How to Build TensorFlow Pipelines with tf.data.Dataset
Chapters
0:00:27 Use the Pipeline Dataset Object
4:40 Reading It Directly from File
7:53 Field Delimiter
8:46 Select Columns
11:41 Shuffle and Batch Methods
16:5 Map Method
22:19 Define a Model
00:00:00.520 | All right, we're going to go through the TensorFlow data sets.
00:00:03.740 | Essentially, these are a more efficient,
00:00:07.740 | built-in way to build our input pipelines.
00:00:11.860 | So we can see the documentation here.
00:00:15.280 | If you'd like to go through it, you can do.
00:00:17.360 | I'll leave a link in the description.
00:00:20.600 | But we are just going to go and dive right into it.
00:00:27.460 | So to use the pipeline data set object,
00:00:31.760 | we need to actually import TensorFlow, of course.
00:00:34.560 | TF.
00:00:38.640 | And we're also going to be using Pandas and NumPy
00:00:42.400 | for a few examples here, so we'll go ahead and import those as well.
00:00:46.180 | (TYPING)
00:00:49.180 | Okay, so there's a few different ways that we can read data
00:01:02.720 | into our data pipelines, data sets.
00:01:05.100 | So the first of those is from in-memory,
00:01:08.540 | which is probably the way that most of you,
00:01:12.300 | if you have seen this before, will have seen it.
00:01:15.040 | We'll go ahead and put that together quickly.
00:01:17.880 | So the first one is a list.
00:01:20.880 | So we can take a couple of Python lists, put them together,
00:01:24.680 | and build our data set using that.
00:01:28.120 | So we'll just put some together really quickly here.
00:01:32.160 | Okay, so we just have input and output, they're both lists.
00:01:38.560 | And then to create our data set object from these two,
00:01:44.800 | we just type
00:01:46.400 | tf.data.DataSet with a capital D.
00:01:52.980 | And we are taking these as a tensor slices.
00:01:59.680 | Like this.
00:02:02.580 | And one thing that we're doing here,
00:02:07.360 | we're putting both of these into a tuple
00:02:10.300 | because this only accepts one input parameter.
00:02:16.040 | And that input parameter is basically all of the data
00:02:18.540 | that we are going to be feeding into our model later on.
00:02:21.780 | The default format for the data set object
00:02:28.080 | when it's feeding into a model is simply one input tensor
00:02:33.820 | and one output tensor or target label tensor,
00:02:37.960 | whatever you'd like to call it.
00:02:39.620 | So we're just going to put that in here.
00:02:41.420 | Here, once it loads, we will have built our first data set.
00:02:50.860 | Took a lot longer than it should have done.
00:02:54.660 | And for item and data set.
00:02:59.200 | So we're just going to see what it looks like.
00:03:01.240 | And we'll see it's like, what's that?
00:03:04.540 | It's a list of tensor arrays.
00:03:08.840 | This is the tuple format that we created here.
00:03:11.460 | So this is the first item we have.
00:03:13.540 | And the first tensor object is a NumPy array
00:03:18.380 | or NumPy integer, which is zero, which matches up to this.
00:03:23.820 | And then next to that, we have the output value,
00:03:25.980 | which is one here.
00:03:27.720 | And then it's the same for the following three rows in there.
00:03:32.980 | So we can also do the same with NumPy arrays.
00:03:38.560 | Which is literally pretty much exactly the same,
00:03:42.300 | exactly the same format, like this.
00:03:46.000 | And this will produce the exact same thing.
00:03:48.500 | And then if we want to use a data frame,
00:03:54.740 | which I assume a lot of you will do.
00:03:57.020 | This time, before we were passing inputs and outputs,
00:04:02.820 | this time we just do the data frame.
00:04:08.120 | And we will see.
00:04:09.620 | Okay, so we'll create a slightly different format here.
00:04:14.460 | And with this, we would reformat or restructure the dataset here
00:04:21.100 | before feeding into our model for it to read everything correctly.
00:04:26.440 | But for now, we're just going to leave it like that.
