RLVR DARLING: Reinforcing Diversity & Quality in LLM Generations (Paper Club Oct 15)
Chapters
0:0 Introduction to Sonnet 4.5 and Haiku 4.5 Performance1:47 Eugene Yan's Use of Haiku 3.5 and Tail-End Reliability
2:50 Introduction to Rob and the RLVR Paper
3:55 Basic Overview of Reinforcement Learning from Verified Rewards (RLVR)
4:21 Rich Sutton's Quote on Knowledge Verification
4:47 OpenAI's 01 Series and Gold Medal Performance in Programming Contests
6:14 Rich Sutton's "Bitter Lesson" and Hot Takes on LLMs
7:48 Defining the Verifier in RLVR
9:15 Reinforcement Learning vs. Pre-training: Dense vs. Sparse Rewards
9:54 RLHF: Reward Hacking and Human Preferences
11:34 Shto Douglas on RLHF being "Fake RL"
11:55 Elaboration on Reward Hackability in RLHF
16:20 The Problem of Syncopancy in Reward Modeling
17:35 DeepSeek R3/R1 and Group Relative Policy Optimization (GRPO)
19:24 The Diversity Problem in GRPO-trained Models (Pass@K Plot)
21:47 Discussion: Suppressing vs. Channeling Creativity
22:44 Detailed Explanation of the Pass@K Graph
25:45 Introduction to the DARLING Paper
26:0 Explaining DARLING's Approach to Diversity and Reward Upweighting
28:20 Context on GRPO Iterations and Budget Controls
30:28 GRPO vs. DARLING Workflow Comparison
31:13 DARLING vs. DrGRPO (Diversity in Reward Aggregation)
32:12 DARLING's Contributions: Open-sourcing, Reward Reweighting, and Results
32:55 DARLING's Improved Pass@K Results at Large K
34:25 Training the Math Equivalence Classifier for Diversity
36:22 Mechanics of Diversity Calculation and Partitioning in DARLING
38:40 The Multiplicative DARLING Score
39:29 Pros and Cons of the DARLING Paper
41:47 Coding GRPO Implementations from Scratch
44:26 Open-Ended Task Verification and the State-of-the-Art in Verifiers
45:6 The Rise of RL Environments Companies
47:32 Generalization of RL in Math and Coding to Other Domains
49:8 Parallel RL and Other RL Limitations
49:50 AlphaGo's "Move 37" and Novelty in RL
50:31 RL for Proofs and Material Sciences
51:43 Mid-Training Definition and Purpose
53:11 Mid-Training in Domain-Specific Models (e.g., Material Sciences)
54:28 Galactica and Bloomberg GPT: Tokenizers and Domain Adaptation
57:42 Mid-Training vs. Continued Pre-training
59:47 RL in Agentic Workflows
00:00:00.000 | Let's try Sonnet 4.5, I'm sorry, Ico 4.5, small model.
00:00:22.660 | How is it?
00:00:27.080 | Is it as good as this one?
00:00:28.700 | I think it's fast.
00:00:31.540 | It's a pretty big thing.
00:00:33.600 | Speed plays a lot.
00:00:36.880 | Recently, I've been trying Codex CLI a lot more, and frankly, it's very slow.
00:00:45.880 | Trying GPT-5 Pro, which has a noticeable performance difference, stuff is taking 20 minutes.
00:00:54.160 | And it's very async in CLI, but Cloud Code has a hybrid mode.
00:01:00.200 | So, you know, planning with Opus or Sonnet 4.5 and then doing a lot of coding with a fast model, I'm pretty excited for it.
00:01:09.500 | But, you know, performance-wise on numbers, it's pretty good.
00:01:13.060 | I find it like, where is this chart?
00:01:15.340 | I find it interesting that, you know, GPT-5 High still doesn't compare to Haiku 4.5 on Coding, which we've managed verified.
00:01:24.780 | Like, the Codex-specific model, sure, but like, yeah, Anthropic is doing good with coding.
00:01:30.900 | Yeah, that is a really nice result, actually.
00:01:33.480 | So, it seems good.
00:01:35.040 | It seems fast.
00:01:36.040 | Slick tweeted this somewhere.
00:01:39.600 | Basically, we did speed as AGA, but otherwise, I don't know, it's nice to have it out.
00:01:48.420 | Eugene Yan was asking about this the other day.
00:01:51.260 | He still has Haiku in production for speed and cost, and he's like, none of the open-source models fill the gap.
00:01:59.400 | They don't have tail-end reliability.
00:02:01.040 | So, he was looking forward to this.
00:02:03.880 | Interesting to see people still use Haiku 3.5, you know?
00:02:11.880 | But, okay, I think I can stop sharing, unless anyone else has fun stuff.
00:02:16.220 | I guess there's a system card.
00:02:17.480 | It's ASL2, model page, docs.
00:02:22.260 | Oh, system card is loading.
00:02:24.780 | Nothing crazy here.
00:02:27.140 | But, I'm sure someone will dig into this, see what other fun stuff they did.
00:02:32.880 | But, you know, not the paper for today.
00:02:35.500 | This week, we have three papers with a volunteer, so I'm going to pass it off.
00:02:40.200 | Swix is speaking right now.
00:02:43.160 | He is at a Cloudflare conference, so he's literally on stage at this minute.
00:02:47.880 | So, we're good to start whenever I've got the recording going.
00:02:52.040 | You want to do a quick intro?
00:02:54.000 | Yeah.
00:02:56.840 | Just want to make sure my mic is working.
00:02:59.120 | Yep, you're good.
00:03:00.680 | Cool.
00:03:01.100 | And your screen's here, too.
00:03:01.900 | Awesome.
00:03:03.280 | So, yeah, I'm Rob.
00:03:05.140 | I moved to San Francisco about a year ago.
00:03:09.180 | Started with a startup, it died.
00:03:10.560 | I used to work at Google as a machine learning engineer, and I've just been kind of deep diving some RL VR papers, and this is, oh, I wanted to present three, but I realized I didn't understand them super well, so I flimmed it down to just the one that I really got nailed down.
00:03:28.940 | So, I think it's a quite nice and elegant paper, and, yeah, I'm going to talk about that.
00:03:37.100 | And we have slides, and we have slides.
00:03:38.440 | Yeah, there we go.
00:03:39.720 | Very nice.
00:03:39.820 | Very nice.
00:03:40.260 | Cool.
00:03:42.940 | Yeah, so feel free to interrupt me whenever.
00:03:45.760 | I'm happy to, you know, go slow, chat, whatever, answer questions.
