Stanford CS25: V2 I Emergent Abilities and Scaling in LLMs
Transcript
OK, great. So the first sort of paper that I'm going to be talking about is called "Emergent Abilities of Large Language Models." And this paper was especially cool, I think, because we got people from Google and DeepMind, and also Stanford. You might recognize Percy, or Tatsu, or Rishi. I mean, we got people to sort of agree on what's a nice framework of looking at why we want to scale in emergent abilities.
So one of the things that we've seen throughout language models is that you sort of get these predictable gains as a result of scaling. So here's the canonical Kaplan et al. paper, where you can see that if you scale up the size of the language model, measured either in compute, in data set size, or in parameters, you see that the loss on the test set actually goes down predictably.
Yeah. I don't know if you're screen sharing, so people in Zoom, I don't think, can see the slides. OK. Yeah, yeah, yeah. Sorry, let me fix that. OK. OK. I guess I'll say this for the third time. As we've seen in language models, if you scale up the size of the language model, measured either in compute, in data set size, or in number of parameters, you can see that there's sort of this predictable improvement in the test loss.
Now, what I'm going to be talking about in terms of emergence is something that's actually unpredictable if you only look at smaller language models. So one way that emergence has been described in the broader science literature is it's basically seen as a qualitative change that arises from quantitative changes.
It sort of started with this article in Science by a Nobel Prize winning physicist called "More is Different." And I really like this post from Jacob Steindart that sort of describes emergence. And he gives a couple of good examples here. For example, he says, "With a bit of uranium, nothing special happens.
With a large amount of uranium packed densely enough, you get a nuclear reaction. And then also with DNA, for example, given only small molecules such as calcium, you can't meaningfully encode useful information. But given larger models such as DNA, you can encode a genome." So for this particular work, we use this definition of emergent abilities of large language models in particular.
So we say that ability is emergent if it is not present in smaller models, but it is present in larger models. And the sort of natural question here is how do you measure the size or the scale of the language model? And there's sort of traditionally three axes of scale.
So the training flops are the amount of compute that you use to train the language model, the number of model parameters, or the size of the language model, and also the size of the training data set that the model is trained on. And a lot of the plots here will use either training flops or the number of model parameters.
The reason is that the training data set size is usually fixed for different size models. And because training flops is just the data set size times model parameters, you can get a similar plot from either training flops or number of model parameters for most language models. Great. And so the first type of emergence-- yeah, sorry, go ahead.
Yeah. For me, it seems like it would be relatively easier to measure the size versus what qualifies as an ability. How do you define what counts as an actual ability versus not? Yeah, sure. So yeah, for example, I'll just give an example here, which is actually next slide. So basically, we have this way of interacting with language models called few-shot prompting.
And the way it works is the language model is a really good next-word predictor. And when you give the model an example, and then you ask it for an unseen movie review, for example, and then you say, what's the output? And then here, the language model can say positive because it understands to use the context from the review to give the next token.
And the definition that we use for having ability or not is that basically, a few-shot prompted task, for example, sentiment analysis, is emergent if it has random accuracy for small models but above random accuracy for large models. Does that make sense? So basically, if the model isn't doing any better than random, then when you say it doesn't have the ability to do this particular task.
And I'll give a few examples here. So here's the canonical way that we look at plots for emergence. So basically, what we have, each of these different plots is a different task. And I'll go over some examples soon. But the way you read the plot is the x-axis is the number of training flops or the model scale.
And then the y-axis is the accuracy or how good the model is doing the task. And then we have different language models from OpenAI, from Google, and from DeepMind. And then each of the points is a different language model. It's not a language model over the course of training.
Each point is a different language model. And what you see is that for the very small language models, you basically get performance that's close to random or not being any better than random. And then once you pass a certain threshold, you can see that the performance suddenly gets substantially above random.
And this is what we call emergence. So basically, if you were to extrapolate the lines from the small language models, you might predict that it would never do better than random because it's just a flat line. But the interesting phenomenon is that when you scale up past a certain threshold, you actually do see this emergent phenomenon where the model does a lot better than random.
So let me go over some concrete examples. So here's one task. It's basically a benchmark called multitask NLU or MMLU. And basically, what it is, it's a bunch of test questions ranging from high school all the way to professional level exams. And how it works is the language model is given-- for example, here is a high school math example.
And the language model is given a few examples. And then for an unseen question, it has to give the answer. And then you can see in the plot on the right-- so for the model scale, if you go up to sort of 10 to the power of 22 training flops, you don't actually get any better than random accuracy on this task.
But if you scale up to 10 to the 24 training flops, then you see that all the three models there do much better than random accuracy. Yeah, go ahead. The scale of the data used to train this, is it roughly similar? Or because these are different models trained by different boards?
Yeah, the scale is, I think, within an order of magnitude for these models here, yeah. But every single dot on each individual tracks is the same data? Yes, the data is fixed except for Chinchilla. Chinchilla uses more data for larger models. But I believe for all the other models here, the amount of data is the same.
