Intro to Machine Learning: Lesson 4
Chapters
0:00:8 How Do I Deal with Version Control and Notebooks
12:25 Max Features
21:15 Feature Importance
38:27 Random Forest Feature Importance
41:9 Categorical Variables
44:37 One-Hot Encoding
55:26 Dendrogram
55:31 Cluster Analysis
59:3 Rank Correlation
67:42 Partial Dependence
70:8 Gg Plot
70:34 Ggplot
72:40 Locally Weighted Regression
75:5 Partial Dependence Plot
75:16 Partial Dependence Plots
81:45 Purpose of Interpretation
81:50 Why Do You Want To Learn about a Data Set
83:10 Goal of a Model
87:40 Pdp Interaction Plot
92:35 Tree Interpreter
94:4 The Bias
99:5 Bias
00:00:00.000 | Alright welcome back
00:00:02.000 | Something to mention somebody asked on the forums really good question was like
00:00:08.320 | How do I deal with version control and notebooks?
00:00:12.320 | the question was something like every time I change the notebook Jeremy goes and changes it on git and then I do a
00:00:18.040 | git pull and I end up with a conflict and
00:00:20.040 | Blah blah blah and that's that happens a lot with notebooks because notebooks behind the scenes are JSON files
00:00:28.080 | Which like every time you run even a cell without changing it
00:00:31.840 | It updates that little number saying like what numbered cell this is and cells now suddenly there's a change and so trying to merge
00:00:38.040 | notebook changes as a nightmare
00:00:40.680 | so
00:00:42.080 | My suggestion like a simple way to do it is is when you're looking at
00:00:47.040 | some notebook
00:00:50.600 | Like lesson 2 RF interpretation you want to start playing around with this
00:00:57.320 | First thing I would do would be to go file
00:00:59.520 | make a copy and
00:01:02.200 | Then in the copy say file rename and give it a name that starts with TMP
00:01:06.880 | So that will hide it from get right and so now you've got your own version of that notebook that you can
00:01:12.480 | That you can play with okay
00:01:14.400 | And so if you're not or get pool and see that the original changed it won't conflict with yours and you can now see
00:01:19.680 | There are two different versions
00:01:24.040 | There are different ways of kind of dealing with this Jupiter notebook get problem like everybody has it one one is there are some hooks
00:01:30.680 | You can use it like remove all of the cell outputs before you commit to get but in this case
00:01:36.100 | I actually want the outputs to be in the repo so you can read it on github and see it
00:01:40.560 | So it's a minor issue, but it's it's something which
00:01:44.640 | catches everybody
00:01:47.320 | Yes
00:01:49.320 | Before we move on to interpretation of the random forest model, I wonder if we could summarize the relationship between the
00:02:00.040 | hyperparameters on the random forest and its
00:02:03.320 | Effect on you know over fitting and dealing with collinearity and yada yada. Yeah, that sounds like a question born from experience
00:02:11.820 | absolutely
00:02:15.480 | so I
00:02:17.480 | Gotta go back to lesson 1 RF
00:02:20.040 | If you're ever unsure about where I am you can always see my top here courses ml1 lesson 1 on earth
00:02:25.760 | In terms of the hyper parameters that
00:02:32.440 | Are interesting and I'm ignoring I'm ignoring like pre-processing, but just the actual hyper parameters
00:02:42.320 | The first one of interest I would say is the set RF samples
00:02:46.540 | command which determines how many
00:02:49.800 | Rows are in each sample so in each tree you're created from how many rows
00:02:55.840 | And each tree
00:02:59.600 | So before we start a new tree we either bootstrap a sample
00:03:05.440 | so sampling with replacement from the whole thing or we pull out a
00:03:09.240 | Subsample of a smaller number of rows, and then we build a tree from there, so
00:03:14.480 | So step one is we've got our whole big data set and we grab a few rows at random from it
00:03:23.640 | And we turn them into a smaller data set and then from that we build a tree right so
00:03:29.800 | That's the size of that is set RF samples, so when we change that size
00:03:35.040 | Let's say this originally had like a million rows
00:03:39.000 | And we said set RF samples 20,000 right and then we're going to grow a tree from there
00:03:45.440 | Assuming that
00:03:49.240 | The tree remains kind of balanced as we grow it can somebody tell me how many layers deep
00:03:56.040 | Would this tree be and assuming we're growing it until every leaf is of size one. Yes
00:04:02.160 | log base 2 of 20,000
00:04:05.580 | Right okay, so the the depth of the tree
00:04:13.540 | Doesn't actually vary that much depending on the number of samples right because it's it's
00:04:19.980 | Related to the log of the size
00:04:23.540 | Can somebody tell me at the very bottom so once we go all the way down to the bottom how many?
00:04:29.780 | Leaf nodes would there be?
00:04:35.340 | Speak up what?
00:04:37.340 | 20,000 right because every single leaf node has a single thing in it, so we've got
00:04:43.280 | Obviously a linear relationship between the number of leaf nodes in the size of the sample
00:04:48.740 | So when you decrease the sample size
00:04:53.620 | It means that there are less kind of
00:04:58.460 | Final decisions that can be made right so therefore the tree is is
00:05:03.580 | Going to be less rich in terms of what it can predict because it's just making less different individual decisions, and it also is making
00:05:11.140 | Less binary choices to get to those decisions, so therefore
00:05:15.860 | Setting our samples lower is going to mean that you over fit less
00:05:21.940 | But it also means that you're going to have a less
00:05:26.660 | Accurate individual tree model right and so remember the way
00:05:30.840 | Brian and the inventor of random forest describe this is that you're trying to do two things when you build a model
00:05:36.580 | when you build a model with bagging
00:05:38.820 | one is that
00:05:41.220 | Each individual tree or as SK loan would say each individual estimator
00:05:46.080 | Is as
00:05:50.820 | Accurate as possible right on the training set
00:05:55.020 | So it's like each model is a strong predictive model, but then the across the estimators
00:06:02.240 | The correlation between them is as low as possible
00:06:12.220 | So that when you average them out together you end up with something that generalizes
00:06:17.820 | So by decreasing the set RF samples number
00:06:21.700 | We are actually decreasing the power of the estimator and increasing the correlation
00:06:26.460 | And so is that going to result in a better or a worse validation set result for you?
00:06:31.680 | It depends right this is the kind of compromise which you have to figure out when you do
00:06:38.160 | machine learning models
00:06:40.860 | Can you pass that back there
00:06:44.340 | If I wait if I put the OV value
00:06:50.940 | So it is it is basically dividing every third it ensures that
00:06:54.500 | Every data won't be there in each tree, right? The OOP second
00:06:59.960 | We if I put OV equal to true. Yeah
00:07:03.220 | Yeah, so isn't that make sure that out of my entire data a different personal data won't be there in every tree
00:07:11.540 | So all our vehicles true does is it says?
00:07:17.060 | Whatever your subsample is it might be a bootstrap sample or it might be a
00:07:22.180 | subsample
00:07:25.340 | Take all of the other rows
00:07:27.380 | Right and put them into a for each tree and put them into a different data set and
00:07:32.980 | Calculate the the error on those so it doesn't actually impact training at all
00:07:39.140 | It just gives you an additional metric which is the OAB error. So if you
00:07:45.540 | Don't have a validation set
00:07:47.540 | Then this allows you to get kind of a quasi validation set for free
00:07:55.020 | If you want to
00:08:00.940 | Set out a sample
00:08:03.180 | RF sample
00:08:05.900 | so the the default is
00:08:07.900 | actually if you say reset RF samples and
00:08:15.060 | That causes it to bootstrap. So it all sample a new data set as big as the original one, but with replacement
00:08:21.980 | Okay, so obviously the second benefit of set our samples is that you can run
00:08:33.020 | More quickly and particularly if you're running on a really large data set like a hundred million rows
00:08:38.140 | You know it won't be possible to run it on the full data set
00:08:41.620 | So you'd either have to pick a subsample if you yourself before you start or you set RF samples
00:08:46.940 | The second key parameter that we learned about was min samples leaf
00:08:53.940 | Okay, so if I changed min samples leaf before we assumed that min samples leaf was equal to
00:09:02.900 | 1
00:09:05.620 | Alright if I set it equal to 2
00:09:09.220 | Then what would be my new?
00:09:11.220 | Depth how deep would it be?
00:09:13.980 | Yes log base 220,000 minus 1 okay, so each time we double them in samples leaf we're removing one layer from the tree
00:09:27.100 | and
00:09:29.540 | Fine I'll come back to you again since you're doing so well. How many leaf nodes would there be in that case?
00:09:34.700 | What how many leaf nodes would there be in that case?
00:09:42.280 | 10,000 okay, so we're going to be again dividing the number of leaf nodes by that number so
00:09:52.780 | The result of increasing min samples leaf is that now each of our leaf nodes has more than one thing in so we're going to get
00:10:00.420 | A more stable average that we're calculating in each tree, okay
00:10:05.520 | We've got a little bit less depth
00:10:11.140 | Okay, we've got less decisions to make and we've got a smaller number of leaf nodes so again
00:10:15.140 | We would expect the result of that would be that each estimator would be less predictive
00:10:20.460 | But the estimators would be also less correlated so again this might help us to avoid overfitting
00:10:28.700 | Could you pass the microphone over here please?
00:10:31.420 | Hi Jeremy, I'm not sure if
00:10:35.860 | In that case every node will have exactly - no it won't necessarily have exactly - and I thank you for mentioning that
00:10:42.940 | So it might try to do a split and so one reason well what would be an example 10 she that you?
00:10:50.300 | Wouldn't split even if you had a hundred nodes what might be a reason for that
00:10:55.660 | Sorry a hundred items in a leaf node. They're all the same. They're all the same in terms of
00:11:01.500 | Well once the independent saw the dependent
00:11:05.640 | And it has the dependent right I mean I guess either but much more likely would be the dependent so if you get to a leaf
00:11:13.380 | node where
00:11:15.380 | Every single one of them has the same option price or in classification like every single one of them is a dog
00:11:20.900 | Then there is no split that you can do that's going to improve your information
00:11:25.020 | All right, and remember information is the term. We use in a kind of a general sense in random for us to describe
00:11:31.940 | the amount of
00:11:35.180 | Difference about about additional information we create from a split is like how much are we improving the model?
00:11:40.580 | So you'll often see this in this word information gain
00:11:43.140 | Which means like how much better did the model get by adding an additional split point?
00:11:47.840 | And it could be based on RMSE or it could be based on cross entropy or it could be based on how different to the standard
00:11:54.020 | Deviations or whatever so that's just a general term
00:11:56.740 | Okay, so that's the second thing that we can do which again
00:12:00.060 | It's going to speed up our training because it's like one less set of decisions to make
00:12:04.700 | Remember even though there's one less set of decisions those decisions like have as much data again as the previous set
00:12:12.880 | So like each layer of the tree can take like twice as long as the previous layer
00:12:16.340 | So it could definitely speed up training and it could definitely make it generalize better
00:12:23.260 | So then the third one that we had was
00:12:25.900 | max features
00:12:28.460 | Who wants to tell me what max features?
