in each of its 5 grid areas something saying, how fishy is that area? Because that's
01:08:24.260 | all it can do. After that, all it can do is to average them together.
01:08:28.860 | So we haven't done anything specifically to calculate it that way, we just created an
01:08:33.900 | architecture that has to do that. Now my feeling is that ought to work pretty well because
01:08:38.940 | as we saw in that earlier picture, the fish only appears in one little spot. And indeed
01:08:44.260 | as we discussed earlier, maybe even a global max pooling could even be better.
01:08:50.500 | So let's try this. We can fit it as per usual, and you can see here even without using bounding
01:08:56.140 | boxes, we've got a pretty stable and pretty good result in about 30 seconds, 97.6.
01:09:05.420 | When I then tried this on the Kaggle leaderboard, I got a much better result. In fact to show
01:09:12.100 | you my submissions, the 20th place was me just averaging together 4 different models,
01:09:25.300 | 4 of the models that I'm showing you today. But this one on its own was 0.986, which would
01:09:42.100 | be 20 seconds. So this model on its own would get its 20 second position. And no data augmentation,
01:09:55.820 | no pseudo-labeling, we're not using the validation set to help us, which you should when you
01:10:01.460 | do your final Kaggle entry.
01:10:05.060 | So you can get 20 second position with this very simple approach, which is to use a slightly
01:10:10.420 | larger image and use a fully convolutional network. There's something else cool about
01:10:16.220 | this fully convolutional network, which can get us into 20 second position. And that is
01:10:21.060 | that we can actually look at the output of this layer, and remember it's 5x5.
01:10:29.340 | How are you using VGG?
01:10:40.620 | VGG, as always before, is the input to this model. So I first of all calculated every
01:10:47.060 | single model I'm showing you today, I pre-computed the output of the last convolutional layer
01:10:52.020 | in VGG.
01:11:00.180 | So I go get data, and I say I want to get a 360, 640 sized data, and so that gives me
01:11:08.100 | my image, and then I -- this is data augmentation which I'm not doing at the moment, I then
01:11:19.580 | create my model, pop off the last layer, because I don't want the last max pooling layer, so
01:11:25.780 | that's the size, and then call predict to get the features from that last layer.
01:11:37.960 | So it's what we always do, it's just the only difference is that we passed 360, 640 to our
01:11:44.140 | constructor for the model, and we passed 360, 640 to the get data command.
01:11:53.500 | I'm always skipping that bit, but everything I'm showing you today is taking as input the
01:12:05.220 | last convolutional layer from VGG.
01:12:15.580 | A couple of reasons why. The first because the authors of the paper which created the
01:12:20.060 | fully convolutional net found that it worked pretty well. The global average pooling 2D
01:12:27.500 | layer has been discussed, turns out to have excellent generalization characteristics.
01:12:31.100 | So you'll notice here we have no dropout, and yet we're in 22nd place on the leaderboard
01:12:37.180 | without even beginning to try.
01:12:42.380 | And then the final reason is the thing I'm about to show you, which is that we basically
01:12:46.700 | have maintained a sense of kind of x-y coordinates all the way through, which means that we can
01:12:57.100 | actually now visualize this last layer. And I want to do that before I take the next question.
01:13:05.380 | So I can say, let's create a function which takes our model's input as input and our fourth
01:13:14.060 | from last layer as output, that is that convolutional layer that I showed you.
01:13:19.740 | And then I'm going to take that and I'm going to pass into it the features of my first validation
01:13:28.780 | image and draw a picture of it for this picture, and here is my picture. And so you can see
01:13:38.900 | it's done exactly what we thought it would do, which is it's had to figure out that there's
01:13:42.380 | a fishy bit here. So these fully convolutional networks have a nice side effect, which is
01:13:51.900 | that they allow us to find whereabouts the interesting parts are.
01:13:56.940 | The default parameters for max pooling are 2,2, so it's taking each 2x2 square and replacing
01:14:13.820 | it with the largest value in that 2x2 square. So this is not the most high-res heat map
01:14:21.300 | we've ever seen. So the obvious thing to make it all more high-res would be to remove all
01:14:26.460 | the max pooling layers. So here's exactly the same thing as before, but I've removed
01:14:31.500 | all the max pooling layers.
01:14:34.060 | So that means that my model now remains at 22x40 all the way through, everything else
01:14:41.220 | is the same. And that indeed does not give quite as accurate a result, we get 95.2 rather
01:14:50.540 | than 97.6. On the other hand, we do have a much higher resolution grid, so if we now
01:15:01.020 | do exactly the same thing to create the heat map, and the other thing we're going to do
01:15:06.140 | is resize the heat map to 360x640, and by default, this resize command will try and
01:15:13.300 | interpolate. So it's going to replace big pixels with interpolated small pixels.
