Stanford CS25: V2 I Language and Human Alignment
00:00:00.000 | It's my pleasure to welcome Jan from OpenAI.
00:00:08.600 | He leads the alignment team there and was previously a researcher at DeepMind as well.
00:00:12.920 | He holds a PhD in reinforcement learning theory, has been thinking about the alignment problem
00:00:17.840 | for over 10 years, and today he'll be giving a very interesting talk.
00:00:21.400 | So hope you guys enjoy.
00:00:22.920 | Yeah, thanks a lot for the intro, and thanks a lot for having me.
00:00:27.160 | I'm very excited to talk about this stuff.
00:00:30.720 | I'm also super happy to keep it interactive.
00:00:33.320 | If you have questions at any point, please interrupt me.
00:00:39.280 | I want to start out with a few very basic observations on what I think is going on.
00:00:50.080 | So the first one is, TeamAI is joining the game, so TeamAI has a lot of different players.
00:01:00.200 | They don't all join at the same time, but rather they join one by one.
00:01:05.520 | And not all their players vary a lot in how good they are.
00:01:10.640 | And right now, a lot of the players that have joined so far aren't really that smart and
00:01:16.720 | usually can do only a very narrow set of tasks.
00:01:23.000 | But one thing that we've kind of observed is that over time, you know, we're seeing
00:01:29.000 | stronger and stronger players join, and this is kind of where we are now.
00:01:35.520 | And then in general, we expect that TeamAI has incredibly strong players, so those will
00:01:41.880 | be players that are able to think so much better than humans, so much faster, and so
00:01:47.820 | much more cheaply.
00:01:50.200 | And these haven't joined yet.
00:01:53.400 | And so the anchor point that we have, if you think, for example, about chat2BT, chat2BT
00:02:01.880 | can already beat any human at knowing more facts or speaking more languages, and it can
00:02:09.360 | write about 50 words per second, and can do so about 100 times cheaper than humans could
00:02:15.760 | at minimum wage.
00:02:18.560 | And so, you know, chat2BT also has some really important limitations, and there's a lot of
00:02:25.940 | things that it can't do yet, but it is kind of an indicator of some of the players that
00:02:33.920 | may be able to join in the future.
00:02:37.220 | And so it seems like in the long run, TeamAI will have all the advantages over TeamHuman.
00:02:47.380 | And there's an important caveat, which is there's one important advantage that TeamHuman
00:02:56.100 | has, which is TeamHuman gets to pick which players from TeamAI join and win.
00:03:03.640 | And so this is kind of like an advantage that we should really be leaning into when we're
00:03:09.500 | thinking about what to do, and when we're thinking about, you know, this game that we're
00:03:13.260 | playing with TeamAI, and that we'll be playing with TeamAI in the future.
00:03:19.340 | So I think two of the main objectives of what we as TeamHuman should do is, like, first,
00:03:28.880 | we should try to recruit players from TeamAI to play on TeamHuman.
00:03:36.100 | And so this is kind of what I would broadly call alignment.
00:03:40.420 | And this is kind of like the problem that I'm working on.
00:03:44.040 | And then there's also other objectives.
00:03:45.700 | So another objective that I think is going to be really important is you want to write
00:03:49.540 | the rules of the game so that TeamHuman doesn't lose.
00:03:53.600 | And right now, TeamHuman kind of has the ball, and we get to write the rules, so we should
00:03:58.140 | write rules that, you know, make sense, and that still play this game in the future.
00:04:06.660 | And so in this talk, I won't really talk about the second point at all.
00:04:10.820 | And I'll talk about the first point, because that's where I know best enough where I'm
00:04:15.220 | working on.
00:04:16.220 | And kind of to phrase it differently, or to make it kind of, like, more practical, like,
00:04:24.340 | one way I'm thinking about alignment is, like, you want to build AI systems that follow human
00:04:29.340 | intent, and that, you know, follow human preferences that do what we want them to do.
00:04:36.620 | And so a bunch of the things, basically, I'll talk about two main things.
00:04:42.380 | The first part is going to be work that we've done in the past, and kind of, like, which
00:04:48.560 | roughly is in the bucket of, like, we are trying to figure out how we can make the models
00:04:56.620 | that we have today as aligned as we can, and we're just kind of trying -- we're going to
00:05:01.420 | try hard to do this, and we'll see how far we get.
00:05:05.180 | And then the second bucket is the things that we have to do next, the stuff that we haven't
00:05:10.140 | done yet that we think are going to be really important, and I want to kind of, like, lay
00:05:14.940 | out why I think they're going to be important.
00:05:19.740 | So, now, I said, you know, I'm, like, trying to make this more clear, or, like, more broken
00:05:27.220 | down what alignment means, so I'm not back here, because now, you know, the big question
00:05:32.540 | is, like, what does it mean to follow human intent?
00:05:35.180 | And kind of, like, two main categories of intent that we care about is, I would say,
00:05:40.580 | assisted intent, so if you -- you know, I give the system an instruction, or if it wanted
00:05:45.420 | to be my assistant, it should be my assistant, and it should follow the instruction.
00:05:49.700 | But then there's also all these other intents that I don't say when I'm usually, you know,
00:05:54.380 | talking to a system or a human that I also really care about, like, you know, it shouldn't
00:05:59.420 | literally always do what I say, but the thing that I mean, and it shouldn't make up stuff,
00:06:03.860 | and it shouldn't, you know, do harmful things, and it should ask a lot of questions when
00:06:08.580 | it's not sure what I mean, and so on and so on.
00:06:11.420 | And so these are all kind of, like, things that are often just, like, really difficult
00:06:17.180 | to, like, precisely specify, or, like, you know, put precisely in groups, but it is still
00:06:26.740 | things that we want to get AI to do, and that we have to figure out how to, you know, get
00:06:32.220 | into our system.
00:06:35.220 | And so, kind of, like, the main technique that we're using today for this is what we
00:06:40.420 | call the cross-line feedback, so that was used to train ScrapGPT and ChatGPT, which
00:06:46.100 | are the two, like, main systems that I'll talk about in this talk.
00:06:50.500 | And basically, the basic system is very simple, and it's also, like, a super general technique
00:06:56.260 | that applies to lots of different AI models, and modalities, and settings, but in this
00:07:03.140 | case, we'll be using that as well, and so the two steps is actually another step of,
00:07:08.980 | like, planning and demonstration, so I'm going to just stop for the sake of simplicity.
00:07:14.580 | The first step is you want to train your reward model from comparison, so you have it on the
00:07:20.420 | top, in this case, you know, explain moving that nucleotide field, or, you know, help
00:07:27.300 | me with my tramp paper, whatever it is, and then the model does a bunch of things, and
00:07:32.900 | then you rate which one is, like, close to the thing that you intended the model to be.
00:07:37.940 | And so you have this big set of preferences, and you train your reward model, and the reward
00:07:41.060 | model basically just learns to predict which one would you prefer.
00:07:44.980 | Everything okay?
00:07:46.180 | I'm going to say, like, just stand more in front of the camera, but I think it'll look
00:07:53.620 | good.
00:07:54.620 | Sorry about that.
00:07:55.620 | Maybe let's turn it a little bit.
00:07:59.220 | Okay.
00:08:00.220 | So now we have this reward model that captures kind of our preferences and what we care about
00:08:06.540 | and what we intend for the model to do, and then the second step is now you optimize your
00:08:12.420 | reward model with the input.
00:08:15.180 | And so in that setting, you know, like, the model tries a whole bunch of different things,
00:08:19.780 | and the reward model kind of tells it which one of these things is probably more of, like,
00:08:25.140 | the thing that it cares about.
00:08:27.580 | Yes?
00:08:28.580 | When you say "comparison," is that made by a new labeler to go get the data?
00:08:33.340 | Okay.
00:08:34.340 | And are those consistent, or does that not depend on the labeler?
00:08:38.740 | It'll depend on the labeler.
00:08:39.740 | Different labelers will have different preferences.
00:08:40.740 | There also might be inconsistencies, and we can give you examples of, like, in-front-of-this
00:08:46.740 | preferences, but those haven't really been a problem in practice.
00:08:52.620 | And so far, you know, like, our labelers often don't agree, but the model will average over
00:08:58.540 | all of that.
00:08:59.540 | But yeah.
00:09:00.540 | So this is, like, the basic technique.
00:09:03.540 | It's conceptually, like, quite simple.
00:09:07.340 | You can make it even simpler if you had, you know, if you didn't train the reward model
00:09:16.340 | and you labeled, instead, like, every arrow, but it would be a lot less data efficient.
00:09:22.820 | And so you can train your reward model to think of, like, data as efficient.
00:09:30.660 | So how well does it work?