00:04:29.000 | And then we'll go over the mapping and everything pretty soon.
00:04:34.540 | So the other option we have for reading the data
00:04:38.540 | into our dataset is actually reading it directly from file.
00:04:42.440 | So from file, the benefits we get from doing that
00:04:47.120 | is that we are reading in data from an out-of-memory source.
00:04:51.660 | And because we're reading from an out-of-memory source,
00:04:56.620 | TensorFlow will read data batch by batch
00:05:01.440 | rather than pulling in the entire data source
00:05:05.240 | or the entire dataset all at once.
00:05:07.340 | So if we have a big dataset, then this is pretty useful
00:05:13.180 | because in a lot of cases, we're working with a big dataset
00:05:16.740 | and we can't actually bring everything into our memory all at once.
00:05:21.760 | So this allows us to get around that.
00:05:24.280 | And it does it in an efficient way.
00:05:25.960 | And it's just super easy as well.
00:05:28.760 | So I have also put this together.
00:05:33.000 | Zoom out a little bit.
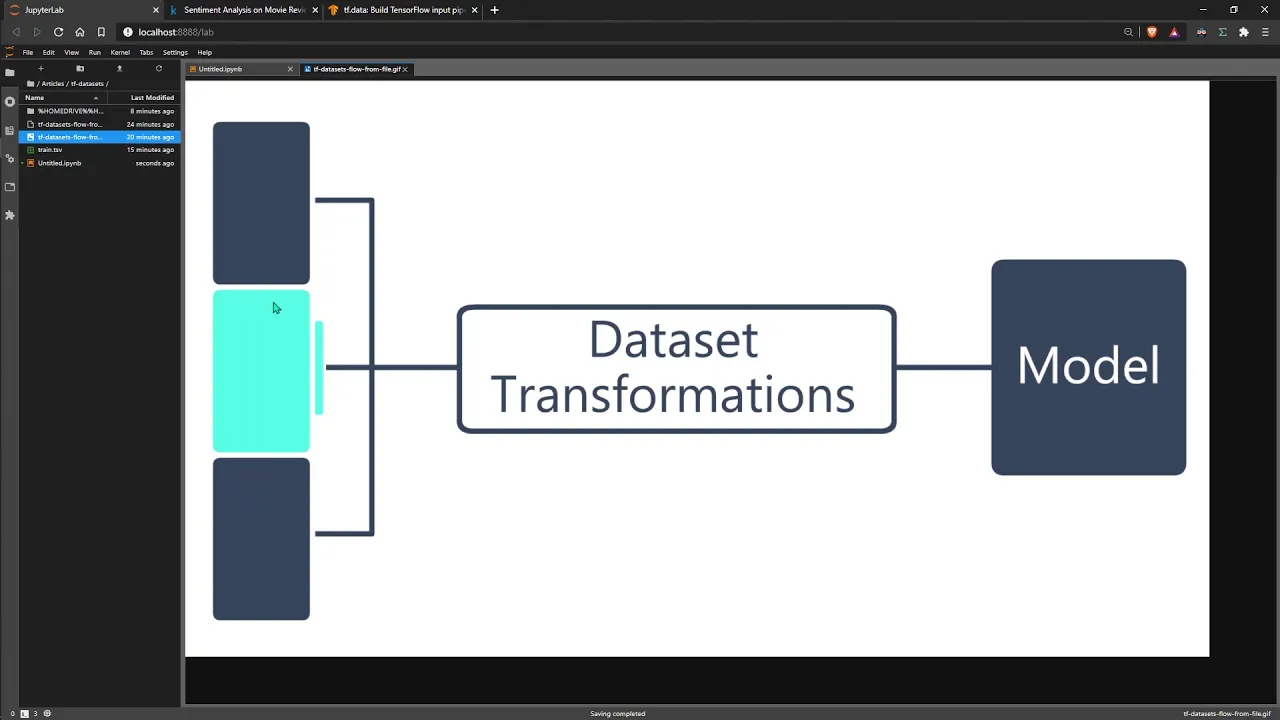
00:05:36.400 | And this is my attempt at demonstrating the difference
00:05:42.240 | or demonstrating what the from file version of this does.