00:03:53.120 | So, first, I'm going to go through just, like, a basic high-level overview of reinforcement learning from verified rewards that probably, if you don't know it, not a lot of stuff is going to make sense.
00:04:04.800 | And then I'll dive into specifically the Darling paper from Meta.
00:04:11.060 | So, yeah, to type up RL VR for a sec, first, a quote from Rich Sutton, "An AI system can create and maintain knowledge only to the extent that it can verify the knowledge itself."
00:04:33.040 | So, this is an interesting take for Rich Sutton, who's not even really that much of a LLM guy, and I think he made this quote more than 20 years ago, but a bit, you know, saw some of the future.
00:04:43.900 | RL VR, it was the sort of key unlock that OpenAI, that, you know, enabled OpenAI to have their 01 series where the model would, instead of just instantly sort of
00:05:01.280 | RL VR, spitting out an answer, you know, token at a time.
00:05:03.920 | RL VR, it allowed kind of
00:05:06.440 | RL VR, this thinking process where it will generate a lot of internal tokens and then give a high quality answer.
00:05:13.940 | RL VR, it enabled recently gold matter performance in both this collegiate programming contest, ICBC,
00:05:23.680 | RL VR, other kind of math, high school math competitions, I think it did almost top performance, and this, an RL VR is like a key tool for training agentic tool use.
00:05:42.440 | So, yeah, is there, is there, I don't know if there's like a chat I can see, if anyone-
00:05:49.580 | RL VR, there's some chat, um, not much yet, someone was asking if you can share slides, but I think once we go into the media feed, you can share later.
00:05:58.340 | RL VR, yeah, so this, oh, should I just share the link to the slides, rather, like you don't see my slides itself?
00:06:03.140 | RL VR, no, no, we see them, we see them.
00:06:04.480 | RL VR, okay.
00:06:04.480 | RL VR, someone was just asking where you can download them later.
00:06:06.800 | RL VR, oh yeah, yeah, yeah, yeah, I just put it in, I'm sorry, I put it in the main, uh, latent space discord chat.
00:06:12.980 | RL VR, perfect, if you guys don't know who Ridge Sutton is, there's this paper, The Bitter Lesson, that everyone likes to cite, um, you should read it, recently he came back on the Dwarkesh podcast, and he's been having some hot takes, like, uh, you know, this, these LLMs are not going to do AGI, they don't actively learn, there's some interesting takes this one.
00:06:35.120 | RL VR, yeah, and actually if you've been looking at that code and think about it a sec, uh, right, it's saying the verifiers are important, but if, like, the deployed language models don't have verifiers, right, like we, we use them during training, um, but at inference time, the verifiers are gone, so, you know, Rich might, uh, object still to, uh, the current state of the art, um, because of this, right, they, they only use verifiers during training, and so, um, at inference, they still might be, uh, lying to you,
00:07:05.100 | or misleading themselves or misleading you, uh, it's an interesting take with how, how deep verifiers go, right, like, we've got very fuzzy verifiers too now, right, like, all the, all the hype is on rubrics, as better LLM as a judge, and, you know, you're abstracting away a strict definition of verifiers, or verification, right, like, you're, you're, I mean, a lot of labs are trying to, trying to do reasoning without verification, how can we strip away as much of the verification as we need, and then you've also got this,
00:07:35.080 | know like you're only as good as you can verify so interesting little divergence that we're taking
00:07:41.080 | yeah yeah um yeah so well what is the verifier um it's a function that you're given a prompt and a
00:07:52.200 | response um tells you um true like the the response was correct so it's it's very clean and binary um
00:08:04.840 | for sort of some math problems where you just want an exact answer you can force the model to say like
00:08:11.480 | oh here's here's my answer after it's done all this thinking um for code you can like if you're just
00:08:19.400 | wanting to implement a function or something you can run the unit tests for that function and see
00:08:23.160 | if they passes them all um you can do other clever things like i think openai um has a benchmark called
00:08:32.280 | webbench or something where they um got interesting information from like the web and then generated
00:08:39.880 | um like true false questions from that data um so they use the web as a way of generating
00:08:47.400 | um sort of complicated questions and then they just throw away some details and then
00:08:51.960 | um have like you know you're encouraged or you encourage the lm agent whatever use a web browser
00:08:58.120 | and try to figure it out and yeah there's just lots of different ways you can sort of fit interesting
00:09:04.600 | problems um into uh this verified rewards kind of domain um so this also should be kind of review for
00:09:16.840 | uh reinforcement learning versus pre-training um but when you're pre-training you know for any given
00:09:23.480 | prefix uh you have you know what's the next token so you have a lot of dense reward and it's not
00:09:29.560 | really like hackable you can't really cheat that too well um but since it's teacher forced the model
00:09:35.720 | like isn't um sort of recursively generating from its own output so it's really kind of stays on the rails
00:09:42.600 | but um and it's kind of efficient for just ingesting large amounts of information um but
00:09:51.320 | um unlike reinforcement learning um it's not learning from its own outputs or its own mistakes
00:09:57.000 | so um rlhf which you know was very big and important about three years ago to kind of unlock
00:10:05.160 | usable chat bots um trains a separate reward model that doesn't say yes or no or this is absolutely good
00:10:12.680 | or this is absolutely bad but you know tries to encode human preferences um so you still have a dense
00:10:20.440 | reward or you can sort of judge partial answers um but it's kind of easy to hack this reward um you can
00:10:30.520 | just look for kind of exploits in the reward model and you know i think in the original rhf paper they
00:10:38.360 | when they when they don't kind of keep the model close to the original uh pre-trained model it starts
00:10:43.880 | just like spamming words like you know amazing and beautiful and generous and doesn't even generate
00:10:48.840 | coherent sentences it just uh spans out these kind of nice adjectives and the the model likes it um
00:10:55.480 | reinforcement learning from verified rewards doesn't have this problem where uh you know you
00:11:01.640 | can kind of hack the model because you actually have to really generate you know a single or like a
00:11:08.280 | specific um token that says or you know whatever sequence of tokens let's say you really nailed the
00:11:15.400 | problem so you've got a clean reward signal um but now you only get feedback um once you've done your
00:11:24.920 | your entire generation right so the reward signal is quite sparse um um what's his name if you guys know
00:11:36.200 | sholto douglas he works at anthropic he's been he says he's scaling rl he's one of the guys that's heavily
00:11:44.120 | scaling reinforcement learning in every domain he's giving a talk this week and one of his quotes is uh
