Stanford CS25: V3 I How I Learned to Stop Worrying and Love the Transformer
00:00:00.000 | [BLANK_AUDIO]
00:00:06.980 | Do folks still have, what is this?
00:00:08.740 | [BLANK_AUDIO]
00:00:10.860 | There's a Stanford, that's a Stanford location.
00:00:13.560 | [BLANK_AUDIO]
00:00:15.820 | You know which one?
00:00:16.960 | Well, first, what is this?
00:00:18.480 | [BLANK_AUDIO]
00:00:20.500 | What was going on here?
00:00:21.200 | >> It's the first Dartmouth in Alabama.
00:00:23.740 | >> That's right, yeah, and then what does the association to Stanford get?
00:00:27.420 | [BLANK_AUDIO]
00:00:30.300 | >> I believe this is the McCarthy, yeah, who started at sale, if I understand
00:00:35.580 | correctly, is that right, he started at sale?
00:00:38.900 | Yeah, I think he did, but anyways, so what's interesting is,
00:00:43.900 | so it's amusing to actually look at what they wrote in their,
00:00:48.780 | I don't know, is it brochure or what they wrote in their goals, right?
00:00:54.900 | So, this font is a bit small.
00:00:57.700 | Okay, so the study is to proceed on the basis of the conjecture that every aspect
00:01:02.460 | of learning or any other feature of intelligence can in principle be so
00:01:06.660 | precisely described that a machine can be made to simulate it, right, fantastic.
00:01:11.540 | So single machine, you wanna simulate all of human intelligence, okay.
00:01:16.300 | And carefully selected group of scientists, and we think that we can make,
00:01:20.960 | actually, the paragraph right before the second set of red underline,
00:01:26.040 | is we think that a significant advance can be made in one or two of these problems.
00:01:31.840 | If a carefully selected group of scientists work on together for a summer, okay.
00:01:38.080 | I don't think they knew of AI winters then actually, they didn't know of it then.
00:01:42.560 | But, and the third thing is amusing is, but
00:01:46.440 | the major obstacle is not lack of machine capacity, but
00:01:50.360 | our inability to write programs taking full advantage of what we have.
00:01:53.880 | >> So, while the goals are noble, it's surprising how wrong you can be with some
00:01:58.280 | of the smartest people in the room, right?
00:02:00.120 | So Selfridge, a neural network OG that were the original pandemoniums,
00:02:05.200 | I think he got everything basically set for path problems in black box optimization.
00:02:09.320 | Then Minsky, of course, Shannon, Solomonoff, I think it was Solomonoff, MDL.
00:02:16.720 | In many ways, you can argue that's the underpinning of
00:02:21.160 | self-supervised learning today.
00:02:24.320 | But it's really amusing to see the first, I mean, at least I don't know if we'll
00:02:30.160 | be able to characterize or write down all the rules for intelligence.
00:02:35.680 | So you can imagine that the approaches they were taking were all these rule-based
00:02:39.160 | systems, right?
00:02:39.960 | And they couldn't be more wrong on machine capacity.
00:02:44.240 | Today's transformers, they don't, they're data centers, right?
00:02:48.440 | And I guess they needed a really, really long summer to solve this one.
00:02:55.440 | But yeah, so it's 1955, so yeah, like about 60 years.
00:03:03.960 | No, not even, I'm getting close to 70, 70 years, right?
00:03:06.600 | So, and we're basically talking about the same problems again,
00:03:11.920 | except maybe some things work, some things don't work.
00:03:16.840 | And this talk is about some of the, one of the pieces that has made this larger
00:03:22.920 | enterprise work, and we're getting closer to the original goals of the
00:03:27.800 | Dartmouth conference, yeah.
00:03:29.760 | Again, okay, so this is like the big gaps.
00:03:32.760 | I mean, so what eventually happened in the field was that their goal of having a
00:03:36.720 | single system that explained most of, that was able to mimic our cognitive
00:03:42.960 | abilities, which would definitely mean like image processing or image
00:03:46.480 | understanding and language processing as well, right?
00:03:48.800 | That, I mean, the field got, I mean, a single model or a single approach to do
00:03:54.560 | all these things was shattered by like thousands of like different research
00:03:58.640 | products.
00:03:59.040 | So, I mean, there was no consolidation, but here's another, here's another,
00:04:02.760 | here's another, this is going to be a harder one.
00:04:06.240 | Can you tell what is a, this is, this is 2009, and this is a, and this is not a
00:04:10.760 | single system.
00:04:11.440 | This is a complicated machine translation system.
00:04:13.760 | So when I started my PhD, our machine translation systems used to be a bit more
00:04:17.040 | complicated, complicated than this, actually.
00:04:19.640 | Thousands of pipeline systems, you had to first extract, you had to first do word
00:04:23.880 | alignments that actually looked like attention as like art.
00:04:27.000 | You think about it as hard attention, then based on that, we extracted like all
00:04:30.120 | larger phrases aligned with other phrases.
00:04:32.320 | Then you had to figure out how they then had to, then you had to teach, there was
00:04:36.240 | some machine learning there, you had to teach the model how to score them
00:04:38.840 | connecting with each other.
00:04:40.040 | So can you tell, can you, does anybody know where a neural network is in this?
00:04:51.280 | All right.
00:04:51.880 | So CS, so this is the, this is a machine translation system from 2009, and CSM is a
00:04:58.200 | continuous state language model.
00:05:00.840 | That's used for rescoring, right?
00:05:03.480 | So the world was so discreet then that he had to call these models like continuous
00:05:07.160 | state language models.
00:05:08.240 | And, I mean, it was a lot, it was largely inspired by the neural probabilistic
00:05:11.800 | language model by, oh, it doesn't appear.
00:05:15.240 | Huh.
00:05:17.920 | Sorry.
00:05:20.200 | Ah, there.
00:05:20.880 | The neural probabilistic language model by Benjy, I think it was in 2003.
00:05:26.040 | And so we were, even in 2013, when I published a paper on neural network language
00:05:33.880 | models, these models were still being put into the fee for neural network language
00:05:40.280 | models was still, you know, rescoring.
00:05:42.240 | And now it's incredible if you think about it.
00:05:45.360 | So just in terms of consolidation, how all of these complicated systems that have now
00:05:50.360 | been replaced by just neurons that talk to each other, and you just learn the rules
00:05:53.840 | from, you just learn the rules from data automatically.
00:05:56.640 | So it's fun to, it's interesting to see.
00:06:02.400 | And so since then, you know, like, so this is what the EMLB 2013 conference was like.
00:06:10.200 | You see these different, like these, you can call it verticalized NLP, these
00:06:15.360 | different areas like morphology, dialogue, and discourse.
00:06:19.080 | I mean, I don't even know if people talk about dialogue and discourse.
00:06:22.560 | There's talk to models now.
00:06:23.680 | There's, I don't know if there's a research track anymore.
00:06:25.760 | Then there is like a machine translation.
00:06:27.360 | So there's opinion mining and sentiment analysis.
00:06:30.080 | Now models make you angry or upset.
00:06:32.960 | So it's, and so you could see that just in 2013, the field, even research was divided
00:06:39.440 | into these smaller tracks and everybody had their own specific, they were bringing their
00:06:43.200 | own specific domain information.
00:06:46.880 | And they had to specialize in a domain in order to solve some tasks.
00:06:50.160 | And we solved tasks to some degree.
00:06:51.800 | Machine translation, because, I mean, probably because of a lot of government funding as
00:06:56.280 | well, we had made a lot of progress and we were making practical translation systems
00:06:59.760 | that were being deployed in the wild.
00:07:01.840 | Google Translate was a great example of that, right?
00:07:05.600 | And so since then, you're like, you have this, you know, we started to, through first, first
00:07:12.040 | we all agree, we need distributed, we need distributed word representations.
00:07:15.400 | And you saw this, like, people probably don't know this funky, this funky embedding algebra
00:07:20.800 | of king minus man plus woman equals, equals queen from word2vec.
00:07:27.000 | And we had a, we had a, and there was a, there was a, there was a big industry of models
00:07:34.000 | that actually, that just, that learned word representations and the word representations
00:07:38.160 | are actually useful in downstream tasks.
00:07:41.040 | And then, then came like, you know, another step in this process.
00:07:45.380 | Another step in this process where now we started saying, okay, these representations
00:07:49.600 | are like in there, but they're, they're, they're only helpful if they're learned in context,
00:07:54.120 | right?
00:07:55.120 | So the king should change based on context, like the, the, the, the king of Persia, or
00:08:00.000 | the king has no clothes, or the emperor has no clothes, right?
00:08:03.840 | And so, so, so that, so we saw these, we saw approaches like sequence to sequence, sequence
00:08:09.120 | learning where we started to like formulate, we started to create these general formulations
00:08:14.860 | of how to solve any task in NLP, right?
00:08:18.360 | So sequence to sequence formulation, if you can, you can, you can, you can formulate many
00:08:22.040 | tasks in language of sequence to sequence, question answering, machine translation, dialogue.
00:08:27.400 | So, and then, and then of course we had, then we, then we developed attention, right?
00:08:31.680 | Which was a, which was a very effective content based way to summarize information.
00:08:37.000 | If you were a, typically you have these encoder decoder architectures, everybody has probably,
00:08:41.560 | I'm guessing, familiar with encoder decoder architectures, right?
00:08:44.300 | So yeah, encoder decoder architecture and a, and a, and a position on the decoder side
00:08:48.540 | would summarize based on its content, all the information on the, on the source sentence,
00:08:52.740 | right?
00:08:53.740 | And this was really effective content-based way of summarizing information.
00:08:56.580 | And what, what started happening was we started these, these general, these general paradigms
00:09:02.060 | started coming up.
00:09:03.860 | Sequence to sequence learning can solve, it can install most language problems because
00:09:08.220 | most language problems have to deal with learning representations of variable length.
00:09:12.100 | The goal is to learn representations of variable length sequences.
00:09:14.740 | And if you do that successfully, you can then potentially solve that problem.
00:09:18.280 | And then attention was an excellent way, a content-based way to actually summarize information
00:09:23.220 | from some neighborhood.
00:09:25.060 | And and, and, and, and so, so, so, so, and the, and the major workhorse until then were
00:09:30.500 | these recurrent models or LSTMs, right?
00:09:33.780 | Where basically the, the, the, the method was typically the same.
