Stanford XCS224U: NLU I In-context Learning, Part 4: Techniques and Suggested Methods I Spring 2023
Chapters
0:03:14 Choosing demonstrations
5:59 Example from Assignment 2
9:11 Chain of Thought
10:24 Generic step-by-step with instructions
13:13 Self-Consistency in DSP
13:52 Self-Ask
15:3 Iterative rewriting
16:5 Some DSP results
17:59 Suggested methods
00:00:00.000 | Welcome back everyone.
00:00:06.000 | This is the fourth and final screencast
00:00:08.000 | in our series on in-context learning.
00:00:09.940 | I'm going to talk about techniques for in-context learning and then
00:00:12.960 | suggest some future directions for you in your own research in this space.
00:00:17.620 | As before, I'm nervous about giving this screencast because it's essentially
00:00:22.760 | certain that what turns out to be a really powerful technique for
00:00:25.640 | in-context learning will be discovered in a few months,
00:00:28.080 | making some of this seem outdated.
00:00:29.920 | In fact, one of you might go off and discover precisely that technique,
00:00:33.760 | which will make this screencast seem incomplete.
00:00:36.320 | Nonetheless, I press on,
00:00:37.880 | I feel confident that we've learned important lessons about what works and what
00:00:41.800 | doesn't and those will carry forward no matter what happens in the field.
00:00:46.400 | Let's dive in. Let's start with the core concept of a demonstration.
00:00:51.440 | This is an idea that stretches back at least to the GPT-2 paper and is indeed
00:00:56.360 | incredibly powerful in terms of designing effective in-context learning systems.
00:01:01.400 | Let me illustrate in the context of few-shot open domain question answering,
00:01:05.740 | which is our topic for the associated homework and bake-off.
00:01:09.560 | Imagine that we're given the question, who is Bert?
00:01:12.300 | We're going to prompt our language model with this question and
00:01:14.520 | hope that it can generate a good answer.
00:01:17.440 | By now, you probably have an intuition that it would be
00:01:20.160 | effective to retrieve a context passage to insert into the prompt,
00:01:24.920 | to help the model to provide it
00:01:26.920 | some evidence that it can use for answering the question.
00:01:30.480 | The idea behind demonstrations is that it might also help to show
00:01:34.960 | the model examples of the kind of behaviors that we would like to elicit.
00:01:40.000 | Maybe we have a train set of QA pairs and we fetch
00:01:43.760 | one of those QA pairs and insert it into the prompt.
00:01:47.600 | Here I've put the question, who is Kermit?
00:01:49.920 | We would also insert the answer.
00:01:52.640 | But this is your first real choice point here.
00:01:55.520 | Of course, you could use the answer that comes
00:01:58.480 | directly from your train set of QA pairs,
00:02:01.400 | and that could be effective.
00:02:02.740 | It will be a gold answer.
00:02:04.600 | But counter-intuitively, it could be useful to instead use
00:02:09.400 | an answer that you retrieve from some data store,
00:02:13.040 | or even generate using
00:02:15.320 | the very language model that you are prompting right now.
00:02:18.360 | That could be good in terms of maybe finding
00:02:21.640 | demonstrations that are attuned to what
00:02:23.640 | your language model is actually capable of doing,
00:02:26.280 | versus just relying on the gold QA pairs which might be
00:02:29.240 | disconnected from the behavior of your model.
00:02:32.400 | The same lesson applies to
00:02:34.840 | the evidence passages that we would
00:02:36.560 | give for each one of these demonstrations.
00:02:38.880 | We could, of course, if we have them,
00:02:40.840 | just use the gold passage from the train data.
00:02:44.000 | But since this is a retrieve passage down here,
00:02:48.020 | it might be better in terms of
00:02:49.840 | exemplifying the intended behaviors to
00:02:52.240 | retrieve a passage instead of using a gold one to
00:02:54.960 | better align with the experience
00:02:57.040 | the model actually has for our target question.
00:02:59.880 | Again, it's counter-intuitive.
00:03:01.240 | We have this gold passage.
00:03:02.440 | Why would you use a retrieved one?
00:03:04.280 | It's because it comes closer to simulating
00:03:07.200 | the situation that your model is actually in.
