DeepSeek Math + The Mamba in the Llama: Distilling and Accelerating Hybrid Models!
00:00:00.000 | Yeah, sir. Yeah, I need you to close the door because I can hear myself. Yeah. And the reason why the DeepSync Math paper is in particularly important, right, is that the previous time around when we went through the DeepSync R1 paper, we essentially kind of just skimmed this through, we skipped past this, but the DeepSync team credited the DeepSync Math paper as one of the key things behind like creating the whole reasoning data set and things like that.
00:00:28.440 | There was a lot of emphasis on the math and, and math data set as being the entire path of how they achieve R1 performance. Well, R1, the paper itself covered more, more into the technical aspects of like how they got it to scale, how they got it to train that far. This is more of like their previous math model that formed the foundation on how they built the data sets involved for the reasoning training.
00:00:52.840 | So, so this is a much older paper and what it did, what it covered was a 7B math model, which at that point in time when it came out, right, was literally one of the best math model out there for its size.
00:01:07.660 | So, in fact, in fact, in fact, are outperforming even if at that point in time, even like some of the GPT-4 APIs, though, if memory serves me right, then GPT-4 updated itself to like be better than the math paper, the math model.
00:01:20.480 | So, but for a period of time, it was better. And what was more exciting is actually for those who were at Kaggle, literally for a very decent period of time, this model just dominated all the math context in Kaggle.
00:01:34.920 | And this is literally how they did the pipeline to build the data set, which based on the responses of all the DCR1 papers and some through Twitter and some through the interviews, it is responsible for how they actually build up the data set subsequently.
00:01:54.180 | So, so yeah, this is the performance there. So introduction, you know, skips, skips, skips. Okay, so here, right, the first, they cover the first step, right? And the challenges is actually to build the data set that is focusing on math itself.
00:02:09.000 | So there are existing data set like open web math and things like that, but it's, in for most part, insufficient. So, so this is really more, this first part is more of like a data set paper, actually.
00:02:21.900 | And what they did, right, what they did, essentially, right, is that using, using known good math sources, yeah, known good math sources, right, they actually scan common crowd for relevant math articles, papers, and so on.
00:02:40.860 | And this is what they use for the pre-training of the math-based model, including existing math data sets. So, so, and wait, I'm sure, I think I'm remembering.
00:02:51.880 | out of sequence. Where was it? Yeah, data collection decontamination. So here it is. So when, when, when they came, when they went through here, right, right, they, they started with 500,000 data points off for the, for the web corpus there, as such positive training examples of these, these are known good examples, and then subsequently, right, they, they, they did the embedding search, so vector dimension on that, and they basically
00:03:15.880 | used the, they used the existing models, right, to crawl through all the common crawl pages, to find the relevant math domain papers, to filter down the data set.
00:03:27.880 | So, obviously, like, obviously, like, to crawl the entire common crawl is, with AI models is not practical, so what they did is that they, they, they, they require at least a, a match to one, the n-grams
00:03:39.880 | of three words, so they used the existing good data set, so the minimum number of word occurrence to three, oops, I can tap that, accordingly.
00:03:46.880 | And then, and then, and then, and then, and then subsequently, right, subsequently, that resulted in 40 billion pages, and, and then subsequent, and then, and once they started using that, right, they subsequently used this to train the model.
00:04:12.880 | So, um, so, um, so, um, yeah, um, and then subsequently, like, when they try to, it covers the training settings itself.
00:04:33.880 | Um, fairly standard, but what, what, what, what was interesting is that for them, right, they found that the downstream performance, subsequently, when they did train the model, pretty much outperform every other math data set prior to that.
00:04:50.880 | And then, uh, if from a token to performance perspective, um, because, because of how they thoroughly deduplicate the, try and, and try to, uh, curate a diverse topic.
00:05:00.880 | Um, subsequently.
00:05:02.880 | Eugene, Eugene, can I stop you there?
00:05:04.880 | Yeah.
00:05:05.880 | One question.
00:05:06.880 | So was this the reason because they got a better data set where they saw the thing blow up?
00:05:11.880 | or was it more of that they improved the training part of it and that's why the model started to show up?
00:05:18.880 | Um, so right now, previously, right, so you have to see, right, this is actually a fairly standard model.
00:05:23.880 | This is not a MOE 256 model.
00:05:26.880 | So this is just purely data set, uh, from a point of view of the data set.
00:05:30.880 | Even the, the parents that they shared previously, it's a fairly standard thing.
00:05:33.880 | So hypothesis, I mean, this, this one, I'm actually need to go through the data set to double check it.
00:05:38.880 | It would be actually for the, one of the reasons why they did the search and scan through the common crawl and filtering, right.
00:05:44.880 | For those math concepts, right.
00:05:46.880 | Is that, um, if you take existing data, math data sets, which tends to be like, let's say using one of it is a filter set of ARXIV papers.
00:05:56.880 | It tends to be math data that is a little bit overfitted to a certain framing or style or narration.
00:06:03.880 | Well, well, they wanted just a lot more data on math in general.
00:06:07.880 | So this is literally the, I guess, in a sense, a diversity and web scaling of the math data set.
00:06:12.880 | Does that make sense?
00:06:13.880 | Yeah.
00:06:14.880 | Uh, I think I will need to double check this, but like, it will not surprise me if like, like random reddit discussion about math suddenly appeared in the data.
00:06:25.880 | Things like that.
00:06:26.880 | So that part I definitely need to fact check because I have, uh, uh, uh, uh, respectively.
00:06:32.880 | But the idea is that it allows them to go beyond what's the existing sources.
00:06:37.880 | Um, this is no different from actually existing.
00:06:41.880 | Uh, techniques per se, but I think, I think it's more of like, no one really bothered doing it for math.
00:06:48.880 | So focus prior to this.
00:06:50.880 | So yeah, that's what I did.
00:06:51.880 | But, uh, I think the next step, right.
00:06:55.880 | Beyond that, right.
00:06:56.880 | It's where, where, where, where, where is the important part where it's the, the seat for R1 is here.
00:07:03.880 | The, the, uh, problem solving step-by-step reasoning.
00:07:06.880 | So, uh, so they, they, they started doing the chain of thought prompts respectively.
00:07:11.880 | And to, and because math is, uh, easy to validate code wise, like you can validate the generated result matches.
00:07:20.880 | They can rinse and repeat that respectively.
00:07:23.880 | So, so this, so this is, uh, so this is where the original seat for deep seat R1, which at that point in time, before we call it reasoning, everyone just calls it chain of thought.
00:07:33.880 | Um, and, and essentially they, they, they prompted the model.
00:07:38.880 | They generated the data, they validated it, and then they repeat the process respectively.
00:07:43.880 | So this is how they bootstrap R1 essentially.
00:07:46.880 | So, um, and then subsequently they cover like, like training, introducing tool use.
00:07:53.880 | And then subsequently they prompt the model.
00:07:56.880 | And then if they get a result, it, then it reinforces itself.
00:07:59.880 | You have to understand that this part, right.
00:08:01.880 | Well, they did have some humans to like validate and check stuff, right.
00:08:04.880 | The big thing here, right.
00:08:06.880 | Was that this is fully automated for most parts.
00:08:10.880 | So this is how they bootstrap.
00:08:13.880 | They are reasoning data.
00:08:15.880 | Uh, without, I would say at that point in time, because this, um, reasoning models wasn't even a thing yet for open AI.
00:08:23.880 | Without even, uh, without needing them needing open AI to generate all this reasoning data for them.
00:08:29.880 | Because at the end of day, math is math.
