Lesson 7: Deep Learning 2
Chapters
0:01:0 Part Two
1:18 Generative Modeling
3:5 Standard Fully Connected Network
13:26 Repackage Variable
50:50 Update Gate
57:38 Cosine Annealing Callback
64:24 Need for Rigor in Experiments in Deep Learning
67:20 Create a Model from Scratch
70:30 Create a Learn Object from a Custom Model
73:59 Convolution
75:37 Stride to Convolution
77:12 Adaptive Max Pooling
80:59 Learning Rate Finder
85:43 Batch Normalization
86:21 Batch Norm
88:20 Normalizing the Inputs
111:0 Increasing the Depth of the Model
113:22 Resnet Block
119:6 Bottleneck Layer
121:25 The Transformer Architecture
129:11 Class Activation Maps
00:00:00.000 | The last class of Part 1, I guess the theme of Part 1 is classification and regression
00:00:12.200 | with deep learning, and specifically it's about identifying and learning the best practices
00:00:18.320 | to classification and regression.
00:00:21.920 | We started out with, here are three lines of code to do image classification, and gradually
00:00:28.600 | we've been, well the first four lessons were then kind of going through NLP, structured
00:00:35.480 | data, cognitive filtering and kind of understanding some of the key pieces, and most importantly
00:00:39.920 | understanding how to actually make these things work well in practice.
00:00:45.520 | And then the last three lessons are then kind of going back over all of those topics in
00:00:50.240 | kind of reverse order to understand more detail about what was going on and understanding
00:00:55.680 | what the code looks like behind the scenes and wanting to write them from scratch.
00:01:02.400 | Part 2 of the course will move from a focus on classification and regression, which is
00:01:09.920 | kind of predicting 'a' thing, like 'a' number, or at most a small number of things, like
00:01:16.120 | a small number of labels.
00:01:17.800 | And we'll focus more on generative modelling.
00:01:21.040 | generative modelling means predicting lots of things.
00:01:25.560 | For example, creating a sentence, such as in neural translation, or image captioning,
00:01:31.640 | or question-answering, or creating an image, such as in style transfer, super-resolution,
00:01:40.400 | segmentation, and so forth.
00:01:44.240 | And then in Part 2, it'll move away from being just, here are some best practices, established
00:01:51.960 | best practices either through people that have written papers or through research that
00:01:56.280 | Fast AI has done and kind of got convinced that these are best practices, to some stuff
00:02:02.160 | which will be a little bit more speculative.
00:02:04.560 | Some stuff which is maybe recent papers that haven't been fully tested yet, and sometimes
00:02:11.600 | in Part 2, papers will come out in the middle of the course, and we'll change direction
00:02:16.040 | with the course and study that paper because it's just interesting.
00:02:19.880 | And so if you're interested in learning a bit more about how to read a paper and how
00:02:26.360 | to implement it from scratch and so forth, then that's another good reason to do Part
00:02:30.640 | 2.
00:02:32.560 | It still doesn't assume any particular math background, but it does assume that you're
00:02:40.720 | prepared to spend time digging through the notation and understanding it and converting
00:02:47.240 | it to code and so forth.
00:02:49.520 | Alright, so where we're up to is RNNs at the moment.
00:02:54.880 | I think one of the issues I find most with teaching RNNs is trying to ensure that people
00:03:00.840 | understand that they're not in any way different or unusual or magical, they're just a standard
00:03:07.000 | fully connected network.
00:03:11.320 | Let's go back to the standard fully connected network which looks like this.
00:03:15.200 | To remind you, the arrows represent one or more layer operations, generally speaking
00:03:22.040 | a linear, followed by a nonlinear function.
00:03:25.160 | In this case, they're matrix modifications, followed by ReLU or THAN.
00:03:32.800 | The arrows of the same color represent exactly the same weight matrix being used.
00:03:41.760 | And so one thing which was just slightly different from previous fully connected networks we've
00:03:46.320 | seen is that we have an input coming in not just at the first layer but also at the second
00:03:53.280 | layer and also at the third layer.
00:03:55.040 | And we tried a couple of approaches, one was concatenating the inputs and one was adding
00:03:59.540 | the inputs.
00:04:00.540 | But there was nothing at all conceptually different about this.
00:04:06.600 | So that code looked like this.
00:04:09.760 | We had a model where we basically defined the three arrows colors we had as three different
00:04:19.260 | weight matrices.
00:04:22.600 | And by using the linear class, we got actually both the weight matrix and the bias vector
00:04:28.960 | wrapped up for free for us.
00:04:31.920 | And then we went through and we did each of our embeddings, put it through our first linear
00:04:37.360 | layer and then we did each of our, we call them hidden, I think they were orange arrows.
00:04:48.640 | And in order to avoid the fact that there's no orange arrow coming into the first one,
00:04:54.880 | we decided to invent an empty matrix and that way every one of these rows looked the same.
00:05:01.400 | And so then we did exactly the same thing except we used a loop just to refactor the
00:05:11.360 | code.
00:05:12.360 | So it was just a code refactoring, there was no change of anything conceptually.
00:05:18.720 | And since we were doing a refactoring, we took advantage of that to increase the number
00:05:23.240 | of characters to 8 because I was too lazy to type 8 linear layers, but I'm quite happy
00:05:28.320 | to change the loop index to 8.
00:05:31.720 | So this now loops through this exact same thing, but we had 8 of these rather than 3.
00:05:43.280 | So then we refactored that again by taking advantage of nn.rnn, which basically puts
00:05:49.880 | that loop together for us and keeps track of this h as it goes along for us.
00:06:00.400 | And so by using that we were able to replace the loop with a single call.
00:06:06.340 | And so again, that's just a refactoring, doing exactly the same thing.
00:06:15.640 | So then we looked at something which was mainly designed to save some training time, which
00:06:23.360 | was previously, if we had a big piece of text, so we've got a movie review, we were basically
00:06:38.560 | splitting it up into 8-character segments, and we'd grab segment number 1 and use that
00:06:47.000 | to predict the next character.
00:06:51.600 | But in order to make sure we used all of the data, we didn't just split it up like that,
00:06:56.560 | we actually said here's our whole thing, the first will be to grab this section, the second
00:07:05.440 | will be to grab that section, then that section, then that section, and each time we're predicting
00:07:11.000 | the next one character along.
00:07:14.560 | And so I was a bit concerned that that seems pretty wasteful because as we calculate this
00:07:21.560 | section, nearly all of it overlaps with the previous section.
00:07:26.440 | So instead what we did was we said what if we actually did split it into non-overlapping
00:07:34.360 | pieces and we said let's grab this section here and use it to predict every one of the
00:07:47.200 | characters one along.
00:07:49.200 | And then let's grab this section here and use it to predict every one of the characters
00:07:53.600 | one along.
00:07:54.600 | So after we look at the first character in, we try to predict the second character.
00:07:59.240 | And then after we look at the second character, we try to predict the third character.
00:08:04.240 | And then what if you perceptive folks asked a really interesting question, or expressed
00:08:11.280 | a concern, which was, after we got through the first point here, we kind of threw away
00:08:27.040 | our H activations and started a new one, which meant that when it was trying to use character
00:08:34.760 | 1 to predict character 2, it's got nothing to go on.
00:08:40.360 | It's only done one linear layer, and so that seems like a problem, which indeed it is.
00:08:49.200 | So we're going to do the obvious thing, which is let's not throw away H. So let's not throw
00:08:55.920 | away that matrix at all.
00:08:59.320 | So in code, the big problem is here.
00:09:04.920 | Every time we call forward, in other words every time we do a new mini-batch, we're creating
00:09:11.640 | our hidden state, which remember is the orange circles, we're resetting it back to a bunch
00:09:19.080 | of zeroes.
00:09:20.400 | And so as we go to the next non-overlapping section, we're saying forget everything that's
00:09:24.880 | come before.
00:09:25.880 | But in fact, the whole point is we know exactly where we are, we're at the end of the previous
00:09:30.860 | section and about to start the next contiguous section, so let's not throw it away.
00:09:35.460 | So instead the idea would be to cut this out, move it up to here, store it away in self,
00:09:48.680 | and then kind of keep updating it.
00:09:51.640 | So we're going to do that, and there's going to be some minor details to get right.
00:09:58.520 | So let's start by looking at the model.
00:10:01.960 | So here's the model, it's nearly identical, but I've got, as expected, one more line in
00:10:15.560 | my constructor where I call something called init_hidden, and as expected init_hidden sets
00:10:22.440 | self.h to be a bunch of zeroes.
00:10:28.280 | So that's entirely unsurprising.
00:10:32.720 | And then as you can see our RNN now takes in self.h, and it, as before, spits out our
00:10:41.960 | new hidden activations.
00:10:44.120 | And so now the trick is to now store that away inside self.h.
00:10:50.840 | And so here's wrinkle number 1.
00:10:53.720 | If you think about it, if I was to simply do it like that, and now I train this on a
00:11:02.960 | document that's a million characters long, then the size of this unrolled RNN is the
00:11:14.100 | one that has a million circles in.
00:11:17.840 | And so that's fine going forwards, but when I finally get to the end and I say here's
00:11:22.720 | my character, and actually remember we're doing multi-output now, so multi-output looks
00:11:28.440 | like this.
00:11:29.440 | Or if we were to draw the unrolled version of multi-output, we would have a triangle
00:11:35.020 | coming off at every point.
00:11:39.320 | So the problem is then when we do backpropagation, we're calculating how much does the error
00:11:47.080 | at character 1 impact the final answer, how much does the error at character 2 impact
00:11:53.960 | the final answer, and so forth.
00:11:55.640 | And so we need to go back through and say how do we have to update our weights based
00:12:01.660 | on all of those errors.
00:12:04.680 | And so if there are a million characters, my unrolled RNN is a million layers long,
00:12:11.520 | I have a 1 million layer fully connected network.
00:12:17.160 | And I didn't have to write the million layers because I have the for loop and the for loop
00:12:20.800 | is hidden away behind the self dot RNN, but it's still there.
00:12:28.720 | So this is actually a 1 million layer fully connected network.
00:12:32.600 | And so the problem with that is it's going to be very memory intensive because in order
00:12:37.160 | to do the chain rule, I have to be able to multiply it every step like f'u g'x.
00:12:46.680 | So I have to remember those values u, the value of every set of layers, so I'm going
00:12:53.160 | to have to remember all those million layers, and I'm going to have to do a million multiplications,
00:12:57.680 | and I'm going to have to do that every batch.
00:13:01.280 | So that would be bad.
00:13:03.360 | So to avoid that, we basically say from time to time, I want you to forget your history.
00:13:12.760 | So we can still remember the state, which is to remember what's the actual values in
00:13:17.200 | our hidden matrix, but we can remember the state without remembering everything about
00:13:22.960 | how we got there.
00:13:24.720 | So there's a little function called repackaged variable, which literally is just this.
00:13:37.400 | It just simply says, grab the tensor out of it, because remember the tensor itself doesn't
00:13:45.400 | have any concept of history, and create a new variable out of that.
00:13:50.200 | And so this variable is going to have the same value, but no history of operations,
00:13:56.320 | and therefore when it tries to backpropagate, it'll stop there.
00:14:01.160 | So basically what we're going to do then is we're going to call this in our forward.
00:14:05.800 | So that means it's going to do 8 characters, it's going to backpropagate through 8 layers,
00:14:13.680 | it's going to keep track of the actual values in our hidden state, but it's going to throw
00:14:18.480 | away at the end of those 8 its history of operations.
00:14:24.040 | So this approach is called backprop through time, and when you read about it online, people
00:14:31.880 | make it sound like a different algorithm, or some big insight or something, but it's
00:14:38.360 | not at all.
00:14:39.360 | It's just saying hey, after our for loop, just throw away your history of operations
00:14:46.180 | and start afresh.
00:14:47.480 | So we're keeping our hidden state, but we're not keeping our hidden state's history.
00:14:55.400 | So that's wrinkle number 1, that's what this repackage bar is doing.
00:15:00.340 | So when you see bptt, that's referring to backprop through time, and you might remember
00:15:07.320 | we saw that in our original RNN lesson, we had a variable called bptt = 70, and so when
00:15:15.880 | we set that, we're actually saying how many layers to backprop through.
00:15:21.200 | Another good reason not to backprop through too many layers is if you have any kind of
00:15:25.760 | gradient instability like gradient explosion or gradient spanishing, the more layers you
00:15:32.240 | have, the harder the network gets to train.
00:15:35.600 | So it's slower and less resilient.
00:15:39.040 | On the other hand, a longer value for bptt means that you're able to explicitly capture
00:15:47.360 | a longer kind of memory, more state.
00:15:52.600 | So that's something that you get to tune when you create your RNN.
00:16:02.320 | Wrinkle number 2 is how are we going to put the data into this.
00:16:10.600 | It's all very well the way I described it just now where we said we could do this, and
00:16:23.880 | we can first of all look at this section, then this section, then this section, but
00:16:30.080 | we want to do a mini-batch at a time, we want to do a bunch at a time.
00:16:36.920 | So in other words, we want to say let's do it like this.
00:16:51.200 | So mini-batch number 1 would say let's look at this section and predict that section.
00:16:58.080 | And at the same time in parallel, let's look at this totally different section and predict
00:17:03.040 | this.
00:17:04.040 | And at the same time in parallel, let's look at this totally different section and predict
00:17:08.480 | this.
00:17:10.600 | And so then, because remember in our hidden state, we have a vector of hidden state for
00:17:18.080 | everything in our mini-batch, so it's going to keep track of at the end of this is going
00:17:22.200 | to be a vector here, a vector here, a vector here, and then we can move across to the next
00:17:27.320 | one and say okay, for this part of the mini-batch, use this to predict that, and use this to predict
00:17:34.600 | that, and use this to predict that.
00:17:38.000 | So you can see that we've got a number of totally separate bits of our text that we're
00:17:43.800 | moving through in parallel.
00:17:47.440 | So hopefully this is going to ring a few bells for you, because what happened was back when
00:17:55.720 | we started looking at TorchText for the first time, we started talking about how it creates
00:18:00.120 | these mini-batches.
