Scaling up Test-Time Compute: s1, Recurrent Depths
00:00:00.000 | you will find it okay he's gone for context uh swicks is at the dmv he is in the process
00:00:10.160 | of getting his license so he's uh up for this one but let's let's give it a few minutes
00:00:18.080 | for people to join in um and then we'll we'll get started these are pretty good papers um
00:00:25.720 | nobody was so stressed out okay so we'll give it a few minutes for people to join um do
00:00:44.960 | we want to get a quick intro of what's going on
00:00:58.480 | he's left and hasn't muted people upon entering let me fix real quick
00:01:20.840 | okay so rafael you're kind of ready to present share yeah sure perfect perfect um let's give
00:01:49.580 | it another two minutes you want to do a quick intro yeah i'll start so um i'm rafael uh
00:01:57.640 | i'm working mostly on the lms uh i'm working to create uh lm for georgian language uh which
00:02:04.960 | is a country in europe which is a low resource language and uh yeah we already developed
00:02:09.720 | our first model uh we started like zero data zero compute and zero talent because uh only
00:02:17.360 | a few people work on lms in georgia so we managed to develop the the model which like
00:02:23.880 | outperforms uh uh larger models like gpt and cloth for georgian language and also it's
00:02:30.340 | like for enterprise use cases and it supports function calling uh json on structure mode
00:02:35.960 | and rag and so on so if you want to test it i can um give you the free uh api and yeah
00:02:43.600 | that's that's uh very sick very sick yeah share share info in discord i'm sure a lot
00:02:49.240 | of people are interested i know uh eugene cha he presents quite a bit he's very interested
00:02:54.720 | in low resource language models but um yeah so today we basically have the two s1 and
00:03:02.520 | scaling up test time compute papers i'll let you go through them however you want uh chat
00:03:07.080 | normally gets pretty active so if you're monitoring that's cool if something is very confusing
00:03:13.120 | i'll probably interrupt but you know take take it as you want yeah sure sure okay
00:03:27.440 | actually let's let's give it another minute some people are needing passcodes they're
00:03:31.760 | just not using the right link but okay once we hit 50 we should be good
00:03:40.960 | okay we've got a new link posted and then we're good to start
00:03:43.520 | yeah um can you see the screen yep
00:03:47.600 | uh okay so the today uh i want to cover a two paper but both of them are about the test
00:03:56.560 | time scaling and the latest uh hot topic the idea is that we want to build lm which uh
00:04:04.560 | so we want to increase the performance so we know from latest models like openai gemini
00:04:10.120 | and tropic already that reasoning works the uh the thinking works so uh idea is to we
00:04:17.440 | want to replicate that work and this paper from stanford is trying to replicate the reasoning
00:04:22.960 | step with uh like um only 200 or something like that so only a small budget the idea
00:04:29.840 | is that uh so uh they collected 1k samples uh in some way i'll take uh i'll take a bit
00:04:38.560 | and uh yeah idea is that they train qn 0.5 uh 32b and it outperforms or one preview actually
00:04:48.000 | on the mass and reasoning data sets that's the idea and um they uh they created some
00:04:56.000 | kind of technique which is pretty simple i think and yeah mostly it's for the people
00:05:02.160 | like me who don't have a lot of budget and resources to train the model and still have
00:05:06.840 | ability to train reasoning elements so uh yeah objective is to to create a simple simplest
00:05:15.400 | approach to achieve this time scaling actually so uh to deep dive into the methodology um
00:05:21.520 | let me scroll a bit um yeah the first thing is that they somehow created uh 1000 examples
00:05:33.600 | and uh what they did actually to took some mass data sets like numina mass uh aj ibel
00:05:40.480 | and so on and they generated uh tracing reasoning tracing using gemini 2.2 flash thinking and
00:05:48.680 | they did some uh pipeline after that so first is that uh they collected uh almost like 60k
00:05:56.440 | examples then they filtered using the quality which means to drop some examples based on
00:06:01.960 | the formatting some uh ascii errors as i remember and uh yeah after that they got 54k uh and
00:06:11.160 | yeah then they filter uh based on the difficulty and what they did is that took two model like
00:06:17.320 | i'm not sure if you can see the image perfectly but they took uh two image qn.57b and 32b
00:06:26.440 | and they asked the question on both models and if any of the model uh responds correctly
00:06:32.400 | they just filter those examples so they the idea is that they want to choose the hardest
00:06:37.960 | question that none of the model can answer and they evaluate the the correctness using
00:06:43.600 | the claw 3.5 sonnet and after that they got uh 25k uh samples uh and also they uh took
00:06:53.720 | the the length of the reasoning so uh reasoning trace so you can say that if the the length