00:08:31.880 | If the model gets it right, provide formal proof.
00:08:33.880 | It succeeds.
00:08:35.880 | So they subsequently repeat this with other domains from, from what was understood.
00:08:44.880 | Uh, and then that lead to what the current reasoning models that are that we have.
00:08:49.880 | But even then they said a lot of it is just based on math and it's scale accordingly.
00:08:53.880 | Uh, currently there's a coordinator open source effort throughout multiple groups, right.
00:08:59.880 | That essentially use this paper as reference.
00:09:02.880 | And the deep seek our model to try to create reasoning data sets for math and code.
00:09:08.880 | Because code, code is similar to math in the sense that it is easy to validate.
00:09:12.880 | You can generate the code, you can generate the code, check whether the inputs and outputs are match, pass, rinse and repeat.
00:09:18.880 | And yep.
00:09:19.880 | And I think what is exciting is that if this is the case, and if, if this is really what is all that's needed to build reasoning data sets for R1.
00:09:29.880 | Um, at least as claimed by deep seek.
00:09:32.880 | It means, right.
00:09:33.880 | They literally gave us the blueprint, right.
00:09:35.880 | Uh, and the, the rest of the community right now, as you can see on.
00:09:39.880 | You can see on cutting face, et cetera.
00:09:41.880 | I'm creating a data set.
00:09:43.880 | It means an R1 data set will be created.
00:09:46.880 | If there is an additional secret source that's needed, which the deep seek team claim that isn't.
00:09:52.880 | Then it's something that we'll find out in time.
00:09:54.880 | So yeah, that's why I said this, this, this, this is kind of like a prerequisite paper to R1.
00:09:59.880 | And, um, the, and it helps.
00:10:02.880 | It literally helps show, right.
00:10:04.880 | If you look at the date itself, right.
00:10:06.880 | This was when was it again?
00:10:09.880 | This was April, 2024.
00:10:11.880 | So, so, so they've been, uh, so for a lot of people who keep thinking R1 as a sudden thing, right.
00:10:16.880 | These are things that they've been building over time in the background to where it is today.
00:10:21.880 | Um, I think what is interesting here is that because they, you, the, the way it's done, right.
00:10:26.880 | Is you have a hyper specialized model focused in one domain, beats out GPT-4, for example.
00:10:31.880 | And then you take that data training on a general, much bigger general model.
00:10:35.880 | And then that's where it, it starts learning how to apply in other domains.
00:10:40.880 | Um, in this case, you can't prompt this math model for medical advice, for example.
00:10:45.880 | It never learned medical advice.
00:10:46.880 | Doesn't even know what medicine is properly.
00:10:48.880 | So yeah.
00:10:49.880 | Any questions on this part so far?
00:10:52.880 | I'm not sure whether you want to cover GPRO, PPO, but I'm not sure whether that's the most important thing about this paper, actually.
00:10:58.880 | That's in my opinion.
00:11:11.880 | Eugene, I go with 7B.
00:11:13.880 | Sorry.
00:11:14.880 | 7B.
00:11:15.880 | Why, why did they choose 7B?
00:11:16.880 | I mean, did they play around and come to 7B?
00:11:18.880 | Or they thought that was good enough?
00:11:21.880 | Honestly, my gut feel was that because, uh, if you remember this, uh, at Kaggle, right, people already, they were already decent math model at 7 to 12B to 32B size.
00:11:36.880 | So it's already been proven like a 7B model is good enough.
00:11:40.880 | And I think for them, this was just an exercise of just like finding the smallest, cheapest model that they can train that can get the job done at a good enough performance.
00:11:50.880 | Um, they might have done abolition or maybe they just picked it.
00:11:54.880 | I honestly don't know.
00:11:55.880 | It wasn't covered in the paper why they picked 7B, but it's an educated guess, I guess.
00:12:00.880 | It's, I think it's a reasonable choice.
00:12:03.880 | The alternative I would have done would probably be the 12Bs because that was fairly popular as well.
00:12:08.880 | The 12 and 14Bs.
00:12:10.880 | The 12 and 14Bs.
00:12:14.880 | The 12 and 14Bs.
00:12:16.880 | The 12 and 14Bs.
00:12:18.880 | The 12 and 14Bs.
00:12:20.880 | The 12 and 14Bs.
00:12:22.880 | The 12 and 14Bs.
00:12:24.880 | Eugene, I had a, I had a question.
00:12:27.880 | I was actually, I haven't read this paper yet.
00:12:29.880 | It's on my list.
00:12:30.880 | I was actually thinking that they were going to cover.
00:12:33.880 | They were going to say they had, they use synthetic data generated by like leaner and other theorem proving language.
00:12:39.880 | Right?
00:12:40.880 | Like I'm really surprised that they didn't leverage mathlib and like all this stuff because there's been a ton of work on theorem proving languages recently.
00:12:50.880 | And it seems so obvious to me.
00:12:52.880 | And I wonder if there's a reason why that's not being done.
00:12:56.880 | Do you know anything about this?
00:12:58.880 | I don't think we can double check it.
00:13:01.880 | But if I remember correctly, they did include other math data sets as well into the mix.
00:13:05.880 | So it doesn't mean what, what, what, what, what they did was to basically add more upside the existing data set.
00:13:13.880 | So I don't think they excluded it.
00:13:16.880 | But I'm not sure whether they added those micro languages.
00:13:20.880 | So, so like, no, what I mean is, oh, I see.
00:13:24.880 | Okay.
00:13:25.880 | You could have, they could have used like mathlib itself.
00:13:28.880 | Yeah, that's, that makes sense.
00:13:30.880 | Okay.
00:13:31.880 | It's like a few math data sets that they used previously.
00:13:35.880 | I apologize that I'm trying to figure out how to best use my phone in this.
00:13:39.880 | But like, if, if you told me, okay, RJ, go create a math model.
00:13:48.880 | I would, of course, kind of copy what they've done here.
00:13:52.880 | But I would also just like have, have, you know, a model generate proofs you like interesting proofs using using lean right.
00:14:05.880 | Right. And then I would, and, and like sort of use that as synthetic data set to train the model, because I think that, you know, like that, that will show the model how to do like proper proofs.
00:14:20.880 | Right, so that you don't have to bake in the logic of the proof into the model, like you're just doing it through the data set, but that you are proving proper reasoning, or you're creating proper reasoning steps that are verifiably correct.
00:14:36.880 | Yeah.
00:14:37.880 | So proof wiki is in, in there.
00:14:39.880 | So.
00:14:40.880 | Okay.
00:14:41.880 | Yeah.
00:14:42.880 | Interesting.
00:14:43.880 | Okay.
00:14:44.880 | It may not be the exact data set that you quoted, but.
00:14:45.880 | Yeah.
00:14:46.880 | Yeah.
00:14:47.880 | Yeah.
00:14:48.880 | Okay.
00:14:49.880 | Yeah.
00:14:50.880 | And maybe proof wiki is at leans on no, no pun intended leans on lean.
00:14:54.880 | Okay.
00:14:55.880 | Yeah.
00:14:56.880 | That makes sense.
00:14:57.880 | So, yeah.
00:14:58.880 | Um, yep.
00:14:59.880 | Um, is there any other questions for this, uh, segment for, I think like subsequently the GPRO PPO.
00:15:09.880 | I don't see.
00:15:11.880 | When I read through it, I don't see something that is like, I'll classify as an innovation.
00:15:16.880 | There is just kind of like, we made the data set.
00:15:19.880 | We taught it how to use tools.
00:15:21.880 | We, we, we, we improve on the data respectively.
