Stanford CS25: V3 I No Language Left Behind: Scaling Human-Centered Machine Translation
00:00:00.000 | We're glad to have Angela Phan today with us here, and she's a research scientist at
00:00:12.520 | Meta AI Research in New York, focusing on research in text generation mainly.
00:00:18.240 | And currently she's working on language modeling and developing the Lion AI agents meta products.
00:00:24.840 | And recent research products include No Language Left Behind, which she'll be talking briefly
00:00:29.160 | about today, universal speech translation for unwritten languages, as well as Lama 2.
00:00:35.720 | So give it up for Angela, I guess.
00:00:38.720 | All right, thank you all so much.
00:00:41.440 | So yeah, when I got this email, I was like, Oh, I should probably talk about Lama 2.
00:00:44.880 | But then I noticed you have Sharon, who will like, you know, is like a 10x better speaker
00:00:48.880 | than me.
00:00:49.880 | So I was like, okay, like, maybe not Lama 2.
00:00:51.960 | But then I thought I maybe would cover this project that we did called No Language Left
00:00:55.560 | Behind, which could be very, also very relevant to this class.
00:00:59.860 | And so when you think about a lot of text generation technology, most of it until fairly
00:01:06.560 | recently, has been really focused on English.
00:01:10.360 | But there are actually more than 3000 written languages worldwide.
00:01:14.440 | And for me, this is extremely personally meaningful, because actually English is my third language.
00:01:20.040 | So it's really important.
00:01:22.040 | Yeah, so it's really also very personally meaningful.
00:01:26.840 | And when you think about some of the multilingual technology that permeates, it's not like we've
00:01:31.520 | never worked on multilingual, right?
00:01:33.760 | Actually, when speaking about generative AI, I actually think translation is one of the
00:01:37.840 | most commercially successful and widespread applications of generative AI.
00:01:41.920 | I mean, ultimately, translation models, they are, you know, like conditional language models.
00:01:47.200 | And so when you think about like traveling or something like that, or my sister is taking
00:01:52.200 | Spanish, so like, just like doing her Spanish homework, we have a lot of tools that exist
00:01:56.040 | today.
00:01:57.040 | So things like Google Translate cover around 130 languages, Microsoft Translate about 110.
00:02:01.840 | This might be a little bit outdated, since I pulled the statistics a little bit ago.
00:02:07.640 | But the project for No Language Left Behind, it started from like a very simple ask, like,
00:02:11.480 | okay, there's 3000 languages worldwide, maybe it'll be like, pretty hard to get to all 3000.
00:02:16.840 | Since some of them are pretty rare, and not spoken by many, but there are still like hundreds
00:02:23.080 | of languages spoken by millions and millions of people.
00:02:26.960 | And so we were like, okay, no big deal.
00:02:28.960 | Like, let's just start from the 100 ish that we have today, and just go for like a doubling,
00:02:34.120 | like what would it take to actually be able to double this kind of coverage?
00:02:38.280 | And of course, you know, just saying that you support a bunch of languages is not the
00:02:41.640 | goal, right?
00:02:42.640 | We actually want to create high quality, safe translations that would be usable by people,
00:02:47.560 | just like if you're going on vacation today, your kind of instinct is to whip out your
00:02:50.960 | phone and get on the Google Translate app.
00:02:54.520 | And so kind of the backdrop to this project was that there was actually a lot of progress
00:02:58.900 | in translation.
00:03:00.200 | So historically, there's been a lot of focus on what we call higher resource languages.
00:03:04.600 | And these are not necessarily languages that are spoken by the most people in the world.
00:03:08.240 | But when we say higher resource, it means the most amount of data.
00:03:12.160 | And so you can think about things like Europarl, or, you know, translations from the European
00:03:16.840 | Parliament, and those served as the foundation for a lot, a lot of translation development.
00:03:22.160 | And more recently, there's been a great focus on low resource languages.
00:03:25.760 | And it's been driven across the research community with groups like Ghana NLP, Masakane, America's
00:03:31.520 | NLP.
00:03:32.520 | And these are all really exciting developments.
00:03:34.760 | And so these have led to a lot of development of new data sets, as well as criticisms of
00:03:39.920 | existing data sets, and also work on new languages, and usually languages that people kind of
00:03:45.160 | speak, and they care a lot about.
00:03:47.120 | And we found this like really, really exciting.
00:03:49.800 | And so looking at a lot of this, a bunch of us got together at FAIR, and started thinking
00:03:54.400 | like, okay, we actually speak some pretty low resource languages from like Catalan,
00:03:59.080 | to Assamese, and so on.
00:04:01.040 | And so we started this as kind of like a big passionate research project.
00:04:04.660 | And so today, I want to cover a little bit about our high level approach to this problem,
00:04:09.520 | which is a little bit interdisciplinary.
00:04:11.560 | I want to talk about how we actually created the data sets to be able to support this kind
00:04:15.960 | of work.
00:04:17.440 | Of course, I want to talk about the models, since this is a class about transformers.
00:04:21.720 | One note here, I think that's actually very interesting in terms of translation as like
00:04:25.000 | a research direction, is that actually a lot of innovations have been done in translation.
00:04:31.320 | The original transformer paper, I think is one of them, and which makes always translation
00:04:35.080 | a quite interesting area to work on, because I feel like it's a very mature research area
00:04:40.000 | as well.
00:04:41.000 | So it kind of is like, okay, if your architecture works in translation, it probably works very
00:04:44.640 | generally.
00:04:45.640 | So that's also one of the things that excites me about translation research.
00:04:48.880 | Then I want to talk about evaluation, like how are we actually measuring and ensuring
00:04:53.200 | the quality of these translations are good and safe for people.
00:04:57.160 | And then I want to end with a little bit of like, you know, high level thoughts about
00:05:00.840 | future directions and things that I hope that we can work on in the future.
00:05:05.520 | So I want to start with our approach.
00:05:08.040 | I think the most important thing in research is to know that we're working on a real problem,
00:05:12.320 | especially when it's really close to people like translation.
00:05:16.560 | And I think in many areas, like when I was working on on-device AI, for example, I feel
00:05:20.720 | like I had like a research problem in mind, but it was like very, very disconnected from
00:05:25.240 | the practical problem of actually putting models on phones.
00:05:28.280 | And so this was something that was really important to us.
00:05:30.760 | And so we actually started the project by kind of like focusing on a social sciences
00:05:35.440 | type approach or sociology type approach.
00:05:39.180 | And we actually did a lot of interviews with low resource speakers.
00:05:42.840 | And so we met with about 44 different native speakers that spoke 36 different languages
00:05:48.280 | across North America.
00:05:50.320 | I will say that a lot of them are like immigrants to the US, since that was kind of like the
00:05:54.280 | easiest kind of cohort to recruit.
00:05:57.360 | And we learned a lot of different things about how they approach low resource languages,
00:06:01.960 | but also the kind of technological need that they have, because I think it's easy to be
00:06:05.520 | like, hey, I have this cool background, like I have this cool problem, and I want to solve
00:06:09.880 | it.
00:06:10.880 | But I think it's very important to actually like talk to the people, this is a problem
00:06:13.320 | that that needs to be solved.
00:06:15.280 | And so we learned that there's great fear in general, that low resource languages might
00:06:19.460 | be undergoing a state of decline, partially because a lot of education is shifting to
00:06:25.280 | languages like Hindi, or like English, or Mandarin, Chinese, for example, and there's
00:06:30.840 | a lot of excitement to be included in existing translation systems.
00:06:34.600 | And people said they have always tried to use Google Translate or Microsoft Translate
00:06:39.200 | in their existing languages.