01:15:20.420 | And that gives us, for this image, this answer, which is much more interesting. And so now
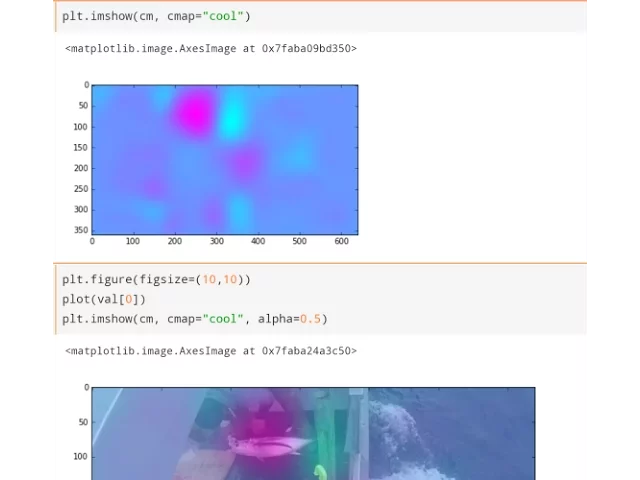
01:15:28.780 | we can stick one on top of the other, like so. And this tells us a lot. It tells us that
01:15:38.340 | on the whole, this is doing a good job of saying the thing that mattered, the fishy
01:15:42.860 | thing, the albacore thing specifically, because we're asking here for the albacore plus. Remember,
01:15:50.140 | the layer, that layer of the model is 8x22x40, so we have to ask how much like albacore is
01:15:59.820 | each of those areas, or how much like shark is each of those areas.
01:16:03.460 | So when we called this function, it returned basically a heat map for every type of fish,
01:16:13.620 | and so we can pass in 0 for albacore, or here's a cool one. Class number 4 is nofish. So one
01:16:23.940 | of the classes you have to predict in this competition is nofish. So we could say, tell
01:16:28.540 | us how much each part of this picture looks like the nofish class. What happens is if
01:16:34.860 | you look at the nofish version, it's basically the exact opposite of this. You get a big
01:16:39.620 | blue spot here, and pink or round it. The other thing I wanted to point out here is these
01:16:48.380 | areas of pinkishness that are not where the fish is. This is telling me that our model
01:16:54.500 | is not currently just looking for fish. It's also looking, if we look at this pink here,
01:17:01.100 | it's looking for particular characteristics of the boat.
01:17:06.860 | So this is suggesting to me that since it's not all concentrated on the fish, I do think
01:17:12.740 | that there's some data leakage still coming through.
01:17:17.180 | I think we know everything about why it's working. We have set up a model where we've
01:17:37.700 | said we want you to predict each of the 8 fish classes. We have set it up such that
01:17:48.860 | the last layer simply averages the answers from the previous layer. The previous layer
01:17:55.300 | we have set up so it has the 8 classes we need. So that's obviously the only way you
01:18:00.500 | can average and get the right number of classes. We know that SGD is a general optimization
01:18:07.780 | approach which will find a set of parameters which solves the problem that you give it
01:18:13.620 | and we've given it that problem.
01:18:15.740 | So really, when you think of it that way, unless it failed to train, which it could
01:18:23.500 | for all kinds of reasons, unless it failed to train, it could only get a decent answer
01:18:31.360 | if it solved it in this way. If it actually looked at each area and figured out how fishy
01:18:35.940 | it is.
01:18:36.940 | We're not doing attention models in this part of the course, per se. I would say for now,
01:18:51.940 | the simple attention model that I would do would be to find the largest area of the heat
01:18:58.980 | mat and crop that, and maybe compare that to the bounding boxes and make sure they look
01:19:05.860 | about the same and those that don't, you might want to hand fix. And if you hand fix them,
01:19:10.860 | you have to give that back to the Kaggle community of course because that's hand labeling.
01:19:17.700 | And honestly, that's the state of the art. In terms of who wins the money in Kaggle,
01:19:25.540 | that's how the Kaggle winners have won these kinds of competitions is by having a two-stage
01:19:31.220 | pipeline where first of all they find the thing of interest and then they zoom into
01:19:35.380 | it and then they do a model on that thing.
01:19:40.220 | Actually the other thing that you might want to do is to orient the fish so that the tail
01:19:47.420 | is kind of in the same place and the head is in the same place. Make it as easy as possible
01:19:52.100 | basically for your consonant to do what it needs to do.
01:20:03.020 | You guys might have heard of another architecture called Inception. A combination of Inception
01:20:09.580 | plus ResNet won this year's ImageNet competition. And I want to give you a very quick hint as
01:20:21.300 | to how it works. I have built the world's tiniest little Inception network here in this screen.
01:20:31.700 | One of the reasons I want to show it to you is because it actually uses the same technique
01:20:36.060 | that we heard from Ben Bowles that he used. Do you remember in his language model, Quid,
01:20:42.940 | Ben used a trick where he had multiple different convolution filter sizes and ran all of them
01:20:49.680 | and concatenated them together? That's actually what the Inception network does.
01:21:09.880 | To align the head and tail, the easiest way would be to hand annotate the head and hand
01:21:14.300 | annotate the tail. That was what was done in the whale competition.
