Stanford CS25: V1 I Transformers in Language: The development of GPT Models, GPT3
Chapters
0:0 Introduction0:8 3-Gram Model (Shannon 1951)
0:27 Recurrent Neural Nets (Sutskever et al 2011)
1:12 Big LSTM (Jozefowicz et al 2016)
1:52 Transformer (Llu and Saleh et al 2018)
2:33 GPT-2: Big Transformer (Radford et al 2019)
3:38 GPT-3: Very Big Transformer (Brown et al 2019)
5:12 GPT-3: Can Humans Detect Generated News Articles?
9:9 Why Unsupervised Learning?
10:38 Is there a Big Trove of Unlabeled Data?
11:11 Why Use Autoregressive Generative Models for Unsupervised Learnin
13:0 Unsupervised Sentiment Neuron (Radford et al 2017)
14:11 Radford et al 2018)
15:21 Zero-Shot Reading Comprehension
16:44 GPT-2: Zero-Shot Translation
18:15 Language Model Metalearning
19:23 GPT-3: Few Shot Arithmetic
20:14 GPT-3: Few Shot Word Unscrambling
20:36 GPT-3: General Few Shot Learning
23:42 IGPT (Chen et al 2020): Can we apply GPT to images?
25:31 IGPT: Completions
26:24 IGPT: Feature Learning
32:20 Isn't Code Just Another Modality?
33:33 The HumanEval Dataset
36:0 The Pass @ K Metric
36:59 Codex: Training Details
38:3 An Easy Human Eval Problem (pass@1 -0.9)
38:36 A Medium HumanEval Problem (pass@1 -0.17)
39:0 A Hard HumanEval Problem (pass@1 -0.005)
41:26 Calibrating Sampling Temperature for Pass@k
42:19 The Unreasonable Effectiveness of Sampling
43:17 Can We Approximate Sampling Against an Oracle?
45:52 Main Figure
46:53 Limitations
47:38 Conclusion
48:19 Acknowledgements
Transcript
Great. Okay, perfect. So, a sample from this model looks like this. So, they also point to $99.6 billion from 2004063%. It's a bunch of kind of gibberish. So, the sentence isn't too coherent, but at least the words do seem to be somewhat related, like they come from the same space.
Now, jumping forward to the beginning of the deep learning boom in 2011, we have language modeling with neural networks now, and in particular with recurrent neural networks. So, we can get rid of this giant lookup table from the n-gram models, and instead we can have our inputs be these tokens and let this kind of recurrent cell remember some state and persist some state.
So, if we set up a neural model like this, we get a sample as shown below. So, the meaning of life is the tradition of the ancient human reproduction is less favorable to the good boy for when to remove vigor. So, again, this doesn't really make any sense, but it kind of starts to have the flow of a real sentence.
Yeah, so jumping forward even more to 2016, we have LSTM models, and of course, LSTMs are an architectural innovation on top of RNNs, and they have kind of better gradient flow, so they can better model long-term dependencies. And so, with an LSTM model, we get a sample like this with even more new technologies coming onto the market quickly.
During the past three years, an increasing number of companies must tackle the ever-changing and ever-changing environmental challenges online. So, this sentence is starting to make a little bit of sense, though there are clear artifacts like the repetition of the phrase ever-changing. Now, starting in 2018, we have our first autoregressive transformer-based language models, which are even better at modeling these very long-term dependencies.
And here, what I'm showing is an example of a completion. So, in a completion, the user supplies the prompt. In this case, this text swings over Kansas, and the model will continue from this prompt. So, you can see that this completion is coherent across multiple sentences now, though there are notable spelling mistakes.
So, you see this like a whatever document it is, so it doesn't quite make sense. And now, we arrive at GPT-2, which is a 1.5-billion-parameter transformer model. And I copied in what I personally found was the most compelling completion from GPT-2. And in contrast with the last slide, what this does is it sets up a clearly fake prompt.
So, we have something about finding unicorns and scientists in South America. And so, the model's probably not seen this exact prompt before and has to make up something that's consistent. So, the thing I find most impressive is it does so, and it's coherent across multiple paragraphs. It invents this fictional Dr.
Perez, and it persists Perez throughout multiple paragraphs. And I think it's very aptly named. You have him from University of LaPaz. And yeah, we just have fairly coherent completions at this point. So, it's worth disclosing that this was the best of 10 samples. So, we still had to sample multiple times to get a sample like this.
And finally, to end this session-- >> Sorry, can I interrupt? >> Yeah, yeah, for sure. >> Are you talking about just examples of it failing, the worst of the 10? >> I can pull some up, yes. Yeah, yeah. >> I'm curious to know what the bad looks like. >> Yes, yes, yes.