00:06:41.200 | But ultimately, they found that the quality is really insufficient for reliable usage.
00:06:45.360 | So if you think about like, well, I was going to say when I was in high school, but you
00:06:49.000 | all are probably like substantially younger than me.
00:06:51.040 | So maybe like, you know, 10 so years ago, you know, and you try to use Google Translate
00:06:54.640 | for your Spanish homework, like your Spanish teacher could always identify that, like,
00:06:58.560 | you know, it was not a human written translation, and so you would get marks off.
00:07:01.920 | But that's not really the case for some of the high resource languages today.
00:07:06.000 | And so I think, as with all things in machine learning, it really starts from a data perspective.
00:07:10.120 | Like, why can't we just train models and hundreds of languages or large language models and
00:07:14.200 | hundreds of languages, it's because we don't have the data to support it.
00:07:17.800 | And so I want to talk first about evaluation data sets, because I think it's extremely
00:07:22.000 | important to nail evaluation.
00:07:24.820 | And then I'll talk about training.
00:07:27.160 | So for an evaluation data set for this work, we started this FLORES effort, it stands for
00:07:32.920 | Facebook low resource, I guess we're called meta now, but I didn't think FLORES was like
00:07:36.880 | a very good renaming, so we're still calling it FLORES.
00:07:41.040 | So this was something we originally started for just two languages in this first paper
00:07:45.200 | at EMNLP many years ago, so it was just for Nepali and Sinhala, and we later extended
00:07:51.400 | it to incorporate two more languages in a release.
00:07:54.440 | Afterwards, we thought a lot about, okay, like, FLORES was really useful for the community.
00:08:00.440 | How can we extend it to 100 languages?
00:08:01.960 | And so that was this follow up work that we did, I think we had at ACL, or WMT.
00:08:08.160 | And then in this project, we were like, okay, how can we go from FLORES 101 to FLORES 200
00:08:14.160 | to really go for the doubling effect?
00:08:16.640 | And so what is FLORES?
00:08:17.880 | Well, it's in the name, it's a focus on low resource languages.
00:08:21.440 | So we do include some higher resource languages like German or Hindi or so on, almost for
00:08:26.680 | calibration effect as well.
00:08:29.000 | But the majority of the focus is on these lower and mid resource languages.
00:08:33.420 | It's the first large scale many to many machine translation evaluation data set, which means
00:08:39.160 | that we take all of the sentences in English, and then we translate them to all of the languages,
00:08:43.840 | which means that you would be able to evaluate any cross pair of languages.
00:08:48.400 | So for example, like Chinese to French, I lived in France for many years.
00:08:52.120 | So it's like very personally relevant to me.
00:08:53.840 | Of course, 200 languages also in the name, there's a broad diversity of different domains
00:08:58.720 | and topics.
00:08:59.720 | I think this is important when designing an evaluation data set, which is like very top
00:09:04.160 | of mind for anybody interested in language modeling research.
00:09:08.040 | Because like the way people train machine translation models, and the way people use
00:09:13.000 | them are often like very different.
00:09:15.300 | And so if you only benchmark your data set, for example, on use, which is very common
00:09:19.220 | in translation research, then you don't really pick up the fact that people talk about such
00:09:23.720 | a wide variety of things, and have like different casual conversations that they need translated
00:09:28.320 | official documents and so on.
00:09:31.020 | It's also document level data set.
00:09:33.200 | This is not something that I think the community is like broadly leveraging right now.
00:09:36.840 | But the way it's translated is that you can have document level context.
00:09:40.800 | And so translators are provided the entire document to translate from, and we also provide
00:09:45.200 | the entire document for evaluation.
00:09:47.720 | And we translate like multiple sentences from the same paragraph.
00:09:50.720 | And so this was like a potential research direction that we wanted to make sure we covered
00:09:54.840 | models that needed like potentially more context, because a lot of translation work is done
00:09:58.840 | at the sentence level.
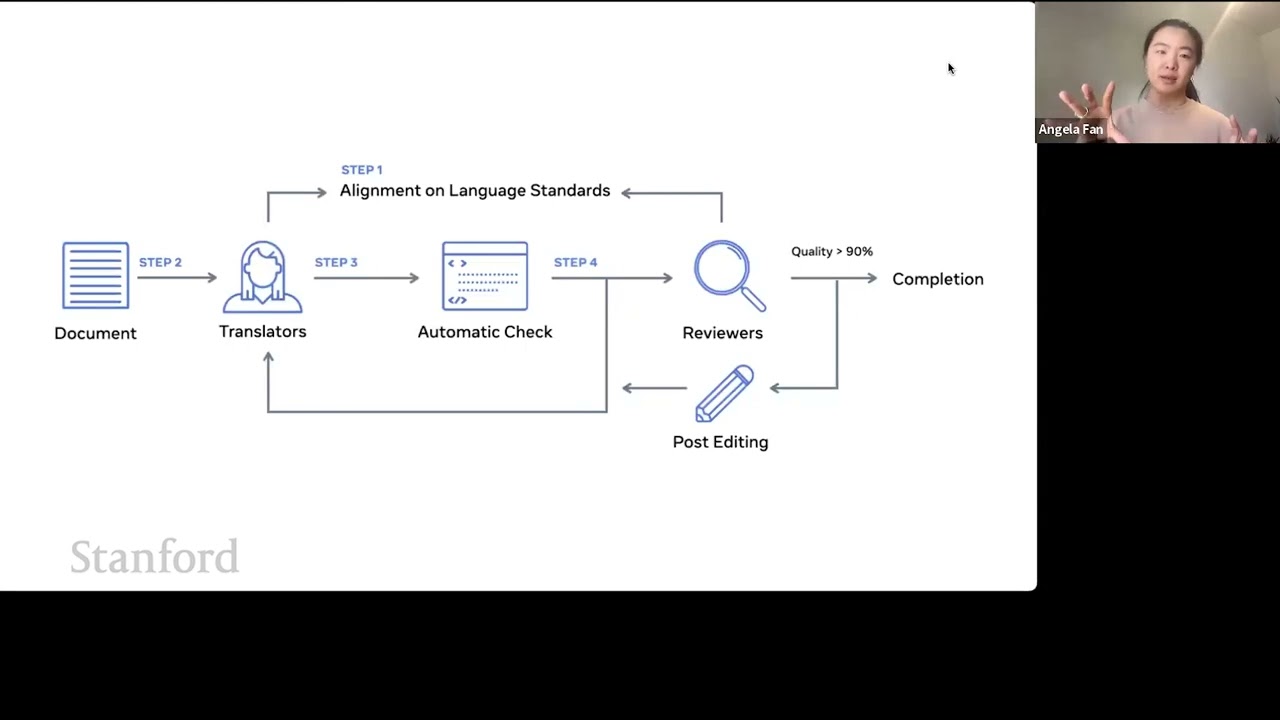
00:10:00.960 | So how do we actually ensure that this data set was high quality.
00:10:04.000 | So the first step is that we take a document.
00:10:06.520 | Well, actually, first step is like alignment on language standards.
00:10:10.300 | So this is very important, because when you're translating French, or Chinese, I think most
00:10:15.240 | people have a strong understanding of like, what it means to produce like a good French
00:10:19.360 | or good Chinese.
00:10:20.840 | And there are a lot of professional translators hired in these languages.
00:10:24.200 | But when you go to lower resource languages, it's not necessarily the case that there's
00:10:28.280 | like a, you know, a glowing translation industry around translating a lower resource language.
00:10:35.420 | And so one of the first things is actually to align on like, what is a high quality translation.
00:10:40.160 | And so there's actually a lot of challenges here.