00:15:24.880 | And then.
00:15:25.880 | So the, in this case, um, reference model, then got the reward.
00:15:31.880 | It, it found out that the proof is valid.
00:15:34.880 | Train it again, rinse and repeat.
00:15:36.880 | I, yeah, I don't see anything new in here unless I missed it.
00:15:42.880 | I apologize because I only like skim through the paper in like half an hour prior to this.
00:15:47.880 | Yeah.
00:15:48.880 | If I made something.
00:15:49.880 | Okay.
00:15:50.880 | If I made something.
00:15:51.880 | Okay.
00:15:51.880 | There's a claim that GRPO is much more efficient than PPO.
00:15:56.880 | Um, the way I do PPO is have the same network kind of, uh, give you the value function and the policy.
00:16:06.880 | So I don't know why they claim GRPO is more efficient.
00:16:10.880 | Oh no.
00:16:11.880 | Yeah.
00:16:11.880 | I saw that phrase.
00:16:12.880 | I know which one you're referring to.
00:16:13.880 | Uh, I would say.
00:16:15.880 | Um, if I remember the exact wording was, where were you, you didn't happen to know where the line is.
00:16:24.880 | Uh, you just, uh, passed it.
00:16:26.880 | I mean, they say it's more, uh, effective and more efficient, but I think in more recent papers or in the R1 paper, they push on the efficiency, uh, even more.
00:16:38.880 | Um, I think, I think another thing to consider is that when they say efficiency, right?
00:16:43.880 | They, they also probably take into account the VRAM overhead and the compute overhead rather than, because here's the, and then when you're compute constraint, right?
00:16:53.880 | Your, your consideration is not.
00:16:55.880 | Um, one thing that strikes me about deep C and, and, and this is very similar to how we operate the other KB group as well, is that we are not research purists per se.
00:17:06.880 | If you are research purists, right?
00:17:08.880 | You'll be like, Hey, if one token step, PPO versus GRPO, um, PPO is better.
00:17:17.880 | Then GRPO is worse.
00:17:19.880 | Like per token step, like, like, like, like, like if you are research purists per token step, but for deep C and for us, you'll be like, if GRPO takes half the RAM and compute, VRAM compute.
00:17:32.880 | Even if it's not as efficient, given my compute budget, it is more efficient.
00:17:38.880 | You, you, you, you get what I'm saying.
00:17:40.880 | So it's a, I don't think it's a contradiction there per se.
00:17:43.880 | Um, it's like, it's like, I, the, the struggle here is because they didn't show abolition.
00:17:49.880 | This is how I interpreted their claim.
00:17:52.880 | They found it more efficient on your hardware.
00:17:55.880 | And then they proceed with this, um, rather than, rather than, um, this is GRPO is more efficient than PPO given the same amount of steps.
00:18:05.880 | Yeah.
00:18:06.880 | It didn't sound like.
00:18:07.880 | Eugene, I thought when we were covering the, uh, the, the R1 paper that there was some discussion of how they didn't need the value model.
00:18:16.880 | And that was why it was more efficient.
00:18:18.880 | Yeah.
00:18:19.880 | If you, if you, if you look at the, the diagram of PPO on, on page 13, so there's that, that value model on the PPO side, that's not on the GRPO.
00:18:30.880 | I thought my understanding was that was the thing that they, that a lot ill GRPO allows you to use the average of the group instead of having a training, a value model.
00:18:41.880 | And that, that was where the efficiency increase came from.
00:18:44.880 | Yeah.
00:18:46.880 | So, so like, once again, you read based on their language and trick and how they think things through it, significantly reduce, reducing training resource.
00:18:55.880 | So, yeah, yeah, it's like, less VRAM.
00:19:00.880 | You have to remember that they, they, they are, well, well, they are not GPU, that GPU poor, they are not exactly GPU rich like the big labs.
00:19:11.880 | So, so these are.
00:19:12.880 | My point is in other, in other networks, or, uh, you can kind of use a common trunk for the policy and for the value model and just have two prediction heads.
00:19:23.880 | One that predicts the policy, the other one that predicts the value.
00:19:26.880 | So like that, you don't always need two models.
00:19:29.880 | So I wonder if, uh, the usual setup is two models or one model that's multitask for, for, um, this RLHF models.
00:19:40.880 | So then the claim that you need just one model here, it's a bit, uh, exaggerated because usually, uh, you may use a multitask model for policy and value.
00:19:52.880 | I mean, you can see in some older RL papers that, uh, yeah, they have two prediction heads instead of one.
00:19:58.880 | Hmm.
00:20:00.880 | That's a, that's a good point.
00:20:01.880 | And, and, and I think we're entering the speculation area because like, like, likewise also like some of the previous papers I seen, it's two models as well.
00:20:09.880 | So yeah, maybe you're right.
00:20:11.880 | Maybe just, just using single model, uh, two heads or two, even like extra layers and head would have, have similar effect.
00:20:22.880 | And we have done that cost savings and, uh, training resource savings.
00:20:27.880 | Uh, as to why they never tried that, or maybe they tried it and it didn't work that way.
00:20:32.880 | We have to ask them.
00:20:33.880 | We have to ask them.
00:20:34.880 | Yeah.
00:20:35.880 | Yeah.
00:20:36.880 | Like, so that I think there's one, one thing that is in very, uh, repeated fashion for deep sea.
00:20:44.880 | Right.
00:20:45.880 | Well, uh, one thing that is always missing, right, is the abolition on how they did things.
00:20:52.880 | So if I would have a criticism, which to be fair, it's not fair to them because everyone else kind of like releases even less details than them.
00:21:01.880 | Uh, is that they'll be like, we did this.
00:21:04.880 | This is what worked.
00:21:05.880 | This is the path.
00:21:06.880 | Then, then when you, then when I have these questions, like, why didn't you try that?
00:21:10.880 | Then we don't know whether they did.
00:21:11.880 | There's a problem.
00:21:12.880 | Yeah.
00:21:14.880 | Probably the other thing with Oniki, when he said about the mathlib and lean, deep seek prover actually used it later on.
00:21:23.880 | So that's, that's what it says.
00:21:26.880 | Okay.
00:21:30.880 | Um, this, it wasn't meant to be a deep paper.
00:21:33.880 | So, uh, is there anything else that we want to cover?
00:21:36.880 | Yeah.
00:21:37.880 | Can I just check my, my understanding?
00:21:40.880 | Oh, whoops.
00:21:41.880 | Yeah, sure.
00:21:42.880 | Um, so even if you had a single model with multiple heads, you'd still have to do the computation and the training on it.
00:21:50.880 | Right.
00:21:51.880 | So it would save something there.
00:21:52.880 | Correct.
00:21:53.880 | V remedies.
00:21:54.880 | Yeah.
00:21:55.880 | It should also save, uh, compute.
00:21:59.880 | It would also save VRAM, but I think it should save some compute.
00:22:01.880 | Am I misunderstanding?
00:22:02.880 | I mean, usually when you have multi-task, the compute part is like two prediction heads that are different.
00:22:09.880 | So very, like compared to the big trunk of, of running it.
00:22:14.880 | Okay.
00:22:15.880 | It should be.
00:22:16.880 | The head is a small number of parameters relative to the size of the, but, but it seems my understanding is wrong.
00:22:22.880 | Cause they, they claim.
00:22:23.880 | So I would do it with a multi-task and I saw other older papers, non LLM set up where they use two prediction heads.
00:22:32.880 | So I was wondering why they haven't tried that here.
00:22:34.880 | Or if that's not the way to do it in LLMs or in RLHF.