>> >> Wait, sorry, one last question. When you have these 10, you said we took the best of 10. That doesn't make sense. >> Yeah. So, this is human judged. And I'll probably expand a little bit on that for today. So, I want to end this kind of flyby overview with GPT-3.
And since GPT-2 already produces such coherent text, how do you characterize GPT-3? And I would say that the best way to do so is that say you took the best out of five or 10 completions from GPT-2, that would be kind of your first completion from GPT-3. And of course, best is kind of a personal metric here.
So, here I'm showing completion from the book Three-Body Problem. And you can see that the impressive things about this completion are that it really stays true to this style of the novel. I think the second thing that kind of impressed me was just how poetic like the metaphors and similes that it produces are.
So, you have this stuff like blood was seeping through her jacket and a dark red flower was blooming on her chest. It's kind of like very poetic and stylistic sentences. So, it definitely understands it's part of a novel and it's trying to generate this kind of prose in the same style.
So, as generated text becomes more and more coherent, I think one really... Yeah, yeah. So, it's 175 billion parameters versus GPT-2, which is around one billion. Yeah, yeah. That's a very good question. So, there's kind of... Maybe we can dive into it a little bit after, but there is work on kind of neural scaling laws.
And so, the idea is like, can you predict the performance of a larger model from a series of smaller models? And so, I would rather characterize the increase in performance, not by kind of the small gain in perplexity, but like whether it lines up with the projections. And in that sense, GPT-3 does.
So, yeah, that's some intuition for... Yeah. I think personally, at OpenAI, we would have stopped the experiment if we did it. So, yeah. No, I just think it's interesting how... This is like a general thing, so we don't need to go into this tangent, but in machine learning, you see people pushing for like an extra, you know, 1% to like 0.5% accuracy, but the models are increasing in a scale that's not functional.
Right, right. So, I wonder sometimes whether it's worth it and like where you should stop, like [inaudible 00:47] Right. Yeah. I think maybe this side we'll get to it a little bit, but there's also some sense in which like as you reach kind of like the entry floor of modeling, like every having kind of gives you like...
If you think about accuracy, right, it's not on a linear scale, right? Like a 1% early on isn't the same as that last 1%. And so, yeah, those last bits really do help you squeeze a little bit out of that, you know, as accuracy, yep. Sorry, excuse me, but I want to ask this too.
Oh, yes, yes. Sorry, this is accuracy. I will explain this slide. Yep. Cool. So, yep. So, as generated text becomes more and more realistic, I think one very natural question to ask is whether humans can still distinguish between real and fake text, right? And so, in here we have...
This is, of course, like a very set up scenario. It's not... In all cases, the model's able to trick humans, but this is for news articles. We kind of presented GPT-3 generated samples against real news articles. And you can tell kind of as the number of parameters increases, the ability of humans to distinguish between the real and fake articles, that that ability goes down to near random chance.
And... Oh, yes. How did you generate the news articles? What prompts did you use? I'm actually not completely sure. So, I didn't do this work particularly, but I think one possible approach would be to prime with a couple of news articles and then just to have a delimiter and just have it start generating news articles from there.
Yeah. Any other questions? Great. So, even with all of these impressive results, I think it's worth taking a step back at this point and asking, "What do we really care about language modeling for? And what is it actually useful for?" And I think one can make the argument that it is actually a fairly narrow capability.
Like, why would you just want some system that just continues text for you? And you could argue that there's more important tasks to solve, like summarization or translation. And I think most researchers at OpenAI would agree with this point of view. And in fact, GPT was not really a project that was focused on language modeling as an end goal, but mostly as a tool to solve a problem called unsupervised learning, which I'm going to go through in the next couple of slides.
So, I want to do a history of language modeling at OpenAI and hopefully motivate why we ended up at the GPT series of models and kind of how we arrived there. And hopefully it'll become much more intuitive after this session. So, the deep learning boom started in 2012 with AlexNet, which was a system that could take images and labels and it could classify images to their labels.
And what we found with AlexNet was these systems were able to generalize surprisingly well. Like you could take data sets that weren't necessarily the training distribution and you still have pretty good features on. And since then, this kind of supervised approach has been really, really powerful, right? We've been able to train models in many different domains to classify very accurately.