00:10:42.580 | So there are certain low resource languages where there's different competing language
00:10:45.640 | standards, or there's like very high variance in different regions on how languages are
00:10:50.480 | spoken.
00:10:51.600 | And so this step is a pretty critical one.
00:10:54.320 | So then what we do is we take the document, we send it to one group of translators, and
00:10:58.640 | they do the first translation step, then we do some automatic checking, you know, like
00:11:03.080 | if the input sentence was like 10 words, and the output sentence like 300 words, it's like,
00:11:07.800 | most likely something went wrong, you know.
00:11:10.040 | And so we send it back.
00:11:11.840 | Otherwise, we'll send it onwards to a separate, completely independent set of translators
00:11:17.640 | that do review.
00:11:19.280 | And so they try to rate the quality of this.
00:11:21.560 | And if the quality doesn't pass a sufficient bar, and it gets sent back to the original
00:11:25.240 | set of translators to to edit, and they kind of go through and like address all of the
00:11:30.000 | feedback.
00:11:31.000 | And then if it's good enough, then it enters our data set.
00:11:34.680 | And so there's many challenges here.
00:11:36.520 | The first one, of course, is just like finding translators, and also finding more translators.
00:11:41.400 | There was a certain issue that we ran into, for example, that in a certain country that
00:11:45.840 | the internet was not available.
00:11:48.040 | And so, you know, it's a lot of recruitment.
00:11:51.480 | The other one, of course, is language standardization.
00:11:53.960 | I think I briefly mentioned this before, but there's a lot of different challenges in just
00:11:59.920 | understanding like, what is a high quality translation, for example, the low resource
00:12:03.920 | language, Breton, there's like two competing groups on like, how do you write Breton?
00:12:08.520 | So it's like very difficult to resolve some of those things.
00:12:11.360 | And the final thing is that there's actually a lot of variation, even in languages like
00:12:15.520 | Arabic, like the Arabic, like Moroccan Arabic is very different from, you know, Jordanian
00:12:21.280 | Arabic and so on.
00:12:22.800 | And there are also certain regions that they speak the same language, but due to historical
00:12:26.960 | reasons they write in different scripts.
00:12:29.400 | And so one of the things we actually did was like, if there are languages written in multiple
00:12:32.920 | scripts, we actually supported the collection of a multiple script evaluation.
00:12:37.040 | And I think this is really important because if you're building an underlying technology
00:12:41.760 | and you only choose one, then I think you risk like just kind of like naturally supporting
00:12:46.500 | one over the other when we really should be like kind of a more neutral technology provider.
00:12:51.860 | And so this is something that we explored a lot, as well as exploring different variants
00:12:55.660 | of Arabic.
00:12:56.660 | This is also open source, if you just go to this link, you can just like download all
00:13:00.440 | of the, all of the text files for this.
00:13:03.920 | With evaluation done, I want to talk a little bit about how we collected some of these training
00:13:08.360 | data sets.
00:13:09.360 | The first thing I want to talk about is this data set we created called NLLB Seed.
00:13:14.040 | And the idea of this is like, it's a really seed data set of high quality translations
00:13:18.880 | and languages that really don't have anything.
00:13:20.880 | Why?
00:13:21.880 | Because, well, you can't start from nothing, you know, you got to bootstrap from somewhere.
00:13:26.120 | A lot of people have been using the Bible as a way to bootstrap.
00:13:30.760 | But it's very limited domain, obviously very religious text.
00:13:34.480 | And so we created this data set, NLLB Seed for languages that really don't have anything
00:13:40.440 | to get started from.
00:13:41.440 | It's only about 5000 sentences, so it's nothing crazy.
00:13:44.360 | But it supports a lot of different use cases, like training language identification models,
00:13:48.960 | or sentence encoders, Ngram language models, like all of these things that I'm about to
00:13:53.320 | talk about in our data set pipeline.
00:13:56.200 | So it covers 43 languages, about 6000 sentences.
00:14:00.000 | And the way we decide to sample is, it's focused on really general content.
00:14:03.960 | So Wikipedia has this article of like, hey, if you're going to start like a new Wikipedia
00:14:08.400 | and your new language, I think Wikipedia is like 309-ish Wikipedias, last I checked.
00:14:14.080 | Here's like a list of articles that every Wikipedia in a new language should have.
00:14:17.480 | And so that's where we sampled this original content from.
00:14:20.840 | And of course, it's also open source if you if you want to download it.
00:14:24.960 | So what we ended up doing to get large scale training data is using mining.
00:14:30.720 | So this is not something we pioneered in this project, we have like a bunch of different
00:14:34.600 | previous work.
00:14:35.700 | So we started from Wikimatrix, where we were like, hey, there's a lot of different sentences
00:14:40.500 | on Wikipedia, and different languages that we should be able to match up.
00:14:44.400 | And so we tried to do that with Wikipedia to get machine translation training data.
00:14:49.600 | We extended that to the web in the CC matrix project.
00:14:52.600 | And then we extended it to very, very large scale mining on all cross pairs.
00:14:56.720 | And this project on beyond English centric multilingual machine translation, we really
00:15:01.080 | tried to ditch like English as a central pivot language.
00:15:04.400 | And so the way this whole data mining thing works, is that it focuses on sentence alignment.
00:15:09.720 | So everyone is probably super familiar with this, because it's how language models are
00:15:12.540 | built now.
00:15:13.540 | But it's like you take Common Crawl, or any other open source dump of the web, I don't
00:15:17.680 | know, like red pajama, or like whatever you want to CC net, whatever you want to use these
00:15:21.560 | days.
00:15:22.560 | And you take all of the data, you extract all of the text, you know, a lot of HTML parsing,
00:15:27.440 | and so on goes into it.
00:15:28.840 | And the idea is that we want to try to find matching text that could be a translation.
00:15:33.160 | So we shatter it all into sentences, we embed them with different sentence encoder models.
00:15:38.480 | And then we do a match to try to understand in a multilingual space, if the sentences
00:15:43.200 | match.
00:15:44.780 | And so one of the biggest challenges to this is that the quality of the sentence encoding
00:15:49.360 | is very important.
00:15:50.360 | So if your sentence encoding is not very accurate, then it's impossible to match in this multi
00:15:54.480 | dimensional space, the idea of like the meaning being the same.
00:15:58.600 | And so one of the big things we tried to do here, this project was try to improve the
00:16:02.760 | quality of the sentence encoders.
00:16:05.440 | And so one of the big things that we did was train sentence encoders with mask language
00:16:09.400 | modeling, you see that on the left, but we also use multilingual distillation, which
00:16:15.280 | you see on the right.
00:16:16.280 | And so previous approaches to sentence encoders and the trend in the research community for
00:16:21.400 | a while was to really try to embed all languages in the same sentence encoder model.
00:16:27.280 | So projects like XLMR, for example, are in that direction, I think is pretty widely used.
00:16:33.200 | The challenge with this, when you're training a low resource model is that a lot of your
00:16:37.200 | high resource data just overwhelms your low resource data.
00:16:42.040 | And so you don't end up with a very high quality sentence encoder for those languages.
00:16:46.400 | So what we ended up doing is we had a multilingual teacher model.
00:16:49.760 | And we distilled a bunch of student models that are specialized to different language
00:16:55.140 | families that are low resource.
00:16:57.760 | And so this enables the quality to be pretty high.
00:16:59.920 | And so the way that distillation works is that the teacher and the student model both
00:17:04.320 | see the same data, and then we try to minimize the cosine loss between the sentence embeddings
00:17:09.720 | that they produce.
00:17:10.720 | I think an important question that you can ask here is, why do you need to do multilingual
00:17:16.880 | distillation?