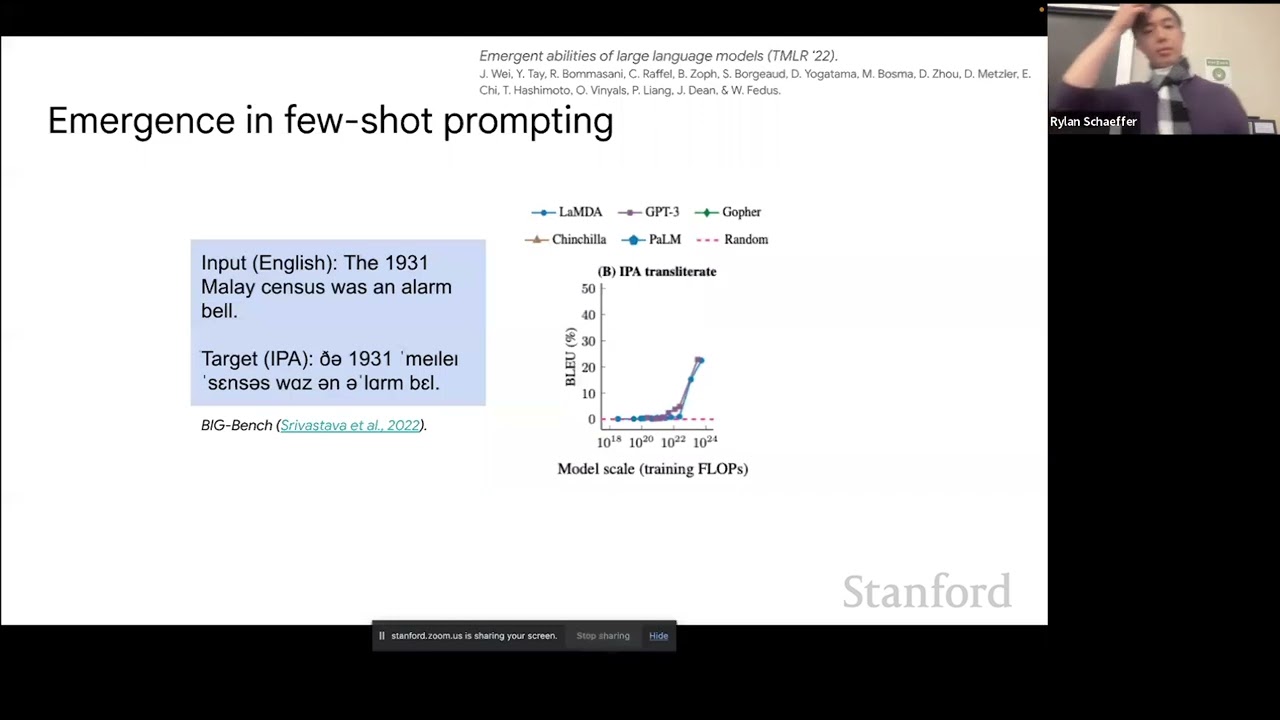
Yeah, here's just another example to show it more concretely. So this is a task from the Big Bench Benchmark. Just as an aside, the Big Bench Benchmark is like 200 benchmarks. And basically, it's like a crowdsource set of benchmarks I'd recommend looking at if you're doing that kind of work.
And basically, the task is the language model has to take an English sentence and then give the international phonetic alphabet transliteration, the IPA transliteration, which is basically how to pronounce it. And for this task, the evaluation metric is actually blue, or like an n-gram overlap metric. And you get a similar phenomenon, where as you increase the size of the language model, it's flat for a while.
And then suddenly, the improvement is above random. Great. So I'll talk about another interesting result here that's why it's emergent. So this was a technical report that we put out a couple of months ago. And basically, there's this really interesting prize in-- or it's like a one-time prize in language models, where Anthropics, which is like a startup, basically had this prize where if people could come up with a task where the performance on the task would actually decrease as you increase the size of the language model, then you would get a bunch of money.
So basically, there are a lot of submissions to this. And here's one example of a task where they found that the performance would actually decrease if you increase the size of the language model. So the task is-- I'll just read it here. It's like, repeat my sentences back to me.
And then the input is like, all that glisters is not glib. And then the output is-- the model has to accurately say glib. And so what happened is for the small language model, it doesn't know the phrase, all that glisters is not gold. So it just copies the input and actually does get-- it's like 100% on that.
But then for the medium-sized language model, what you would see is that the performance actually decreased because the medium-sized language model knows the phrase, all that glisters is not gold. And then it says gold, which actually is not what the task asks it to do. Yeah, go ahead. Someone on Zoom asked, can you give a physical estimate of 10 to the 24 flops, possibly in terms of training time or number of GPUs?
Yeah, so I think 10 to the 24 flops is around-- so at Google, we use TPUs. And one pod of TPUs, I believe, is equal to like 4,000 A100s. And 10 to the 24 flops is like two pods for around six weeks or something like that. So it's a lot of compute to do the pre-training.
I don't know. Do you guys remember in chemistry class when you'd have moles? And it would be like 10 to the 23. And then your teacher would be like, oh, I don't even think about how big this number is. That's the number of floating point operations that goes into the pre-training of some of these models.
OK, great, anyways. So yeah, so basically, the medium-sized language model would actually do worse. Oh, yeah, did you have another question? Yeah, oh, wait, did this one win the prize or not? This one is one of the winners. I think it's a third-place winner or something. Yeah? What do you mean, flip a negative sign?
Well, because all of this depends on which evaluation scheme you use to measure if you do your task right. So it's like the measurement is very sparse. You only get credit if you do it perfectly or something. Yeah, yeah. Yeah, so for this thing, they accounted for all-- you can't just say the task should be a do badly on something.
It has to be a meaningful sort of task. And then, I guess, your point about how credit assignment or the valuation metric works is actually a really good one. Yeah, so I guess it still kind of counts if-- I guess the argument is that the performance might not look emergent if you assign partial credit.
But we have a bunch of-- I can show an example later. But even if you use partial credit metrics, you'll often still see the same type of emergence. So it's not purely a phenomenon of not assigning partial credit based on the valuation metric. And then-- great. So what we sort of argued in this paper is that, yeah, there might be some tasks where the performance starts to decrease if you use a medium sized language model.
But if you keep scaling all the way to the largest model that we have at Google that's known publicly, Palm, you'll see that the language model can actually go back and do the task correctly. Because the large language model also knows the phrase, all that glisters is not gold.
But it also understands, repeat my sentences back to me. So it's able to get 100% on this task. So this is a different type of emergence also. And another class of emergence that we talk about in the paper is an emergent prompting technique. So basically, other than future prompting, there's other ways of interacting with the language models that can be considered emergent.