00:07:00.120 | is the peak maybe it's a more like challenging problem or something like that after that
00:07:05.400 | uh the the key point is to take some so since the idea is do we want to uh run and train
00:07:11.720 | the model and uh small uh samples they have to take some uh sampling right so they took
00:07:20.200 | uh some llm and cluster those examples of 25k and after that took some uh just do some
00:07:29.880 | sampling to collect 1k examples and uh took them based on the reasoning trace length actually
00:07:37.160 | so yeah after those pipelines they collected 1k examples okay data sets which replace like
00:07:43.720 | the question the reasoning and the answers uh so if there are any questions about that
00:07:50.400 | I can stop a few seconds and I can continue because it's important to understand that
00:07:55.600 | it's simplest approach I mean but yeah it's pretty good to collect and uh yeah take some
00:08:02.080 | data okay uh after that they trained a qn 2.5 stemming to b and yeah as you can uh imagine
00:08:13.080 | they got some good results so yeah another thing that we uh that I want to explain before
00:08:23.040 | I show the result is that uh after creating data set they um create uh some technique
00:08:30.440 | uh to increase the test time scaling so the name is budget forcing or something like that
00:08:36.520 | as I remember and the idea is that if you want to generate more tokens and more thinking
00:08:42.480 | steps you add the word wait in the output and model understand to continue the generation
00:08:50.120 | and if you want to stop the thinking process and for the generation you add the final answer
00:08:56.680 | that those words in the generation and it stops the um the process yeah that the budget
00:09:03.560 | forcing here so they have the maximum number of tokens the minimum number of tokens and
00:09:08.200 | you have the ability to control the length of the traces based on those simple words
00:09:13.520 | that's the idea uh yes okay and about about the results that first thing is that they
00:09:24.080 | it outperforms or one preview and we also it's comparable to everyone this deal from
00:09:31.360 | deep seek qn reasoning and also the sky sky one t which is a few weeks ago um yeah also
00:09:41.580 | interesting thing that we can see um is that uh if you increase it uh the thinking time
00:09:49.680 | so the if you generate more tokens the performance increased for some uh data set like mess time
00:09:57.080 | and qa uh okay yeah that's the example if you want to see how it works so let's say
00:10:09.120 | how many are in the raspberry uh and as you can see it got the the wrong answer and they
00:10:15.280 | add the word weight which continues the the generation and after that it corrects uh it
00:10:22.400 | yeah return the correct answer okay um yeah another uh good thing is that uh as you can
00:10:33.920 | see after some time the results uh converge so if you generate a lot of tokens or if you
00:10:41.880 | add a lot of weight awards in the generation after some time it converts that's another
00:10:48.920 | uh result and also they compare those methods for other uh methods like majority voting
00:10:57.520 | or other else and found that the scaling law for the test times for those uh techniques
00:11:05.560 | are different so as you can see uh for um for this budget forcing uh results goes up
00:11:12.400 | but for majority voting yeah a little bit um yeah yeah that's also an interesting results
00:11:23.960 | so as you can see this is a their model the final one and they compare the results for
00:11:30.760 | openai gemini and qn uh and other open weights and open data models also as we mentioned
00:11:38.600 | that the data the model all of these are open source so you can check it uh yeah and test
00:11:46.560 | and then data as well okay so yeah as you can see it outperforms for uh or one preview
00:11:54.040 | on math data set and for amy and not for pqa and the same results for all mini uh for gemini
00:12:03.320 | we only have one results uh for other tool that i remember they can't test it because
00:12:09.640 | gemini blocks some uh blocks some uh api requests and for amy this is only 30 or 40 examples
00:12:18.000 | so they test it manually in a google ai studio and that's why we have only those results
00:12:23.440 | and it's nearly comparable to the gemini and the idea is that they kind of a distill
00:12:30.720 | uh gemini right and uh with only 1000 example they got comparable results to gemini actually
00:12:40.320 | another interesting thing is that uh this is the base model that they took uh and yeah
00:12:45.800 | the gain of the performance is a lot so like 30 uh for me and so on which is a huge yeah
00:12:55.960 | and uh some results from uh deepsec is comparable as well but the idea that they mentioned is
00:13:03.200 | that uh in date in uh in those case they only took 1000 examples so for deepsec they distill
00:13:11.080 | uh 800k examples to to train their models okay
00:13:19.400 | okay after that they do they did some ablations uh and uh found some good interesting things