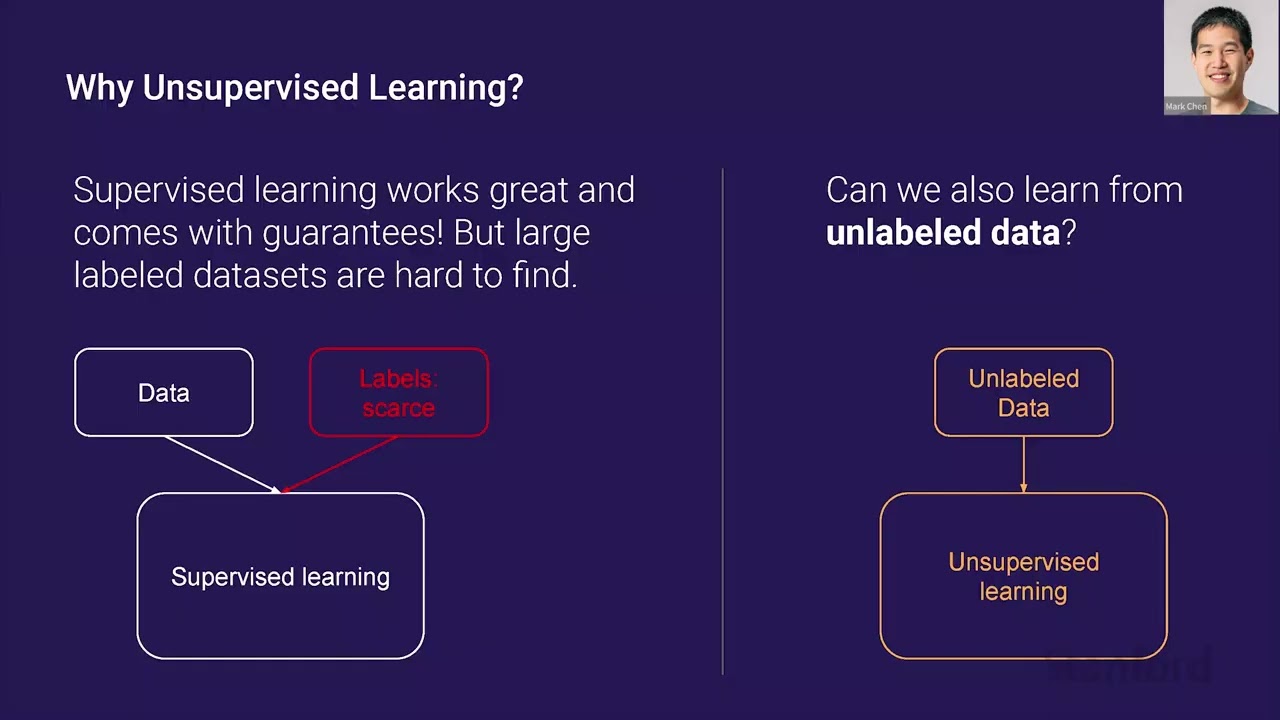
And you can even have some guarantees that supervised learning will work well. So, there's empirical risk minimization. But the problem with supervised learning is that oftentimes the labels are scarce, right? Especially in language tasks, there isn't really that many kind of texts paired with their summaries or too many pairs across languages, for instance.
So, collecting a lot of data can be not too hard, but actually scalably labeling all of that data, it could be very time consuming and expensive. So, the main problem with unsupervised learning is can we also learn from unlabeled data? And this is a lot scarier because all of a sudden we're starting to optimize an objective, which isn't the one we care about downstream, right?
So, a lot of the guarantees that we used to have, we no longer have. And we can only kind of hope that we learn some features that are adaptable to a wide variety of downstream tasks. But nevertheless, there's a reason to be very optimistic in language. And the reason is that there is a huge trove of unlabeled data and it's called the internet.
And so, the real question is, can we leverage all this unlabeled data from the internet to solve language tasks where we don't really have that much data? And the hope is that if we kind of pre-train this model on the internet, you'll see all of these words used in different settings, kind of understand the relationships, and you'll be able to leverage this kind of understanding for any kind of task we do.
So, now that we've established why language is such a good domain to try unsupervised learning in, let's talk about why use generative models for it and also why use autoregressive generative models. And I do want to stress that a lot of the guarantees you have with supervised learning are no longer there for unsupervised learning.
So, some of these arguments will be a little bit kind of intuitive. And so, the first argument I want to present is this quote by Richard Feynman, which is pretty widespread. So, what I cannot create, I do not understand. And there's the inverse of this idea, which we call analysis by synthesis.
And it's what I can create, I can also understand. And this has been studied by Josh Tenenbaum. There's definitely some kind of biological motivation as well for it. But the idea here is that if you're able to create a language model, which can generate diverse samples that are coherent, then it must also build up representations that can help you solve language understanding tasks.
And then the next question is, why do we use autoregressive models? You might argue that autoregressive models are a kind of local objective, right? Like you're just predicting the next words. You could do really well with kind of some N-gram approximation, right? Why would it be good at solving things that allow you to summarize an entire piece of text?
And so, an intuitive argument here could be, say that you wanted to do very well on language modeling for a mystery novel. And there's this grand reveal at the end, like, oh, like the culprit was, and then you want to predict that next token. And to do really well at that task, you really need to have a good understanding of what happened in the story, along with all the twists and turns, and maybe even some of this kind of like deductive reasoning built in.