00:18:01.720 | And I said what happened was we took our whole big long document consisting of the entire
00:18:10.720 | works of Nietzsche, or all of the IMDb reviews concatenated together, or whatever, and a lot
00:18:17.320 | of you, not surprisingly, because this is really weird at first, a lot of you didn't
00:18:21.520 | quite hear what I said correctly.
00:18:23.120 | What I said was we split this into 64 equal-sized chunks, and a lot of your brains went, "Jermi
00:18:31.160 | just said we split this into chunks of size 64."
00:18:35.000 | But that's not what Jermi said.
00:18:36.360 | Jermi said we split it into 64 equal-sized chunks.
00:18:41.300 | So if this whole thing was length 64 million, which would be a reasonable sized corpus,
00:18:50.360 | then each of our 64 chunks would have been of length 1 million.
00:18:57.440 | And so then what we did was we took the first chunk of 1 million and we put it here.
00:19:03.360 | And then we took the second chunk of 1 million and we put it here.
00:19:06.920 | The third chunk of 1 million, we put it here.
00:19:09.280 | And so forth to create 64 chunks.
00:19:14.880 | And then each mini-batch consisted of us going, "Let's split this down here, and here, and
00:19:24.120 | here."
00:19:25.120 | And each of these is of size BPTT, which I think we had something like 70.
00:19:36.640 | And so what happened was we said, "All right, let's look at our first mini-batch is all
00:19:42.160 | of these."
00:19:44.040 | So we do all of those at once and predict everything offset by 1.
00:19:52.320 | And then at the end of that first mini-batch, we went to the second chunk and used each
00:19:58.000 | one of these to predict the next one offset by 1.
00:20:02.760 | So that's why we did that slightly weird thing, is that we wanted to have a bunch of things
00:20:08.960 | we can look through in parallel, each of which hopefully are far enough away from each other
00:20:16.240 | that we don't have to worry about the fact that the truth is the start of this million
00:20:21.200 | characters was actually in the middle of a sentence, but who cares?
00:20:26.480 | Because it only happens once every million characters.
00:20:30.800 | I was wondering if you could talk a little bit more about augmentation for this kind
00:20:38.880 | of dataset?
00:20:41.380 | Data augmentation for this kind of dataset?
00:20:43.080 | Yeah.
00:20:44.080 | No, I can't because I don't really know a good way.
00:20:48.640 | It's one of the things I'm going to be studying between now and Part 2.
00:20:54.920 | There have been some recent developments, particularly something we talked about in the
00:20:59.640 | machine learning course, which I think we briefly mentioned here, which was somebody
00:21:03.640 | for a recent Kaggle competition won it by doing data augmentation by randomly inserting
00:21:12.240 | parts of different rows, basically.
00:21:16.640 | Something like that may be useful here, and I've seen some papers that do something like
00:21:20.680 | that, but I haven't seen any kind of recent-ish state-of-the-art NLP papers that are doing
00:21:32.240 | this kind of data augmentation, so it's something we're planning to work on.
00:21:39.000 | So Jeremy, how do you choose BPTT?
00:21:47.000 | So there's a couple of things to think about when you pick your BPTT.
00:21:49.840 | The first is that you'll note that the matrix size for a mini-batch has BPTT by batch size.
00:22:07.280 | So one issue is your GPU RAM needs to be able to fit that by your embedding matrix, because
00:22:14.960 | every one of these is going to be of length embedding, plus all of the hidden state.
00:22:21.320 | So one thing is if you get a CUDA out of memory error, you need to reduce one of those.
00:22:29.920 | If your training is very unstable, like your loss is shooting off to NAN suddenly, then
00:22:38.080 | you could try decreasing your BPTT because you've got less layers to gradient explode
00:22:42.440 | through.
00:22:46.160 | You could try decreasing your BPTT because it's got to do one of those steps at a time,
00:22:51.080 | like that for loop can't be paralyzed.
00:22:57.660 | Well I say that.
00:22:59.160 | There's a recent thing called QRNN, which we'll hopefully talk about in Part 2 which
00:23:04.040 | kind of does paralyze it, but the versions we're looking at don't paralyze it.
00:23:08.160 | So that would be the main issues, look at performance, look at memory, and look at stability,
00:23:13.880 | and try and find a number that's as high as you can make it, but all of those things
00:23:19.220 | work for you.
00:23:24.680 | So trying to get all that chunking and lining up to work is more code than I want to write,
00:23:33.260 | so for this section we're going to go back and use Torch Text again.
00:23:41.880 | When you're using APIs like FastAI and Torch Text, which in this case these two APIs are
00:23:47.440 | designed to work together, you often have a choice which is like, okay, this API has
00:23:55.320 | a number of methods that expect the data in this kind of format, and you can either change
00:24:01.080 | your data to fit that format, or you can write your own data set subclass to handle the format
00:24:08.240 | that your data is already in.
00:24:11.000 | I've noticed on the forum a lot of you are spending a lot of time writing your own data
00:24:16.080 | set classes, whereas I am way lazier than you and I spend my time instead changing my
00:24:22.040 | data to fit the data set classes I have.
00:24:25.960 | Either is fine, and if you realize there's a kind of a format of data that me and other
00:24:34.760 | people are likely to be seeing quite often and it's not in the FastAI library, then by
00:24:38.720 | all means write the data set subclass, submit it as a PR, and then everybody can benefit.
00:24:45.640 | In this case, I just thought I want to have some niche data fed into Torch Text, I'm just
00:24:55.400 | going to put it in the format that Torch Text kind of already supports.
00:24:58.740 | So Torch Text already has, or at least the FastAI wrapper around Torch Text, already
00:25:03.840 | has something where you can have a training path and a validation path and one or more
00:25:09.880 | text files in each path containing a bunch of stuff that's concatenated together for
00:25:14.400 | your language model.
00:25:16.040 | So in this case, all I did was I made a copy of my nature file, copied it into training,
00:25:22.480 | made another copy, stuck it into the validation, and then in the training set, I deleted the
00:25:29.560 | last 20% of rows, and in the validation set, I deleted all except for the last 20% of rows.
00:25:37.800 | And I was done.
00:25:38.800 | In this case, I found that easier than writing a custom data set class.
00:25:44.400 | The other benefit of doing it that way was that I felt like it was more realistic to
00:25:49.240 | have a validation set that wasn't a random shuffled set of rows of text, but was like
00:25:55.880 | a totally separate part of the corpus, because I feel like in practice you're very often
00:26:01.140 | going to be saying, "Oh, I've got these books or these authors I'm learning from, and then
00:26:06.880 | I want to apply it to these different books and these different authors."
00:26:10.080 | So I felt like getting a more realistic validation of my nature model, I should use a whole separate
00:26:18.280 | piece of the text, so in this case it was the last 20% of the rows of the corpus.
00:26:25.760 | So I haven't created this for you intentionally, because this is the kind of stuff I want you
00:26:32.480 | practicing is making sure that you're familiar enough, comfortable enough with bash or whatever
00:26:37.760 | you can create these, and that you understand what they need to look like and so forth.
00:26:43.560 | So in this case, you can see I've now got a train and a validation here, and then I could
00:26:52.800 | go inside here.
00:26:56.920 | So you can see I've literally just got one file in it, because when you're doing a language
00:27:01.400 | model, i.e. predicting the next character or predicting the next word, you don't really
00:27:05.680 | need separate files.
00:27:08.160 | It's fine if you do have separate files, but they just get concatenated together anyway.
00:27:14.240 | So that's my source data, and so here is the same lines of code that we've seen before,
00:27:20.720 | and let's go over them again because it's a couple of lessons ago.
00:27:23.880 | So in Torch Text, we create this thing called a field, and a field initially is just a description
00:27:32.320 | of how to go about pre-processing the text.
00:27:36.440 | In this case, I'm going to say lowercase it, because I don't -- now I think about it, there's
00:27:43.920 | no particular reason to have done this lowercase, uppercase would work fine too.
00:27:48.400 | And then how do I tokenize it?
00:27:49.960 | And so you might remember last time we used a tokenization function which largely spit
00:27:55.800 | on white space and tried to do clever things with punctuation, and that gave us the word
00:28:00.160 | model.
00:28:01.160 | In this case, I want a character model, so I actually want every character put into a
00:28:05.720 | separate token.
00:28:07.660 | So I can just use the function list in Python, because list in Python does that.
00:28:18.320 | So this is where you can kind of see like, understanding how libraries like Torch Text
00:28:24.780 | and FastAI are designed to be extended can make your life a lot easier.
00:28:29.900 | So when you realize that very often, both of these libraries kind of expect you to pass
00:28:36.400 | a function that does something, and then you realize, oh, I can write any function I like.
00:28:44.680 | So this is now going to mean that each mini-batch is going to contain a list of characters.
00:28:51.480 | And so here's where we get to define all our different parameters.
00:28:56.080 | And so to make it the same as previous sections of this notebook, I'm going to use the same
00:29:00.960 | batch size, the same number of characters, and I'm going to rename it to bptt since we
00:29:06.480 | know what that means.
00:29:09.360 | The number of the size of the embedding, and the size of our hidden state.
00:29:15.440 | Remembering the size of our hidden state simply means going all the way back to the start,
00:29:24.760 | and then hidden simply means the size of the state that's created by each of those orange
00:29:29.960 | arrows.
00:29:30.960 | So it's the size of each of those circles.
00:29:39.240 | So having done that, we can then create a little dictionary saying what's our training,
00:29:43.440 | validation and test set.
00:29:45.080 | In this case, I don't have a separate test set, so I'll just use the same thing.
00:29:49.760 | And then I can say I want a language model data subclass with model data, I'm going to
00:29:55.320 | grab it from text files, and this is my path, and this is my field, which I defined earlier,
00:30:05.360 | and these are my files, and these are my hyperparameters.
00:30:11.640 | MinFract is not going to do anything actually in this case because I don't think there's
00:30:15.120 | going to be any character that appears less than 3 times, so that's probably redundant.
00:30:22.180 | So at the end of that, it says there's going to be 963 batches to go through.
00:30:28.760 | And so if you think about it, that should be equal to the number of tokens divided by
00:30:34.880 | the batch size divided by bptt, because that's the size of each of those rectangles.
00:30:46.120 | You'll find that in practice it's not exactly that, and the reason it's not exactly that
00:30:51.200 | is that the authors of TorchText did something pretty smart, which I think we've briefly
00:30:57.600 | mentioned this before.
00:30:58.600 | They said we can't shuffle the data, like with images we like to shuffle the order so
00:31:03.240 | every time we see them in a different order, so there's a bit more randomness.
00:31:06.480 | We can't shuffle because we need to be contiguous, but what we could do is basically randomize
00:31:14.580 | bptt a little bit each time.
00:31:17.900 | And so that's what PyTorch does.
00:31:20.480 | It's not always going to give us exactly 8 characters long, 5% of the time it'll actually
00:31:27.800 | cut it in half, and then it's going to add on a small little standard deviation to make
00:31:34.880 | it slightly bigger or smaller than 4 or 8.
00:31:37.400 | So it's going to be slightly different to 8 on average.
00:31:44.600 | So a mini-batch needs to do a matrix multiplication, and the mini-batch size has to remain constant
00:32:08.960 | because we've got this h-weight matrix that has to line up in size with the size of the
00:32:17.880 | mini-batch.
00:32:20.720 | But the sequence length can change, no problem.
00:32:33.560 | So that's why we have 963, so the length of a data loader is how many mini-batches, in
00:32:38.920 | this case it's a little bit approximate.
00:32:41.760 | Number of tokens is how many unique things are in the vocabulary.
00:32:45.960 | And remember, after we run this line, text now does not just contain a description of
00:32:55.240 | what we want, but it also contains an extra attribute called vocab, which contains stuff
00:33:04.040 | like a list of all of the unique items in the vocabulary and a reverse mapping from each
00:33:15.680 | item to its number.
00:33:18.960 | So that text object is now an important thing to keep track of.
00:33:30.600 | Let's now try this.
00:33:31.960 | Now we started out by looking at the class.
00:33:35.480 | So the class is exactly the same as the class we've had before.
00:33:39.120 | The only key difference is to call init_hidden, which sets out.
00:33:44.240 | So h is not a variable anymore, it's now an attribute, self.h is a variable containing
00:33:50.040 | a bunch of zeroes.
00:33:53.320 | Now I mentioned that batch size remains constant each time, but unfortunately when I said that
00:34:00.240 | I lied to you.
00:34:02.760 | And the way that I lied to you is that the very last mini-batch will be shorter.
00:34:09.960 | The very last mini-batch is actually going to have less than 64 -- it might be exactly
00:34:14.080 | the right size if it so happens that this data set is exactly divisible by bptt times
00:34:19.800 | batch size.
00:34:20.800 | But it probably isn't, so the last batch will probably have a little bit less.
00:34:26.320 | And so that's why I do a little check here that says let's check that the batch size
00:34:31.000 | inside self.h is going to be the height, the number of activations, and the width is going
00:34:45.560 | to be the mini-batch size.
00:34:48.080 | Check that that's equal to the actual batch size length that we've received.
00:34:58.160 | And if they're not the same, then set it back to zeroes again.
00:35:03.120 | So this is just a minor little ring call that basically at the end of each epoch, it's going
00:35:08.200 | to do like a little mini-batch.
00:35:12.600 | And so then as soon as it starts the next epoch, it's going to see that they're not
00:35:16.360 | the same again, and it will reinitialize it to the correct full batch size.
00:35:20.960 | So that's why if you're wondering, there's an init hidden not just in the constructor,
00:35:26.240 | but also inside forward, it's to handle this end of each epoch, start of each epoch difference.
00:35:34.680 | Not an important point by any means, but potentially confusing when you see it.
00:35:44.320 | So the last ring call.
00:35:47.640 | The last ring call is something that slightly sucks about PyTorch, and maybe somebody can
00:35:55.000 | be nice enough to try and fix it with a PR if anybody feels like it, which is that the
00:36:00.400 | loss functions such as softmax are not happy receiving a rank 3 tensor.