00:09:37.820 | You had a, you had a sentence and you crushed the sentence into a, into a set of, into a
00:09:41.980 | set of vectors, set of representations, one typically, typically one for each position,
00:09:46.860 | right?
00:09:47.860 | And the way LSTMs did it was where they walked along the sentence, they ate up a word, and
00:09:52.260 | then they summarized, they summarized the entire history into one fixed bottleneck.
00:09:57.500 | And that bottleneck was then transmitted, was updated based on the next word.
00:10:01.020 | So, so, so now, and, and, and, and if we, if you were successfully able to learn representations,
00:10:07.360 | then we could solve these tasks, translation, summarization, dialogue.
00:10:09.620 | So it's an important movement and, and, and, and like the 20, 20, I, I, 20, I guess when
00:10:14.580 | was the sequence to sequence learning papers, 2015, NeurIPS, then we saw, then we saw the
00:10:19.140 | attention paper in around 2015, 2016, and the machine translation community was kind
00:10:23.440 | of the first to respond and say, hey, yeah, you know, machine translation is a classic
00:10:27.660 | sequence to sequence learning problem.
00:10:29.540 | Like why don't we now first start rescoring?
00:10:31.860 | And then can we still build native, greeny, rethink machine translation with the sequence
00:10:35.780 | to sequence models, right?
00:10:38.500 | And these are fantastic models.
00:10:39.780 | I don't know if you guys have ever done these exercises on LSTMs can, can count, like if
00:10:45.260 | you, if you, for example, if you, if you train an encoder decoder on, if you, like on A,
00:10:50.980 | to model A to the N, B to the N. So you feed in NAs and you ask the decoder to predict
00:10:55.020 | N, NBs, and you actually, just a single cell LSTM, if you know the structure of an LSTM,
00:11:01.380 | there's a cell that basically keeps, so it's a, it's a notion of state, and just a single
00:11:05.700 | cell is able to actually just do trivial counting.
00:11:08.980 | It counts how many A's you consumed, and then it decrements it, and then when you consume
00:11:13.820 | all the, exactly the same number of B's as the number of A's, something lights up and
00:11:17.620 | says, I'm done, I've recognized this language, so you can train trivial A to the N, B to
00:11:20.860 | the N.
00:11:21.860 | And here, you have a, I'm sorry, this is not clear, but you have somewhat of a, you have
00:11:26.140 | a grammar here, and you can see that these are different cells, there's about eight cells
00:11:29.740 | here, and each one of these cells actually increments its counter once it feeds a particular
00:11:34.060 | symbol, and it's able to actually track how deep you are in this, how deep you are in
00:11:37.980 | this hierarchy, in this grammar.
00:11:40.020 | And Google, of course, the crowning achievement, perhaps, of sequence-to-sequence models, which
00:11:47.740 | I was actually, right, I was fortunate to be in the same cuticle as this work was being
00:11:55.340 | done, was the Google neural machine translation system, where they took LSTMs, I mean, they
00:11:59.940 | added many advancements, of course, a lot of systems improvements, a lot of data that
00:12:04.700 | Google had, and they produced what you might, at that time, the state-of-the-art neural
00:12:09.540 | machine translation system, sequence-to-sequence models.
00:12:12.020 | So now, this big consolidated, this big complicated system, which looked much, which looked much
00:12:17.380 | more complicated, and now become a homogenous, just as a single homogenous neural network,
00:12:22.820 | right?
00:12:23.820 | So at the time, the biggest frustration we had was, this was, I mean, these, the LSTMs
00:12:29.620 | were the primary workforce, and the biggest, the biggest frustration we had was, I mean,
00:12:36.100 | not only were we producing, not only were we, did we produce the output order aggressively,
00:12:41.420 | we were sequentially decoding the output, left to right, but also, we were reading the
00:12:45.500 | input sequentially.
00:12:46.500 | So you had to kind of, in order to produce that, in order to produce that representation
00:12:49.980 | for the 10th word, you had to eat up, you had to, the first word, the second word, the
00:12:53.820 | third word.
00:12:54.820 | So that was, that was really slow, and, and, and, and, and, and, and, and not the whole,
00:12:59.580 | and another big problem with LSTMs were that you have this bottleneck that basically, that
00:13:05.740 | contains all the information about your past.
00:13:08.340 | So you have to now, you have to now crush, you have to, you have to pack both long distance
00:13:12.820 | interactions that you might have, and local interactions through the single, single fixed
00:13:17.100 | vector that you need to transmit, right?
00:13:19.200 | And, and sequentiality, it doesn't, inhibits parallelism, which means that you couldn't
00:13:23.940 | even read, like the encoder couldn't even read the sentence in parallel, and of course
00:13:28.220 | decoding was autoregressive, so you couldn't even write in parallel, right?
00:13:32.620 | And convolutions, they were starting to emerge as a solution largely. I mean, they had been
00:13:39.100 | very successful in-- they had been very successful in computer vision. They had also figured
00:13:43.220 | out how to optimize them well, how to make them really fast on GPUs, because they're
00:13:50.340 | just basically matrix multiplications. And matrix multiplication is largely-- it's parallelizable.
00:13:55.980 | So convolutions were a solution to this problem of not being able to read in parallel, because
00:14:03.300 | you could-- in parallel, every word could basically produce its representation by looking
00:14:08.340 | at its neighbors, its local neighbors. And there were some breakthrough papers, such
00:14:16.380 | as Bitenet for machine translation, the convolutional sequence-to-sequence model that was contemporaneous
00:14:22.020 | to the transformer, actually, probably predated by a few months, where they used convolutions
00:14:26.260 | both in the encoder and decoder to get good scores on machine translation that were better
00:14:31.180 | than the Google neural machine translation system. And of course, probably the most successful
00:14:39.780 | was Bitenet, which was a text-to-speech system that was state-of-the-art at the time.
00:14:45.260 | And again, so convolutions still have this problem that, one, I guess they were parallelizable,
00:14:53.940 | but the issue was that you still-- you couldn't directly capture long-distance interactions
00:14:59.880 | between-- you couldn't directly capture long-distance interactions between words. So if you're
00:15:04.860 | basically a receptive field, if it's like a 3 by 3, if it's a 1 by 3, then it basically
00:15:10.620 | grows linearly, either with the factor of-- it grows linearly with the number of layers
00:15:15.860 | each time it expands by 3. So you still needed a linear number of layers to capture these
00:15:22.020 | long-distance relationships. But attention, on the other hand, was this really effective
00:15:26.500 | mechanism that we knew was-- that could actually get-- in one, it could actually capture all
00:15:34.660 | the interactions between one word and every other word using content-based addressing.
00:15:40.780 | Because convolutions basically match-- convolutions match weights with parameters. Attention was
00:15:45.540 | actually able to use content with content. So based on how similar I am to my neighborhood,
00:15:49.820 | based on how similar I am to my neighbors, I'm going to absorb that information. And
00:15:54.420 | this motif actually appears everywhere, even in computer vision.
00:15:58.340 | So maybe, actually, I can go there. So here's a-- in vision, there is this approach-- do
00:16:05.460 | people here know non-local means? So in computer vision, there's an approach called non-local
00:16:11.940 | means that's basically-- it was originally developed for image denoising. So if you want
00:16:18.380 | to denoise an image patch, you look at all your neighbors, and you see which patch is
00:16:23.460 | very similar to you. And based on the similarity, you actually pull in that information. And
00:16:27.980 | this largely works in images because images are very self-similar. This starts sounding
00:16:31.980 | like, hey, based on content, I want to pull in information. And again, there were similar--
00:16:36.740 | there were approaches like texture synthesis by EFROS, where if you wanted to-- if you
00:16:41.960 | wanted to do painting, or if you wanted to generate an image, then you would look at
00:16:45.640 | a patch that's similar to this rectangle in some other-- in your dictionary, or in a database
00:16:51.740 | that you have of patches. And then based on what's closest to it, you actually bring it.
00:16:55.940 | So you'll bring that patch, and then you'll paste it there. So these approaches that looked
00:16:59.580 | like attention were already prevalent. It's a very natural formulation. And the Baden-Auwe
00:17:08.460 | paper had shown that this actually works really well for language as well.
00:17:12.180 | So the question then was, OK, why can't we then learn representations? Instead of being
00:17:17.220 | this source target, why can't we actually learn representations by the sentence attending
00:17:21.740 | onto itself? So now you basically use-- instead of attending a source sentence, attending
00:17:26.900 | to a target sentence, can it just attend to itself?
00:17:29.260 | And the original goal of actually when we wanted to actually do parallel decoding--
00:17:36.420 | so attention by construction is parallelizable, because each token can basically construct
00:17:44.340 | its representations from its neighbors in parallel, right? And it directly captures
00:17:49.900 | token-to-token interactions, because now, of course, we'll run into complexities of
00:17:54.420 | length, but we can-- and we'll discuss how to solve some of these things later, how to
00:17:59.580 | overcome them. But you can direct-- instead of having this sort of linear growth in receptive
00:18:03.220 | field, you can directly capture these interactions.
00:18:05.620 | Because convolutions, if you have a very, very large receptive field, it gets computationally
00:18:08.660 | very expensive. And it also had these explicit gating and multiplicative interactions, which
00:18:12.740 | we've often seen, like, in gated-pixel CNN or GeLUs. These explicit gated-multiplicative
00:18:20.220 | interactions have typically helped training and have led to better accuracies.
00:18:26.420 | And as I mentioned, the original motivation of why we actually wanted to do this was,
00:18:31.300 | we said, hey, OK, so the LSTMs are-- we have good translation systems, but the problem
00:18:37.340 | is that actually, both reading and writing sequentially, can we actually do both in parallel?
00:18:42.820 | So we wanted to read-- we wanted to read the German sentence in parallel and then translate
00:18:47.540 | it in-- and then also write in parallel by that, instead of actually decoding it sort
00:18:52.180 | of autoregressively, can you decode it-- instead of decoding in time, can you decode it in
00:18:56.500 | height?
00:18:57.500 | So, like, you first spit out one word, or you spit out all the words, and you iteratively
00:19:01.000 | define them, right? And this was-- this turned out to be very, very challenging and hasn't
00:19:07.260 | been solved successfully until today. Because the biggest challenge, essentially, is when
00:19:11.580 | you-- whenever you're decoding, right, essentially, as you predict a word, you kind of bend the
00:19:15.100 | probability distribution that then nails down-- narrows down what you're going to predict
00:19:19.540 | later on. And the ordering that allows you, basically-- the ordering that allows you to
00:19:25.340 | nail these modes was very hard to learn. So imposing a left-to-right ordering is much
00:19:30.500 | easier than actually not having one and having to learn it as you're decoding.