00:13:33.360 | i think uh so uh first one is that um how you choose uh 1000 examples from 60k and yeah
00:13:41.920 | they choose like from for example from random from the diverse like based on the clusters
00:13:47.200 | to cut the 1k based on the lengths of the traces and just train on the full data set
00:13:53.960 | and as you can see it outperforms all 1k examples but it's comparable and yeah full data outperforms
00:14:01.680 | a little bit but the idea is that we only use 1k examples rather than the 60k and got
00:14:08.520 | that mostly the same results
00:14:12.240 | uh yeah i found that last section pretty interesting basically uh they these results show that
00:14:19.760 | if they didn't go through their like four step approach of filtering to a thousand samples
00:14:24.960 | their results are 40 30% worse right so their whole thing of like step one see if the questions
00:14:32.320 | are easy step two cluster and take like diverse samples that alone to like get the thousand
00:14:39.120 | high quality versus just a thousand random samples 30% net difference so pretty big importance
00:14:45.860 | in their little filtration pipeline
00:14:48.560 | yeah exactly so the pipeline is pretty simple i think but maybe one of the good thing is
00:14:54.900 | to filter based on the the quality and uh based on the model response i think rather
00:15:03.580 | than that like the formatting i think doesn't matter actually
00:15:07.520 | yeah the model response if i'm not mistaken from the two base plan models was basically
00:15:12.240 | just throwing out a lot of it so like when they use the quen 7b and quen 32b the base
00:15:17.960 | models basically what they did was they ran their 60 000 questions through these if the
00:15:23.980 | two basic models could answer it correctly then we just throw out the sample it's too
00:15:27.760 | easy so step one you know that filters a good bit just to get hard questions but yeah high
00:15:33.560 | level their whole pipeline was pretty interesting um yeah that seems to be like half of the
00:15:40.480 | value so yeah a lot of it was just yeah there's good at 1000 samples the other one was kind
00:15:47.840 | of the budget forcing right so you want to i think explain a bit more about how the budget
00:15:53.640 | forcing is working and what it's doing i thought it was pretty unique yeah just to summarize
00:15:59.160 | those are the important things so data sampling those data pipeline and budget forcing actually
00:16:05.880 | for the data uh side actually i test this idea for my use cases not for the uh the reasoning
00:16:12.720 | uh thing but uh i collect and i mix the data set based on this technique and yeah it really
00:16:18.580 | works because you can choose the high quality data based on that and yeah about the body
00:16:24.080 | budget forcing um as i mentioned so you can uh you have ability to control the size of
00:16:32.200 | the reasoning so let's say you have the minimum number of token that you want to generate
00:16:37.520 | and maximum number of token that you want to generate right and you can control this
00:16:41.680 | uh the length based on the wording so if you want to generate more you add wording like
00:16:47.200 | weight like as you can see here and model uh continue the generation and generate more
00:16:53.840 | tokens and you can do that several times like two or three times if you want to generate
00:16:58.800 | more and if you want to stop the generation you can add the final answer word and it's
00:17:04.280 | total generation so you can control the maximum number of tokens based on that yeah that's
00:17:10.880 | the idea i'm not sure if any other work is uh doing something like that um but yeah so
00:17:19.320 | after this came out some other people started doing it essentially what people are also
00:17:24.080 | saying is it's a way some people are saying this is the distinction between o3 mini low
00:17:29.080 | and o3 mini high and it allows you to control how much thinking you do right so as we generate
00:17:35.320 | tokens autoregressively eventually we generate an end of sentence token end of text token
00:17:41.840 | and then we stop generation so what they're doing is anytime the model the next likely
00:17:45.840 | token is the end of token end of sentence we replace it with a thinking token you know
00:17:50.480 | so hmm what should i do and like it continues thinking and now at inference time you can
00:17:56.120 | kind of just force more thinking or if it's rambling too much you can you know force it
00:18:01.400 | to end once it's given an answer if you look at the outputs or you can tell it you know
00:18:06.000 | like final answer and start boxing your answer but the the interesting thing here is like
00:18:11.880 | yeah it also played quite in effect so they show their scores of um with and without budget
00:18:18.320 | forcing but it's essentially like a inference time hack to control the amount of thinking
00:18:23.280 | right so if you think of like as an api consumer if i want thinking to be like 30 maybe i add
00:18:30.080 | in three extra think tokens instead of end of sentence if i want like 60 i add in six