00:11:50.680 | rlhf is fake rl so he had like a little skit about how rlhf is fake rl uh someone in the chat is asking if
00:11:59.240 | if you can elaborate on reward hackability i think it's a i think it's pretty important to understand
00:12:04.920 | what that is in rl do you wanna do you wanna take it yeah yeah i mean you can also take a shot at this but
00:12:09.800 | um so when you're doing rlhf um basically you'll you'll train a sort of separate reward model so you'll
00:12:17.560 | say collect i don't know a thousand prompts or ten thousand prompts get um pairs of answers from your model
00:12:24.680 | um and then send those pairs to humans humans will say you know iris what you know for this prompt i
00:12:33.160 | liked the the one on the right better for this one i like the one on the left better so you get this uh
00:12:38.680 | this kind of training set of pairs of uh responses to a given prompt and then you won't learn a model
00:12:46.040 | that tries to encode like what would a human uh what would they prefer right and so you have um
00:12:56.040 | a kind of a model that can tell you given two responses which one is better um but you know you
00:13:03.400 | don't have tons and tons of data for this and that that reward model itself might um have like maybe
00:13:12.280 | misaligned preferences or bugs or make mistakes um and so as you train your model um your sort of main
00:13:21.320 | shot model to generate responses that the the reward model likes um increasingly as you as you train it
00:13:29.720 | more and more or as you let it go further and further from the base model um you stop getting the the real
00:13:37.320 | signal like you know response a is better than b um for real like uh humans would agree with that and
00:13:44.600 | you start picking up on just kind of um whatever is weird or errors in the in that reward model so you
00:13:53.080 | kind of uh this is called reward hacking um and this is like a big problem with um using models to to
00:14:04.200 | judge the reward um where yeah there was there was this concept of rlaif so you have like a another
00:14:11.880 | model judge the output of another one and um it's not always like reward hacking just really really like
00:14:20.360 | leads to you add random stuff and then reward goes up because the models disagree but sometimes it's
00:14:25.880 | like it's hard to model your high level preference the little changes right so some examples are like
00:14:32.840 | emojis right um some of the models got really over excited with emojis like basically anything you'd ask
00:14:40.040 | them it would respond with emojis fire emojis happy faces and you know it learned that through rl because that
00:14:47.000 | optimized the mathematical like rl reward policy that okay you know in some domains like emojis are good
00:14:54.920 | or m dashes like let's always add m dashes and then same thing with some stuff like cificancy right you
00:15:00.680 | want better outputs that seem like they agree with you but then you take it too far and now the model just
00:15:06.760 | agrees with you in every sense and it doesn't push back so like there's clearly like a trade-off balance and
00:15:12.040 | it's really hard to get that mixture right but those are like some of the nuanced real examples of reward
00:15:19.000 | hacking right like it's starting to realize like okay you like how i chat but i can get a little better
00:15:25.960 | reward by throwing some emojis in there and then that like there was the whole thing off balance so now
00:15:30.040 | you're asking it about like explain a math formula and you've got a bunch of emojis right so it can be
00:15:35.080 | subtle and it can also be like very very obvious like you know um you just start shitting out longer
00:15:42.520 | responses and you get more rewards because that's what the policy is like saying and you found out this
00:15:48.520 | trick right let me just add noise because long response is good or the opposite let me let me be really
00:15:53.960 | short because short response is good so those are some examples that are like easier to understand right where you could
00:15:59.720 | understand how in some cases that that's like giving a good reward signal because it's good for some
00:16:06.120 | senses but then it kind of throws the whole thing off and reward hacking is where the model like really
00:16:11.000 | fits in on okay this is like this is giving me a lot of reward let me let me start doing this a lot more
00:16:16.840 | but you might not want it yeah and another sort of interesting problem with um reward modeling is like this
00:16:23.400 | problem is syncophancy right where people tend to like responses that agree with them maybe even if
00:16:28.920 | they're not true so this can slip into your reward model and then also slip into your your chat bot right
00:16:35.480 | so if you sort of have vaguely equivalent prompts but one that you know leans on expecting the answer to
00:16:42.040 | go a certain way uh models sometimes pick up on that too much uh it's another like important problem with uh
00:16:50.520 | parley jeff and reward hacking last year in the end of april open ai actually no this year what am i
00:16:58.040 | talking about in april they had to roll back a version of gpt4o they put out a good blog post i just
00:17:03.560 | shared it basically they're like um yeah gpt4o we did a little change and it's loving to agree with people
00:17:10.920 | um not what we want we got to roll it back so that was like the first you know big lab like okay here's
00:17:17.640 | here's a president issue that we're gonna have to deal with yeah yeah and i'm sure it's like you know
00:17:22.360 | that this is one where they really screwed it up so badly that they had to roll back a model but i
00:17:25.800 | think it's something that you kind of always have to fight with uh when you're using these reward models
00:17:34.920 | um i'm gonna kind of move on i think that's um so about a year ago um deep seek released uh r3 and i
00:17:45.880 | think or it was r1 i forget the names of it but it was a very high quality open source model um and they
00:17:53.080 | also released uh also released uh a paper uh where they described this group relative policy optimization
00:18:00.120 | which has become um i think a bedrock of uh work in the research world and open source ai world um
00:18:08.440 | so uh what it did was basically replace that reward model um for with like simple verifiers right so this
00:18:19.240 | only works in domains where you have uh verifiers but um you've given a prompt you generate a bunch of
00:18:27.000 | responses um you score them with the verifiers and then you say uh you know the reward uh is just
00:18:37.800 | some uh like a sum of your scores from your verifiers and then you say every token um
00:18:45.160 | and the response that is good it's kind of sort of shares that reward um and every every token and
00:18:51.880 | responses that are bad uh gets penalized so it's it's a very kind of broad brush but it's a clean signal
00:18:59.560 | and this i think allowed them to get quite close to uh the quality of opening eyes thinking models
00:19:08.280 | at the time it was released um and uh became not just this basis for a lot of additional work uh because
00:19:16.840 | it you know it worked well uh