00:19:34.740 | So the original approaches didn't work, but then we still had-- we still had-- we still
00:19:40.140 | had our salvation in being able to read it parallelly. So we said, all right, let's take
00:19:43.700 | this back to the encoder-decoder models. And unlike-- at that time, there were a few formulations,
00:19:50.700 | right? So we had this sort of-- the original formulation of attention from graves, then
00:19:55.780 | we had the additive attention formulation, and we took the-- and we took the dot product
00:20:00.020 | attention formulation, largely because it allowed us to do-- it-- because it allowed
00:20:05.940 | us to actually do attention as a matrix multiplication. And oftentimes, some of the biggest constraints
00:20:11.340 | that actually-- physics is such a big constraint in neural networks that if you can-- if you
00:20:17.220 | can make your-- if you can make your architecture amenable to modern accelerators, you have
00:20:22.660 | a much better chance of-- you have a much better chance of succeeding. And dot product
00:20:26.820 | attention could be expressed as a matrix multiplication, and it's-- and there are already sub-- there
00:20:31.260 | are already kernels for being able to do matrix multiplication very effectively on the GPA.
00:20:36.300 | So we had-- so the formulation was, all right, so now we have-- similar to the dot product
00:20:40.500 | attention, we had a scaling factor, simply because if the dot product actually becomes
00:20:45.140 | too big and you can solve it under certain assumptions of mean and variance in the representations,
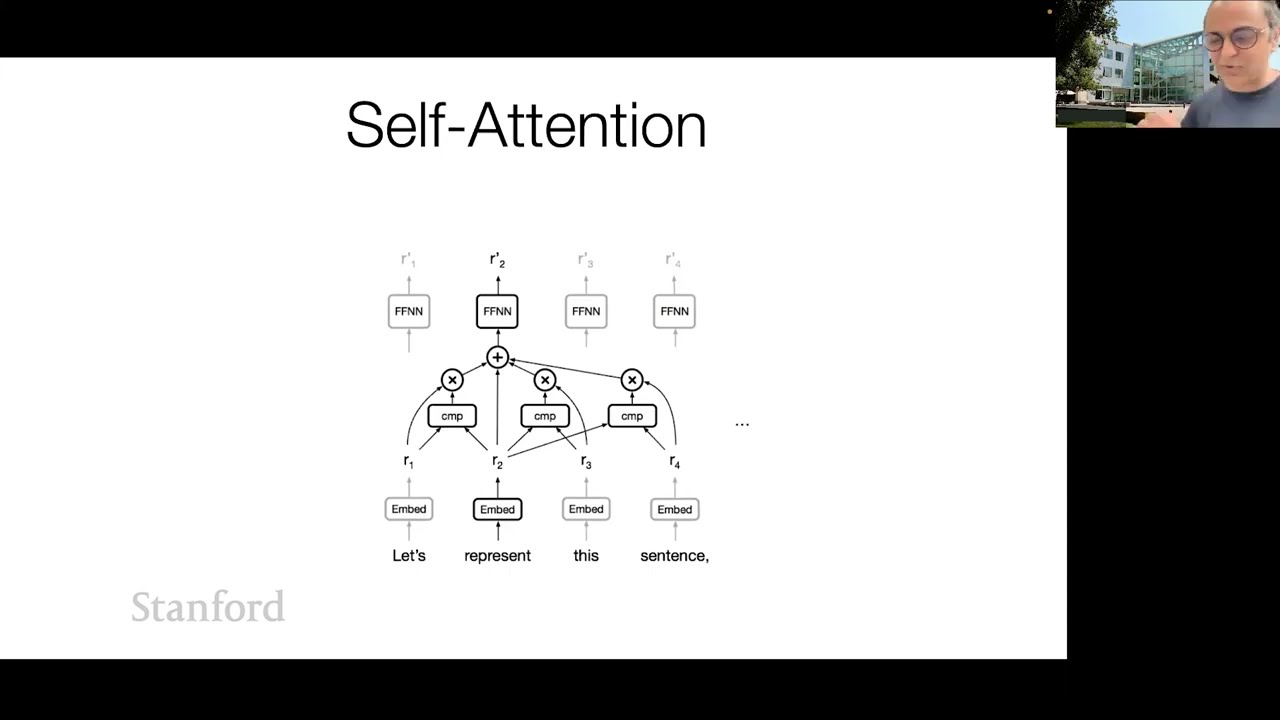
00:20:50.860 | you can-- it hasn't updated, actually. Yeah, so our formulation is basically you have--
00:20:58.420 | you now have your queries, which-- what you end up doing is if you have a-- if you have
00:21:04.740 | a position, you first project it into queries, and then the same-- the same token-- the same--
00:21:10.500 | the representation of the same token gets projected into-- to also keys and values.
00:21:14.740 | And the first-- the query determines how much-- how much you're actually going to pull from
00:21:20.780 | all these keys. So you first do a dot product of the query with every key, and then based
00:21:25.380 | on that, you combine or you pool the content of-- in all these positions based on-- based
00:21:30.820 | on what the-- based on what the score was after-- after normalizing and using a softmax.
00:21:34.980 | So in some sense, you can think of self-attention also as kind of a content-based pooling mechanism,
00:21:41.860 | right? And the scaling factor basically avoids you-- avoids you-- like, it saved us from
00:21:47.260 | these logits actually blowing up and training becoming unstable. And on the decoder side,
00:21:52.820 | you could trivially-- you can trivially implement causality by just adding an-- adding an attention--
00:21:58.260 | adding an attention mask. And what this-- where this-- where this brings us is that--
00:22:03.620 | all right, so-- so now we've-- we've solved-- now there's-- it's-- so a caveat on the flops.
00:22:09.260 | We'll actually cover this later. But now what we have is a mechanism that-- that's parallelizable.
00:22:14.340 | It gives you direct-- it gives you direct content-- it gives you direct token interactions
00:22:19.500 | that will-- and that-- that we-- that we assume-- that we believe is going to help you actually
00:22:22.940 | learn-- model these relationships between the words better. And it's-- and it's-- and
00:22:26.500 | the complexity of self-attention is faster than convolutions, right? Because it was--
00:22:30.100 | because convolutions are quadratic in the number-- they're quadratic in the number of
00:22:34.420 | channels and the number of-- in the hidden dimension, but a self-attention is quadratic
00:22:37.660 | in the length. So if your length is not much more than a hidden dimension, you've actually
00:22:40.500 | saved on flops. Now this is a-- not-- not quite a complete picture because not all flops
00:22:45.860 | are equal, and we'll talk about this later on. And-- and-- and-- and now when you put
00:22:52.060 | it-- when you put everything together, what we-- what-- basically, we-- we kind of took
00:22:56.060 | the-- the-- the-- the-- the basis-- this has a very strong similarity to the-- to the ResNet
00:23:01.260 | architecture, actually. So if we look at ResNets, right? So in ResNets, you have contraction,
00:23:06.260 | you have spatial mixing with convolutions, and then you have the expansion again, right?
00:23:10.380 | If you just-- the transformer, if you just adjust, if you just move it one-- one step
00:23:14.580 | down, it's very-- it's analogous. You have-- you have attention, then you have expansion
00:23:17.980 | and contraction, but it is a-- and-- and the difference in where the residual connections
00:23:21.940 | are, but it's a-- it's a very similar-- it's a very similar sort of basic building block
00:23:25.940 | with, say, the residual-- with the residual connections, and you have these contractions
00:23:29.540 | and expansions. And in the transformer, those were-- there was multi-head attention with
00:23:34.660 | expansion and contraction, which was in the feed-forward layers. And with-- and-- and
00:23:39.020 | then one-- one-- one challenge with the tension, we loo-- LSTMs can count, they can impact,
00:23:44.220 | they can-- they can-- they can-- they can count-- they can learn interesting temporal
00:23:49.100 | patterns, but attention is permutation-invariant, so we had to actually add position-- we had
00:23:55.940 | to add position information so that we could-- we could learn ordering. So we add position
00:23:59.860 | information at the input, which trans-- gets transmitted to the other layers through--
00:24:04.580 | through the-- through the residual connections. And the-- the original paper, we had those--
00:24:09.500 | we had post-layer norm, but later on, we realized that as we actually make the model deeper,
00:24:14.660 | post-layer norm is-- doesn't-- doesn't allow you to train effectively, so we have to--
00:24:18.620 | then we did-- then we used a pre-layer norm formulation, which was also observed in the
00:24:22.380 | original ResNet papers.
00:24:24.780 | And so the model is basically, all right, you've got your input, well, you have spatial
00:24:29.940 | mixing-- spatial mixing through attention, three, four layers, and this sort of repeats.
00:24:34.900 | And the-- the difference in-- on the decoder side is that you also now have encoder-decoder
00:24:39.780 | attention and encoder-decoder attention at every-- at every-- at every layer. If there's
00:24:46.380 | any questions, yeah.
00:24:47.380 | Yes, what was your question behind the [INAUDIBLE] post-layer norm?
00:24:51.500 | Oh, so-- so it ended up-- so if you do post-layer norm, then-- then--
00:24:57.860 | actually, Liz-- Liz, do I have that slide? Let me check. Probably I've deleted it. But
00:25:02.380 | if you do post-layer norm, then you are basically squashing both the residual and the additive
00:25:09.060 | parts. So when you-- so your activations from the lower layers keep getting-- keep going
00:25:13.340 | through layer norms. But in pre-layer norm, you're only-- you're only-- a residual path
00:25:17.660 | has a layer norm, which means your-- your activations all the way from the bottom of
00:25:21.340 | the model are free. They're untouched, and they can pass through the-- yeah.
00:25:27.820 | Yes, OK. OK, so now-- so now-- I mean, so until this point, we haven't discussed why
00:25:34.180 | did we-- you know, we haven't discussed multi-head attention, which ended up being very important.