00:18:35.680 | very high level just to understand conceptually what's going on but that's kind of what the
00:18:40.640 | budget forcing here was um another comment rj made is it only had a minor improvement
00:18:47.960 | over the base plan model it seems pretty high do you want to go to the performance benchmarks
00:18:53.680 | like you make the base yeah this is the base base is pretty bad so uh the base aime score
00:18:59.320 | of quen32b is 26.7 the s1 score is 50 and 56 with budget forcing so yeah this is result
00:19:09.400 | and this is always budget forcing oh right i was i was misreading i was looking at the
00:19:13.800 | qwq yeah okay got it yeah qwq is the quen reasoning model preview they haven't released
00:19:21.960 | it yet i think they have a second update that they put out this week someone at the quen
00:19:26.840 | team on twitter is cooking about this and keeps saying he's doing it but that's quen's
00:19:31.320 | internal reasoning model it's not it's not just a base instruct it's also just um not
00:19:35.520 | out yet yeah that's what surprised me that with only 1000 example you can just run fine
00:19:43.320 | tuning with sft and got a really big improvement rather than base model that's uh yeah yeah
00:19:50.080 | it's kind of it's not necessarily just fine tuning with sft right it's also distillation
00:19:56.240 | because they're distilling gemini thinking traces so it's not like a distillation loss
00:20:01.420 | but it's sft to match like um gemini's thinking output plus a little hack of think a little
00:20:09.000 | more if you're not on the right path but um the the interesting thing there is still the
00:20:13.920 | 800,000 samples does this very well with distillation uh so qwq is quen's internal native rl based
00:20:22.400 | reasoning model and if we look at it the performance is pretty similar right like the model is
00:20:27.320 | not out yet but um performance wise it's pretty much just as good the the difference here
00:20:35.000 | and with s1 is probably that you know they're similar to the 800,000 samples like i don't
00:20:41.000 | think they said but i think it's a fair assumption that they're very yeah they're in the hundreds
00:20:45.740 | of thousands of samples yeah exactly and they just spend uh i don't remember 26 minutes
00:20:54.800 | for 16h100 to run the training yeah thousand samples not much but it's it's very cool work
00:21:02.040 | to see and then this also leads to the here's a rumor of here's what openai does for more
00:21:07.480 | and less reasoning models thinking models and also here's a little hack for how you
00:21:11.960 | can do it yeah yeah and also they compare these budget forcing techniques for other
00:21:17.480 | uh conditional control techniques like token conditions step conditions and plus condition
00:21:24.280 | which is like uh you say that let's uh think 100 words or something like that or let's
00:21:30.000 | think with three steps and uh yeah they did some evaluation and they took it budget forcing
00:21:36.440 | is the best uh rather than those techniques yeah so also they did ablations about the
00:21:45.360 | word actually so uh they compare that you would like weight and like alternative without
00:21:54.680 | strain or something like that and yeah weight works the best it's also interesting yeah
00:22:02.200 | uh some of the other like little like local stuff that has come out after this paper is
00:22:09.640 | instead of just um appending the weight word or something people started slapping in aha
00:22:15.960 | moments and like people themselves have started testing quite a bit of this right so instead
00:22:21.640 | of end of token what they found best was to you know give it weight which is like wait
00:22:26.520 | i've figured this out and it's like that's pretty cool makes like it's an interesting
00:22:30.600 | idea people locally have tried like you know 50 other things and like uh one thing i was
00:22:36.520 | hoping someone on is let's train a classifier to see what's the best swap word to put in
00:22:41.480 | and like it does slightly better but now you have to run a classifier but it's fun little
00:22:46.560 | stuff yeah yeah so idea of this paper and motivation is that this is the simplest technique
00:22:53.800 | i i think which um gives you a big improvement on them in terms of results like rather than
00:23:01.240 | base model yeah i mostly the same gemini and so on and that's the main idea i think yeah
00:23:09.000 | uh yeah uh what else i think that's it pretty small paper but interesting and yeah
00:23:23.000 | all the all the results are on math related uh data sets yeah i wonder if there's a
00:23:32.280 | certain deal of performance degradation on more other
00:23:39.640 | data sets that require reasoning but maybe are not math based yeah that's good question
00:23:48.680 | but yeah for this paper they just only test on the math but no gpqa is not just math and they go
00:23:56.680 | into their data set curation uh the the majority like the 50 000 samples out of the 60 000 they