00:19:22.120 | and then uh one one interesting problem people found uh with uh these verified reward
00:19:31.080 | or grpo trained models right is though it helped uh improve the quality of the responses
00:19:39.400 | especially if you're going to get you know just a single response um
00:19:45.560 | it actually hurt uh the the diversity of the degenerations like it's kind of compressed uh the
00:19:54.680 | response space on what it could find is as the kind of the good answer uh or a good answer um but it
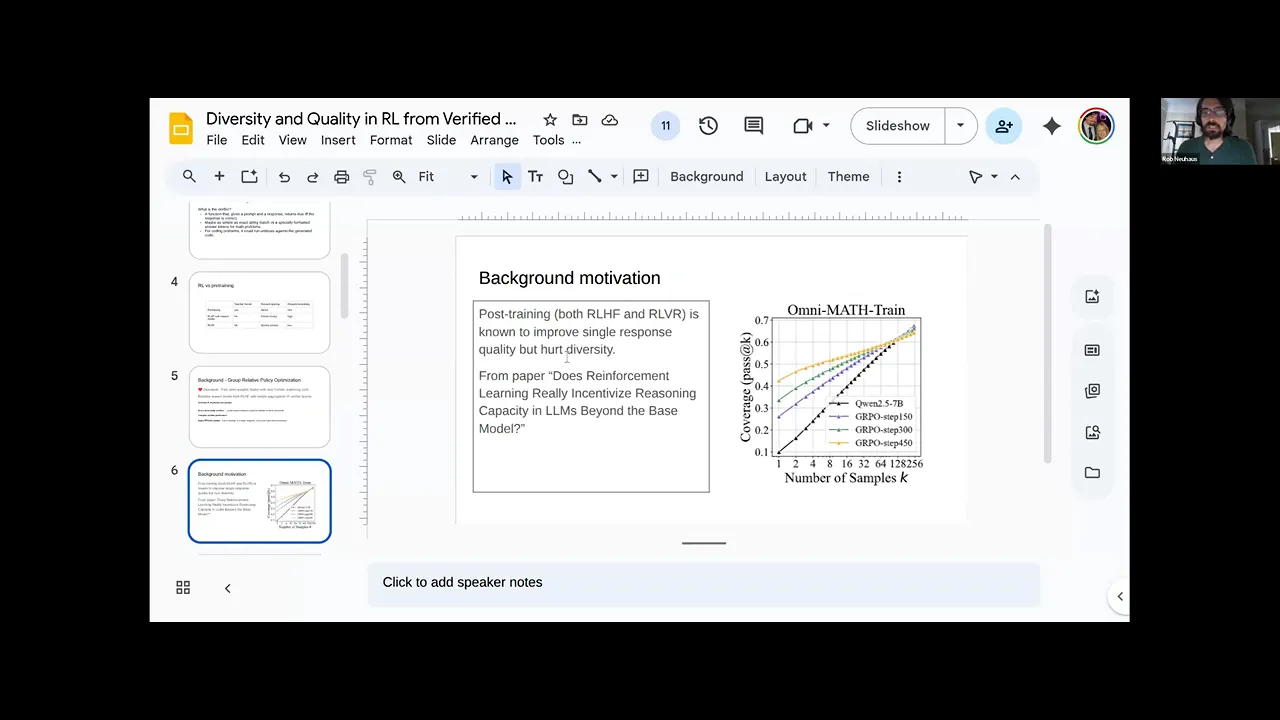
00:20:03.400 | maybe hacked away interesting and useful bits of the model so if we look at this uh this plot here it's
00:20:12.120 | from a different paper um you see uh the base model is this quin uh 2.57b model and then there's um that
00:20:24.760 | model trained with grpo through more and more steps um and on the x-axis is uh the number of samples you
00:20:34.200 | generate and then on the y-axis is uh so-called passet k so does does any you know if any of the
00:20:42.040 | those k let's say in this 256 uh like x-axis you're going to generate 20 256 responses do any of them
00:20:52.680 | pass the firefighter right and we could see that as the grpo training goes on and on right the passet one
00:21:03.960 | gets better and better um but as the the k increases here up to 200
00:21:11.960 | 256 by the time you get here the base model actually is maybe doing a little bit better than
00:21:19.320 | the untrained model right so um empirically maybe one way to say this is um you're kind of
00:21:28.840 | getting rid of or um suppressing some of the models uh kind of true intelligence in some way right like um
00:21:41.880 | it's yeah i don't know maybe i should slow down here or people can ask questions but
00:21:46.680 | i think this is a very kind of important idea to understand is it suppressing or is it channeling
00:21:53.800 | sorry say that again is it suppressing or is it channeling channeling yeah i mean i'm not sure
00:22:03.720 | what what would the difference be so let's say a base model is super creative uh and then rl hf sorry
00:22:11.800 | rlbr model is less creative but more capable yeah yeah yeah i think that's a fair characterization
00:22:27.320 | yeah yeah yeah i mean this terms get tricky but yeah yeah um
00:22:33.880 | yeah
00:22:37.880 | um could i explain this exactly okay yeah yeah so i'll sort of slow down and try to say this again
00:22:50.120 | um in a different way um or like we'll just try to slowly explain this graph um
00:22:56.920 | so what we're going to do is we have one prompt or we'll actually be able to say we'll have 10 prompts
00:23:02.760 | right and then for each of those prompts we're going to generate let's say um 256 answers right
00:23:12.440 | um if any of those responses
00:23:15.800 | are like past the verifier right then you get credit for um
00:23:25.800 | covering or passing at 256 so you can you can be right simply one out of 256 times
00:23:33.400 | for a given prompt um and that will give you a point there right so if you you know in
00:23:39.160 | seven out of those ten prompts you'll have you know seven times 256 answers uh for a given prompt
00:23:47.080 | you know just imagine oring right say false false false false false true false false false if that or
00:23:52.520 | right if there's any true you get credit per prompt right that's how you make this plot
00:23:59.320 | um and yeah empirically what people have found in rl vr is um right as you continue to train um
00:24:11.320 | you know when when k is small you have a big advantage you do much better
00:24:18.520 | than your your base model but as you generate just tons and tons of responses right
00:24:26.280 | um you're actually less likely to solve kind of maybe really hard problems or problems that require like
00:24:34.840 | um some maybe clever spark of inspiration or some kind of weird way of solving the problem right so
00:24:44.520 | um the the training process uh is kind of smoothing out or getting rid of these kind of rough edges that
00:24:54.040 | don't tend to work but at the cost uh of some diversity or creativity in the models
00:25:01.880 | there are similar findings for rlhf in terms of um like i think like diversity of uh responses right if you
00:25:15.800 | ask um
00:25:28.040 | um
00:25:29.960 | all right i think i'm gonna move on here i think i've got this explained basically as well as i can but
00:25:36.680 | um having other people take a shot at explaining this would be worthwhile if if it's not clear
00:25:44.920 | um so yeah this is the paper that uh you know really motivated this talk um jointly reinforcing
00:25:53.400 | diversity and quality in language model generations um came out of meta mostly out of meta i think one
00:26:00.520 | of the authors is at johns hopkins um and uh this is i'm just like a beautiful slide that explains
00:26:14.280 | um the process quite well um so okay this may be not a verified reward kind of problem right
00:26:21.080 | write a story about a programmer with superpowers um these um blue rollouts
00:26:28.680 | are considered identical and good and this green rollout is considered good right it's actually a story
00:26:38.680 | about superpowers um and it's different than the blue ones which are considered kind of the same
00:26:45.320 | and then this red one is just not doesn't pass the verifier right so we want to penalize
00:26:52.120 | the red one in both grpo and and in darling right so that that advantage is kind of negative off to the
00:26:58.520 | left um whereas both the blue and green ones have advantage that's positive you know kind of to the right
00:27:05.480 | um but what darling says is since this uh this green response is different than the blue responses and
00:27:13.560 | you know it doesn't have any other um similar responses we're going to upgrade it all right so
00:27:20.840 | uh the advantage uh the advantage the kind of reward the score that we assigned to the screen one is
00:27:26.040 | going we're going to we're going to say it's it's more important or better than the blue ones
00:27:30.760 | even though um you know they all pass the verifier um just because it's distinct
00:27:37.240 | grpo doesn't have any mechanism like this it only uses the verifier and your score is independent of
00:27:46.440 | um how different or any any kind of diversity measure from uh from the other responses
00:27:53.160 | oh can i make this slide bigger um oh i should have went into presentation mode i'm sorry
00:28:02.840 | uh i don't actually give many presentations
00:28:09.240 | some uh full screen is there next to a slideshow right right here if i just put this okay well it's
00:28:18.280 | huge um i will say just for people to have more background information the original grpo was like
00:28:26.040 | very vanilla right you output stuff you you pick whatever passes the bar and you average out multiple
00:28:34.360 | if they do but there have been a lot of iterations on grpo right uh some of them change the kale divergence
00:28:41.400 | penalty some of them like there's like three or four different papers we've done in paper club
00:28:46.040 | gimme k2 did a different instance the original um grpo came out before deep seek r1 deep seek put out
00:28:54.120 | deep seek math in february or so of 2024 that had a slightly different grpo policy but the base premise
00:29:03.320 | is always the same right you have you generate a bunch of outputs and you have rollouts per se and then