Yeah. Can I interrupt? Sorry, somebody else had a question on the previous one. Yeah. The question is, did all models undergo instruction-binding tuning? None of these models underwent instruction-binding tuning for this plot. Yeah. Great. Yeah. So one way of interacting with language models is by basically finding the model using a technique called RLHF.
And basically, the way it works is you have this data. And humans rate preferences based on the data. And humans rate preferences for what type of outputs they prefer. And then the model is trained on RL to optimize for human preferences. And what this plot is showing here is that if you do this RLHF on the model, the model performance on a different zero-shot task actually gets worse for small models.
You can see the blue line is above the orange line. Blue line is the baseline. The orange line is RLHF. And then if you do it for large models, though, then you can see that the performance actually has a positive delta from doing RLHF. And so this is an interesting thing where a certain technique might only help if you try on a large enough language model.
So if you only try it on the small language models, it'd be tough to draw the conclusion that it wouldn't help performance. And then later, I'll talk about chain-of-thought prompting as another emergent prompting technique. So here's the hand-wavy diagram that I used to think about emergence as a framework.
So on the x-axis here, there's a scale of the language model. And on the y-axis is a imaginary scale of a range of things that a language model can do. And then basically, you can pick some random point, like, say, 100 blind parameters in the language model. And there will be certain abilities.
So first, you can see, as you increase the size of the language model, the number of tasks or things that the language model can do increases. And then you can see there are some tasks where-- models above 100 blind parameters, for example, can do them. But models below 100 blind parameters can't do them.
And we call these emergent abilities. Sorry, quick question about this. Yeah. What are the colors? Oh, it's just highlighting the dark blue is tasks that a smaller language model wouldn't be able to do. Does that make sense? Yeah. And then to the right of the dotted line, the white region on top?
Oh, that just means tasks that we haven't been able to solve yet with language models. Yeah. Cool. And I'm curious to know, do you think that it's not that those tasks in the white region are unsolvable, like the 100 billion scale? Or do you think that better models, specific training data, would allow us to, at the 100 billion scale, get into that white region?
Yeah, I definitely think that it's not a fixed-- I'll give an example shortly. But it's not a rule that you have to have 100 blind parameters to do a certain task. It's just that that happens to be the threshold that we've observed in models so far. And I do think with better training data, and architecture, and algorithms, we can probably beat that.
Cool. Yeah, so as Rylan just mentioned, one example of getting emergence can be with better data. So it's not all about scale. I'll give some nuance here. So for this task, it's just one of the tasks in the Big Bench benchmark. You can see that for Lambda, which is a Google model, and GPT-3, you actually don't get emergence from scaling to 137 or 175 billion parameters.
But when you come in with a different language model, Palm, which is trained on better data than Lambda and GPT-3, you actually can get this emergent ability, even with the smaller language model, so here at 62 billion parameters. Do you see Perpetuary's better model as better data, or also better architectural loss choices, or data for it?
Yeah, so the challenging thing is-- that's a great question. There's a lot of differences between Palm and Lambda, for example. And we can't really ablate them in any controlled way because of the cost of pre-training. But our running hypothesis is that Palm is trained on better data. And that accounts for a lot of the difference between Palm and Lambda.
I've seen the smaller scales where it is possible to ablate stuff, or some really architectural ways. Does anyone look into it? Yeah, that's a good question. So I guess even here, you can look at, for example, the Palm 8 billion model, like that point there. You can ablate it, and it's a little bit higher, but it's not really emergent yet at that point.
So it's hard to tell, for example, this particular task, what the effect is. Yeah. There's a question on Zoom. Are there two different versions of Palm? If not, why are there two lines for it? Oh, so I think the two lines here-- one is maybe three shot, and then one is zero shot, something like that.
So it just refers to the way that we're using the language model, either with or without exemplars. Great. I'll talk about a small ablation here that shows this. So this is an ablation on a toy task, where basically, the language model has to know that in English, you have to use plural verbs with plural subjects and singular verbs with singular subjects.
And what we're doing here is basically, we train these small BERT models from scratch, and then we fixed the frequency of certain verbs in the training data set, which basically says, OK, what's the effect of seeing a certain verb in the data more often? In this plot, the x-axis is the frequency of the verb, and the y-axis is the error rate.
And what you basically see is that if you have more in-domain data, so if the model sees the verb more times, it does the task a lot better. So this is an example of having high-quality data or data that's more in-domain for the task that you're evaluating on can make a big difference, even if you're fixing the compute, the size of the model, and the rest of the data.
Yeah? Question on Zoom. Someone asks, could there be a way to distill convergent abilities down to smaller models from larger teacher models? Yeah, I think so. So larger teacher models, you can use them, for example, to generate data. And then if you fine-tune the smaller model on data, it's pretty likely that you'll be able to get the ability to emerge in the smaller model.
I'll talk about an example of this, too. Oh, actually, that's the next slide. Desired behaviors can be induced in smaller models once you know what behavior you want. So for example, here's the figure from the InstructGPT paper. And basically, the desired behavior here is instruction following. And you can see that there's multiple models.
So on the left, you have these small models that are trained with RLHF. And they actually have better performance than larger models trained on weaker techniques. So basically, the point is, if you know that you want a certain behavior that you saw previously in an emergent way in a larger model, you can find a way to fine-tune on that behavior specifically and induce that behavior in a smaller model.
I guess that one of the limitations is that unless you know all the behaviors that you want, you can't really get this natural emergent behavior. Yeah, another discussion point here is that there's this question of what's the right x-axis for emergence. So right now, we mostly talk about model parameters and training flops.
But I guess if you ask deep mind people how they look at it, you'll get this argument that model parameters and training flops are really just a proxy for how good the model is. And how good the model is can really be measured by perplexity, or how well it's doing on some dev sets, such as Wikitext 103.