00:05:48.000 | So this is our full dataset here.
00:05:50.580 | And we've batched into three batches here.
00:05:52.320 | Obviously, you'd have way more than this.
00:05:55.880 | And at any one time, we feed in a single batch,
00:05:59.780 | apply our dataset transformations,
00:06:01.940 | feed it into the model for training.
00:06:03.920 | And then once we're done with that, we go on to the next batch.
00:06:07.420 | And then we feed it into dataset transformations
00:06:10.380 | and go and train the model with it.
00:06:13.160 | So let's do that quickly.
00:06:17.660 | So I've got this train.tsv here.
00:06:22.960 | And that file is actually from the sentiment analysis
00:06:27.660 | on the movie reviews from Kaggle.
00:06:30.400 | So you can download it here.
00:06:31.820 | You can see the link, I'll put it in the description.
00:06:35.300 | And we're going to read from this, read from it directly.
00:06:41.000 | So it's slightly different.
00:06:45.900 | We do tf.data.experimental.
00:06:52.880 | And then we make CSV dataset.
00:06:59.060 | So I know we are actually using tab separated values here
00:07:03.560 | rather than comma separated values.
00:07:06.560 | So all we're doing here is we're going to change the field
00:07:09.940 | delimiter to a tab character instead.
00:07:13.740 | So it's train.tsv.
00:07:21.340 | And then also in here, we actually define our batch size.
00:07:26.720 | So we're just going to do something really small for now.
00:07:29.420 | But obviously, when you are using this for your actual models,
00:07:35.620 | you would probably be doing something like a batch size of 64
00:07:38.220 | or 128 or whatever it is you're using.
00:07:42.200 | But we're just going to go for eight now
00:07:44.040 | so we can really easily visualize everything.
00:07:48.440 | And then next, I don't know why it's doing that.
00:07:51.280 | It's fine.
00:07:53.020 | Next, we do field delimiter.
00:07:56.080 | So this is where we tell it it's actually a tab delimited file
00:07:59.580 | rather than comma.
00:08:01.260 | Try and sort that out.
00:08:09.900 | It's really annoying.
00:08:12.260 | And then we also need to...
00:08:20.780 | We need to set the label for our dataset.
00:08:24.720 | Which if we look here,
00:08:33.460 | our label is this sentiment field.
00:08:38.220 | So your sentiment.
00:08:41.200 | And then actually another really useful argument here
00:08:46.040 | is the select columns.
00:08:49.240 | So with this, we just pass a list of the columns that we want to keep
00:08:53.580 | and then it will drop all the other columns.
00:08:57.720 | So for now, I mean,
00:09:01.480 | it depends on what you're doing, obviously, here.
00:09:04.860 | But we're just going to keep the ID.
00:09:07.760 | And then we're also going to keep the input and target data.
00:09:13.740 | Which so the ID is phrase ID.
00:09:19.040 | And then the input data is phrase.
00:09:25.440 | Yep.
00:09:28.320 | And then sentiment for the label.
00:09:31.960 | Let's execute that.
00:09:33.660 | And then let's just have a quick look at what we have.
00:09:41.460 | So we use this take to just take the first batch
00:09:47.360 | within our dataset.
00:09:49.700 | If we say take 20, then it will take the first 20 batches
00:09:54.500 | and nothing else.
00:09:57.500 | But we just want to see the first one
00:09:59.580 | so we can see the actual format within the dataset.
00:10:04.640 | So you can see here we have the phrase ID.
00:10:09.380 | And this is why I wanted to keep the phrase ID in.
00:10:12.420 | I mean, we don't actually need it for training model.
00:10:16.780 | But I wanted to show you that it actually shuffles the data.
00:10:20.820 | So you can see in here,
00:10:23.700 | phrase ID is 1, 2, 3, 4, 5.
00:10:27.060 | It's in order.