So the first sign of life, oh, you got a question? Oh yeah. So the first sign of life we had at OpenAI was in the task of predicting whether Amazon reviews were positive or negative. And this was work done in 2017. So instead of training a classifier in the kind of typical supervised way, what we did was we trained an LSTM model just to predict the next character in Amazon reviews.
And when we trained a linear model on the features from this LSTM, what we found surprisingly was like one of these cells or one of these neurons was firing in terms of predicting sentiment. And positive activations for this neuron corresponded to positive reviews and negative activations to negative reviews.
And this was despite not seeing any of the labels at training time. So you can even track kind of what this neuron value is across a sample. So it's a little bit hard to read, but these are reviews where maybe someone says, oh, I really like this film, but I didn't like this part.
And you can kind of see the sentiment switching as you go from positive to negative. So yeah, just predicting the next character resulted in-- oh, yeah? Was there any sort of complicated architecture to encourage it? Oh, yeah. No, no. This was just a pure LSTM. Oh, yeah. So you basically looked at all the neurons and saw which ones were most-- Yeah, in the hidden state.
Yeah. So you train a linear classifier on top of that, and one neuron is firing with, yeah, just outsized predictive power. Yeah. Great. So next, GPT-1 was one of the first demonstrations that this kind of approach could work broadly for text. So GPT-1 was trained on the internet, not on Amazon Reviews anymore, and it was fine-tuned on a bunch of different downstream tasks.
And one thing to stress here was kind of to your point that the fine-tuning was very, I guess, minimally kind of-- you're not kind of bashing the architecture apart and kind of repurposing new modules. And it's just a new head that classifies for your task. And this showed that you can use this approach not just for semantic analysis, but also for entailment, semantic similarity, and getting SODAs on a lot of these benchmarks downstream.
So I've already presented GPT-2 from the point of view of a very powerful language model. And now, I think it's worth revisiting from the viewpoint of unsupervised learning. So like GPT-1, GPT-2 was trained on a large chunk of the internet. And it's only trained to predict the next token or word from previous words.
But the key insight of GPT-2 is that many downstream tasks can be expressed naturally as a language modeling task. And yeah, so GPT-2 explores how well we can perform on downstream tasks simply by using this method without any fine-tuning. So let me start with a couple of examples. So let's say you want to solve some reading comprehension benchmark.
And this is usually set up as a prompt, which is some passage you have to read, and then a bunch of questions which you have to answer. So you can literally just take the entire prompting context. You put a question colon. You write out the question, answer colon, and then have the model complete from there.
And this kind of gives you zero-shot reading comprehension. We can also use it for other tasks, like summarization. For instance, here's like the beginning of a CNN article about some archaeological finding. And you can just put TLDR after you see this passage. And the model, hopefully, if it's good enough, will produce good summaries.
And the final example I want to show is that you can do zero-shot translation as well. So the way you would do this is if you wanted to convert, let's say, a French sentence into English, you could set up a prompt like the sentence-- insert the French sentence, translate it from French to English means, and then the model will complete.
And you can sometimes do this as well. And one kind of critical thing to note here is that here's the chart of performance as you increase the number of parameters. And in all these models, they were trained on the same data set. So the only kind of compounding variable is scale.
And you can see that as we scale up the models, these kind of zero-shot capabilities emerge and kind of smoothly get better. So the role of scale is important here. And yeah, and I think these are starting to approach some-- I guess they're not great benchmarks, but at least respectable benchmarks.
Yeah, yeah, yeah, exactly. It's not going to be great in a lot of cases. And to be honest, the blue metric used for translation is actually often-- oh, thank you very much. It's not a great metric. What it does is it takes a reference solution. And basically, it does some kind of like n-gram comparison.
So it is a big problem to have good translation metrics in an LP. And yeah, I think when I talk about code, I'll talk a little bit more about it. Right, so let's finally talk about how GPT-3 fits into this picture. So the primary insight of GPT-3 is that the training process itself can be interpreted in the context of meta-learn, which is kind of like learning over a distribution of tasks.
And during training, what the model is doing is it's developing certain kind of capabilities. It's picking up some set of skills in terms of modeling certain passages. And during inference time, what it's doing, it's quickly picking up on what a task is based on what the prompt is so far, and adapting to that task to predict the next token.
So you can view there's this outward loop of all the SGD steps you're doing during training, this inward loop of picking up on what the task is, and then modeling the next token. So you can imagine a lot of tasks being framed in this way. For instance, on the left, you can have addition.
You have a lot of examples of addition in context. And hopefully, that would help you with a new addition problem, or you can try to unscramble a word, for instance. And I'll explore results on these two benchmarks in the next slides. So this setting we call a few-shot arithmetic.