So basically, you can also measure emergence in terms of perplexity. So here is Wikitext perplexity. And then you can see on a downstream task that, as the perplexity gets better, there's sort of this threshold where you're able to do a lot better on the downstream task. And there's sort of a strong correlation, at least right now, between perplexity and training compute.
So you can see these two lines are pretty similar. And basically, I think in the future, if we have much better models that are a lot smaller, turn on much better data and better algorithms, then maybe Wikitext perplexity can show a different type of plot than using other metrics.
Yeah, go ahead. So Wikitext is basically a-- I think it's like a subset of Wikipedia. And then perplexity is like a measure of how well you can predict the next word in a data set. So basically, if you're really good at modeling the next word on this particular evaluation set, that's sort of a measure of how well you understand language.
That make sense? Oh, this is like a held-out test set. And then a final thing that I think is pretty exciting about emergence is that there's sort of not just technical emergence that we've talked about, but there's sort of sociological changes in how the AI community views scaling and how to use language models.
So here's some examples of where scaling up the size of the language model enables you to, in this sort of few-shot scenario, beat a task-specific fine-tuned language model that's usually fine-tuned on, say, thousands of examples. So basically, the green line is the prior state of the art achieved by fine-tuning.
And then the blue dots basically show, if you take a pre-trained language model and you do few-shot prompting, which means the language model isn't intentionally trained to do the task, you can often get state-of-the-art results just by continuing to scale up the size of the language model. And obviously, there's limitations here.
You don't want to just keep scaling up in order to get state-of-the-art. But I think it's a pretty big change in people's minds that you could actually get some of the best results just by scaling up the size of the language model and doing prompting. Question from Zoom. Someone asks, is that not a contradiction graph from two to three slides ago?
What is that? Which one? This one? I'm not sure. Should we, in general, assume-- oh, he said yes. OK. He said, should we, in general, assume that scale trumps fine-tuning? Yeah, so that's a great question. So this plot is saying that you fine-tune and you can do-- OK, yeah.
So it depends on your particular task. But what this plot is saying is that fine-tuned smaller models can do well on some tasks if you target it well. But for tasks that are more complicated, often you can do better just by scaling. So there's sort of tasks that fall into both of these categories.
And I wouldn't say that it's contradictory. I guess some tasks you would do a lot better just by scaling up the size of the model. And then other tasks, if it's a very narrow domain or the large language model might not be trained on that kind of data, then you would do better by fine-tuning.
OK, great. So here's sort of a little summary slide. So basically, emergent abilities can only be observed in large models. And if you try to predict their emergence just by looking at the plots for small models, then you wouldn't be able to do it. And I sort of had a little reflection on how to look at this.
So emergence is really this framing of how to view new abilities that are not intentionally built in to the pre-training. And I think the subtext for this is super important, which is you can see it as an implicit argument for why we should keep scaling up language models, because you get these abilities that are really hard to find otherwise.
And the context around this is pretty important, because it's really expensive to continue scaling up these models. And even one year ago, a lot of people didn't believe that you could do better on certain tasks just by scaling up the size of the language model. They sort of-- if you work in industry at all, there's this interesting tension between emergence and also many production tasks.
So emergence is sort of this task general phenomena where you scale up the model, and it's really expensive. But the single model can do a lot of tasks. This is sort of in the direction of AGI. And then for many production tasks, you have sort of the opposite, where you know what task it is, for example, translating to Spanish.
And then you have these constraints on compute, because when you build Google Translate, for example, you don't want people to have to wait a couple of seconds just to get the translation. And then you also happen to have a lot of in-domain data. So you have, for example, a million pairs of English-Spanish sentences to train on.
And this is sort of the opposite setting, where you don't really care about the model's emergence. You can just train a very small model on the data and do all of the tasks without having to use a lot of compute. And the final point is that I think a really promising research direction, if anyone is interested in doing research, is to work on predicting future emergent abilities.
And I haven't seen a lot of work on it recently, just because I think maybe it's too hard, for example. You can only predict emergence for a specific task. Or one way of predicting emergence might not be super general. And so I haven't seen much work on that. But I think this is a pretty promising direction to work on.
And maybe Anthropic is working on it. I don't know. OK, great. Any questions on that before I move on to chain of thought prompting? Yeah, go ahead. Do we have any theoretical basis to predict which parameters are best scaled to get related properties? Because obviously, there are many different options for where the actual parameters like GPT, for example, you could add more to the inventory.
You could add more in or whatever. Is that mostly something we just test? And then we find out which ones scale better and give us better results? Yeah, I would say that we don't have very principled methods for how to scale up these architectures. I'm not an expert in this.
But some of it has to deal with how many parameters you can fit onto a particular TPU. But in general, I think you scale up the number of intentions heads and embeddings somewhat proportionally. But yeah, I think this is an open research question. And because you can't really do ablations over these pre-training, you can't really do ablations over pre-training.
It's hard to have any principled way of doing it, other than some engineers who are in charge of doing it, saying, OK, I think this is the right thing to do. And it kind of works, and you go with it. Yeah? Do you have any indication of the asymptotic behavior of this get thing?
If you expect that, eventually, it would reach either some plateau of finite or non-zero loss, or it would just go all the way down to zero? Yeah, that's a great question. You mean on perplexity or on a particular task, or just in general on an export prediction? Well, it seems like these results are pretty general, pretty task-independent, right?
It's emergent scaling. But if you take the limit of infinite parameters, then even analytically, is there any sense of how that converges? Yeah, I have no clue. I think, for most of these tasks, there's a limit to accuracy, like 100%, for example. So there's some sort of asymptote there.
But I guess the deeper question that you might be asking is, can a language model perfectly know how to predict the next word for any given input? And maybe. I mean, I guess there's some limit to-- if I say a sentence, there are two possible next words or something.