00:36:10.040 | Remember a rank 3 tensor is just another way of saying a dimension 3 array.
00:36:17.040 | There's no particular reason they ought to not be happy receiving a rank 3 tensor.
00:36:21.520 | Like somebody could write some code to say hey, a rank 3 tensor is probably a sequence
00:36:25.960 | length by batch size by results thing, and so you should just do it for each of the two
00:36:36.280 | initial axes.
00:36:37.280 | But no one's done that.
00:36:39.920 | And so it expects it to be a rank 2 tensor.
00:36:42.920 | Funnily enough, it can handle rank 2 or rank 4, but not rank 3.
00:36:49.640 | So we've got a rank 2 tensor containing, for each time
00:37:04.920 | period (I can't remember which way around the axes are, but whatever) for each time
00:37:11.340 | period for each batch, we've got our predictions.
00:37:19.920 | And then we've got our actuals for each time period for each batch, we've got our predictions,
00:37:31.260 | and we've got our actuals.
00:37:33.800 | And so we just want to check whether they're the same.
00:37:36.400 | And so in an ideal world, our loss function would check item 1 1, then item 1 2, and then
00:37:42.320 | item 1 3, but since that hasn't been written, we just have to flatten them both out.
00:37:48.320 | We can literally just flatten them out, put rows to rows.
00:37:53.160 | And so that's why here I have to use .view, and so .view says the number of columns will
00:38:04.800 | be equal to the size of the vocab, because remember we're going to end up with a probability
00:38:09.560 | for each letter.
00:38:11.120 | And then the number of rows is however big is necessary, which will be equal to batch
00:38:15.960 | size times bptt.
00:38:22.780 | And then you may be wondering where I do that for the target, and the answer is torch text
00:38:31.000 | knows that the target needs to look like that, so torch text has already done that for us.
00:38:35.840 | So torch text automatically changes the target to be flattened out.
00:38:40.320 | And you might actually remember if you go back to lesson 4 when we actually looked at
00:38:45.920 | a mini-batch that spat out of torch text, we noticed actually that it was flattened, and
00:38:51.640 | I said we'll learn about why later, and so later is now arrived.
00:38:58.600 | So there are the 3 wrinkles.
00:39:01.000 | Get rid of the history, I guess 4 wrinkles.
00:39:09.080 | Recreate the hidden state if the batch size changes, flatten out, and then use torch text
00:39:19.100 | to create mini-batches that line up nicely.
00:39:22.200 | So once we do those things, we can then create our model, create our optimizer with that model's
00:39:30.720 | parameters, and fit it.
00:39:38.600 | One thing to be careful of here is that softmax now, as of PyTorch 0.3, requires that we pass
00:39:56.000 | in a number here saying which axis do we want to do the softmax over.
00:40:03.040 | So at this point, this is a 3-dimensional tensor, and so we want to do the softmax over
00:40:10.160 | the final axis.
00:40:11.160 | So when I say which axis do we do the softmax over, remember we divide by, so we go e to
00:40:17.840 | the x_i divided by the sum of e to the x_i.
00:40:21.400 | So it's saying which axis do we sum over, so which axis do we want to sum to 1.
00:40:26.520 | And so in this case, clearly we want to do it over the last axis, because the last axis
00:40:31.200 | is the one that contains the probability per letter of the alphabet, and we want all of
00:40:36.360 | those probabilities to sum to 1.
00:40:40.880 | So therefore, to run this notebook, you're going to need PyTorch 0.3, which just came
00:40:48.600 | out this week.
00:40:50.040 | So if you're doing this on the MOOC, you're fine, I'm sure you've got at least 0.3 or later.
00:40:55.200 | Where else are the students here?
00:41:02.760 | The really great news is that 0.3, although it does not yet officially support Windows,
00:41:09.920 | it does in practice.
00:41:11.000 | I successfully installed 0.3 from Conda yesterday by typing Conda install PyTorch in Windows.
00:41:18.520 | I then attempted to use the entirety of Lesson 1, and every single part worked.
00:41:23.720 | So I actually ran it on this very laptop.
00:41:27.520 | So for those who are interested in doing deep learning on their laptop, I can definitely
00:41:32.280 | recommend the New Surface Book.
00:41:36.000 | The New Surface Book 15" has a GTX 1060 6GB GPU in it, and it was running about 3 times
00:41:47.800 | slower than my 1080Ti, which I think means it's about the same speed as an AWS P2 instance.
00:42:00.360 | And as you can see, it's also a nice convertible tablet that you can write on, and it's thin
00:42:05.240 | and light, so I've never seen such a good deep learning box.
00:42:11.160 | Also I successfully installed Linux on it, and all of the fastai stuff worked on the
00:42:16.920 | Linux as well, so a really good option if you're interested in a laptop that can run
00:42:22.960 | deep learning stuff.
00:42:27.720 | So that's going to be aware of with this dm= -1.
00:42:31.840 | So then we can go ahead and construct this, and we can call fit, and we're basically going
00:42:37.520 | to get pretty similar results to what we got before.
00:42:45.120 | So then we can go a bit further with our RNN by just unpacking it a bit more.
00:42:54.000 | And so this is now exactly the same thing, gives exactly the same answers, but I have
00:42:59.240 | removed the call to RNN.
00:43:02.960 | So I've got rid of this self.RNN.
00:43:08.300 | And so this is just something, I won't spend time on it, but you can check it out.
00:43:12.280 | So instead, I've now defined RNN as RNN cell, and I've copied and pasted the code above.
00:43:18.880 | Don't run it, this is just for your reference, from PyTorch.
00:43:22.640 | This is the definition of RNN cell in PyTorch.
00:43:26.040 | And I want you to see that you can now read PyTorch source code and understand it.
00:43:31.980 | Not only that, you'll recognize it as something we've done before.
00:43:35.040 | It's a matrix multiplication of the weights by the inputs plus biases.
00:43:41.400 | So f.linear simply does a matrix product followed by an addition.
00:43:46.940 | And interestingly, you'll see they do not concatenate the input bit and the hidden bit,
00:43:55.080 | they sum them together, which is our first approach.
00:43:59.480 | As I said, you can do either, neither one is right or wrong, but it's interesting to
00:44:03.120 | see that this is the definition here.
00:44:05.520 | Can you give us an insight about what are they using that particular activation function?
00:44:14.800 | I think we might have briefly covered this last week, but very happy to do it again if
00:44:23.000 | I did.
00:44:24.680 | Basically, than looks like that.
00:44:39.080 | So in other words, it's a sigmoid function, double the height -1, literally, they're equal.
00:44:47.720 | So it's a nice function in that it's forcing it to be no smaller than -1, no bigger than
00:44:56.120 | +1.
00:44:57.220 | And since we're multiplying by this weight matrix again and again and again and again,
00:45:03.040 | we might worry that a ReLU, because it's unbounded, might have more of a gradient explosion problem.
00:45:10.920 | That's basically the theory.
00:45:12.600 | Having said that, you can actually ask PyTorch for an RNN cell which uses a different nonlinearity.
00:45:25.240 | So you can see by default it uses than, but you can ask for a ReLU as well.
00:45:30.560 | But most people seem to, pretty much everybody still seems to use than as far as I can tell.
00:45:37.260 | So you can basically see here, this is all the same except now I've got an RNN cell,
00:45:41.120 | which means now I need to put my for loop back.
00:45:44.280 | And you can see every time I call my little linear function, I just append the result onto
00:45:52.880 | my list.
00:45:53.880 | And at the end, the result is that all stacked up together.
00:45:59.320 | So I'm just trying to show you how nothing inside PyTorch is mysterious, you should find
00:46:06.360 | you get basically exactly the same answer from this as the previous one.
00:46:13.720 | In practice you would never write it like this, but what you may well find in practice
00:46:17.780 | is that somebody will come up with a new kind of RNN cell, or a different way of keeping
00:46:23.440 | track of things over time, or a different way of doing regularization.
00:46:27.080 | And so inside fastai's code, you will find that we do this by hand because we use some
00:46:38.960 | regularization approaches that aren't supported by PyTorch.
00:46:45.400 | So another thing I'm not going to spend much time on but I'll mention briefly is that nobody
00:46:50.720 | really uses this RNN cell in practice.
00:46:54.480 | And the reason we don't use that RNN cell in practice is even though the than is here,
00:47:00.420 | you do tend to find gradient explosions are still a problem, so we have to use pretty
00:47:06.400 | low learning rates to get these to train, and pretty small values for bptt to get them
00:47:13.400 | to train.
00:47:15.640 | So what we do instead is we replace the RNN cell with something like this.
00:47:21.280 | This is called a GRU cell, and here's a picture of it, and there's the equations for it.
00:47:38.320 | So basically I'll show you both quickly, but we'll talk about it much more in Part 2.
00:47:44.200 | We've got our input, and our input normally gets multiplied by a weight matrix to create
00:47:57.080 | our new activations.
00:48:00.400 | That's not what happens, and then of course we add it to the existing activations.
00:48:06.600 | That's not what happens here.
00:48:07.720 | In this case, our input goes into this h_tilde temporary thing, and it doesn't just get added
00:48:16.000 | to our previous activations, but our previous activations get multiplied by this value R.
00:48:24.080 | And R stands for reset, it's a reset gate.
00:48:29.240 | And how do we calculate this value, it goes between 0 and 1 in our reset gate?
00:48:35.760 | Well the answer is, it's simply equal to a matrix product between some weight matrix
00:48:42.280 | and the concatenation of our previous hidden state and our new input.
00:48:47.600 | In other words, this is a little one hidden layer neural net.
00:48:52.920 | And in particular it's a one hidden layer neural net because we then put it through
00:48:56.360 | the sigmoid function.
00:48:58.760 | One of the things I hate about mathematical notation is symbols are overloaded a lot.
00:49:03.800 | When you see sigma, that means standard deviation.
00:49:06.640 | When you see it next to a parenthesis like this, it means the sigmoid function.
00:49:11.440 | So in other words, that which looks like that.
00:49:26.120 | So this is like a little mini-neuronet with no hidden layers, so to think of it another
00:49:29.780 | way is like a little logistic regression.
00:49:32.640 | And I mentioned this briefly because it's going to come up a lot in part 2, so it's
00:49:37.360 | a good thing to start learning about.
00:49:39.440 | It's this idea that in the very learning itself, you can have little mini-neuronets inside
00:49:47.020 | your neural nets.
00:49:48.840 | And so this little mini-neuronet is going to be used to decide how much of my hidden
00:49:54.920 | state am I going to remember.
00:49:57.320 | And so it might learn that in this particular situation, forget everything you know.
00:50:02.640 | For example, there's a full stop.
00:50:04.600 | When you see a full stop, you should throw away nearly all of your hidden state.
00:50:09.800 | That is probably something it would learn, and that's very easy for it to learn using
00:50:13.960 | this little mini-neuronet.
00:50:16.200 | And so that goes through to create my new hidden state along with the input.
00:50:22.040 | And then there's a second thing that happens, which is there's this gate here called z.
00:50:27.200 | And what z says is you've got some amount of your previous hidden state plus your new
00:50:34.240 | input, and it's going to go through to create your new state.
00:50:38.880 | And I'm going to let you decide to what degree do you use this new input version of your
00:50:45.760 | hidden state, and to what degree will you just leave the hidden state the same as before.
00:50:50.300 | So this thing here is called the update gate.
00:50:53.080 | And so it's got two choices it can make.
00:50:54.920 | The first is to throw away some hidden state when deciding how much to incorporate that
00:50:59.800 | versus my new input, and how much to update my hidden state versus just leave it exactly
00:51:05.880 | the same.
00:51:07.580 | And the equation hopefully is going to look pretty familiar to you, which is check this
00:51:13.080 | out here.
00:51:14.080 | Remember how I said you want to start to recognize some common ways of looking at things?
00:51:21.120 | Well here I have a 1 minus something by a thing, and a something without the 1 minus
00:51:30.080 | by a thing, which remember is a linear interpolation.
00:51:35.120 | So in other words, the value of z is going to decide to what degree do I have keep the
00:51:42.680 | previous hidden state, and to what degree do I use the new hidden state.
00:51:48.800 | So that's why they draw it here as this kind of like, it's not actually a switch, but you
00:51:55.480 | can put it in any position.
00:51:56.880 | You can be like, oh it's here, or it's here, or it's here to decide how much to update.
00:52:04.800 | So they're basically the equations.
00:52:06.520 | It's a little mini-neuronet with its own weight matrix to decide how much to update, a little
00:52:10.520 | mini-neuronet with its own weight matrix to decide how much to reset, and then that's
00:52:14.520 | used to do an interpolation between the two hidden states.
00:52:18.440 | So that's called a GRU, gated recurrent network.
00:52:24.600 | There's the definition from the PyTorch source code.
00:52:28.440 | They have some slight optimizations here that if you're interested in we can talk about
00:52:32.560 | them on the forum, but it's exactly the same formula we just saw.
00:52:38.580 | And so if you go nn.giu, then it uses this same code, but it replaces the RNN cell with
00:52:47.760 | this cell.
00:52:49.560 | And as a result, rather than having something where we're getting a 1.54, we're now getting
00:52:59.600 | down to 1.40, and we can keep training even more, get right down to 1.36.
00:53:05.640 | So in practice, a GRU, or very nearly equivalently, we'll see in a moment, an LSTM, is in practice
00:53:12.440 | what pretty much everybody always uses.
00:53:16.780 | So the RT and HT are ultimately scalars after they go through the sigmoid, but they're applied
00:53:25.600 | element-wise.
00:53:26.600 | Is that correct?
00:53:27.600 | Yes, although of course one for each mini-batch.
00:53:42.880 | On the excellent Chris Olar's blog, there's an understanding LSTM networks post, which
00:53:50.840 | you can read all about this in much more detail if you're interested.
00:53:54.600 | And also, the other one I was dealing with here is WildML, I also have a good blog post
00:53:59.280 | on this.
00:54:00.280 | If somebody wants to be helpful, feel free to put them in the lesson wiki.
00:54:09.960 | So then putting it all together, I'm now going to replace my GRU with an LSTM.