00:12:31.200 | does
00:12:33.860 | I don't know pass that back over there
00:12:36.140 | Okay, Vinay
00:12:40.180 | Features the dimensions how many features you're going to use in each tree in this case
00:12:46.260 | It's a fraction up. So you're going to use half of the features for each tree
00:12:52.860 | Nearly right or kind of right? Can you be more specific or can somebody else be more specific? It's not exactly for each tree
00:12:59.180 | essentially
00:13:01.820 | That is it for each tree randomly sample half of the
00:13:07.380 | So not quite. It's not for each tree. So the the set don't pass it to Karen. So the set RF samples picks a
00:13:15.860 | Picks a subset of samples subset of rows for each tree
00:13:23.660 | But min samples leaf. Sorry that max features doesn't quite do that. It's not something different
00:13:29.060 | Yeah, right
00:13:39.820 | So it kind of sounds like a small difference, but it's actually quite a different way of thinking about it
00:13:44.620 | Which is we do our set RF samples
00:13:47.140 | So we pull out our sub sample or a bootstrap sample and that's kept for the whole tree
00:13:52.300 | And we have all of the columns in there, right and then with
00:13:56.300 | Max features equals 0.5 at each point we then at each split we pick a different half of
00:14:04.420 | The features and then here we'll take a pick a different half of the features and here we'll pick a different half of the features
00:14:10.020 | And so the reason we do that is because we want the trees to be as as rich as possible
00:14:16.780 | Right, so particularly like if you if you were only doing a small number of trees like you had only ten trees
00:14:22.340 | And you pick the same column set all the way through the tree
00:14:27.020 | You're not really getting much variety and what kind of things are confined. Okay, so this this way at least in theory
00:14:34.100 | Seems to be something which is going to give us a better set of trees is picking a different
00:14:39.860 | Random subset of features at every decision point
00:14:47.540 | So the overall effective max features again, it's the same it's going to mean that the each individual tree is probably going to be
00:14:55.260 | less accurate
00:14:57.620 | But the trees are going to be more varied and in particular here
00:15:01.780 | This can be critical because like imagine that you've got one feature. That's just super predictive
00:15:08.140 | It's so predictive that like every random sub sample you look at always starts out by splitting on that same feature
00:15:14.700 | Then the trees are going to be very similar in the sense like they all have the same initial split, right, but
00:15:20.720 | There may be some other interesting initial splits because they create different interactions of variables. So by like half the time
00:15:28.780 | That feature won't even be available at the top of the tree
00:15:32.240 | So half at least half the trees are going to have a different initial split so it definitely can give us more
00:15:37.580 | Variation and therefore again it can help us to create more generalized trees that have less correlation with each other
00:15:44.580 | Even though the individual trees probably won't be as predictive
00:15:47.660 | In practice, we actually looked at have a little picture of this that as as you add more trees
00:15:54.700 | Right if you have max features equals none that's going to use all the features every time
00:15:59.900 | Right then with like very very few trees that can still give you a pretty good error
00:16:04.700 | but as you create more trees
00:16:07.540 | It's not going to help as much because they're all pretty similar because they're all trying every single variable
00:16:14.720 | Where else if you say max features equals square root or max pictures equals log 2
00:16:18.960 | Then as we add more estimators, we see improvements
00:16:23.660 | Okay, so there's an interesting interaction between those two and this is from the SK learn docs this cool little chart
00:16:29.920 | Okay
00:16:32.640 | So then things which don't impact our training at all and jobs
00:16:37.720 | Simply says how many CPU how many cores do we run on? Okay, so it'll make it faster
00:16:43.640 | Up to a point generally speaking making this more than like eight or so. They may have diminishing returns
00:16:50.440 | Minus one says use all of your cores
00:16:53.080 | So there's I don't know why the default is to only use one core. That's seems weird to me
00:17:01.360 | You'll definitely get more performance by using more cores because all of you have computers with more than one core nowadays
00:17:07.060 | And then our B score equals true
00:17:11.600 | Simply allows us to see the OOB
00:17:14.200 | Score if you don't say that it doesn't calculate it and particularly if you had set RF samples pretty small compared to a big data
00:17:22.680 | Set OOB is going to take forever to calculate
00:17:25.360 | Hopefully at some point we'll be able to fix the library so that doesn't happen
00:17:29.080 | There's no reason it need be that way but right now that's that's how the library works
00:17:34.160 | Okay
00:17:37.320 | So there are
00:17:40.080 | Base, you know key basic parameters that we can change there are
00:17:44.480 | More that you can see in the docs or shift tab to have a look at them
00:17:48.880 | But the ones you've seen are the ones that I've found useful to play with so feel free to play with others as well
00:17:54.680 | And generally speaking, you know max features of as I said max features of like either
00:18:01.240 | None
00:18:05.640 | Means all of them
00:18:09.640 | about 0.5
00:18:11.640 | or
00:18:14.400 | Square root
00:18:17.920 | Or log, you know kind of those
00:18:20.200 | Trees seem to work pretty well and then for min samples leaf
00:18:24.600 | You know, I would generally try kind of
00:18:28.320 | 135 10
00:18:31.640 | 25
00:18:33.000 | You know 100 and like as you start doing that if you notice by the time you get to 10
00:18:37.280 | It's already getting worse that there's no point going further if you get to a hundred it's still going better
00:18:41.680 | Then you can keep trying right? But they're the kind of
00:18:44.600 | General amounts that most things need to sit in
00:18:47.760 | All right
00:18:51.720 | so random for us interpretation
00:18:54.400 | is something which
00:18:57.160 | You could use to create some really cool Kaggle kernels now
00:19:01.760 | Obviously one issue is the fast AI library is not available in Kaggle kernels
00:19:07.120 | But if you look inside fast AI structured, right and remember you can just use
00:19:12.640 | Double question mark to look at the source code for something or you can go into the editor to have a look at it
00:19:18.960 | You'll see that most of the methods we're using are a small number of lines of code in this library and have no
00:19:25.880 | Dependencies on anything so you could just copy that
00:19:28.640 | Little if you need to use one of those functions just copy it into your kernel
00:19:33.920 | And and if you do just say this is from the fast AI library
00:19:37.280 | You can link to it on github because it's available on github as open source, but you don't need to
00:19:42.200 | Import the whole thing right?
00:19:44.200 | So this is a cool trick is that because you're the first people to learn how to use these tools you can start to show
00:19:49.940 | Things that other people haven't seen right? So for example this confidence based on tree variance is something which doesn't exist anywhere else
00:19:58.640 | feature importance definitely does and that's already in quite a lot of Kaggle kernels if you're looking at a
00:20:04.240 | Competition or a data set that where nobody's done feature importance
00:20:07.160 | Being the first person to do that is always going to win lots of votes because it's like the most important thing is like
00:20:13.480 | Which features are important?
00:20:15.480 | So last time we let's just make sure we've got our tree data
00:20:27.160 | So we need to change this to add one extra thing all right, so that's going to load in that data
00:20:32.880 | It is our data, okay?
00:20:38.720 | So as I mentioned when we do a model interpretation
00:20:46.280 | I tend to set RF samples to some subset something small enough that I can run a model in under 10 seconds or so
00:20:53.960 | Because there's just no point run running a super accurate model 50,000 is more than enough
00:20:59.560 | To see you'll basically see each time you run an interpretation
00:21:04.600 | You'll get the same results back and so as long as that's true, then you you're already using enough data, okay?
00:21:10.440 | So feature importance we learnt it works by randomly shuffling a column
00:21:23.920 | Each column one at a time and then seeing how accurate the model the pre-trained model the model we've already built is
00:21:30.160 | When you pass it in all the data as before but with one column shuffled
00:21:35.800 | so
00:21:38.400 | Some of the questions I got after class kind of
00:21:43.200 | reminded me that it's very easy to
00:21:47.320 | under appreciate how
00:21:51.160 | powerful and kind of magic this approach is
00:21:54.240 | And so to explain I'll mention a couple of the questions that I heard so one question was like
00:22:01.840 | Why don't we or what if we just create took one column at a time and created a tree on?
00:22:09.520 | Just each one column at a time, so we've got our data set. It's got a bunch of columns
00:22:14.840 | So why don't we just like grab that column and just build a tree from that right?
00:22:19.880 | And then like we'll see which which columns tree is the most predictive?
00:22:24.800 | Can anybody tell me?
00:22:27.520 | Why what why that may give misleading results about feature importance?
00:22:32.960 | Okay
00:22:36.400 | Okay
00:22:45.000 | We just shuffle them it will be at randomness and we were able to both capture the interactions and the importance of the picture
00:22:52.760 | It's great. Yeah, and and so
00:22:54.840 | This issue of interactions is not a minor detail. It's like
00:22:59.720 | It's massively important. So like think about this
00:23:03.800 | bulldozers data set where for example where there's one field called year made and
00:23:09.880 | There's one field called sale date
00:23:14.020 | and like
00:23:16.020 | If we think about it
00:23:18.060 | It's pretty obvious that what matters is the combination of these two which in other words is like
00:23:23.460 | How old is the piece of equipment when it got sold so if we only included one of these?
00:23:29.380 | We're going to massively underestimate how important that feature is now
00:23:34.540 | Here's a really important point though if you
00:23:40.460 | It's pretty much always possible to create a simple like logistic regression
00:23:46.300 | Which is as good as pretty much any random forest if you know ahead of time
00:23:51.980 | Exactly what variables you need exactly how they interact exactly how they need to be transformed and so forth, right?
00:23:58.380 | So in this case, for example, we could have created a new field which was equal to year made
00:24:04.300 | So sale date or sale year minus year made and we could have fed that to a model and got you know
00:24:11.460 | Got that interaction for us. But the point is
00:24:14.660 | We never know that like you never like you might have a guess of it
00:24:19.980 | I think some of these things are interacted in this way and I think this thing we need to take the log and so forth
00:24:24.540 | But you know, the truth is that the way the world works the causal structures, you know
00:24:30.660 | They've got many many things interacting in many many subtle ways
00:24:34.260 | Right. And so that's why using trees whether it be gradient boosting machines or random forests works so well
00:24:41.740 | So can you pass that to Terrence, please?