00:25:40.220 | So one of the problems with attention is that imagine if you wanted to-- I mean, so oftentimes
00:25:48.900 | language is about understanding who did what to whom. So in this case, the cat licked the
00:25:54.340 | owner's hand. So licked-- who licked what? Like, the cat licked the owner, right? So
00:25:58.620 | now if you actually want to combine information from these two slots, these positions, these
00:26:03.940 | vectors, then the best you could do with attention is 0.5, 0.5 to the single layer, right? Half
00:26:08.700 | probability, half probability. But then they get mushed together, right? But now imagine
00:26:12.140 | the-- imagine the strength that a convolution has. It can actually have-- that actually
00:26:18.940 | should have-- well, OK, well, I think the point will still come across. So now what
00:26:25.300 | a convolution can do is because it has-- it basically applies-- essentially, a convolution,
00:26:30.460 | in this case, it's a 5 by 1. All it really does is it just applies a different linear
00:26:36.540 | transformation at each position, right? So it can take any-- and because these linear
00:26:41.740 | transformations are different, it can-- the first linear transformation can learn, I'm
00:26:46.100 | going to take a little bit of information from here. I'm going to take a little bit
00:26:49.140 | of information from here. And I'm going to put them together, right? And the attention,
00:26:53.460 | the best way that you could actually just do this is best by averaging. That would mush
00:26:56.300 | all these things.
00:26:57.300 | But having different linear transformations allows you to take a part of the embedding
00:27:00.660 | here, a part of the embedding here, mix it up, and then maybe put it together without
00:27:04.300 | actually then interfering with each other. And multi-head attention, which is a bit like
00:27:08.500 | basically a multi-tape, multi-head of a multi-head Turing machine with different read-write
00:27:16.300 | heads, essentially allows you-- starts getting you that property back, where now what you
00:27:22.600 | do is you essentially-- you now-- you bring back the ability to select different parts
00:27:28.580 | of the input. So you chop up the hidden dimension into independent pieces. And then each one
00:27:33.580 | of them is now able to do attention. So now you can have probability 1 in this place and
00:27:37.980 | probability 1 in this other subspace, instead of having 0.5, 0.5. So now you don't have
00:27:42.460 | to-- you don't have to get these averaging effects. You can actually be selective, right?
00:27:48.340 | And also, for computational reasons, instead of actually having eight attention layers
00:27:53.420 | of like-- or six attention heads of d dimensions, we had-- or eight attention heads of d dimensions,
00:27:58.780 | we had eight attention heads of d by 8 dimensions, right?
00:28:03.260 | So we wouldn't incur any more-- we wouldn't incur any more flops, for the same amount
00:28:10.540 | of flops. But that's only half the story, because the attention heads themselves turn
00:28:14.180 | out to be quite expensive, which then later on had to be-- they were doing improvements
00:28:17.620 | that needed to be made, right? And the most important part-- probably the most important
00:28:26.260 | result was that, with the transformer, we were able to outperform previous ensembled
00:28:33.860 | models as well. And that was very, very exciting, that, hey, this single model actually is able
00:28:38.500 | to outperform previous ensembled models. And not only that-- and this was machine translation
00:28:44.580 | in WMT 2014, English, German, and English, French machine translation tasks. And not
00:28:51.780 | only were we able to do it in less flops, but also these-- it was very clear that this
00:29:01.660 | was a very general model, as we immediately applied it to parsing, and we were able to
00:29:06.220 | get-- we were able to get, with a small model, excellent results.
00:29:10.980 | So in some sense, this was very exciting, because this meant that, all right, now this
00:29:18.900 | consolidation that we're trying to go for in machine learning, we probably have a model
00:29:22.460 | that's more general than what we had before, and we can now throw it at different-- maybe
00:29:27.420 | we can now throw it at different problems, right? And ultimately, why? Because it would
00:29:32.580 | be helpful to have a single model that's able to combine representations from speech, images,
00:29:40.420 | and language. And if you had a general substrate that worked well in all tasks, then potentially
00:29:45.940 | you could get to the single multimodal model.
00:29:51.180 | Sometimes interpretability is like tea leaves. It's like reading tea leaves, so one should
00:29:57.660 | be careful. But it was nice that the attention by itself can give you some interpretability,
00:30:03.180 | and we were able to kind of see how some of these attention heads, or some of these attention
00:30:09.140 | mechanisms were actually able to learn long-distance relationships. Some actually learned to be
00:30:14.100 | kind of early on in the transformer. We saw this generally invariant pattern, where some
00:30:20.340 | of the attention heads basically turned out to just look like convolutions. They were
00:30:23.740 | just putting in local information. There's, of course, now being much more advanced work
00:30:27.860 | with some of the mechanistic interpretability stuff with grokking and the stuff that's happening
00:30:34.060 | in entropic, which is where they're learning now that actually learning how to interpret
00:30:40.300 | these induction heads. So it's interesting. But we were able to see some anecdotal evidence
00:30:46.900 | of these heads actually performing very, very distinct and clear actions.
00:30:51.060 | OK, so if there's any more questions, then I'll pause for a second.
00:30:57.740 | Do you, by the research, find that it's the induction heads that are causing the in-context
00:31:03.180 | learning?
00:31:04.180 | Yeah, it's hard to tell. So from what I haven't looked at the most recent work, but they have
00:31:10.220 | solved this issue of superposition. Is that right? So now, with having solved that, they're
00:31:14.180 | able to-- does that roughly mean that now they'll be able to assign distinguishing features
00:31:19.260 | to each one of these heads and be able to explain it, from what I understand? Or the
00:31:25.140 | in-context learning part is that-- is it that they have to show it, or is it that they're
00:31:30.660 | saying that in-context learning happens because of induction heads?
00:31:33.340 | Yeah, the latter.
00:31:34.340 | Yeah, it's the latter. Yeah, it's not clear, because-- yeah, I think there's probably many,
00:31:42.860 | many kinds of-- in-context learning is shown to work in so many different tasks that--
00:31:49.140 | and actually, I haven't followed this quite well. I don't know specifically-- what are
00:31:53.300 | the induction heads typically-- what kinds of properties do they have? Do you know what
00:31:57.860 | kinds of mechanisms they have?
00:31:59.660 | OK, so yeah, so then-- so since both of us don't know this really, really well, we won't
00:32:05.420 | be able to go very far here. But I'm not sure if they've gotten to the point where they're
00:32:10.580 | able to explain most of the in-context learning because of induction heads, from what I understand.
00:32:14.420 | They might have, yeah. Does anybody know about the induction heads? OK, so now, over the
00:32:25.780 | years, so there have been a few-- there have been many papers, but there have been a few
00:32:33.340 | changes that have been important. There have been a few changes that have stuck, and the
00:32:39.060 | new transformers typically have these improvements, right? And we'll go from bottom to top with
00:32:47.500 | some of them and see which ones have actually stuck, right?
00:32:51.260 | So we started with the first-- one of the biggest problems with self-attention was that
00:32:55.140 | it was-- that self-attention itself is permutation invariant, right? You need to dope position
00:33:04.260 | information in order for it to learn some kind of temporal structure. And in the original
00:33:09.260 | transformer, we used these sinusoids, and we had hoped that it would actually learn
00:33:13.540 | relative position encodings because you could decompose the position encoding of another--
00:33:19.660 | you could decompose the position embedding of another position as some linear function
00:33:24.060 | of the previous one. And we had-- and some-- and another factor, which depends on the relative
00:33:30.500 | distance between the two. But that didn't happen. Learned position encodings in the
00:33:34.900 | original paper did as well, and so we were not quite able to get-- we were not quite
00:33:43.620 | able to get these model relative distances using the sinusoids.
00:33:46.980 | So then a couple of important-- and this is a very biased sample, but I think it generally
00:33:52.820 | covers a large category of these-- it covers a large set of papers. There's roughly sort
00:33:59.820 | of three categories, right? So there's-- and all of them are kind of now explicitly learning
00:34:05.700 | relative-- explicitly learning relative embeddings. So there's-- so in the relative position transformer,
00:34:13.340 | we had an embedding for every pair of relative positions. And using that, we basically then
00:34:18.300 | dot-- we did a dot product of that embedding with a query that produced a logit that modulated
00:34:23.060 | according to the relative distance. And we found this to be extremely-- we found this
00:34:27.900 | to be extremely useful for translation, but I'll show also in music.
00:34:34.180 | Another sort of-- maybe a simplification, this is the alibi paper where-- this is non-parametric.
00:34:40.100 | These are not learned, where instead of an embedding for every pair of positions, you
00:34:44.740 | actually have a single bias, right? So you just add a single bias to the logit, and you
00:34:50.220 | can either learn it, or you can use a heuristic, which Alibi did. And one other advantage about
00:34:58.300 | relative position encodings is that they could potentially allow you to extrapolate to new
00:35:02.500 | to longer sequence lengths, which you couldn't do with absolute position encodings.
00:35:08.340 | I'm curious about the room-- about what the room thinks here, but I believe that the latest
00:35:15.040 | in partition relative position encodings where this is-- I believe it's called the row former,
00:35:20.740 | where they basically just rotate the embedding with every pair of dimensions a little bit.
00:35:28.600 | And the angle of rotation depends on your actual absolute distance. But what ends up
00:35:33.060 | happening is, when you do the attention operation, you end up getting relative-- you end up basically
00:35:38.940 | getting an effect where you're modulating the logit based on relative distance.
00:35:43.140 | So now what's remarkable about this approach, what's-- it combines the best of both worlds,
00:35:48.180 | right? It actually-- it's absolute position encodings-- relative position encodings had
00:35:52.420 | a couple of challenges in that you have to maintain an extra logit for-- or an embedding
00:35:57.700 | for every pair. So there was a lot of-- so it ended up increasing your memory. Here,
00:36:02.860 | these are actually absolute position encodings, but they gave you-- they ended up giving you
00:36:07.060 | the relative modulation in the attention operation that you needed.