00:17:17.880 | Why can't you just train a bunch of different student models, one per language family?
00:17:22.960 | Why even care about distillation?
00:17:25.120 | And the reason is because if you're going to use a bunch of sentence encoders for mining,
00:17:29.960 | the important thing is that they all exist in the same embedding space.
00:17:34.280 | If you train one separate model and another separate model, there's nothing constraining
00:17:38.240 | them so that you can mine all of the data against each other.
00:17:42.000 | And so one of the things we found is that by starting everything from the same teacher
00:17:45.840 | model and trying to use this cosine loss to minimize the distance between embeddings,
00:17:50.520 | you are able to have this constrained space where you can mine every language against
00:17:55.160 | every other, even if you have different student models.
00:17:58.900 | And so this graph on the y-axis, it shows the error rates of mining.
00:18:05.100 | And so lower is better.
00:18:06.700 | And on the x-axis, it shows a bunch of different low-resource languages.
00:18:10.020 | So for example, the first one is Urdu, the second one is Telugu, third one is Tagalog,
00:18:15.140 | and so on.
00:18:16.140 | And so the gray bar here is the original laser paper.
00:18:19.740 | So this is a paper we put out maybe in 2018-ish, and we had all of these languages, we counted
00:18:24.540 | them as included.
00:18:25.700 | But as you can see, the error rate is extremely, extremely high for these languages.
00:18:30.180 | So even though they were included, couldn't really be used for high quality.
00:18:34.540 | And the blue bar is the laser model that we trained based on the technique I just described
00:18:39.440 | in the previous slide.
00:18:40.760 | And you can see that I think the most important point is that you can barely see the blue
00:18:43.300 | bars.
00:18:44.300 | So it was very effective, even for these previous languages that people had thought we had previously
00:18:49.260 | embedded.
00:18:50.260 | And then so now how does this kind of thing fit into a whole data pipeline around this
00:18:55.620 | approach?
00:18:56.700 | So one of the most important things is when you download the data from the web, you don't
00:19:01.780 | really know what language it's in.
00:19:04.320 | And so this is part of all of the large-scale data cleaning that goes into training large
00:19:08.940 | language models today.
00:19:10.540 | And so the way we identify different languages is through simple classification models called
00:19:15.940 | language identification models.
00:19:18.340 | And I think it's a classification model.
00:19:20.860 | And so people think it's easier than it actually is.
00:19:24.540 | But I think some of the major challenges are that there's so many different languages.
00:19:29.140 | They're written in many different ways.
00:19:31.340 | And web text is very casual.
00:19:33.900 | And so it can be very difficult to actually train a good classification model that can
00:19:37.620 | generalize to that.
00:19:39.020 | And so what we did is, you know, we had our LID training data, and we produced a language
00:19:45.380 | identification model, LID.
00:19:47.460 | And then we actually did human evaluation to label errors coming from the LID system
00:19:52.500 | to iteratively improve this on web text itself to improve the quality of this specific model.
00:19:58.780 | Then after we produce this LID model, then we insert, like, all of our Common Crawl,
00:20:02.580 | where the web arrow is coming in, and we do a ton of filtering and cleaning.
00:20:06.820 | And this produces a huge corpus of different monolingual data that you can then use for
00:20:11.900 | training anything.
00:20:13.580 | Afterwards, we train our encoder, what I described on the previous text.
00:20:18.260 | And then we convert this monolingual data into what we call mind bytexts.
00:20:22.460 | So these are a huge data set of things that we think are translations of each other.
00:20:27.820 | And then finally, what we do is we actually try to validate that these are real mind bytexts
00:20:32.860 | by training very small bilingual, multilingual, sorry, bilingual translation models in order
00:20:38.520 | to see, you know, what the quality is like.
00:20:40.920 | And I think this is important because, like, the data development cycle and, like, the
00:20:45.540 | end task that it's being used for, you don't want to, you know, like, completely separate
00:20:50.860 | it.
00:20:51.860 | An analogy to large language model training today is that, like, when you're doing your
00:20:54.900 | pre-training, you don't want, like, someone to just deliver you a data, like, the data
00:20:59.220 | mix of your different data sets is very important.
00:21:01.660 | And it's pretty similar here.
00:21:04.560 | And I think one of the highlights that we did here is really, like, focused on the human
00:21:09.300 | evaluation of the language identification model, because that actually improves the
00:21:13.260 | quality of, like, all of the underlying data if you just, like, more accurately know what
00:21:17.300 | language it's in.
00:21:19.700 | And this entire data pipeline is actually open source in this library.
00:21:23.100 | And we had an EMNLP paper describing it.
00:21:25.500 | The reason why I thought this was important is that because, like, I think data cleaning
00:21:29.020 | is actually such a fundamental underlying thing that drives model quality and people's
00:21:33.460 | data pipelines.
00:21:34.460 | You know, it's like, oh, I have this script and this other thing and this other thing.
00:21:37.740 | And so, it's actually, I think, very important to be able to recreate it and rerun it as
00:21:42.300 | part of, you know, almost like your research that you would do as follow-up work.
00:21:47.620 | And so, that's why we open sourced it.
00:21:50.540 | A few reflection things.
00:21:53.700 | For low-resource languages, even though we did a large-scale mining, I think monolingual
00:21:58.020 | data is the limiting factor.
00:21:59.300 | Like, there are many languages that do not have, like, a huge amount of text written
00:22:03.780 | online, and so, it can be very challenging to get a large amount.
00:22:07.980 | Further, I think languages and unique scripts can be extremely hard to get good representations
00:22:13.820 | of if you don't have very much data.
00:22:16.460 | There are certain languages, as well, where they were historically written in a new script,
00:22:20.460 | but now the government would like to write it in a totally new one, like the old Cheeky
00:22:25.220 | script, for example.
00:22:26.740 | And so, there's not a lot of content to represent these scripts, so it's hard to learn representations.
00:22:32.540 | And then further, a lot of the content we create, it's even after mining, it's a fairly
00:22:37.620 | limited domain, often religious content.
00:22:40.740 | Okay, so, with data discussed, I want to segue a little bit into some of the modelling work.
00:22:48.580 | Just to kind of start with, like, a high-level picture, I think there's, like, three major
00:22:53.180 | challenges when you talk about, like, large-scale multilingual modelling, and these pretty much
00:22:57.660 | apply to language models, as well.
00:23:01.780 | The first one is effective data augmentation for low-resource languages, like, how can
00:23:05.880 | you prevent the low-resource language data from just being completely drowned out by
00:23:11.140 | the time you've seen, like, all of your words of German or Russian?
00:23:14.780 | I think there's also a question of, like, scalability of the model, so even if you train
00:23:19.420 | very large-scale models, how do you prevent the representations of different languages
00:23:23.860 | from interfering with each other?
00:23:25.740 | And that leads to the last point, as well, of, like, if you give the model very limited
00:23:29.780 | capacity, then, of course, it may not have the capacity to model all of these different
00:23:34.460 | languages, and so you also need to accelerate the scale of the model.
00:23:39.340 | And so, preliminary, for those who may not have seen a translation system before, I don't
00:23:45.780 | know how many of you that practically is, so we use standard sequence-to-sequence models,
00:23:50.700 | so the input text, the, like, choral thing is what you want to translate, enters a transformer
00:23:55.060 | decoder model that then, you know, with a tension mechanism, goes to a transformer decoder
00:23:59.780 | model, and then it decodes autoregressively the actual translation, which you can see
00:24:04.740 | here in yellow.