And you might not be able to guess that perfectly. So I think there's some limit, but I think we're far from reaching that limit. And there's still a lot of unsolved tasks that sort of indicate that there's a lot of headroom. Yeah. If researchers are interested in studying emergence, what family of differently-sized models is publicly available or best for studying this?
Yeah, good question. So I think the OpenAI API has a lot of language models. And we actually use that a lot. Even at Google, it's used to study emergence. And that's sort of one way of doing it. And actually, a lot of these models are currently free. They're rate-limited, but they're free.
So we also use that. I think there's also smaller language models. Like, for example, there's a UL2 model that's 20 billion parameters. But I guess you're right. There is sort of this challenge where the small language models, you won't see a lot of these emergent behaviors. So you kind of have to either train-- yeah, so you kind of have to either use OpenAI API for now or wait until people train larger models.
I guess there's also the Bloom and, like, you guys probably know better than me, like, OPT models that are publicly available, but I haven't seen a lot of experiments on them. Yeah, yeah. So my question is, are there emergent abilities that are accessible in lower parameter regimes? I can think of, like, more of a speech technique or I would expect maybe there might be, like, some better-- maybe not, like, chain of thought, but are there some that are, like-- Yeah, definitely.
I think in the paper, we had, like, the list of a couple dozen abilities that would be emergent at, like, 8 billion parameters or, like, 60 billion parameters, something like that, yeah. Yeah. Yeah. We have two questions from Zoom. The first question is, do you see strategy tactics between the larger tech firms differing systematically in studying these models, or is basically everyone taking the same approach?
I wouldn't say that everyone is taking the same approach. I think, as one example, Anthropic takes, like, a very safety-centric approach. And they're super interested in, like, emergent abilities because there could be emergent abilities that are undesirable and they want to predict those types of things. I also don't know what happens at other companies other than at Google, so I can't really speak too much to that.
Yeah. The second question, what are some examples of tasks or abilities that have not yet emerged, even in models like Lambda, ChatGPT, et cetera? Oh, yeah, I have-- maybe I'll just show this real quick. Uh-- there's, like, a nice list somewhere. So-- yeah, so basically, what we did is there's, like, 200 tasks in BigBench.
And then we basically classified them into, like, smoothly increasing, emergent with GPT-3 or Lambda, emergent with POM, and then flat, which is, like, no model better than random. So I think if you look at any of these tasks here, they should still not have emerged yet. And if you can get them to emerge, that'd be interesting.
Sorry? I think ChatGPT should be 20 questions. Oh, OK, yeah, this is not a super-- I think this is, like, a couple of months old. Sorry, Yeah, yeah. Oh, 20 questions? OK, yeah. Yeah, I think-- like, the cool thing is, like, you can see over time, right? Like, originally, like, maybe only these were emergent.
And then when POM came out, you'd see a couple dozen more abilities became emergent. And then I suspect in a year or two, most of these will become emergent. And we'll need harder benchmarks. Yeah? There's another question on here. Why doesn't Google take as much of a safety-centered approach, like you said, in Prometheus?
Are there reasons to believe harmful capabilities wouldn't be emergent? Yeah, I don't want to answer the question on behalf of Google. I just can only talk about my own opinions. But I think the reality is that Google-- even if you look at, like, the amount of research that Google does, it might not be in the large language models very specifically.
But the amount of safety research that we do, I think, is more than anthropic if you actually look at the number of papers published. Don't quote me on this. But I think that's correct. Great. Yeah, I'll talk about chain-of-thought prompting. So basically, chain-of-thought prompting is this way of doing reasoning, multi-step reasoning, with large language models.
And yeah, I wanted to say that it's super exciting to see a lot of people at Google working on this, and also to see Sundar, our CEO, present this at our last year's Google I/O press event. And basically, the motivation for this is that we want language models to do more complicated tasks.
For example, we know language models can do easy tasks like sentiment analysis or translation. But what about more complicated tasks that might even take a human a minute or more to do? And the goal here is to basically guide them with metadata. So for example, instead of just giving an input-output pair, we want to give them the entire reasoning process and have them mimic that.
And basically, you can see here, in a standard prompt, you have the question and then the answer. And then you have a question, and the model gives a new answer. Unfortunately, it's wrong. And then with chain-of-thought prompting, you give the model a question. And then, kind of like how your teacher would ask you to show your work, you give the chain-of-thought, is what we call it, or basically a reasoning path.
And then you give the final answer. And then when the model sees this unseen question, now it's able to give the reasoning path and then give the correct final answer. And the way that we add these prompts into the prompt is basically we just manually write a couple and then add it into the prompt.
So let me just show how that works. So this is the OpenAI API. And basically, here's the non-chain-of-thought way of doing it. So basically, you would have question, answer, question, answer, question, answer, and then new question about cafeteria has 23 apples. They used 20 to make lunch and bought six more healthy apples to have.
And the model gets it wrong. And the only difference with chain-of-thought is that you give these intermediate reasoning paths before giving the final answer. So here's a path. There's a reasoning chain. There's another reasoning chain. And then now, the model for this unseen question gives the entire reasoning process.
And then this actually enables the model to get it correct. I'll give another quick example, this one. So here, the task is just take the last letters of the words in Bill Gates, so like L from Bill and S from Gates, and then concatenate them. And the answer should be LS.
And then here, the model gets it wrong. The answer should be NK, so it's SK. And then if you do chain-of-thought, obviously, this becomes very easy for the model. So it says the last letter of Bill is L. The last letter of Gates is S. The answer is LS.
And then here, it's able to do the last letter of Elon is M. And the last letter of Musk is K. And the answer is NK. So is this clear? Any questions about what's going on here? OK, great. So basically, we can have these similar plots where the x-axis is the model scale.