00:24:03.320 | started uh subsetting from that old data set they include quite a few other non-math-based benchmarks
00:24:11.560 | and then part of their clustering is to um like not just sample math so their sonnet um clustering
00:24:21.080 | does diversity past just math so they have standardized like lsat in there they have the
00:24:26.200 | hardest questions of the lsat they have chem biophysics they have other stuff in there and
00:24:31.000 | then the gpqa benchmark shows that it's not just math the other two are math but at a high level
00:24:38.200 | one thing that we've seen with reasoning models is like math and verified code kind of converge to
00:24:44.200 | quality on other uh just general tasks but one of their um benchmarks here is not math
00:24:51.160 | yeah people um did you see uh did anyone try do like replicating this with some of the same
00:25:02.840 | uh models that that are that the um r1 model was distilled too because i would be interested to see
00:25:10.040 | like okay if we use this technique versus distillation from like the r1 like god model
00:25:17.000 | what happens like how does that compare because it's a little bit apples to oranges to compare to
00:25:23.000 | like a distill right i mean this r1 distill but is that like the same size or like how do
00:25:29.080 | which one is that uh so r1 like deep seek themselves put out um when 32b r1 like when
00:25:37.560 | 32b reasoning so they did the exact same model so in the in the opposite sense s1 did this on
00:25:44.200 | the same model that deep seek did it on so we have the direct to i think and i could be completely
00:25:50.040 | wrong here i don't think deep seek told us how much data they use for distillation they just
00:25:54.520 | said we distilled the big ones here you go they're good here's how they perform but like
00:25:58.840 | you know we don't know did they do 500 samples did they do 50 000 we don't know what they did
00:26:04.200 | for distillation except for i i think they did a proper distillation loss not just sft on outputs
00:26:10.040 | and it's a little different too because like this is trained on um outputs from gemini that would
00:26:17.400 | be on outputs of r1 so like there's a little stuff different but directly to your question
00:26:23.080 | deep seek did do the same model you can compare the two and i don't know if someone wants to
00:26:28.440 | fact check or make a note i don't think the deep seek paper paper said how many samples are used
00:26:34.440 | for their distillation right yeah but but is that result in this paper do you did anyone figure out
00:26:42.040 | is that the same is that r1 distill is that the like equivalent quinn model the 32b
00:26:50.040 | because like regardless of how much i mean obviously it's like i mean to me this is an
00:26:57.080 | amazing result right like you use minimal compute and get something very close to the same
00:27:02.920 | performance that even even if it's not up to par i'd just be curious to see how it compares
00:27:08.840 | so um two two things one is i think what they're going after here is sample efficiency right so
00:27:18.360 | they want to show how you can do it in a couple thousand samples and two i think we can look at
00:27:25.400 | the um r1 distill so apparently r1 distill is better according to my quick let's ask chachi pt
00:27:35.240 | but it could have hallucinated so yeah i just i just do it it's like r1 distill is better i don't
00:27:45.080 | trust okay so it looks like um they did give numbers i remember this so they used um 600,000
00:27:57.720 | sft also thanks um leah for pointing this out so for the r1 the original deep seek paper they used
00:28:06.360 | 800,000 samples 600,000 sft plus 200,000 reasoning traces and i think they actually yeah they do put
00:28:13.000 | it in the paper here so uh it performed they have benchmarks of r1 distill right there
00:28:18.920 | it's the third row but um sample efficiency you know that's the difference but also the
00:28:24.840 | technical distillation was different right so that is the largest yeah totally not like totally get
00:28:31.560 | uh like this is it's going after something different just one it's an interesting
00:28:36.520 | comparison but i guess i yeah so that distill presumably is that 32b quinn yes it is uh 800,000
00:28:45.400 | samples yeah
00:28:49.560 | um well um do we want to move on to second paper or any other closing thoughts on this one i'm
00:29:05.240 | sure if there's a discussion in chat we can always pop back in but we have a second paper
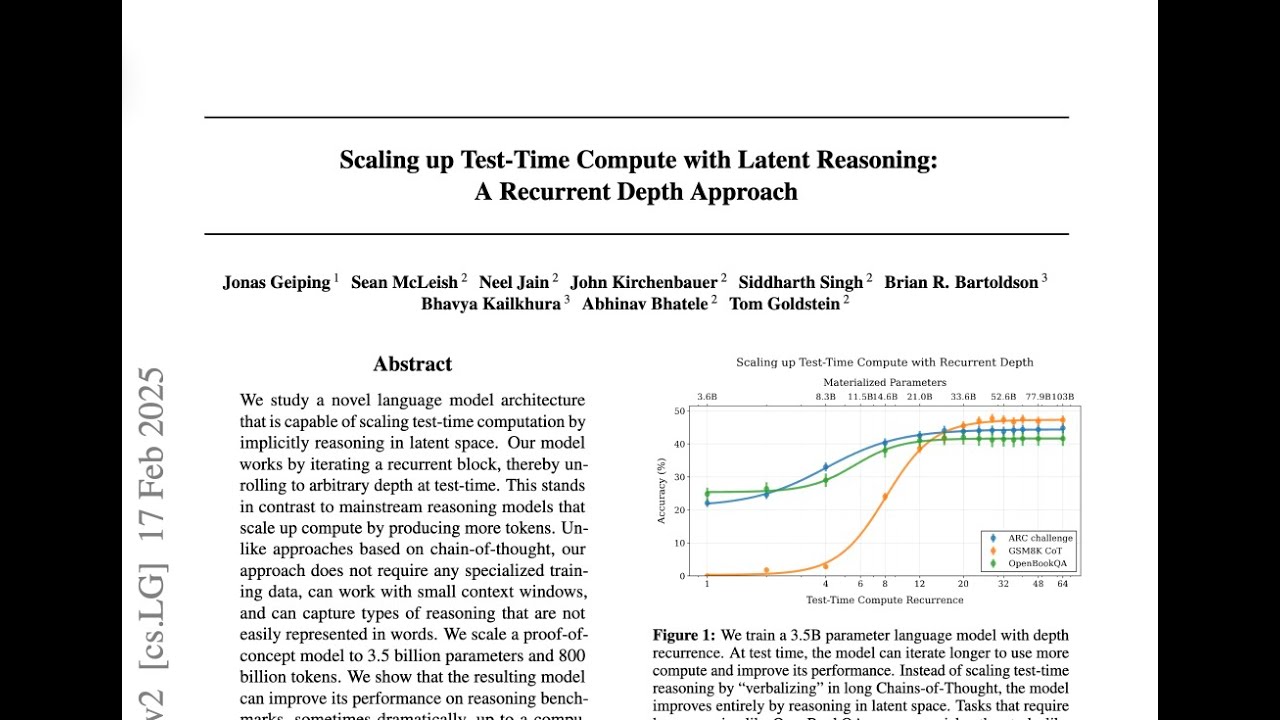
00:29:15.800 | yeah so the second paper is scaling up test and compute with latent reasoning
00:29:24.520 | uh a recurrent test approach so the topic is the same so we want to build the reasoning model but
00:29:30.440 | the idea is that most of the model that we already know generates the reasoning and thinking tokens
00:29:37.400 | in the output right and in that paper they create the architecture which doesn't produce explicitly
00:29:45.240 | tokens in the generation so with things and reason in the architecture itself that's the