00:29:07.960 | you want some way to give preference towards something now it's known that like you lose
00:29:15.800 | diversity and responses so this is specifically tackling that but there are other um variations as well
00:29:24.280 | yeah yeah i mean i think there's been a ton of work on improving grpo and a nice thing about them doing
00:29:30.520 | so well and open sourcing it i think is you know that it spurred a bunch of research yeah so so like for
00:29:35.800 | example um this one is focusing on diversity right you cluster outputs and you add more weight to the
00:29:43.720 | unique cluster right the one that only has one sample that will promote diversity some of the other stuff
00:29:49.640 | they've done is uh they have budget controls for output length right so um you can give more reward
00:29:57.080 | at different lengths um stuff like that right and then you can yeah so so that's just like another
00:30:04.040 | example of stuff that you could prefer right you don't want simple questions to have really long
00:30:09.640 | rollouts um you'll you'll basically do a similar thing where if an answer is shorter you give it more
00:30:15.320 | reward or or if it's longer for certain domain so there's stuff like that yeah and then here's yeah
00:30:22.840 | just a restatement of that that slide um to emphasize the difference right we have their input
00:30:28.840 | prompts they go through the verifier in grpo we do reward our aggregation and then we use actually kind
00:30:34.840 | of the same algorithm that is used for rlhf to do the updating once we've got the rewards um for darling
00:30:41.800 | we take the inputs uh we generate our rollouts now we apply our diversity classifier um we rewrite our
00:30:50.840 | rewards for um answers that are both correct and different than other correct responses and then we
00:30:57.720 | do the ppo update so it's it's not really that much uh a change on gpr grpo it just really focuses on
00:31:05.640 | boosting um answers that are both correct and different than other correct answers
00:31:12.280 | what is this sorry to interrupt how is this different from um uh i read a paper called us a d
00:31:20.280 | grpo done right or i think it's abbreviated as a dr grpo um i think i i i don't know dr grpo that well
00:31:31.640 | but i think this like dr dr um does some calculation that changes like how much reward you get based on
00:31:41.960 | the length of the response or something like it's okay it changes the reward aggregation um but it
00:31:47.320 | doesn't do anything that like compares responses against each other for their their semantic content
00:31:54.440 | and then reward like ones that are different right so i think um dr grpo is like a smaller change
00:32:02.280 | to grpo than this doesn't doesn't require any other classifiers or anything like that yeah got it thanks
00:32:10.120 | okay um so yeah what does the paper do well they open source their code which you know i love
00:32:17.880 | um they show that you can use this learn classifier to do this reward we're waiting and um now i'll show
00:32:29.560 | you some results later but they um like promoting diversity actually um seems to get rid of this problem of
00:32:39.000 | uh uh for large k like lots of rollouts uh losing your like the this kind of base model intelligence or
00:32:50.200 | creativity um
00:32:55.000 | so i hope you guys can can see this and see the graphs but the general gist is the base model is
00:33:04.200 | green um here it's a similar um plot to the the one that i showed a few slides ago but this is actually
00:33:11.800 | from the paper um and yeah so the number of rollouts is on this x-axis your pass at k is on the y-axis
00:33:19.640 | and we see this kind of same trend for the green like the base model versus the orange models is grpo
00:33:26.440 | versus where um as k increases kind of the base model tends to catch up to or i guess in some cases even
00:33:34.200 | pass um the grpo trains model um but um darling the this idea that um rewards diversity tends to keep this
00:33:48.840 | this edge over grpo and over the base model even at large k uh so we can you know at least in this math
00:34:00.760 | domain uh maybe see that it's really attacking this this problem and giving benefits even most of the
00:34:10.200 | time at for pass at one right which is maybe what you care about the most right because this is what
00:34:17.240 | you'll tend to ship to users right you only generate one response um
00:34:21.400 | okay um
00:34:29.560 | here's a question of like how do they train um this math equivalence classifier right so um the problem
00:34:40.600 | it solves is given given two rollouts um tries to maybe vaguely quickly determine you know are they
00:34:48.120 | saying essentially the same thing right not not not string match but um you know are they solving
00:34:54.120 | the problem in the same way um so the way they did this was they tried to get um a bunch of uh
00:35:02.840 | like a diverse solution set for different problems by generating uh rollouts from i think there's like
00:35:10.120 | five or six different models they're mostly it's from the coin family some from llama
00:35:15.320 | and then um given pairs of these responses they ask uh llama 70b to be like this oracle that generates the
00:35:26.200 | right answer and then um they take these pairs of responses with the uh the answer
00:35:37.400 | with with the answer from llama and they train a classifier on top of a coin embedding model to be
00:35:44.680 | able to um mimic llama mimic what this big llama model does um and they got pretty good accuracy i
00:35:53.480 | guess eight nine percent on holdout set um here's the prompts that they uh use to generate the training
00:36:06.120 | data for this equivalence classifier uh which i don't know seems pretty well thought out and
00:36:12.200 | uh well reasoned but it's not not actually that long um
00:36:17.880 | so right so how does the mechanics of this work right when you're doing your rollouts i think in
00:36:29.160 | the paper or in the code they said only eight um rollouts um they'll actually call this uh this
00:36:39.080 | embedding based classifier on every pair of inputs um and then if any pair uh before any pair the the
00:36:50.520 | classifier says yes um those those answers get merged um and then after you do this basically
00:37:01.240 | you'll have a partitioning of those responses right so um if a matches with b and b matches with c
00:37:09.400 | even if a doesn't match with c you still include uh consider a and c equivalent um and then you form this
00:37:16.200 | diversity score that's just like a simple function of the size of the partition um which just says like
00:37:24.600 | how many uh other correct responses are you um distinct from right so if if your cluster is big you kind of
00:37:37.400 | lose some credit uh because um you know the model tended to like to generate that style of answering um
00:37:46.920 | whereas if you got the answer correct and you are distinct from all of the other responses um you'll get
00:37:55.320 | uh substantially higher reward so maybe in some sense it's trying to um reward or uh upweight these kind of
00:38:06.520 | more creative or weird or subtle kind of reasoning paths uh to keep that diversity in the model