01:21:30.540 | Hand labeling always has errors, and indeed there are quite a few people in the forum
01:21:35.340 | who have various bounding boxes that they don't think are correct. It's great to have
01:21:39.780 | an automatic approach which ought to give about the same answer as the hand approach,
01:21:44.740 | and you can then compare the two and use the best of both worlds.
01:21:50.460 | And in general, this idea of combining human intelligence and machine intelligence seems
01:21:55.640 | to be a great approach, particularly early on. You can do that for the first few bounding
01:22:01.140 | boxes to improve your bounding box model and then use that to gradually make the model
01:22:11.380 | have to ask you less and less for your input.
01:22:40.080 | The heatmap you don't need to. The heatmap was just visualizing one of the layers of
01:22:50.700 | the network. We didn't use the bounding boxes, we didn't do anything special. It's just a
01:22:56.620 | side effect of this kind of model. You can visualize the last convolutional layer and
01:23:02.460 | in doing so we'll give you a heatmap.
01:23:14.820 | There's so many ways of interpreting neural nets, and one of them is to draw pictures
01:23:19.160 | of the intermediate activations. You can also draw pictures of the intermediate gradients.
01:23:24.520 | There's all kinds of things you can draw pictures of.
01:23:38.300 | The Inception network is going to use this trick where we're going to use multiple different
01:23:56.120 | convolutional filter sizes. Just like in ResNet, there's this idea of a ResNet block which is
01:24:10.520 | repeated again and again. In the Inception network, there's an Inception block which
01:24:14.620 | is repeated again and again. I've created a version of one here. I have one thing which
01:24:22.400 | takes my input and does a 1x1 convolution. I've got one thing that takes the input and
01:24:27.320 | does a 5x5 convolution. I've got one thing that takes the input and does 2 3x3 convolutions.
01:24:33.560 | I've got one thing that takes the input and just average pulls it. And then we concatenate
01:24:39.000 | them all together.
01:24:40.640 | So what this is doing is each Inception block is basically able to look for things at various
01:24:46.560 | different scales and create a single feature map at the end which adds all those things
01:24:52.600 | together.
01:24:54.600 | So once I've defined that, I can create a model that just goes Inception block, Inception
01:24:58.760 | block, Inception block, Comm2D, global average pulling 2D, output. I haven't managed to get
01:25:05.600 | this to work terribly well yet. I've got the same kind of results. I haven't actually tried
01:25:11.840 | submitting this to Kaggle. Part of the purpose of this is to give you guys a sense of the
01:25:23.040 | kinds of things we'll be doing next year. This idea of we've built the basic pieces
01:25:28.920 | now of convolutions, fully connected layers, activation functions, SGD, and really from
01:25:38.800 | here, deep learning is putting these pieces together. What are the ways people have learned
01:25:43.400 | about putting these things together in ways that solve problems as well as possible?
01:25:50.200 | And so the Inception network is one of these ways. And the other thing I wanted to do was
01:25:54.000 | to give you plenty of things to think about over the next couple of months and play with.
01:25:58.840 | So hopefully this notebook is going to be full of things you can experiment with and
01:26:03.800 | maybe even try submitting some Kaggle results.
01:26:10.240 | I guess the warnings about the Inception network are a bit similar to the warnings about the
01:26:13.440 | ResNet network. Like ResNet, the Inception network is available, actually Keras. I haven't
01:26:20.440 | converted one to my standard approach, but Keras has an Inception network that you can
01:26:25.960 | download and use. It hasn't been well-studied in terms of its transfer learning capabilities.
01:26:36.040 | Again I haven't seen people who have won Kaggle competitions using transfer learning of Inception
01:26:42.160 | network, so it's just a little bit less well-studied. But like ResNet, the combination of Inception
01:26:50.120 | plus ResNet is the most recent image network. So if you are looking to really start with
01:26:56.760 | the most predictive model, this is where you would want to start.
01:27:02.600 | So I want to finish off on a very different note, which is looking at RNNs. I've spent
01:27:16.840 | much more time on CNNs than RNNs. The reason is that this course is really all about being
01:27:23.200 | pragmatic. It's about teaching you the stuff that works, and in the vast majority of areas
01:27:29.080 | where I see people using deep learning to solve their problems, they're using CNNs.
01:27:38.520 | Having said that, some of the most challenging problems are now being solved with RNNs like
01:27:45.160 | speech recognition and language translation. So when you use Google Translate now, you're
01:27:51.000 | using RNNs. My suspicion is you're going to come across these kinds of problems a lot
01:27:58.120 | less often, but I also suspect that in a business context, a very common kind of problem is a
01:28:06.400 | time series problem, like looking at the time series of click events on your website or
01:28:13.080 | e-commerce transactions or logistics or whatever.
01:28:20.000 | These sequence-to-sequence RNNs we've been looking at, which we've been using to create
01:28:25.240 | Nietzschean philosophy, are identical to the ones you would use to analyze a sequence of
01:28:31.680 | e-commerce transactions and try to find anomalies.