00:24:44.780 | One thing that
00:24:50.100 | Did me years ago was also I tried that
00:24:54.020 | Doing one variable at a time thinking. Oh, well, I'll figure out which one's most correlated with the dependent variable
00:25:00.660 | but what it doesn't
00:25:03.180 | Pull apart is that what if all variables are basically copied the same variable then they're all going to seem equally important
00:25:10.340 | But in fact, it's really just one factor
00:25:12.620 | Yeah, and that's also true here. So if we had like a column
00:25:18.660 | appeared twice
00:25:21.220 | Right then shuffling that column isn't going to make the model much worse, right? There'll be if you think about like how it was built
00:25:29.860 | Some of the times particularly if we had like max features is 0.5
00:25:33.780 | And some of the times we're going to get version a of the column some of the times you get going to get version
00:25:37.900 | B of the column, so like
00:25:39.740 | half the time
00:25:41.740 | Shuffling version a of the column is going to make a tree a bit worse half the time
00:25:45.980 | It's going to make you know column B or make it a bit worse. And so it'll show
00:25:49.060 | that both of those features are
00:25:51.980 | somewhat important
00:25:54.980 | And it'll kind of like share the importance between the two features. And so this is why
00:25:59.740 | A-rack collinearity but collinearity literally means that they're linearly related. So this isn't quite right
00:26:08.580 | But this is why having two variables that are related closely related to each other or more variable sort of closely related to each other
00:26:16.620 | Means that you will often
00:26:18.780 | Underestimate their importance using this this random forest technique
00:26:25.260 | Yes, Terrence and so once we've shuffled and we get a a new model
00:26:31.540 | What exactly are the units of these importances? Is this a change in the R squared?
00:26:36.700 | Yeah, I mean it depends on the library. We're using so the units are kind of like I
00:26:41.580 | Never think about them. I just kind of know that like in this particular library
00:26:49.460 | You know 0.005 is often kind of a cutoff. I would tend to use but all I actually care about is is this picture
00:26:56.740 | right, which is the
00:26:58.980 | feature importance
00:27:01.140 | Ordered for each variable and then kind of zooming into turning into a bar plot and I'm kind of like, okay, you know
00:27:07.860 | Here they're all pretty flat and I can see okay
00:27:12.440 | That's about 0.005 and so I remove them at that point and just see like the model
00:27:19.020 | Hopefully the validation score didn't get worse and if it did get worse
00:27:22.460 | I'll just increase this a little bit. Sorry decrease this a little bit until it it doesn't get worse
00:27:27.380 | so yeah, I the the
00:27:30.700 | The units of measure of this don't matter too much and we'll learn later about a second way of doing variable importance
00:27:37.220 | By the way, can you pass that over there?
00:27:39.220 | Is one of the goals here to remove variables that
00:27:47.140 | I
00:27:48.900 | guess your your score will not
00:27:52.100 | Get worse if you remove them. So you might as well get rid of them. Yeah, so that's what we're going to do next. So
00:27:58.860 | So what having looked at our feature importance plot we said, okay, it looks like the ones like less than 0.005
00:28:07.980 | You know a kind of this long tail of
00:28:12.100 | Boringness, so I said let's try removing them, right? So let's just try grabbing the columns where it's greater than 0.005
00:28:19.840 | And I said let's create a new data frame called DF keep which is DF train with just those kept columns
00:28:26.780 | created a new training and validation set with just those columns better than you random forest and I looked to see how the
00:28:34.500 | Validation set score and the validation set RMSE changed and I found they got a tiny bit better
00:28:42.860 | so if they're about the same or a tiny bit better then the thinking my thinking is well, this is
00:28:48.700 | Just as good a model, but it's now simpler. And so now when I redo the feature importance, there's less
00:28:55.700 | collinearity
00:28:57.460 | Right. And so in this case I saw that year made went from being like
00:29:02.080 | Quite a bit better than the next best thing which was coupler system to
00:29:07.700 | Way better than the next best thing. All right, and coupler system went from being like quite a bit more important than the next two
00:29:15.880 | to
00:29:17.540 | Equally important to the next two so it did seem to definitely change these feature importances and hopefully give me some more insight there
00:29:24.660 | So
00:29:31.820 | How does that help our model in general like what does it mean that you're made is now way ahead of the others
00:29:37.660 | Yeah, so we're gonna dig into that kind of now, but basically
00:29:41.860 | It tells us
00:29:44.620 | That for example if we're looking for like how we're dealing with missing values is there noise in the data
00:29:52.620 | You know if it's a high cardinality categorical variable, they're all different steps we would take so for example
00:30:00.180 | If it was a high cardinality categorical variable that was originally a string, right like for example
00:30:05.960 | I think like maybe fi product class description. I remember one of the
00:30:10.640 | Ones we looked at the other day had like first of all was the type of vehicle and then a hyphen and then like the
00:30:16.460 | Size of the vehicle we might look at that and be like, okay. Well, that was an important column
00:30:20.420 | Let's try like splitting it into two on hyphen and then take that bit which is like the size of it and trying
00:30:26.340 | You know pass it and convert convert it into an integer, you know
00:30:29.780 | We can try and do some feature engineering and basically until you know, which ones are important
00:30:33.820 | You don't know where to focus that feature engineering time
00:30:37.700 | You can talk to your client, you know and say, you know
00:30:41.620 | or you know and if you're doing this inside your workplace you go and talk to the folks that like
00:30:47.340 | We're responsible for creating this data
00:30:49.700 | so in this if you were actually working at a
00:30:52.900 | Bulldozer auction company, you might now go to the actual auctioneers and say I'm really surprised that coupler system seems to be driving people's
00:31:01.540 | Pricing decisions so much. Why do you think that might be and they can say to you? Oh, it's actually because
00:31:07.380 | Only these classes of vehicles have coupler systems or only this manufacturer has coupler systems
00:31:13.940 | And so frankly, this is actually not telling you about coupler systems, but about something else and oh, hey that reminds me
00:31:21.060 | That's that that's something else. We actually have measured that it's in this different CSV file
00:31:26.260 | I'll go get it for you. So it kind of helps you focus your attention
00:31:30.620 | So I had a fun little problem this weekend as you know, I introduced a couple of
00:31:38.400 | crazy computations in
00:31:40.980 | Into my random forest and all of a sudden they're like, oh my god
00:31:44.340 | These are the most important variables ever squashing all of the others, but then I got a terrible score
00:31:49.460 | And then is that because?
00:31:51.460 | Now that I think I have my scores computed correctly
00:31:55.420 | What I noticed is that the importance went through the roof, but the validation set
00:32:00.480 | Was still bad or got worse is that because somehow that computation allowed the training
00:32:08.220 | to almost like an identifier map exactly what the answer was going to be for training, but of course that doesn't
00:32:17.500 | Generalize to the validation set. Is that what I is that what I observed
00:32:20.220 | Okay, so there's there's two reasons why your validation score
00:32:25.940 | Might not be very good
00:32:28.940 | Let's go up here
00:32:34.300 | Okay, so we get these five numbers right the
00:32:42.340 | RMSE of the training validation R squared of the training validation and the R squared of the ORB
00:32:49.860 | Okay, so there's two reasons and really in the end what we care about like for this Kaggle competition is the RMSE of the validation
00:32:58.300 | Set assuming we've created a good validation set. So in Terrence's case. He's saying this number is this thing I care about
00:33:06.180 | Got worse when I did some feature engineering. Why is that?
00:33:11.140 | Okay
00:33:12.300 | There's two possible reasons
00:33:14.300 | Reason one is that you're overfitting if you're overfitting
00:33:19.140 | Then your OOB
00:33:21.780 | Will also get worse
00:33:24.100 | If you're doing a huge data set with a small set RF sample, so you can't use an OOB then instead
00:33:31.660 | Create a second validation set which is a random sample
00:33:36.340 | okay, and and do that right so in other words if you're OOB or your random sample validation set is
00:33:43.680 | Has got much worse than you must be overfitting
00:33:47.980 | I think in your case Terrence, it's unlikely. That's the problem because random forests
00:33:56.180 | Don't overfit that badly like it's very hard to get them to overfit that badly
00:34:03.220 | Unless you use some really weird parameters like only one estimator for example like once you've got ten trees in there
00:34:10.620 | There should be enough variation that you're you know
00:34:13.540 | You can definitely overfit but not so much that you're going to destroy your validation score by adding a variable
00:34:19.060 | So I think you'll find that's probably not the case
00:34:22.120 | But it's easy to check and if it's not the case
00:34:24.720 | Then you'll see that your OOB score or your random sample validation score hasn't got worse. Okay
00:34:31.300 | So the second reason your validation score can get worse if your OOB score hasn't got worse
00:34:37.020 | You're not overfitting, but your validation score has got worse
00:34:40.380 | That means you're you're doing something that is true in the training set but not true in the validation set
00:34:47.940 | So this can only happen when your validation set is not a random sample
00:34:54.740 | So for example in this bulldozers competition or in the grocery shopping competition
00:35:00.020 | We've intentionally made a validation set that's for a different date range. It's for the most recent two weeks, right?