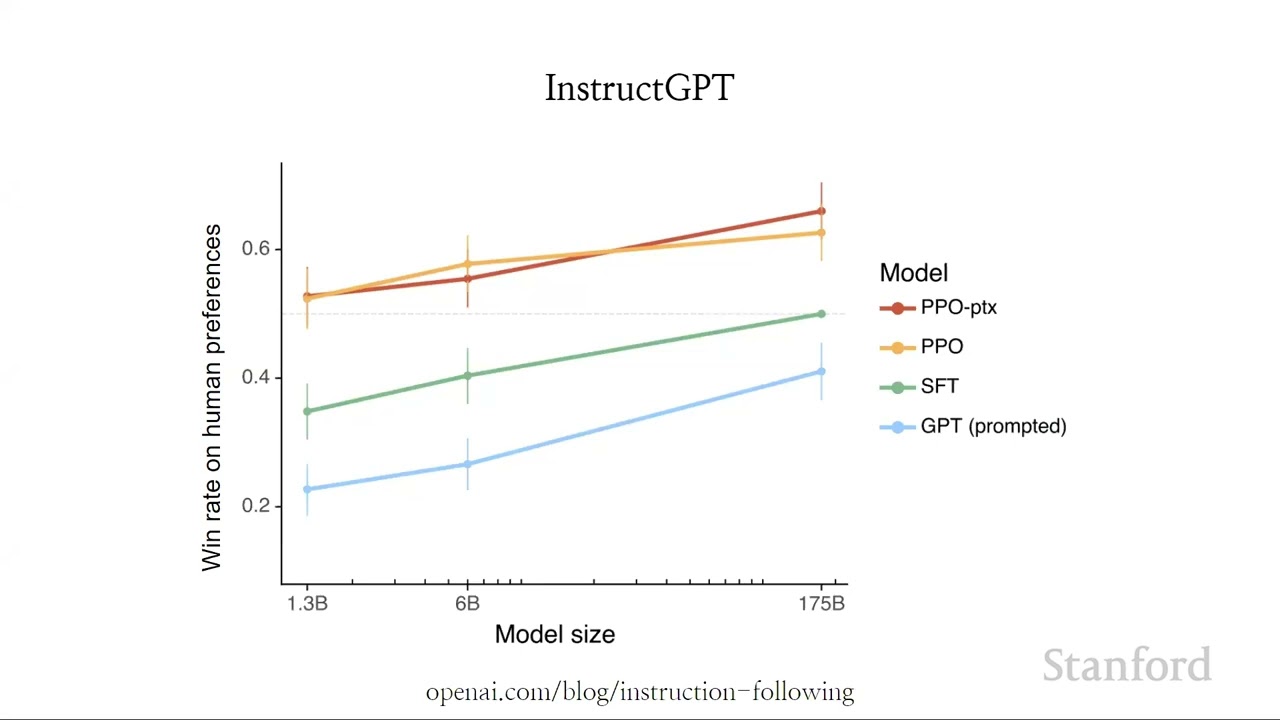
00:09:31.660 | So this is kind of, like, one of the main thoughts from the instruction sheet paper.
00:09:35.660 | And this is the one I like showing, because it really blew my mind, and it still does.
00:09:41.780 | What do we see here?
00:09:42.780 | So on the x-axis, you see, this is from the GP3 model series, and you see this is, like,
00:09:49.060 | three different sizes of models over two orders of magnitude.
00:09:53.020 | And on the y-axis is, how well does the model score on human preferences?
00:09:57.980 | So if we show a bunch of samples to humans, how likely are they to prefer one over the
00:10:03.460 | other?
00:10:04.460 | And then what we see is that even, like, the largest GP3 model, is this preferred to the
00:10:11.260 | smallest instruct GPT variant.
00:10:13.780 | And so the 100x smaller instruct model is actually preferred over the much larger, like,
00:10:25.900 | full-size GP3 model.
00:10:29.380 | And that's kind of wild.
00:10:30.380 | Sorry.
00:10:31.380 | Let me just finish my talk.
00:10:32.380 | So why is this a big deal?
00:10:33.380 | So basically, it basically shows that there was, like, a phenomenal line of code that
00:10:45.380 | makes the model score on information so much more useful than, you know, scaling up and
00:10:55.300 | fine-tuning.
00:10:56.300 | Or fine-tuning makes the model worse, because nobody wants to use it, and then we make all
00:10:57.300 | these fancy alignment techniques that don't get adopted.
00:11:00.100 | And so what we were-- like, originally, in, like, the first version, we saw these regressions.
00:11:07.100 | And then what here is labeled PPO, PTX, is kind of like a variant where we mix in pre-training
00:11:14.220 | data into the fine-tuning.
00:11:16.220 | And that mitigated a bunch of the regressions that we saw.
00:11:19.780 | Yeah.
00:11:20.780 | And I just had a quick follow-up to that.
00:11:45.680 | How important is, like, fidelity of fine-tuning data that you have?
00:11:46.680 | Like, you guys-- you collect data from humans, right?
00:11:47.680 | Yeah.
00:11:48.680 | What if you were to use some pre-trained language model to score, you know, general data for
00:11:49.680 | the courts or something like that?
00:11:50.680 | How do you do that?
00:11:53.560 | In terms of-- well, there are certain things that the language model will be able to automatically
00:11:58.440 | rank, and some things it won't, because it won't know your exact preferences, or it won't
00:12:04.320 | know exactly what we wanted to do.
00:12:07.440 | And so whenever the language model does something that we disprefer, we actually-- we have to
00:12:14.160 | give it another data point, right?
00:12:16.240 | Or in other words, you know, if you're aligning with humans, you somehow have to put humans
00:12:20.720 | into the loop so that, you know-- otherwise, how does the model know what it's supposed
00:12:26.720 | to do?
00:12:27.720 | OK.
00:12:28.720 | And lots of more questions.
00:12:29.720 | I don't know who was first.
00:12:30.720 | Yeah?
00:12:31.720 | How many human-- approximately, like, what's-- how many orders of that intuitive, like, human
00:12:32.720 | preferences do you need to achieve these--
00:12:33.720 | Yes.
00:12:34.720 | I'm going to get to that in a second.
00:12:35.720 | Sure.
00:12:36.720 | Of course, it will sort of like-- it will look at your PD over here, which is, I think,
00:13:00.280 | not a sample of each other, but some others.
00:13:01.280 | Yeah.
00:13:02.280 | So why would you decide to use an experiment theory for this?
00:13:03.280 | We haven't-- we haven't actually compared-- carefully compared across our all algorithms.
00:13:04.760 | And it could very well be that a different RL algorithm would be better.
00:13:08.080 | That was kind of like-- I know, PPO was invented in OpenAI, so that's why we used it.
00:13:14.760 | It's not-- not a really good reason other than that.
00:13:18.760 | It works also pretty well.
00:13:20.760 | Yes?
00:13:21.760 | What are the labels that humans are using to, like, count up and count down versus comparisons?
00:13:29.760 | Comparisons.
00:13:30.760 | This is better than this other thing.
00:13:31.760 | We have people compare between, like, three to six different responses from usually different
00:13:37.760 | models.
00:13:38.760 | Yeah.
00:13:39.760 | So is PPO in the reward model currently used in GPT--
00:13:47.760 | Yep.
00:13:48.760 | --introduction?
00:13:49.760 | And if so, like, do you use any of the human feedback, like, you know, regenerate responses
00:13:54.760 | and stuff like that to help as a reward function as well?
00:13:58.760 | How do you mean regenerate?
00:13:59.760 | Like, there's a button on chat GPT where you can say, like, regenerate responses.
00:14:03.760 | Or do you use any implicit feedback, basically, in human use?
00:14:07.760 | I don't know what the current state is for that.
00:14:10.760 | I expect people will try to use it.
00:14:12.760 | But, you know, model-- chat GPT hasn't been out that long.
00:14:15.760 | OK.
00:14:16.760 | Yeah.
00:14:17.760 | So I'm curious about this graph.
00:14:19.760 | Like, it seems like 100x, as you mentioned, increasing parameter doesn't give you that
00:14:23.760 | much more, like, fidelity there.
00:14:25.760 | Qualitatively, you have been tracking this for a while.
00:14:28.760 | Can you tell right off the bat, if you're, like, interacting with the 1 billion, like,
00:14:32.760 | model or the, like, 100 billion model, like, a pseudo-Turing test, the parameter size?
00:14:36.760 | Like, I give you a black box, can you tell me how many parameters it has?
00:14:40.760 | Probably not very precisely.
00:14:43.760 | But I think the big counter question is, like, do I get to write the prompt?
00:14:49.760 | I see.
00:14:50.760 | So if you just draw random prompts from whatever people put in the opening of Playground, which
00:14:55.760 | is what we use for unstructured GPT, then I probably need quite a few to tell the difference.
00:15:01.760 | But if I get to write the prompt, I can probably do it in one or two.
00:15:04.760 | At least, like, if the task is, like, tell the difference between this and this.
00:15:10.760 | Yeah.
00:15:13.760 | I want to-- can I just do two more slides, and maybe your questions get answered?
00:15:17.760 | And then-- so this was the question about training costs.
00:15:22.760 | So this is another thing that kind of really blew my mind, is, like, compared to pre-training,
00:15:27.760 | it is incredibly cheap.
00:15:29.760 | So if you look at, like, the amount of laps that it takes to train GPT to E, and then
00:15:34.760 | you compare it with, like, how much does fine-tuning and the RL, what's pre-training mix and everything,
00:15:41.760 | like, the most expensive unstructured GPT version is, like, less than 2% of the pre-training
00:15:46.760 | compute.
00:15:47.760 | And if you want to train an even bigger model, it's going to be more expensive, and you could
00:15:51.760 | still use the same, like, fine-tuning step to make it more aligned.
00:15:56.760 | And of course, I think the important thing to note also here is, like, we haven't fixed
00:15:59.760 | all the problems.
00:16:00.760 | There's, like, important limitations.
00:16:02.760 | And so I wouldn't say that this is, like, you know, the last version, and we wouldn't
00:16:07.760 | try to figure out how to spend more compute and more human data in the future.
00:16:11.760 | But all in all, it was surprisingly effective.
00:16:16.760 | OK, there were no more questions.
00:16:19.760 | More questions?
00:16:20.760 | Yeah.
00:16:21.760 | I just wanted to ask what the PTFs were.