01:28:35.400 | So I think CNNs are more practically important for most people in most organizations right
01:28:43.320 | now, but RNNs also have a lot of opportunities, and of course we'll also be looking at them
01:28:50.880 | when it comes to attentional models next year, which is figuring out in a really big image
01:28:56.360 | which part should we look at next.
01:28:58.200 | Question - Does Inception have the merge characteristic?
01:29:05.040 | The Inception merge is a concat rather than that, which is the same as what we saw when
01:29:09.720 | we looked at Ben Bowles' quid NLP model. We're taking multiple convolution filter sizes and
01:29:20.160 | we're sticking them next to each other. So that feature basically contains information
01:29:27.240 | about 5x5 features and 3x3 features and 1x1 features.
01:29:32.920 | And so when you add them together, you lose that information. ResNet does that for a very
01:29:37.800 | specific reason, which is we want to cause at all our residuals. In Inception, we don't
01:29:43.600 | want that. Inception, we want to keep them all in the feature space.
01:29:55.280 | The other reason I wanted to look at RNNs is that last week we looked at building an
01:30:02.600 | RNN nearly from scratch in Theano. And I say nearly from scratch because there was one
01:30:09.460 | key step which it did for us, which was the gradients. Really understanding how the gradients
01:30:19.040 | are calculated is not something you would probably ever have to do by hand, but I think
01:30:25.600 | it can be very helpful to your intuition of training neural networks to be able to trace
01:30:32.280 | it through.
01:30:33.280 | And so for that reason, this is kind of the one time in this course over this year and
01:30:37.640 | next year's course where we're going to really go through and actually calculate the gradients
01:30:42.840 | ourselves. So here is a recurrent neural network in pure Python. And the reason I'm doing a
01:30:49.720 | recurrent neural network in pure Python is this is kind of the hardest. RNNs are the
01:30:54.200 | hardest thing to get your head around backpropagating gradients. So if you look at this and study
01:31:00.720 | this and step through this over the next couple of months, you will really be able to get
01:31:04.720 | a great understanding of what a neural net is really doing. There's going to be no magic
01:31:09.160 | or mystery because this whole thing is going to be every line of code, something that you
01:31:13.600 | can see and play with.
01:31:15.560 | So if we're going to do it all ourselves, we have to write everything ourselves. So
01:31:21.560 | if we want a sigmoid function, we have to write the sigmoid function. Any time we write
01:31:25.680 | any function, we also have to create this derivative. So I'm going to use this approach
01:31:31.520 | where _d is the derivative function. So I'm going to have relu and the derivative of relu.
01:31:40.280 | And I'll just kind of check myself as I go along that they look reasonable. The Euclidean
01:31:45.040 | distance and the derivative of the Euclidean distance.
01:31:50.520 | The cross entropy and the derivative of the cross entropy. And note here that I am clipping
01:31:56.560 | my predictions because if you have zeros or ones there, you're going to get infinities
01:32:02.860 | and it destroys everything.
01:32:04.800 | So you have to be careful of this. This did actually happen. I didn't have this Euclidean
01:32:08.800 | at first and I was starting to get infinities and this is necessary. My softmax is the derivative
01:32:15.560 | of softmax.
01:32:18.560 | So then I basically go through and I double check that the answers I get with my versions
01:32:22.200 | are the same as the answers I get with the theana versions to make sure they're all correct
01:32:26.680 | and they all seem to be fine.
01:32:32.160 | So I am going to use as my activation function relu, which means the derivative is relu derivative
01:32:37.800 | and my loss function is cross entropy derivative. I also have to write my own scan. So you guys
01:32:46.120 | remember scan. Scan is this thing where we go through a sequence one step at a time,
01:32:51.560 | calling a function on each element of the sequence. And each time the function is going to get
01:32:56.040 | two things, it's going to get the next element of the sequence as well as the previous result
01:33:01.200 | of the call.
01:33:02.640 | So for example, scan of add two things together on the integers from 0 to 5 is going to give
01:33:12.560 | us the cumulative sum. And remember the reason we do this is because GPUs don't know how to
01:33:19.560 | do loops, so our theano version used a scan. And I wanted to make this as close to the
01:33:24.000 | theano version as possible.
01:33:26.320 | In theano, scan is not implemented like this with a for loop. In theano, they use a very
01:33:31.840 | clever approach which basically creates a tree where it does a whole lot of the things
01:33:36.320 | kind of simultaneously and gradually combines them together. Next year we may even look
01:33:41.840 | at how that works if anybody's interested.
01:33:47.040 | So in order to create our Nietzschean philosophy, we need an input and an output. So we have
01:33:53.560 | the eight character sequences, one hot encoded for our inputs, and the eight character sequences
01:34:01.600 | moved across by one, one hot encoded for our outputs. And we've got our vocab size, which
01:34:08.040 | is 86 characters. So here's our input and output shapes, 75,000 phrases, each one has
01:34:16.880 | eight characters in, and each of those eight characters is a one-hot encoded vector of
01:34:20.360 | size 86.