00:35:06.620 | And so if something different happened in the last two weeks to the previous weeks
00:35:12.860 | then
00:35:15.460 | You could totally
00:35:17.340 | Break your validation set. So for example
00:35:19.900 | If there was some kind of unique identifier
00:35:23.820 | which is like
00:35:28.340 | Different in the two date periods then you could learn to identify things using that identifier in the training set
00:35:34.220 | But then like the last two weeks may have a totally different set of IDs for the different set of behavior
00:35:38.900 | Could get a lot worse
00:35:41.580 | Yeah, what you're describing is not common though
00:35:46.060 | And so I'm a bit skeptical. It might be a bug
00:35:49.980 | but
00:35:52.620 | Hopefully there's enough
00:35:54.460 | Things you can now use to figure out if it is about we'll be interested to hear what you learn
00:35:58.580 | Okay
00:36:02.620 | so that's that's feature importance and so
00:36:05.860 | I'd like to compare that to
00:36:08.980 | How feature importance is
00:36:12.340 | normally done in
00:36:15.220 | industry and in
00:36:17.380 | academic communities outside of machine learning like in psychology and
00:36:21.220 | Economics and so forth and generally speaking people in those kind of environments tend to use
00:36:26.060 | Some kind of linear regression logistic regression general linear models
00:36:30.620 | So they start with their data set and they basically say that was weird
00:36:35.900 | Oh, okay, so they start with their data set
00:36:41.760 | And they say I'm going to assume that I know
00:36:46.060 | The kind of parametric relationship between my independent variables and my dependent variable
00:36:52.020 | so I'm going to assume that it's a linear relationship say or it's a linear relationship with a
00:36:57.100 | link function like a sigmoid
00:36:59.700 | Listic logistic regression say and so assuming that I already know that I can now write this as an equation
00:37:06.740 | So if we've got like x 1 x 2 so forth, right? I can say all right my y values are equal to
00:37:14.340 | a x 1 plus b x 2
00:37:17.300 | Equals y and therefore I can find out the feature importance easily enough by just looking at these
00:37:24.860 | Coefficients and saying like which one's the highest but it particularly if you've normalized the data first, right? So
00:37:31.540 | There's this kind of trope out there. It's it's very common which is that like this is somehow
00:37:41.460 | More accurate or more pure or in some way better way of doing feature importance
00:37:47.020 | But that couldn't be further from the truth, right? If you think about it if you were like if you were missing an interaction
00:37:55.380 | Right, or if you were missing a transformation you needed
00:37:59.420 | or if you've anyway
00:38:02.220 | Been anything less than a hundred percent perfect in all of your pre-processing
00:38:07.940 | So that your model is the absolute correct truth of this situation, right? Unless you've got all of that correct
00:38:14.460 | Then your coefficients are wrong, right? Your coefficients are telling you in your totally wrong model
00:38:20.680 | This is how important those things are right, which is basically meaningless
00:38:25.020 | So we're also the random forest feature importance. It's telling you in this extremely
00:38:33.540 | High parameter highly flexible functional form with few if any statistical assumptions. This is your feature importance
00:38:40.060 | right
00:38:42.980 | So I would be very cautious, you know and and again
00:38:46.260 | I can't stress this enough when you when you leave m San when you leave this program
00:38:50.780 | You are much more often going to see people talk about logistic regression coefficients
00:38:55.260 | Then you're going to see them talk about random forest variable importance
00:38:58.260 | And every time you see that happen
00:39:00.180 | You should be very very very skeptical of what you're seeing any time you read a paper in economics or in psychology
00:39:05.980 | Or the marketing department tells you they did this regression or whatever
00:39:09.380 | every single time those coefficients are going to be massively biased by
00:39:15.100 | any issues in the model
00:39:17.620 | Furthermore
00:39:21.220 | If they've done so much pre-processing that actually the model is pretty accurate
00:39:25.940 | Then now you're looking at coefficients that are going to be of like
00:39:30.180 | a coefficient of some principal component from a PCA or a coefficient of some
00:39:35.300 | Distance from some cluster or something at which point they're very very hard to interpret anyway
00:39:40.700 | They're not actual variables, right? So they're kind of the two options
00:39:44.260 | I've seen when people try to use classic statistical techniques to do a cover a variable importance equivalent
00:39:51.860 | I think things are starting to change
00:39:58.580 | Slowly, you know, there are there are some fields that are starting to realize that this is totally the wrong way to do things
00:40:03.980 | but it's been
00:40:05.780 | You know nearly 20 years since random forests appeared so it takes a long time, you know people say that the only way that
00:40:13.020 | Knowledge really advances is when the previous generation dies and that's kind of true, right? Like particularly academics
00:40:20.380 | you know, they make a career of being good at a particular sub thing and
00:40:25.260 | You know often don't it, you know, it's not until the next generation comes along that that people notice that
00:40:32.180 | Oh, that's actually no longer a good way to do things. I think that's what's happened here
00:40:36.120 | Okay, so
00:40:40.620 | We've got now a model which isn't really any better as a predictive accuracy wise
00:40:45.380 | But it's kind of we're getting a good sense that there seems to be like four main important things
00:40:52.060 | When it was made the capital system its size and its product classification. Okay, so that's cool
00:40:59.360 | There is something else that we can do however, which is we can do something called one hot encoding
00:41:07.100 | So this is kind of where we're talking about categorical variables. So remember a categorical variable. Let's say we had like
00:41:14.900 | A string hi
00:41:20.900 | And remember the order we got was kind of back weird. It was high low medium. So it was in alphabetical order by default
00:41:27.980 | Right. Was there our original category for like usage band or something? And so we mapped it to 0
00:41:35.020 | 1
00:41:37.140 | 2 right and so by the time it gets into our data frame, it's now a number
00:41:41.740 | So the random forest doesn't know that it was originally a category. It's just a number
00:41:48.260 | Right. So when the random forest is built it basically says, oh is it?
00:41:52.220 | Greater than one or not or is it greater than not or not, you know, basically the two possible decisions it could have made
00:41:59.580 | For
00:42:05.820 | For something with like five or six bands, you know
00:42:10.260 | It could be that just one of the levels of a category is actually interesting
00:42:15.380 | Right. So like if it was like very high
00:42:18.300 | Very low
00:42:21.820 | Or or unknown
00:42:24.460 | Right, then we've know about like six levels and maybe
00:42:28.620 | The only thing that mattered was whether it was like unknown maybe like not knowing its size somehow impacts the price
00:42:34.900 | and so if we wanted to be able to recognize that and particularly if like it just so happened that the way that the
00:42:42.100 | Numbers were coded was it unknown ended up in the middle?
00:42:45.980 | right
00:42:47.980 | Then what it's going to do is it's going to say okay
00:42:50.820 | There is a difference between these two groups, you know less than or equal to two versus greater than two
00:42:56.040 | And then when it gets into this this leaf here, it's going to say
00:43:00.380 | Oh, there's a difference between these two between less than four and greater than or equal to four and so it's going to take two
00:43:06.620 | Splits to get to the point where we can see that it's actually unknown that matters
00:43:13.180 | So this is a little
00:43:15.020 | Inefficient and we're kind of like wasting tree computation and like wasting tree computation matters because every time we do a split
00:43:21.500 | We're halving the amount of data at least that we have to do more analysis
00:43:25.860 | so it's going to make our tree less rich less effective if we're
00:43:30.780 | Not giving the data in a way that's kind of convenient for it to do the work. It needs to do
00:43:36.280 | so what we could do instead is
00:43:42.260 | create
00:43:43.580 | six columns
00:43:45.580 | We could create a column called is very high is very low is high is
00:43:51.700 | Unknown is low is medium and each one would be ones and zeros, right? It's either one or zero
00:43:59.780 | So we had six columns this one moment
00:44:08.940 | So having added six additional columns to our data set
00:44:13.020 | the random forest
00:44:15.740 | Now has the ability to pick one of these and say like oh, let's have a look at is unknown
00:44:21.780 | There's one possible split I can do which is one versus zero. Let's see if that's any good
00:44:26.360 | right, so it actually now has the ability in a single step to pull out a single category level and so
00:44:34.820 | This this kind of coding is called one hot
00:44:39.460 | encoding and
00:44:42.060 | for many many types of machine learning model, this is like
00:44:46.820 | Necessary something like this is necessary like if you're doing logistic regression
00:44:52.740 | You can't possibly put in a categorical variable that goes north through five
00:44:56.620 | Because there's obviously no linear relationship between that and anything right so one hot encoding a
00:45:03.740 | Lot of people incorrectly assume that all machine learning requires one hot encoding
00:45:08.520 | But in this case, I'm going to show you how we could use it optionally and see whether it might improve things sometimes. Yeah
00:45:16.020 | Hi, Jeremy. So if we have six categories like in this case, would there be any problems with adding a column for each of the
00:45:24.560 | Categories, oh because in linear regression we so we had to do it like if there's six categories
00:45:30.260 | We should only do it for five of them. Yeah, so um
00:45:33.020 | It you certainly can say oh, let's not worry about adding is medium because we can infer it from the other five
00:45:42.620 | I would say include it anyway
00:45:47.180 | because like
00:45:49.940 | rather than the otherwise the random forest would have to say is
00:45:53.180 | Very high. No is very low. No is high. No is unknown. No is low
00:45:58.280 | No, okay, and finally I'm there right so it's like five decisions to get to that point. So
00:46:03.660 | the reason in
00:46:06.460 | Linear models that you you need to not include one is because linear models hate co-linearity
00:46:14.140 | But we don't care about about that here
00:46:17.020 | So we can do one hot encoding easily enough and the way we do it is we pass
00:46:27.780 | One extra parameter to procte F. Which is what's the max?
00:46:31.940 | Number of
00:46:35.420 | Categories right so if we say it's seven then anything with
00:46:40.340 | Less than seven levels is going to be turned into one hot encoded bunch of columns
00:46:47.180 | Right so in this case this has got six levels
00:46:50.660 | So this would be one hot encoded where else like zip code has more than six levels
00:46:55.480 | And so that would be left as a number
00:46:57.480 | And so generally speaking you obviously probably wouldn't want a one hot encode
00:47:02.140 | Zip code right because that's just going to create masses of data memory problems computation problems and so forth, right?
00:47:09.200 | So so this is like another parameter that you can play around with so
00:47:13.920 | if I do that
00:47:16.640 | Try it out run the random forest as per usual you can see what happens to the
00:47:23.440 | R squared of the validation set and to the RMSE of the validation set and in this case
00:47:29.280 | I found it got a little bit worse
00:47:31.280 | This isn't always the case, and it's going to depend on your data set
00:47:35.980 | You know do you have a data set where you know single categories tend to be quite important?
00:47:41.320 | Or not in this particular case it didn't make it more predictive however
00:47:48.620 | What it did do is that we now have different features, right?
00:47:52.960 | so the procte F puts the name of the variable and then an underscore and then the level name and
00:47:58.160 | So interestingly it turns out that where else before it said that enclosure
00:48:05.020 | was somewhat important
00:48:07.720 | When we do it as one hot encoded it actually says enclosure E rots with a C is the most important thing
00:48:16.760 | So for at least the purpose of like interpreting your model. You should always try
00:48:22.900 | One hot encoding you know
00:48:25.780 | Quite a few of your variables, and so I often find somewhere around six or seven is pretty good
00:48:31.240 | You can try like making that number as high as you can
00:48:35.800 | so that it doesn't take forever to compute and the feature importance doesn't include like
00:48:43.480 | Really tiny levels that aren't interesting, so that's kind of up to you to play it play around with
00:48:48.040 | But in this case like this is actually I found this very interesting it clearly tells me I need to find out
00:48:56.340 | What enclosure E rops with a C is why is it important because like it means nothing to me
00:49:04.180 | Right and but it's in the most important thing, so I should go figure that out so that I had a question
00:49:10.200 | plus that
00:49:12.840 | so
00:49:14.840 | Can you explain how?
00:49:18.120 | Changing the max number of categories works because for me it just seems like there's five categories your side categories
00:49:23.000 | Oh, yeah, sorry, so it's it's just like
00:49:25.240 | All it's doing is saying like okay. Here's a column called zip code. Here's a column called usage band and
00:49:37.680 | Here's a column sex right. I don't know whatever right and so like zip code has whatever
00:49:44.480 | 5000 levels the number of levels in a category we call its
00:49:49.400 | cardinality
00:49:52.160 | Okay
00:49:53.720 | So it has a cardinality of 5000 usage band maybe has a cardinality of six sex has maybe a cardinality of two
00:50:01.160 | So when Procte F goes through and says, okay, this is a categorical variable should I one hot encode it?
00:50:08.780 | It checks the cardinality against max and cats and says all 5,000 is bigger than seven
00:50:16.120 | So I don't one hot encode it and then it goes to usage band six is less than seven
00:50:22.260 | I do one hot encode it goes to six two is less than seven. I do one thing code it
00:50:27.140 | So it just says for each variable
00:50:30.000 | How do I decide whether the one hot encoded or not in Procte F?