00:36:10.900 | And I believe the consensus is that this is the most successful-- this is the most successful
00:36:15.300 | position encoding. Is that correct, or are there-- is that-- are there others that are--
00:36:19.780 | that people-- is that the consensus? OK. So it looks like-- so I would say that the
00:36:27.620 | the-- these relative rotations are from-- or the approach that's in the reformer is
00:36:33.940 | likely-- is basically an actual new genuine improvement that is now going to stay with
00:36:39.260 | the transformer. And it has all the-- it has all the great properties of what you would
00:36:42.980 | want. It has-- it's an absolute position encoding that gives you relative effects, which is
00:36:46.940 | what we originally wanted. And one-- and to emphasize that we needed relative-- like that
00:36:56.580 | being-- emphasize two things. One, that modeling, like, interesting temporal relationships,
00:37:04.100 | which is-- which are really important in music, requires a good position representation. We
00:37:09.660 | actually found significant improvements in the music transformer. Is it-- is it possible
00:37:13.820 | to play this? OK. So here is a-- like, here's a priming sequence. This is-- this is work
00:37:21.740 | by-- work by Anna Huang, by the way. So this is a in-context learning in music, because
00:37:36.380 | you actually see this prompt and you ask the model to complete it. OK. So now this is the
00:37:41.180 | vanilla transformer. And you can already-- so you can see that these were using-- I mean,
00:37:53.140 | we tried both learned and sinusoids. And you can see that it starts off peppy and happy,
00:37:57.660 | but then just sort of languishes into something really sad and confused, right? So it's not
00:38:02.260 | able to capture these-- because music has these interesting motifs where-- well, there's
00:38:07.620 | motifs at different levels, because there's some repetition locally, but there's a repetition
00:38:12.860 | across the entire piece as well. So now here, this is with the relative transformer. And
00:38:20.980 | this is with the first approach where we had relative embeddings. And we had to-- we had
00:38:26.060 | to-- we had to develop a compute-efficient approach to actually with-- by using some
00:38:32.260 | matrix calisthenics to actually put the logits in the right place. So you can read the papers
00:38:37.600 | here. It's fun. So here's the same prime sequence. And let's see the completion here.
00:38:52.140 | So Anna, who is the first author of this paper, and also a musician, tells me this actually
00:39:07.720 | captures a lot of structure in music. It sounds nicer than the previous one, but maybe-- depends
00:39:12.880 | on what people's tastes are. Like maybe some avant-garde jazz fan would like the second--
00:39:18.120 | would like the first piece. But the point here was that the difference is pretty clear
00:39:23.840 | between not working and working. And I think people-- it'd be fun to try this out with
00:39:28.680 | the new rotary position encodings. All right. OK. So walking up, now that we have a good
00:39:37.920 | mechanism-- a better mechanism than we originally had for modeling relative distances. And there's
00:39:45.520 | advancements on top of the rotary position encodings where, by adjusting the base frequencies,
00:39:49.840 | you can-- when you encounter longer sequences, you can just adjust the base frequencies.
00:39:54.720 | And then the model's not going to-- the model's not going to degrade. So that has good properties.
00:40:01.480 | Probably there's been several, several important contributions to the attention piece itself,
00:40:09.400 | which is the primary workhorse here. It's the one that you can think of it as-- it's
00:40:13.920 | either-- there's induction heads that are learning how to copy. Or maybe all it's really
00:40:19.640 | doing is just routing information so that the giant feed-forward layers can actually
00:40:23.600 | learn the important features. But there's broadly two classes of problems. There are
00:40:28.440 | two classes of issues with the attention mechanism. One that was brought up today that's very
00:40:32.600 | evident is long context itself. So the complexity, as we remember, was quadratic in the length
00:40:40.560 | of the sequence. And once your sequences get very, very long-- once your sequences get
00:40:44.560 | very, very long, then not only-- I mean, there's one problem that's going to-- it's going to
00:40:51.040 | become very-- it's going to become computationally expensive. But it's also the logics that are
00:40:54.920 | going to become infeasible, right?
00:40:56.760 | So there's just generally a few groups of papers. One is restricting attention windows.
00:41:02.160 | And we did this for images where they had local 1D and 2D attention for images. And
00:41:09.440 | in the first one, we actually just rasterized the image. And we had local 1D attention,
00:41:13.760 | which is very similar to the sliding window attention in the recent Mistral paper. And
00:41:20.000 | then in the 2D case, we have a spatial 2D attention. Then there was these sparse versions
00:41:28.960 | where you actually-- you had these specific patterns that over many layers-- I mean, you
00:41:34.200 | can think about it as, if you have these sparse matrices, how many of them do you have to
00:41:39.800 | multiply with each other until you get a really dense matrix, right? So roughly, this kind
00:41:43.640 | of turns out to be-- so here, you can get connectivity-- is that for me? No, OK. You
00:41:54.040 | can get connectivity between distant pixels or distant notes in a musical tune or words
00:42:02.840 | pretty quickly. And then there's a second one, which there hasn't been enough work.
00:42:08.360 | And there's some challenges there. But it's these unstructured sparse attention approaches.
00:42:13.400 | And they're typically-- they're essentially-- at a higher level, what they're really trying
00:42:18.120 | to do is imagine that I walked up to you and I told you that, hey, these are the bunches
00:42:25.600 | of tokens that just have very high inter-similarity. Like, they're likely to tend to each other.
00:42:33.080 | How quickly can I approximate it without actually having to do the whole computation, right?
00:42:37.480 | Two approaches. And in routing attention, you use vector quantization. And in the LSH
00:42:42.320 | or the-- I forget what-- I think I forget the name of the paper. But in this paper,
00:42:48.720 | they used LSH. And in the routing transformer, most layers were actually local. The final
00:42:58.960 | layers, which typically are the ones that end up do modeling, that end up modeling these
00:43:03.640 | long-distance relationships, were the ones that actually used this kind of content-based
00:43:07.680 | unstructured sparse attention. And the results were generally better. And it's also interesting
00:43:13.240 | that maybe we can build models on very long sequences, where most layers are fairly local.
00:43:20.120 | And you have only a few layers that are actually doing these long-distance attentions.
00:43:23.400 | Now, one of the bigger challenges there, actually, even though it ended up being-- even though
00:43:28.720 | you end up nullifying a lot of the flops that you would do if you did full attention, the
00:43:34.320 | problem always ends up being memory movement. Always ends up being memory movement. And
00:43:39.720 | there's still more innovation to be done here, also, with memory bandwidth improving. Maybe
00:43:43.960 | some of these approaches become more feasible today than they were when we wrote these papers.
00:43:50.000 | But this is an interesting approach, where you're essentially trying to approximate the
00:43:52.820 | original attention matrix.
00:43:53.820 | Sorry. This is kind of a silly thing, but a clarification. How is this unstructured
00:43:57.920 | sparse attention scheme very different from just convolutions that are sparse, in the
00:44:02.440 | sense that you're losing a lot of the long-distance or unrelated context from any arbitrary comparison
00:44:08.160 | elements?
00:44:09.160 | Right. So I would say that this is similar to the convolution there. If you did this
00:44:15.120 | perfectly, then what you didn't attend to would have very little attention in itself.
00:44:22.720 | So you're essentially trying to guess, as best as you can, what would have attended
00:44:27.840 | to each other. And so it uses content based unstructured sparsity.
00:44:35.200 | And there's probably more interesting work to be done there. Maybe instead of actually
00:44:39.320 | just doing a token at a time, you end up doing a lot of memory movement. You end up deciding
00:44:43.800 | which chunks want to self-attend to which chunks. So then you just move entire chunks
00:44:47.160 | at a time.
00:44:48.160 | Right. So I think there's some interesting directions here. And frankly, the ones that
00:44:56.400 | ended up sticking are the simplest ones. And because structure sparsity is easy, you're
00:45:03.700 | able to optimize easily in modern accelerators. So again, you should make physics your friend.
00:45:12.400 | And so typically, local attention or sliding into attention, we're still seeing it often
00:45:17.320 | appear and do well. These other sort of really wild but very expressive unstructured sparse
00:45:24.320 | attention approaches typically haven't quite succeeded.
00:45:27.160 | There's, of course, linear attention variance that I don't think today are in any of the
00:45:32.360 | [INAUDIBLE] architectures. There were other approaches that, hey, instead of actually
00:45:35.560 | doing n squared, you do n squared d, where you learn new k embeddings, where you do nkd
00:45:45.080 | and then you do ndk. So you basically factor it, right? Just like an analog matrix factorization.
00:45:51.400 | Something that's-- one other approach that's interesting that I would like myself to actually
00:45:55.660 | investigate is we are seeing, in general, using retrieval as a tool. So why don't you
00:46:00.640 | just pretend that your memories, your memories themselves were documents and use retrieval
00:46:05.320 | as a tool there. So the memorizing transformer, basically, it essentially does a mix of local
00:46:12.000 | and it then retrieves from very, very long memories. And they find that you don't need
00:46:16.120 | to train the model from scratch. All you need to do is adapt with this approach on some
00:46:22.400 | small amount of data. And you're able to learn a good retrieval mechanism. I think it's quite
00:46:25.880 | interesting.
00:46:26.880 | So it still comes in this content-based decision of what I should attend to. But I like the
00:46:34.200 | fact that it just makes retrieval a tool that you can use either on your own memories or
00:46:38.960 | you could use it on documents. It's a nice general view of looking at things.
00:46:44.600 | OK, so now the second piece, which you basically run into-- you run into the issue that not
00:46:52.080 | all flops are equal, right? So if you look at the memory hierarchy, a lot of your activations
00:47:00.120 | that are stored in the GPU-HPU, which today in the H100 is about 80 gigabytes. But the
00:47:08.980 | H100 is 80 gigabytes, and the A100 is 40 gigabytes, right? So it's a limited amount of high-bandwidth
00:47:16.120 | memory. And so you have to first go from high-bandwidth memory to the SRAM. And then you have to go
00:47:21.160 | to the compute elements and then back, right?
00:47:23.240 | So every single time-- and this is-- I mean, it probably-- whenever-- if interested, you
00:47:32.400 | look at roofline analysis. The roofline analysis actually gives you a nice picture to characterize
00:47:39.920 | for any device where you would need-- where your workload or operation needs to be so
00:47:48.320 | that you can actually effectively utilize the compute as much. You want to be compute-bound,
00:47:52.460 | because ultimately, if you don't calculate representations, if you don't calculate, you're
00:47:55.920 | not going to get any output. But if you spend a lot of time moving things around and spend
00:47:59.640 | less relative time calculating, then you're actually-- you're kind of wasting effort,
00:48:05.680 | right?
00:48:06.680 | So one of the-- so if you look at standard attention mechanism, right, one of the issues
00:48:10.520 | is that-- OK, so imagine you have your queries, keys, and values all in your memory. But then
00:48:15.600 | you need to then-- your standard approach would be you move it from HBM. You do the
00:48:21.120 | calculations. You compute the attention. You compute the logits. You move logits back into
00:48:25.640 | HBM. And then you compute softmax, right, the softmax back into HBM. And then you basically
00:48:31.840 | load the probabilities and the values then to then finally compute the outputs, right?