01:34:24.440 | So we first of all need to do the forward pass. So the forward pass is to scan through
01:34:34.400 | all of the characters in the nth phrase, the input and output, calling some function. And
01:34:42.160 | so here is the forward pass. And this is basically identical to what we saw in theano. In theano,
01:34:47.720 | we had to lay out the forward pass as well.
01:34:50.000 | So to create the hidden state, we have to take the dot product of x with its weight
01:34:55.120 | matrix and the dot product of the hidden with its weight matrix, and then we have to put
01:35:00.760 | all that through the activation function. And then to create the predictions, we have to
01:35:06.360 | take the dot product of the hidden with its weight matrix and then put that through softmax.
01:35:15.240 | And so we have to make sure we keep track of all of the state that it needs, so at the
01:35:18.880 | end we will return the loss, the pre-hidden and pre-pred, because we're going to use them
01:35:31.120 | each time we go through. In the back prop, we'll be using those. We need to know the
01:35:36.800 | hidden state, of course, we have to keep track of that because we're going to be using it
01:35:40.720 | the next time through the RNN. And of course, we're going to need our actual predictions.
01:35:46.960 | So that's the forward pass, very similar to the other one. The backward pass is the bit
01:35:52.560 | I wanted to show you, and I want to show you how I think about it.
01:36:04.360 | This is how I think about it. All of my arrows, I've reversed their direction. And the reason
01:36:10.480 | for that is that when we create a derivative, we're really saying how does the input change,
01:36:16.720 | how does a change in the input impact the output? And to do that, we have to use the
01:36:21.560 | chain rule, we have to go back from the end all the way back to the start.
01:36:25.920 | So this is our output last hidden layer activation matrix. This is our loss, which is adding together
01:36:37.360 | all of the losses of each of the characters. If we want the derivative of the loss with
01:36:43.280 | respect to this hidden activation, we would have to take the derivative of the loss with
01:36:47.560 | respect to this output activation and multiply it by the derivative of this output activation
01:36:53.520 | with respect to this hidden activation. We have to then multiply them together because
01:36:58.280 | that's the chain rule. The chain rule basically tells you to go from some function of some
01:37:06.960 | other function of x, the derivative is the product of those functions.
01:37:17.640 | So I find it really helpful to literally draw the arrows. So let's draw the arrow from the
01:37:24.160 | loss function to each of the outputs as well. And so to calculate the derivatives, we basically
01:37:32.280 | have to go through and undo each of those steps. In order to figure out how that input
01:37:39.560 | would change that output, we have to basically undo it. We have to go back along the arrow
01:37:44.640 | in the opposite direction.
01:37:46.680 | So how do we get from the loss to the output? So to do that, we need the derivative of the
01:37:55.720 | loss function. If we're going to go back to the activation function, we're going to need
01:38:02.880 | the derivative of the activation function as well. So you can see it here. This is a
01:38:08.280 | single backward pass. We grab one of our inputs, one of our outputs, and then we go backwards
01:38:18.560 | through each one, each of the 8 characters from the end to the start. So grab our input
01:38:23.840 | character and our output character, and the first thing you want is the derivative of
01:38:29.960 | pre-pred. Remember pre-pred was the prediction prior to putting it through the softmax. So
01:38:38.800 | that was the bit I just showed you. It's the derivative of the softmax times the derivative
01:38:45.360 | of the loss.
01:38:47.320 | So the derivative of the loss is going to get us from here back to here, and then derivative
01:38:53.600 | of the softmax gets us from here back to the other side of the activation function. That
01:38:59.520 | basically gets us to here. So that's what that gets us to. So we want to keep going
01:39:09.920 | further, which is we want to get back to the other side of the hidden. We want to get all
01:39:15.360 | the way over now to here.
01:39:25.320 | For those of you that haven't done vector calculus, which I'm sure is many of you, just
01:39:30.360 | take my word for it. The derivative of a matrix multiplication is the multiplication with
01:39:37.480 | the transpose of that matrix. So in order to take the derivative of the pre-hidden times
01:39:45.920 | its weights, we simply take it by the transpose of its weights. So this is the derivative
01:39:53.720 | of that part.
01:39:55.880 | And remember the hidden, we've actually got 2 arrows coming back out of it, and also we've
01:40:02.160 | got 2 arrows coming into it. So we're going to have to add together that derivative and
01:40:09.080 | that derivative.
01:40:10.860 | So here is the second part. So there it is with respect to the outputs, and there it
01:40:16.920 | is with respect to the hidden. And then finally, we have to undo the activation function. So
01:40:24.080 | multiply it by the derivative of the activation function. So that's the chain rule that gets
01:40:28.880 | us all the way back to here.
01:40:34.480 | So now that we've got those two pieces of information, we can update our weights. So
01:40:41.160 | we can now say for the blue line, what are these weights now going to equal? So we basically
01:40:48.800 | have to take the derivative that we got to at this point, which we called dprered. We
01:40:56.080 | have to multiply by our learning rate, which we're calling alpha. And then we have to undo
01:41:02.960 | the multiplication by the hidden state to get the derivative with respect to the weights.