00:24:07.020 | And so I want to talk a little bit about, like, how the data looks as we feed it into
00:24:11.900 | the models, so there's a few different ways that you might want to think about data, so
00:24:15.740 | you want to be, like, okay, did a human look at it and decide that, like, these two sentences
00:24:20.100 | are translations, or are they noisy?
00:24:22.780 | So is it limited in size?
00:24:25.540 | Another thing you can think about is, like, is the data quality dependent on some other
00:24:28.500 | factor, and so that's, like, the model-dependent thing, in which case, like, the data quality
00:24:32.500 | may be capped by the quality of that dependency, and so I think you can think a little bit,
00:24:38.940 | like, the ideal data set, it would be, like, humans have reviewed, you know, every bit
00:24:42.980 | of it, it's not noisy at all, we have an infinite amount, and it doesn't have any dependencies
00:24:48.440 | on any other models, it's just, like, pure quality, but in reality, like, closer to what
00:24:52.700 | we have are these.
00:24:54.540 | So we have a bunch of different data sources.
00:24:56.620 | We have the seed data that I discussed, like, way back in the talk, where it's a small amount
00:25:01.400 | of, like, really high-quality human-aligned data, but the only problem is that it's limited
00:25:06.260 | in size, it's, like, 6,000 sentences per language.
00:25:09.780 | We have the public bitext, so this is data that people have created over many years of
00:25:14.380 | working in translation, you know, you can download it from, like, the Opus corpus, for
00:25:18.260 | example, mostly has not been reviewed by humans, so pretty extremely noisy, in many languages,
00:25:25.360 | it's just coming from the Bible, so the size is quite limited.
00:25:28.820 | You have our mind data, so this is not human-aligned either, but it does have a model dependency,
00:25:36.660 | you know, it's dependent on the quality of the sentence encoders, and we have two other
00:25:40.540 | sources of data from back translation, so the idea of back translation, it's a model
00:25:45.980 | augmentation technique heavily used in machine translation, where you use a model to produce,
00:25:51.100 | like, pseudo-translations, like silver data, and we use two different techniques to produce
00:25:56.260 | these back translations that also are dependent on the underlying model used to make the translations.
00:26:02.460 | So this is a picture of, like, our high-level different data sources, and, like, how you
00:26:05.820 | want to think about the quality and the different axes, and so if we put them all together,
00:26:10.260 | what do we get?
00:26:11.260 | The y-axis here is the number of training pairs, and the x-axis here is the languages
00:26:16.780 | sorted by resource, so you can see, like, on the left-hand side, you have your low-resource
00:26:21.340 | languages like Wolof, and on your right-hand side, you've got your high-resource languages
00:26:26.140 | like French, the peak is English, of course.
00:26:29.700 | And so if you just look at what's available publicly, this is the distribution you get,
00:26:34.420 | and you'll see, like, a huge, huge fall-off pretty quickly, and then if you add in the
00:26:39.500 | data that we have created for mining and back translation, our goal is basically to, like,
00:26:44.940 | make the distribution a little bit more uniform.
00:26:47.700 | It's very hard on the extremely low-resource side, of course, but to make it a little bit
00:26:52.380 | more uniform so that you don't just immediately, you know, overfit on your low-resource languages
00:26:57.140 | before you've even seen, like, three shards of your German data.
00:27:02.380 | With that kind of data strategy in mind, I want to talk a little bit about mixture of
00:27:07.740 | experts.
00:27:08.740 | So this is something that we explored quite aggressively in the translation space for
00:27:12.500 | a number of years.
00:27:13.500 | You know, we could have this equal conversation about some of the debates going on, on, like,
00:27:17.940 | do you want sparse or dense architectures for large language models?
00:27:22.300 | But essentially, mixture of experts, it enables massive scale because you don't have to just
00:27:27.500 | scale, like, your kind of your dense trunk model, but you can have, like, a bunch of
00:27:31.540 | different separate experts that you activate per token.
00:27:36.060 | It also allows you to avoid language interference because the idea is that the different experts,
00:27:40.980 | they could specialize to specific languages.
00:27:43.660 | Unfortunately, it adds a ton of capacity, so it becomes pretty easy to overfit.
00:27:49.140 | So I'm going to talk a little bit about this overfitting phenomenon.
00:27:52.820 | So the top set of graphs that we're going to talk about is for the language Congo, and
00:27:59.100 | then the bottom set of languages is French.
00:28:01.940 | So you really want to compare, like, a low-resource language on top with a high-resource language
00:28:05.940 | on bottom.
00:28:07.180 | So if you just take your dense model, traditional transformer sequence-to-sequence architecture,
00:28:11.780 | that's this graph that you're showing, right?
00:28:13.780 | So there's a little bit of overfitting on the low-resource language, but you can pretty
00:28:17.580 | much regularize this with standard dropout techniques, right?
00:28:20.780 | So there's not a big problem, and on French, you know, you basically have no real problem.
00:28:25.860 | However, the minute you switch from, like, a dense architecture to a token-level MOE
00:28:30.740 | architecture, you just experience massive overfitting on the low-resource language.
00:28:35.480 | So the green line here is, like, just demonstrating without dropout the overfitting.
00:28:40.220 | And then if you add dropout, you know, you get a little bit better performance, but it's
00:28:44.020 | still overfitting quite a bit.
00:28:45.940 | Like, essentially, by, like, you know, 12K updates, you know, there's no real point in
00:28:50.580 | continuing training.
00:28:51.580 | Like, you're burning GPU, basically.
00:28:54.580 | And so one of the things we actually worked on quite a bit was, like, trying to figure
00:28:57.740 | out how to properly regularize these MOE architectures with this specific masking technique on the
00:29:04.500 | gating function that decides, like, which expert to route to in your MOE architecture
00:29:10.120 | to just try to pull back some of this overfitting effect.
00:29:13.420 | So if you look in the top right graph, the purple line, you know, you still see some,
00:29:19.860 | you know, successful regularization.
00:29:23.220 | Another thing that we did to control the overfitting effect, it's actually quite being used in language
00:29:28.660 | models today as well, is curriculum learning.
00:29:32.140 | And the idea of this is, like, how are we going to stage when languages are introduced?
00:29:37.420 | And so what we did was we tried to train a vanilla model, and then we started to measure
00:29:41.740 | when the languages begin to overfit.
00:29:44.220 | And then we basically bucketed them into different sections.
00:29:47.760 | And so for high resource languages like French, you want to start it early, and it needs to
00:29:51.860 | be trained the entire way.
00:29:53.660 | But for a lower resource language like Wolof, you know, after maybe like 100K updates, it's
00:29:59.220 | done.
00:30:00.220 | So the rest of the time is just overfitting.
00:30:01.980 | And so it actually gets worse the more you train it.
00:30:03.860 | So what we did is we moved some of those lower resource languages, and we inserted them much
00:30:07.900 | later into the training schedule.
00:30:09.940 | So you start training your high resource, then you start training your mid resource,
00:30:13.720 | and then your low resource, and then your very low resource.
00:30:16.140 | And so by the end, you know, everything in theory has trained and is not as overfit as
00:30:21.140 | it would be without this kind of technique.
00:30:24.180 | So I want to show some results.
00:30:25.740 | So first, I want to show results on existing data sets.
00:30:28.980 | So before we get to 200 languages, like let's just talk about 100 languages.
00:30:33.140 | And so this is the Flores 101 dev test.
00:30:35.880 | It's important to compare to this because this is where like existing benchmarks in
00:30:39.780 | the community lie.
00:30:40.780 | Whereas on 200, of course, we can put up anything, you know, because it's the first work on that.
00:30:46.300 | So the first column is translating out of English.
00:30:51.180 | So English to Chinese, English to Icelandic, anything like that.