00:16:24.760 | Mixing pre-training data into the RL fine-tune, just, like, mix the gradients.
00:16:30.760 | Yeah.
00:16:31.760 | Quick one.
00:16:32.760 | What's the number of branches for this graph?
00:16:34.760 | So you're fixing a number of branches for this graph.
00:16:37.760 | So this is the full-size GPT-3 version.
00:16:39.760 | So this is the $175 billion model.
00:16:45.760 | More questions?
00:16:46.760 | No?
00:16:47.760 | OK.
00:16:48.760 | There's also some questions on Zoom.
00:16:50.760 | Great.
00:16:51.760 | [INAUDIBLE]
00:16:54.760 | OK, sure.
00:16:55.760 | So the first one is--
00:16:57.760 | OK, sure.
00:16:58.760 | So the first question is, how do you deal with RFH breaking in the limit?
00:17:02.760 | Example preferences are a good proxy for values.
00:17:05.760 | But optimizing for them is theorized to incentivize perception.
00:17:11.760 | Yes, I'll get to that.
00:17:12.760 | OK.
00:17:13.760 | Sure.
00:17:15.760 | Sure.
00:17:16.760 | That's the next question.
00:17:17.760 | So that is, like, you want to automate alignment research.
00:17:20.760 | What happens if you need conceptual breakthroughs, which
00:17:23.760 | are difficult for experts to verify?
00:17:25.760 | OK, that would be a good take at the end as well.
00:17:30.760 | Sure, let's see.
00:17:31.760 | Sorry.
00:17:32.760 | [LAUGHTER]
00:17:34.760 | Yeah, I guess, like, one question is, like,
00:17:36.760 | how would fine-tuning direct you on human feedback
00:17:38.760 | compared to fine-tuning with RL?
00:17:41.760 | Fine-tuning, like, supervised fine-tuning?
00:17:44.760 | I think it's more like if you directly use the human feedback data.
00:17:50.760 | I'm also not sure what that means.
00:17:52.760 | OK.
00:17:54.760 | So, I mean, so one baseline I'm showing here
00:17:56.760 | is, like, what if you just take human demonstrations in the sense
00:18:00.760 | that, you know, we have a bunch of tasks.
00:18:02.760 | We just ask humans to do them, record what they did,
00:18:05.760 | and then train the model to imitate that.
00:18:08.760 | And here, it's, like, just very basic behavioral cloning,
00:18:11.760 | just using the same loss they use in pre-training.
00:18:14.760 | And then, you know, it is noticeably better than the Qsharp-pumped version,
00:18:18.760 | but it's still not as good as RL.
00:18:21.760 | And so that's why we like using RL.
00:18:23.760 | And basically, conceptually, there's two problems
00:18:26.760 | with the imitating humans approach.
00:18:28.760 | One is humans are better at some things than the model is,
00:18:32.760 | and they're worse at other things.
00:18:34.760 | And so at the things that the model is worse,
00:18:36.760 | you're trying to imitate something that you can't do.
00:18:39.760 | And on the things where the model is better,
00:18:41.760 | you're making the model worse because you're forcing it
00:18:44.760 | to do the thing in the way that the human would.
00:18:49.760 | And so with RL, you're kind of--with RLHF,
00:18:53.760 | you're kind of letting the model do whatever it wants to,
00:18:55.760 | and it can just figure out, like, the best way for it to do things.
00:19:01.760 | There's also another important advantage,
00:19:03.760 | and I'm going to get to that, but I briefly want to talk about chat GPT.
00:19:07.760 | So one thing--I kind of think of chat GPT as, like,
00:19:10.760 | the upgrade to instructor GPT.
00:19:12.760 | It's kind of like the next step at making the models more aligned
00:19:15.760 | and more useful to humans.
00:19:17.760 | And some things that is, like, you know, I think chat does better
00:19:21.760 | is kind of, like, using dialogue as the universal interface, right?
00:19:24.760 | You can talk to it directly.
00:19:26.760 | You can ask follow-up questions.
00:19:28.760 | You can, like, ask it to, you know, refine the answer
00:19:32.760 | and all these things.
00:19:33.760 | That makes it a lot easier to deal with.
00:19:36.760 | It's better at refusing harmful tasks,
00:19:39.760 | but it's also--there's still important limitations, right?
00:19:43.760 | Like, the biggest one is, like, the model hallucinates a lot.
00:19:46.760 | It makes up facts when, you know, for whatever task you give it,
00:19:53.760 | and that, you know, just makes it quite unreliable.
00:19:56.760 | It's also still sensitive to prompting,
00:19:58.760 | which kind of shows that, you know, it still has important misalignment
00:20:03.760 | that we need to fix.
00:20:06.760 | Like, really, if the model was, like--
00:20:09.760 | the model should really, like, do the task to the best of its ability
00:20:15.760 | no matter how you prompt it to do that.
00:20:20.760 | But, yeah, one important principle that I think is really useful for--
00:20:26.760 | or that, like, our job leans on a lot
00:20:28.760 | is that evaluation is easier than generation.
00:20:31.760 | So if we ask humans to compare and rank different responses the model gave,
00:20:37.760 | it is easier to tell the difference between different variants
00:20:42.760 | of what the model did than it is to do the task itself.
00:20:46.760 | Or, in other words, you know, you can do the comparisons on tasks--
00:20:51.760 | you can still, like, spot good behavior on tasks
00:20:53.760 | that you might not be able to do by yourself.
00:20:56.760 | And so if you're giving this kind of, like, feedback
00:21:00.760 | that lets the system do better than you actually could.
00:21:07.760 | And I think that's a very general principle that holds in lots of domains.
00:21:11.760 | So, kind of like, you're probably most familiar--
00:21:15.760 | if you studied CS, you know that P versus NP and everyone--
00:21:18.760 | you know, we don't actually know whether they're different,
00:21:20.760 | but in practice it seems like NP tasks are just much harder.
00:21:25.760 | It also applies to lots of other settings,
00:21:27.760 | like a lot of professional sports or esports just wouldn't be fun to watch
00:21:30.760 | if you couldn't tell who's winning more easily
00:21:34.760 | than you could actually compete on a professional level.
00:21:38.760 | It applies to a lot of consumer products.
00:21:40.760 | You can, like, look at your smartphones and tell which one you like more.
00:21:45.760 | That is, like, also deeper than just looking at, like, the specs.
00:21:50.760 | But it is actually very hard to build a good smartphone.
00:21:53.760 | It also applies to academic research.
00:21:56.760 | You know, it's much easier to review a paper
00:21:58.760 | and say all the things that are bad about it
00:22:02.760 | than it is to write a good paper yourself.
00:22:05.760 | It applies to, I don't know, when you--
00:22:10.760 | yeah, basically there's lots of domains where this applies.
00:22:13.760 | And so I think this is, like, a very--
00:22:16.760 | this principle is, like, very useful when we want to, like,
00:22:20.760 | align AI systems on tasks that we might not be able to do ourselves well.
00:22:26.760 | Okay, so having said that,
00:22:29.760 | RLHF has some really important limitations.
00:22:33.760 | And I think that's going to make it really difficult
00:22:36.760 | to use RLHF to scale alignment.
00:22:44.760 | Let me explain this with a diagram.
00:22:46.760 | So basically, on the x-axis, let's plot, like, the AI progress.
00:22:53.760 | And on the y-axis, how difficult different tasks are.
00:22:57.760 | And then as we have more AI progress, kind of like the tasks that AI--
00:23:01.760 | the difficulty of tasks that AI can do goes up.
00:23:05.760 | And, like, one of the fundamental problems is that
00:23:09.760 | the level of tasks that humans can reliably evaluate doesn't go up
00:23:14.760 | because humans don't get better with AI progress.
00:23:18.760 | And so I think we're, like, somewhere here.
00:23:22.760 | But the problem is, once you cross this line,
00:23:25.760 | you don't really know what--
00:23:28.760 | like, whether your model is actually doing the right thing
00:23:31.760 | because you can't reliably evaluate anymore.
00:23:34.760 | And so that's kind of, like, the point where
00:23:37.760 | RLHF training will start to break down.
00:23:40.760 | And what we'll probably see is kind of what the question
00:23:45.760 | before I lead it to is, like, well, now the systems are optimized
00:23:49.760 | for whatever feedback we give them.
00:23:52.760 | And so they will try to tell us what we want to hear,
00:23:54.760 | rather all the things that they know to be true.
00:23:57.760 | And, you know, they might learn how to deceive us
00:24:00.760 | because, you know, that makes it easier to score higher on preferences.
00:24:06.760 | And so kind of, like, the basic idea that we want to leverage
00:24:11.760 | is related to the principle I just mentioned,
00:24:16.760 | which is evaluation is easier in generation.
00:24:19.760 | So, for example, if you have a large language model
00:24:22.760 | writing a code base, like an entire code base,
00:24:25.760 | there's just no way humans would be able to find all the bugs
00:24:29.760 | and all the flaws in the code base.
00:24:31.760 | Or, you know, the code base could have, like, a Trojan in there
00:24:34.760 | and you might not be able to tell because it is so hard.
00:24:38.760 | And that's why we see so much buggy code out there.
00:24:41.760 | But if you ask your language model to find bugs and point them out to you,
00:24:46.760 | once you've seen the bug, it's so much easier for you to say,
00:24:50.760 | "Oh, yeah, this was a bug. Please fix it."
00:24:54.760 | And so now you've taken the task of writing a code base down to,
00:24:58.760 | "Well, I just have to evaluate whether that was a bug
00:25:02.760 | according to the spec that I had in mind."