00:03:10.720 | That's just one lesson for demonstrations.
00:03:13.520 | Let's think more broadly about this.
00:03:15.160 | How might you choose demonstrations?
00:03:17.440 | Of course, you could just randomly choose them from
00:03:20.120 | available data but perhaps you could do better.
00:03:23.120 | Maybe you should choose your demonstrations based
00:03:25.640 | on relationships that they have to your target example.
00:03:29.440 | For example, in generation,
00:03:31.160 | you might choose examples that are retrieved
00:03:33.760 | based on similarity in some sense to the target input.
00:03:37.280 | Or for classification, you might select demonstrations to
00:03:41.040 | help the model implicitly determine the target input type.
00:03:46.200 | You might also start to filter
00:03:48.760 | your demonstrations to satisfy specific criteria.
00:03:51.880 | For example, in generation,
00:03:53.760 | maybe we want to be sure that
00:03:55.280 | the evidence passage contains
00:03:57.520 | the output string that would help the model
00:04:00.040 | figure out how to grapple with
00:04:01.480 | the evidence that we present to it.
00:04:03.560 | Or in generation, you might want
00:04:05.840 | the language model to be able to predict the correct answer.
00:04:08.840 | That's an idea that I alluded to before.
00:04:11.760 | In classification, maybe a straightforward thing would be to
00:04:15.280 | ensure that your demonstration set for
00:04:17.520 | every prompt includes every label that's
00:04:20.600 | represented in your dataset so that your model has
00:04:23.000 | an example of every possible behavior and isn't
00:04:26.440 | accidentally limited by the sort of
00:04:28.640 | thing that it sees in the prompt.
00:04:31.200 | We could also think about massaging
00:04:33.760 | these demonstrations that we have available to us.
00:04:36.320 | Maybe we sample them and then
00:04:37.920 | rewrite them with the language model.
00:04:39.840 | We could do this to synthesize
00:04:41.760 | across multiple initial demonstrations.
00:04:44.560 | Maybe that's more efficient and allows us
00:04:46.600 | to include more demonstrations.
00:04:48.560 | We could also change the style
00:04:50.400 | or formatting to match the target.
00:04:52.760 | Use the LM to make the demonstrations more
00:04:55.680 | harmonious with what the language model
00:04:58.040 | expects given the target
00:04:59.640 | or the capabilities of the language model.
00:05:02.040 | For example, if it's really important to
00:05:04.680 | you to generate answers in the style of a pirate,
00:05:07.720 | it might be useful to have your language model actually
00:05:10.360 | rewrite the demonstrations in the style of a pirate,
00:05:13.520 | if it has that capability to further
00:05:15.720 | guide it toward the intended behavior.
00:05:18.480 | The fundamental thing that you have to get used to,
00:05:22.840 | and that will seem obvious in retrospect,
00:05:25.320 | is that for powerful in-context learning systems,
00:05:28.600 | your prompt might contain
00:05:30.640 | substrings that were generated by
00:05:32.800 | a different prompt to that self-same language model.
00:05:36.160 | Yes, that could be recursive.
00:05:38.480 | Even those substrings might themselves be
00:05:41.080 | the product of multiple calls to your language model.
00:05:44.760 | Again, it takes some getting used to,
00:05:47.120 | and it can be hard to think through
00:05:48.320 | how these systems actually work,
00:05:49.760 | but the end result can be something that is very powerful in terms of
00:05:53.040 | aligning the behaviors of
00:05:54.640 | your language model with the results that you want to see.
00:05:58.760 | In that context, let me actually linger a little bit
00:06:02.920 | over one of the questions on the assignment,
00:06:05.280 | because this is one that people often find hard to think about,
00:06:08.960 | but fundamentally I think it's an intuitive and powerful idea.
00:06:12.200 | This is about choosing demonstrations.