00:30:54.860 | The second column is translating into English, so Chinese to English.
00:30:58.880 | The third column, XXYY, it's translating any cross pair, not involving English.
00:31:04.700 | And the last column is the average.
00:31:06.780 | So if you look at the first set of rows, this is a comparison on models that cover 87 different
00:31:11.460 | languages.
00:31:12.460 | So there was this paper MTM 100.
00:31:14.780 | There was also this deep net paper.
00:31:16.720 | So you can see the average blue score.
00:31:18.880 | Blue is a standard translation metric, essentially a metric of word overlap.
00:31:23.640 | So we're looking at blue score here.
00:31:25.460 | And so you can see the last row NLB 200, even though we cover 200 languages, the blue score
00:31:32.100 | is substantially above some of the existing work.
00:31:35.380 | Now if we look at 101 languages, only the Delta LM paper from Microsoft at the time
00:31:40.220 | covered that number of languages.
00:31:42.340 | And so if you compare on all of the different cross sets, similarly, you see that this no
00:31:47.340 | language left behind model is much stronger in terms of blue.
00:31:51.960 | One thing really quick on the variance of these blue numbers, I think it's important
00:31:55.140 | to understand, like, is something statistically significant or not?
00:31:58.340 | I think about 0.5 blue is kind of like the general, like, plus minus that you'll see.
00:32:04.660 | And so if it's like above that, it's usually a statistically significant metric improvement.
00:32:10.340 | Okay.
00:32:11.340 | So now I want to talk a little bit about Flores 200 results.
00:32:14.920 | So here's similar, like the first chunk of columns translating out of English, then like
00:32:19.300 | next chunk is translating into English, then you have like your cross pairs, and then you
00:32:23.500 | have your average.
00:32:25.660 | So we have this blue metric as well.
00:32:27.920 | We also have a character level metric based on CHRF++ that's commonly used in the translation
00:32:34.860 | community.
00:32:35.860 | So I think looking at these numbers, of course, like there's no baseline work to compare to
00:32:39.140 | unlike on the previous slide.
00:32:40.980 | And so, you know, when we get to human evaluation in a little bit, it'll be more concrete.
00:32:45.620 | But I think generally, one of the kind of rules of thumb I have for these types of numbers
00:32:50.140 | is like around 30 is like pretty reasonably becomes usable.
00:32:57.080 | And I think another thing, like if you compare these supervised pairs to zero shot pairs,
00:33:02.420 | I think we don't see like a huge drop off on zero shot, which indicates the model has
00:33:06.580 | like some sort of generalization, even if it didn't see that translation pair directly
00:33:11.140 | during training.
00:33:13.060 | Another way to calibrate some of this is to compare to Google Translate.
00:33:17.100 | And so if you compare to Google Translate, no language left behind is quite a bit better
00:33:21.220 | at translating into English, and not as good as translating out of English, although if
00:33:26.220 | you like average across everything, it's a little bit better.
00:33:31.580 | I want to talk a little bit about human evaluation as well to complement some of our discussion
00:33:36.700 | on automatic evaluation.
00:33:38.180 | And so I think, you know, automatic metrics, fast, really good for research iteration,
00:33:43.860 | impossible to move forward without.
00:33:45.460 | But human evaluation is really the real deal here.
00:33:49.440 | And so we had this paper at Amta on how to make this human evaluation very consistent
00:33:54.740 | and scalable across different language pairs.
00:33:57.420 | I think this goes back to the kind of evaluation data set point that I was making at the beginning
00:34:01.880 | of the talk, where, you know, if you're a professional German translator, you're really
00:34:06.380 | good at evaluating the quality of your German translation.
00:34:10.180 | But beyond that, you know, there's not a lot of consistency.
00:34:14.080 | And if you evaluate translation on like a five point scale, you know, like a five translating
00:34:19.860 | between two languages and like a three translating between other two languages, like, are those
00:34:23.660 | really comparable?
00:34:25.060 | And so we had this entire experiment methodology on how we might want to make this a little
00:34:30.140 | bit more comparable.
00:34:32.300 | So I want to show some results now on this.
00:34:35.400 | So the y-axis here, so the metric is called XSTS, so metric for how we're doing this human
00:34:41.020 | evaluation.
00:34:42.280 | The y-axis here is actually the delta.
00:34:45.740 | So anything, you know, it's a five point scale.
00:34:48.660 | So it's a delta, not the raw score.
00:34:52.020 | The x-axis here is a bunch of different translation directions that we evaluated.
00:34:56.740 | So the gray set is translating into English.
00:34:59.880 | The green set is translating non-English directions.
00:35:03.400 | So like French to Wolof.
00:35:07.180 | And then the blue set is translating out of English.
00:35:10.120 | And so what you're looking for is like a positive delta indicates that our modeling architecture
00:35:16.100 | is much better.
00:35:17.140 | So what the delta is between is like a baseline transformer model just trained on all of our
00:35:23.180 | data versus like the final no language left behind model that we created.
00:35:27.440 | So the data is actually the same for both of them.
00:35:29.740 | That's how we get all 200 languages.
00:35:32.200 | So we're just measuring here the human eval of the modeling improvements.
00:35:35.300 | And so you can see most of the delta is pretty noticeable.
00:35:41.520 | Some of them not so much like, you know, I don't know, Zulu to English, we didn't seem
00:35:47.460 | to improve very much, but in general, like it's an improvement detectable by human evaluation.
00:35:52.580 | You might also ask like, OK, what is the statistically significant difference here between about
00:35:57.100 | 0.2 to 0.3 plus or minus is something that's like pretty noticeable and like above 0.5
00:36:04.300 | it's very noticeable.
00:36:07.180 | One of the things that I also want to get at in evaluation is that there's many different
00:36:13.220 | facets of model evaluation.
00:36:15.820 | And I think if you look at like all of the different like LLM leaderboards or like the
00:36:19.120 | transparency reports or whatever, you like begin to internalize this pretty quickly.
00:36:23.620 | But what we just looked at are just like very high level summary numbers.
00:36:27.480 | And they don't really tell you like what exactly are the errors and like is it ultimately usable
00:36:31.920 | by people?
00:36:32.920 | Is it like a safe thing that people can rely on?
00:36:35.480 | And so one of the things we really focused on is user safety.
00:36:39.680 | And some of that manifests in some of the toxicity work that we did.
00:36:44.200 | And the driving thing here is that like not all errors in translation are made equal.
00:36:48.560 | So during COVID, there was this one that was like really went viral circulating around,
00:36:53.000 | but the message during COVID is like you got to wash your hands.
00:36:55.800 | But the translation producers like you got to hold hands, which I think is like exactly
00:36:59.480 | the opposite of what you want to do.
00:37:02.260 | And other types of measurement errors are really important as well.
00:37:05.580 | So if you're like telling someone how far they want to go, and you're like, hey, you
00:37:08.880 | want to travel like five kilometers, and then your translation is like travel 500 kilometers.
00:37:13.840 | It's a completely different type of issue.
00:37:16.820 | And so what we did for toxicity, which is a big focus for this work, is that we collected
00:37:21.720 | different toxicity lists for all 200 languages.
00:37:25.760 | And so why do I care so much about toxicity?
00:37:27.720 | I think it's a user safety thing.
00:37:29.760 | So if you input like some perfectly benign text, and then the output is profanity, I
00:37:34.400 | think it's just like really unexpected.
00:37:36.800 | And it breaks a lot of trust in the system.
00:37:39.160 | And it's an extremely poor experience for people.
00:37:42.560 | That being said, it's also a very, very challenging thing, because it's extremely culturally specific.