00:22:39.880 | Okay.
00:22:40.880 | I'm willing to be willing to say it could very well just be the case that they never tried.
00:22:44.880 | So we have to ask them, like, I think this is generally, but conceptually, it will save VRAM as you're on.
00:22:53.880 | The data goes in.
00:22:54.880 | Yeah.
00:22:54.880 | It just goes through.
00:22:55.880 | They don't need to backward pass this.
00:22:56.880 | So yeah, it, it, it, it isn't that much more compute as well.
00:23:00.880 | Okay.
00:23:01.880 | It does seem, I'll just say amazing that we've got a whole model in one case.
00:23:07.880 | And then in GRPR, they're like, let's just do a Monte Carlo average.
00:23:11.880 | Uh, it just seems like, oh yeah.
00:23:15.880 | Why didn't, why didn't somebody else think of that?
00:23:18.880 | Um, but anyways, uh, we can, we can move on.
00:23:20.880 | Yeah.
00:23:21.880 | It seems they can run for the same prefix.
00:23:23.880 | They run more completions and then they get the average.
00:23:27.880 | My understanding is that in PPO, you just run one completion, for example, and then you score that completion.
00:23:34.880 | But if you run 128, uh, things at the same time, uh, maybe you, you get a like more signal.
00:23:42.880 | So, so there's some trade-off in like, uh, preusing the prefix and generating more things versus, uh, just using one prefix at a time and scoring it.
00:23:52.880 | Um, and I, I don't have a mental model what the trade-offs are between the two.
00:23:56.880 | That was going to be my, my question.
00:23:58.880 | Okay.
00:23:59.880 | Thank you.
00:24:00.880 | Yeah.
00:24:01.880 | But I think down here is just more of like, for each prefix, there's a multiplier effect.
00:24:04.880 | Well, in PPO, you have multiple individual prefix, but at the end of the PPO is still trained in batches.
00:24:13.880 | I mean, if not, I'll be too slow.
00:24:15.880 | So, so it's just, yeah, I think it's just about, uh, it still needs to go through.
00:24:21.880 | But here they have a batch of, uh, a few prefixes and then for each prefix, they generate, um, a few outputs.
00:24:33.880 | Uh, so it's, it's kind of like, I don't know.
00:24:36.880 | I used to work in recommender systems and we would have point wise learning where we would learn for, from one label, um, like one click or one not click.
00:24:46.880 | And then, uh, um, list wise learning where we look at the entire request and see which result was clicked and propagate based on a set of results.
00:24:56.880 | Uh, so it's kind of a same, like in group group RPO, you, you propagate signal from more, more things, some positive, some negative, and you also average them out.
00:25:08.880 | Um, but yeah, it's kind of interesting to think about, but I haven't figured out exactly why it's one is much better than the other.
00:25:17.880 | All right.
00:25:18.880 | Okay.
00:25:19.880 | This does give me a little bit to think about.
00:25:22.880 | Yeah.
00:25:23.880 | Cause I, I, I did never really considered it too much because for, I think for, for me as well, like for us, right.
00:25:32.880 | We always tend to lean in on if it's cheaper resources, all we care about actually.
00:25:37.880 | Yeah.
00:25:41.880 | So yeah.
00:25:42.880 | Okay.
00:25:43.880 | I'll move on to the next paper.
00:25:44.880 | Um, forgive for the buggy switches.
00:25:48.880 | Okay.
00:25:49.880 | Let's see.
00:25:50.880 | Yep.
00:25:51.880 | Yeah.
00:25:52.880 | Anyway, for those who's wondering, my laptop is like in an infinite log in loop.
00:25:56.880 | We've, we've, um, yeah.
00:25:59.880 | Eugene.
00:26:00.880 | Uh, I, I'm sure you are not aware of that, but, uh, the speaking attendees picture that keeps popping in front of us, uh, and hiding.
00:26:09.880 | Oh, I can get it.
00:26:10.880 | Get rid of it now.
00:26:11.880 | Yeah.
00:26:12.880 | Thanks.
00:26:13.880 | Okay.
00:26:14.880 | So I shared how you can block it, uh, with the options.
00:26:17.880 | Yeah.
00:26:18.880 | Oh yeah.
00:26:19.880 | Uh, it's just that I have no means to open that without, without sharing the screen.
00:26:23.880 | Yeah.
00:26:24.880 | Okay.
00:26:25.880 | Uh, even while you're sharing, you can go down to the options more and, uh, select the host option and, uh, hide the, uh, the profile pictures.
00:26:38.880 | But anyway.
00:26:39.880 | Yeah.
00:26:40.880 | Are you able to see the mama and the llama picture, uh, right now?
00:26:43.880 | Just making sure.
00:26:44.880 | Yes.
00:26:45.880 | Okay.
00:26:46.880 | All right.
00:26:47.880 | So, um, so deep, deep, deep R1, um, like I said, there are multiple teams trying to replicate the data set based on that map paper and then subsequently on the R1 model itself.
00:26:58.880 | Um, um, so that is like one road to reasoning data set with open AI.
00:27:04.880 | Um, I'm covering the, the other people I'm covering is mamba in the llama because, um, for those who don't know, uh, we did a similar process, uh, modified based from, uh, based on this paper.
00:27:16.880 | Um, the authors of this paper are very well aware about what we did because, uh, we collaborated notes, uh, for upcoming paper as well.
00:27:23.880 | Um, and, and essentially we made, this is not the name on the paper, the RwKV in the llama or in this case, the RwKV in the quen.
00:27:33.880 | Uh, so, uh, so using several of the concepts from this paper and we, we modified respectively, uh, how to modify an existing transformer model to a linear model.
00:27:44.880 | Um, we present, we, we launched our 32B model at, uh, at Europe and a little bit of a spoiler.
00:27:51.880 | We are launching our upcoming 72B hybrid version of using the, uh, altered version of the techniques that we did previously, uh, in the next few days.
00:28:01.880 | So that's why I'm going through this paper.
00:28:03.880 | Um, okay, so for most parts, there's a lot of things in here, right?
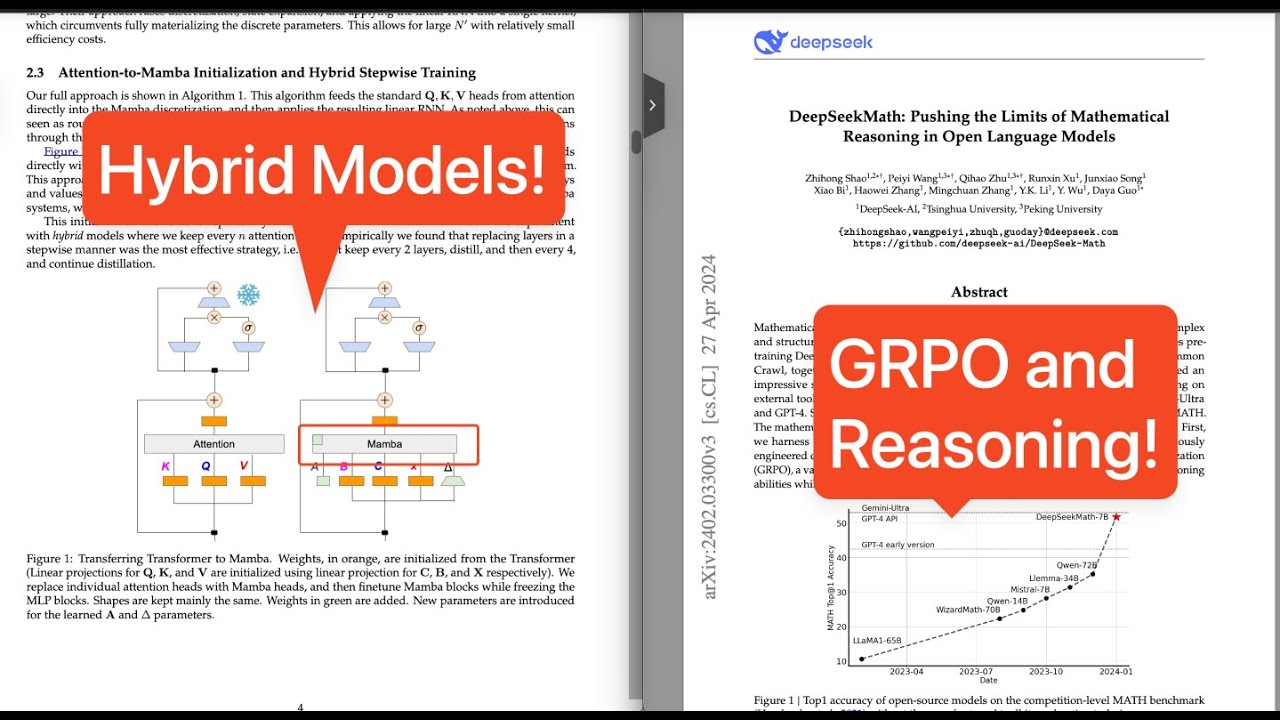
00:28:08.880 | Literally because this paper is talking about retraining a model.