00:54:16.040 | I'm not going to bother showing you the cell for this, it's very similar to GRU.
00:54:20.240 | But the LSTM has one more piece of state in it called the cell state, not just the hidden
00:54:26.200 | state.
00:54:27.200 | So if you do use an LSTM, you now inside your init_hidden have to return a tuple of matrices.
00:54:33.720 | They're exactly the same size as the hidden state, but you just have to return the tuple.
00:54:40.080 | The details don't matter too much, but we can talk about it during the week if you're
00:54:44.120 | interested.
00:54:47.760 | When you pass in, you still pass in self.h, it still returns a new value of h, you still
00:54:52.080 | can repackage it in the usual way.
00:54:54.020 | So this code is identical to the code before.
00:54:57.400 | One thing I've done though is I've added dropout inside my RNN, which you can do with the PyTorch
00:55:05.000 | RNN function, so that's going to do dropout after each time step.
00:55:09.680 | And I've doubled the size of my hidden layer since I've now added 0.5 dropout, and so my
00:55:14.400 | hope was that this would be able to learn more but be more resilient as it does so.
00:55:24.440 | So then I wanted to show you how to take advantage of a little bit more fast.ai magic without
00:55:33.360 | using the layer class.
00:55:35.400 | And so I'm going to show you how to use callbacks, and specifically we're going to do SGDR without
00:55:45.600 | using the learner class.
00:55:47.760 | So to do that, we create our model again, just a standard PyTorch model.
00:55:52.680 | And this time, rather than going, remember the usual PyTorch approach is opt=optim.atom
00:56:00.200 | and you pass in the parameters and the learning rate, I'm not going to do that, I'm going to
00:56:04.400 | use the fast.ai layer optimizer class, which takes my optim class constructor from PyTorch.
00:56:16.360 | It takes my model, it takes my learning rate, and optionally takes weight decay.
00:56:24.720 | And so this class is tiny, it doesn't do very much at all.
00:56:29.700 | The key reason it exists is to do differential learning rates and differential weight decay.
00:56:35.960 | But the reason we need to use it is that all of the mechanics inside fast.ai assumes that
00:56:41.720 | you have one of these.
00:56:43.300 | So if you want to use callbacks or SGDR or whatever in code where you're not using the
00:56:50.040 | learner class, then you need to use, rather than saying opt=optim.atom, and here's my
00:56:56.840 | parameters, you instead say layer optimizer.
00:57:03.440 | So that gives us a layer optimizer object, and if you're interested, basically behind
00:57:09.840 | the scenes, you can now grab a .opt property which actually gives you the optimizer.
00:57:20.160 | You don't have to worry about that yourself, but that's basically what happens behind the
00:57:23.240 | scenes.
00:57:24.240 | The key thing we can now do is that when we call fit, we can pass in that optimizer, and
00:57:33.640 | we can also pass in some callbacks.
00:57:36.240 | And specifically we're going to use the cosine annealing callback.
00:57:41.940 | And so the cosine annealing callback requires a layer optimizer object.
00:57:47.560 | And so what this is going to do is it's going to do cosine annealing by changing the learning
00:57:52.160 | rate inside this object.
00:57:57.000 | So the details are terribly important, we can talk about them on the forum, it's really
00:58:01.120 | the concept I wanted to get across here.
00:58:03.800 | Which is that now that we've done this, we can say create a cosine annealing callback
00:58:09.120 | which is going to update the learning rates in this layer optimizer.
00:58:14.560 | The length of an epoch is equal to this here.
00:58:18.220 | How many mini batches are there in an epoch?
00:58:20.920 | Well it's whatever the length of this data loader is, because it's going to be doing the
00:58:25.680 | cosine annealing, it needs to know how often to reset.
00:58:31.480 | And then you can pass in the cycle melt in the usual way.
00:58:34.800 | And then we can even save our model automatically, like remember how there was that cycle save
00:58:41.760 | name parameter that we can pass to learn.fit?
00:58:45.080 | This is what it does behind the scenes.
00:58:46.480 | It sets an on-cycle end callback, and so here I have to find that callback as being something
00:58:53.600 | that saves my model.
00:58:57.080 | So there's quite a lot of cool stuff that you can do with callbacks.
00:59:02.400 | Callbacks are basically things where you can define at the start of training, or at the
00:59:06.320 | start of an epoch, or at the start of a batch, or at the end of training, or at the end of
00:59:09.920 | an epoch, or at the end of a batch, please call this code.
00:59:13.640 | And so we've written some for you, including SGDR, which is the cosine annealing callback.
00:59:21.760 | And then Sahar recently wrote a new callback to implement the new approach to decoupled
00:59:26.820 | rate decay.
00:59:28.760 | We use callbacks to draw those little graphs of the loss of a time, so there's lots of
00:59:34.880 | cool stuff you can do with callbacks.
00:59:36.600 | So in this case, by passing in that callback, we're getting SGDR, and that's able to get
00:59:43.480 | us down to 1.31 here, and then we can train a little bit more, and eventually get down
00:59:53.200 | to 1.25.
00:59:55.340 | And so we can now test that out.
00:59:59.520 | And so if we pass in a few characters of text, we get not surprisingly an e after 4 or thus.
01:00:07.160 | Let's do then 400, and now we have our own Nietzsche.
01:00:12.700 | So Nietzsche tends to start his sections with a number and a dot.
01:00:15.600 | So 293, perhaps that every life of values of blood, of intercourse, when it senses there
01:00:22.000 | is unscrupulous, his very rights and still impulse love.
01:00:25.920 | So it's slightly less clear than Nietzsche normally, but it gets the tone right.
01:00:33.240 | And it's actually quite interesting to play around with training these character-based
01:00:39.220 | language models, to run this at different levels of loss, to get a sense of what does
01:00:45.160 | it look like.
01:00:46.160 | You really notice that this is like 1.25, and at slightly worse, like 1.3, this looks
01:00:55.880 | like total junk.
01:00:57.440 | There's punctuation in random places and nothing makes sense.
01:01:02.560 | And you start to realize that the difference between Nietzsche and random junk is not that
01:01:09.040 | far in language model terms.
01:01:12.120 | And so if you train this for a little bit longer, you'll suddenly find it's making more
01:01:16.640 | and more sense.
01:01:18.360 | So if you are playing around with NLP stuff, particularly generative stuff like this, and
01:01:24.000 | you're like, the results are kind of okay but not great, don't be disheartened because
01:01:30.600 | that means you're actually very very nearly there.
01:01:33.520 | The difference between something which is starting to create something which almost
01:01:37.880 | vaguely looks English if you squint, and something that's actually a very good generation, it's
01:01:44.400 | not far in loss function terms.
01:01:48.800 | So let's take a 5-minute break, we'll come back at 7.45 and we're going to go back to
01:01:52.800 | computer vision.
01:02:00.920 | So now we come full circle back to vision.
01:02:09.660 | So now we're looking at lesson 7, sci-fi 10 notebook.
01:02:18.140 | You might have heard of sci-fi 10.
01:02:20.280 | It's a really well-known dataset in academia.
01:02:24.480 | And it's actually pretty old by computer vision standards, well before ImageNet was around,
01:02:33.560 | there was sci-fi 10.
01:02:34.760 | You might wonder why we're going to be looking at such an old dataset, and actually I think
01:02:41.080 | small datasets are much more interesting than ImageNet.
01:02:46.840 | Because most of the time you're likely to be working with stuff with a small number
01:02:51.340 | of thousands of images rather than 1.5 million images.
01:02:56.040 | Some of you will work with 1.5 million images, but most of you won't.
01:02:59.520 | So learning how to use these kind of datasets I think is much more interesting.
01:03:03.660 | Often also a lot of the stuff we're looking at in medical imaging, we're looking at the
01:03:08.120 | specific area where there's a lung nodule, you're probably looking at 32x32 pixels at
01:03:14.520 | most as being the area where that lung nodule actually exists.
01:03:18.720 | And so sci-fi 10 is small both in terms of it doesn't have many images, and the images
01:03:22.760 | are very small, and so therefore I think in a lot of ways it's much more challenging than
01:03:29.680 | something like ImageNet.
01:03:30.680 | In some ways it's much more interesting.
01:03:33.920 | And also, most importantly, you can run stuff much more quickly on it, so it's much better
01:03:38.580 | to test out your algorithms with something you can run quickly, and it's still challenging.
01:03:44.960 | And so I hear a lot of researchers complain about how they can't afford to study all the
01:03:50.920 | different versions of their algorithm properly because it's too expensive, and they're doing
01:03:55.400 | it on ImageNet.
01:03:56.720 | So it's literally a week of expensive GPU work for every study they do, and I don't understand
01:04:03.920 | why you would do that kind of study on ImageNet, it doesn't make sense.
01:04:08.800 | And so there's been a lot of debate about this this week because a really interesting
01:04:18.200 | researcher named Ali Rahami at NIPS this week gave a talk, a really great talk about the
01:04:24.480 | need for rigor in experiments in deep learning, and he felt like there's a lack of rigor.
01:04:31.000 | And I've talked to him about it quite a bit since that time, and I'm not sure we yet quite
01:04:38.880 | understand each other as to where we're coming from, but we have very similar kinds of concerns,
01:04:44.160 | which is basically people aren't doing carefully tuned, carefully thought about experiments,
01:04:50.280 | but instead they throw lots of GPUs and lots of data and consider that a day.
01:04:55.320 | And so this idea of saying, well, is my algorithm meant to be good at small images, at small
01:05:04.200 | data sets, well if so, let's study it on so far 10 rather than studying it on ImageNet
01:05:09.280 | and then do more studies of different versions of the algorithm, turning different bits on
01:05:13.520 | and off, understand which parts are actually important, and so forth.
01:05:19.600 | People also complain a lot about MNIST, which we've looked at before, and I would say the
01:05:24.520 | same thing about MNIST, which is like if you're actually trying to understand which parts
01:05:28.360 | of your algorithm make a difference and why, using MNIST for that kind of study is a very
01:05:32.880 | good idea.
01:05:34.120 | And all these people who complain about MNIST, I think they're just showing off.
01:05:38.320 | They're saying, I work at Google and I have a pod of TPUs and I have $100,000 a week of
01:05:44.000 | time to spend on it, no worries.
01:05:47.120 | But I think that's all it is, it's just signaling rather than actually academically rigorous.
01:05:53.560 | Okay, so sci-fi 10, you can download from here.
01:05:58.000 | This person has very kindly made it available in image form.
01:06:03.600 | If you Google for sci-fi 10, you'll find a much less convenient form, so please use this
01:06:07.720 | one.
01:06:08.720 | It's already in the exact form you need.
01:06:10.360 | Once you download it, you can use it in the usual way.
01:06:16.840 | So here's a list of the classes that are there.
01:06:21.760 | Now you'll see here I've created this thing called stats.
01:06:25.320 | Normally when we've been using pre-trained models, we have been saying transforms from
01:06:33.040 | model, and that's actually created the necessary transforms to convert our dataset into a normalized
01:06:41.960 | dataset based on the means and standard deviations of each channel in the original model that
01:06:47.880 | was trained.
01:06:48.880 | In our case, this time we've got to train a model from scratch, so we have no such thing.
01:06:54.760 | So we actually need to tell it the mean and standard deviation of our data to normalize
01:07:01.000 | it.
01:07:02.160 | And so in this case, I haven't included the code here to do it.
01:07:05.000 | You should try and try this yourself to confirm that you can do this and understand where
01:07:08.960 | it comes from.
01:07:09.960 | But this is just the mean per channel and the standard deviation per channel of all
01:07:15.120 | of the images.
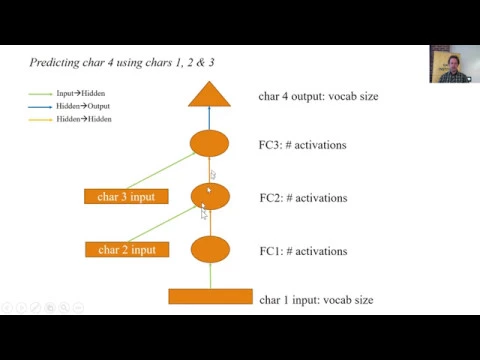
01:07:19.080 | So we're going to try and create a model from scratch.
01:07:25.300 | And so the first thing we need is some transformations.
01:07:28.680 | So for sci-fi 10, people generally do data augmentation of simply flipping randomly horizontally.
01:07:37.980 | So here's how we can create a specific list of augmentations to use.
01:07:44.400 | And then they also tend to add a little bit of black padding around the edge and then
01:07:49.560 | randomly pick a 32x32 spot from within that padded image.
01:07:54.800 | So if you add the pad parameter to any of the fastai transform creators, it'll do that
01:08:01.760 | for you.
01:08:04.080 | And so in this case, I'm just going to add 4 pixels around each size.
01:08:12.200 | And so now that I've got my transforms, I can go ahead and create my image_classifier
01:08:16.240 | data.from_paths in the usual way.
01:08:21.160 | I'm going to use a batch size of 256 because these are pretty small, so it's going to let
01:08:25.820 | me do a little bit more at a time.
01:08:28.200 | So here's what the data looks like.
01:08:30.960 | So for example, here's a boat.
01:08:33.120 | And just to show you how tough this is, what's that?
01:08:37.360 | It's a frog.
01:08:43.360 | So I guess it's this big thing, whatever the thing is called, there's your frog.
01:08:49.880 | So these are the kinds of things that we want to look at.
01:08:54.440 | So I'm going to start out, so our student, Karim, we saw one of his posts earlier in
01:08:59.560 | this course, he made this really cool notebook which shows how different optimizers work.
01:09:11.300 | So Karim made this really cool notebook, I think it was maybe last week, in which he
01:09:15.920 | showed how to create various different optimizers from scratch.
01:09:19.920 | So this is kind of like the Excel thing I had, but this is the Python version of Momentum
01:09:24.480 | and Adam and Nesterov and Adagrad, all written from scratch, which is very cool.
01:09:29.340 | One of the nice things he did was he showed a tiny little general-purpose fully connected
01:09:35.520 | network generator.