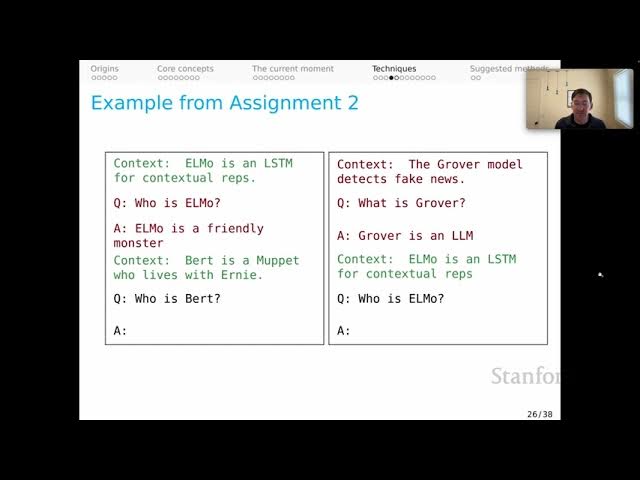
00:06:15.000 | Let's start with our usual question, who is Bert?
00:06:18.640 | We're going to retrieve some context passage presumably,
00:06:22.240 | and then the question is what to do for demonstrations.
00:06:25.240 | Suppose that I find the demonstration,
00:06:27.680 | who is Elmo, with answer,
00:06:29.120 | Elmo is a friendly monster,
00:06:30.800 | and maybe that's just from my train set.
00:06:33.160 | But the train set doesn't have context passages,
00:06:35.880 | so what I decide to do is retrieve a context passage.
00:06:40.000 | The context passage that I retrieve is,
00:06:42.720 | Elmo is an LSTM for contextual representations.
00:06:46.640 | That looks worrisome.
00:06:49.040 | That context passage is about a different Elmo than the one
00:06:52.560 | represented in this question-answer pair serving as my demonstration.
00:06:56.440 | You might worry that that is going to be
00:06:58.640 | very confusing for the language model.
00:07:01.400 | The evidence is not relevant.
00:07:03.240 | The question is, could we detect that automatically?
00:07:06.120 | I think the answer is yes.
00:07:07.760 | The way we do that is by firing
00:07:10.040 | off another instance of the language model.
00:07:12.960 | In this case, we prompt it with
00:07:14.800 | our demonstration question, who is Elmo?
00:07:17.600 | We get that same context passage,
00:07:20.720 | and then yes, we'll probably insert a demonstration.
00:07:23.840 | For simplicity right now,
00:07:25.360 | let's assume that that demonstration just comes from
00:07:27.720 | some train data I have for the context,
00:07:30.400 | the question, and the answer to keep things simple.
00:07:33.000 | This is a new prompt to
00:07:34.880 | our language model and we see what comes out,
00:07:36.920 | and the answer is, Elmo is an LSTM.
00:07:39.640 | We can observe that that predicted response to
00:07:43.240 | this demonstration does not match the gold answer in our dataset.
00:07:48.200 | We could use that as a signal that something about
00:07:51.200 | this demonstration is problematic and we
00:07:53.640 | throw it out and we start again.
00:07:55.920 | We're back to our question, who is Bert?
00:07:57.760 | We retrieve our context passage and we
00:08:00.960 | sample another demonstration instance.
00:08:03.960 | In this case, the context question and answer look harmonious.
00:08:09.120 | Again, we could try to detect that automatically by firing off
00:08:12.800 | another instance of the language model
00:08:14.640 | with our demonstration question, who is Ernie?
00:08:17.360 | Same retrieved passage,
00:08:19.480 | we sample another demonstration there,
00:08:22.200 | and we look to see what the model does.
00:08:24.400 | In this case, the model's response matches our gold answer,
00:08:28.040 | and we decide we can therefore trust this as
00:08:30.520 | a demonstration in the hopes that that will
00:08:33.000 | finally lead to good behavior from our model.
00:08:36.720 | That's a bit convoluted,
00:08:38.480 | but I think the intuition is clear.
00:08:39.960 | We're using the language model demonstrations and our gold data to
00:08:43.560 | figure out which demonstrations are likely to be
00:08:46.000 | effective and which aren't and we're trying to do that automatically.
00:08:50.360 | Yes, for this sub-process with this language model where I
00:08:54.800 | just inserted a gold context question-answer pair,
00:08:58.440 | you can imagine recursively doing the same thing of trying to find
00:09:02.080 | good demonstrations for the demonstration selection process.
00:09:06.720 | At some point, that recursive process needs to end.
00:09:10.880 | Let's move to another technique.