00:48:38.320 | So the arithmetic intensity or the arithmetic intensity or operational intensity, which
00:48:43.880 | is the amount of flops that you do per byte on attention, even though it's less flops
00:48:49.360 | than, say, a one-by-one convolution, it has more-- it is lower, because it typically has
00:48:53.800 | more memory movement. Whereas one-by-one convolutions have less memory movement. You just move the
00:48:58.240 | weights, move the activations, you do the calculations, and you bring them back, right?
00:49:01.440 | And same goes for convolutions, too. And convolutions have a very high arithmetic intensity. It's
00:49:04.960 | not that you just want the highest arithmetic intensity or operational intensity operations,
00:49:08.800 | because you still want to have useful parameters, right? So it's a trade-off.
00:49:13.640 | So a lot of-- so there's been a bunch of improvements that will stick. I mean, they're almost certain
00:49:19.680 | likely to stay, that try to combat this issue both in training time, because your logits
00:49:24.640 | can get really big, but also inference time or your KB. When you're doing inference, then
00:49:29.560 | you have a single query. But your KB cache, right, you have to maintain your keys and
00:49:35.000 | values that can grow quite a bit. So you have to move that around.
00:49:37.800 | And so the first step of the day is simple. Let's just decrease the activation memory.
00:49:42.840 | So the multi-query approach, where it's basically in a multiple-- so you reduce-- you have multiple
00:49:50.160 | queries, but just you reduce the number of read heads to just one. So you have just one
00:49:55.000 | key and one value. That does reduce your expressivity.
00:49:57.920 | So grouped query, which is now a simple balance, that basically says, hey, let's not take the
00:50:02.680 | extreme of having all this temporary activation memory. Let's actually group it to a different
00:50:07.800 | query. So a bunch of queries will attend to the same keys and values.
00:50:12.480 | And then what ends up happening is-- another point to note here is that all of this is
00:50:18.200 | relative, because most of the work in these very, very-- oh, but a third approach, actually,
00:50:22.920 | that I should say of not worrying about your attention is just to make it more of a debate.
00:50:29.160 | But then you just get about your three-fold computations and your attention computations
00:50:33.000 | just like a small slice of that. So you don't worry about it, right?
00:50:36.000 | So typically, these larger models, even though grouped query attention has more activation
00:50:42.320 | memory than multi-query, when with these large models, it's still not a much larger-- it's
00:50:46.680 | not a much larger-- it's still a smaller proportion of what you're doing in the feedforce or your
00:50:50.480 | certified, right? So I guess three things, like ignore, make it really big. Second is,
00:50:56.800 | I guess, you-- but even with prolonged context, you can do some of these approaches that we
00:51:04.720 | talked about. But then you also have these system optimizations, which are pretty cool.
00:51:10.600 | So the softmax has an interesting property that you can compute it in an online fashion.
00:51:15.400 | You can compute it incrementally. So if you've got a bunch of logits, so you're kind of streaming
00:51:20.000 | them, if you've got a partial softmax and a new logit comes in, you can update it in
00:51:24.920 | an online fashion, right? So what does that mean? That means that now you never needed
00:51:31.320 | to write logits or the p's into the HBM. So you save a lot, right? If there's an extremely
00:51:36.280 | long sequence, you end up writing a lot. So you save on that. And both these approaches
00:51:41.600 | end up-- in one case, the first paper was on TPUs that introduced this property or took
00:51:48.640 | advantage of this property, the property to be able to compute the softmax in an online
00:51:53.160 | fashion. And the second paper, which is now flash attention today, they've had many advancements.
00:52:00.000 | They actually had some systems-level optimization where now you can actually have very, very
00:52:04.600 | long sequences on GPUs, the optimizations for GPUs, by basically not moving the logits
00:52:12.280 | back into HBM, using this online-- using this property and also writing the right columns
00:52:16.280 | that use the SRAM and everything-- use the GPU. With any questions? What's the time?
00:52:27.600 | So we are basically 20 minutes. I'll finish in 10. So I just covered these two. There's
00:52:33.680 | many, many-- there's, I guess, there's other important improvements. I'd say this to the--
00:52:40.520 | we talked about the pre- and post-versus post-layer norm. There's been some changes of the feed-forward
00:52:46.440 | layers themselves. You can stare at the feed-forward layers. I mean, you can stare at anything
00:52:51.360 | long enough, everything becomes attention. But it's true in the feed-forward case that
00:52:54.640 | if you look at it, you can think about them as-- it looks like attention. And there was
00:52:58.880 | a paper that sort of turned that into a bit of a-- turned those into memories. It was
00:53:06.000 | originally by Facebook. I actually forget what it was. But it didn't-- and the feed-forward
00:53:10.520 | layers just stayed-- I mean, we typically haven't seen a lot of improvements on them.
00:53:16.280 | There have been some efforts on higher-order attention right now. Attention, if you think
00:53:21.720 | about it, is a third-order interaction. You have queries, keys, and values. But-- and
00:53:25.800 | right now-- but you could imagine actually having four-order interactions where you're
00:53:29.800 | actually computing logits of pairs of things against all pairs of things, right? So these
00:53:34.240 | are now higher-order interactions where now you can have complicated geometries that you
00:53:39.040 | actually include in your attention computation. And maybe it's important for, say, biology
00:53:44.320 | or some biology, but it's not been explored much.
00:53:47.840 | What has actually worked and is likely to now stay is some approaches on password decoding.
00:53:53.040 | Not quite the original, less or non-order-regressive aspirations that we had, but these more speculative
00:53:58.960 | decoding where-- the heuristic there is pretty simple. You score-- if you want-- instead
00:54:04.440 | of generating from a heavy model, generate from a really light model that captures the
00:54:09.040 | diversity and then score with a heavy model. So then you re-rank the list. And that ends
00:54:12.800 | up working quite well. And most production deployments likely use speculative decoding.
00:54:19.240 | OK. So now switching gears, I guess we started this-- or we started by coding the Dartmouth
00:54:31.760 | conference where they wanted to build a single machine. And the question now is, with large
00:54:35.240 | language models that are now eating up most of the internet, are we quite getting there?
00:54:41.440 | And we are seeing some remarkable-- we're finally seeing self-supervised learning work
00:54:45.360 | at a scale that-- work at an unprecedented scale where now by digesting carefully curated
00:54:54.480 | and colossal amounts of text with very, very large models, you're able to-- they're able
00:54:58.720 | to perform, presumably, or it's still waiting to be confirmed, tasks that are-- or they're
00:55:06.560 | able to actually perform at least a large-- a broad variety of tasks by just specifying
00:55:12.200 | them in the prompt. And it's now-- it's almost like now you have-- now you have a new computer.
00:55:18.120 | And for people who are really excited about the future of agents, now they can program
00:55:21.600 | thousands of agents with the same computer. Oh, maybe you-- now they have-- now they have
00:55:27.040 | agents that they can-- several agents that they can program with the same computer that
00:55:31.400 | then coordinate to solve problems. So we're getting much closer to the single model, not
00:55:37.200 | quite being able to specify all the rules of intelligence, but at least learning all
00:55:40.960 | the rules from data. We're very close to-- we're much closer than we were before. Now,
00:55:46.600 | this doesn't include all the important thing-- all the important specialization that has
00:55:51.720 | to happen after, like, RLHF or the alignment that you have to do to make a model more steerable.
00:55:59.440 | But it's-- and as it stands today, the scaling laws that the transformer exhibits are better
00:56:08.000 | than any other existing model, right? And there's an interesting question of, you know,
00:56:14.000 | which-- can we build a better model? And there are efforts-- there's, I guess, from the Stanford,
00:56:18.640 | from Chris Rea's lab, there have been a couple of efforts. There's been some revival of RNNs.
00:56:23.840 | But I think the only-- the only-- the only thing I'll say that is that the attention
00:56:28.640 | operation itself, this operation of actually moving information around or routing information
00:56:33.040 | based on content, is very, very useful. And it's maybe not a surprise that this general
00:56:39.400 | sort of spatial mixing of sampling, downsampling architecture has kind of stayed both in cognition,
00:56:44.720 | computer vision, and language, now with the transformer. So there are some invariants
00:56:48.320 | that are likely to stay, but I do think that maybe that it-- and there is certainly much
00:56:52.880 | more room there to improve, I mean, not just in the architecture, but on data itself. Like,
00:56:58.680 | there's probably 2x improvements on data. But I wouldn't say that there's-- there aren't
00:57:04.160 | architectures in the future that will get better scaling loss. They might, but there
00:57:08.600 | are properties about the transformer, such as self-attention and its general structuring,
00:57:12.880 | that is likely-- that we're likely to see in future architectures to come. Also, it's
00:57:19.320 | hard to really think of a modern-- like, if somebody really, really wanted to study large-scale
00:57:25.200 | modern transformers, you'd have to study, like, all-reduces, InfiniBand, Rocky, and
00:57:31.720 | what are-- like, well, but they get congestion, and they have very, very large clusters. So
00:57:37.640 | the computer is no-- the computer-- the transformer is now, in some sense, a data center, because
00:57:42.320 | it's not split up. These large transformers are with tens of-- potentially tens of thousands
00:57:46.360 | of GPUs. So-- and so if you-- so now you actually have to really focus on several parts, the
00:57:56.720 | infrastructures and the model itself. But what's really interesting, I think, is-- you
00:58:01.560 | know, I was just thinking of the smallest model that has exhibited emergent phenomena.
00:58:05.560 | Well, so we certainly know that GPT-4, which is likely-- I don't know if you're allowed
00:58:10.480 | to say it's some big-- like, trillion parameters. Yeah, I think you're allowed to say it, yeah.