01:09:37.120 | So we're going to start with his.
01:09:38.960 | So he called that SimpleNet, so are we.
01:09:41.660 | So here's a simple class which has a list of fully connected layers.
01:09:50.200 | Whenever you create a list of layers in PyTorch, you have to wrap it in an nn.module list just
01:09:55.840 | to tell PyTorch to register these as attributes.
01:10:01.800 | And so then we just go ahead and flatten the data that comes in, because it's fully connected
01:10:05.960 | layers, and then go through each layer and call that linear layer, do the value to it,
01:10:14.060 | and at the end do a softmax.
01:10:16.400 | So there's a really simple approach, and so we can now take that model and now I'm going
01:10:23.160 | to show you how to step up one level of the API higher.
01:10:26.720 | Rather than calling the fit function, we're going to create a learn object, but we're
01:10:30.500 | going to create a learn object from a custom model.
01:10:34.720 | And so we can do that by saying we want a convolutional learner, we want to create it
01:10:38.880 | from a model and from some data, and the model is this one.
01:10:44.880 | This is just a general PyTorch model, and this is a model data object of the usual kind.
01:10:51.780 | And that will return a learner.
01:10:53.240 | So this is a bit easier than what we just saw with the RNN -- we don't have to fiddle
01:10:57.080 | around with layer optimizers and cosine annealing callbacks and whatever.
01:11:01.640 | This is now a learner that we can do all the usual stuff with, but we can do it with any
01:11:06.560 | model that we create.
01:11:10.500 | So if we just go Learn, that will go ahead and print it out.
01:11:15.520 | You can see we've got 3,072 features coming in because we've got 32 by 32 pixels by 3
01:11:22.120 | channels.
01:11:23.120 | And then we've got 40 features coming out of the first layer, that's going to go into
01:11:26.840 | the second layer, 10 features coming out because we've got the sci-fi 10 categories.
01:11:34.920 | You can call dot summary to see that in a little bit more detail.
01:11:38.520 | We can do LRfind, we can plot that, and we can then go fit, and we can use cycle length,
01:11:45.600 | and so forth.
01:11:47.320 | So with a simple -- how many hidden layers do we have?
01:11:52.720 | One hidden layer, one output layer, one hidden layer model.
01:11:59.840 | And here we can see the number of parameters we have is over 120,000.
01:12:07.560 | We get a 47% accuracy.
01:12:12.220 | So not great, so let's kind of try and improve it.
01:12:17.280 | And so the goal here is we're going to try and eventually replicate the basic architecture
01:12:23.960 | of a ResNet.
01:12:24.960 | So that's where we're going to try and get to here, to gradually build up to a ResNet.
01:12:30.560 | So the first step is to replace our fully connected model with a convolutional model.
01:12:37.080 | So to remind you, a fully connected layer is simply doing a dot product.
01:12:49.560 | So if we had all of these data points and all of these weights, then we basically do
01:13:01.040 | some product of all of those together, in other words it's a matrix model.
01:13:05.600 | And that's a fully connected layer.
01:13:09.520 | And so the weight matrix is going to contain every element of the input for every element
01:13:16.920 | of the output.
01:13:18.360 | So that's why we have here a pretty big weight matrix.
01:13:26.020 | And so that's why despite the fact that we have such a crappy accuracy, we have a lot
01:13:31.420 | of parameters because in this very first layer we've got 3072 coming in and 40 coming out,
01:13:40.560 | so that gives us 3000x40 parameters.
01:13:44.400 | And so we end up not using them very efficiently because we're basically saying every single
01:13:49.080 | pixel in the input has a different weight.
01:13:51.720 | And of course what we really want to do is find groups of 3x3 pixels that have particular
01:13:57.160 | patterns to them, and remember we call that a convolution.
01:14:02.280 | So a convolution looks like so.
01:14:12.420 | We have a little 3x3 section of our image and a corresponding 3x3 set of filters, or
01:14:21.840 | a filter with a 3x3 kernel, and we just do a sum product of just that 3x3 by that 3x3.
01:14:31.000 | And then we do that for every single part of our image.
01:14:36.580 | And so when we do that across the whole image, that's called a convolution.
01:14:40.760 | And remember, in this case we actually had multiple filters, so the result of that convolution
01:14:46.920 | actually had a tensor with an additional third dimension to it effectively.
01:14:56.920 | So let's take exactly the same code that we had before, but we're going to replace nn.linear
01:15:03.080 | with nn.com2d.
01:15:08.040 | Now what I want to do in this case is each time I have a layer, I want to make the next
01:15:14.240 | layer smaller.
01:15:16.540 | And so the way I did that in my Excel example was I used max_pooling.
01:15:23.080 | So max_pooling took every 2x2 section and replaced it with its maximum value.
01:15:31.020 | Nowadays we don't use that kind of max_pooling much at all.
01:15:36.120 | Instead nowadays what we tend to do is do what's called a Stride 2 convolution.
01:15:40.960 | A Stride 2 convolution, rather than saying let's go through every single 3x3, it says
01:15:51.040 | let's go through every second 3x3.
01:15:55.600 | So rather than moving this 3x3 1 to the right, we move it 2 to the right.
01:16:01.040 | And then when we get to the end of the row, rather than moving one row down, we move two
01:16:05.640 | rows down.
01:16:07.240 | So that's called a Stride 2 convolution.
01:16:09.740 | And so a Stride 2 convolution has the same kind of effect as a max_pooling, which is
01:16:15.100 | you end up halving the resolution in each dimension.
01:16:19.400 | So we can ask for that by saying Stride = 2.
01:16:23.960 | We can say we want it to be 3x3 by saying kernel size, and then the first two parameters
01:16:28.440 | are exactly the same as nn.linear, they're the number of features coming in and the number
01:16:32.640 | of features coming out.
01:16:35.720 | So we create a module list of those layers, and then at the very end of that, so in this
01:16:43.400 | case I'm going to say I've got three channels coming in, the first one layer will come out
01:16:48.540 | with 20, then 40, and then 80.
01:16:52.200 | So if we look at the summary, we're going to start with a 32x32, we're going to spit
01:16:56.800 | out a 15x15, and then a 7x7, and then a 3x3.
01:17:04.020 | And so what do we do now to get that down to a prediction of one of 10 classes?
01:17:11.200 | What we do is we do something called adaptive max_pooling, and this is what is pretty standard
01:17:16.880 | now for state-of-the-art algorithms, is that the very last layer we do a max_pool, but
01:17:24.720 | rather than doing a 2x2 max_pool, we say it doesn't have to be 2x2, it could have been
01:17:31.320 | 3x3, which is like replace every 3x3 pixels with its maximum, it could have been 4x4.
01:17:37.720 | Adaptive max_pool is where you say, I'm not going to tell you how big an area to pool,
01:17:43.920 | but instead I'm going to tell you how big a resolution to create.
01:17:49.760 | So if I said, for example, I think my input here is 28x28, if I said do a 14x14 adaptive
01:17:59.080 | max_pool, that would be the same as a 2x2 max_pool, because in other words it's saying
01:18:03.780 | please create a 14x14 output.
01:18:07.080 | If I said do a 2x2 adaptive max_pool, then that would be the same as saying do a 14x14
01:18:16.080 | max_pool.
01:18:17.280 | And so what we pretty much always do in modern CNNs is we make our penultimate layer a 1x1
01:18:26.360 | adaptive max_pool.
01:18:28.480 | So in other words, find the single largest cell and use that as our new activation.
01:18:39.520 | And so once we've got that, we've now got a 1x1 tensor, or actually 1x1 by number of
01:18:48.080 | features tensor.
01:18:49.920 | So we can then on top of that go x.view, x.size, -1, and actually there are no other dimensions
01:19:01.040 | to this basically.
01:19:02.960 | So this is going to return a matrix of mini-batch by number of features.
01:19:09.520 | And so then we can feed that into a linear layer with however many classes we need.
01:19:17.680 | So you can see here the last thing I pass in is how many classes am I trying to predict,
01:19:22.560 | and that's what's going to be used to create that last layer.
01:19:25.200 | So it goes through every convolutional layer, does a convolution, does a ReLU, does an adaptive
01:19:32.320 | max_pool.
01:19:34.640 | This dot view just gets rid of those trailing unit axes, the 1,1 axis, which is not necessary.
01:19:43.840 | That allows us to feed that into our final linear layer that bits out something of size
01:19:49.440 | C, which here is 10.
01:19:53.460 | So you can now see how it works.
01:19:54.800 | It goes 32 to 15 to 7x7 to 3x3.
01:19:59.960 | The adaptive max_pool makes it 80 by 1 by 1, and then our dot view makes it just mini-batch
01:20:08.160 | size by 80, and then finally a linear layer which takes it from 80 to 10, which is what
01:20:14.360 | we wanted.
01:20:16.480 | So that's our most basic -- you'd call this a fully convolutional network, so a fully convolutional
01:20:23.160 | network is something where every layer is convolutional except for the very last.
01:20:32.280 | So again, we can now go lr.find, and now in this case when I did lr.find, it went through
01:20:39.840 | the entire data set and was still getting better.
01:20:43.440 | And so in other words, the default final learning rate it tries is 10, and even at that point
01:20:48.840 | it was still pretty much getting better.
01:20:51.600 | So you can always override the final learning rate by saying end_lr=, and that'll just get
01:20:57.520 | it to try more things.
01:20:59.320 | So here is the learning rate finder, and so I picked 10^-1, trained that for a while, and
01:21:09.640 | that's looking pretty good, so then I tried it with a cycle length of 1, and it's starting
01:21:13.520 | to flatten out at about 60%.
01:21:16.360 | So you can see here the number of parameters I have here are 500, 7000, 28000, about 30,000.
01:21:28.100 | So I have about 1/4 of the number of parameters, but my accuracy has gone up from 47% to 60%.
01:21:36.640 | And the time per epoch here is under 30 seconds, and here also.
01:21:42.960 | So the time per epoch is about the same.
01:21:44.800 | And that's not surprising because when you use small simple architectures, most of the
01:21:49.060 | time is the memory transfer, the actual time during the compute is trivial.
01:21:57.820 | So I'm going to refactor this slightly because I want to try and put less stuff inside my
01:22:04.400 | forward, and so calling relu every time doesn't seem ideal.
01:22:09.160 | So I'm going to create a new class called conv_layer, and the conv_layer class is going
01:22:15.740 | to contain a convolution with a kernel size of 3 and a stride of 2.
01:22:20.960 | One thing I'm going to do now is add padding.
01:22:23.800 | Did you notice here the first layer went from 32x32 to 15x15, not 16x16?
01:22:31.620 | And the reason for that is that at the very edge of your convolution, here, see how this
01:22:43.320 | first convolution, there isn't a convolution where the middle is the top left point because
01:22:50.240 | there's nothing outside it.
01:22:52.840 | Or else if we had put a row of 0's at the top and a row of 0's at the edge of each column,
01:22:59.320 | we now could go all the way to the edge.
01:23:02.600 | So pad=1 adds that little layer of 0's around the edge for us.
01:23:11.320 | And so this way we're going to make sure that we go 32x32 to 16x16 to 8x8.
01:23:17.080 | It doesn't matter too much when you've got these bigger layers, but by the time you get
01:23:20.400 | down to 4x4, you really don't want to throw away a whole piece.
01:23:26.560 | So padding becomes important.
01:23:28.560 | So by refactoring it to put this with its defaults here, and then in the forward I'll
01:23:34.440 | put the ReLU in here as well, it makes my ConvNet a little bit smaller and more to the
01:23:41.080 | point it's going to be easier for me to make sure that everything's correct in the future
01:23:44.960 | by always using this ConvLayer class.
01:23:47.740 | So now you know not only how to create your own neural network model, but how to create
01:23:53.040 | your own neural network layer.
01:23:55.440 | So here now I can use ConvLayer.
01:23:58.880 | This is such a cool thing about PyTorch is a layer definition and a neural network definition
01:24:04.360 | are literally identical.
01:24:06.400 | They both have a constructor and a forward.
01:24:09.520 | And so anytime you've got a layer, you can use it as a neural net, anytime you have a
01:24:13.280 | neural net, you can use it as a layer.
01:24:16.800 | So this is now the exact same thing as we had before.
01:24:20.320 | One difference is I now have padding.
01:24:23.380 | And another thing just to show you, you can do things differently.
01:24:26.060 | Back here, my max_pull I did as an object, I used the class nn.adaptive_max_pull, and
01:24:35.440 | I stuck it in this attribute and then I called it.
01:24:38.560 | But this actually doesn't have any state.
01:24:40.760 | There's no weights inside max_pulling, so I can actually do it with a little bit less
01:24:45.440 | code by calling it as a function.
01:24:49.000 | So everything that you can do as a class, you can also do as a function inside this
01:24:52.760 | capital F which is nn.functional.
01:24:58.200 | So this should be a tiny bit better because this time I've got the padding.
01:25:05.080 | I didn't train it for as long to actually check, so let's skip over that.
01:25:13.640 | So one issue here is that in the end, when I tried to add more layers, I had trouble
01:25:23.280 | training it.
01:25:25.960 | The reason I was having trouble training it was if I used larger learning rates, it would
01:25:30.920 | go off to nin, and if I used smaller learning rates, it kind of takes forever and doesn't
01:25:35.560 | really have a chance to explore properly.
01:25:38.320 | So it wasn't resilient.
01:25:40.420 | So to make my model more resilient, I'm going to use something called batch normalization,
01:25:45.840 | which literally everybody calls batchnorm.
01:25:48.360 | And batchnorm is a couple of years old now, and it's been pretty transformative since
01:25:55.320 | it came along because it suddenly makes it really easy to train deeper networks.
01:26:01.880 | So the network I'm going to create is going to have more layers.
01:26:05.120 | I've got 1, 2, 3, 4, 5 convolutional layers plus a fully connected layer.
01:26:10.840 | So back in the old days, that would be considered a pretty deep network and we'd be considered
01:26:15.360 | pretty hard to train.
01:26:16.840 | Nowadays it's super simple thanks to batchnorm.