00:50:34.000 | We are keeping both label encodes and one
00:50:36.600 | No, once we decide to one hot encode it does not keep the original variable
00:50:42.520 | Maybe the best
00:50:49.560 | Well, you don't need a labeling code if the if so if the best is an interval it can approximate that with multiple one
00:50:59.640 | hot encoding levels
00:51:01.640 | Yeah, so like, you know, it's a
00:51:05.080 | The the truth is that each column is going to have some
00:51:10.080 | You know different, you know, should it be label encoded or not, you know, which you could make on a case-by-case basis
00:51:17.800 | I find in practice
00:51:19.800 | It's just not that sensitive to this and so I find like just using a single number for the whole data set
00:51:27.960 | Gives me what I need
00:51:29.760 | but you know if you were
00:51:31.760 | Building a model that really had to be as awesome as possible and you had lots and lots of time to do it
00:51:37.160 | You can go through man, you know, don't use property if you can go through manually and decide which things to use dummies or not
00:51:43.140 | You'll see in the code if you look at the code for Procte F
00:51:49.040 | Procte F
00:51:52.520 | Right, like I never want you to feel like
00:51:56.640 | The code that happens to be in the fastai library is the code that you're limited to right? So where is that done?
00:52:03.080 | you can see that
00:52:06.240 | The max ncat gets passed to numerical eyes and numerical eyes
00:52:15.760 | Simply checks, okay, is it a numeric type and it's the number of categories either not
00:52:26.600 | passed to us at all or
00:52:28.440 | We've got more unique that values than there are categories and if so, we're going to use the categorical codes
00:52:34.040 | So for any column where that's where it's skipped over that, right?
00:52:40.120 | So it's remained as a category then at the very end
00:52:42.760 | We just go pandas dot get dummies we pass in the whole data frame and so pandas dot get dummies you pass in a whole
00:52:48.400 | Data frame it checks for anything that's still a categorical variable and it turns it into a dummy variable
00:52:53.680 | Which is another way of saying a one hot encoding. So, you know with that kind of approach you can easily
00:52:58.800 | override it and do your own
00:53:01.680 | dummy verification
00:53:03.400 | variable ization
00:53:05.400 | Did you have a question?
00:53:07.400 | So some data has
00:53:10.840 | Quite obvious order like if you have like a rating system like good bad
00:53:16.040 | Or whatever things like that
00:53:19.840 | There's an order to that and showing that order by doing the dummy variable thing probably will work in your benefit
00:53:27.320 | So is there a way to just force it to leave alone one variable just like convert it beforehand yourself?
00:53:35.680 | Not not in the library
00:53:39.840 | And to remind you like unless we explicitly do something about it. We're not going to get that order
00:53:46.320 | so when we
00:53:49.840 | When we import the data
00:53:51.960 | This is in lesson 1 RF
00:53:57.560 | We showed how
00:54:01.080 | By default the categories are ordered alphabetically
00:54:03.840 | And we have the ability to order them
00:54:07.000 | Properly, so yeah, if you've actually made an effort to turn your ordinal variables into proper ordinals
00:54:17.840 | using
00:54:18.960 | property f
00:54:20.960 | Can destroy that if you have max-end cats
00:54:23.880 | so the simple thing the simple way to avoid that is if we know that we always want to use the codes for usage band rather
00:54:31.640 | than the
00:54:33.640 | You know like never one hot encode it you could just go ahead and replace it right you could just say okay
00:54:39.260 | Let's just go df dot usage band equals df dot usage band dot cat dot codes and it's now an integer
00:54:45.240 | And so it'll never get thing
00:54:47.240 | All right, so
00:54:52.520 | We kind of already seen how
00:54:59.960 | Variables which are basically measuring the same thing can kind of confuse our variable importance
00:55:08.920 | And there can also make our random forests slightly less good because it requires like more computation to do the same thing
00:55:16.160 | There's more columns to check
00:55:18.160 | So I'm going to do some more work to try and remove
00:55:21.720 | redundant features
00:55:23.920 | And the way I do that is to do something called a dendrogram
00:55:27.760 | And it's a kind of hierarchical clustering so cluster analysis
00:55:34.640 | Is something where you're trying to look at objects they can be either rows in a data set or columns and find which ones are
00:55:41.960 | Similar to each other so often you'll see people particularly talking about cluster analysis
00:55:47.320 | They normally refer to rows of data, and they'll say like oh let's plot it
00:55:51.160 | Right and like oh, there's a cluster, and there's a cluster, right?
00:55:56.000 | The common type of cluster analysis time to permitting we may get around to talking about this in some detail is
00:56:03.560 | called K means
00:56:05.560 | Which is basically where you assume that you don't have any labels at all and you take basically a?
00:56:11.440 | Couple of data points at random and you gradually
00:56:17.080 | Find the ones that are near to it and move them closer and closer to centroids and you kind of repeat it again
00:56:23.120 | And again, and it's an iterative approach that you basically tell how many clusters you want
00:56:27.680 | And it'll tell you where it thinks the classes are
00:56:31.560 | Really, and I don't know why but I really underused technique
00:56:35.480 | 20-30 years ago. It was much more popular than it is today is
00:56:39.400 | hierarchical clustering
00:56:42.800 | hierarchical
00:56:45.320 | Also known as agglomerative clustering and in hierarchical or agglomerative clustering
00:56:51.120 | We basically look at every pair of option up every pair of objects and say okay, which two objects are the closest
00:56:59.320 | Right so in this case we might go okay
00:57:01.800 | Those two objects are the closest and so we've kind of like delete them and replace it with the midpoint of the two
00:57:09.560 | And then okay here the next two closest we delete them and replace them with the midpoint of the two
00:57:13.880 | And you keep doing that again and again right since we've got of removing points and replacing them with their averages
00:57:20.000 | You're gradually reducing a number of points
00:57:23.040 | By pairwise combining and the cool thing is you can plot that like so right so if rather than looking at points
00:57:30.640 | You look at variables. We can say okay, which two variables are the most similar that says okay?
00:57:36.440 | Say all year and sale elapsed are very similar so the kind of horizontal axis here is
00:57:42.560 | How similar are the two points that are being compared right so if they're closer to the right?
00:57:48.520 | That means they're very similar so sale year and sale elapsed have been combined and they were very similar
00:57:54.200 | Again it's like who cares you know it'll be like the correlation coefficient or something like that you know in this particular case
00:58:04.960 | What I actually did
00:58:06.760 | So you get to tell it so in this case. I actually used spearmen's are so
00:58:14.480 | You guys familiar with correlation coefficients already, right so correlation is as almost exactly the same as the R squared, right?
00:58:22.640 | But it's between two variables rather than a variable and its prediction the problem with a normal correlation is
00:58:33.640 | that
00:58:36.320 | if the
00:58:38.360 | Get a new workbook here
00:58:42.960 | If you have data that looks like this then you can
00:58:47.480 | Do a correlation and you'll get a good result right, but if you've got data
00:58:52.480 | which looks like
00:58:55.160 | This right and you try and do a correlation and assumes linearity that's not very good, right?
00:59:02.080 | So there's a thing called a rank correlation a really simple idea. It's replace every
00:59:08.880 | point by its rank right so instead of like so we basically say okay. This is the smallest so we'll call that one
00:59:16.680 | Two there's the next one three is the next one four
00:59:20.640 | Five right so you just replace every number by its rank that then you do the same for the y-axis so call that one
00:59:29.760 | two
00:59:32.000 | Three and so forth right and so then you do like a new plot where you don't plot the data
00:59:38.200 | But you plot the rank of the data and if you think about it the rank of this data set is going to look
00:59:44.560 | An exact line because every time something was greater on the x-axis. It was also greater on the y-axis
00:59:51.400 | So if we do a correlation on the rank that's called a rank correlation
00:59:59.380 | Okay, and so
01:00:03.980 | Because I want to find the
01:00:08.160 | Columns that are similar in a way that the random forest would find them similar
01:00:12.680 | Random forests don't care about linearity. They just care about ordering so a rank correlation is the the right way to think about that so
01:00:21.560 | Spearmons are is is the name of the most common rank correlation
01:00:26.480 | But you can literally replace the data with its rank and chuck it at the regular correlation
01:00:30.980 | And you'll get basically the same answer the only difference is in how ties are handled. It's a pretty minor issue
01:00:37.800 | um
01:00:39.800 | Like if you have like a full parabola in that rank correlation, you will not write why right?
01:00:47.080 | It has to be has to be monotonic. Okay. Yeah, yeah
01:00:50.360 | Okay, so
01:00:58.280 | Once I've got a correlation matrix
01:01:00.720 | there's basically a couple of standard steps you do to turn that into a
01:01:05.440 | Dendogram which I have to look up on Stack Overflow each time I do it
01:01:10.120 | You basically turn it into a distance matrix
01:01:13.540 | And then you create something that tells you you know, which things are connected to which other things hierarchically. So this kind of
01:01:20.480 | These two and this step here are like just three standard steps that you always have to do to create a dendrogram
01:01:28.680 | and
01:01:31.480 | So then you can plot it
01:01:33.760 | and so
01:01:35.320 | Alright, so sale year and sale elapsed and be measuring basically the same thing at least in terms of rank
01:01:40.040 | Which is not surprising because sale elapsed is the number of days since the first day in my data set
01:01:47.200 | So obviously these two are nearly entirely correlated with some ties
01:01:51.720 | Grouse attracts and hydraulics flow and coupler system all seem to be measuring the same thing and this is interesting because remember couple system
01:01:59.240 | It said was super important, right?
01:02:01.320 | And so this rather supports our hypothesis that it's nothing to do with whether it's a coupler system
01:02:05.360 | But whether it's whatever kind of vehicle it is. It has these kind of features
01:02:08.860 | Product group and product groups desks seem to be measuring the same thing
01:02:14.480 | Fi based model and Fi model desk seem to be measuring the same thing. And so once we get past that
01:02:20.360 | Everything else like suddenly the things are further away. So I'm probably going to not worry about those
01:02:26.320 | So we're going to look into these one two three four groups that are very similar. She passed that over there
01:02:32.880 | Is it in that graph that the similarity between stick length and enclosure is higher than with stick lens and anything that's higher
01:02:48.120 | Yeah, pretty much
01:02:49.560 | I mean it it's a little hard to interpret but given that stick length and enclosure
01:02:53.880 | Don't join up until way over here
01:02:56.720 | It would strongly suggest that then that they're a long way away from each other
01:03:02.200 | Otherwise you would expect them to have joined up earlier
01:03:04.600 | I mean it's it's possible to construct like a synthetic data set where you kind of end up joining things that were close to each other
01:03:12.200 | through different paths
01:03:14.600 | So you've got to be a bit careful, but I think it's fair to probably assume that stick length or enclosure are probably very different
01:03:21.440 | so they are very different, but would they be more similar than for example stick length and
01:03:27.040 | sale day of year
01:03:29.600 | No, there's nothing to suggest that here because like the point is to notice where they sit in this tree
01:03:38.000 | Right and they both that they sit in totally different halves of the tree. Thank you
01:03:43.320 | But really to actually know that the best way would be to actually look at this BM and our correlation matrix
01:03:50.160 | Right if you just want to know how similar is this thing to this thing this theme and our correlation matrix tells you that
01:03:55.920 | Can you pass that over there?