And just to explain what's going on, you're taking the entire context slide of your transformer, and you're putting in as many examples as will fit. And then finally, you put in the example that you would like to solve. So here, these examples could be these kind of first three addition problems, and then you have 31 plus 41 equals, and you ask the model to complete.
So you notice that as the language model gets bigger, it's better able to recognize this task. And you can see that performance on addition, subtraction, even some kind of multiplication tasks increases sharply as you go towards 200 billion parameters. And there does seem to be some step function change right here.
And looking at word unscrambling, this is also true. So we have parameters, again, on the x-axis. We have accuracy, and each of these is a different kind of unscrambled task. So this blue line is you do a cyclic shift of the letters, and you want it to uncycle. And there's a lot of other transforms you can do, like randomly inserting words, for instance.
So the final point here is that this is a pretty general phenomenon. We didn't just test it on these two aforementioned tasks. We tried an array of, I think, 40 plus tasks. And here you can see how the zero shot, one shot, and few shot performance increases as we scale the models.
So of course, they're all smoothly increasing. But one thing to be aware of is that the gap between zero shot and few shot is also improving as a function of scale. Awesome. So we've just seen that we can pre-train a transform-- oh, go ahead. Yeah. One is the tasks themselves that we're using.
Two is the number of parameters. And then three, my understanding, is also the quantity of data that we've ingested. Yeah, yeah. And I was curious between those three, which ones-- you've shown a lot of-- the number of parameters definitely helps. I was curious, though, in terms of the degree to which also the training tasks and the sophistication of the tasks, as well as the quantity of data ingested.
Yeah, yeah. So I guess I can dive-- maybe it's something to save for after. But yeah, let's dig into that after. Yeah. I guess GPT-2 and 3 aren't different. GPT-1 just has an extra classification head for the training tasks. Yeah. Yeah. Great, yeah. Good questions. So yeah, we've just seen that we can use a transformer in this pre-train and binding setup, where we have a lot of unlabeled data in the pre-training setting.
And we have just a little bit of data in the binding setting. And we can solve a lot of language tasks in this way. And I would say this has become the dominant paradigm in language over the last couple of years. So there's follow-up objectives like BERT and T5, which have done extremely good at pushing the SOTA.
But there's nothing really that says that these transformer models have to be applied to language. The transformer is a sequence model. And as such, it can just ingest any sequence of bytes and model them. And when you think about this, all of the data that we consume, like videos or audio, they're represented on our computers as sequences of bytes, right?
And so you might think, oh, could this approach be used to just model whatever modality we want? And I think this kind of paradigm is very, at least interesting, when we don't really have good inductive biases. Like we don't data. But one question to ask is, does it even work when you do have really strong inductive biases?
So I'm going to present some work that suggests that the answer is, yes, it still works fairly well in this case, in the domain of images, where convolutions are already so popular and proven out. And I'm going to show a second result very briefly here, which is DALI, which shows that it's strong enough to even ingest two different modalities and be able to jointly model them.
So the first question is, how would you apply GPTU to images? And there's a few things you have to do. You have to modify this autoregressive next word prediction objective. So the natural analog is, you can think of images as a very strange language, where the words are pixels instead.
And instead, you need to predict the next pixel at each point. And so we can just change the objective from next word prediction to next pixel prediction. And of course, we want this kind of large-- Oh, yeah. So you just unroll it as a sequence. It's the same way it's stored on a computer.
You just have a sequence of bytes. Yeah. Yeah, good question. So in the language setting, we pre-train on this large unlabeled data set on the internet, and we fine tune on question answering or these other benchmarks. In images, one good analog of this situation is you can pre-train on image net without the labels.
You have, let's say, a low resource-- low data, sorry, setting, like CIFAR. And you can try to attack CIFAR classification. And of course, in both settings, you can do fine tuning. In GPT, you can do zero shot. And I would say the standard eval on images is you do linear probes.
So you take features from your model. The model is frozen. You pass through CIFAR through the model, get some features, and you see how predictive these features are of the CIFAR classes. Is it kind of pixels there, which basically you ask a model to predict the max pixel given the-- Yeah, yeah.
So pixel CNN is an instantiation of an autoregressive image prediction model. So what we're asking here is, can we actually take the same transformer architecture that we use in language, don't make any modifications at all, and just throw-- so there's no kind of 2D prior. So yeah, I'll call this a model that we train image GTC or IGPT for short.
And here you can see actually what some completions from the model look like. So on the left column, what I'm feeding in is the pixels of the first half of the image. And the next four columns, what you're seeing is different model-generated completions. And the right column here is the original reference image.