00:28:11.880 | We are retaining most of its benefit at a really low budget, uh, and changing the attention mechanism, right?
00:28:18.880 | Um, you can actually replace, search and replace Mamba with RwKV in concept.
00:28:23.880 | You can search and replace it with XLSTM and Titan and et cetera, because conceptually the technique will work the same.
00:28:32.880 | So, uh, so the idea, the idea here is that, uh, the idea here is that you, uh, you take an existing, uh, transformer model.
00:28:40.880 | And essentially you freeze the feed forward network layer because, uh, where were you, where were you?
00:28:48.880 | This is explanation.
00:28:49.880 | What's the different RNNs and transformers, but okay.
00:28:53.880 | Here it is.
00:28:54.880 | Okay.
00:28:55.880 | Okay.
00:28:56.880 | So at the end of the day, right?
00:28:57.880 | Uh, all, all transform models are attention layers, feed forward network layers.
00:29:01.880 | Uh, then you have the embedding and then the, uh, the, uh, the output hits.
00:29:06.880 | And, and subsequently, right?
00:29:08.880 | Subsequently, right?
00:29:09.880 | Um, um, what you can do is take an existing pre-trained transformer.
00:29:13.880 | There's, let's say 15 trillion tokens trained.
00:29:15.880 | Freeze the feed forward network layer.
00:29:16.880 | So this is similar to what they did.
00:29:18.880 | Hence the ice there, the freeze logo.
00:29:21.880 | Uh, and then subsequently you delete the attention and you, you, you delete the attention layer
00:29:27.880 | and then subsequently you, you add in the, the Mamba layer and then you train it respectively.
00:29:33.880 | Um, and what we realized, um, based on base, uh, when we, when we did the same thing for
00:29:39.880 | RWKB is that this is actually incredibly cheap and fast by transformer, by AI training standards.
00:29:45.880 | To put into illustration, right?
00:29:48.880 | Our upcoming 72B model, right?
00:29:50.880 | Well, we started with two MI 300 nodes.
00:29:54.880 | Uh, we essentially made improvement to the VRAM technique stuff.
00:29:59.880 | Basically we optimize our training code to the point where we ran the whole training process.
00:30:04.880 | Again, we are trying to replicate the model on a single node.
00:30:09.880 | So we were able, so we were able to successfully convert, uh, a transformer model.
00:30:14.880 | Be a 32E and 72B to a linear model with, with some loss in MMLU.
00:30:22.880 | But given the amount of tokens that we trained was like, it was like, it was only a few hundred millions, right?
00:30:28.880 | There were, it was, there was no way for it to actually learn new knowledge given the very limited dataset.
00:30:36.880 | So one of the, one of the derivatives for this paper and, uh, and based on, uh, likewise in our replication was that.
00:30:44.880 | It's actually leaning into the conclusion right now that majority of your knowledge for the lack of better words, right?
00:30:51.880 | Is actually only in this peak forward network layer.
00:30:54.880 | And the attention layer is just more of like.
00:30:57.880 | Being able to pay focus on things.
00:30:59.880 | You know, uh, to quote one of our teammates, right?
00:31:03.880 | The way they, the, the way the frame is like, if the FFN is the knowledge, right?
00:31:07.880 | Then the attention layer is just, it's just basically the part of the brain that lets them, uh, pay focus.
00:31:13.880 | And when they reset the model, right?
00:31:15.880 | It's as if the person has ADHD and just can't focus.
00:31:18.880 | So, so us doing that limited training is basically fixing the nerves, uh, to, to essentially allow them to pay focus again.
00:31:26.880 | And, and that's why we, uh, that's why it's something similar to here below.
00:31:31.880 | I believe they did cover MML, uh, the scoring.
00:31:34.880 | No, so speculative decoding.
00:31:35.880 | I'm going to skip the speculative decoding part because that's, that's not the point of this paper.
00:31:39.880 | Uh, is that they subsequently showed that in, in, uh, as they convert it and then, um, with different ratios of.
00:31:49.880 | Linear layers to, to, uh, to transformer layers.
00:31:55.880 | It's able to actually retain quite a large percentage of the, uh, uh, transformer level performance.
00:32:02.880 | Um, so this is empty bench.
00:32:04.880 | Um, like for example, you look at the Lama empty bench.
00:32:06.880 | Um, the baseline is it.
00:32:08.880 | Uh, if, uh, and then subsequently as, as the supply as this pricing is, is, is around 7.7.
00:32:13.880 | Um, for, and likewise, we have seen similar things.
00:32:17.880 | Um, I think the better example is below.
00:32:19.880 | So for example, 50% 7.32, 6.7, 4, 6.48, 5.64.
00:32:25.880 | Um, 5.64 is basically pure Mamba.
00:32:28.880 | Uh, that is so, well, there is a slight performance degradation, right?
00:32:33.880 | There, uh, there is a question of like, why do we bother them?
00:32:36.880 | Because this makes the model slightly dumber.
00:32:39.880 | I think the key thing here, right.
00:32:41.880 | Is it's all about trade offs here.
00:32:43.880 | Um, one, um, one, right.
00:32:46.880 | Is that, well, it is slightly dumber.
00:32:48.880 | The computational cost is substantially cheaper.
00:32:52.880 | So, so for example, right.
00:32:55.880 | Even at, even, even at, uh, even at like 50%, right.
00:33:01.880 | Uh, at 50%, uh, mixed transformers to, to, uh, to, uh, basically state space.
00:33:08.880 | State space, rwq, whatever it is, right.
00:33:10.880 | We are looking at easily cutting the VRAM requirement by close to half.
00:33:15.880 | Because essentially the RNN models, especially over longer context length, right.
00:33:21.880 | Their VRAM requirements are essentially rounding error for, for the layers.
00:33:26.880 | Another thing that, which is not covered in this paper,
00:33:29.880 | which we actually managed to further dive deeper into, right.
00:33:34.880 | So what we realized is that in, in a train transformer layers,
00:33:38.880 | because we experimented by replacing different layers one at a time,
00:33:42.880 | and basically Frankenstein in various way, right.