00:29:49.800 | main difference so now why do we need that kind of model because uh if you want to generate like
00:29:58.040 | as you can see the latest models like generate thousand tokens in their thinking and reasoning
00:30:02.920 | so it takes a lot of time also you need to have a big context window and which doesn't work for
00:30:10.360 | small models and also as i mentioned there are some reasoning abstractions that you can explicitly
00:30:21.080 | say by words so you need to have some high dimensional latent space where the model
00:30:28.200 | resonating itself in the architecture yeah that's the idea and about the methodology so they create
00:30:36.840 | the architecture so they add some recurrent block in the transformers and the idea is that when you
00:30:44.200 | train the model you run several ties in the loop so as i remember they took random numbers so
00:30:53.320 | sometimes you run three times maybe five times and so on and yeah that's the most of the idea
00:31:01.000 | so they took a 3.5 b model and they train on 800 billion tokens and as i mentioned it is equivalent
00:31:10.680 | like 50 billion parameter models so the result is pretty impressive as well
00:31:15.480 | yeah and as you can see the result in the first case as you run the loops in the test time so
00:31:28.440 | performance increase and for some benchmarks it converts quickly but for gsm8k it has a lot of
00:31:37.720 | improvements actually okay um yeah so uh why why they train the models as i mentioned that
00:31:49.080 | you don't you don't in this case you don't need to have uh the specialized data for the for the
00:31:55.400 | training uh also this technique uh takes less memory memory so idea is that you use a small
00:32:02.920 | model but more compute to increase the performance and yeah as i mentioned it takes more flops
00:32:10.360 | but it's more efficient since you have small models you don't need to have a
00:32:16.920 | communication cost or interconnect and it's much faster as i mentioned
00:32:25.560 | yeah that's the architecture uh yeah there are some uh sections uh the the topics why they use
00:32:34.360 | the embeddings and uh yeah some uh some improvements in the efficiency because
00:32:40.040 | they train this model on amd hardware uh with specialized gpus as i remember and as i mentioned
00:32:48.440 | they uh needed to create some kind of tricks and uh to make some uh fast training
00:32:54.360 | uh yeah so and as the previous paper also they published their pre-training codes
00:33:03.320 | and uh the model and the data okay so uh what they did actually that uh
00:33:12.040 | since they have they don't have a lot of money so they just took some already
00:33:16.840 | published data sets they just create some kind of mix and uh yeah mostly they wanted to test the
00:33:25.080 | model on mass and reasoning tasks so most of the data comes from the holding and mass data sets
00:33:32.200 | and as i mentioned the mixing strategy maybe is not the best but the idea is that
00:33:38.360 | just to test if this module architecture works so um yeah um and they did some uh
00:33:47.160 | they published the parameters hyperparameters uh they did some packing and so on one of the
00:33:54.440 | problem that they have in the training was to uh since it's a different architecture
00:34:01.080 | they mentioned that hyperparameters and the setup uh matters actually so in the first run this is
00:34:09.000 | the the orange they don't have a good performance but after some tweaking like learning rate and
00:34:15.480 | some hyperparameters they get some good results the blue one which is the latest the main model
00:34:23.160 | and yeah loss goes down um and yeah they uh i'm not sure about the the number of loops
00:34:32.200 | but yeah maybe we'll see in the results
00:34:36.520 | and yeah so when i see the results it doesn't look uh very good rather than the previous paper
00:34:47.240 | but we can see some uh some improvements in the in the for loop i think so yeah if you check
00:34:53.400 | the results it's uh it doesn't outperform most of the models actually so they compare
00:35:01.160 | the old models and pythea which is pretty old i think already uh and yeah the result is uh
00:35:09.160 | not so good but uh the main main thing is that performance increase if you include the loop as
00:35:16.280 | well uh but yeah as you can see 49 and 69 for arc easy um yeah and uh
00:35:27.480 | yeah they test on gsm rate k
00:35:43.800 | and yeah also one thing is that they check if uh if this architecture um emerged some ability
00:35:52.840 | like for example a chain of thought and some skills that we know for the other lens right
00:35:57.960 | so they test those ideas and see that this architecture works also for uh with the context
00:36:05.000 | so if you give some for example few short examples it improves the performance so just to test the
00:36:11.640 | idea that it doesn't goes wrong for for other ability uh yeah they publish some early checkpoints
00:36:20.440 | as well and uh yeah as you can see performance goes up uh there was yeah also they compare the