00:37:47.800 | So things that are slurs, or insults in certain languages, they don't really generalize across
00:37:55.040 | cultures, which means that things like this are very challenging to create.
00:38:00.460 | And I also was very interested in this direction, because I think it's broadly useful for all
00:38:04.480 | sorts of different type of detection, things that you need to do, and also mitigation.
00:38:09.480 | And so even though we developed this in the context of translation, it can be used very
00:38:13.560 | broadly in other types of NLP applications.
00:38:17.880 | This is also open source.
00:38:19.040 | You can download it.
00:38:20.040 | You have to type in a little password that's in the GitHub repo, just so that you don't
00:38:24.160 | accidentally like download and realize you have files of like curse words all over your
00:38:28.480 | computer.
00:38:29.480 | Okay, so I want to end a little bit with some thoughts about future directions.
00:38:34.620 | And before I get there, like, you know, there's like a 190 page paper that like writes up
00:38:39.880 | like all of this in far greater detail, in case you're curious.
00:38:45.320 | So a few future directions that I think I'm really interested in, and some of these like
00:38:50.440 | are also very applicable to things like speech, is that I think one of them is more explicit
00:38:55.600 | multilingual.
00:38:57.760 | So I think a lot of approaches to multilingual have been like, hey, you know, we have this
00:39:02.440 | thing that's working well for one language, like, let's try to scale it to a bunch of
00:39:06.760 | different languages, and then we're going to put them all in the same modeling bucket
00:39:10.000 | and just kind of like hope that the model learns a lot of these different representations.
00:39:14.760 | But I think there's a lot of potential room for explicitly bringing in, like the fact
00:39:20.600 | that you know, it's multilingual into the architecture more.
00:39:25.360 | And so, you know, it's possible to capture more nuances between languages or different
00:39:32.360 | relationships between languages.
00:39:35.600 | The other one is continued support for everyone.
00:39:37.960 | I think it's like something reflecting on this project is that, you know, going from
00:39:42.520 | 100 to 200 was already pretty challenging, but going beyond a lot of the techniques that
00:39:47.320 | we developed here are not necessarily that scalable.
00:39:51.280 | This is actually what inspired some of our work on speech translation as well.
00:39:55.320 | So if you recently saw like the seamless M4T release, or like the unwritten languages,
00:39:59.920 | like we did a lot of modeling of Hokkien, and I think that goes into this direction
00:40:03.740 | really well, because many of the languages that people want to use are like spoken first
00:40:08.740 | languages and not necessarily like primarily written.
00:40:13.120 | And then I think the last thing that I'm still really passionate about is like continued
00:40:17.120 | increased ease of use and training of these models and like democratization for the community.
00:40:23.040 | So one of the things that we tried to do in this work is just like really, really clearly
00:40:27.280 | write down everything that we did, and like open source, like even the data pipeline and
00:40:31.720 | things like that.
00:40:32.720 | And so that's where you get like all of the repos that I linked and, you know, like a
00:40:37.040 | huge write up.
00:40:38.040 | But I think if someone were to try to reproduce this for their own language, and many people
00:40:41.800 | have, like, I'm not saying that that hasn't been, but it's like, if you wanted to like
00:40:45.520 | do this, it would be extremely, extremely hard, because there's like so much different
00:40:51.200 | things going on.
00:40:52.200 | So I think most of the what we've seen is like people have downloaded the base model
00:40:55.800 | and fine tuned it for their own language.
00:40:58.160 | But it's pretty hard to just like add on many, many more languages to the system, because
00:41:03.160 | of how complicated all the moving parts are.
00:41:06.040 | And so I feel like something for the translation community overall, is like how to how do we
00:41:11.280 | simplify a lot of these things.
00:41:13.160 | And I think that's where like a lot of fundamental modeling innovation could help us get to.
00:41:19.080 | And so, yeah, I got a chance to give this talk.
00:41:21.440 | But of course, the work is like being done by a huge team of people that I've cited here.
00:41:27.440 | But yeah, if you want to use any of this, or read more about it, like everything is
00:41:31.840 | linked from this main GitHub repo here in Fair Seek, and you can like click on everything
00:41:37.680 | else afterwards.
00:41:38.680 | But yeah, maybe maybe I'll go back to Steven, if we have any questions or anything else
00:41:44.200 | like that.
00:41:45.200 | All right.
00:41:46.200 | No, thanks for the great talk.
00:41:47.200 | Yeah.
00:41:48.200 | If anybody has any questions, feel free to unmute and ask.
00:41:57.360 | Did you consult with a lot of like native speakers for like, you know, profanities and
00:42:02.920 | this type of stuff?
00:42:03.920 | Like, how are you able to get access to the, you know, low quality languages or low resource
00:42:10.320 | languages and make sure the translations are correct?
00:42:12.760 | Yeah, yeah, that's a really good question.
00:42:15.040 | I mean, I think it's the most important to consult like a bunch of native speakers across
00:42:19.880 | the entire development process.
00:42:21.800 | So part of our original thing was just like interviewing a bunch of people to understand
00:42:25.240 | like what they're looking for in a high quality translation.
00:42:28.760 | And then we have like an entire professional translation team hired, which took quite a
00:42:33.480 | long time to find, to consult with along the process.
00:42:40.280 | And then right now, like we also have some of the things like toxicity lists are open
00:42:44.200 | to the community.
00:42:45.200 | So if you make like a pull request, we try to like, you know, validate that it's like
00:42:48.960 | a useful addition and then like try to merge it in as well.
00:42:56.880 | We have a question in the room.
00:42:58.280 | Let's see if that comes over soon.
00:43:00.600 | So I'll speak, so like, did you spend most of your time in the data pipeline state?
00:43:10.360 | Yeah.
00:43:11.360 | Yeah.
00:43:12.360 | Yeah.
00:43:13.360 | A good question.
00:43:14.360 | I think the question is, did you spend most of your time in the data pipeline state?
00:43:16.920 | It ended up being about like, kind of like 50/50, like data or more like driving work
00:43:23.160 | and then like 50/50 on the other side, like modeling and evaluation work, because once
00:43:27.680 | like the data is set, then there is a lot and a lot of iteration on the modeling side
00:43:32.280 | to figure out like, okay, which, how much of the data should we use?
00:43:35.800 | Like how should we portion the data?
00:43:37.000 | How do we prevent overfitting?
00:43:38.120 | What is the right architecture?
00:43:40.280 | But a lot of work goes into the data because I think if you don't have high quality data,
00:43:44.720 | you know, you just can't get a good model.
00:43:49.120 | And for data mining, how do you mine the data?
00:43:52.400 | Do you use like Selenium or how do you mine the web?
00:43:56.840 | Yeah.
00:43:57.840 | So for the web, we start with Common Crawl.
00:44:00.520 | So we downloaded all of the different dumps of Common Crawl, and then we use HTML parser.
00:44:05.160 | I think now, like, you know, if you download, for example, the red pajama data set, like
00:44:09.360 | they've done a lot of this, like parsing and stuff.
00:44:12.160 | And then we have like large scale pipelines that are set up, like you can use Spark, for
00:44:17.000 | example, to process these things to like split all of the different sentences out, run your
00:44:21.960 | language identification, you know, you can do different heuristic cleaning.
00:44:26.560 | There are certain languages where it's like very, actually very challenging to identify
00:44:29.680 | what is a sentence.
00:44:30.680 | Like, I think in Thai, there is no like period.
00:44:34.320 | So you have to like use different models to identify what is a sentence and I parse some
00:44:38.840 | of those things out.
00:44:40.560 | And then we end up with, you know, our monolingual data dump.
00:44:44.280 | What is Common Crawl?
00:44:47.960 | Is it software that you use for data sets?