00:25:05.760 | And so the general principle that we're excited about here is, like,
00:25:09.760 | we want to leverage AI assistance for human evaluation.
00:25:14.760 | And so the hope is that we, together, if we pair up humans with AI,
00:25:17.760 | you actually get a line that looks more like this,
00:25:20.760 | where, you know, like, humans together with AI can evaluate
00:25:23.760 | much more than they could on their own.
00:25:29.760 | And so to make this concrete,
00:25:32.760 | there's, like, two different ways you could do that,
00:25:34.760 | or there's many different ways you could do that.
00:25:36.760 | Two I want to highlight is, like, first, you can ask AI to write a critique.
00:25:41.760 | This is a project we did last year.
00:25:44.760 | And in this case, it was a simple summarization task,
00:25:47.760 | and we trained a language model to kind of, like,
00:25:49.760 | to say things that are wrong with the summary.
00:25:54.760 | And there's other things you could do.
00:25:57.760 | For example, you could give people chat GPT and ask them,
00:26:01.760 | "Okay, use chat GPT to help you evaluate."
00:26:04.760 | And then you could ask for a critique,
00:26:06.760 | or you could ask for a lot of other things.
00:26:08.760 | You could ask for an explanation.
00:26:10.760 | You can ask for fact-checking or a quote or, you know,
00:26:13.760 | whatever the model, like, chat GPT can actually reliably help you with.
00:26:18.760 | And so the idea would be that, you know, like, using AI assistance,
00:26:22.760 | you can kind of get all the smarts that AI has and leverage that
00:26:28.760 | in order to figure out how you should evaluate what this system is doing
00:26:31.760 | and, like, whether it's aligned with your preferences
00:26:34.760 | or whether it's trying to deceive you.
00:26:38.760 | And the big problem with this is how do we know whether it's working?
00:26:43.760 | And one of the kind of, like, difficulties is that by assumption,
00:26:51.760 | we're kind of dealing with a hard task where it's difficult to evaluate.
00:26:55.760 | And we also want the task to be real because we don't want to, you know,
00:26:59.760 | we don't want to solve a hard task that doesn't matter.
00:27:03.760 | And so it becomes different.
00:27:06.760 | So you need, like, a hard task that is real.
00:27:09.760 | But also, if you have those, you usually don't have ground truth,
00:27:13.760 | so you don't know which was the right answer
00:27:15.760 | and how do you know whether the assistance is working
00:27:17.760 | or it's biasing everyone to just say the same thing.
00:27:21.760 | And so there's a simple technique that we use in a critique to do this
00:27:29.760 | where, like, that we call targeted perturbations.
00:27:33.760 | And so what you do is you have a bunch of prompts.
00:27:35.760 | So this could be, like, whatever people type into ChatGPT.
00:27:39.760 | And then you kind of, like, take the response that you have
00:27:45.760 | and say, like, this is the correct response.
00:27:46.760 | It doesn't actually have to be correct, but let's just assume it is.
00:27:50.760 | And now you're asking a human to introduce some kind of subtle flaw
00:27:54.760 | that is easy to miss but is an important flaw.
00:27:58.760 | And now what you have is you have this pure data set of, like,
00:28:01.760 | a good response and a bad response.
00:28:03.760 | And you know which one is good and bad because you made it worse.
00:28:07.760 | And so, you know, in a way, that gives you ground truth.
00:28:13.760 | And so what you now can do is you can take, like,
00:28:18.760 | randomly select either the correct or the flawed response
00:28:21.760 | and then show it to either a human or a human with assistance.
00:28:24.760 | And then they have to say whether it was the correct or the flawed one
00:28:27.760 | or, like, how good the response is.
00:28:30.760 | And in this setting, we can kind of, like, figure, like,
00:28:36.760 | just try a lot of different AI assistance or scalable oversight techniques
00:28:41.760 | and then say, you know, like, is this actually helping humans find the flaws
00:28:47.760 | that we wanted more likely than not.
00:28:51.760 | And if it is, then, you know, like, you're actually really helping.
00:28:57.760 | And so we did this in the critiques paper.
00:29:01.760 | So this is training the language models to write critiques for summaries.
00:29:05.760 | And what we can show is that when we are assisting humans with critiques
00:29:09.760 | at the evaluation, they actually find 50% more flaws than it did without.
00:29:14.760 | And so this is kind of, like, real signs of life that you can already use
00:29:18.760 | in models that we can have today to help humans evaluate
00:29:22.760 | and, like, find problems they would have missed otherwise.
00:29:26.760 | And, of course, we still have to do this, like, on a much harder task
00:29:30.760 | and, like, with, like, a real task in a sense.
00:29:35.760 | And we also want to have, like, bigger effect size.
00:29:38.760 | But I think it's just, like, it shows that there's promise
00:29:41.760 | of these techniques already working.
00:29:44.760 | And so in the long run, what I think we want to get to is
00:29:50.760 | we kind of want to leverage AI for all the cognitive labor
00:29:54.760 | that goes into evaluating whatever our AI systems are doing.
00:29:58.760 | And this could be, you know, like, reading everything that's relevant
00:30:02.760 | or fact-checking or doing calculations or, like, writing code
00:30:07.760 | or any of these things.
00:30:10.760 | And then humans should focus on, like, their preference input,
00:30:13.760 | like the things figuring out what they actually care about
00:30:16.760 | and what they want the model to do.
00:30:19.760 | And this way we can kind of, like, leverage, you know, like,
00:30:27.760 | the abilities that, you know, the AI players will bring to the table
00:30:32.760 | and the things that they will be better at than us eventually.
00:30:36.760 | And then kind of, like, use them to help communicate the thing
00:30:41.760 | that we actually care about and, you know, the things that we
00:30:44.760 | actually want them to do.
00:30:48.760 | And, yeah, that's it.
00:30:52.760 | But, yeah, those are, like, the main slides.
00:30:54.760 | I'm happy to take more questions.
00:31:04.760 | Yes.
00:31:05.760 | I was wondering about this hallucination of responses.
00:31:09.760 | Have you ever tried to consider some notion of uncertainty
00:31:12.760 | in the answers?
00:31:14.760 | Yes.
00:31:15.760 | [INAUDIBLE]
00:31:24.760 | So ensembling is difficult because either you're, like,
00:31:28.760 | training and fine-tuning an ensemble from the same pre-trained model
00:31:32.760 | so you don't get that much variance in your ensemble,
00:31:34.760 | or you're pre-training a bunch of different models
00:31:37.760 | and now you're spending a lot of money on pre-trainings.
00:31:41.760 | One thing, I mean, it seems like it should be a solvable problem
00:31:46.760 | to just teach the model to say it's uncertain when it's actually uncertain.
00:31:53.760 | And there's been a bunch of research in that direction,
00:31:56.760 | but I think right now it's still, like, we're not really in a good shape.
00:32:02.760 | There's more stuff to do.
00:32:06.760 | Yeah.
00:32:07.760 | Do you think we may run into a kind of signals and noise ratio problem
00:32:12.760 | when it comes to AI-suggested critiques to AI answers?
00:32:17.760 | Because I'm sure, like, when AI is trying to point out
00:32:21.760 | particular problems in text, humans are more likely to report more problems.
00:32:26.760 | But what if it's noticing problems that humans wouldn't have necessarily
00:32:29.760 | had a problem with to begin with?
00:32:31.760 | Yeah.
00:32:32.760 | So we did try to control for that a little bit
00:32:35.760 | by, like, having humans rate the severity of their flaws
00:32:40.760 | and whether they would have noticed them otherwise.
00:32:43.760 | It can still see a significant effect.
00:32:47.760 | But also, like, I mean, a lot of the time the model is nitpicking,
00:32:51.760 | and then those are, like, not the interesting cases.
00:32:54.760 | Yeah.
00:32:55.760 | Also, if you, like, look at the example I showed,
00:32:58.760 | which I think is from the blog post,
00:33:00.760 | like, a lot of the critiques are just actually quite garbage.
00:33:03.760 | And one of the, like, things that makes it easy for critiques is it's okay
00:33:10.760 | if most of them are garbage because the human can just read them
00:33:12.760 | and discard them.
00:33:14.760 | And it kind of, like, more, you know, helps the evaluator know
00:33:19.760 | where to focus on or, like, notice, like, think of something
00:33:23.760 | they would have missed otherwise.
00:33:25.760 | So it's more like, you know, the critiques help you brainstorm
00:33:28.760 | how you should evaluate or something.
00:33:31.760 | But if you're kind of, like, using an assistant,
00:33:33.760 | you probably want more reliability than, like, filling most of the answers
00:33:37.760 | of why.
00:33:40.760 | Yeah.
00:33:44.760 | Yes.
00:33:45.760 | How do we ensure that the evaluation metrics we are using
00:33:48.760 | in your recursive reward modeling approach, like, detect deception
00:33:52.760 | and, like, left turns or something don't have, like,
00:33:54.760 | major discontinuity?
00:33:57.760 | Yeah, I think, well, it depends a lot what kind of discontinuity
00:34:03.760 | you're talking about.
00:34:04.760 | Like, if, you know, you get overnight, like, a model that is,
00:34:09.760 | let's say, 1,000 inches larger on, like, number of parameters
00:34:14.760 | or, like, equivalently better, that can, like, create quite a step up
00:34:20.760 | and that makes it quite difficult to do this kind of evaluation.
00:34:29.760 | So in that sense, I think it's going to be very important
00:34:32.760 | to, like, scale up AI more continuously and, like,
00:34:36.760 | do more incremental steps.