01:03:57.920 | So today's we are passing the data frame, right?
01:04:03.600 | Say again
01:04:07.000 | This is just a data frame so we're passing in DF keep so that's the data frame
01:04:13.660 | Containing the whatever it was 30 or so features that our random forest thought was interesting
01:04:19.000 | so
01:04:20.360 | There's no random first being used here the measure of the distance measure is being done entirely on rank correlation
01:04:26.680 | So what I then do is I take these these groups
01:04:32.280 | Right and I create a little function that I call bit out of band score right which is it does a random forest
01:04:39.120 | for some data frame I
01:04:44.600 | Make sure that I've taken that data frame and split it into a training and validation set
01:04:49.080 | And then I call fit and return the OOB score right so basically what I'm going to do is I'm going to try
01:04:56.800 | Removing each one of these one two three four five six seven eight nine or so
01:05:02.840 | variables one at a time and
01:05:05.680 | See which ones I can remove and it doesn't make the OOB score get worse
01:05:11.600 | And each time I run this I get slightly different results
01:05:14.880 | So actually it looks like last time I had seven things not not eight things
01:05:18.120 | So you can see I just do a loop through each of the things that I'm thinking like maybe I could get rid of this
01:05:23.280 | Because it's redundant and I print out the column
01:05:26.880 | Name and the OOB score of a model that is trained after dropping
01:05:32.160 | that one column
01:05:34.840 | Okay, so the OOB score on my whole data frame is 0.89 and
01:05:41.320 | then after dropping each one of these things
01:05:45.000 | They're basically none of them get much worse sale elapsed is
01:05:51.720 | Getting quite a bit worse than sale year, but like it looks like pretty much everything else
01:05:56.440 | I can drop with like only like a third decimal place
01:05:59.580 | Problem so obviously though you've got to remember the dendrogram what let's take Fi model desk and Fi based model
01:06:08.760 | Right, they're very similar to each other, right?
01:06:11.080 | So what this says isn't that I can get rid of both of them, right?
01:06:14.800 | I can get rid of one of them because they're basically measuring the same thing
01:06:18.680 | Okay, so so then I try it. I say okay. Let's try getting rid of one from each group sale year
01:06:25.520 | Fi based model and
01:06:28.040 | grouser tracks
01:06:29.960 | Okay, and like let's now have a look. It's like okay. I've gone from point eight nine. Oh to point eight eight eight
01:06:35.840 | It's like again so close as to be meaningless. So that sounds good simpler is better
01:06:41.920 | So I'm now going to drop those columns from my data frame
01:06:48.280 | And then I can try running the full model
01:06:53.360 | Again, and I can see you know, so reset RF samples
01:06:57.640 | Means I'm using my whole data frame of my whole big strap sample
01:07:03.160 | Use 40 estimators and I've got point 907. Okay, so I've now got a
01:07:09.880 | Model which is smaller and simpler and I'm getting a good score for
01:07:16.160 | So at this point I've now
01:07:19.840 | got rid of as many columns as I feel I comfortably can ones that either didn't have a good feature importance or were
01:07:28.080 | Highly related to other variables and the model didn't get worse significantly with that when I removed them
01:07:33.520 | So now I'm at the point where I want to try and really understand my data better by taking advantage of the model
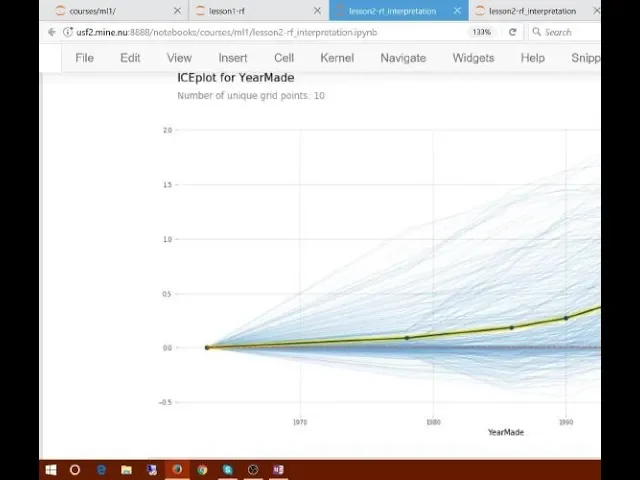
01:07:40.840 | And we're going to use something called partial dependence
01:07:43.680 | And again
01:07:44.080 | This is something that you could like using the cable kernel and lots of people are going to appreciate this because almost nobody knows
01:07:49.440 | About partial dependence and it's a very very powerful technique
01:07:53.840 | What we're going to do is we're going to find out for the features that are important
01:07:58.200 | How do they relate to the dependent variable?
01:08:01.800 | Right. So let's have a look right? So let's again since we're doing interpretation
01:08:07.680 | We'll set set our samples to 50,000 to run things quickly
01:08:10.720 | We'll take our data frame
01:08:15.440 | We'll get our feature importance and notice that we're using
01:08:21.200 | Max and cat because I'm actually pretty interested in terms of for interpretation and seeing the individual levels
01:08:27.840 | And so here's the top ten and so let's try and learn more about those top ten
01:08:33.880 | So yeah made is the second most important so one obvious thing we could do would be to plot
01:08:46.080 | Year made against sale elapsed because as we've talked about already like it just seems to make sense. They're both important
01:08:53.840 | but it seems very likely that they kind of combine together to find like how old was the
01:09:01.480 | Product when it was sold so we could try plotting year made against sale elapsed to see how they relate to each other and when we do
01:09:09.800 | We get this very ugly graph and it shows us that year made
01:09:15.040 | Actually has a whole bunch that are a thousand
01:09:17.680 | Right. So clearly, you know, this is where I would tend to go back to the client or whatever and say
01:09:23.080 | Okay
01:09:23.660 | I'm guessing that these bulldozers weren't actually made in the year 1000 and they would presumably say to me
01:09:28.600 | Oh, yes, they're ones where we don't know when it was made, you know, maybe before 1986
01:09:34.360 | We didn't track that or maybe the things that are sold in Illinois. You don't have that data
01:09:39.600 | Provided or or whatever. They'll tell us some reason. So
01:09:45.840 | in order to
01:09:47.840 | Understand this plot better. I'm just going to remove them from this interpretation section of the analysis
01:09:53.240 | So I'm just going to say okay. Let's just grab things where year made is greater than 1930. Okay?
01:09:57.840 | So let's now look at the relationship between year made and sale price and there's a really great
01:10:06.900 | Package called GG plot
01:10:10.360 | GG plot originally was an R package GG stands for the grammar of graphics and the grammar of graphics is like this
01:10:17.580 | very powerful way of thinking about
01:10:20.720 | how to produce
01:10:23.880 | Charts in a very flexible way. I'm not going to be talking about it much in this class
01:10:28.440 | There's lots of information available online
01:10:30.440 | But I definitely recommend it as a great package to use GG plot
01:10:36.400 | Which you can pip install. It's part of the fast AI environment already
01:10:40.520 | GG plot in Python has basically the same
01:10:46.120 | Parameters and API is the R version the R version is much better documented
01:10:50.920 | So you should read its documentation to learn how to use it. But basically you say okay, I want to create a plot
01:10:57.680 | of
01:11:00.000 | This data frame now when you create plots
01:11:04.720 | Most of the data sets you're using are going to be
01:11:07.320 | Too big to plot as in like if you do a scatter plot
01:11:11.680 | It'll create so many dots that it's just a big mess and it'll take forever and remember when you're plotting things
01:11:18.360 | You just you're you're looking at it, right?
01:11:21.680 | So there's no point plotting something with a hundred million samples when if you only used a hundred thousand samples
01:11:27.240 | It's going to be pixel identical
01:11:29.400 | Right. So that's why I call get sample first. So get sample just grabs a random sample. Okay, so I'm just going to grab
01:11:35.960 | 500 points
01:11:38.360 | For now, okay, so I've got to grab 500 points from my data frame. I got a plot
01:11:44.240 | Year made against sale price AES stands for aesthetic. This is the basic way that you set up your columns in GG plot
01:11:51.840 | Okay, so this says to plot these columns from this data frame
01:11:55.640 | And then you there's this weird thing in GG plot where plus means basically add chart elements. Okay, so I'm going to add a
01:12:02.880 | smoother
01:12:05.160 | so
01:12:06.300 | Most of the very very often you'll find that a scatter plot is very hard to see what's going on because there's too much randomness
01:12:12.360 | Where else a smoother basically creates a little linear regression for every little subset of the graph
01:12:20.000 | And so it kind of joins it up and allows you to see a nice smooth curve. Okay
01:12:25.580 | so this is like the main way that I tend to look at univariate relationships and
01:12:30.780 | By adding standard error equals true. It also shows me the confidence interval of this smoother, right?
01:12:38.120 | So lowest stands for locally weighted regression, which is this idea of like doing kind of like doing lots of little
01:12:44.380 | linear aggressions
01:12:47.260 | So we can see here the relationship between year made and sale price is kind of all over the place, right?
01:12:55.040 | Which is like not really what I would expect. I would I would have expected that more recent
01:13:00.480 | Stuff that sold more recently
01:13:04.080 | Would probably be like more expensive because of inflation and because they're like more current models and so forth
01:13:10.160 | and the problem is that when you look at a univariate relationship like this, there's a whole lot of
01:13:16.000 | Co-linearity going on a whole lot of interactions that are being lost. So for example
01:13:21.880 | Why did the price drop?
01:13:24.840 | Yeah, is it actually because like things made between 1991 and 1997 a
01:13:30.800 | Less valuable or is actually because most of them were also sold during that time and actually there was like maybe a recession then
01:13:39.040 | Or maybe it was like product sold during that time a lot more people were buying
01:13:44.040 | Types of vehicle that were less expensive
01:13:47.620 | like there's all kinds of reasons for that and so again as
01:13:52.040 | Data scientists one of the things we're going to keep seeing is that at the companies that you join people will come to you with
01:13:58.320 | With these kind of univariate charts where they'll say like oh my god
01:14:02.080 | our sales in Chicago have disappeared that got really bad or
01:14:06.140 | people aren't clicking on this ad anymore and they'll show you a chart that looks like this and they'll be like what happened and
01:14:12.280 | Most of the time you'll find the answer to the question. What happened is that there's something else going on, right?
01:14:18.920 | So actually all in Chicago last week actually we were doing a new promotion
01:14:24.920 | And that's why our you know revenue went down. It's not because people aren't buying stuff in Chicago anymore
01:14:30.260 | It's because the prices were lower for instance
01:14:32.260 | So what we really want to be able to do is say well
01:14:36.320 | What's the relationship between sale price and year made all other things being equal?