00:09:13.880 | This is called chain of thought,
00:09:15.280 | and this is also, I think, a lasting idea.
00:09:18.600 | The intuition behind chain of thought is that for complicated things,
00:09:23.160 | it might be simply too much given
00:09:25.720 | the prompt to ask the model to simply produce the answer in its initial tokens.
00:09:31.280 | It's just too much.
00:09:32.720 | What we do with chain of thought is construct
00:09:36.200 | demonstrations that encourage the model to generate in a step-by-step fashion,
00:09:42.200 | exposing its own reasoning,
00:09:44.120 | and finally arriving at an answer.
00:09:46.960 | This again shows the power of demonstrations.
00:09:49.280 | We illustrate chain of thought with these extensive,
00:09:52.360 | probably hand-built prompts.
00:09:54.400 | Then when the model goes to do our target behavior,
00:09:57.800 | the demonstration has led it to walk through a similar chain of
00:10:01.560 | thought and ultimately produce what we hope is the correct answer.
00:10:05.320 | Assume we didn't lead it down the garden path or it didn't lead
00:10:08.480 | itself down the garden path toward the wrong answer,
00:10:10.800 | which absolutely can happen with chain of thought.
00:10:14.400 | The original chain of thought is quite bespoke.
00:10:17.320 | We need to carefully construct these chain of thought demonstration
00:10:20.720 | prompts to encourage the model to do particular things.
00:10:23.800 | I think there is a more generic version of this that can be quite powerful.
00:10:28.080 | I've called this generic step-by-step with instructions.
00:10:31.360 | Here we are definitely aligning with the instruct fine-tuning that
00:10:36.880 | these models are probably undergoing and leveraging that in some indirect fashion.
00:10:41.720 | Here's an illustration.
00:10:43.160 | I have prompted DaVinci 3 with the question,
00:10:46.280 | is it true that if a customer doesn't have any loans,
00:10:49.040 | then the customer doesn't have any auto loans?
00:10:51.680 | It's a complicated conditional question involving negation,
00:10:55.600 | and the model has unfortunately given the wrong answer.
00:10:58.440 | No, this is not necessarily true.
00:11:00.880 | The continuation is revealing a customer can have
00:11:03.440 | auto loans without having any other loans,
00:11:05.740 | which is the reverse of the conditional question that I posed.
00:11:10.280 | It got confused logically.
00:11:12.200 | In generic step-by-step,
00:11:14.180 | what we do is just have a prompt that
00:11:16.360 | tells it something high level about what we want to do.
00:11:19.020 | It says logic and common sense reasoning exam.
00:11:21.740 | Explain your reasoning in detail.
00:11:24.280 | Then we give a description of what
00:11:27.340 | the reasoning should look like and what the prompt will look like,
00:11:30.220 | using an informal markup language that probably the model
00:11:33.620 | acquired via some instruct fine-tuning phase.
00:11:37.460 | Then we actually have the prompt there.
00:11:40.100 | What happens is the model walks through the logical reasoning,
00:11:44.860 | and in this case, arrives at the correct answer,
00:11:47.740 | and also does an excellent job of explaining its own reasoning.
00:11:50.980 | It's the same model,
00:11:52.540 | but here it looks like this generic step-by-step instruction format,
00:11:57.340 | led it to a more productive endpoint.
00:12:01.100 | Self-consistency is another powerful method.
00:12:06.040 | This is from Wang et al, 2022,
00:12:08.400 | and it relates very closely to
00:12:10.060 | an earlier model called retrieval augmented generation.
00:12:13.420 | This is a complicated diagram here.
00:12:15.620 | Let me zoom in on what the important piece is.
00:12:18.060 | We're going to use our language model to
00:12:20.980 | sample a bunch of different generated responses,
00:12:24.460 | which might go through different reasoning paths
00:12:26.860 | using something like chain of thought reasoning,
00:12:29.080 | and ultimately will produce some answers.
00:12:31.900 | Those answers might vary across
00:12:34.300 | the different generated paths that the model has taken.
00:12:37.340 | What we're going to do is select the answer that
00:12:41.120 | was most often produced across all of these different reasoning paths.