01:41:08.360 | And I created this little columnify function to do that. So it's turning a vector into
01:41:14.200 | a column, so essentially taking its transpose if you like.
01:41:17.720 | So that gives me my new output weights. My new hidden weights are basically the same
01:41:23.040 | thing. It's the learning rate times the derivative that we just calculated, and then we have
01:41:29.240 | to undo its weights and our new input weights, again at the learning rate, times the pre-hidden
01:41:36.280 | times the columnify version of x.
01:41:40.080 | So I'll go through that very quickly. The details aren't important, but if you're interested
01:41:45.720 | it might be fun to look at it over the Christmas break or the next few days. Because you can
01:41:52.120 | see in this here is all of the steps necessary to do that through an RNN, which is also why
01:42:01.960 | we would never want to do this by hand again.
01:42:04.600 | So when I wrote this code, luckily I did it before I got my code. You can see I've written
01:42:13.040 | after every one the dimensions of each matrix and vector because it just makes your head
01:42:17.200 | hurt. So thank God, Theano does this for us. But I think it's useful to see it.
01:42:27.640 | So finally, I now just have to create my initial weight matrices, which are normally distributed
01:42:34.360 | matrices where these normal distribution, I'm going to use the square root of 2 divided
01:42:39.120 | by the number of inputs because that's that Glauro thing, ditto for my y matrix, and remember
01:42:45.000 | for my hidden matrix for a simple RNN, we will use the identity matrix to initialize
01:42:51.040 | it.
01:42:57.880 | We haven't got to that bit yet, so it depends how we use this. At this stage all we've done
01:43:02.600 | is we've defined the matrices and we've defined the transitions. And whether we maintain state
01:43:09.000 | will depend entirely on what we do next, which is the loop. So here is our loop. In our loop
01:43:16.440 | we're going to go through a bunch of examples, we should really go through all of them, but
01:43:19.480 | I was too lazy to wait. Run one forward step, and then one backward step, and then from
01:43:30.120 | time to time print out how we're getting along.
01:43:34.960 | So in this case, the forward step is passing to scan the initial state is a whole bunch
01:43:46.400 | of zeros. So currently this is resetting the state, it's not doing it statefully. If you
01:43:55.360 | wanted to do it statefully, it would be pretty easy to change. You would have to have the
01:43:59.800 | final state returned by this and keep track of it and then feed it back the next time
01:44:05.040 | through the loop.
01:44:06.040 | If you're interested, maybe you could try that. Having said that, you probably won't
01:44:09.680 | get great results because remember that when you do things statefully, you're much more
01:44:14.240 | likely to have gradients and activations explode unless you do a GIU or an LSTM. So my guess
01:44:22.320 | is it probably won't work very well. So that was a very quick fly-through and really more
01:44:33.320 | showing you around the code so that if you're interested, you can check it out.
01:44:39.880 | What I really wanted to do was get onto this more interesting type of RNN, which is actually
01:44:47.640 | two interesting types of RNN called Long Short-Term Memory and Gated Recurrent Unit. Many of you
01:44:57.120 | will have heard of the one on the left, LSTM.
01:45:11.120 | For stateful RNNs, you can't exactly have minivatches because you're doing one at a
01:45:18.480 | time. In our case, we were going through it in order. Using minivatches is a great way
01:45:29.520 | to parallelize things on the GPU and make things run faster, but we have to be careful
01:45:35.640 | about how you're thinking about state.
01:45:41.400 | So LSTMs a lot of you will have heard about because they've been pretty popular over the
01:45:44.840 | last couple of years for all kinds of cool stuff that Google does. On the right, however,
01:45:51.000 | is the GRU, which is simpler and better than the LSTM. So I'm not going to talk about the
01:45:59.720 | LSTM, I'm going to talk about the GRU. They're both techniques for building your recurrent
01:46:06.640 | neural network where your gradients are much less likely to explode.
01:46:12.360 | They're another great interesting example of a clever architecture, but it's just going
01:46:19.440 | to be more of using the same ideas that we've seen again and again.
01:46:25.600 | What we have here on the right-hand side is this box. It's basically zooming into what's
01:46:37.320 | going on inside one of these circles in a GRU. So normally in our standard RNN, what's
01:46:43.560 | going on in here is pretty simple, which is we do a multiplication by this WH weight matrix
01:46:49.080 | and stick it through an activation function, and we grab our input, do it by a multiplication
01:46:54.520 | by weight matrix and grab its, and do it through its activation function, and we add the two
01:47:01.240 | together.
01:47:02.240 | At GRU, though, it's going to do something more complex. We still have the input coming
01:47:06.720 | in and the output going out, so that's what these arrows are. They're representing our
01:47:11.360 | new input character and our prediction. But what's going on in the middle is more complex.
01:47:18.360 | We still have our hidden state, just like before. But in a normal RNN, the hidden state
01:47:27.720 | each time simply updates itself. It just goes through a weight matrix and an activation
01:47:35.400 | function and updates itself.