00:33:45.880 | Long-term attention, right.
00:33:47.880 | Is actually mostly done by the upper layers.
00:33:50.880 | Well, the lower layers, um, don't actually impact much on long-term attention.
00:33:56.880 | So once we realized that, right.
00:33:58.880 | It means that the lower layers, right.
00:34:00.880 | You can safely do the conversion, right.
00:34:02.880 | We are still maintaining stronger, uh, strong, uh, um, stronger longer-term attention, uh, scores.
00:34:09.880 | And this is reflected, right, in this paper as well.
00:34:12.880 | Uh, likewise.
00:34:13.880 | When we go further down in, in here.
00:34:17.880 | So if you see, if you see respectively, right.
00:34:20.880 | Uh, this is the very classic needle in the haystack test, right.
00:34:24.880 | Um, uh, needle in the haystack test, right.
00:34:27.880 | Even, even with their, their, in one of their models, right.
00:34:32.880 | Even though it was converted with 50% train, right.
00:34:35.880 | Um, it was able to, for most parts, pass the test.
00:34:39.880 | I know there's like some issues here.
00:34:41.880 | Um, what we realized, right.
00:34:43.880 | And this, I don't think it was covered in the paper, right.
00:34:45.880 | It was that, was that what we realized during our replication, right.
00:34:48.880 | Is that these segments, right.
00:34:49.880 | Well, a lot of it looks bad, right.
00:34:51.880 | When you actually look at the exact needle in the haystack result, right.
00:34:54.880 | If the model was doing things like, for example, the test number was.
00:34:58.880 | Like 2001, the model was answering 2000.
00:35:04.880 | It was like getting like slightly off by one's off by one digit errors, uh, kind of thing.
00:35:09.880 | Um, which, which was promising because, uh, what, what, what it meant was that it means
00:35:14.880 | there was a little bit misalignment during the conversion process, which is to be expected
00:35:18.880 | because we literally Frankenstein these things together.
00:35:21.880 | So one of the things that we did in addition to, to all of this, right.
00:35:26.880 | Was that after we did the conversion, right.
00:35:28.880 | Is we did additional training to, for the lack of better words, we cue the layers together.
00:35:35.880 | And that actually improved the needle in the haystack performance respectively.
00:35:39.880 | Whether that will be replicated in Mamba, that one, um, we'll leave it to them after we share
00:35:45.880 | our details with them again.
00:35:46.880 | So, so, so there's a little bit of back and forth between, between both groups right now,
00:35:50.880 | actually when, when it comes to like these kind of details respectively.
00:35:54.880 | So, yep.
00:35:55.880 | Uh, and that's about it.
00:35:59.880 | Yep.
00:36:00.880 | So it's exciting because if we all, if everything we hear work as planned, um, this technique
00:36:09.880 | conceptually will apply to any transformer model.
00:36:14.880 | And even in the, even if let's say you want to retain most of the performance,
00:36:19.880 | you could literally just convert half.
00:36:23.880 | And we've no substantial loss.
00:36:26.880 | And then subsequently have that savings in compute.
00:36:29.880 | So it just means potentially just cheaper inference in the future for all models,
00:36:34.880 | including potentially the deep sink model, et cetera, et cetera.
00:36:37.880 | Yeah.
00:36:38.880 | Yeah.
00:36:39.880 | Yeah.
00:36:40.880 | Any questions on that?
00:36:41.880 | So yeah, you didn't mention it might be in the paper though.
00:36:48.880 | So why so few, uh, tokens for training?
00:36:52.880 | Like that wouldn't, it wouldn't help to improve the performance on MMLU or whatever.
00:37:00.880 | if you just trained for longer?
00:37:03.880 | Um, I'm certain because it's just, especially in the case of like the larger models.
00:37:10.880 | Uh, at least when we were explaining for the 2B, we just didn't have the budget.
00:37:14.880 | Oh, okay.
00:37:15.880 | Sorry.
00:37:16.880 | Okay.
00:37:17.880 | So you, you trained as many tokens as you could.
00:37:19.880 | Yeah.
00:37:20.880 | So, um, we did, we did, so we did train on additional tokens.
00:37:24.880 | It didn't get better.
00:37:27.880 | Very slightly.
00:37:28.880 | Uh, the, the, the long context range performance also got better.
00:37:33.880 | And then we drew a trajectory and I was like, okay, this is going to take forever, which is
00:37:38.880 | like, to be fair.
00:37:40.880 | Right.
00:37:41.880 | That is how it's supposed to be.
00:37:42.880 | So it's.
00:37:43.880 | Yeah.
00:37:44.880 | Yeah.
00:37:45.880 | So it's just a more of a shortcut for like, if you want to view it this way, right?
00:37:48.880 | This in a way it shortcuts.
00:37:51.880 | I'm doing very roughly.
00:37:54.880 | So if I say, you know, the, the training curve of 15 trillion tokens, this allows us to shortcut
00:37:59.880 | the first one quarter of the 15 trillion tokens to half depending on the percentage ratio.
00:38:05.880 | Okay.
00:38:06.880 | Yeah.
00:38:07.880 | Yeah.
00:38:08.880 | Yeah.
00:38:09.880 | So did you, I are, is, does your paper that you're about to release, does it have that training
00:38:19.880 | curve in it?
00:38:20.880 | I'd be super interested in that.
00:38:22.880 | Uh, so yeah, that paper hasn't been written yet.
00:38:25.880 | And that's why I'm reading this paper.
00:38:27.880 | So don't ask me, can I cover the paper?
00:38:29.880 | I was like, okay.
00:38:30.880 | Yeah.
00:38:31.880 | Can I just cover what I'm reading?
00:38:32.880 | Because I'm reading it anyway.
00:38:34.880 | Yeah.
00:38:35.880 | Did that make sense?
00:38:39.880 | Yeah.
00:38:40.880 | Yeah.
00:38:41.880 | Yeah.
00:38:42.880 | Awesome.
00:38:43.880 | Thank you.
00:38:44.880 | Yeah.
00:38:45.880 | Yeah.
00:38:46.880 | So how, Eugene, how does this work?
00:38:48.880 | You just replace, um, the attention layers with, with kind of linear layers and the linear
00:38:56.880 | layers are randomly initialized and you start from scratch and, uh, they learn pretty fast.
00:39:01.880 | Yeah.
00:39:02.880 | Yeah.
00:39:03.880 | The most important step is you need to freeze the feed forward network layer.
00:39:06.880 | At least for the first stage of training.
00:39:08.880 | Um, so, so I, I think what we extended on is that we, we, we changed the process into different
00:39:14.880 | stages.
00:39:15.880 | Um, and we found that to be more reliable.
00:39:18.880 | Um, and we are quite certain about this because we, we haven't read repeated this process at
00:39:23.880 | least a hundred times on, on the seven beat model at this point.
00:39:27.880 | So, so, so, so, so, so what we did is that we freeze the feed forward network layer similar
00:39:32.880 | to Mamba and the Lama.
00:39:34.880 | We train the attention layer, uh, attention layer.
00:39:36.880 | But the trick is that instead of training on the whole model input output, you just, you
00:39:42.880 | just, you just train on the output for the original attention layer.
00:39:46.880 | So it's like, it's essentially like you just do that.
00:39:49.880 | One layer you forward, take the output, take that instead of training on the logit.
00:39:57.880 | So, so your layers are previous attention activations.
00:40:00.880 | So you're, you're trying to match the full attention with the linear attention.
00:40:05.880 | Yeah.
00:40:06.880 | We're trying to match the hidden state output.
00:40:09.880 | Essentially.