00:34:39.760 | Having said that, I think the basic picture
00:34:42.760 | with recursive reward modeling is that you're training the systems
00:34:47.760 | to help you evaluate, you know, systems that are trained
00:34:51.760 | or fine-tuned from the same system, right?
00:34:53.760 | And so if you can figure out how to get, like, fine-tune them
00:35:00.760 | in a way that they mention everything that is actually useful
00:35:03.760 | and relevant, then it would still be able to evaluate systems,
00:35:08.760 | even though they're much smarter than anything you've evaluated before.
00:35:13.760 | Maybe let me make this more concrete because there is, I think,
00:35:17.760 | a way that you could measure that or, like, one way we've tried it
00:35:21.760 | was using what we call the discriminative critique gap.
00:35:24.760 | So to measure that, you're training two different,
00:35:27.760 | or you're fine-tuning two different models
00:35:29.760 | from the same pre-trained model.
00:35:31.760 | One is the discriminator, which says, like,
00:35:34.760 | is this the flawed response or the correct response
00:35:37.760 | or more correct response?
00:35:39.760 | And the other one is a critique model
00:35:41.760 | that tells you what the flaw was.
00:35:44.760 | And now you can measure how often
00:35:47.760 | did the discriminator get it correctly?
00:35:49.760 | And the discriminator is just, like, pure gradient descent.
00:35:52.760 | It doesn't have to want to tell you anything.
00:35:54.760 | You're just basically hooking into the model's representations
00:35:57.760 | and trying to, like, get all the relevant latent insight it has
00:36:03.760 | to this prediction task.
00:36:05.760 | And then on the other hand, you have this critique model
00:36:08.760 | or this general assistance model, and you're measuring
00:36:12.760 | how often does the assistant actually help me point to the right flaw?
00:36:17.760 | And then if you compare these two scores,
00:36:19.760 | you can, like, look at the gap between them.
00:36:22.760 | Hence, this discriminator critique gap.
00:36:25.760 | And then if the gap is large, then the model
00:36:28.760 | knows a lot about the task it's not telling you.
00:36:30.760 | And so that would be very worrying.
00:36:32.760 | And if the gap is small, then there's much--
00:36:38.760 | presumably, there's, like, fewer things
00:36:40.760 | that the model is, like, not telling you.
00:36:42.760 | Yeah, but I guess there's, like, lots of value
00:36:45.760 | in ensuring this approach is, like, robust
00:36:47.760 | and testing it on [INAUDIBLE]
00:36:50.760 | That's right.
00:36:51.760 | That's why we want to test it on the current models.
00:36:55.760 | Yes, I don't know who was first.
00:36:57.760 | I think someone in the back.
00:36:59.760 | So I wanted to ask about, like, maybe towards the end,
00:37:08.760 | you had a slide where, like, there was, like,
00:37:10.760 | [INAUDIBLE]
00:37:12.760 | And so, you know, I couldn't help but notice, like,
00:37:15.760 | part of that also is, like, communicating
00:37:17.760 | what you want the AI to do, right?
00:37:19.760 | Right.
00:37:20.760 | Like, not just, like, evaluating, but, like,
00:37:22.760 | communicating, like, what happens, like,
00:37:24.760 | I would like you to do this.
00:37:25.760 | And maybe it can't do that.
00:37:27.760 | And so, like, at least, like, in my personal experience
00:37:30.760 | using the chat GPT, like, there were some things
00:37:32.760 | that could do that without surprising.
00:37:34.760 | Like, you could, like, approach somebody
00:37:36.760 | with a terminal, for instance.
00:37:38.760 | And I was like, oh, like, how did that come up?
00:37:40.760 | Or, you know, like, you can ask about, like,
00:37:43.760 | if it's, like-- there's, like, different things, right?
00:37:45.760 | Or I'm like, OK, like, what can I ask for?
00:37:47.760 | And, like, what kind of--
00:37:48.760 | Yeah.
00:37:49.760 | One thing that I thought was a bit concerning
00:37:52.760 | was just this idea that, like, you know,
00:37:54.760 | people don't always communicate their preferences,
00:37:56.760 | like, honestly.
00:37:58.760 | Or, like, there could be, like, coordinated efforts,
00:38:02.760 | right, to, like, instill rewards for, like,
00:38:06.760 | specific capabilities, you know, like,
00:38:08.760 | a coordinated effort to do such a thing.
00:38:10.760 | One idea, like, I had with this was, like,
00:38:12.760 | I tried to ask if it has, like, some idea
00:38:14.760 | of, like, a Wikipedia for itself, right?
00:38:16.760 | Because, like, I don't--
00:38:17.760 | I didn't know how to use it at first,
00:38:19.760 | so I just thought, like, maybe [INAUDIBLE]
00:38:21.760 | well, there didn't seem to be one.
00:38:23.760 | But, like, I was hoping there was one.
00:38:25.760 | There was one for, like, GPT-3, right?
00:38:27.760 | Like, I think Brockman broke, like,
00:38:29.760 | a little unofficially.
00:38:30.760 | So I was hoping.
00:38:31.760 | And so my question is, like, how do you, like,
00:38:35.760 | make that sort of, like, thing safe, right?
00:38:38.760 | Like, have you, like, recognized coordinated efforts
00:38:41.760 | to, like, you know, like, specifically reward
00:38:44.760 | certain kinds of behavior?
00:38:47.760 | Maybe, like, some group opportunity
00:38:49.760 | decides that they would like to--
00:38:51.760 | Yeah.
00:38:52.760 | --you know, give it some capability.
00:38:55.760 | So this is a--
00:38:56.760 | You know, like--
00:38:57.760 | Yeah, this is a really good question.
00:38:58.760 | And, like, in a way--
00:39:00.760 | I mean, the first obvious thing that you shouldn't do
00:39:02.760 | is, like, you shouldn't just, like,
00:39:04.760 | literally turn in the data that people
00:39:07.760 | give through, like, using interface.
00:39:09.760 | And we've kind of, like, seen other examples
00:39:12.760 | of what happens if you do that.
00:39:14.760 | If you think of, like, Microsoft Pay or something,
00:39:16.760 | that can go pretty wrong.
00:39:18.760 | The other thing is--
00:39:20.760 | I mean, right now, what we're doing is, like,
00:39:22.760 | we're hiring a bunch of people and then ask them
00:39:24.760 | to rate different model responses.
00:39:26.760 | But also, now the question becomes, like,
00:39:29.760 | you know, who are we hiring?
00:39:31.760 | And, like, what's their background?
00:39:32.760 | What are they trying to do?
00:39:34.760 | And so--
00:39:35.760 | And in particular, like, the thing I think
00:39:38.760 | we're doing quite poorly right now is, like,
00:39:40.760 | actually, like, importing, like,
00:39:44.760 | a diverse and representative set of human preferences.
00:39:48.760 | And it's more just, like, you know,
00:39:49.760 | whoever we end up, we can hire.
00:39:53.760 | And so I kind of wish there was also just, like,
00:39:56.760 | more targeted research on, like, how we should do that
00:40:00.760 | and how that could be done well.
00:40:02.760 | And some of it is also, like, you know,
00:40:04.760 | better placed outside of, like, big tech companies.
00:40:07.760 | Because if you are-- like, tech companies
00:40:10.760 | always have an incentive to, like, you know,
00:40:15.760 | import human preferences in a way that maybe
00:40:18.760 | is not, like, the thing that we actually--
00:40:21.760 | humanity would do under a reflection or something.
00:40:24.760 | And so I think it's a really big, important question.
00:40:27.760 | There's a slight follow-up.
00:40:28.760 | Like, data contamination is, like,
00:40:30.760 | the dual problem for this.
00:40:31.760 | Like, do you think the internet might be
00:40:34.760 | contaminated with--
00:40:36.760 | Obvious.
00:40:37.760 | Yeah.
00:40:38.260 | I mean--
00:40:38.760 | Do you have, like-- is that something--
00:40:39.760 | People might-- can--
00:40:40.760 | anyone can poison the free training, right?
00:40:42.760 | Just put something on the internet.
00:40:45.760 | And it's, you know, something that we
00:40:47.760 | have to be very mindful of.
00:40:51.760 | Yes.
00:40:52.760 | I don't know.
00:40:53.760 | Have you thought much about, like,
00:40:55.760 | considering that we're currently training these models
00:40:59.760 | [INAUDIBLE]
00:41:01.760 | and hopefully getting closer to human preferences
00:41:03.760 | at this point.
00:41:04.760 | As human preferences change, we've seen, like,
00:41:07.760 | [INAUDIBLE]
00:41:08.760 | quite drastically.
00:41:10.760 | Is there something-- like, is it a paradigm?
00:41:12.760 | Is it a [INAUDIBLE]
00:41:14.760 | models keeping up with data better?
00:41:16.760 | Like, that's, like, a very complex problem.
00:41:19.760 | Yeah.
00:41:20.260 | I mean, the most obvious thing is it's, like--
00:41:22.760 | the model's knowledge base is kind of like the free training
00:41:25.760 | cut-out date.
00:41:26.760 | Like, somebody-- you know, whatever data
00:41:28.760 | you went into pre-training, it doesn't
00:41:30.760 | know about, like, a lot of things
00:41:32.760 | that happened after that.
00:41:35.760 | In terms of updating kind of, like, human preferences
00:41:38.760 | or the, you know, like, the comparisons that
00:41:40.760 | go into the robot model, you just
00:41:42.760 | collect more data and retrain.
00:41:43.760 | And the fine-tuning run is, like, comparatively cheap.