01:47:39.560 | But in this case, you can see that the loop looks like it's going back to come direct
01:47:43.640 | with self, but then there's this gate here. So it's actually not just a self-loop, there's
01:47:52.520 | something more complicated. So in order to understand what's going on, we're going to
01:47:55.600 | have to follow across to the right hand side.
01:47:58.880 | So on the right hand side, you can see that the hidden state is going to go through another
01:48:03.440 | gate. So what's a gate? A gate is simply a little mini-neural network which is going
01:48:15.000 | to output a bunch of numbers between 0 and 1, which we're going to multiply by its input.
01:48:22.080 | In this particular one, the R stands for reset. And so the numbers between 0 and 1, if they
01:48:29.880 | were all 0, then the thing coming out of the reset gate would be just a big bunch of 0's.
01:48:35.560 | In other words, it would allow this network to forget the hidden state. Or it could be
01:48:42.960 | a big bunch of 1's which would allow the network to remember all of the hidden state. Do we
01:48:51.400 | want it to remember or forget? We don't know, which is why we implement this gate using
01:48:57.200 | a little neural network. And this little neural network is going to have two inputs, which
01:49:02.840 | is the input to the gate, the input to the GIU unit, and the current hidden state.
01:49:11.240 | And so it's going to learn a set of weights that it's going to use to decide when to forget.
01:49:18.400 | So it's now got the ability to forget what it knows. And that's what the reset gate does.
01:49:25.200 | So assuming that the reset gate has at least some non-zero entries, which it most surely
01:49:30.160 | will most of the time, then whatever comes through we're going to call h_tilde, or in
01:49:35.440 | my code I call it h_new. So this is the new value of the hidden state after being reset.
01:49:47.220 | And so then finally, that goes up to this top bit here. The original hidden state goes
01:49:53.200 | up to this top bit here. And then there's a gate which decides how much of each one should
01:50:00.020 | we have. So this is an update gate. This update gate is going to decide if it's 1, we'll take
01:50:12.160 | more from this side. If it's 0, we'll take more from this side. And again, that's implemented
01:50:17.360 | as a little neural network. I think the easiest way to understand this is probably to look
01:50:23.380 | at the code. So I have implemented this in Theano. You can use a GIU in Keras by simply
01:50:30.200 | replacing the words simple RNN with GIU. So you don't really need to know this to use
01:50:36.040 | it, and you get pretty good results. But here's what it looks like when implemented. We don't
01:50:47.560 | just have a hidden input weight matrix and an output weight matrix anymore, we also have
01:50:54.240 | a hidden input weight matrix for our little reset gate, and for our update gate.
01:51:04.400 | So here is the definition of a gate. A gate is something which takes its inputs, its hidden
01:51:10.080 | state, its hidden state weights, its input weights, and its biases. It does a dot product
01:51:17.940 | of the x with w_x, a dot product of h with w_h, and adds the biases and sticks to its
01:51:23.180 | true or single action. So that's what I meant by a mini-neuronet. It's hardly a neuronet,
01:51:28.880 | it's just got one layer. So that's the definition of the reset gate and the update gate.
01:51:37.920 | And so in our step function, this is the thing that runs each time on the scan, it looks
01:51:45.320 | exactly the same as what we looked at last week. The output equals the hidden state times
01:51:51.600 | the hidden weight matrix plus the hidden biases. The new hidden state equals our inputs times
01:52:01.520 | its weights and the hidden state times its weights plus the biases, but this time the
01:52:07.440 | hidden weights are multiplied by the reset gate. And the reset gate is just a little
01:52:15.320 | neural net. So now that we have h new, our actual new hidden state is equal to that times
01:52:26.960 | 1 minus the update gate plus our previous hidden state times the update gate. So you
01:52:32.560 | can see that update plus 1 minus update will add to 1. So you can see why it's been drawn
01:52:41.560 | like so, which is that this can really be anywhere at either end or somewhere in between.
01:52:49.040 | So the update gate decides how much is h new going to replace the new hidden state with.
01:52:59.560 | So actually, although people tend to talk about LSTMs and GRUs as being pretty complex,
01:53:04.640 | it really wasn't that hard to write. The key outcome of this though is that because we
01:53:14.000 | now have these reset and update gates, is that it has the ability to learn these special
01:53:19.580 | sets of weights to make sure that it throws away state when that's a good idea, or to
01:53:27.120 | ignore state when that's a good idea. And so these extra degrees of freedom allow SGD
01:53:33.480 | to find better answers, basically.
01:53:37.120 | And so again, this is one of these things where we're coming up with architectures which
01:53:42.600 | just try to make it easier for the optimizer to come up with good answers. Everything after
01:53:49.000 | this is identical to what we looked at last week. That goes into the scan function, to
01:53:53.240 | calculate the loss, we calculate the gradients, we do the SGD updates, and we chuck it into
01:54:00.480 | the scan function.