00:10:28.560 | But then when we read data in with this,
00:10:32.540 | it actually automatically shuffles everything,
00:10:34.580 | which is a pretty cool feature.
00:10:37.840 | So yeah, it's pretty useful.
00:10:39.640 | And then here we have phrases,
00:10:43.820 | which would be our input data.
00:10:46.680 | And then here we have the sentiment ratings,
00:10:50.520 | which would be our target data.
00:10:52.800 | And so that's everything for the reading into our dataset.
00:11:04.000 | And we'll move on to performing a few operations on it.
00:11:10.000 | So I'm going to go back and just assume
00:11:16.820 | that we're not reading it from here.
00:11:20.160 | Actually, let's use this,
00:11:21.960 | but we're going to load it into our memory first.
00:11:31.020 | Like this.
00:11:32.700 | Let's do this.
00:11:34.760 | So I'm going to do this because I want to show you
00:11:41.100 | the shuffle and batch methods.
00:11:43.860 | And obviously, if it's already shuffled and batched,
00:11:46.640 | there's no point in showing you.
00:11:49.580 | But this is useful to know if you're reading things from in-memory.
00:11:53.840 | Obviously, if you are reading things from your disk,
00:11:57.480 | then there's no pointing in doing this part.
00:12:01.480 | And then we're in TSV, so we need to keep the separator as a tab.
00:12:11.120 | Okay, and let's just make sure we've read it in correctly.
00:12:16.660 | Okay, cool.
00:12:21.040 | So what I want to show you here,
00:12:24.680 | we actually need to, sorry, we need to read it into our dataset.
00:12:28.680 | So we're going to use the same here.
00:12:32.740 | And then let's do the
00:12:40.080 | for item in dataset.take1.
00:12:46.160 | Print item.
00:12:51.700 | Print item.
00:12:53.700 | Okay, so this is because we have these phrases in here.
00:13:01.800 | So, I mean, we don't really need them.
00:13:06.440 | So let's just go sentence ID
00:13:09.780 | to make things a bit easier for now.
00:13:18.080 | So, I mean, if you were using strings,
00:13:20.920 | obviously, for machine learning, you're going to tokenize it.
00:13:24.720 | So, I mean, you would do that first.
00:13:28.780 | But we're not going to go all the way through to actually training the model.
00:13:34.860 | We're just going to have a look at the pipelining.
00:13:38.920 | Okay, cool.
00:13:43.740 | So our first row is 1, 1, 1, 1, 1, 1.
00:13:48.740 | That's what we expect.
00:13:50.820 | First thing is to actually do the shuffling
00:13:56.180 | and the batch, like I said before.
00:13:58.760 | So we're going to do a more,
00:14:01.660 | in fact, no, we stick with a batch of eight
00:14:04.800 | just to make things a bit more readable.
00:14:07.300 | So what we do is, it's like super easy.
00:14:12.640 | So we shuffled dataset and we just add in a large number here
00:14:17.640 | to make sure it shuffles everything like as far away
00:14:22.180 | from its neighboring samples as possible.
00:14:27.240 | And the sort of standard number here is actually 10,000.
00:14:31.520 | I don't know exactly why,
00:14:34.280 | but almost every time I've seen shuffling,
00:14:38.660 | I've seen people use 10K, so I'm going to stick with it.
00:14:43.160 | And then I'm so used to putting like 6,428.
00:14:47.420 | We'll just put a batch of eight here.
00:14:50.500 | So if we take, so now we've batched it,
00:14:56.740 | so we should actually see more than one
00:14:59.380 | because it's taking the first,
00:15:02.040 | like one of the highest level record
00:15:06.980 | or batch within the dataset.
00:15:09.680 | So now we should see quite a few and we can see, okay, cool.
00:15:13.280 | It's definitely mixed up the phrase IDs
00:15:17.860 | because these were one, two, three, four before.
00:15:21.100 | And now they're all mixed up.
00:15:23.500 | So that's cool, we shuffled and batched it like incredibly easily.
00:15:27.560 | So, you know, that's one of the benefits of doing it.