00:44:51.200 | Oh, yeah.
00:44:52.200 | Yeah.
00:44:53.200 | Common Crawl is kind of like an open source version of the web that runs, I think, maybe
00:44:57.200 | quarterly, I would have to check.
00:44:58.920 | But yeah, if you go to like commoncrawl.org, you can download it.
00:45:01.640 | But warning, it's like, very large.
00:45:05.440 | Hey, I have a question.
00:45:14.040 | You might have mentioned this briefly, but I'm wondering how ChatGPT and GPT-4 does on
00:45:18.120 | this.
00:45:19.120 | Like, does just more scale and pre-training data help as well for low resource machine
00:45:25.400 | translation?
00:45:26.400 | Yeah, yeah.
00:45:27.400 | Good question.
00:45:28.400 | Actually, there have been some studies done on like how, you know, these systems work.
00:45:31.600 | I think for high resource languages, it's actually quite beneficial to scale up.
00:45:36.320 | I think part of that is because the models have some innate generalization.
00:45:40.480 | And so one of the challenges that people talk about different things in different languages,
00:45:44.040 | so like seeing that knowledge in another language can actually help the generalization.
00:45:48.800 | But on low resource languages, it's, yeah, the performance is pretty difficult, especially
00:45:54.800 | on some of these translation benchmarks.
00:45:57.680 | I also think that language models, in terms of being trained for like a translation objective,
00:46:03.280 | tend to score worse on translation benchmarks, because language models are like approximately
00:46:07.560 | capturing the same thing, whereas translation models, you really try to align the meaning
00:46:11.760 | a little bit more.
00:46:13.040 | But yeah, so I think for low resource, still pretty challenging.
00:46:17.720 | But yeah, one thing that's interesting is, for most English language models that can
00:46:21.600 | actually do a reasonable job at producing other languages, because it's impossible to
00:46:25.840 | get rid of other languages in your English specific data.
00:46:28.920 | So things like French or German will work reasonably.
00:46:33.000 | So just to clarify, you said language models trained with a translation objective do better,
00:46:43.160 | right?
00:46:44.160 | Because they tend to do better, like if you fine tune for the translation task, it will
00:46:49.840 | tend to do better.
00:46:50.840 | Yeah, that makes sense compared to like, for example, some few shot in context examples.
00:46:56.640 | Right, right, exactly, exactly.
00:46:59.280 | One other question is, do you see this being similar to, for example, fine tuning on particular
00:47:07.040 | expert domains, which might also have less data and low resource and as well as domain
00:47:14.960 | specific jargon and so forth?
00:47:17.320 | Yeah, I mean, I think if we were to restart this project, now, I think that would be one
00:47:22.520 | of the first things we also explored, or at least like an extremely strong baseline, where
00:47:27.160 | if you like take some of the data and you try to fine tune, or, you know, try to do
00:47:31.560 | domain adaptation, I think that's also where like some of the like retrieval type approaches
00:47:36.520 | go in for, you know, translation, but also large language modeling work, where you try
00:47:40.960 | to have like a separate domain that you can like retrieve some text in for adaptation.
00:47:45.400 | I think all of those approaches are pretty promising.
00:47:49.120 | All right, great, any other questions?
00:47:59.520 | One quick one on the point of irreplaceability on one of the slides, I think you showed some
00:48:04.320 | peak results with zero shot that were higher than just the base model.
00:48:10.160 | Do you think that's because there might still be some overfitting on those low resource
00:48:14.560 | languages?
00:48:15.560 | Yeah, good question.
00:48:17.040 | So for our large scale mining, we don't mind like every single possible cross pair.
00:48:23.080 | So like, like Icelandic Wulof, it's probably not like the most in demand translation direction.
00:48:30.200 | And so we did not mind like all 200 times 200, because it's like really producing like
00:48:34.080 | a combinatorial explosion.
00:48:36.040 | And so that's where the zero shot results come from, where, you know, you don't need,
00:48:40.620 | you don't have training data directionally in that pair, but the model has seen both
00:48:44.560 | the input and the output.
00:48:46.600 | And so I think those results are pretty good, well, they're good for certain languages,
00:48:52.760 | which I think goes to show like the generalization capability.
00:48:56.840 | And it's not like as critical to have like every single pair covered, but many of them
00:49:01.380 | are not as good.
00:49:02.480 | And so you see overall, the performance is lower, even though on certain languages, it
00:49:06.200 | can perform better than you expect.
00:49:08.060 | But that's because it has seen the input and the output.
00:49:10.260 | It's not zero shot on like completely unseen language.
00:49:14.040 | I have a question, but I wanted you to also, you know, do something related to transcription
00:49:30.980 | of audio information.
00:49:33.440 | Yeah, good question.
00:49:35.700 | So in this project, no, not so much transcription.
00:49:39.080 | But we had a follow up work that we released actually just like a month or so ago, called
00:49:43.240 | seamless M4T, which is like a joint model for both speech and text translation.
00:49:48.600 | And that's where we do leverage a lot of audio transcription, because that also has like,
00:49:53.200 | it helps us bridge, you know, like the spoken data and the text data to leverage both of
00:49:57.240 | them together.
00:50:00.240 | Right, just to clarify, the supervised fine tuning, it worked better, right, compared
00:50:12.560 | to other methods.
00:50:16.680 | So actually, in this work, it was a couple years ago now.
00:50:19.240 | So supervised fine tuning wasn't as common as it was now.
00:50:23.680 | But I think in the literature, if you want to use like a large language model to do translation,
00:50:28.280 | it's currently best, yeah, if you do some supervised fine tuning.
00:50:31.880 | I'm just wondering about that, because the way as humans, right, we don't just learn
00:50:36.960 | by looking at pairs of the same thing in different languages, and kind of memorizing how to map
00:50:42.400 | from one to the other, we kind of learn in a more unsupervised way, where if we know
00:50:47.300 | both languages, then we can kind of naturally translate between them.
00:50:54.560 | And I guess it makes sense for an LLM, why having supervised examples would help.
00:51:00.200 | Yeah.
00:51:01.200 | Yeah, I mean, I think it's like the base foundation model continues to improve in quality.
00:51:06.680 | I think that's where the quality will probably improve, and you don't need less and less
00:51:10.180 | fine tuning.
00:51:11.180 | I mean, do you think that's like the open AI approach, like if you have the best foundation
00:51:14.800 | model, then you don't need as much like domain specific fine tuning.
00:51:17.760 | I think like, you know, like at the start, when I started working on text generation,
00:51:21.240 | there was like translation researchers, and like summarization researchers, and like question
00:51:24.440 | answering researchers, and they like work very differently.
00:51:27.280 | But now it's like, it's all driven by the same underlying thing, and you're not like
00:51:30.680 | a specialized summarization researcher anymore.
00:51:33.640 | Right.
00:51:34.640 | I think that's that makes a lot of sense.
00:51:38.840 | Do we have any other questions?
00:51:46.480 | Ron, any more in person questions?
00:51:57.120 | I don't think so.
00:52:00.000 | Okay, great.
00:52:01.000 | All right.
00:52:02.000 | Well, thank you, Angela, for the very interesting and great talk again, and for taking the time
00:52:08.440 | and we hope, yeah, we hope that you can keep in touch and if anybody has any other questions,
00:52:15.960 | feel free to get in touch with Angela.
00:52:19.040 | All right.
00:52:20.040 | Thanks so much for having me today.
00:52:21.040 | Bye, everyone.
00:52:22.040 | Transcribed by https://otter.ai
00:52:22.040 | Transcribed by https://otter.ai
00:52:23.040 | [BLANK_AUDIO]