01:54:03.920 | So I think really the main reason I wanted to do all that today was to show you the backdrop
01:54:14.480 | example. I know some learning styles are more detail oriented as well, and so I think some
01:54:22.200 | of you hopefully will have found that helpful. Any time you find yourself wondering how the
01:54:29.360 | hell did this neural network do this, you can come back to this piece of code and that's
01:54:36.180 | all it did. That's all that's going on.
01:54:40.280 | That's one way of thinking about it. Where you really get successful with neural nets
01:54:44.520 | though is when you go to a whole other level and you don't think of it at that level anymore,
01:54:49.320 | but instead you start thinking, if I'm an optimizer and I'm given an architecture like
01:54:56.240 | this, what would I have to do in order to optimize it?
01:55:01.200 | And once you start thinking like that, then you can start thinking in this kind of like
01:55:06.920 | upside down way that is necessary to come up with good architectures. You can start
01:55:12.600 | to understand why it is that this convolution layer followed by this average pooling layer
01:55:20.200 | gives the answers that it does. Why does it work? You get that real intuition for what's
01:55:25.000 | going to work for your problem.
01:55:26.700 | So there's two ways, two levels at which you need to think about neural nets. The sooner
01:55:36.560 | you can think of it at this super high level, I feel like the sooner you'll do well with
01:55:40.680 | them. One of the best ways to do that is to, over the next couple of weeks, run this FISH
01:55:48.640 | notebook yourself and screw around with it a lot. Make sure that you know how to do
01:55:54.960 | these things that I did where I actually create a little function that allows me to spit out
01:56:03.680 | the output of any of the layers and visualize it. Make sure you kind of know how to inspect
01:56:09.000 | it and really look at the inputs and outputs. I think that's the best way to get an intuition.
01:56:18.400 | So this was kind of like, particularly the first half of this class was a bit of a preview
01:56:25.160 | of next year. In the first 6 weeks, you learn all the pieces. And then today, we very rapidly
01:56:33.320 | tried putting those pieces together in a thousand different ways and saw what happened. There's
01:56:40.640 | a million more ways that we know of, and probably a billion more ways we don't know of. So knowing
01:56:47.680 | this little set of tools, convolutions, fully connected layers, activation functions, SGD,
01:56:58.280 | you're now able to be an architect, create these architectures. Keras' functional API
01:57:05.800 | makes it ridiculously easy. I created all of the architectures you see today, this week,
01:57:13.760 | while I was sick and my baby wasn't sleeping. My brain was not even working, that's how
01:57:18.960 | easy Keras makes this. It takes a few weeks to build your comfort level up, but hopefully
01:57:31.000 | you can try that. And most importantly, over the next few weeks, as Rachel and I, maybe
01:57:39.240 | with some of your help, start to develop the MOOC, you guys can stay talking on the forums
01:57:46.880 | about keep working through whatever problems you're interested in. Whether it be the projects
01:57:52.080 | that you want to apply these things to in your own organizations or your personal passion
01:57:56.240 | projects or if you want to try and win a competition or two. Rachel and I are still going to be
01:58:02.880 | on the forums. And then in a few weeks time, when the MOOC goes online, hopefully there's
01:58:11.000 | going to be thousands of people joining this community. So we'll be like the seed. So I
01:58:18.640 | really hope you guys will stay a part of it and help. Can you imagine that first day when
01:58:26.680 | half the people still think that a python is a snake and don't know how to connect to
01:58:33.280 | an AWS instance? You'll all be able to say, read the wiki, here's the page, oh yeah, I
01:58:39.200 | had that problem too. And hopefully our goal here is to create a new generation of deep
01:58:46.560 | learning practitioners, people who have useful problems that they're trying to solve and
01:58:54.000 | can use this tool to solve them, rather than create more and more exclusive, heavily mathematical
01:59:03.880 | content that's designed to put people off. So that's our hope. That's really why we're
01:59:11.040 | doing this. Rachel, anything else that we should add before we wrap up?
01:59:18.280 | Okay, well thank you so much. It really has been a genuine pleasure and I'm so happy to
01:59:24.840 | hear that most of you are going to see you again next year. You guys obviously will get
01:59:32.560 | first dibs on places for next year's course. If the MOOC successful, next year's course
01:59:39.400 | could be quite popular, so I do suggest that you do nonetheless get your applications in
01:59:44.680 | not too late. They'll certainly go through with priority.
01:59:50.680 | Be aware if you're not already, we don't send email much, really the forums is our main
01:59:59.840 | way to communicate and Slack to some extent. So if you want to see what's going on, that's
02:00:04.840 | the places to look. And of course, our wiki is the knowledge base that we're creating
02:00:11.520 | for everybody. So anytime you see something missing on the wiki or something you think
02:00:15.000 | could be improved, edit it. Even if you're not sure if you're saying the right thing,
02:00:19.320 | you can add a little comment after it's saying "I'm not sure if this is correct." The next
02:00:22.440 | person coming along will help you.
02:00:25.200 | Thanks so much everybody. I hope you all have a great vacation season.
02:00:29.280 | [applause]