00:15:32.500 | And as well, I mean, writing this code is,
00:15:35.840 | one, it's incredibly easy and simple to remember.
00:15:38.440 | Like it's not hard to remember that.
00:15:41.380 | It's very obvious when you're reading it,
00:15:43.180 | like what is happening in dataset shuffle batch into eight.
00:15:47.220 | That's super easy.
00:15:48.280 | I mean, maybe some people might get a bit confused
00:15:50.460 | by this number here, but otherwise super easy to read.
00:15:55.460 | And it's really quick and efficient.
00:15:57.700 | So it's pretty good.
00:16:03.340 | Next thing I would show you is the map method.
00:16:08.140 | So for any more complex data transformations,
00:16:14.120 | this is probably what you'd use.
00:16:17.620 | I mean, it's really, really useful.
00:16:21.820 | So what can we do?
00:16:23.160 | We can maybe add or multiply everything in the labels by two.
00:16:28.820 | I mean, obviously we wouldn't do this in reality,
00:16:30.940 | but it's just an example.
00:16:34.540 | And we'll also reformat the data.
00:16:38.180 | So we're going to build it as if we have two input fields.
00:16:45.240 | So for example, when you're working with transformers
00:16:49.580 | or a lot of the time you have an input ID field or layer,
00:16:54.800 | and you also have an attention mass field or layer.
00:16:57.920 | And don't worry if that doesn't really make sense.
00:17:01.420 | But essentially we just have two input layers and fields.
00:17:04.860 | So we'll format this to be formatted in the correct way
00:17:09.220 | to have two inputs and then one output.
00:17:11.960 | And we'll also change the number of the output
00:17:15.500 | just so we can see how it works.
00:17:18.900 | So generally the best way of doing this is to create a function.
00:17:23.940 | So I'm just going to call it map func and pass X.
00:17:28.080 | So this is just going to pass every single record
00:17:31.880 | within our dataset.
00:17:35.040 | So one thing I actually just realized
00:17:37.520 | is that we should batch this afterwards
00:17:41.780 | because otherwise we have to consider the batching.
00:17:45.460 | So let's move these after and let's write this.
00:17:51.900 | So we're going to return.
00:17:53.900 | So when we are working with multiple inputs or outputs,
00:18:03.980 | even the best way to let TensorFlow know
00:18:07.880 | where each input is supposed to be going
00:18:10.520 | is to give the input layers or output layers a name
00:18:15.280 | when you're defining the model and building it
00:18:19.520 | and match that to the names that we give to this dictionary here.
00:18:25.260 | So with the transformer example,
00:18:28.660 | I think most people just do input IDs.
00:18:34.240 | And then I'm just going to make this up.
00:18:36.040 | So our input ID for this is going to be this value here.
00:18:42.140 | And we're going to put it into a list
00:18:48.380 | because typically you'd have like an array
00:18:50.860 | or a list of numbers coming in here.
00:18:56.600 | And we're just going to take the first value of X.
00:19:04.800 | And then the mask, we're going to write it like this.
00:19:12.480 | And put one.
00:19:15.180 | And then on the outside of this dictionary,
00:19:18.820 | we only have one label, one output, one target,
00:19:24.660 | however you want to call it.
00:19:26.820 | And we're just going to perform like a really basic operation on it
00:19:29.720 | just to show that we can.
00:19:32.000 | So multiply by two and nothing special.
00:19:36.760 | I'm just putting a list.
00:19:41.380 | So to apply this mapping function,
00:19:45.340 | all we need to do, again, like it's incredibly easy,
00:19:50.120 | is dataset.map.
00:19:54.660 | And then we map the map func like this.
00:20:00.360 | And then we did batch it before.
00:20:01.820 | So let's just rerun this bit of the code
00:20:04.860 | so that we have it all unbatched again.
00:20:09.400 | Run this and this.
00:20:11.540 | Okay, so let's have a look at what we have now.
00:20:14.940 | So you can see here we have this format.
00:20:18.300 | Let's do that again.
00:20:20.380 | Let's see what we have.