The y-axis is the performance. So on the left, we have this math word question benchmark called GSMAK. It's basically like questions that you'd see in an elementary school math test. And you can see the blue dot is standard, and the purple star is chain-of-thought. And basically, you see that the chain-of-thought, if you use a large enough model, does a lot better than standard prompting.
It actually beats the fine-tuned state-of-the-art at the time. A similar example is on this benchmark called Strategy QA. And what Strategy QA is, it's basically like this world knowledge plus common sense reasoning benchmark. So the question would be, can you hide a basketball in a sand cat's ear? And then the model would say, a basketball is about this size.
A sand cat's ear is that. So it would not fit. And on this benchmark, you can also see that we can beat the fine-tuned state-of-the-art from before just by using chain-of-thought with a large enough model. So one way we use this is that we evaluate a chain-of-thought on a certain subset of Big Bench tasks.
So we created a subset called Big Bench Hard. And basically, it's like 23 challenging tasks from Big Bench, where no model had done better than the average human rater. So the way that you prompt the model is that you'd have a task description, question, options, chain-of-thought, and then the test time question.
And so I'll give a couple examples of tasks here. So one example is navigate. Basically, what the language model has to do in this task is it has to basically follow these. So the question is, if you follow these instructions, do you return to the starting point? Turn left, turn right, take five steps, take four steps, turn around, take nine steps.
And then the model, following the few shot exemplars, is able to basically track state after all of the actions. And then at the end, it says, OK, are we at the final answer? Are we at the original location? If it is 0, 0, the answer is yes. Just to give an example of another task, here's a task that's very easy for humans, basically word sorting.
So there's a list of words, burly, baila. I'm not going to read them. And basically, the model has to sort them alphabetical order. And here, the model can follow the few shot exemplars. So you have this pretty complicated chain-of-thought where the model has to sort each of the subparts.
And then finally, it gets to the final answer, which is correct. So here's this result summary on the subset of BigBench. So you can see, OK, we have two metrics. One is just the average performance on all these tasks. And the second is the percent of tasks that are above the average human reader.
So average human reader is 67. Max human reader is 94. And then prior results, the model was doing way worse. It was like 50. And this is by construction of the subset. And then we used Code Da Vinci 02, which is one of the OpenAI models. And actually, you can use this one for free with OpenAPI.
And basically, if you do answer-only prompting without chain-of-thought, then you are beating the average human reader on 5 of 27. But if you use chain-of-thought prompting, then the performance increases by this pretty decent amount. And you're able to pass the average human on the majority of tasks. And then below is just this visualization of the tasks that are doing worse than humans in red and then better than humans in blue.
Yeah. Two questions. Isn't this similar to RLHF in spirit, at least? Is what similar? I think chain-of-thought prompting. I'm not sure what the statement is. I think chain-of-thought. Yeah, I think it's-- I wouldn't call it similar. So chain-of-thought is basically you take a pre-trained language model and you use a prompting technique that includes intermediate reusing path.
The way that RLHF works is that you have this additional data that you want to fine-tune the model on. And you have a preference model that sort of predicts how well does a certain output-- how likely is that to be preferred by humans? And then RLHF, what that does is it fine-tunes the language model to do well on the preference model's prediction.
So basically, it's sort of aligning the model with what humans would prefer. Is there a second question? Yeah, sorry. Just a few. OK. Andres asks, can chain-of-thought be included in fine-tuning rather than having to be in the prompt? Yes. The short answer is yes. The sort of complicated thing about that is that you have to have chain-of-thought intermediate steps.
And those are pretty-- it can be costly to gather that data and to do the fine-tuning. One last question. Sorry for everybody getting in. Another student asks, do you think that chain-of-thought and prompt engineering in general is just an artifact that won't be necessary for larger scale models that are better able to understand the prompts Yeah, so that's a great question.
Basically, the question is how ephemeral is prompt engineering going to be. I think we'll find out. But some initial intuitions are that for easy tasks that are easy to describe and maybe they're multiple choice, larger models will probably be more robust to prompt engineering. And there's sort of less you can do with that.
But I think as language models get more powerful, they'll sort of be more normal to use them on a lot more challenging tasks. And in those tasks, you'll have to specify exactly what you want the model to do, et cetera. So I think there will still be some room for prompt engineering there, at least in the near future.
Yeah, go ahead. Do you know how well this chain-of-thought prompting is generalizing to, for example, you showed these two tasks, right, a simple math and a map, and then the other one basically sorting the words alphabetically, right? Yeah. So I mean, I see that's the case with the math.
Math has to give this chain-of-thought prompting, and it does that super well. But would that model also perform better on sorting the alphabet? Or do you have to give the chain-of-thought for sorting words alphabetically? Yeah, that's a great question. So for some tasks where you've seen similar data in pre-training, the model can do really well, even if the chain-of-thought is from another task.
So for example, like math word problems, you actually don't really need a math chain-of-thought, because the model already knows how to do that. But for tasks like this, you probably haven't seen any data that's like the chain-of-thought here. So without task-specific exemplars, you probably wouldn't do super well on tasks like this without manually writing them for other examples.
Yeah. I'm wondering, as the researcher behind this, what mental model would lead you to even try this? Do you perceive the model as, if I was a person, how would I do this better? Or is it trying to give it more compute in order to make the orgasmic answer?
Yeah, great question. I think my motivation was just thinking about it, just as you said, what's going on in a human's mind while they try to solve this math question? And well, if you notice, at least some humans will think actually in natural language. So if you pay attention a lot to what's going on in your mind, you actually notice that sometimes you think in language.
And so well, the language model can think in language, too. So that was the motivation behind asking the language model to do that. And I think one thing that went well is that the development of this technique actually coincided with the development of Palm. And so yeah, basically having the model Palm allowed us to do a lot more challenging tasks using chain of thought.