00:40:10.880 | And it work.
00:40:12.880 | If anything, right.
00:40:13.880 | Between both teams, we were like, this works way too fast.
00:40:16.880 | And, and, and right now, right now, right.
00:40:19.880 | For us, right.
00:40:20.880 | The beauty for this technique, right.
00:40:22.880 | Is that because we don't need to invest a huge amount of money into the training, the
00:40:28.880 | FFN layer from scratch.
00:40:30.880 | This actually allows us to iterate on the attention layer experiments on the cheap.
00:40:36.880 | I'll just use air code cheap here because we're still, to be fair, we are still using an MI 300 server.
00:40:42.880 | So, so it's not exactly that cheap, but it allows us to iterate without doing the full 2 trillion token strain in a very rapid fashion.
00:40:52.880 | So, and, and yeah, we have modified the RWKV mechanism in our upcoming hybrid model because we found it to be better.
00:41:02.880 | Yeah.
00:41:03.880 | It just, it just allows a lot more experimentation.
00:41:05.880 | I think that's one thing that was exciting about, about this technique when it comes to experimenting with linear attention.
00:41:11.880 | And yeah, I do expect newer space, uh, attention mechanism as well.
00:41:18.880 | In, in terms of data distribution, do you have to train on some specific data or you're like, you're using some random sample or cause I, I, I guess the attention path, it might matter to match the attention patterns of the pre-trained, uh, data set.
00:41:35.880 | Yeah.
00:41:36.880 | Yeah.
00:41:37.880 | So that's the tricky thing because we, so both, I think both of us, we use DCRM, which right now is considered like quite a good data set.
00:41:46.880 | That's refined.
00:41:47.880 | fine.
00:41:48.880 | Um, but the issue for, for me was that at the end of the day, we have absolutely no idea.
00:41:53.880 | What, what's the exact data composition from Lama and Quen?
00:41:57.880 | So there could be better.
00:41:59.880 | They are sets.
00:42:00.880 | It's just, I don't know.
00:42:03.880 | It makes sense.
00:42:04.880 | Thanks.
00:42:05.880 | Yep.
00:42:06.880 | By the way, the view, the, I'm still on screen.
00:42:14.880 | Yeah.
00:42:15.880 | Yeah.
00:42:16.880 | I only put it open because I was trying to respond to you.
00:42:18.880 | Yeah.
00:42:19.880 | All right.
00:42:20.880 | Yeah.
00:42:21.880 | Is anyone else?
00:42:22.880 | Any more questions?
00:42:23.880 | I got 10 minutes.
00:42:24.880 | I guess.
00:42:25.880 | Yeah.
00:42:26.880 | Okay.
00:42:27.880 | So it looks like I will just keep in the bonus paper, which is, we'll not see too much time.
00:42:45.880 | Okay.
00:42:46.880 | The reason why, why I say this is an, uh, to me, this is a rather exciting paper in a sense
00:42:52.880 | that this is the first large scale text diffusion model, uh, at seven B in size, but it's also
00:43:00.880 | a very boring paper because it's just basically we scaled up image, the, the, the scaling expectation
00:43:08.880 | and it works.
00:43:09.880 | So, so yeah, um, for those who don't know about text diffusion models.
00:43:15.880 | Um, the general idea, right.
00:43:17.880 | Is similar to like image diffusion where, where you have your prompt and response.
00:43:22.880 | Um, sorry, uh, your image, right.
00:43:25.880 | But then, but then like it, token by token, fill in, fill it in, but it doesn't necessarily
00:43:31.880 | need to fill it in, in sequence.
00:43:34.880 | Uh, in fact, I think, I think the, I get hard, right.
00:43:38.880 | Has an example where, where they literally just showed.
00:43:41.880 | Um, I, I don't do that.
00:43:43.880 | I have it in here and I can't, I can't remember where, where the guitar is, but they showed,
00:43:47.880 | right.
00:43:48.880 | The text appear appearing at different, different times, not necessarily in linear order.
00:43:53.880 | I think the big, the big thing is that for, for this, right.
00:43:59.880 | Cause I'm, I'm, I'm, I'm just always trying to shout out alternatives.
00:44:02.880 | Be it to RWKB to maybe this text diffusion architecture will end up killing RWKB anyone else.
00:44:09.880 | Um, is that, is that it worked and, and, and then subsequently now they are experimenting more into like scaling into different directions.
00:44:16.880 | One thing that is interesting about this technique, right, is because since it goes in a rare repeated activity fashion, it did much better than all existing architecture, right.
00:44:28.880 | On the reversing test.
00:44:29.880 | So for those who don't know the reversing test is that I asked you to put in, put in a text and then I asked it to reverse the text.
00:44:36.880 | Uh, a lot of models tend to do it badly in part because reversing tokens is not an easy task as well, because it depends on your tokenizer, but the diffusion models, right.
00:44:49.880 | The diffusion model, according to this paper, because they never released the weights.
00:44:52.880 | So we can't verify.
00:44:53.880 | Didn't have any issues with it.
00:44:55.880 | And, and that was one of the things that they observed beyond that, uh, until they released the weights.
00:45:02.880 | Um, um, I am not, I don't really have much reasons to doubt what they put in the paper here because they were very transparent.
00:45:09.880 | Some things did bad.
00:45:10.880 | Some things did good.
00:45:11.880 | They did.
00:45:12.880 | Uh, and, and, and yeah, it's a foreign paper beyond that other than the fact that it works.
00:45:18.880 | So.
00:45:19.880 | Yeah.
00:45:20.880 | The reason why I'm excited over text diffusion and this is my extra thing is that which they didn't do in this paper.
00:45:28.880 | Was was the fact that let me go back to zoom and stop screen share.
00:45:34.880 | Is that?
00:45:35.880 | Is that my speculation on text diffusion, right?
00:45:38.880 | Is that?
00:45:39.880 | Is that if we do it right and we, we, we scale it correctly, right?
00:45:44.880 | Um, we, we can start testing multi-epop training.
00:45:48.880 | Um, why I think that's important is that if you remember the previous, all the, all existing transformers, linear models, whatever.
00:45:56.880 | We have the same weakness that when we train on the same data set multiple times, our models are first.
00:46:02.880 | The multi-epop problem.
00:46:04.880 | If you are familiar with image models and diffusion models, that group trains over the data set thousands of times and the law still goes down.
00:46:14.880 | And there's something about it that we don't understand that allows that class of models to do it.
00:46:22.880 | And for me, text diffusion models might be a way to unlock the understanding of how can we do multi-epop training?
00:46:30.880 | Because if anything, humans are fairly multi-epop trainable.
00:46:34.880 | Uh, if anything, we train by repetition sometimes as well.
00:46:37.880 | So, so this to me is a important research step in overall to figuring that out.
00:46:43.880 | Um, yeah.
00:46:45.880 | Sorry.
00:46:46.880 | Okay.
00:46:47.880 | The question to Eugene, when you do the multi-epop training, can you always say that it improves or it could suffer also?
00:46:59.880 | Is there a way to say that you're doing better versus not better?
00:47:03.880 | Yeah.
00:47:04.880 | It's loss benchmarks.
00:47:06.880 | Um, it tends to end up creating a weird overfitting problem for transformer or even linear models.
00:47:14.880 | In our internal test, which I think some people disagree with is that we found that for most transformer models, it tends to break after three or four epochs.
00:47:25.880 | For RWKV, it tends to break after like six, seven epochs.
00:47:30.880 | Not really a big win because it's like, um, it's like, yeah, it's still breaking.