And you can actually see that the model is kind of doing some interesting things. If you look at the last two rows, it's not coming up with semantically the same completion every single time. It's like putting these birds in different settings, sometimes adding reflections. It's putting this lighthouse in grassy areas and watery areas, for instance.
So if you buy into this philosophy of analysis by synthesis, we definitely have some hint of the synthesis part. So I don't have time to go through all the results with you. But I just want to say that it is fairly successful in this SIFAR setting where you don't have much labeled data.
If you train a linear model on top of the features, you get better results than if you do the same approach with a ResNet trained on ImageNet with labels. So that's like the typical approach in the field. You train some ResNet on ImageNet, you get the features. Oh yeah.
And if you compare to this approach, a generative model on ImageNet without the labels, take the features, it's actually better predictive of synthesis. Yeah. I'm just curious, once the architecture for this is the same as GPT? Oh yeah. Exactly. Yeah, yeah, yeah, yeah. It's the GPT architecture. So you can modify GPT to have 2D bias.
You can do 2D position embeddings. Well, we don't do that. We just want to see, can you use the same exact approach? So early use of the data is just sequential. Yeah. But also there's metadata showing about how that sequential should be reconstructed. Like what's the weight, for example.
Oh, can you explain? So the data on this stored, but when you want to transform that sequence into an image, you have metadata that will say something like, just like in NumPy arrays, it'll say, here's the strike. So here's how to rearrange it. I see. What I'm curious to notice is GPT, before it's given an image, at least given this metadata.
I see, I see. Okay. Yeah, that's an extremely good question. I don't know how this problem is solved. Yeah, yeah, yeah. In this case, all the images have the same shape. Oh, okay, okay. Yeah, but we don't tell it the concept of row within the model. Yeah, but all images are the same shape.
Yeah, so it needs to learn it from the data, but yeah, the data looks the same. Got it. Yeah. It'll be interesting if it's variable image shapes, then it's going to be interesting to do it. Yeah, yeah. Cool. Are there a lot more pixels than there are token sizes in the context there?
Yeah, so this is a pretty low resolution images. Yeah, so we can actually, the models we're comparing against are trained on kind of high resolution images. So I think that makes it even more impressive. But yeah, we're just training at 32 by 32 resolution. Yeah. Cool. So if we fine tune these models for CIFAR classification, we can get 99% accuracy, which matches G-pipe.
And this is G-pipe, for instance, is a system which is pre-trained on ImageNet with labels and then also fine tuned with labels. So yeah, it just kind of shows you like even this approach, which doesn't really know about convolutions can do well. I think you're going to hear more about that next week with Lucas' talk.
Cool. So by now, it shouldn't be surprising at all that you can model a lot of different modalities with transformers. So in DALI, we just asked, what about throwing two different modalities at the model and seeing if it can learn kind of how to condition on text to produce an image.
And for instance, one thing you might want it to do is like you provide one of these text captions and you want it to generate some image like the one below. And the easy way to do this is just train a transformer on the concatenation of a caption and an image.
And of course, in a lot of these situations, the idea is very simple, but the implementation and execution is where the difficulty is. And I'm not going to talk too much about that. I think the focus today is on language, but you can refer to the paper for a lot of those details.
Oh, yeah. So you have a max caption length and you just kind of cut it off at that length and you can pad up to that. Right. So you can see that it can generate fairly good samples. So if you want like a storefront with the word "OpenAI" on it, it's not perfect, but it's understood at least it's kind of like reverse OCR problem where you take some text and render it.
And it's kind of typically rendering it in like office looking places. So that's one encouraging sign. But I do think my favorite results here are zero-shot image transformation. So what's going on here is, for instance, if your prompt is the exact same cat on the top as a sketch on the bottom and you feed in the top half of it, this image, which is a cat, and you ask it to complete the rest of the image, then it'll render the top cat actually as like a sketch.
And you can do the same thing with like flipping over photos, for instance. You can zoom in to a photo. Of course, they're not perfect, but it has some understanding of what the text is trying to do. In the captions originally, like the training, in the training set, do they have like wording such as extreme close up view?
I think that is the, it probably are some examples like that. And that's probably where it's picking up some of this knowledge from. Though we don't seek out these examples. It's just, yeah, yeah, exactly. Okay. Perfect. Yeah. So this is just how we just go and do a massive web script.
There's no kind of, we're not trying to find examples like this. Right. And so you can also do things like colorization, right? You can take the cat color red, and this has to kind of recognize that what the object is in the figure. And yeah, and here you can do stuff like semantic transformations, like adding sunglasses into the cat, and you can put it on postage, for instance.
Yeah. So it's remarkable that you can do a lot of these, like transform zero shot. It wasn't trained to do these things specifically. Cool. So moving on, the last section of my talk today is on codex, which is our most recently released code writing models. And the first question you should rightly ask here is why, why train them all on code anyway?