00:41:46.760 | So you can, you know, do that again.
00:41:48.760 | I think what gets harder is that, you know,
00:41:51.760 | like, as you've deployed the model
00:41:53.760 | and people started using it for all kinds of, you know,
00:41:56.760 | tasks that they want to build their company around,
00:41:59.760 | like, they--
00:42:00.760 | if you update and you change the model,
00:42:05.760 | then they also have to do a bunch of work
00:42:07.760 | into, like, adopting their prompts to whatever
00:42:09.760 | they're doing.
00:42:11.760 | And so it doesn't come at a zero cost.
00:42:16.760 | Yes.
00:42:17.760 | Sorry.
00:42:18.760 | You.
00:42:19.760 | So on the note of exceeding human level performance,
00:42:22.760 | one of the advantages of GPT-3 is that it
00:42:25.760 | has this immense corpus of the entire internet.
00:42:28.760 | If you want to specialize in a specific domain,
00:42:30.760 | like chemistry or material science or something,
00:42:33.760 | and potentially to generate new compounds,
00:42:36.760 | then GPT-3 adapted, like, to use less data
00:42:41.760 | and still learn as efficiently.
00:42:44.760 | [INAUDIBLE]
00:42:46.760 | You mean, like, less data on, like, the chemical domain
00:42:49.760 | or something?
00:42:50.760 | Yeah.
00:42:50.760 | [INAUDIBLE] research paper over the last 30 years or something.
00:42:53.760 | Yeah.
00:42:54.760 | And you can throw that into pre-training, right?
00:42:56.760 | And then the model knows about it.
00:42:57.760 | But can the model really learn this effectively
00:42:59.760 | without so much data?
00:43:00.760 | Or can we somehow adapt the abstract concepts
00:43:02.760 | behind GPT-3 before that's over?
00:43:05.760 | Yeah.
00:43:06.260 | I mean, that's kind of the general idea with what you
00:43:09.760 | intend to do with fine tuning.
00:43:11.260 | And to some extent, we've seen it, like,
00:43:13.760 | generalized in this way.
00:43:14.760 | For example, InstructGPT was trained almost entirely
00:43:17.760 | on English language feedback and demonstrations.
00:43:22.760 | And it works in other languages.
00:43:24.760 | And so that's kind of wild.
00:43:25.760 | And so similarly, you could train the model
00:43:28.760 | with people who don't know anything about chemistry.
00:43:31.760 | And then it learns to follow instructions.
00:43:33.760 | And it will do so on the topic of chemistry.
00:43:37.760 | And this fine tuning can be very sample efficient.
00:43:39.760 | Like, with 100 data points, you can actually
00:43:41.760 | make a meaningful change in the model behavior.
00:43:44.760 | So it can be quite effective.
00:43:47.760 | I'm going to pick someone who hasn't asked.
00:43:50.760 | Yes.
00:43:51.760 | Regarding response generation, do you
00:43:55.760 | or how much effort do you put on or do you
00:43:59.760 | put emphasis in training on different expression styles?
00:44:03.760 | So what I've noticed from GPT-3 that it always
00:44:06.760 | gives you, like, very structured or scientifically
00:44:09.760 | structured answers.
00:44:11.760 | Do you consider any training if it returns you,
00:44:16.760 | like, a scientifically structured answer
00:44:20.760 | or rather an asterisk answer?
00:44:23.760 | Yeah.
00:44:25.760 | I mean, the tricky thing is, ideally, the model
00:44:28.760 | should give you the kind of answer that you want to have.
00:44:32.760 | Right?
00:44:33.760 | And some people prefer a more scientific or technical
00:44:35.760 | answer.
00:44:36.760 | Some people might prefer a more generic answer.
00:44:39.760 | And I mean, right now, like, ChatGPT doesn't have,
00:44:43.760 | like, you know, a way for you to set, like,
00:44:46.760 | your specific preferences.
00:44:48.760 | And that's something that would be really exciting to have.
00:44:52.760 | But also, I think the kind of statistic property
00:44:56.760 | that you've observed is, in fact, like, probably
00:44:59.760 | a product of our labeler pool.
00:45:02.760 | And so a lot of the ChatGPT workers were, like, more,
00:45:06.760 | you know, like, I think more, like, computer science-y
00:45:09.760 | and, like, more-- there was, like, more data generated
00:45:12.760 | by programmers compared to InstructGPT, which
00:45:16.760 | was more, like, generalist labelers.
00:45:20.760 | And yeah, there's, like, different-- it's, like,
00:45:24.760 | kind of-- it changes also the style.
00:45:27.760 | So there is no specific effort to distinguish that,
00:45:31.760 | but you can.
00:45:34.760 | Yeah.
00:45:35.760 | I mean, we should make a distinguished effort.
00:45:38.760 | It should give you, like, the style that you want, right?
00:45:41.760 | Yes.
00:45:45.760 | So one of the things that I've been thinking about,
00:45:48.760 | honestly, is how ChatGPT is going
00:45:52.760 | to play a factor in the education of the younger
00:45:57.760 | generation or the coming generation.
00:46:00.760 | And so if you go back to the graph of the AI progress
00:46:03.760 | and the human level-- yeah, what humans can evaluate,
00:46:08.760 | what I'm starting to think about is, like, over a break,
00:46:11.760 | I have used this.
00:46:12.760 | I showed, like, my 10-year-old cousin how to compare ChatGPT
00:46:15.760 | just to mess around with.
00:46:17.760 | And that green line is a lot lower, right?
00:46:22.760 | And furthermore, if said just becomes
00:46:25.760 | part of their educational experience,
00:46:28.760 | it's going to be much--
00:46:30.760 | or I perceive it to be more difficult for them
00:46:32.760 | to discriminate even simpler tasks than what we do now.
00:46:37.760 | And so I'm already thinking about, like,
00:46:39.760 | how that might disrupt or make this alignment
00:46:44.760 | a little bit more difficult in the long run,
00:46:47.760 | as you have people who are more--
00:46:49.760 | who take, for instance, what ChatGPT says as a given truth
00:46:56.760 | anyway.
00:46:58.760 | I was just wondering what your thoughts are on that.
00:47:01.760 | I mean, there's a real risk of overlying
00:47:03.760 | on a tech that is immature and that is not
00:47:05.760 | ready for you just believing--
00:47:09.760 | like, please don't believe everything the model says,
00:47:11.760 | right?
00:47:12.760 | Right.
00:47:13.760 | But also, I think one thing that I'm hopeful for
00:47:17.760 | is that, like, your cousin will end up, like, figuring out
00:47:21.760 | how to do this, where, like, they grew up
00:47:24.760 | with all of these AI tools that are getting better
00:47:29.760 | and learning how to actually leverage them productively,
00:47:33.760 | right?
00:47:34.760 | And, like, it's kind of like, you know,
00:47:38.760 | 20 years ago or something, when you were, like,
00:47:41.760 | using Google Search much earlier than everyone else,
00:47:44.760 | you're probably going to get better at, like,
00:47:46.760 | using that as a tool for everything you want to do.
00:47:48.760 | Any more questions?
00:47:54.760 | I think you had your hand up for a while.
00:47:56.760 | [INAUDIBLE]
00:47:57.760 | I think the slide where human tasks and the chat tasks
00:48:02.760 | and the model tasks, right?
00:48:04.760 | The AI tasks.
00:48:07.760 | Oh, wait, the last one?
00:48:08.760 | The last one.
00:48:11.760 | Yeah, so right now, it seems like you
00:48:13.760 | guys are using humans as biological sensors
00:48:18.760 | to the real world, to, like, physical ground truth,
00:48:21.760 | and using language as, like, a compressed interface
00:48:25.760 | to that ground truth.
00:48:26.760 | Are you guys also looking at using
00:48:28.760 | accessor technology directly with your models
00:48:31.760 | to get a more truthful answer of, you know--
00:48:36.760 | Yeah.
00:48:38.760 | I mean, it depends on what that sensor could be, right?
00:48:40.760 | Like, I guess, like, one of the most straightforward things
00:48:43.760 | is you could ask the model to browse,
00:48:45.760 | and then it can, like, fact check its own answers,
00:48:48.760 | and it can, you know, like, import external knowledge
00:48:52.760 | that it didn't remember.
00:48:54.760 | And yeah, I think that would be quite useful.
00:48:59.760 | I think that would also be quite useful for assisting
00:49:01.760 | human evaluation.
00:49:02.760 | [INAUDIBLE]
00:49:08.760 | And you can look at WebGBT, which, you know,
00:49:12.760 | is a published work on using the model for browsing.
00:49:17.760 | I think-- so one thing that makes it harder when you're
00:49:20.760 | using these, like, external sensors, or if you're
00:49:23.760 | letting the model interact more directly with the real world
00:49:26.760 | is that it raises more safety questions, right?
00:49:29.760 | If you let your language model make arbitrary API calls,
00:49:33.760 | then you have to be a lot more careful with which calls
00:49:38.760 | it's allowed to make, and which is it not.
00:49:41.760 | And if you're-- as opposed to if you're just, like,
00:49:44.760 | you're reviewing everything the model says,
00:49:46.760 | then you can decide which ones you want to make.
00:49:49.760 | So yeah.
00:49:53.760 | It's an open problem.
00:49:56.760 | OK.
00:49:57.760 | One more question.
00:49:59.760 | I think you did.
00:50:01.760 | [INAUDIBLE]
00:50:02.760 | About the reasoning abilities of these model language models.