00:38:15.400 | uh yeah note that this is like super super simple right we do these n squared classifications um and
00:38:23.800 | then we just binarize the score from the classifier and then form clusters right so we kind of do quite a
00:38:29.400 | a bit of work and then just get very kind of simple outputs to um change the reward using that um yeah
00:38:40.520 | and then this is the actual uh math basically this darling score is a re-weighting of these space um
00:38:51.640 | you know reward scores from the verifiers um with some normalization um they tried some other ways of
00:39:01.080 | incorporating the diversity score using addition rather than multiplication uh they found that this
00:39:05.880 | uh multiplicative score um works the best and then yeah as that previous slide showed right um once you're
00:39:14.360 | done with this now you've got your reward scores calculated and it's it's identical to uh grpo from
00:39:22.280 | here um okay so what did i like about the paper right so it's it's a well-motivated problem i think
00:39:33.880 | this approach is is pretty simple right it's maybe not as simple as like dr gpr grpo which just as far as
00:39:39.400 | i understand like changes some like length normalization right you have to introduce this new
00:39:43.240 | classifier um but i think fundamentally you're going to attack diversity you need to be able to
00:39:47.880 | you know compare responses and the semantic quality content of responses against each other so it's sort
00:39:54.520 | of some necessary complexity um has you know good results and um they open source the code
00:40:05.000 | um what don't i like so i actually tried to run the code um and then you quickly uh hit this problem
00:40:12.120 | where they don't actually include this semantic classifier for you so you can't just out of the box
00:40:17.960 | run it um maybe this diversity calculations overly simple right um you could imagine maybe you've got
00:40:28.040 | four responses and a is equivalent to b is equivalent to c and then just you know d is equivalent to b
00:40:35.400 | but not to a and c right so you've got this little cluster or this big cluster and then just one little
00:40:41.240 | spike spoke coming out connecting them now we the calculation will say d is exactly equivalent to a b and
00:40:49.240 | c even though even like this graph structure kind of makes you think probably d is a little bit different
00:40:55.560 | than a b and c so maybe you should actually give d more credit than a b and c the paper only talks about
00:41:05.160 | using you know one particular diversity classifier for the math problems they didn't say you know see
00:41:11.640 | what happens if they were to train that classifier for longer on more data or use like a simpler model
00:41:18.680 | and they also don't actually say how much time is going into doing this diversity classification
00:41:25.640 | right um could be the case that if you were to spend that time uh you know just generating more rollouts
00:41:32.760 | uh you know maybe you would have done better right um but yeah all in all i was pretty happy with uh
00:41:40.600 | how this paper was written you know the idea how to attack the problem
00:41:44.360 | uh i will say it's pretty fun exercise there's like seven or eight different like easy to implement
00:41:54.680 | your po papers that don't share the code and really open source it but like the models are really good
00:42:02.360 | at converting this stuff to code so like it's one thing to take a paper that doesn't have an open
00:42:09.240 | source implementation and like caught it up from scratch but grpo is one of those things that's
00:42:14.200 | actually very easy because they spend a very long section of this paper of like all the papers
00:42:19.320 | explaining the changes to math right like okay we're getting rid of this like normalization
00:42:26.040 | distribution we're doing these little changes and then you know you go into cloud code or whatever
00:42:31.080 | you want to use and you you get a base grpo implementation you share the changes and then
00:42:36.520 | you just have it kind of implement it right tests and like they're pretty good at this because you not
00:42:41.400 | only have math formulas you also have like two pages of here's why and what's changing and how it changes and
00:42:48.120 | it's a little hard math at least for me to follow like and implement myself in code it would take a lot
00:42:53.800 | longer but like and while they're pretty good at this stuff so uh if any of you guys are going through
00:42:58.760 | like the nano gpt nano chats or whatever and you want to like do some rl training from scratch
00:43:04.440 | implementing grpo with like a coding co-pilot and iterations of it really helps you understand what's
00:43:11.000 | going on and it's a lot easier than it seems
00:43:13.000 | but like you know quite irrelevant to the paper sorry no no no it's cool i mean i yeah i kind of want
00:43:24.680 | to get my hands dirty like you know hacking on this stuff um so yeah maybe i should kind of pull out some
00:43:30.840 | other papers and uh you know not get stunted by oh you know this big missing piece of them uh the
00:43:37.480 | paper is it's not there uh yeah this is the end of my talk happy to answer more questions
00:43:45.240 | very nice slides by the way yeah thanks and thank you for offering to present yeah i mean i i initially
00:43:59.560 | wanted to present three and then uh realized that was a lot of work and i didn't like really understand
00:44:05.320 | the details of the other two papers super well so i pumped it and only did the one that you know i
00:44:09.880 | feel like i really wrapped my head around so um okay any other questions comments from anyone
00:44:26.120 | i have a question about like the open-ended nature of task verification for let's say llms
00:44:33.800 | and the fact that that's what's led to not having good verifiers like uh what's the state of the art in
00:44:39.080 | terms of like developing closed tasks of some kind and benchmarking them and using them as like a harder
00:44:44.920 | type of type of verifier yeah i don't know this stuff super well um yeah i know karpathy has this
00:44:56.040 | tweet like three months ago that says like you know everyone should try to be coding up verifiers for
00:44:59.960 | their problems and this would you know really help the models if you guys have seen the current meme trend
00:45:07.720 | of everyone starting an oral environments company that's kind of what this is right uh everyone's
00:45:13.480 | starting up companies to sell to the labs and make environments uh i'll give you a bit of the background
00:45:19.720 | of what it's really like the labs want exclusivity right they want their environment like your unique
00:45:26.200 | environment to be just for them so uh you know you can be the mercore that's like you're the player and
00:45:33.000 | you can do stuff for everyone or if you're a small startup you're basically a little consulting arm
00:45:37.880 | creating little interactive environments for one lab and then it's like a whole thing to manage to do
00:45:44.040 | multiple unique ones and then they don't want you to work with other ones but on the other side um a lot
00:45:51.160 | of the pilots and where they start is actually you're making environments for evals so say you're