00:20:23.340 | Okay, it's kind of hard to read, but inside a tuple.
00:20:29.920 | Right, so this is the index one of the tuple
00:20:36.960 | and this is index zero.
00:20:38.960 | All right, so inside index zero,
00:20:44.000 | we have this dictionary that we defined,
00:20:48.340 | which has input IDs and then also has the mask.
00:20:54.080 | And that is what this tuple format here
00:20:59.840 | with the input and the output
00:21:05.360 | here is what TensorFlow will be expecting
00:21:09.060 | when we fit to the model.
00:21:12.300 | And then if it sees a dictionary
00:21:15.260 | in either the input or the output,
00:21:18.240 | it will read the key values of the dictionary
00:21:24.840 | and the values that match to those keys
00:21:28.680 | will be provided to a corresponding key.
00:21:31.740 | So essentially, you would have to have a layer
00:21:35.740 | called input IDs and it would pass this to that layer.
00:21:40.900 | And then it would also pass this to the layer of mask.
00:21:47.140 | And then we would also have the outputs
00:21:49.420 | being passed to our output layer.
00:21:52.820 | We wouldn't necessarily need to mark this one out though.
00:21:58.020 | Okay, now we want to batch it.
00:22:00.960 | Like we did before, and then we can just view what we have here.
00:22:04.900 | Okay, so we have the dictionary
00:22:06.500 | and then we have everything else as well.
00:22:09.100 | Okay, so that's pretty good, that's what we want.
00:22:12.200 | Okay, so we need to define a,
00:22:18.540 | just like really quickly define a model.
00:22:22.540 | So it's going to have a input IDs,
00:22:29.780 | and then it's going to have this layer.
00:22:31.860 | Okay, and so I'm not actually going to define all of this.
00:22:46.500 | I'm just going to show you how it would work.
00:22:48.040 | So you define your shape, you define it here,
00:22:52.580 | and then you would also have your name.
00:22:55.740 | And then it's this name that would have to match up
00:22:57.920 | with the dictionary that we have fed in previously.
00:23:02.320 | So we go like input's ID, or was it input's ID?
00:23:07.500 | Or, okay, so input's IDs, right, they would have to match.
00:23:14.280 | And then we would have a mask as well,
00:23:21.480 | because we have two inputs, remember?
00:23:24.480 | And then this one would be called mask.
00:23:26.960 | And obviously you'd call this mask or anything else you want.
00:23:31.860 | We call it like input one, input two, it doesn't matter.
00:23:37.100 | Okay, but later on, when we actually fit the model,
00:23:41.640 | we do it like this.
00:23:43.740 | So obviously we would have an output here as well,
00:23:49.500 | and I'm not defining the rest of it.
00:23:52.480 | But we'd have two inputs, and then the output.
00:23:57.180 | We'd have the two inputs, something in the middle,
00:24:00.080 | the output, and then all we'd have to do
00:24:03.040 | with that model architecture is it's fit in dataset like this.
00:24:07.680 | And then you'd have however many epochs you're training for.
00:24:14.500 | And then that's everything for that.
00:24:18.040 | So actually, there's one other thing that I wanted to mention as well.
00:24:23.940 | So obviously, a lot of the time,
00:24:27.780 | you're going to want to split your data for training
00:24:32.940 | into a training and a validation set.
00:24:41.020 | So to do that, it's actually super easy.
00:24:45.700 | So before we mentioned the take method,
00:24:49.000 | so we use dataset.take,
00:24:54.000 | and we can also use dataset.skip.
00:24:59.980 | And these are like equal and opposite.
00:25:02.440 | So if we do dataset.take 10,
00:25:07.540 | it will take the first 10 batches of the dataset and nothing else.
00:25:11.480 | Then if we do dataset.skip 10,
00:25:15.120 | it will skip the first 10 batches of the dataset and nothing else.
00:25:19.620 | So this is not the most efficient way of doing it,
00:25:26.600 | but let's just do it like this for now.