00:36:34.200 | baseline so baseline needs to take the same data set uh and run just uh with the base training
00:36:42.920 | technique and without those architecture and uh yeah as you can see performance uh is much better
00:36:49.240 | as well so for example 46 and 69 i think this is a good result uh because we know that with the
00:36:57.480 | same data set with the um same compute let's say you get much better performance and also they
00:37:07.400 | compare with r equals one and yeah actually it's the less performance than the baseline
00:37:14.360 | that's another uh interesting thing as well yeah they uh checked a few short examples and as you
00:37:22.280 | can see if you use the zero shot it converged quickly but if you use uh more shots yeah
00:37:29.480 | performance goes up which is good
00:37:31.080 | yeah so in this case they uh check that uh model uh uh needs more uh loops in the architecture
00:37:47.560 | uh when the problem is complex let's say so it's like uh for example high school mathematics
00:37:54.840 | needs uh five loops but uh logical or moral scenarios need much more let's say 20 or 25
00:38:04.360 | uh yeah some of the inference time loops are kind of interesting so rj asked about the recurrent
00:38:14.600 | backprop so they have this little section here in chapter four on recur uh truncated backdrop
00:38:21.160 | backprop where i think they truncate everything except for like the last eight or something and
00:38:28.680 | then so what that allows is you can still have somewhat efficient training but at inference
00:38:34.600 | time you know the thing can still like roll out its internal thought for as long as it wants
00:38:41.080 | but they they have a little section somewhere i think it's in chapter section four on truncated
00:38:45.320 | backdrop but um efficiency training wise that helps
00:38:51.560 | right but but for like if i think it was saying like it did they did they truncated it like eight
00:39:01.240 | eight loops or whatever but doesn't that mean that like for those eight loops you can't
00:39:07.720 | parallelize right like you have to do one after another
00:39:11.160 | yeah i think which i mean i understand if you truncated it some number then you're limiting
00:39:19.560 | the impact of that but still uh that will that will i don't but i'd be curious to see like the
00:39:27.000 | impact overall of those layers that are recurrent um what's the impact on the training efficiency or
00:39:34.680 | speed yeah it was the eighth
00:39:41.000 | is there any question or my internet oh sorry when people join they're just unmuted so
00:40:03.880 | okay
00:40:04.380 | yeah um there is another question in chat though how does it choose the depth would it make sense
00:40:13.720 | to recur until the stop token slash signal is output do you want to kind of explain what this
00:40:19.000 | internal thinking is doing and how it works uh so actually in the training they took some random
00:40:28.760 | numbers i'm not sure why they did that because actually it can be
00:40:33.320 | let number parameter because you don't know the complexity of the
00:40:37.720 | data right so you cannot say the exact number of the loops in the pre-training
00:40:43.800 | but uh yeah actually it works and uh yeah i'm not sure
00:40:55.080 | yeah as i mentioned this uh the recurrent work is not the novel idea we know a lot of papers
00:41:01.560 | we did the same kind of things but yeah as i mentioned some ideas should be rediscovered
00:41:07.720 | sometimes so yeah but i i like that idea especially for small models i mean you
00:41:15.240 | don't have a lot of context size and uh yeah that's interesting at least so
00:41:20.680 | i think at a high level as well we have to remember what they're doing right they're
00:41:24.600 | training a 3b from scratch on 800 million billion samples billion samples uh it's very proof of
00:41:34.040 | concept right so there is uh ways where you can synchronize recurrent depth and parallelize this
00:41:41.480 | stuff but this is more show just a more so the proof of concept to show that this works and it
00:41:46.600 | this is more show just a more so the proof of concept to show that this works and if we should
00:41:51.000 | scale it up the other thing we've seen with a lot of um recurrent networks and state models is
00:41:57.560 | you can do conversions so even if they're not peak efficient you can convert quen to this style
00:42:05.000 | by you know replacing layers and adding stuff so all optimization stuff kind of comes a little bit
00:42:11.560 | later but um there there is stuff like this i know in cuda but they probably got some amd
00:42:18.280 | compute sponsorship to train this on mi 300xs which is cool now i don't know if they would
00:42:24.040 | write all that in the paper because it's not applicable for everyone but just that's a little
00:42:28.280 | bit of high level too yeah okay any other questions or comments
00:42:41.880 | actually they mentioned that it's equivalent to 50 billion but i can't see that in the results
00:42:53.960 | because in the result they compare only for uh
00:42:56.200 | for all normal models which is 7 billion