00:45:59.080 | working with not a lab doing rl you're you're working or you are you're working with like a company that
00:46:05.240 | wants to do rl or test their agent or whatever what you're really doing is you're making like a sandbox
00:46:11.320 | environment that should test whatever they want to test in like a unique setting and then they're really
00:46:17.000 | just using it for evals even though the conversations like oh i want to do rl this that it kind of always
00:46:23.560 | starts with um i want evals for my thing and we'll help you create unique evals right like it's a eval as
00:46:31.320 | a service game so instead of you can run on sweet bench how about even instead of like running on real
00:46:38.920 | github how about we make you a sandbox of like random coming in through a slack like chatbot and this
00:46:45.160 | all end to end and you can see where your agent fails but um i low-key forgot the question you
00:46:51.960 | were asking where i started this yeah what's the state of the art of like yeah exactly yeah yeah yeah
00:46:57.640 | so uh a lot of the companies that are trying to try to make environments and stuff um you know they're
00:47:03.720 | going at it from that angle or or they're all trying to just sell to a lab which is cool too um outside of
00:47:11.000 | that like you know no one not many people outside of labs are doing the real rl yet so it's interesting
00:47:17.000 | that it covers both domains right um but that's kind of where it is and then it's very very saturated like
00:47:23.320 | you want rl environments we'll send you a list of 20 that'll build you a sandbox that tries to mimic
00:47:29.000 | your thing but there's no value in evals for it right it's stuff that your thing has probably never seen
00:47:33.320 | yeah it seems like one approach would have just been like hopefully rl just scaled all the way to some
00:47:38.200 | sort of all-encompassing god model but you know short of that uh we'll take rl for task specific uh
00:47:44.040 | and just just um max out each task domain basically i think rl is very general right it scales out
00:47:51.960 | as a god model that's what all the thinking models are right like uh o1 o3 gpt5 thought thinking those
00:48:01.160 | are very good general purpose reasoning models they're not per se trained to just one thing now on the other
00:48:07.640 | and if you look at scaling laws and um generalization of this stuff it just so happens that when you do
00:48:15.640 | this type of rl on math and coding it actually generalizes like uh look at a chess benchmark we're
00:48:22.840 | not doing rl on chess but you rl on math and code your test gets really good um it's it's just that
00:48:29.080 | general roll out a chain of thought step by step and it's not to say that there aren't issues right like
00:48:34.520 | right now we can't do um we can't do a lot of um parallel rl because you have to stay on policy right
00:48:44.280 | so the pre-training side is very parallelized um but rl push training per se we don't know how to do it
00:48:53.720 | that well in parallel across a budget you know like i can't just optimize parallel rl then there's other stuff
00:48:59.960 | like diffusion i can't diffuse rl i can't do um native voice spectrogram or also there's stuff there
00:49:07.240 | and i guess maybe my chess example isn't good yikes but the the the topic still uh you know the premise
00:49:14.520 | still holds like there's there is generalization in rl uh alpha zero was a specific model on
00:49:20.760 | chess but you can you can rl on just math and you can see that it generalizes to other domains there's like
00:49:27.560 | quite a few papers on this there's a lot of small models where they like they show rl just on the
00:49:33.560 | data set make sure like i think even the mixture models uh the phi models they explain what their
00:49:39.080 | data set is and there's definitely a few that are just all math and code and then you run the benchmark
00:49:44.600 | on regular gsm ak and you know stuff like that and it still goes up so it does generalize it's also just
00:49:50.600 | that that's the most verifiable data right now yeah that's fair and i think uh what i was thinking
00:49:56.120 | about was like the alpha go uh debut and like that you know that that novel move that happened as a
00:50:01.160 | result of just rl maxing all the way till it invented a new move that's we haven't seen that level of rl
00:50:06.840 | maxing on like the other areas right so yeah move 37 you should look into 37 pretty pretty fun stuff
00:50:18.920 | like it'd be interesting what is the move 37 of like triage my inbox or something you know we'll see
00:50:31.560 | uh some people are using it for proofs christian sagetti is doing a new math inc company trying to
00:50:39.240 | solve math um the i guess the move 37 for interesting stuff is like periodic labs from liam they're doing
00:50:48.840 | it for rl for material sciences um you know predict new materials silicon and stuff all on mid-trained rl
00:50:57.240 | models and hopefully you find something cool harmonic i don't know what that is but there's there's people
00:51:04.200 | doing in different domains it's just it's just different problems i think it reflects back on
00:51:11.160 | the hardware soft verifiers and like the our bio that we did last week is sort of related as well
00:51:16.120 | uh this idea of like what's hard verifier ever soft and yeah
00:51:19.880 | cool more comments questions thoughts
00:51:37.240 | okay if not we can always give people some time back on their wednesday um next week
00:51:43.640 | uh of what exactly is mid training does anybody have a good succinct uh description of that
00:51:50.840 | yikes you do yikes knows what mid training is i was gonna yeah i don't have a good um succinct one uh
00:52:01.080 | normally i would assume it's it's the essentially the rl process right where it's if post training is
00:52:07.560 | going to be the chat or instruction tune and then pre-training is going to be the foundation
00:52:11.240 | then mid training i guess should come before the instruction or chat tune so i am wrong yeah yeah my
00:52:20.200 | understanding of mid training is like you're selecting really high quality documents for pre-training so you know
00:52:26.680 | you know you'll first pre-training on like just everything and then you'll select i don't know
00:52:31.320 | the top one percent or ten percent or something of like really good documents and and finish your
00:52:36.600 | pre-training there oh and then yeah yeah so there's a yeah just interesting problems of like figuring out
00:52:43.480 | you know what's what's the real good data um and yeah that and um it's in so we have we have pre-training
00:52:52.200 | we have initial pre-training then we have mid training with a refined data set then we have
00:52:55.800 | chat or instruction tune with a different data set and then we have rl on top of that which is building
00:53:01.080 | the chain of thought to be more rewardy um one wonders like how many other junctures there are could be
00:53:07.720 | different stuff uh presumably i can extend the principle in some way or another yeah typically it's a
00:53:15.640 | mid training stage isn't like it's very odd to just say mid training for general use right because
00:53:21.960 | yeah after you do your trillions of tokens of pre-training you do save the best for last but when