00:50:06.760 | I've seen, like, different people talk about how
00:50:08.760 | it's only, like, a fixed amount of compute per token,
00:50:10.760 | while, like, humans, they have system one and system two,
00:50:13.760 | where we can, like, just speak quickly versus, like,
00:50:15.760 | actually do some reasoning and think through things
00:50:17.760 | that take more effort.
00:50:19.760 | And then I've seen other works that try to, like,
00:50:21.760 | kind of use-- to force it to a chain of prompt
00:50:23.760 | or a chain of, like, reasoning, or, like,
00:50:25.760 | just think step by step and stuff.
00:50:27.760 | Do you think that stuff is sufficient to do, like,
00:50:29.760 | everything that's two-level what we want,
00:50:31.760 | or will it require real, big fine-tuning
00:50:35.760 | or architectural changes?
00:50:39.760 | I don't know.
00:50:40.760 | I'm also the wrong person to ask.
00:50:42.760 | I'm mostly not trying to get the models
00:50:46.760 | to have new capabilities, and more, like, you know,
00:50:50.760 | getting them to play on Team Human.
00:50:52.760 | Oh, do we want to do the online questions?
00:50:57.760 | Yeah.
00:51:02.760 | Sorry.
00:51:03.760 | [INAUDIBLE]
00:51:05.760 | So what do you think is the-- is there a role for [INAUDIBLE]
00:51:08.760 | playing from the feedback, especially if you have, like,
00:51:11.760 | human-- like, you don't have to play chatbots.
00:51:13.760 | It's hard to model human interactions.
00:51:15.760 | So do you think, like, this would be more popping out?
00:51:17.760 | Yeah, quite possibly.
00:51:22.760 | I mean, yeah, as you point out, right,
00:51:30.760 | like, there is a lot of conversational data.
00:51:32.760 | And if you can use it, that would be--
00:51:35.760 | should be useful.
00:51:38.760 | I think, broadly, you can categorize this kind of thing
00:51:41.760 | as, like, let's make the RL algorithm better
00:51:44.760 | and, like, RL from the feedback.
00:51:46.760 | And I think that's valuable, and that should help us,
00:51:48.760 | like, make the same pre-trained models, like,
00:51:52.760 | more aligned according to the human preferences
00:51:54.760 | that we collected.
00:51:57.760 | But also, you would still run into, like,
00:52:00.760 | all the limitations that RLHF has, right?
00:52:03.760 | Also, if, like, someone wants to use RLHF on, like,
00:52:06.760 | the GPT-3 models, will OpenAI offer some sort of API for that?
00:52:09.760 | I think there's a fine-tuning API for GPT-3.
00:52:12.760 | I don't think it offers RL right now.
00:52:14.760 | Got it.
00:52:15.760 | But it's supervised fine-tuning.
00:52:17.760 | So you could do, like--
00:52:19.760 | you can, like, distill best of M and do this kind
00:52:21.760 | of expert iteration RL.
00:52:23.760 | Got it.
00:52:24.760 | So I'll try to move on to the questions.
00:52:26.760 | So the first question is, could you more clearly describe
00:52:29.760 | the pre-training process for chat GPT?
00:52:31.760 | For example, starting with the text wc001,
00:52:35.760 | then xdb of programming data, y steps of RLHF.
00:52:39.760 | Sorry.
00:52:40.760 | I didn't catch that.
00:52:41.760 | Start with text wc001.
00:52:43.760 | And then, so how much ease of data do you use?
00:52:46.760 | And how many steps of RLHF kind of things?
00:52:49.760 | I think the exact numbers are not public.
00:52:56.760 | It's basically similar to Instruct GPT.
00:52:59.760 | And for the Instruct GPT numbers,
00:53:03.760 | we had, I think, around 50,000 comparisons,
00:53:08.760 | and probably, like, 10,000 demonstrations,
00:53:11.760 | or, like, maybe tens of thousands.
00:53:13.760 | I don't remember the exact number.
00:53:16.760 | And so I had, like, this other slide with--
00:53:20.760 | yeah, it was, like, about 20,000 hours of human feedback,
00:53:23.760 | is what I calculated.
00:53:24.760 | And do you think it's [INAUDIBLE]
00:53:26.760 | human feedback, because that's-- you can get, like,
00:53:28.760 | 1 million or whatever [INAUDIBLE]
00:53:31.760 | Right.
00:53:32.260 | I mean, the big question is, like, how do you make--
00:53:34.760 | how do you ensure quality?
00:53:35.760 | [INAUDIBLE]
00:53:39.760 | But that's the whole problem, right?
00:53:45.260 | Like, that assumes you already have
00:53:46.760 | their one model that you trust.
00:53:48.760 | So--
00:53:51.260 | OK.
00:53:52.760 | Sure.
00:53:53.260 | So the next question, I think, that I was told was,
00:53:55.760 | you want to automate alignment research.
00:53:57.760 | What happens if you need conceptual visuals,
00:53:59.760 | which are difficult for experts to verify?
00:54:02.760 | Yeah, so, I mean, the kind of, like, ambition of that plan
00:54:08.760 | is to train a model that can do this kind
00:54:11.760 | of conceptual research.
00:54:13.760 | And, you know, you can picture, like,
00:54:16.760 | a language model that, like, you know,
00:54:18.760 | writes an alignment research paper that we read,
00:54:22.760 | and then we're like, oh, this is a really cool idea.
00:54:24.760 | We should try this.
00:54:26.760 | And I think, you know, going back to evaluation,
00:54:30.760 | it's easier in generation.
00:54:31.760 | I think it also applies to alignment research.
00:54:34.760 | And, like, I think, at the very least,
00:54:36.760 | like, I find it much easier to evaluate, you know,
00:54:39.760 | alignment research than I find it to, like, produce it.
00:54:43.760 | And so while there might be conceptual breakthroughs
00:54:48.760 | that we need that we couldn't even evaluate right now
00:54:52.760 | because they're just, like, you know,
00:54:54.760 | if we saw them, we'd be like, what is this?
00:54:57.760 | And this is kind of, like, this is, like,
00:55:00.760 | the reason why we want to do scalable oversight, right?
00:55:03.760 | Because, you know, like, if, you know,
00:55:06.760 | the language model produces this really brilliant insight
00:55:09.760 | and we can't even recognize it at the time,
00:55:13.760 | we should be able to have an easier time recognizing it
00:55:16.760 | if we use AI assistance.
00:55:18.760 | And if we leverage, like, our best AI models
00:55:22.760 | to, like, figure out whether or not that was a good idea,
00:55:25.760 | what is the weaknesses and what are the strengths?
00:55:27.760 | And, like, you know, what kind of experiments should we run
00:55:30.760 | to know whether this is a good idea?
00:55:32.760 | And so, yeah, I think basically, you know,
00:55:37.760 | the story of just using LLHF to train a model
00:55:40.760 | to do good alignment research,
00:55:42.760 | you have the obvious pitfalls, which is, you know,
00:55:45.760 | the model might write, like, an alignment proposal
00:55:47.760 | that kind of looks good to us, but is actually, you know,
00:55:50.760 | not a good proposal, and it creates AI
00:55:52.760 | that is misaligned with humans.
00:55:55.760 | And so in order to distinguish the two,
00:55:58.760 | which might be really hard, maybe it's not, but, you know,
00:56:02.760 | I think we should expect it to be really hard,
00:56:04.760 | and then leveraging AI assistance to evaluate that
00:56:08.760 | seems like a really promising plan.
00:56:12.760 | [INAUDIBLE]
00:56:18.760 | I mean, that was my whole point.
00:56:20.760 | It's not suppression.
00:56:21.760 | [LAUGHTER]
00:56:24.760 | [INAUDIBLE]
00:56:38.760 | I mean, the generalists were, like,
00:56:41.760 | I think basically the vast majority
00:56:45.760 | of the model's capabilities and, like,
00:56:47.760 | all the cool things you see it do come from pre-training
00:56:50.760 | and not from the fine-tuning stage.
00:56:52.760 | The reason why people sometimes attribute it
00:56:55.760 | to the fine-tuning stage is that you didn't see it
00:56:59.760 | in the pre-trained model.
00:57:01.760 | And the reason, I think, the reason
00:57:03.760 | that we didn't see it in the pre-trained model
00:57:05.760 | is because the pre-written model was so misaligned,
00:57:07.760 | it was not trying to help you, and it
00:57:09.760 | was not trying to show you all the things it can do.
00:57:12.760 | And instead, it just regurgitates
00:57:14.760 | a bunch of random web text.
00:57:16.760 | And that's not what you're looking for.
00:57:19.760 | And so, yeah.
00:57:21.760 | I think that what our project basically has been doing
00:57:24.760 | is, like, unlocking capabilities that were already in the model
00:57:28.760 | and making those available for humans to use.
00:57:32.760 | And in some ways, like, you know,
00:57:35.760 | alignment research is very dual-use in the sense that,
00:57:38.760 | you know, A, if you have really good alignment techniques,
00:57:42.760 | you can use it to align with whatever values you want,
00:57:45.760 | including values that, you know,
00:57:47.760 | we wouldn't particularly endorse.
00:57:49.760 | And B, it also, like, if you're doing alignment right,
00:57:54.760 | it will always look a little bit like you made
00:57:57.760 | the AI system more capable because before,
00:58:01.760 | it just wasn't really trying that hard to help you.
00:58:04.760 | And now, you've made it more aligned.
00:58:06.760 | So, you know, you actually see these capabilities
00:58:08.760 | that you already have.
00:58:11.760 | Sure.
00:58:12.760 | Let's see.
00:58:14.760 | [INAUDIBLE]
00:58:27.760 | Yeah, so that was what I was talking about here, right?