01:14:41.420 | So
01:14:45.920 | All other things being equal basically means if we sold something in
01:14:52.240 | 1990 versus 1980 and it was exactly the same thing to exactly the same person and exactly the same option
01:14:58.520 | So on and so forth. What would have been the difference in price?
01:15:01.200 | And so to do that we do something called a partial dependence plot and this is a partial dependence plot
01:15:10.160 | There's a really nice library which nobody's heard of
01:15:12.320 | called PDP
01:15:15.880 | Which does these partial dependence plots and what happens is this we've got our sample of 500 data points
01:15:22.280 | Right and we're going to do something really interesting. We're going to take each one of those hundred randomly chosen auctions and
01:15:29.400 | We're going to make a little data set out of it, right? So like here's our
01:15:34.080 | Here's our
01:15:38.960 | Here's our data set of like 500 auctions and
01:15:45.520 | Here's our columns
01:15:47.520 | One of which is the thing that we're interested in which is year made so here's year made
01:15:53.880 | Okay, and what we're going to do is we're now going to try and create a chart
01:15:58.880 | Where we're going to try and say all other things being equal in
01:16:02.880 | 1960
01:16:06.040 | How much did
01:16:09.160 | Bulldozers cost how much did things cost in options? And so the way we're going to do that is we're going to replace the year
01:16:15.600 | Made column with 1960 we're going to copy in the value 1960 again and again and again all the way down
01:16:22.200 | Right. So now every row the year made is
01:16:26.160 | 1960 and all of the other data is going to be exactly the same and we're going to take our random forest
01:16:31.120 | And we're going to pass all this through our random forest
01:16:33.840 | To predict the sale price
01:16:38.560 | So
01:16:40.060 | That will tell us for everything that was auctioned how much do we think it would have been sold for if?
01:16:46.540 | That thing was made in 1960 and that's what we're going to plot here
01:16:52.900 | All right, that's the price we're going to plot here, and then we're going to do the same thing for 1961
01:16:58.620 | All right, we're going to replace all these and do 1961
01:17:04.380 | Yeah
01:17:06.380 | Yeah
01:17:10.660 | So to be clear
01:17:12.660 | We've already fit the random forest yes, and then we're just passing a new year and seeing what it determines
01:17:19.820 | The price should be yeah
01:17:20.740 | So this is a lot like the way we did feature importance, but rather than randomly shuffling the column
01:17:25.600 | We're going to replace the column with a constant value
01:17:28.700 | All right, so randomly shuffling the column tells us
01:17:33.340 | How accurate it is when you don't use that column it anymore?
01:17:36.460 | Replacing the whole column with a constant tells us or estimates for us how much we would have sold that product for
01:17:43.920 | In that auction on that day in that place if that product had been made in 1961, right?
01:17:50.620 | So we basically then take the average of all of the sale prices that we calculate from that random forest
01:17:56.740 | And so we do it in 1961 and we get this value, right?
01:18:01.660 | So what the partial dependence plot here shows us is each of these light blue lines
01:18:05.760 | Actually is showing us all 500 lines, so it says
01:18:11.140 | for row number one in our data set
01:18:15.240 | If we sold it in 1960, we're going to index that to zero right so call that zero right if we sold it in
01:18:23.020 | 1970 that particular
01:18:25.460 | Auction would have been here if we sold it in 1980 it would have been here if we sold in 1990
01:18:31.020 | It would have been here, so we actually plot all
01:18:33.460 | 500
01:18:36.660 | Predictions of how much every one of those 500 it
01:18:39.700 | Auctions would have gone for if we replace it if we replace the EMA with each of these different values
01:18:46.700 | And there are then then this dark line here is the average
01:18:51.160 | Right so this tells us
01:18:53.780 | How much would we have sold?
01:18:56.140 | On average all of those options for if all of those products were actually made in 1985
01:19:03.640 | 1990 1993 1994 and so forth and so you can see what's happened here is at least in the period where we have a reasonable
01:19:11.820 | Out of data which is since 1990. This is basically a totally straight line
01:19:15.780 | Which is what you would expect right because if it was sold on the same date
01:19:21.260 | And it was the same kind of tractor that was sold to the same person in the same option house
01:19:26.620 | Then you would expect more recent vehicles to be more expensive
01:19:31.900 | Because of inflation and because they're they're newer
01:19:36.540 | Like they're not they're not as second-hand and you would expect that relationship to be roughly linear
01:19:41.900 | And that's exactly what we're finding okay, so by removing all of these
01:19:48.340 | personalities it often allows us to see the truth
01:19:52.420 | Much more clearly there's a question at the back. Can you pass that back there? You're done, okay
01:19:57.660 | so
01:20:00.660 | This this partial dependence plot concept is something which is
01:20:06.620 | using a random forest
01:20:09.260 | To get us a more clear
01:20:11.700 | interpretation of what's going on in our data and so the steps were to first of all
01:20:17.900 | look
01:20:19.260 | at the feature importance to tell us like which things do we think we care about and
01:20:24.460 | Then to use the partial dependence plot to tell us
01:20:28.660 | What's going on on average?
01:20:31.500 | right
01:20:34.340 | There's another cool thing we can do with PDP is we can use clusters and what clusters does is it uses cluster analysis?
01:20:40.740 | to look at all of these
01:20:43.180 | each one of the 500 rows and say
01:20:46.820 | Does some of those 500 rows kind of move in the same way and like we can kind of see it seems like there's a whole
01:20:52.860 | Lot of rows that kind of go down and then up and there seems to be a bunch of rows that kind of go up
01:20:59.020 | And then go flat like it does seem like there are some kind of different types of behaviors being hidden
01:21:04.020 | And so here is the result of doing that cluster analysis, right is we still get the same average
01:21:10.660 | But it says here are kind of the five
01:21:13.220 | most common shapes that we see
01:21:16.500 | And this is where you could then go in and say all right. It looks like some kinds of vehicle
01:21:21.820 | Actually after 1990 their prices are pretty flat and before that they were pretty linear
01:21:28.900 | Some kinds of vehicle are kind of exactly the opposite and so like different kinds of vehicle have these different shapes
01:21:35.740 | Right, and so this is something you could dig into I think there's one at the back. Oh, you could okay
01:21:40.020 | So what we're going to do with this information
01:21:42.740 | well
01:21:45.140 | the purpose of
01:21:47.140 | Interpretation is to learn about a data set and so why do you want to learn about a data set?
01:21:52.180 | It's because you it's because you want to do something with it, right? So in this case
01:21:56.620 | It's not so much something if you're trying to win a Kaggle competition
01:22:01.100 | I mean it can be a little bit like some of these insights might make you realize how I could
01:22:05.980 | Transform this variable or create this interaction or whatever
01:22:10.660 | Obviously feature importance is super important for Kaggle competitions, but this one's much more for like real life
01:22:16.660 | you know so this is when you're talking to somebody and you say to them like
01:22:20.980 | Okay, those plots you've been showing me which actually say that like there was this kind of dip in prices
01:22:28.300 | You know based on like things made between 1990 and 1997 there wasn't really you know actually it was they were
01:22:36.240 | Increasing there was actually something else going on at that time
01:22:40.420 | You know it's basically the thing that allows you to say like
01:22:43.300 | For whatever this outcome. I'm trying to drive in my business is this is how something's driving it right so
01:22:49.320 | efforts like
01:22:51.980 | I'm looking at you know kind of advertising technology
01:22:55.440 | What's driving clicks that I'm actually digging in to say okay?
01:22:58.500 | This is actually how clicks are being driven. This is actually the variable that's driving it
01:23:02.540 | This is how it's related so therefore we should change our behavior in this way
01:23:06.660 | That's really the goal of any model. I guess there's two possible goals one goal of a model is just to get the predictions
01:23:12.940 | Like if you're doing hedge fund trading
01:23:14.720 | You probably just want to know what the price of that equity is going to be if you're doing insurance
01:23:19.540 | You probably just want to know how much claims that guy's going to have but probably most of the time you're actually trying to change
01:23:26.180 | Something about how you do business how you do marketing how you do logistics
01:23:31.040 | So the thing you actually care about is how the things are related to each other
01:23:34.940 | All right, I'm sorry can you explain again when you scroll up and you were looking at the sale price year may
01:23:42.580 | Look me at the entire model, and you saw that dip
01:23:45.420 | And you said something about that dip didn't signify what we thought it did can you explain why yeah, so this is like a classic
01:23:56.080 | Boring univariate plot right so this is basically just taking all of the dots all of the options
01:24:02.780 | Plotting year made against sale price, and we're going to just fitting a rough average through them and so
01:24:10.900 | It's true that products made between 1992 and
01:24:18.300 | 1997 on average in our data set being sold for less
01:24:23.500 | So like very often in business you'll hear somebody look at something like this, and they'll be like oh we should
01:24:30.860 | We should stop auctioning equipment that is made in that year in those years because like we're getting less money for for example
01:24:37.860 | But if the truth actually is that during those years
01:24:42.860 | It's just that people were making more
01:24:47.380 | Small industrial equipment where you would expect it to be sold for less and actually our profit on it is just as high for instance or
01:24:57.580 | During those years. It's not that it's not things made during those years now would have
01:25:03.300 | Would be cheaper. It's that during those years
01:25:06.740 | When we were selling things in those years they were cheaper because like there was a recession going on
01:25:12.700 | So if you're trying to like actually take some action based on this
01:25:16.460 | You probably don't just care about the fact that things made in those years are cheaper on average, but how does that impact?
01:25:23.220 | today you know so
01:25:27.220 | This this approach where we actually say let's try and remove all of these externalities
01:25:33.380 | So if something is sold on the same day to the same person of the same kind of vehicle
01:25:39.460 | Then actually how does year made impact price and so this basically says for example if I am
01:25:45.180 | Deciding what to buy at an option then this is kind of saying to me okay like
01:25:51.540 | Getting a more recent vehicle on average really does on average
01:25:56.820 | Give you more money
01:25:58.460 | Which is not what the kind of the naive univariate plot said?