01:26:20.700 | Now to use batchnorm, you can just write in nn.batchnorm, but to learn about it, we're
01:26:25.800 | going to write it from scratch.
01:26:28.240 | So the basic idea of batchnorm is that we've got some vector of activations.
01:26:36.440 | Any time I draw a vector of activations, obviously I mean you can repeat it for the minibatch,
01:26:40.280 | so pretend it's a minibatch of 1.
01:26:41.840 | So we've got some vector of activations, and it's coming into some layer, so probably some
01:26:49.840 | convolutional matrix multiplication, and then something comes out the other side.
01:26:56.600 | So imagine this is just a matrix multiply, say it was an identity matrix.
01:27:11.160 | Then every time I multiply it by that across lots and lots of layers, my activations are
01:27:15.360 | not getting bigger, they're not getting smaller, they're not changing at all.
01:27:19.960 | That's all fine, but imagine if it was actually like 2, 2, 2.
01:27:27.160 | And so if every one of my weight matrices or filters was like that, then my activations
01:27:32.200 | are doubling each time.
01:27:34.760 | And so suddenly I've got this exponential growth, and in deep models that's going to
01:27:41.040 | be a disaster because my gradients are exploding at an exponential rate.
01:27:46.840 | And so the challenge you have is that it's very unlikely unless you try carefully to
01:27:54.600 | deal with it that your weight matrices on average are not going to cause your activations
01:28:03.040 | to keep getting smaller and smaller, or keep getting bigger and bigger.
01:28:06.280 | You have to carefully control things to make sure that they stay at a reasonable size,
01:28:12.440 | you want to keep them at a reasonable scale.
01:28:16.760 | So we start things off with 0 mean standard deviation 1 by normalizing the inputs, but
01:28:23.920 | what we'd really like to do is to normalize every layer, not just the inputs.
01:28:31.440 | And so, okay, fine, let's do that.
01:28:36.620 | So here I've created a bn layer which is exactly like my conv layer.
01:28:40.800 | It's got my conv2d with my stride, my padding.
01:28:45.200 | I do my conv and my relu, and then I calculate the mean of each channel or of each filter,
01:28:55.560 | and the standard deviation of each channel or each filter, and then I subtract the means
01:29:00.980 | and divide by the standard deviations.
01:29:04.540 | So now I don't actually need to normalize my input at all because it's actually going
01:29:10.760 | to do it automatically.
01:29:12.240 | It's normalizing it per channel, and for later layers it's normalizing it per filter.
01:29:21.120 | So it turns out that's not enough because SGD is bloody-minded.
01:29:29.960 | And so if SGD decided that it wants the weight matrix to be like so, where that matrix is
01:29:37.480 | something which is going to increase the values overall repeatedly, then subtract the means
01:29:46.720 | and divide by the standard deviations just means the next mini-batch is going to try
01:29:50.880 | and do it again.
01:29:53.880 | So it turns out that this actually doesn't help, it literally does nothing because SGD
01:30:00.680 | is just going to go ahead and undo the next mini-batch.
01:30:06.280 | So what we do is we create a new multiplier for each channel and a new added value for
01:30:18.600 | each channel, and we just start them out as the addition is just a bunch of zeros, so for
01:30:25.440 | the first layer, 3 zeros, and the multiplier for the first layer is just 3 ones.
01:30:31.360 | So the number of filters for the first layer is just 3.
01:30:35.060 | And so we then basically undo exactly what we just did, or potentially we undo them.
01:30:42.160 | So by saying this is an nn.parameter, that tells PyTorch you're allowed to learn these
01:30:48.220 | as weights.
01:30:50.400 | So initially it says subtract the means, divide by the standard deviations, multiply by 1,
01:30:57.820 | add on 0, okay that's fine, nothing much happened there.
01:31:07.280 | Like if it wants to kind of scale the layer up, it doesn't have to scale up every single
01:31:13.000 | value in the matrix, it can just scale up this single trio of numbers, self.m.
01:31:21.240 | If it wants to shift it all up or down a bit, it doesn't have to shift the entire weight
01:31:25.480 | matrix, it can just shift this trio of numbers, self.a.
01:31:31.980 | So I will say this, at this talk I mentioned at Nip's Ali Rahimi's talk about rigor, he
01:31:38.080 | actually pointed to this batch norm paper as being a particularly useful, particularly
01:31:46.160 | interesting paper where a lot of people don't necessarily know why it works.
01:31:56.080 | And so if you're thinking subtracting out the means and then adding some learned weights
01:32:02.000 | of exactly the same rank and size sounds like a weird thing to do, there are a lot of people
01:32:11.280 | that feel the same way.
01:32:13.480 | So at the moment I think the best is intuitively what's going on here is that we're normalizing
01:32:22.480 | the data and then we're saying you can then shift it and scale it using far fewer parameters
01:32:31.400 | than would have been necessary if I was asking you to actually shift and scale the entire
01:32:36.620 | set of convolutional filters.
01:32:39.480 | That's the kind of basic intuition.
01:32:42.040 | More importantly, in practice, what this does is it basically allows us to increase our learning
01:32:51.660 | rates and it increases the resilience of training and allows us to add more layers.
01:32:56.960 | So once I added a bn layer rather than a conv layer, I found I was able to add more layers
01:33:08.620 | to my model and it's still trained effectively.
01:33:12.240 | Question 6 Are we worried about anything that maybe we are divided by something very small
01:33:21.880 | or anything like that?
01:33:25.880 | Once we do this...
01:33:26.880 | Answer 7 Yeah, probably.
01:33:27.880 | I think in the PyTorch version it would probably be divided by self.studs plus epsilon or something.
01:33:38.480 | This worked fine for me, but that is definitely something to think about if you were trying
01:33:45.040 | to make this more reliable.
01:33:46.840 | Question 8 So the self.m and self.a, I'm guessing it's
01:33:55.600 | getting updated through backpropagation as well?
01:33:58.400 | Answer 9 Yeah, so by saying it's an nn.parameter, that's
01:34:02.360 | how we flag to PyTorch to learn it through backprop.
01:34:09.880 | The other interesting thing it turns out that BatchNorm does is it regularizes.
01:34:16.000 | In other words, you can often decrease or remove dropout or decrease or remove weight
01:34:21.120 | decay when you use BatchNorm.
01:34:23.720 | And the reason why is if you think about it, each many batch is going to have a different
01:34:30.280 | mean and a different standard deviation to the previous mini-batch.
01:34:34.440 | So these things keep changing.
01:34:37.080 | Because they keep changing, it's kind of changing the meaning of the filters in this subtle way.
01:34:42.840 | And so it's adding a regularization effect because it's noise.
01:34:46.240 | When you add noise of any kind, it regularizes your model.
01:34:52.440 | I'm actually cheating a little bit here.
01:34:55.560 | In the real version of BatchNorm, you don't just use this batch's mean and standard deviation,
01:35:02.560 | but instead you take an exponentially weighted moving average standard deviation and mean.
01:35:09.020 | And so if you wanted to exercise to try during the week, that would be a good thing to try.
01:35:14.240 | But I will point out something very important here, which is if self.training.
01:35:19.560 | When we are doing our training loop, this will be true when it's being applied to the
01:35:27.580 | training set, and it will be false when it's being applied to the validation set.
01:35:33.200 | And this is really important because when you're going through the validation set, you
01:35:36.560 | do not want to be changing the meaning of the model.
01:35:41.280 | So this really important idea is that there are some types of layer that are actually
01:35:48.240 | sensitive to what the mode of the network is, whether it's in training mode or, as PyTorch
01:35:56.560 | calls it, evaluation mode, or we might say test mode.
01:36:02.160 | We actually had a bug a couple of weeks ago when we did our Mininet for MovieLens, the
01:36:08.080 | collaborative filtering, we actually had f.dropout in our forward pass without protecting it with
01:36:14.800 | a if self.training f.dropout, as a result of which we were actually doing dropout in
01:36:21.560 | the validation piece as well as the training piece, which obviously isn't what you want.
01:36:27.240 | So I've actually gone back and fixed this by changing it to using an n.dropout.
01:36:34.360 | And nn.dropout has already been written for us to check whether it's being used in training
01:36:39.360 | mode or not.
01:36:41.520 | Or alternatively, I could have added an if self.training before I use the dropout here.
01:36:49.640 | So it's important to think about that, and the main two, or pretty much the only two
01:36:55.280 | built into PyTorch where this happens is dropout and that's not.
01:37:02.240 | And so interestingly, this is also a key difference in fast.ai, which no other library does, is
01:37:09.480 | that these means and standard deviations get updated in training mode in every other library
01:37:20.400 | as soon as you basically say I'm training, regardless of whether that layer is set to
01:37:24.840 | trainable or not.
01:37:27.100 | And it turns out that with a pre-trained network, that's a terrible idea.
01:37:31.400 | If you have a pre-trained network, the specific values of those means and standard deviations
01:37:36.040 | in batch norm, if you change them, it changes the meaning of those pre-trained layers.
01:37:41.640 | And so in fast.ai, always by default it won't touch those means and standard deviations
01:37:47.580 | if your layer is frozen.
01:37:49.760 | As soon as you unfreeze it, it'll start updating them.
01:37:55.520 | Unless you've set learn.bnfreeze true.
01:38:01.040 | If you set learn.bnfreeze true, it says never touch these means and standard deviations.
01:38:06.920 | And I've found in practice that that often seems to work a lot better for pre-trained
01:38:14.800 | models, particularly if you're working with data that's quite similar to what the pre-trained
01:38:19.360 | model was trained with.
01:38:21.560 | So, I have two questions.
01:38:29.160 | Looks like you did a lot more work calculating the aggregates, you know, as you...
01:38:33.480 | Looks like I did a lot of work, did you say?
01:38:36.680 | Like quite a lot of code here?
01:38:38.040 | Well, you're doing more work than you would normally do, essentially you're calculating
01:38:42.800 | all these aggregates as you go through each layer.
01:38:45.680 | Yes.
01:38:46.680 | Wouldn't this mean you're training like your epoch time loser?
01:38:52.040 | Now this is super fast.
01:38:53.680 | If you think about what a conv has to do, a conv has to go through every 3x3 with a stride
01:39:01.960 | and do this multiplication and then addition.
01:39:05.240 | That is a lot more work than simply calculating the per-channel mean.
01:39:11.600 | So it adds a little bit of time, but it's less time-intensive than the convolution.
01:39:18.000 | So how would you basically position the batch norm?
01:39:21.240 | Would it be right after the convolutional layer, or would it be after the relu?
01:39:26.080 | Yeah, we'll talk about that in a moment.
01:39:28.680 | So at the moment, we have it after the relu, and in the original batch norm paper, I believe
01:39:35.200 | that's where they put it.
01:39:41.120 | So there's this idea of something called an ablation study, and an ablation study is something
01:39:48.720 | where you basically try kind of turning on and off different pieces of your model to
01:39:56.180 | see which bits make which impacts.
01:39:58.840 | And one of the things that wasn't done in the original batch norm paper was any kind
01:40:02.980 | of really effective ablation study, and one of the things therefore that was missing was
01:40:08.040 | this question which you just asked, which is where do you put the batch norm, before
01:40:12.360 | the relu, after the relu, whatever.
01:40:14.400 | And so since that time, that oversight has caused a lot of problems because it turned
01:40:20.200 | out the original paper didn't actually put it in the best spot.
01:40:25.000 | And so then other people since then have now figured that out, and now every time I show
01:40:29.060 | people code where it's actually in the spot that turns out to be better, people always
01:40:33.380 | say your batch norm is in the wrong spot, and I have to go back and say no, I know that's
01:40:37.720 | what the paper said, but it turned out that's not actually the right spot, and so it's kind
01:40:40.920 | of caused this confusion.
01:40:42.680 | So there's been a lot of question about that.
01:40:46.000 | So, a little bit of a higher level question, so we started out with CIFAR data, so is the
01:40:58.440 | basic reasoning that you use a smaller data set to quickly train a new model, and then
01:41:06.480 | you take the same model and you're using a much bigger data set to get a higher accuracy
01:41:15.800 | level?
01:41:16.800 | Is that the basic question?
01:41:18.580 | Maybe.
01:41:19.580 | So if you had a large data set, or if you were interested in the question of how good
01:41:28.000 | is this technique on a large data set, then yes, what you just said would be what I would
01:41:32.240 | do.
01:41:33.240 | I would do lots of testing on a small data set which I had already discovered had the
01:41:38.640 | same kinds of properties as my larger data set, and therefore my conclusions would likely
01:41:43.260 | carry forward and then I would test them at the end.
01:41:46.200 | Having said that, personally, I'm actually more interested in actually studying small
01:41:53.640 | data sets for their own sake because I find most people I speak to in the real world don't
01:42:00.960 | have a million images, they have somewhere between about 2,000 and 20,000 images seems
01:42:06.460 | to be much more common.
01:42:09.640 | So I'm very interested in having fewer rows because I think it's more valuable in practice.
01:42:17.800 | I'm also pretty interested in small images, not just for the reason you mentioned which
01:42:22.120 | is it allows me to test things out more quickly, but also as I mentioned before, often a small
01:42:28.640 | part of an image actually turns out to be what you're interested in that's certainly
01:42:32.540 | true in medicine.
01:42:37.160 | I have two questions.
01:42:39.040 | The first is on what you mentioned in terms of small data sets, particularly medical imaging
01:42:44.440 | if you've heard of, I guess, is it vicarious to start up in the specialization and one
01:42:48.480 | shot learning?
01:42:49.480 | So your opinions on that, and then the second being, this is related to I guess Ali's talk
01:42:56.600 | at NIPS, so I don't want to say it's controversial, but like Yann LeCun, there was like a really,
01:43:02.000 | I guess, controversial thread attacking it in terms of what you're talking about as a
01:43:05.920 | baseline of theory just not keeping up with practice.
01:43:11.080 | And so I guess I was starting with Yann, whereas Ali actually, he tweeted at me quite a bit
01:43:15.760 | trying to defend like he wasn't attacking Yann at all, but in fact, he was trying to
01:43:23.760 | support him, but I just kind of feel like a lot of theory as you go is just sort of
01:43:28.920 | added data.