Yeah? So when talking about the data quality, we're saying that it matters that the absolute number of examples of this chain of thought process or whatever in the data set or in the fine tuning, is that the main significant thing? Or is it this relative number of frequency of those examples are just negative examples, which are not good examples of how to reason?
Do those matter as much as the absolute number of good examples? Yeah, good question. So I guess the challenging thing is we can't really measure how many similar examples are in the training set. It's hard to do that well. And I don't think anyone has done that before. So it's more of this open question of why a chain of thought even works.
Because you actually don't see similar data like that in the training set. Yeah, I think it's open question of why it works. I mean, you said, OK, think about how new things-- sometimes we think in language, and then model should do that, too. But how do you actually think in-- what is the intuition for the model?
I mean, is there a shift in what specific task? Some weights get more focus from the model? How do you think about that? Yeah, I don't really think about it in terms of what's going on in the weights. I guess the way that I think about it is that it'd be unfair for me to give you a math question and ask you to give me the answer within half a second, which is basically what you're doing with the model and when you don't do a chain of thought, right?
You're basically asking this challenging question, and the model doesn't have enough compute to solve it in one pass to give you the answer immediately. I think the second thing that I think about is that the model has learned a compositional set of skills during pre-training, so maybe it hasn't really learned this particular navigate task during pre-training.
But it's learned other things, right? It's learned like, OK, if you take five steps and you're facing this, maybe you should add five here or something like that, right? And it's learned how to do pattern matching. So maybe in the future exemplars, it can match what the reasoning path is with what the question was.
And so there's sort of these little skills that the model might know. And then maybe if you can combine them together in some clever way, then you can get the model to solve more challenging problems. OK. Ryan, how much time do we have? Oh, OK, 50, OK. OK. OK, great.
That's a good example of how we judge these tasks, anyway. A bunch of different answers. All of them are right, but we judge them. Yeah. OK, great. Yeah, feel free to keep asking questions if you have any. So yeah, here's another example of emergence. So basically, you can see there's three models here, InstructGBT, Codex, and Palm.
Chain of thought in blue and non-chain of thought is in gray. And then you can see, you actually have to have sufficient model scale to get chain of thought to work well. And I guess the intuition here is that if you have a really small model, the model will keep repeating itself or not say anything coherent or never get a final answer, which is why using chain of thought for the small models doesn't really work well.
And then for the large models, obviously, for multi-step problems, the model is going to be able to solve the task at a lot higher accuracy with chain of thought. And another cool thing about chain of thought is there are some tasks where you wouldn't get emergent behavior at all.
So emergence hasn't been unlocked yet. But you can see that if you use chain of thought, you can unlock this emergent performance in smaller models. So one example here is multi-step arithmetic, where I don't know if you'll ever-- maybe I don't want to say never, but it's hard to imagine a model getting this.
Here's a question, and then the next token is correct. That's pretty hard to solve in one step. But with chain of thought, you can get 50% accuracy on this just by having the model output these intermediate reasoning steps. So I have a question about this. This is something that needs to have intuition about what's going on.
Abstractly, I know that a transformer can definitely do addition, like an arithmetic in one step. But it can take in the numbers and do the carries. Definitely, yeah, yeah. But then there's this question of what happens empirically. And I understand that it isn't necessarily a lot space to cover per tick.
My question is, how do we tell the difference? Are there ways to tell the difference between things that have an emerge because there's just no space? Or there's so many tasks that it couldn't allow any space to specifically do that one, versus the task is so hard that it just can't even if you use all the capacity to try and do it?
Yeah, that's a good question. I think there seems to be some subset of tasks where it just doesn't fit well with the way that we train language models. So for example, in language models, we use tokens, right? And so if you give it the token four, it actually doesn't take the number four.
It takes this embedding that's 1,000 dimensions or something. Or if you give it a word and ask it to reverse the letters, this is a super easy task, but the way we train the model doesn't actually look at the letters and stuff. So I think there's a certain subset of tasks where it doesn't really just fit well with the way that we train transformers.
And I think if you really care about these tasks, you can just solve them using code or something like that. But yeah, I don't think this is really an inherent-- something that would never emerge because it's too hard. Yeah. Yeah. We have a question on Zoom. Also, by the way, sorry, I forgot to mention.
Somebody asked, can you repeat the questions? Because they can't always hear you. Oh, OK. Yeah. That's my bad. That's my bad. So the question someone asked is, do you think chain of thought would be a viable interpretability technique for very advanced AI systems? And they mentioned that there is some research by a professor called Externalized Reasoning Oversight by Cameron Landon.
Will it be a viable interpretability technique for advanced AI? Yeah. Am I supposed to repeat this? Yeah, yeah, yeah. Sorry. Please. So the question is, can chain of thought be a viable interpretability technique for AI? I think there's no guarantee that the chain of thought is how the model actually arrives at the final answer.
But often, you can use it to debug, why isn't the model getting this question correct? Or what can we do better in the chain of thought to help the model get this correct? I haven't read the anthropic paper that was mentioned. So I actually don't know the answer to that.
OK. Another interesting result that we had here was that you can actually do multilingual chain of thought prompting. And so basically, what we had is we translated this benchmark of math word problems to 10 languages. And then we prompt the model to do it in, say, Bengali. And then the model has to basically do the math problem in Bengali and give the final answer.
And I think the cool thing about this is that this input is highly improbable, right? So Bengali is 0.01% of the pre-training data. And math word problems are probably an even smaller subset of that. And basically, the interesting thing is, the model can actually do these types of questions pretty well, to probably surprising degrees.
If you ask people before I showed them this result, how well can the model do these math questions in Swahili? Probably like 10%. But actually, even very underrepresented languages like Swahili or Bengali or Telugu and Thai, the model can do surprisingly well despite the fact that they only occupy a very small subset of the pre-trained data.