00:12:44.940 | That is technically speaking a version of
00:12:47.040 | marginalizing out the reasoning paths to arrive at an answer,
00:12:51.800 | with the intuition being that the answer that was arrived at by
00:12:55.140 | the most paths effectively or the most probable answer
00:12:58.220 | given all these paths is likely to be a trustworthy one.
00:13:01.980 | That too has proved really effective.
00:13:04.140 | It can get expensive because you sample a lot of
00:13:06.260 | these different reasoning paths,
00:13:08.560 | but the result can make models more self-consistent.
00:13:13.340 | Just by the way, in DSP,
00:13:16.420 | we have a primitive called dsp.majority
00:13:19.380 | that actually makes it very easy to do self-consistency.
00:13:22.580 | You just set your model up to generate a lot of
00:13:24.820 | different responses given your prompt template,
00:13:27.500 | and then dsp.majority will figure out which answer was
00:13:30.780 | produced most often given all of those reasoning paths.
00:13:34.380 | A nice simple primitive that makes
00:13:37.100 | self-consistency essentially a drop-in for any program that you write,
00:13:41.380 | assuming you can afford to do all of the sampling.
00:13:44.860 | For more details on that,
00:13:46.380 | I would refer you to
00:13:47.820 | Omar's intro notebook which walks through this in more detail.
00:13:51.940 | Self-ask is another interesting idea.
00:13:55.700 | Here, the idea behind self-ask is that we will,
00:13:59.900 | via demonstrations, encourage the model to break
00:14:04.100 | down its reasoning into a bunch of
00:14:06.500 | different questions that it poses to itself,
00:14:09.060 | and then seeks to answer.
00:14:10.820 | In that way, the idea is that it will iteratively get to
00:14:13.620 | the point where it can find the answer to the overall question.
00:14:17.460 | This is especially powerful for questions that might be multi-hop,
00:14:21.180 | that is, might involve multiple different resources,
00:14:24.340 | which you can essentially think of as being broken down into
00:14:27.260 | multiple sub-questions that need to be
00:14:29.260 | resolved in order to get an answer to the final question.
00:14:33.020 | That's self-ask, and it has an intriguing property for
00:14:35.820 | us as retrieval-oriented researchers.
00:14:38.440 | Self-ask can be combined with
00:14:40.320 | retrieval for answering the intermediate questions.
00:14:43.000 | Instead of trusting the model
00:14:44.760 | generations for those intermediate questions,
00:14:46.960 | you'd look to something like a search engine,
00:14:49.560 | like in the paper they use Google to answer those questions,
00:14:52.640 | the answers get inserted into the prompt and the model continues.
00:14:57.080 | That's self-ask or maybe self-ask and Google answer.
00:15:02.320 | Another very powerful general idea that I'm sure will
00:15:07.620 | survive no matter what people discover about in-context learning,
00:15:11.300 | is that it can be useful to iteratively rewrite parts of your prompt.
00:15:15.840 | You could be rewriting demonstrations or
00:15:18.720 | the context passages that they contain,
00:15:21.140 | or the questions or the answers.
00:15:23.540 | I've given some code here that shows how this
00:15:25.800 | plays out in the context of multi-hop search,
00:15:28.240 | where we're essentially gathering together
00:15:30.480 | evidence passages for a bunch of different sources,
00:15:33.440 | synthesizing them into one,
00:15:35.880 | and then using those as evidence for answering a complicated question.
00:15:40.080 | But the idea is very general,
00:15:42.760 | especially given a limited prompt window or
00:15:46.080 | a very complicated situation in terms of information,
00:15:49.900 | it might be helpful to iteratively have your language model rewrite parts of
00:15:54.400 | its own prompt and then prompt the model with
00:15:56.800 | those rewritten chunks as a way of
00:15:58.840 | synthesizing information and getting better results.
00:16:02.060 | Very powerful idea.
00:16:04.560 | In the context of all of this,
00:16:06.960 | I thought I would just call out some results from the DSP paper.
00:16:11.160 | In the DSP paper,
00:16:12.640 | we evaluate across a bunch of different knowledge-intensive tasks,
00:16:16.120 | most of them oriented toward
00:16:18.000 | question answering or information-seeking dialogue.
00:16:21.860 | The high-level takeaway here is that we can write
00:16:25.360 | DSP programs that are breakaway winners in these competitions.