Isn't at this point, isn't it just another modality and what is the novelty that there is at this point? Right. So let me give you a couple of reasons. So the first is that GPT-3, it had a rudimentary ability to write Python code already from a doc string or descriptive method name.
And we actually didn't train it on much code data. Actually, I think there might've been active filtering to get rid of code data. And so we were surprised that there was this capability anyway. So that, you know, like if we actually purpose the model and trained it on the large amount of code that we can find, maybe something interesting will happen there.
Next, what sets apart code from other modalities is that there is a kind of ground truth correctness of a sample and functions can be tested with unit tests and an interpreter. So this is very different from language, whereas to get a ground truth, you might need a human to come in.
And even then sometimes humans won't agree like this, this is the better sample or this isn't the better sample. And the last thing is I used to dabble in competitive programming myself and yeah, I really wanted to create a model that could solve problems that I could. So yeah, we wrote a paper on it too.
So yeah. I think it's kind of a high-level programming language which is similar to our human language. Have you guys ever tried to predict some even lower level languages like CPP? Yeah. I think there's, yeah, there's follow-up work where we just train on a bunch of different languages and I don't know the metrics off the top of my head, but I have seen some assembly writing models.
Yeah. Cool. So I guess, yeah, continue on the third from before. So we have this setting where we have unit tests and interpreter. So how do we actually evaluate these models in a way that's kind of aware of these two concepts? So the first thing we did was we have a data set, a new data set, which is 164 handwritten programming problems.
And these kind of have the format shown here. Like there's a function name, a doc string, there's a solution and there's an average of around eight units per problem. And why is it important that we hand wrote these? Well, the thing is we're training on such a large part of GitHub.
Like if you said, okay, I'm going to take like some B code problems and I'm going to turn them into an evaluation, that's not going to work because there's just so many GitHub repos that are like, oh, here's the solution to this B code problem. So while this doesn't kind of guarantee that this problem isn't duplicated, at least someone wrote it without trying to copy it from another source.
So here's some kind of examples of a unit test that you would evaluate the previous function on. I think it should be fairly clear that we should be using this metric. This is the correct kind of ground truth metric to use. I mean, humans do use unit tests to evaluate code.
And I would say if you're familiar with competitive programming, you can't manually judge all like tens of thousands of submissions that are coming in. You need the unit tests and that is a fairly good filter. So one interesting point here was we had to create a sandbox environment to run these kind of generated solutions in.
Because when you train on GitHub, there's a bunch of malicious code. There's a bunch of kind of insecure code. You know, all your models should be sampling that and kind of running that on your environment. Cool. So now that we have an evaluation data set, let's define a metric.
And so the metric we're going to use is called pass at K. And the definition is the average probability over all the problems that at least one out of two samples passes the unit test. So if we evaluate this metric by just taking every problem and exactly generating K samples, it's actually not, there's high variance just kind of sampling in that way.
But you imagine the pass rate of a particular sample is around one over K. This is kind of like an all or nothing metric. So what we do instead is we generate a much larger set of samples and greater than K. Most of the times it's like greater than 5K.
And we count the number that are correct and we compute this unbiased estimator. And it looks more complicated than it actually is. It's just complimentary counting. You take kind of the number of combos where all of them fail. Cool. So then we train our model. And like I alluded to earlier, there's 160, about 160 gigabytes of code, which is collected from 54 million repositories.
For efficient training, what we did was we fine tuned from GPT-3 models of various sizes. And this isn't actually strictly necessary. We find that we can get to roughly the same final loss and performance without this, but it is slower to do it without the super training stuff. And so we already have these models, why not just fine tune them?
And one extra trick to make training much faster here is in code, there's a lot of runs of spaces, right? And those don't get compressed efficiently in language because you just don't see them very often. So they typically get broken up into like many separate tokens. So we introduce additionally some tokens that compress runs of that space.
And that makes training maybe like 30 or 40% more efficient. Yeah, exactly. Yeah. Great. So once we have these models, we can go and revisit the human eval data set. And I can share a couple of problems to give you a sense of where the models are at and also what kind of difficulty level the problems in the data set are at.
So this is a 12 billion parameter model that passed out 90%, which means that 90% of the samples will pass the unit test. And this is something like anyone doing a first day of Python would be able to do. So you increment all the elements of a list by one.
Here's a problem where the pass rate is 17%. So this is the problem I gave earlier. So you are given a non-empty list of integers. You want to return the sum of all odd elements that are in even positions. And this might not sound that much harder to you, but models can often get confused about like, "Oh, is odd referring to positions or elements?" And so here you can actually see that it's doing the right thing.