00:58:29.760 | Like, this is, like, the whole problem that we have,
00:58:34.760 | where what humans can evaluate is constant.
00:58:38.760 | And so we won't be able to evaluate, like,
00:58:40.760 | sophisticated attempts at deceiving us.
00:58:43.760 | And that's why we want to do scalable supervision
00:58:45.760 | so that we empower humans to spot
00:58:47.760 | these attempts at deception.
00:58:53.760 | [INAUDIBLE]
00:59:02.760 | Yeah, so I think these are real worries.
00:59:07.760 | And to some extent, we kind of, like,
00:59:10.760 | have to test empirically, like, how difficult
00:59:15.760 | and how severe they actually are.
00:59:18.760 | I think-- so my personal stance right now
00:59:22.760 | is something like, I think, trying
00:59:24.760 | to get the outer alignment signal really right
00:59:27.760 | is going to be, like, 90% of the effort.
00:59:30.760 | And once we have that, then a lot of the other things
00:59:33.760 | might also fall into place.
00:59:35.760 | So for example, I mean, it kind of
00:59:37.760 | depends on which story of inner misalignment
00:59:39.760 | you're worried about.
00:59:40.760 | But, you know, one story is you're kind of training
00:59:43.760 | your system, and it learns how to do--
00:59:47.760 | it learns, basically, a bunch of inner optimizers,
00:59:50.760 | kind of like meta reinforcement learning.
00:59:53.760 | So for example, like, GPT-3 can do, like, in-context learning.
00:59:57.760 | And that's, like, a kind of, you know, learned optimizer.
01:00:01.760 | And so now you're, like, doing all that GIF training
01:00:05.760 | or whatever, like, alignment training you have.
01:00:08.760 | And you're, like, the learned optimizers
01:00:11.760 | learn to do the thing that you want on distribution.
01:00:15.760 | But now if you have a distributional shift--
01:00:17.760 | and this distributional shift could be auto-induced,
01:00:19.760 | meaning, like, the model is causing it itself.
01:00:22.760 | And now you're going out of distribution.
01:00:24.760 | All these inner optimizers, like, try
01:00:26.760 | to optimize for something else.
01:00:28.760 | And one way you can, like--
01:00:33.760 | and, you know, like, how much that would actually happen
01:00:36.760 | in practice is kind of unclear.
01:00:37.760 | But one kind of, like, more important question
01:00:40.760 | is, like, if you have a really reliable outer alignment
01:00:44.760 | signal and you have this, like, general training
01:00:46.760 | signal that you trust, you can also
01:00:50.760 | use that, you know, on the new distribution
01:00:52.760 | to train the system to be more--
01:00:56.760 | or, like, to get its inner optimizers in a row, basically.
01:01:01.760 | And so then you've reduced, like, the inner alignment
01:01:04.760 | problems to, like, how do you deal
01:01:06.760 | with a distributional shift?
01:01:07.760 | And how do you, like, construct an outer alignment
01:01:10.760 | signal that you trust?
01:01:11.760 | And those are problems that we have to deal with anyways.
01:01:14.760 | But yeah, I don't know how it's actually going to shake out.
01:01:19.760 | But there's some important open questions.
01:01:27.760 | So regarding alignments, one of the kind of problems
01:01:33.760 | that I've been encountering in some discussions
01:01:35.760 | is there's not much interest, it seems,
01:01:38.760 | in, like, explaining why we come to these judgments
01:01:41.760 | or these lack thereof.
01:01:42.760 | There's not even been much interest in the way
01:01:45.760 | I would decompose these models.
01:01:47.760 | It's, like, explaining why this--
01:01:49.760 | and even set constraints arbitrarily.
01:01:51.760 | I mean, that's definitely a truthful route
01:01:53.760 | is to be able to show this.
01:01:54.760 | But as to why it's making these out-of-line judgments,
01:02:00.760 | have you all been able to interrogate the model?
01:02:04.760 | I mean, I think where we are right now
01:02:07.760 | is, like, pretty dissatisfactory.
01:02:12.760 | I mean, you can ask the model why
01:02:15.760 | it gave a certain response.
01:02:16.760 | But you don't know whether it's answering truthfully.
01:02:19.760 | And you can also--
01:02:20.760 | I mean, another thing you can do is
01:02:22.760 | you can give the model its own response
01:02:24.760 | and ask it to find out flaws, which is
01:02:26.760 | what we did in the Geeks paper.
01:02:29.760 | But, you know, I think that, like--
01:02:32.760 | I mean, there's one version where
01:02:34.760 | you try to make that better.
01:02:35.760 | But then the question is, like, what
01:02:37.760 | is your ground truth signal?
01:02:39.760 | I think a, like, better angle of attack
01:02:42.760 | is probably interpretability, where, you know,
01:02:46.760 | you figure out how to look inside the model
01:02:48.760 | and then how it actually works.
01:02:50.760 | That's what I was asking about, like,
01:02:52.760 | the level of research of interpretability.
01:02:54.760 | Yeah.
01:02:55.760 | It's like, it seems as though that's
01:02:57.760 | been really difficult to do for you
01:02:58.760 | because you are going through models
01:02:59.760 | in particular, and that's such a high-critical space.
01:03:01.760 | Yeah.
01:03:02.760 | Your current thinking is moving towards
01:03:05.760 | [INAUDIBLE]
01:03:06.760 | reducing the missionality of that representation
01:03:09.760 | [INAUDIBLE]
01:03:12.760 | Yeah, I mean, we are working on that problem.
01:03:16.760 | But I don't think we have anything
01:03:18.760 | that to show right now.
01:03:20.760 | And so it seems generally not to be a very easy problem.
01:03:28.760 | But, you know, I'm hopeful that we can do some things.
01:03:32.760 | I think, in general, the problem of interpretability,
01:03:37.760 | or, like, using interpretability for alignment,
01:03:39.760 | is kind of tricky because I suspect
01:03:43.760 | it's going to be neither--
01:03:45.760 | it's going to be not sufficient.
01:03:47.760 | And it might not be necessary.
01:03:49.760 | So any amount of interpretability
01:03:51.760 | you can leverage would be useful because it's
01:03:54.760 | another tool in your toolbox of, like, detecting deception
01:03:57.760 | or, like, knowing what you said, like,
01:04:00.760 | how-- why the model gave a certain answer
01:04:02.760 | and made a certain decision.
01:04:05.760 | But, you know, it is kind of unclear
01:04:10.760 | if you really get really good at interpretability,
01:04:12.760 | how you then leverage that for alignment.
01:04:15.760 | Like, presumably, you can look in the model
01:04:17.760 | and just, like, throw all the models out
01:04:19.760 | that you can find a misalignment in.
01:04:21.760 | But then aren't you just selecting
01:04:23.760 | for models that have misalignments that
01:04:25.760 | are really hard to find with the interpretability tools?
01:04:28.760 | - Sure.
01:04:29.760 | Just a follow-up to that.
01:04:30.760 | It's-- really, my aspect of that is kind
01:04:32.760 | of the standard practice that we have in general
01:04:34.760 | is that you have to find explanations of the problem.
01:04:36.760 | - Yeah.
01:04:37.760 | - And I guess then my question would be is, like,
01:04:39.760 | why would you take the interpretability
01:04:41.760 | to not be necessary?
01:04:43.760 | - Yes.
01:04:44.760 | - Why would it not be necessary?
01:04:46.760 | So, again, this is kind of, like, an open question.
01:04:50.760 | But basically, what stance you could take
01:04:53.760 | is that at the end of the day, what really is going to matter
01:04:57.760 | is the decisions that the model actually takes
01:05:00.760 | and not the reasons why it took them.
01:05:03.760 | And so if you can get to the point
01:05:05.760 | where you're confident that all the things the model actually
01:05:08.760 | does are aligned with what you want,
01:05:12.760 | then does it still matter what the model thinks internally?
01:05:16.760 | I don't know.
01:05:17.760 | - But you have to find out, too.
01:05:19.760 | You have to find out, like, if that value would be more
01:05:21.760 | valid than the model.
01:05:22.760 | - Yeah.
01:05:23.760 | That's what we're trying to do, right?
01:05:24.760 | Like, we're trying to make, like, a really, really
01:05:26.760 | good evaluation signal.
01:05:28.760 | And then you can select for--
01:05:30.760 | you know, you can train the model to do the things
01:05:32.760 | that you want it to do because you can always
01:05:35.760 | evaluate better than the model can do stuff.
01:05:41.760 | Yeah.
01:05:42.760 | - I'll probably have my shot at that.
01:05:44.760 | That's my question.
01:05:45.760 | - Very good.
01:05:49.760 | Thanks so much, Dion, for the great lecture.
01:05:51.760 | Very interesting.
01:05:52.760 | - I might actually do, like--
01:05:53.760 | as we're talking about the topic of connectivity,
01:05:55.760 | I might just do, like, a live--
01:05:58.760 | I want just, like, an application thing.
01:06:01.760 | - Yeah, sure.
01:06:02.760 | Sure.
01:06:03.760 | - Just to end up the class.
01:06:06.760 | Sorry.
01:06:07.760 | So how do you find this thing?
01:06:10.760 | - Oh, you need--
01:06:11.760 | - All right, guys.
01:06:12.760 | Can we give our speaker a round of applause?
01:06:14.760 | - Thank you.
01:06:15.760 | - Thank you.
01:06:16.760 | - Thank you.
01:06:17.760 | - Thank you.
01:06:18.760 | - Thank you.
01:06:19.760 | - Thank you.