00:43:03.560 | so
00:43:28.120 | okay i think that's it yeah there was a lot of other sections but i think the idea
00:43:36.680 | was to create a different technique rather than explicitly generate the output token
00:43:43.000 | which is interesting at least in a different kind of architecture so i think it works to test
00:43:50.680 | maybe you'll see the other paper that do the same so that's why i i like that paper just
00:43:59.800 | to understand other kind of techniques rather than the generation and so on so awesome well
00:44:07.720 | thank you so much for volunteering to present we have any other questions on these two we still
00:44:13.160 | have a little bit of time um so scaling up test time compute was more so how we do internal reasoning
00:44:20.200 | if we don't want to externally spit out this reasoning can we have a recurrent state piece
00:44:26.760 | in our model that's kind of what recurrent networks used to do can we can we train this
00:44:32.120 | to internally think and then s1 was basically can we get really good sample efficiency for
00:44:38.760 | reasoning tokens and yeah hopefully they show pretty good promise
00:44:46.280 | yeah actually this is pretty different but yeah the idea is the same
00:44:50.840 | okay um how does it decide to stop iteration on a token um in the inference right
00:45:11.560 | i'm not sure actually
00:45:12.840 | maybe you control the loop not it doesn't decide itself no i think it does because if you look on
00:45:25.080 | page 31 there's a in the appendix there's a one of these heat maps um and it shows it for
00:45:34.520 | different tokens it's inferencing for different numbers of steps yeah for different tokens
00:45:42.920 | yeah so basically it's trained to keep doing this but we only back prop on eight steps but that
00:45:53.000 | doesn't mean that it can't unroll the amount of iterations it wants to do it's it's internal in
00:45:58.600 | the model or maybe i'm reading this wrong maybe this is 64 steps and it's just oh yeah this is
00:46:04.280 | the log is like the convergence time oh yeah okay so this is so maybe it does you just do configure
00:46:11.720 | it to reason for a certain number of steps and whatever that is yeah that makes that makes more
00:46:17.320 | sense okay got it okay um very very cool papers pretty pretty interesting to see other reasoning
00:46:38.200 | stuff um so we have we have a few more minutes um anything else anyone wants to bring up or
00:46:44.600 | should we talk about next week's paper okay well we'll end a little early and go straight into
00:46:58.520 | next week's stuff uh thank you so much for presenting by the way we always like
00:47:03.160 | volunteers if anyone wants to volunteer i think um next week i'm doing one then the week after
00:47:10.920 | we should have an opening so if there's anything interesting anyone wants to do feel free to you
00:47:16.200 | know volunteer and then we can we can get that worked out but yeah thank you so much for presenting
00:47:22.360 | last minute we kind of switched up uh paper so sorry for people that didn't get a chance to
00:47:29.480 | pre-read it's always nice to be able to pop in but you know you always get most value if you
00:47:34.600 | do some basic pre-reading come with your questions and then we can discuss them
00:47:38.920 | so that's kind of the whole point of it um for next week hugging face put out this um
00:47:45.640 | pre-training guide so it's kind of everything about scaling up llms and they go very in depth so
00:47:53.160 | it's it's a very long one i'm hoping hoping we can get it done in an hour but you know it starts
00:47:59.080 | with how do we train on one gpu multiple gpus um how do we do moes like what is training configs
00:48:07.880 | basically everything you would want to know about training and scaling up models so i will go
00:48:14.520 | through this and condense it down to what's a tldr of this probably like eight hour reading how can we
00:48:22.680 | condense this down into like you know high level overview 45 minutes of chat and then five minutes
00:48:29.720 | of q a but a very very good resource i will share it back in zoom um i think you know come prepared
00:48:38.920 | and just read over the sections you find interesting if you have any questions come with
00:48:44.200 | questions i'm sure this will be one where zoom chat will be very very active since it's basically
00:48:49.880 | a book but um that's the paper for next week yeah i started reading but it's a huge it's huge it's
00:48:58.120 | huge uh thomas wolf the one of the co-founders at hugging face apparently he also did a walk through
00:49:03.000 | on youtube so if you guys like side content want to listen to it there's a youtube version where
00:49:08.760 | he goes through this for quite a while but yeah next week um maybe just brush up on that i'll
00:49:15.160 | try to have something in an hour that we can go through and then it'll be good for q a you know
00:49:19.080 | well we'll have about like 100 people here that are all somewhat versed on the topic but yeah
00:49:26.840 | cool thanks everyone yeah run thank you take care