01:43:29.920 | It's hard to keep up other than an archive from Andre Keparthi to keep up, but if the
01:43:35.040 | theory isn't keeping up but the industry is the one that's actually setting the standard,
01:43:38.520 | then doesn't that mean that people who are actual practitioners are the ones like Yann
01:43:43.920 | LeCun that are publishing the theory that are keeping up to date, or is like academic
01:43:47.480 | research institutions are actually behind?
01:43:49.420 | So I don't have any comments on the vicarious papers because I haven't read them.
01:43:52.960 | I'm not aware of any of them as actually showing better results than other papers, but I think
01:44:00.960 | they've come a long way in the last 12 months, so that might be wrong.
01:44:05.720 | I think the discussion between Yann LeCun and Ali Rahimi is very interesting because
01:44:09.040 | they're both smart people who have interesting things to say.
01:44:12.680 | Unfortunately, a lot of people talk Ali's talk as meaning something which he says it
01:44:20.040 | didn't mean, and when I listen to his talk I'm not sure he didn't actually mean it at
01:44:24.880 | the time, but he clearly doesn't mean it now, which is, he's now said many times he was
01:44:30.160 | not talking about theory, he was not saying we need more theory at all.
01:44:34.920 | Actually he thinks we need more experiments.
01:44:37.320 | And so specifically he's also now saying he wished he hadn't used the word rigor, which
01:44:42.880 | I also wish because rigor is kind of meaningless and everybody can kind of say when he says
01:44:48.680 | rigor he means the specific thing I study.
01:44:55.680 | So lots of people have kind of taken his talk as being like "Oh yes, this proves that nobody
01:45:00.080 | else should work in neural networks unless they are experts at the one thing I'm an expert
01:45:05.200 | in."
01:45:06.200 | So I'm going to catch up with him and talk more about this in January and hopefully we'll
01:45:11.600 | figure some more stuff out together.
01:45:13.120 | But basically what we can clearly agree on, and I think Yann LeCun also agrees on, is careful
01:45:22.000 | experiments are important, just doing things on massive amounts of data using massive amounts
01:45:28.080 | of TPUs or GPUs is not interesting of itself, and we should instead try to design experiments
01:45:35.120 | that give us the maximum amount of insight into what's going on.
01:45:38.400 | So Jeremy, is it a good statement to say something like, so dropout and bashnorm are very different
01:45:52.160 | things.
01:45:53.160 | Dropout is a regularization technique and bashnorm has maybe some realization effect
01:45:59.400 | but it's actually just about convergence of the optimization method.
01:46:04.040 | And I would further say I can't see any reason not to use batchnorm.
01:46:13.920 | There are versions of batchnorm that in certain situations turned out not to work so well,
01:46:20.560 | but people have figured out ways around that for nearly every one of those situations now.
01:46:26.240 | So I would always seek to find a way to use batchnorm.
01:46:30.800 | It may be a little harder in RNNs at least, but even there, there are ways of doing batchnorm
01:46:38.320 | in RNNs as well.
01:46:41.080 | Try and always use batchnorm on every layer if you can.
01:46:44.440 | The question that somebody asked is, does it mean I can stop normalizing my data?
01:47:03.400 | It does, although do it anyway because it's not at all hard to do it, and at least that
01:47:06.240 | way the people using your data, I don't know, they kind of know how you've normalized it.
01:47:12.920 | And particularly with these issues around a lot of libraries, in my opinion, my experiments
01:47:21.800 | don't deal with batchnorm correctly for pre-trained models.
01:47:26.680 | Just remember that when somebody starts retraining, those averages and stuff are going to change
01:47:32.320 | for your dataset, and so if your new dataset has very different input averages, it could
01:47:36.640 | really cause a lot of problems.
01:47:40.440 | So yeah, I went through a period where I actually stopped normalizing my data, and things kind
01:47:46.660 | of worked, but it's probably not worth it.
01:47:54.520 | So the rest of this is identical.
01:47:57.280 | All I've done is I've changed conv_layer to bn_layer, but I've done one more thing, which
01:48:03.720 | is I'm trying to get closer and closer to modern approaches, which I've added a single
01:48:08.480 | convolutional layer at the start, with a bigger kernel size and a stride of 1.
01:48:16.600 | Why have I done that?
01:48:18.640 | So the basic idea is that I want my first layer to have a richer input.
01:48:25.960 | So before my first layer had an input of just 3, because it was just 3 channels.
01:48:31.360 | But if I start with my image, and I kind of take a bigger area, and I do a convolution
01:48:50.320 | using that bigger area, in this case I'm doing 5x5, then that kind of allows me to try and
01:49:00.800 | find more interesting, richer features in that 5x5 area.
01:49:06.640 | And so then I spit out a bigger output, in this case I spit out 10 5x5 filters.
01:49:15.620 | And so the idea is pretty much every state-of-the-art convolutional architecture now starts out
01:49:21.840 | with a single conv layer with like a 5x5 or 7x7 or sometimes even like 11x11 convolution
01:49:32.000 | with quite a few filters, something like 32 filters coming out.
01:49:41.200 | And it's just a way of trying to -- because I used a stride of 1 and a padding of kernel
01:49:49.220 | size -1/2, that means that my output is going to be exactly the same size as my input, but
01:49:55.040 | just got more filters.
01:49:56.440 | So this is just a good way of trying to create a richer starting point for my sequence of
01:50:03.400 | convolutional layers.
01:50:05.640 | So that's the basic theory of why I've added this single convolution, which I just do once
01:50:11.140 | at the start, and then I just go through all my layers, and then I do my adaptive max pooling
01:50:16.440 | and my final classifier layer.
01:50:19.000 | So it's a minor tweak, but it helps.
01:50:22.960 | And so you'll see now I can go from 60% and after a couple it's 45%, now after a couple
01:50:34.360 | it's 57%, and after a few more I'm up to 68%.
01:50:38.760 | So you can see the batch norm and tiny bit, the conv layer at the start, it's helping.
01:50:45.160 | And what's more, you can see this is still increasing.
01:50:48.840 | So that's looking pretty encouraging.
01:50:52.160 | So given that this is looking pretty good, an obvious thing to try is to try increasing
01:51:02.000 | the depth of the model.
01:51:03.680 | And now I can't just add more of my stride 2 layers, because remember how at half the
01:51:10.800 | size of the image each time?
01:51:12.640 | I'm basically down to 2x2 at the end, so I can't add much more.
01:51:18.080 | So what I did instead was I said, okay, here's my original layers, these are my stride 2 layers,
01:51:24.360 | for every one also create a stride 1 layer.
01:51:28.280 | So a stride 1 layer doesn't change the size.
01:51:30.940 | And so now I'm saying zip my stride 2 layers and my stride 1 layers together, and so first
01:51:38.920 | of all do the stride 2 and then do the stride 1.
01:51:42.300 | So this is now actually twice as deep, but I end up with the exact same 2x2 that I had
01:51:57.040 | before.
01:51:58.760 | And so if I try this, here after 1, 2, 3, 4 epochs is at 65%, after 1, 2, 3 epochs I'm
01:52:07.080 | still at 65%.
01:52:08.080 | It hasn't helped.
01:52:10.960 | And so the reason it hasn't helped is I'm now too deep even for batch norm to handle
01:52:19.720 | it.
01:52:20.720 | So my depth is now 1, 2, 3, 4, 5 times 2 is 10, 11, conv1, 12.
01:52:31.100 | So 12 layers deep, it's possible to train a standard convNet 12 layers deep, but it
01:52:36.800 | starts to get difficult to do it properly.
01:52:39.480 | And it certainly doesn't seem to be really helping much, if at all.
01:52:43.100 | So that's where I'm instead going to replace this with a ResNet.
01:52:49.120 | So ResNet is our final stage, and what a ResNet does is I'm going to replace our BN layer,
01:52:57.880 | I'm going to inherit from BN layer, and replace our forward with that.
01:53:04.080 | And that's it, everything else is going to be identical.
01:53:07.840 | But now I'm going to do way lots of layers, I'm going to make it 4 times deeper, and it's
01:53:13.160 | going to train beautifully, just because of that.
01:53:18.680 | So why does that help so much?
01:53:22.120 | So this is called a ResNet block, and as you can see I'm saying my predictions equals my
01:53:36.240 | input plus some function, in this case a convolution of my input.
01:53:44.360 | That's what I've written here.
01:53:47.460 | And so I'm now going to shuffle that around a little bit.
01:53:53.120 | And I'm going to say f(x) = y - x.
01:54:05.720 | So that's the same thing shuffled around.
01:54:09.440 | That's my prediction from the previous layer.
01:54:14.680 | And so what this is then doing is it's trying to fit a function to the difference between
01:54:20.540 | these two.
01:54:22.580 | And so the difference is actually the residual.
01:54:36.860 | So if this is what I'm trying to calculate, my actual y value, and this is the thing that
01:54:45.560 | I've most recently calculated, then the difference between the two is basically the error in
01:54:51.140 | terms of what I've calculated so far.
01:54:53.920 | And so this is therefore saying that try to find a set of convolutional weights that attempts
01:55:01.200 | to fill in the amount I was off by.
01:55:06.920 | So in other words, if we have some inputs coming in, and then we have this function
01:55:17.600 | which is basically trying to predict the error, it's like how much are we off by, right?
01:55:24.480 | And then we add that on.
01:55:25.960 | So we basically add on this additional prediction of how much were we wrong by.
01:55:31.020 | And then we add on another prediction of how much were we wrong by that time.
01:55:35.240 | And add on another prediction of how much were we wrong by that time.
01:55:38.520 | Then each time we're kind of zooming in, getting closer and closer to our correct answer.
01:55:45.720 | And each time we're saying we've got to a certain point, but we've still got an error.
01:55:51.440 | We've still got a residual.
01:55:53.320 | So let's try and create a model that just predicts that residual, and add that onto
01:55:58.120 | our previous model.
01:55:59.120 | And then let's build another model that predicts the residual, and add that onto our previous
01:56:03.360 | model.
01:56:04.360 | And if we keep doing that again and again, we should get closer and closer to our answer.
01:56:10.760 | And this is based on a theory called boosting, which people that have done some machine learning
01:56:16.680 | will have certainly come across.
01:56:18.960 | And so basically the trick here is that by specifying that as being the thing that we're
01:56:30.440 | trying to calculate, then we kind of get boosting for free.
01:56:40.680 | It's because we can just juggle that around to show that actually it's just calculating
01:56:45.760 | a model on the residual.
01:56:48.440 | So that's kind of amazing.
01:56:52.200 | And it totally works.
01:56:55.920 | As you can see here, I've now got my standard batch norm layer, which is something which
01:57:02.200 | is going to reduce my size by 2 because it's got the stride 2.
01:57:06.960 | And then I've got a ResNet layer of stride 1, and another ResNet layer of stride 1.
01:57:11.560 | I think I said that was 4 of these, it's actually 3 of these.
01:57:15.580 | So this is now 3 times deeper, I've zipped through all of those.
01:57:19.120 | And so I've now got a function of a function of a function.
01:57:23.440 | So 3 layers per group, and then my conv at the start, and my linear at the end.
01:57:30.680 | So this is now 3 times bigger than my original.
01:57:35.440 | And if I fit it, you can see it just keeps going up, and up, and up, and up.
01:57:40.560 | I keep fitting it more, it keeps going up, and up, and up, and up, and up.
01:57:44.800 | And it's still going up when I kind of got bored.
01:57:48.940 | So the ResNet has been a really important development, and it's allowed us to create
01:58:00.000 | these really deep networks.
01:58:04.000 | The full ResNet does not quite look the way I've described it here.
01:58:09.480 | The full ResNet doesn't just have one convolution, but it actually has two convolutions.
01:58:16.440 | So the way people normally draw ResNet blocks is they normally say you've got some input
01:58:21.400 | coming into the layer, it goes through one convolution, two convolutions, and then gets
01:58:31.800 | added back to the original input.
01:58:36.440 | That's the full version of a ResNet block.
01:58:38.960 | In my case, I've just done one convolution.
01:58:42.920 | And then you'll see also, in every block, one of them is not a ResNet block, but a standard
01:59:00.880 | convolution with a stride of 2.
01:59:06.000 | This is called a bottleneck layer, and the idea is this is not a ResNet block.
01:59:11.040 | So from time to time, we actually change the geometry, we're doing the stride too.
01:59:16.600 | In ResNet, we don't actually use just a standard convolutional layer, there's actually a different
01:59:22.080 | form of bottleneck block that I'm not going to teach you in this course, I'm going to
01:59:25.800 | teach you in Part 2.
01:59:26.880 | But as you can see, even this somewhat simplified version of a ResNet still works pretty well.
01:59:33.160 | And so we can make it a little bit bigger.
01:59:38.360 | And so here I've just increased all of my sizes, I have still got my 3, and also I've
01:59:45.120 | added dropout.
01:59:46.920 | So at this point, I'm going to say this is, other than the minor simplification of ResNet,
01:59:52.680 | a reasonable approximation of a good starting point for a modern architecture.
01:59:58.560 | And so now I've added in my point 2 dropout, I've increased the size here, and if I train
02:00:03.720 | this, I can train it for a while, it's going pretty well, I can then add in TTA at the end,
02:00:10.440 | eventually I get 85%.
02:00:12.800 | And this is at a point now where literally I wrote this whole notebook in like 3 hours.
02:00:18.560 | We can create this thing in 3 hours, and this is like an accuracy that in 2012, 2013 was
02:00:26.320 | considered pretty much state-of-the-art for SciFi 10.
02:00:30.560 | Nowadays, the most recent results are like 97%, there's plenty of room we can still improve,
02:00:43.360 | but they're all based on these techniques.
02:00:45.600 | There isn't really anything -- when we start looking in Part 2 at how to get this right
02:00:52.640 | up to state-of-the-art, you'll see it's basically better approaches to data augmentation, better
02:00:57.360 | approaches to regularization, some tweaks on ResNet, but it's all basically this idea.
02:01:04.400 | "So is the training on the residual method, is that only, looks like it's a generic thing
02:01:15.200 | that can be applied, non-image problems?"