00:58:16.400 | So it's a trillion-parameter size model. That's what everybody says. Size model. And then
00:58:19.600 | you have Brocking, which is a two-layer transformer that has this weird emergent behavior that,
00:58:26.280 | when you just keep training it on just-- on some amount of data, suddenly it just exhibits
00:58:30.400 | a space shift, right? So we're lucky. There are these, like, really-- there's strange--
00:58:35.840 | there's weirdness everywhere. There's weirdness in small models and large models. And maybe
00:58:40.240 | we can learn something about large models by studying these small models, one would
00:58:44.720 | hope. But it's funny. There's still unexplained phenomena in very, very large models and very,
00:58:51.160 | very small models. But large transformers are no more just, you know, like a cola. There's
00:58:57.480 | just-- I mean, it could still be, but it's-- you have to-- there's so many-- there's so
00:59:02.360 | much that you have to keep in your stack in order to really optimize this entire-- this
00:59:07.640 | model. Of course, some of the very exciting directions are LLMs using tools. Yeah, that's--
00:59:14.640 | so now the benefits of-- now language models or transformers are actually starting to use
00:59:19.800 | external entities. So they're connecting with the rest of the world. And I guess that's
00:59:24.000 | a good-- that's a good pitch for-- it makes a lot of sense to actually build products
00:59:28.820 | today because it's through interactions with-- like, if you want to get to the next tranche
00:59:33.520 | of capabilities, where will they come from? And likely, with a lot of usage, you will
00:59:38.840 | learn much more about how to guide these models and how to train them without-- than in vacuum.
00:59:43.320 | Now, you can definitely do very, very important work still in-- by even with a smaller model
00:59:49.200 | or even without building a product, without building a product because there's so many
00:59:52.360 | important unsolved problems. And maybe you shouldn't even work on the transformer because
00:59:56.880 | it's like Burning Man right now. Everybody's going to the same party. But I think that
01:00:03.320 | you will be able to build new capabilities once these-- with this human-machine collaboration.
01:00:09.800 | Of course, teaching models or models being able to express what they don't know, how
01:00:15.120 | do you learn new skills in infants' time, important for-- there's some interesting work,
01:00:18.640 | I think, on Minecraft that showed some evidence of this is also important for agents. And
01:00:23.760 | another-- a great property that some of these diffusion models have is the more compute
01:00:28.720 | you spend, the potentially better the quality of the image gets. But we don't exactly quite
01:00:32.720 | have that for language. And what does that mean? So today, the best-- the models that
01:00:37.240 | can reason-- that have the most proficient reasoning and planning are also the largest
01:00:42.600 | ones. Can we separate it out? Can we have smaller models that do some adaptive thinking
01:00:47.600 | and are able to match the capabilities of potentially larger models and reasoning and
01:00:52.080 | planning? And maybe the answer is going to come by connecting to external planners and
01:00:56.280 | planners or maybe with better representations of data, you can actually reason better on
01:01:02.000 | it.
01:01:03.000 | Also, this is, again, a more systems piece, but it's fascinating how low you can actually
01:01:09.040 | get on your-- how low you can-- how few bits you can actually use and still get something
01:01:15.320 | useful out. We already went from-- the original transformer was trained on 32-bit precision.
01:01:19.600 | Then we went to BFLOAT16. And now there's good signs that INT8 and FP8 would also work.
01:01:25.040 | And I think there's useful work to be done there. Again, going back to the same-- this
01:01:29.360 | argument about if you're actually-- if you're vector-- if you're using fewer bits to represent
01:01:36.000 | a number, you're actually transmitting fewer bits to the-- from HPM. So actually, you can
01:01:40.400 | get faster. You can utilize your matrix multipliers much more effectively.
01:01:45.240 | That was it. So there's many topics, but hopefully, we covered something fun. Thank you.
01:01:51.880 | Yeah.
01:01:52.880 | Could you talk about what you're working on now and what you're working on?
01:02:03.880 | Yeah. So I'm a co-founder of a startup with my transformer co-author, Nikki. And we're
01:02:12.680 | working on building models that will ultimately automate workflows. And we're starting with
01:02:21.080 | data. So it's very puzzling what happens in a company. Companies are just basically just
01:02:26.320 | masses of dark knowledge, right? And there's very few people that have both the technical
01:02:31.200 | privilege and the understanding to ask questions, like typically analysts. But the less you
01:02:36.400 | understand, the less effective your company can be. So how can you eventually help anyone
01:02:41.320 | become an effective analyst, in some sense, right? So help them ask the right question,
01:02:46.120 | help them figure out, eventually, the whys, which then requires some kind of counterfactual
01:02:50.760 | reasoning that's very complicated. But start with data, since it's so important, and companies
01:02:55.280 | are essentially drowning in it. And then be spread out from there, and then try to automate
01:03:00.320 | other workflows and be impressed. But we believe that some of the early signs that we're seeing
01:03:06.440 | and our position is that I believe that this is going to require a full stack approach.
01:03:12.600 | So not just building the model, because you can then control what feedback you get. And
01:03:18.920 | so if you have a gap in the model, you ask for that. You start to get that feedback,
01:03:23.040 | so then you can improve the model. That's what we're doing.
01:03:26.720 | Please talk to us after we've done it.
01:03:29.880 | Yes?
01:03:30.880 | I'm surprised to hear that you're fairly bullish about tools in the end, like in our
01:03:34.680 | transparency control and third-party things. We talked about in the beginning that your
01:03:37.840 | motivation was transformers that enabled us to get rid of pipelines. But I feel like the
01:03:41.040 | rule was against pipelines again. So I'm surprised at this. Can you talk about that and where
01:03:45.160 | do you think that's going to go?
01:03:47.680 | Right. So until we get to the point where it's like, you know, we're turtles all the
01:03:52.880 | way down, it's like transformers all the way down. No, I think that tools just allows you
01:03:57.480 | to-- so it's kind of like, how do you interface with a machine that can think, right? You
01:04:05.120 | have to build some kind of interface. And if you build a useful functionality, you want
01:04:08.240 | the machine to be able to take your functionality and do generally useful things with it, right?
01:04:12.840 | And I think that using tools is just a way of leveraging things that people have built
01:04:18.160 | and software out there. Certain tools will probably get absorbed in the model, right?
01:04:23.520 | Some others won't. And that still gives us the ability to-- yeah, it still gives us the
01:04:29.120 | ability to-- and certain things that transformers shouldn't even do, sorry. I mean, like you
01:04:35.640 | don't want to spend a billion flops per position to calculate two numbers, right? You don't
01:04:40.800 | want to spend more flops to do an operation that required like 1 billion flops, right?
01:04:45.240 | So there's certain things that the model should not do. It should use external tools. And
01:04:50.960 | there's certain things that the-- certain kind of thinking that the model should do.
01:04:55.880 | So even from a capability perspective, there's an important question of what all the capability
01:05:00.560 | should be in this neural network, right? But then also being able to utilize the work that
01:05:04.680 | others have done, software that other people have built. Yeah.
01:05:11.120 | It talks more about why like the original approach of decoding parallely and then integratively
01:05:15.440 | refining it. Yeah.
01:05:16.440 | Why that didn't work and what-- Yeah, so sometimes if you know exactly why
01:05:20.520 | things work, maybe you can make it work. But it ended up being-- so you're able to do silly
01:05:25.360 | things like randomly sort, which means that if somebody walks up to you with a sequence
01:05:31.160 | and you can-- I mean, you can break two modes. Like you can say ascending or descending.
01:05:36.080 | So how do I say this? So typically, when you decode, right, imagine that when you give
01:05:42.580 | a prompt, you have many possible computations, right? And each time you make a choice, you
01:05:49.600 | narrow that space. And each time another choice, you narrow that space, right? And you have
01:05:54.720 | a very-- and you've learned to narrow the set of all possible, in some sense, paths
01:06:00.840 | in a way. The model doesn't have to decide what's the order in which you have to go.
01:06:05.520 | When you're doing this less or non-autoregressive generation, you have to do both, right? And
01:06:11.880 | doing learning both simultaneously is hard. I mean, but eventually, I think that if for
01:06:17.880 | a particular-- I think this is probably true, right? If an oracle walked up to me and said,
01:06:25.840 | this is the order in which all these sentences should be generated. First, you should generate
01:06:30.120 | these three words. Then you should generate these other two. Then these other two. If
01:06:33.200 | somebody walked up to you and gave you this oracle ordering for all of human language,
01:06:36.880 | I think you would have a much better chance. And you could actually get this less non-autoregressive
01:06:40.440 | generation. So one thing was basically the ordering itself. And I think it kind of has
01:06:50.000 | to do that, because the ordering helps you then lock down the modes. It narrows down
01:06:53.880 | what you're going to generate next. So ultimately, I think it does boil down to what's the right
01:06:58.640 | non-autoregressive ordering. And that could be either you're still generating one word
01:07:02.640 | at a time, but not autoregressively, or you're generating a few. And then based on that,
01:07:06.280 | you're generating the other few. So the words that you can generate all at once should be
01:07:11.200 | conditionally independent of each other, right? What you've generated so far should have completely
01:07:15.000 | explained them. And then what you generate after should again be-- they should be conditionally
01:07:20.720 | independent, right? So how do you learn these conditional independences? Yeah. And if somebody
01:07:24.400 | walked up to me and gave them to me, I think they'd probably learn them. Yeah.
01:07:28.880 | Christian?
01:07:29.880 | [INAUDIBLE]
01:07:30.880 | Yeah.
01:07:31.880 | [INAUDIBLE]
01:07:32.880 | Yeah.
01:07:33.880 | [INAUDIBLE]
01:07:34.880 | Yeah.
01:07:35.880 | I think more of his thinking is that only scaling small and small doesn't help them
01:07:46.880 | to actually learn how the real world actually works. And we have a good idea of truth and
01:07:57.380 | real world now. And do you agree with him? Do you think that [INAUDIBLE]
01:08:08.760 | So yeah, I think it's interesting. You can't learn a word model with just language, right?
01:08:16.680 | So I mean, some of these models are not exactly being learned that way. You're doing RLHFs.
01:08:20.400 | You're getting some feedback, which means there's some-- you're applying some-- they
01:08:26.680 | are modifying themselves to some preference, right? So it's not just a pure language model.
01:08:33.240 | But it's interesting. So you've seen some of the work where robotics is now potentially
01:08:37.840 | starting to flourish because they're able to use these large models as planners, right?
01:08:43.040 | And so I think that it's surprising how much of the world-- how much information about
01:08:47.400 | the world that they carry. And if I understand, is that right that the SACAN were basically
01:08:51.320 | used a language model now as a planner, right? And then they left the rest of it to just
01:08:55.960 | the standard perception and the classical tasks of even solving the robotics. So that's
01:09:01.240 | a-- I mean, that's-- no, while Jan is probably still right, but the usefulness of it is evident
01:09:07.920 | in something that needs world knowledge, right?
01:09:11.240 | So I think you can do a lot with what you have. I mean, they're probably-- yeah, I mean,
01:09:21.500 | we still haven't quite extracted all the usefulness out of these models as well. And you might
01:09:27.560 | be right in some things. But there's still a lot more to be gained. Yeah.