01:26:02.720 | For like this bulldozer bulldozers made in 2010 probably are not
01:26:18.500 | Close to the type of bulldozers that were made in 1960 right and if you're taking something that would be
01:26:26.860 | so
01:26:27.980 | very different like a
01:26:29.980 | 2010 bulldozer and then trying to just drop it to say oh if it was made in 1960 that may cause
01:26:37.740 | poor
01:26:40.180 | Prediction at a point because it's so far outside. Absolutely
01:26:42.740 | Absolutely, so you know I think that's a good point. It's you know it's a
01:26:46.580 | limitation
01:26:49.140 | Of a random forest is if you're got a kind of data point
01:26:53.140 | That's like of a kind of you know which is kind of like in a part of the space that it's not seen before
01:26:57.700 | Like maybe people didn't put air conditioning really in bulldozers in 1960
01:27:02.780 | And you're saying how much with this bulldozer with air conditioning have gone for in 1960. You don't really have any information to know that so
01:27:09.320 | you know you it's a
01:27:12.620 | It's it's this is still the best technique. I know of but it's it's not perfect
01:27:20.980 | And you know you kind of hope that
01:27:22.980 | The trees are still going to find some
01:27:26.620 | Useful truth even though it hasn't seen that combination of features before but yeah, it's something to be aware of
01:27:34.500 | So you can also do the same thing in a PDP
01:27:41.860 | Interaction plot and a PDP interaction plot which is really what I'm trying to get to here is like how the sale elapsed and
01:27:48.220 | Year made together impact price and so if I do a PDP interaction plot it shows me sale elapsed versus price
01:27:56.820 | It shows me year made versus price, and it shows me the combination
01:28:02.260 | Versus price remember this is always log of price
01:28:05.420 | That's why these prices look weird right and so you can see that the combination of sale elapsed and year made is
01:28:11.500 | as you would expect
01:28:14.900 | Later dates so more or less time
01:28:17.300 | is
01:28:20.460 | Giving me. Oh, sorry. It's
01:28:23.180 | The other way around isn't it so the highest prices?
01:28:27.460 | Those where there's the least elapsed and the most recent year made
01:28:33.100 | So you can see here. There's the univariate relationship between sale elapsed and price
01:28:41.020 | And here is the univariate relationship between year made and price
01:28:44.860 | And then here is the combination of the two
01:28:49.900 | It's enough to see like clearly that these two things are driving price together
01:28:56.140 | You can also see these are not like simple diagonal lines, so it's kind of some interesting interaction going on
01:29:02.860 | And so based on looking at these plots
01:29:07.820 | It's enough to make me think oh, we should maybe put in some kind of interaction term and see what happens
01:29:13.540 | So let's come back to that in a moment, but let's just look at a couple more
01:29:16.980 | Remember in this case. I did one hot encoding
01:29:21.720 | Way back at the top here. I said max n cat equals 7 so I've got like n
01:29:28.480 | Closure erops with AC so if you've got one hot encoded variables
01:29:33.620 | You can pass an array of them
01:29:38.060 | To pit plot PDP, and it'll treat them as a category
01:29:42.580 | Right and so in this case. I'm going to create a PDP plot of these three categories. I'm going to call it enclosure
01:29:49.900 | and I can see here that
01:29:53.180 | Enclosure erops with AC
01:29:57.140 | On average are more expensive than enclosure erops and enclosure erops
01:30:03.580 | It actually looks like enclosure erops and enclosure erops are pretty similar or else erops with AC is higher
01:30:09.140 | So this is you know at this point. You know I'd probably be inclined to hop into Google and like type erops and erops
01:30:16.500 | And find out what the hell these things are
01:30:19.300 | And here we go
01:30:22.020 | So it turns out that erops is
01:30:25.140 | enclosed rollover protective structure and so it turns out that if your
01:30:32.500 | Your bulldozer is fully enclosed then optionally you can also get air conditioning
01:30:41.040 | So it turns out that actually this thing is telling us whether it's got air conditioning if it's an open structure
01:30:46.060 | Then obviously you don't have air conditioning at all, so that's what these three levels are and so we've now learnt
01:30:51.180 | All other things being equal the same bulldozer sold at the same time
01:30:57.380 | Built at the same time sold to the same person is going to be quite a bit more expensive as if it has air conditioning
01:31:03.580 | Than if it doesn't okay, so again. We're kind of getting this nice interpretation ability and
01:31:08.860 | You know now that I spent some time with this data set
01:31:12.180 | I've certainly noticed that this you know knowing this is the most important thing you do notice that there's a lot more
01:31:17.780 | air-conditioned bulldozers nowadays than they used to be and so there's definitely an interaction between kind of date and that
01:31:25.540 | So based on that earlier interaction analysis. I've tried
01:31:29.220 | First of all setting everything before 1950 to 1950 because it seems to be some kind of missing value
01:31:35.580 | I've been set age to be equal to
01:31:38.980 | sale year minus year made
01:31:42.060 | and so then I try running a random forest on that and
01:31:46.700 | Indeed age is now the single biggest thing
01:31:53.180 | Sale elapsed is way back down here
01:31:55.180 | Year made is back down here, so we've kind of used this to find
01:32:00.740 | an interaction
01:32:03.420 | But remember of course a random forest can create a can create an interaction through having multiple split points
01:32:10.340 | So we shouldn't assume that this is actually going to be a better result
01:32:14.660 | and in practice I actually found when I
01:32:19.780 | Looked at my score and my RMSE adding age was actually a little worse
01:32:25.500 | We'll see about that later probably in the next lesson
01:32:29.060 | Okay
01:32:32.380 | So one last thing is tree interpreter
01:32:38.100 | so
01:32:40.940 | This is also in the category of things that most people don't know exist, but it's super important
01:32:47.100 | Almost pointless for like Kaggle competitions, but super important for real life and here's the idea
01:32:53.660 | let's say you're an insurance company and
01:32:57.620 | somebody rings up and you give them a quote and
01:33:00.700 | They say oh, that's
01:33:03.500 | $500 more than last year why
01:33:06.180 | Okay, so in general you've made a prediction from some model and somebody asks why?
01:33:13.380 | And so this is where we use this method called tree interpreter and what tree interpreter does is
01:33:20.180 | It allows us to take a particular row so in this case. We're going to pick
01:33:27.260 | Row number zero right so here here is row zero right presumably. This is like a year made
01:33:33.340 | I don't know what all the codes stand for but like his is all of the columns in row zero
01:33:40.380 | What I can do with a tree interpreter is I can go ti dot predict pass in my random forest
01:33:47.140 | Pass in my row so this would be like this particular customers insurance information or this in this case this particular
01:33:54.760 | Auction right and it'll give me back three things the first is the prediction
01:34:00.700 | from the random forest
01:34:03.420 | The second is the bias the bias is basically the average sale price
01:34:10.300 | Across the whole original data set right so like remember in a random forest. We started with single trees
01:34:17.620 | We haven't got a drawing there anymore, but remember we started with a single tree in our random forest
01:34:28.260 | And we split it once and then we split that once and then we split that once right and we said like
01:34:35.420 | Oh, what's the average value for the whole data set?
01:34:38.980 | Then what's the average value for those where the first bit was true?
01:34:42.820 | And then what's the average value?
01:34:44.820 | Where the next bit was also true until eventually you get down to the leaf nodes where you've got the average value you predict right?
01:34:51.820 | So you can kind of think of it this way if this for a single tree if this is our final leaf node
01:34:58.200 | Right maybe we're predicting like nine point one
01:35:00.600 | Right and then maybe the average log sale price for the whole
01:35:07.060 | The whole lot is like ten point two right that's the average for all the options
01:35:12.260 | And so you could kind of like work your way down here, so let's go and create this
01:35:18.020 | Let's actually go and run this so we can see it
01:35:21.020 | Okay, so let's go back and redraw this single tree you'll find like in Jupyter notebooks often a
01:35:30.260 | lot of the things we create like
01:35:34.060 | Videos progress bars and stuff they don't know how to like save themselves to the file
01:35:39.420 | So you'll see just like a little string here, and so you actually have to rerun it
01:35:43.440 | to create the string
01:35:46.260 | So this was the single tree that we created
01:35:52.080 | So the whole data set had an average log sale price of 10.2
01:36:02.860 | The data set for those with couple system equals true
01:36:05.700 | had an average of ten point three
01:36:08.660 | The data set for couple system equals true enclosure less than point less than two was nine point nine and
01:36:17.100 | Then eventually we get all the way up here
01:36:19.740 | And also model ID less than 45 73 it's ten point two so you could kind of like say okay
01:36:26.780 | Why did this particular?
01:36:30.020 | Row let's say we had a row that ended up over in this leaf node. Why did we predict ten point two well?
01:36:35.300 | It's because we started with ten point one nine
01:36:38.740 | And then because the couple system was was was less than point five so it was actually false
01:36:44.020 | We added about two to that so we went from ten point one to ten point three right so ten point two to ten point three
01:36:52.620 | So we added a little bit because this one is true and then to go from ten point three to nine point nine
01:36:59.760 | So because enclosure is less than two we subtracted
01:37:03.320 | About point four and then because model ID was less than 4500 we
01:37:09.920 | added about point seven
01:37:12.760 | Right so you could see like with a single tree you could like break down like why is it that we predicted?
01:37:19.740 | 10.2 right and it's like at each one of these decision points. We're adding or subtracting a little bit from the value
01:37:27.500 | So what we could then do is we could do that for all the trees
01:37:31.800 | And then we could take the average so every time we see in closure
01:37:37.060 | Did we increase or decrease the value and how much by every time we see model ID did we increase or decrease the value?
01:37:45.420 | and how much by and so we could take the average of all of those and
01:37:48.960 | That's what ends up in this thing called
01:37:52.680 | contributions so here is all of our
01:37:57.480 | predictors and
01:37:59.000 | Here is the value of each and so this is telling us and I've sorted them here that
01:38:05.120 | The fact that this thing was made in
01:38:08.000 | 1999
01:38:09.960 | was the thing that most negatively impacted our prediction and
01:38:14.040 | the fact that the age of the vehicle was
01:38:19.640 | 11 years was what most positively impacted
01:38:24.360 | I
01:38:26.360 | Think you actually need to sort after you zip them together. They seem to be sorted negative point five
01:38:34.480 | No, the values are sorted, but then they're just reassigned to the columns in the original order
01:38:38.600 | Which is why in 11 your own tractor is what's most thank you. Thank you
01:38:45.140 | That makes perfect sense
01:38:47.760 | Yes, we need to do an index sort
01:38:50.200 | Okay
01:38:52.560 | Thank you. We'll make sure we fix that by next week
01:38:55.120 | So we need to sort
01:38:58.040 | columns by the index from contributions
01:39:02.460 | So then there's this thing called bias and so the bias is just the
01:39:08.440 | average
01:39:10.920 | With before we start doing any splits right so if you basically start with the average
01:39:15.560 | Log of value and then we went down each tree and each time we saw a year made we had some impact
01:39:22.600 | Couple of systems some impact product size some impact and so forth, right?
01:39:26.800 | Okay, so I think what we might do is we might come back to because we kind of out of time we might come back to
01:39:35.440 | tree interpreter
01:39:36.800 | Next time but the basic idea. This is the last
01:39:39.580 | this was the last of our key interpretation points and the basic idea is that
01:39:44.120 | we want some ability to
01:39:49.040 | Not only tell us about the model as a whole and how it works on average
01:39:52.840 | But to look at how the model makes predictions for an individual
01:39:56.520 | Row and that's what we're doing here. Okay. Great. Thanks everybody. See you on Thursday