02:01:18.000 | Oh, great question.
02:01:19.400 | Yeah, yes it is, but it's been ignored everywhere else.
02:01:24.360 | In NLP, something called the transformer architecture recently appeared, and it was shown to be the
02:01:31.400 | state-of-the-art for translation, and it's got a simple ResNet structure in it.
02:01:38.480 | First time I've ever seen it in NLP.
02:01:40.000 | I haven't really seen anybody else take advantage of it.
02:01:44.600 | This general approach, we call these skip connections, this idea of skipping over a
02:01:48.400 | layer and doing an identity, it's been appearing a lot in computer vision and nobody else much
02:01:55.400 | seems to be using it, even though there's nothing computer vision specific about it.
02:01:59.680 | So I think it's a big opportunity.
02:02:03.780 | So final stage I want to show you is how to use an extra feature of PyTorch to do something
02:02:12.600 | cool, and it's going to be a segue into Part 2.
02:02:16.720 | It's going to be our first little hint as to what else we can build on these neural nets.
02:02:22.280 | It's also going to take us all the way back to lesson 1, which is we're going to do dogs
02:02:26.960 | and cats.
02:02:29.080 | So going all the way back to dogs and cats, we're going to create a ResNet-34.
02:02:34.700 | So these different ResNet-34, 50, 101, they're basically just different numbers, different
02:02:43.640 | size blocks, it's like how many of these pieces do you have before each bottleneck block, and
02:02:49.960 | then how many of these sets of super blocks do you have.
02:02:53.840 | That's all these different numbers mean.
02:02:55.880 | So if you look at the TorchVision source code, you can actually see the definition of these
02:03:01.720 | different ResNets, you'll see they're all just different parameters.
02:03:09.440 | So we're going to use ResNet-34, and so we're going to do this a little bit more by hand.
02:03:16.240 | So if this is my architecture, this is just the name of a function, then I can call it
02:03:21.280 | to get that model.
02:03:23.160 | And then true, if we look at the definition, is do I want the pre-trained, so in other
02:03:28.600 | words, is it going to load in the pre-trained image net weights.
02:03:32.560 | So m now contains a model, and so I can take a look at it like so.
02:03:39.600 | And so you can see here what's going on is that inside here I've got my initial 2D convolution,
02:03:50.400 | and here is that kernel size of 7x7.
02:03:54.120 | And interestingly in this case, it actually starts out with a 7x7 strived 2.
02:03:58.680 | There's the padding that we talked about to make sure that we don't lose the edges.
02:04:02.520 | There's our batchnorm, there's our ReLU, and you get the idea, right?
02:04:08.520 | And then so here you can now see there's a layer that contains a bunch of blocks.
02:04:15.120 | So here's a block which contains a conv, batchnorm, ReLU, conv, batchnorm.
02:04:20.600 | You can't see it printed, but after this is where it does the addition.
02:04:25.680 | So there's like a whole ResNet block, and then another ResNet block, and then another
02:04:29.280 | ResNet block.
02:04:33.560 | And then you can see also sometimes you see one where there's a strived 2.
02:04:40.760 | So here's actually one of these bottleneck layers.
02:04:47.240 | So you can kind of see how this is structured.
02:04:51.440 | So in our case, sorry I skipped over this a little bit, but the approach that we ended
02:05:00.280 | up using for ReLU was to put it before our batchnorm, which we've got batchnorm, ReLU,
02:05:24.520 | conv, batchnorm, ReLU, conv.
02:05:26.160 | So you can see the order that they're using it here.
02:05:29.600 | And you'll find there's 3 different versions of ResNet floating around.
02:05:36.520 | The one which actually turns out to be the best is called the Preact ResNet, which has
02:05:41.840 | a different ordering again, but you can look it up.
02:05:48.160 | It's basically a different order of where the ReLU and where the batchnorm sit.
02:05:53.240 | So we're going to start with a standard ResNet 34, and normally what we do is we need to
02:06:01.000 | now turn this into something that can predict dogs versus cats.
02:06:06.480 | So currently the final layer has 1000 features because ImageNet has 1000 features.
02:06:14.040 | So we need to get rid of this.
02:06:16.500 | So when you use conf-learner from pre-trained in fast.ai, it actually deletes this layer
02:06:23.280 | for you, and it also deletes this layer.
02:06:29.440 | And something that as far as I know is unique to fast.ai is we see this average pooling
02:06:35.840 | layer of size 7x7, so this is basically the adaptive pooling layer.
02:06:41.320 | But whoever wrote this didn't know about adaptive pooling, so they manually said I know it's
02:06:45.380 | meant to be 7x7.
02:06:47.520 | So in fast.ai, we replace this with adaptive pooling, but we actually do both adaptive average
02:06:52.120 | pooling and adaptive max pooling, and we then concatenate the two together, which is something
02:07:00.080 | we invented, but at the same time we invented it, somebody wrote a paper about it, so we
02:07:05.560 | don't get any credit.
02:07:06.560 | But I think we're the only library that provides it, and certainly anyone that does it by default.
02:07:13.440 | We're going to, for the purpose of this exercise though, do a simple version where we delete
02:07:18.120 | the last two layers, so we'll grab all the children of the model, we'll delete the last
02:07:22.160 | two layers, and then instead we're going to add a convolution which just has two outputs.
02:07:31.480 | I'll show you why in a moment.
02:07:35.080 | Then we're going to do our average pooling, and then we're going to do our softmax.
02:07:41.680 | So that's a model which you'll see that this one has a fully connected layer at the end,
02:07:49.820 | this one does not have a fully connected layer at the end.
02:07:53.000 | But if you think about it, this convolutional layer is going to be 2 filters only, and it's
02:08:01.720 | going to be 2x7x7.
02:08:05.200 | And so once we then do the average pooling, it's going to end up being just two numbers
02:08:10.240 | that it produces.
02:08:11.240 | So this is a different way of producing just two numbers.
02:08:13.560 | I'm not going to say it's better, I'm just going to say it's different, but there's a
02:08:17.720 | reason we do it.
02:08:18.720 | I'll show you the reason.
02:08:20.400 | We can now train this model in the usual way.
02:08:23.480 | So we can say transforms.model, image_classifier_data_from_paths, and then we can use that conv_learner_from_model_data
02:08:31.400 | we just learned about.
02:08:32.640 | I'm now going to freeze every single layer except for that one, and this is the 4th last
02:08:41.480 | layer, so we'll say freeze to -4.
02:08:45.240 | And so this is just training the last layer.
02:08:48.320 | So we get 99.1% accuracy, so this approach is working fine.
02:08:53.200 | And here's what we can do though.
02:08:55.200 | We can now do something called class_activation_maps.
02:09:05.800 | What we're going to do is we're going to try to look at this particular cat, and we're
02:09:11.360 | going to use a technique called class_activation_maps where we take our model and we ask it which
02:09:16.920 | parts of this image turned out to be important.
02:09:21.040 | And when we do this, it's going to feed out, this is the picture it's going to create.
02:09:27.040 | And so as you can see here, it's found the cat.
02:09:30.760 | So how did it do that?
02:09:31.920 | Well the way it did that, we'll kind of work backwards, is to produce this matrix.
02:09:38.320 | You'll see in this matrix, there's some pretty big numbers around about here which correspond
02:09:45.200 | to our cat.
02:09:47.840 | So what is this matrix?
02:09:49.980 | This matrix is simply equal to the value of this feature matrix times this py vector.
02:10:04.600 | The py vector is simply equal to the predictions, which in this case said I'm 100% confident
02:10:11.760 | it's a cat.
02:10:13.360 | So this is just equal to the value of, if I just call the model passing in our cat, then
02:10:22.560 | we get our predictions.
02:10:23.560 | So that's just the value of our predictions.
02:10:25.600 | So py is just the value of our predictions.
02:10:28.900 | What about feed?
02:10:29.900 | What's that equal to?
02:10:31.700 | Feed is equal to the values in this layer.
02:10:39.960 | In other words, the value that comes out of the final convolutional layer.
02:10:46.700 | So it's actually the 7x7x2.
02:10:52.120 | And so you can see here, the shape of features is 2 filters by 7x7.
02:11:01.880 | So the idea is, if we multiply that vector by that tensor, then it's going to end up
02:11:12.080 | grabbing all of the first channel, because that's a 1, and none of the second channel,
02:11:18.200 | because that's a 0.
02:11:20.480 | And so therefore it's going to return the value of the last convolutional layer for
02:11:27.920 | the section which lines up with being a cat.
02:11:31.560 | But if you think about it, the first section lines up with being a cat, the second section
02:11:36.880 | lines up with being a dog.
02:11:38.440 | So if we multiply that tensor by that tensor, we end up with this matrix.
02:11:45.840 | And this matrix is which parts are most like a cat.
02:11:51.640 | Or to put it another way, in our model, the only thing that happened after the convolutional
02:11:57.360 | layer was an average pooling layer.
02:12:00.840 | So the average pooling layer took that 7x7 grid and said average out how much each part
02:12:07.360 | is cat-like.
02:12:08.360 | And so my final prediction was the average cattiness of the whole thing.
02:12:17.040 | And so because it had to be able to average out these things to get the average cattiness,
02:12:22.640 | that means I could then just take this matrix and resize it to be the same size as my original
02:12:29.740 | cat and just overlay it on top to get this heatmap.
02:12:34.440 | So the way you can use this technique at home is to basically calculate this matrix on some
02:12:41.680 | really big picture.
02:12:44.960 | You can calculate this matrix on a quick small little ConvNet and then zoom into the bit
02:12:50.280 | that has the highest value, and then rerun it just on that part.
02:12:55.720 | So this is the area that seems to be the most like a cat or the most like a dog, that zoom
02:13:00.680 | in to that bit.
02:13:04.120 | So I skipped over that pretty quickly because we ran out of time.
02:13:09.680 | And so we'll be learning more about these kind of approaches in Part 2 and we can talk
02:13:13.040 | about it more on the forum, but hopefully you get the idea.
02:13:15.400 | The one thing I totally skipped over was how do we actually ask for that particular layer.
02:13:22.960 | I'll let you read about this during the week, but basically there's a thing called a hook.
02:13:29.120 | So we called save_features, which is this little class that we wrote that goes register_forward_hook.
02:13:39.520 | And basically a forward_hook is a special PyTorch thing that every time it calculates
02:13:44.880 | a layer, it runs this function.
02:13:47.740 | It's like a callback, basically.
02:13:49.960 | It's like a callback that happens every time it calculates a layer.
02:13:52.840 | And so in this case, it just saved the value of the particular layer that I was interested
02:13:59.360 | in.
02:14:01.260 | And so that way I was able to go inside here and grab those features out after I was done.
02:14:11.000 | So I called save_features, that gives me my hook, and then later on I can just grab the
02:14:16.200 | value that I saved.
02:14:18.380 | So I skipped over that pretty quickly, but if you look in the PyTorch docs, they have
02:14:21.840 | some more information and help about that.
02:14:24.560 | Yes, you're next.
02:14:26.040 | Can you spend five minutes talking about your journey into deep learning and finally how
02:14:37.440 | can we keep up with important research that is important to practitioners?
02:14:46.320 | I think I'll close more on the latter bit, which is like what now?
02:14:50.480 | So for those of you who are interested, you should aim to come back for part 2.
02:14:57.540 | If you're aiming to come back for part 2, how many people would like to come back for
02:15:00.880 | part 2?
02:15:01.880 | Okay, that's not bad.
02:15:02.880 | I think almost everybody.
02:15:05.000 | So if you want to come back for part 2, be aware of this.
02:15:08.700 | By that time, you're expected to have mastered all of the techniques we've learned in part
02:15:13.000 | 1.
02:15:14.000 | There's plenty of time between now and then, even if you haven't done much or any ML before,
02:15:19.440 | but it does assume that you're going to be working at the same level of intensity from
02:15:24.840 | now until then that you have been with practicing.
02:15:27.920 | So generally speaking, the people who did well in part 2 last year had watched each
02:15:33.560 | of the videos about three times, and some of the people I knew had actually discovered
02:15:39.800 | they learned some of them off by heart by mistake.
02:15:42.840 | Watching the videos again is helpful.
02:15:44.520 | And make sure you get to the point that you can recreate the notebooks without watching
02:15:48.680 | the videos.
02:15:50.640 | And so to make it more interesting, obviously try and recreate the notebooks using different
02:15:55.120 | datasets.
02:15:58.520 | And definitely then just keep up with the forum and you'll see people keep on posting
02:16:03.000 | more stuff about recent papers and recent advances, and over the next couple of months
02:16:08.060 | you'll find increasingly less and less of it seems weird and mysterious, and more and
02:16:12.800 | more of it makes perfect sense.
02:16:16.480 | And so it's a bit of a case of staying tenacious, there's always going to be stuff that you
02:16:21.840 | don't understand yet, but you'll be surprised.
02:16:25.280 | If you go back to lesson 1 and 2 now, you'll be like, oh that's all trivial.
02:16:32.720 | So that's kind of hopefully a bit of your learning journey, and I think the main thing
02:16:40.160 | I've noticed is the people who succeed are the ones who just keep working at it.
02:16:44.680 | So not coming back here every Monday, you're not going to have that forcing function.
02:16:49.120 | I've noticed the forum suddenly gets busy at 5pm on a Monday.
02:16:53.560 | It's like, oh, the course is about to start and suddenly these questions start coming
02:16:57.240 | in.
02:16:58.240 | So now that you don't have that forcing function, try and use some other technique to give yourself
02:17:04.120 | that little kick.
02:17:05.120 | Maybe you can tell your partner at home, I'm going to try and produce something every Saturday
02:17:09.320 | for the next 4 weeks, or I'm going to try and finish reading this paper or something.
02:17:16.280 | So I hope to see you all back in March, and regardless whether I do or don't, it's been
02:17:22.240 | a really great pleasure to get to know you all, and I hope to keep seeing you on the
02:17:26.120 | forum.
02:17:27.120 | Thanks very much.
02:17:28.120 | [Applause]
02:17:28.120 | (applause)