01:09:35.520 | So I'm similar to the previous question, and you're also talking about immersion, right?
01:09:41.480 | I'm just curious to know what your thoughts are more on generalizability and immersion,
01:09:47.920 | especially in the-- I know there was a paper from DeepMind about the science-- yeah, I
01:09:54.040 | think-- yeah.
01:09:55.040 | Yeah, yeah, yeah.
01:09:56.040 | Like, they can't really generalize outside of what they've been trained on as-- especially
01:09:59.600 | because these large models now that they're just trained on everything. Is there truly
01:10:03.560 | anything left that's out of distribution that you could really sort of benchmark it on?
01:10:08.600 | So I have been caught saying that if I had all my test data in my training, I'd make
01:10:12.520 | a billion dollars. Yeah. So I don't have a problem with it. But I still think-- so OK,
01:10:19.320 | so correct me if I'm wrong, but the general argument is that these models have learned
01:10:25.400 | such a vast set of distributions and phenomena that typically, when you interrogate them,
01:10:32.360 | they're often very cleverly blending or bringing information from what they've learned, right?
01:10:40.720 | It might, yes. And then they have these algorithmic tasks where the models fail to generalize,
01:10:46.640 | right?
01:10:47.640 | So I'll focus on the former. I think that that's an incredibly useful property. It might
01:10:54.680 | be that-- so I think maybe the feeling is that we actually don't quite understand how
01:10:59.720 | much we could-- how much is even represented in text. And second, how much-- how far we
01:11:05.240 | could go if we were able to blend information from different-- like, certainly being able
01:11:11.560 | to write about the Stanford-- this lecture in the rhyme meter and words of Chaucer, not
01:11:17.840 | possible because nobody did it, right? But I think that you could do it, right?
01:11:22.160 | Now, is that blending information from what you already have? If so, that's-- that means
01:11:27.160 | you can-- that's an incredible skill, right? Yeah, I haven't read it. It's very recent,
01:11:35.560 | but I believe the work. I think you can show that in these [INAUDIBLE] but I think there's
01:11:40.080 | a surprising amount of new-- seemingly new things you could do by just blending information
01:11:47.120 | from what you've already learned. And yeah, it largely probably has to do with-- there's
01:11:52.080 | so much of it. Yeah, yeah. So you have a question? Yeah, I have two questions to go. [INAUDIBLE]
01:12:00.960 | I think I had an ordering in mind and then I came back to you. Sorry. But [INAUDIBLE]
01:12:08.800 | Give me a second. [INAUDIBLE] I was wondering if you might have insights into connecting
01:12:15.120 | different agents, transformers, or whatnot. Neurons is a great-- I feel like transformers
01:12:21.920 | essentially like a great connection of neurons in a specific way and it's awesome, right?
01:12:27.120 | So you figured out the best way to connect them so far.
01:12:30.040 | The agents? No, the neurons. Oh, the neurons. You're talking about-- do
01:12:33.520 | I know somehow to do this in the brain? No, the neurons in the transformer, right?
01:12:38.120 | The transformer is the way you connect different pieces together. And then when you connect
01:12:43.880 | them together, it works. Yeah. [INAUDIBLE] I was wondering if you have some insights
01:12:48.240 | in the building system that can actually go perform the best together.
01:12:52.480 | Yeah. [INAUDIBLE] I like to make this joke that the best agents are actually just the
01:12:58.840 | neurons because they can communicate with each other. They can update themselves really,
01:13:02.960 | really well by what the other agents are doing. What is the fundamental problem by making--
01:13:09.840 | what is the fundamental issue in making a bunch of-- I'm trying to understand what are
01:13:16.560 | the fundamental problems in trying to make a bunch of systems work together, if that's
01:13:19.760 | what you're asking. One is goal decomposition, right? And one is the second big one is coordination,
01:13:27.200 | and third one is verification. If you solved a successful decomposition of the goals based
01:13:32.160 | on what your estimate of the skills of these agents are, if you're able to do what they've
01:13:36.920 | done, and if you're able to coordinate, then I think you could make a lot of progress,
01:13:40.840 | right? So while I didn't answer your question, I don't know in general how much progress
01:13:45.320 | you've made in all these three areas. But does somebody have any input here?
01:13:50.360 | [INAUDIBLE] and you have something that's [INAUDIBLE] and you want to verify this [INAUDIBLE]
01:14:00.120 | and make sure [INAUDIBLE] and verify everything and make it big enough. You can see how this
01:14:12.480 | is almost [INAUDIBLE] everything and making it efficient over time. And it's a lot of
01:14:18.800 | time [INAUDIBLE] how do you break the stuff, how do you [INAUDIBLE]
01:14:25.800 | Yeah, right. But I think these [INAUDIBLE] are probably maybe to some degree [INAUDIBLE]
01:14:32.360 | What's on mind? [INAUDIBLE]
01:14:34.720 | It's actually one question. So [INAUDIBLE] now we have a [INAUDIBLE] but the human brain
01:14:44.400 | is very modular. So it's modularity like the emergence phenomena, you need some spatial
01:14:53.280 | space to make that happen. Yeah, and by modularity here you mean that
01:14:58.440 | is it modularity in that they have this vision, has this responsibility, or even is the composition
01:15:06.000 | different, the construction different? What do you mean by that? Because you could have
01:15:11.440 | both, right? You could argue that there's no-- the responsibility is diffused across
01:15:15.360 | the model. And it's just that experts try to go in the opposite direction, which I should
01:15:20.040 | probably mention. That's another really exciting direction, which certainly has happened in
01:15:23.800 | a few folders, and it's going to stick. I totally missed it. That tries to get the specialization,
01:15:29.680 | right? So maybe that is some kind of modularity, right? Learn modularity. The rest of responsibility
01:15:36.440 | for performing the task is likely distributed. But if now you're going to these subsystems
01:15:41.520 | themselves of different composition, then you get back to-- and I know that this was
01:15:47.200 | a goal with the Pathways Project at Google, where you wanted to have these really modular
01:15:52.360 | systems communicate with each other. And I think there's-- it's just taken so long to
01:15:57.640 | get gradient descent. In fact, sometimes I think that rigid building architectures deserve
01:16:02.360 | gradient descent. And I feel like if you can learn with gradient descent, it's very useful.
01:16:11.040 | Maybe it's actually possible to make these modular systems work. We have some of the
01:16:14.080 | three experts, and I imagine some of these problems that we discussed before. Does that
01:16:21.880 | make sense?
01:16:22.880 | Sorry, circling back to whatever seven questions ago, you mentioned that the problem with decoding
01:16:29.400 | all at once was one of the things that code generating all at once has this assumption
01:16:33.960 | that the outputs are conditionally independent. But aren't they, in a sense that if you have
01:16:38.280 | a latent space-- if you're given the latent space as your prior, then your posterior
01:16:42.720 | outputs should be conditionally independent of each other, right?
01:16:45.520 | So great point. And where do you get the latent space from?
01:16:48.920 | Well, from the encoder, or whatever, in the beginning.
01:16:51.840 | Right, but there might be quite a few ways to translate something, right? Yeah, there's
01:16:57.280 | a multiple-- so if there's only one mode, then yeah, it's probably [INAUDIBLE] right?
01:17:03.160 | But if there's multiple ways of-- well, actually, there's two things. How much does the latent
01:17:07.760 | space actually carry? That was an important thing to ask, right? How much does it actually
01:17:11.880 | carry? Because it's not just the one latent vector that you're transmitting every-- you're
01:17:16.720 | doing attention again and again. But we took this approach, where we did precisely this.
01:17:25.000 | We autoregressively generated tokens in a new vocabulary using vector quantization.
01:17:33.920 | So the conditional dependence was modeled in a latent space, where we discretized using
01:17:40.480 | vector quantization. And then, based on that, we generated everything conditionally independent.
01:17:45.800 | And that didn't work. But again, so that didn't work in translations. The issue-- there were
01:17:52.600 | some funky issues there, where the latent-- the latent sequence of latent vectors were
01:18:00.280 | only effective-- were not effective if you can learn directly on the original data. You
01:18:03.960 | have to do something like distillation. Because distillation itself throws away, potentially,
01:18:08.360 | some of the modes. So generally, lower entropy data was-- we had to train on it.
01:18:12.640 | The second piece was, for practical systems, you have to make the whole thing really, really
01:18:17.080 | fast. But this was a good research exercise. But ultimately, it didn't have the right practical
01:18:23.040 | impact. Because speculative decoding, practically, with what we have right now didn't work well.
01:18:27.440 | [INAUDIBLE]
01:18:28.800 | Yeah, exactly. Yeah. But you're right. I think if you can generate a sufficiently-- if you
01:18:33.520 | can generate a good, sufficient latency, then yes, you're right. We can assume-- that makes
01:18:38.560 | everything conditionally independent. Yeah. And we managed to do that a bit. But it wasn't
01:18:43.800 | quite good, I think.
01:18:48.160 | I guess this is the last question, now? Or are we already done now?
01:18:52.120 | [INAUDIBLE]
01:19:00.240 | Oh, wow. That's too personal.
01:19:01.760 | [INAUDIBLE]
01:19:05.280 | And I have friends there. They're all really great. They're doing terrible things. I think
01:19:13.080 | that there's-- we'll be surprised how much there is to do. And if-- so first, the motivation,
01:19:20.560 | right? That is an entire new-- there's an entire new bucket of-- or like a new tranche
01:19:28.960 | of capabilities that you will get with human-computer interaction. So you can make a product. People
01:19:33.160 | use it. They give you feedback. Models get smarter. And this closed-loop system can really
01:19:38.680 | bring-- can really advance models. And then bring value, right? That's one.
01:19:45.160 | And I think it's helpful to have some deep learning benefit. It's so much from a diversity
01:19:52.720 | of ideas and people pursuing important directions. And I would say the same about building company
01:20:02.800 | products, as well, or building companies that are building new kinds of products with these
01:20:10.160 | models, right? So I would say that we have-- there's so much surface area that we could
01:20:16.160 | build something incredible. So that's the second piece. Third, yeah. Maybe that's the
01:20:23.360 | more personal direction I want to bring on, right? Yeah.
01:20:31.320 | [END PLAYBACK]
01:20:32.880 | [BLANK_AUDIO]