00:25:31.540 | So if we just get the length of the dataset,
00:25:38.580 | so I say this isn't efficient because it's to take a list of the dataset
00:25:44.680 | we're loading everything in or we're generating,
00:25:47.880 | because the dataset is a generator
00:25:49.820 | and we're putting everything into memory as a list
00:25:54.560 | and then taking the length of it.
00:25:56.700 | So it's bad just to know how many batches you're building from the start,
00:26:03.160 | if it's a big dataset.
00:26:04.400 | I mean, for this, it's fine because we don't have a lot of data,
00:26:08.240 | but normally it would be better not to do that.
00:26:12.100 | So let's see, I mean, you can see even with this dataset was pretty small,
00:26:17.780 | it's still taking quite a long time.
00:26:19.980 | And then say if we want to take a 70% split,
00:26:23.480 | so 70/30, 70% for the training data,
00:26:26.820 | 30% for the validation and probably test data as well,
00:26:29.720 | but you just split that after.
00:26:34.420 | We would take, so training size
00:26:39.400 | would be 0.7.
00:26:47.200 | And remember, this is taking the batches.
00:26:51.700 | So it would actually be the length
00:26:57.440 | divided by the batch size, which is eight.
00:27:04.880 | Okay, and then we're going to have to round this to the nearest batch
00:27:08.880 | or the nearest, sorry, the nearest integer
00:27:11.660 | because we can't take 10.2 or something like that.
00:27:15.120 | So we just round it here.
00:27:17.200 | And then let's just see what we have for training size.
00:27:23.600 | Okay, so we have 1,707 batches for the training data.
00:27:33.120 | Okay, so we want to take that number of batches.
00:27:36.920 | So train size, and we create another dataset,
00:27:45.020 | which is the train dataset.
00:27:47.700 | And then for the validation dataset,
00:27:51.860 | we just skip those 1,707 batches.
00:28:00.920 | Like that.
00:28:02.920 | Super simple.
00:28:07.300 | So let's take the length of those so we can see again.
00:28:13.360 | I know it's not efficient, but it's quick.
00:28:16.900 | It's the easiest way to do it quickly.
00:28:18.980 | Okay, so yeah, we get 1,707 and then our 30% value
00:28:26.480 | is when it finally loads.
00:28:30.480 | When it finally loads.
00:28:39.000 | Okay, so we already have the batch size here.
00:28:46.940 | I don't know why. That was really stupid.
00:28:49.680 | So we've already considered the batches in here.
00:28:52.940 | So we didn't need to consider it here as well.
00:28:56.520 | That's why it was taking so long.
00:28:58.520 | Okay, so it would actually be, it should actually be that way.
00:29:05.100 | So let's do that.
00:29:06.760 | So yeah, we have a training size of 13.6K
00:29:11.500 | and then the remaining batches will feed into our validation data,
00:29:18.140 | which will be around 600 values.
00:29:23.180 | Yeah, just under, sorry, just under 6,000 values.
00:29:27.360 | But that's everything I think that I wanted to go through.
00:29:31.500 | So we've covered all of the essentials
00:29:37.260 | of the TensorFlow data set object,
00:29:41.540 | how we can load in-memory data and/or read into data sets from file,
00:29:48.680 | how to batch and shuffle the ones that we read from in-memory sources,
00:29:55.660 | how to transform the data sets with map,
00:29:58.460 | how we can feed them into models.
00:30:01.460 | One thing to note that if we just have an input and output,
00:30:05.660 | like you probably will for most models,
00:30:09.360 | you don't need to do anything.
00:30:10.940 | You just have it in the tuple format
00:30:14.280 | and you have inputs and outputs.
00:30:18.140 | And then you would just do model.fit data set like that.
00:30:24.080 | You don't have to name the layers or anything.
00:30:27.120 | You just feed it straight in.
00:30:29.960 | And then after that, we went through the splits,
00:30:39.020 | which we've just done here.
00:30:40.860 | So yeah, that's everything.
00:30:42.960 | I hope it's been a useful video.
00:30:46.200 | And I hope you enjoyed the video.
00:30:50.440 | Thanks for watching.