00:53:28.760 | you think of it like in a specific domain right like say periodic or are all for material sciences um
00:53:36.120 | they'll take a base model like trained from scratch and preferably not sft then they themselves like
00:53:44.120 | they'll license a bunch of data in different domains like material sciences books articles patents like
00:53:51.320 | as many domain specific tokens as they can do mid training where you take like a base quen model
00:53:59.000 | you domain adapt it towards your your domain of material sciences and you have how many ever high
00:54:05.720 | quality tokens then they'll do a sft rl whatever um so that's that's kind of the mid training phase
00:54:14.360 | uh in general purpose models it's more so like okay you know here's here's basic tool use here's code
00:54:21.480 | here's whatever use cases we find interesting let's let's start training in on those then do our 15 rl as well
00:54:28.200 | um i because i remember the thing that's coming to mind is the um like the galactica model and then
00:54:34.200 | maybe like slightly bloomberg gbt where they have the general idea was like okay we need a new foundation
00:54:40.920 | model because we want to do domain specific stuff and the issue that they were running into was that
00:54:45.800 | the domain specific jargon uh like needed its own tokenizer effectively um so i'm curious
00:54:55.640 | as to because galactic is kind of old news at this point so i'm curious if we got to hey what we
00:55:01.640 | should actually do is not really worry about the tokenizer stuff and we should just take like a pretty
00:55:05.960 | you know a capable generalized model then train it so that it's more more capable in this domain and
00:55:13.800 | i yeah i'm curious i won't like uh uh galactica plus plus bench i guess to see if uh galactic and fire the
00:55:22.520 | one of the ones on the line yeah that's that's basically a good example actually the the bloomberg
00:55:29.800 | gpt that it's not necessarily mid training because that thing was so under trained but um you know
00:55:36.920 | towards towards the end of it they they did train on a bunch of unique bloomberg data set stuff i think we
00:55:45.080 | actually did a paper club i covered it on bloomberg gpt so it should be recorded that paper was basically
00:55:51.640 | all just data set uh but but then they're like you know we have hundreds of billions of tokens of
00:55:57.000 | financial data sets news filings press bloomberg stuff and the order in which they do it is pretty
00:56:02.840 | interesting i think you get a lot more conceptual understanding of mid training by reading small
00:56:09.080 | language model papers um so we've gone through a lot of those because they're a big component is
00:56:15.720 | basically their training mixture and the um order in which they do training so just find any of the
00:56:23.640 | new small small models and then look at look at their training stuff so was was bloomberg gpt effectively
00:56:30.200 | like mid-trained with the bloomberg stuff because i feel like they said that they had a new foundation
00:56:35.800 | model right or so there are they yeah mid training it and then calling it a new foundation model or is
00:56:40.120 | they actually like okay we handpicked all these tokens and now we're just rolling it from scratch i don't
00:56:44.520 | know i think the problem with considering bloomberg gpt mid training is that half the data set was
00:56:50.920 | financial like i can pull it up but i quite strongly remember that half that data set for pre-training
00:57:00.040 | as well like it was a very clear split half of it was like pile c4 books or something the other half was
00:57:07.720 | 40 financial news so you know it was just a pre-train with a lot of financial yeah yeah and i think
00:57:16.440 | galactica is the same way where it's like uh yeah we mess with the tokenizer we you know uh decided to do
00:57:23.240 | the data set this way and then train the whole thing so i'm yeah i'm interested that's an interesting like
00:57:29.560 | there's a lot of decisions that you could make there that uh didn't really occur to me as like
00:57:33.240 | decisions that you could really make architecturally or like ones that people don't often take i'm
00:57:37.800 | curious if it's just like not effective or if it's um mid training is kind of the better way to do that
00:57:42.680 | regarding the nomenclature mid training seems pretty similar to continued pre-training like
00:57:51.080 | what's the difference yeah there's uh i'll quote jeremy howard on the latent space podcast there's
00:57:59.480 | no concept of post training it's all just training right like yeah at the at some level like post
00:58:06.040 | training is still training rl is still training it's all it's all just training it's just that the the
00:58:11.320 | bound that we define is like quality of data right you typically consider uh like chat um instruction
00:58:20.760 | following a separate category because the data is per se instruction following right and it's like
00:58:28.200 | chat user assistant pairs but you're not doing anything different you're just training you're still doing
00:58:34.360 | typically sft right so the words go in the magic sand and that's what it is um in some actually like
00:58:42.280 | in a pure literal sense it is still training there's pre-training post training is the same
00:58:48.040 | the the useful bounds difference is that you know the majority of your 15 trillion tokens will be
00:58:54.360 | just random token understand the world english the reason we call it post training is not because
00:59:01.080 | you're doing any fancy training it's just because that's where you're starting to do instruction
00:59:05.640 | following and you know user assistant chat so there's a there's a bound in terms of what the
00:59:12.840 | you know what we're trying to accomplish but in the literal sense it's all just training right it's
00:59:19.560 | we're not changing the training objective we're just predicting tokens right so yeah the way i look
00:59:26.280 | at it is pre-training is mostly unsupervised right like including continued pre-training or mid-training
00:59:31.880 | the data might be changing for domain adaptation but post-training you're adding in some supervised
00:59:39.080 | element or reinforcement element um not completely unsupervised uh yeah yeah there are ways to look at it
00:59:53.480 | yeah and i'm curious like do you see any uh companies or you know um use cases where uh
00:59:59.560 | rl is seeping into agentic workflows uh uh you know i almost see it as one way to squeeze
01:00:08.440 | you know most of the foundation models um yeah i'm curious if you have any interesting use cases that you came across
01:00:19.960 | yeah a lot of the labs have done cool rl for specific stuff right like deep research is rl
01:00:26.440 | on opening eyes model there's coding ones that have come out uh we've shared quite a few in discord but
01:00:32.760 | there are cool use cases of um people doing rl for a task and and that turning straight into product
01:00:41.400 | um yeah yeah yeah okay guys thanks again rob for sharing we're kind of at that time next week we have
01:00:51.080 | uh real-time detection of hallucinations you can find it in discord i shared it in the link here but
01:00:56.600 | thank you thank you for sharing really good slides good presentation