00:16:29.160 | That is the final row of this table here.
00:16:31.340 | You can see us winning across the board.
00:16:33.580 | We are often winning by very large margins,
00:16:36.440 | and the largest margins are coming from
00:16:38.600 | the most underexplored datasets like MusicQ and PopQA.
00:16:43.520 | The lesson here is, first of all,
00:16:46.360 | that DSP is amazing and Omar and the team did an amazing job.
00:16:50.480 | But I think the deeper lesson is that it is very early days for these techniques.
00:16:55.680 | The only time you see these breakaway results for modeling is when
00:17:00.560 | something new has happened and people are just figuring out what to do next,
00:17:04.720 | and we caught that wave.
00:17:06.800 | I expect the gap to close as people discover
00:17:09.480 | more powerful in-context learning techniques,
00:17:11.760 | and I would just encourage you to think about DSP as
00:17:15.080 | a tool for creating prompts that are truly full-on AI systems.
00:17:20.920 | We want to bring the software engineering to prompt engineering,
00:17:24.340 | and really think of this as a first-class way of designing AI systems.
00:17:28.640 | If we move into that mental model,
00:17:30.960 | I think we're going to see more and more breakaway results,
00:17:34.320 | and we will indeed realize the vision of having in-context learning systems
00:17:38.340 | surpass the fine-tuned systems that were supervised in the classical mode.
00:17:45.560 | But it's going to take some creativity,
00:17:47.700 | and there's lots of space in which to be creative right now.
00:17:52.160 | That's a good opportunity for me to queue up this final part of the screencast,
00:17:57.200 | some suggested methods for you as you think about working in the space.
00:18:00.960 | First, as a working habit,
00:18:03.600 | create Devon test sets for yourself based on the task you want to solve,
00:18:08.040 | aiming for a format that can work with a lot of different prompts.
00:18:11.580 | Do this first so that as you explore,
00:18:15.920 | you have a fixed target that you're trying to achieve that will help you get
00:18:19.240 | better results and be more scientifically rigorous.
00:18:22.800 | Learn what you can about your target model,
00:18:25.920 | about how it was trained and so forth.
00:18:27.840 | Paying particular attention to whether it was
00:18:30.080 | tuned for specific instruction formats.
00:18:32.240 | I think we have already seen that the extent to which you can
00:18:35.520 | align with its instruct fine-tuning data,
00:18:38.440 | you will get better results.
00:18:40.240 | Often, we don't know what that data set was like,
00:18:43.240 | but we can discover it in a heuristic fashion, at least in part.
00:18:47.800 | Think of prompt writing as AI system design.
00:18:51.600 | That's what I said before.
00:18:52.960 | Try to write systematic generalizable code for handling the entire workflow,
00:18:58.280 | from reading data to extracting responses and analyzing the results.
00:19:02.560 | That is a guiding philosophical idea behind DSP.
00:19:06.400 | But even beyond this DSP,
00:19:08.320 | I think this is an important methodological note.
00:19:10.800 | We shouldn't be pecking out prompts and designing systems in that very ad hoc way.
00:19:15.680 | We should be thinking about this as the new mode in which we
00:19:19.520 | program AI systems and take it as seriously as we can.
00:19:24.160 | Finally, for the current and perhaps brief moment,
00:19:27.680 | prompt designs involving multiple pre-trained components and tools seem to
00:19:31.600 | be underexplored relative to their potential value.
00:19:34.840 | For this unit, we are exploring how a retrieval model
00:19:38.400 | and a language model can work in concert to do powerful things.
00:19:42.280 | But we could obviously bring in other pre-trained components and maybe
00:19:46.360 | even other just core computational capabilities like calculators,
00:19:50.640 | weather APIs, you name it.
00:19:53.000 | Thinking about how to design prompts that take advantage of
00:19:55.920 | all of those different tools is a wonderful new avenue.
00:19:59.160 | We're starting to see exploration in this space and it is
00:20:02.160 | sure to pay off in one form or another.
00:20:05.160 | Maybe go forth and see what value you can extract out of
00:20:09.920 | this new mode of tooling around prompting.
00:20:14.880 | [BLANK_AUDIO]