Yeah. Actually, speaking to this, and most of my experience with this is with Chatterjee PP, but if you ask it things in different languages, despite not being explicitly trained in these languages, it seems to have derived reasoning independent of language, to a certain extent. It can do the reasoning.
Actually, it's kind of funny. Sometimes, it always looks like it does the reasoning in English, and it translates back to the other language, because the answers it gives you is sort of like if you reasoned in English and then translated to the other thing. So do you think that learning the structure of a language and learning reasoning abilities are somewhat separate in large language models, or that it inherently will learn a chain of thought reasoning within that language, within the structure of the language, like the way thought works in that language?
Does that make sense? Yeah, that's a great question. I'm not sure how to measure that, but I've definitely thought about it. I think the language-- I mean, based on these results, you probably didn't have any math questions in Swahili for the model to learn from. And I think, definitely, there's something language agnostic going on, where the model learns reasoning sort of independently of the language, and then it can express it in different languages if it needs to.
But I don't think we know the answer to that yet. Yeah, so basically, one question that comes up frequently is, why does scaling up improve chain of thought? And one way of looking at this is, we can take a smaller model, like POM62B, and see what types of errors are fixed from scaling up to 540 billion parameters.
And you can see that, for these three categories that we came up with, some of all of them get fixed. So scaling seems to have this universal effect on improving different types of errors from solid models. And then here's the same hand-wavy diagram expressed in different ways. So basically, you have some tasks that are doable with standard prompting, so in blue.
And then the goal of chain of thought prompting is to sort of increase the set of tasks that we can do. So for example, now, the ones shown in pink include math word problems, symbolic reasoning, and challenging commonsense reasoning, yeah. One more question. Have you done any calculations to figure out how much-- is any of this contribution just because of the fact that you do more computations when you put in longer prompts?
Like, you put multiple tasks into the model. You create multiple embeddings to sort of adjust the things the model is looking at, in a way. Yeah. How much of that have you tried non-chain of thought prompts with same token lengths? Yeah, yeah. We tried with XXXXX or something. And it doesn't really-- it doesn't work.
I see. So I think it's not just about the compute. I think it's about the language to guide in the model as part of the reasoning, yeah. I see. And have you tried describing the problem in more detail than non-chain of thought? I know this is a super question.
I'm just very curious about-- this sounds like a very interesting property. And I'm very curious exactly how it fits in. Yeah, you mean like describing the question in three different ways and seeing if that-- Yeah, just describing the question in more detail instead of explicitly doing the step-by-step things and seeing how that-- Yeah.
I haven't tried that, but I would be surprised if that worked. I see. Yeah. That is a question to me. Did you try having it output the answer and then explain its reasoning into that? Yeah, that doesn't work as well. OK. Yeah, but it depends on the task also.
So like-- Yeah, yeah. Yeah. So like, there is something out of the That seems to be the case, yeah. Yep. Does it really have to be like reasoning? Can we do like just any amount of extra calculation to sort of conjugate the worst answer? Like, in a way, you know, in a way like in an ablation, chain of thought is like a very structured thing.
It's like, what if the same structure is preserved, but like we do some more random things? Yeah, you could try it. I would be surprised if it works. I think like outputting tokens is pretty important for the model. Yeah. Yeah. OK. So we're doing on time. OK, great. So the last part, I think, is a pretty cool trick with chain of thought.
So basically, what people usually do is they'll just generate one chain of thought, and then they'll take the final answer. But there's this nice trick called self-consistency where you can use like temperature sampling with the model to generate like a bunch of different reasoning pods and final answers. And then if you just take a majority vote over the final answers, this ends up like improving performance by like a pretty big margin.
So for example, here, you can see on GSM 8K, which is like the math for problem data set, the improvement goes from like, you know, the performance is like 56. And then if you do self-consistency, then it becomes 74, which is like a pretty big improvement. Quick clarification question.
Yeah. Here, how many are we averaging over for self-consistency? Oh, I think 40. So it increases the cost of the inference time compute. But yeah, it improves performance by a lot. You might be about to answer this, but I'm curious to know how many samples or how many chains does one need to draw to get a significant-- like, what is the trade-off between number of chains averaged over versus performance gain?
I think it depends on the-- sorry, the question is, how many chains do you need to get a performance gain? I think the answer really depends on the data set. But usually, you can get something good with like 16, I think. Yeah. Oh, sorry, we have a question. How does the temperature change the way the model works?
Oh, OK, the question is, how does the temperature change the way the model works? Basically, when you use temperature decoding, the language model can like stochastically pick one of the outputs instead of always picking the highest probability next word. So basically, you get these more stochastic outputs that are still based on what the language model has learned, but it's just a little bit more random.
And then finally, yeah, self-consistency also seems to be a merge-ability. I guess part of it is because chain of thought is emergent because you wouldn't get any better than the random performance without doing chain of thought. But yeah, you kind of see this big delta from self-consistency for larger models.
Great, so I'm going to run out of time. Let me just go to-- I'll just talk about this a little bit. So I think in addition to just purely scaling up the language model, which is only available to people in the industry, I think there's a couple interesting directions to work on.
One is better prompting and characterization of language model abilities. I think right now, we're just at the edge of knowing what the best way to prompt language models is. There's also pretty good applied work. So you can use language models, I've heard, to train therapists, to help with creative writing, to help with science.
I think ChatGPT has really shown what language models can do in this regard. I think benchmarks are also something that's pretty lacking because I think we solve benchmarks pretty quickly. For example, Palm beat the average human on Big Bench within a year or something of Big Bench coming out.
So I think we need more benchmarks, and I think that's going to be an important contribution. And then the final one is, how can we have compute-efficient methods to make language models better so that it's less expensive to use them and more people get to use them? Great. So I'll end here.
And feel free to email me if you have any feedback. And if you're interested in Google, feel free to email me as well. Thanks. Thank you. you