00:47:37.880 | Unlike diffusion model, thousands of epochs.
00:47:40.880 | So that's to me, to me, the real goal is to really like go to that like much larger direction.
00:47:46.880 | It also will make it easier for, uh, if we can get this right, right?
00:47:50.880 | It'll make it substantially much easier for like fine tuning task related for domain specific or even like company specific stuff.
00:47:59.880 | Cause if you can retrain it a thousand times without any issue, right?
00:48:03.880 | When you're trying to refine the model, you can just add data, retrain on your company data again.
00:48:09.880 | And yeah, sure.
00:48:10.880 | It's not a problem.
00:48:11.880 | And that's exactly where I was coming from.
00:48:13.880 | Yeah.
00:48:14.880 | It's one of the things that for example, you train on your company data.
00:48:19.880 | And then I say your company policy half change or only few paragraphs.
00:48:25.880 | I mean, and then you, you train it again.
00:48:27.880 | And the model goes crazy.
00:48:28.880 | It's like, it's a very annoying experience for, for, for fine tuning.
00:48:33.880 | Yeah.
00:48:35.880 | Oh yeah.
00:48:41.880 | Okay.
00:48:45.880 | How are these diffusion models different from BERT?
00:48:47.880 | How are these text diffusion models different from BERT?
00:48:54.880 | I think the key thing for the text diffusion model is,
00:48:57.880 | one when the attention mechanic is applied, right?
00:49:02.880 | For the individual token.
00:49:03.880 | So, so you can like freeze the prompt.
00:49:05.880 | So it's like prompt then completion, right?
00:49:07.880 | So imagine it as like pixels in the diffusion model,
00:49:11.880 | like your traditional diffusion model, right?
00:49:13.880 | These pixels or these tokens, right?
00:49:16.880 | It's allowed to pay attention in all directions.
00:49:19.880 | So that's my speculation.
00:49:22.880 | It's just probably why it's able to do the reversal test very well,
00:49:25.880 | because it's able to like, through multiple steps.
00:49:28.880 | Hey, the text is that character.
00:49:30.880 | Then I can reverse it like pairwise in, in a sorting direction.
00:49:34.880 | Yeah.
00:49:35.880 | Uh, uh, uh, um, that part didn't really surprise me.
00:49:39.880 | And yeah.
00:49:40.880 | Um, so I think, I think that's the big benefit.
00:49:44.880 | Great benefit there.
00:49:45.880 | It's, um, other than that, it's essentially just like more towards transform on diffusion models
00:49:49.880 | with just a much wider attention range.
00:49:52.880 | If that makes sense.
00:49:54.880 | Yup.
00:49:55.880 | But as a set threshold for masking, uh, and text diffusion is an activity process, I think.
00:50:04.880 | Yup.
00:50:05.880 | I think that's one way, one way to frame it as well.
00:50:06.880 | Correct.
00:50:07.880 | Um, yeah.
00:50:09.880 | It's sorry.
00:50:12.880 | I want to be in self drive remote.
00:50:14.880 | Oh, because I put my phone by the side.
00:50:16.880 | Yeah.
00:50:17.880 | No, no.
00:50:19.880 | Okay.
00:50:20.880 | Sorry.
00:50:21.880 | Yeah.
00:50:22.880 | So I think like what to be clear about this diffusion model, right?
00:50:30.880 | Um, diffusion text models is not a very popular path in particular because you need to go through
00:50:35.880 | that multiple iterative steps.
00:50:37.880 | Like, so like if you want to generate, like, my 30, um, the whole, or completion, right?
00:50:45.880 | You need to like, like, like expert diffusion to a hundred steps.
00:50:49.880 | So that doesn't sound great.
00:50:51.880 | Um, but if I say your completion is, uh, is more than a hundred tokens, right?
00:50:55.880 | It might actually be more efficient than a transformer model.
00:50:58.880 | The issue at hand is like, sometimes when you're doing answers like chat GP star, you don't actually know the amount of tokens.
00:51:07.880 | Yeah.
00:51:08.880 | Okay.
00:51:13.880 | Yup.
00:51:17.880 | So yeah.
00:51:18.880 | Um, yeah, I think we are towards the end of the session, uh, for, for everyone else.
00:51:25.880 | Um, next week.
00:51:26.880 | Um, this week is a bit hectic because like a lot of the key members for the, this is a space discord.
00:51:32.880 | It's kind of like in New York, including me, uh, for, for the latest, uh, AI engineer summit.
00:51:39.880 | Um, if any of you here, shout out, uh, we'll be probably glad to meet you around here at New York.
00:51:45.880 | Um, beyond that, beyond that, uh, beyond that, um, for next week, if anyone has any papers they want to volunteer to, please, please draw a message into, into the channel.
00:51:54.880 | Um, I saw some people edit stuff into slido.
00:51:56.880 | Um, yeah, but you edit yourself as anonymous and saying, you might be able to, to probably cover the paper.
00:52:04.880 | Cover the paper.
00:52:05.880 | I have no idea who you are and just like, because you are anonymous.
00:52:08.880 | So yeah.
00:52:09.880 | If anyone wants to cover the papers that they edit this title, please do so as well.
00:52:13.880 | Uh, yeah.
00:52:15.880 | Same time next week.
00:52:17.880 | Have a good day as well.
00:52:19.880 | Thanks Eugene.
00:52:20.880 | All right.
00:52:20.880 | Thanks Eugene.
00:52:21.880 | All right.
00:52:22.880 | Thanks Eugene.
00:52:23.880 | Thank you.
00:52:24.880 | All right.
00:52:25.880 | Thanks Eugene.
00:52:25.880 | Thank you.
00:52:25.880 | Thank you.
00:52:26.880 | Thank you.
00:52:27.880 | Thank you.
00:52:27.880 | Thank you.
00:52:28.880 | Thank you.
00:52:28.880 | Thank you.
00:52:28.880 | Thank you.
00:52:29.880 | Thank you.
00:52:30.880 | Thank you.
00:52:30.880 | Thank you.
00:52:31.880 | Thank you.
00:52:32.880 | Thank you.
00:52:33.880 | Thank you.
00:52:34.880 | Thank you.
00:52:35.880 | Thank you.
00:52:36.880 | Thank you.
00:52:37.880 | Thank you.
00:52:38.880 | Thank you.
00:52:39.880 | Thank you.
00:52:40.880 | Thank you.
00:52:41.880 | Thank you.
00:52:42.880 | Thank you.
00:52:43.880 | Thank you.
00:52:44.880 | Thank you.
00:52:45.880 | Thank you.
00:52:46.880 | Thank you.
00:52:47.880 | Thank you.
00:52:48.880 | Thank you.
00:52:49.880 | Thank you.
00:52:50.880 | Thank you.
00:52:51.880 | Thank you.
00:52:52.880 | Thank you.
00:52:53.880 | Thank you.
00:52:54.880 | Thank you.
00:52:55.880 | Thank you.
00:52:56.880 | Thank you.
00:52:57.880 | Thank you.
00:52:58.880 | Thank you.
00:52:59.880 | Thank you.
00:53:00.880 | Thank you.
00:53:02.880 | Thank you.
00:53:03.880 | Thank you.
00:53:04.880 | Thank you.
00:53:05.880 | Thank you.
00:53:06.880 | Thank you.
00:53:07.880 | Thank you.
00:53:08.880 | Thank you.
00:53:09.880 | Thank you.
00:53:10.880 | Thank you.
00:53:11.880 | Thank you.
00:53:12.880 | Thank you.
00:53:13.880 | Thank you.
00:53:14.880 | Thank you.