And finally, this is an example of one of the harder problems in the data set. So the pass rate is under 1% here. And so what's going on here is actually there's an encode function which takes a string. It chunks it up into groups of three characters and it does a cyclic shift on each character.
And you have to write a decoder, something that reverses this operation. So you can see that the model, this is a real model solution. So it chunks up the characters in the same way. You can see that the cyclic shift is the opposite way. So up there, it takes the first element of each group, moves it to the end, and now it takes the last element of each group, moves it to the end.
Okay. So I'm wondering what's the effect of... So you had a couple of examples in the previous slide, but you didn't give us in the comments. So I'm wondering if the model will be able to extrapolate what it's doing by the examples on its own and not relying on the distribution.
Right. Yeah. So some of our tasks, there are some examples in the doc string, and some of them don't. I think it's just to kind of match the distribution of real kind of tasks we find in the real world. Like in this case, it doesn't have it, but definitely for the unit tests, none of those appear within...
I'm just curious if you just give it the examples and not be able to distribute all the tasks. Oh, I see. I see. So can it do like pure induction where you don't tell the task at all? Yeah. I haven't tried it, to be honest. I think it's worth a shot.
Yeah. Thanks. Yep. So yeah, at this point, we've trained codex models, we've evaluated on this metric, but the thing is, was it worth all this trouble? You already have these metrics like blue that are match-based in language. Couldn't we have just used this to approximate it? We don't need an interpreter, we don't need to generate so many samples.
And it would be great if it kind of separated out like this. But what we find is that this is, if you take four random problems from human data, and you plot the distribution of blue scores for correct and wrong solutions, you actually find a lot of distributional overlap, right?
It's hard to distinguish the green from the blue distribution. And so this suggests that blue actually isn't a very good metric for gauging functional correctness, and that we actually do need this new kind of metric and this new data set. So now let's explore the setting where in PASAC-K, K is greater than one.
And so the first observation we have here is that the temperature that you sample at, it affects your PASAC-K. And just for some intuition, if you do temperature zero sampling, you're going to get the same sample every single time you're doing hard fact sampling. So it doesn't matter how many samples you generate, you're just going to get the same PASAC-K.
But if you want to generate a hundred samples, you can afford to make some mistakes. You just want a very diverse set of samples. So you can up the temperature. You can see kind of as you up the temperature, the slope of the kind of number of samples against pass rate, it becomes steeper.
And so you can kind of take the upper hull of this and you can find the optimal temperature for each number of samples. And so this brings me to personally my favorite result of the paper, which I call the unreasonable effectiveness of sampling. And so let me explain what's going on here.
So this is the number of parameters in the model, and here you have pass rate at one and a pass rate at a hundred. And the reason I use this term unreasonable effectiveness is that I think there's a world where if the orange line and the blue line weren't that far apart, I might not be that surprised.
At these scales, the model, it rarely makes kind of syntactical errors anymore. Like if you run it, it'll run and produce some kind of output. So you could imagine a world where basically what you're doing, the model has some approach in mind. It's just repeatedly sampling that approach and it's just either right or wrong.
But instead, what we find is that the model is actually composing different parts and producing functionally different things. And you get this huge boost from under 30% to over 70% just by sampling a lot of samples from the model. So unfortunately, knowing that one of your samples is correct, it isn't that useful if you don't have access to the unit tests.
And one setting where, practical setting where you would care about this is say you're creating an autocomplete tool, right? And you generate a hundred samples, but you don't want to show your user a hundred samples and have them pick one, right? You want to kind of try to pre-filter, but you don't have unit tests.
So can we kind of approximate this Oracle sampling with some other ranking heuristic? So here I'm showing a couple of different heuristics. You can randomly pick one, but the one that seems most promising is to rank by mean probability. And I know it's kind of maybe not theoretically well grounded, but in language, this kind of heuristic is fairly strong as well.
So recall that what we're doing is we have this evaluation set where we have kind of standalone functions. We want to produce solutions to that. But when we're doing training, there's a lot of code that isn't relevant for this task. For instance, there's a lot of classes that we're seeing.
There's actually data classes too, which aren't relevant at all. And actually there's a lot of incorrect code on GitHub too. So we might be modeling incorrect solutions as well as correct ones. So one thing we thought was let's fine tune codecs on further on a couple of data sets where they are standalone functions and you have kind of more guaranteed correct solutions to that.
So what we did was we found these problems from a couple of sources. So one is competitive programming problems. You can kind of go on these sites. Oftentimes they'll just give you the unit test. Sometimes when they don't give you the unit test, you can submit incorrect solutions and they'll tell you the first one you failed on and then you can kind of keep inserting that in.
So you can get a lot of competitive programming problems. And another source is projects where continuous integration is enabled. So why are these useful? Because you can actually kind of do an execution tracing. So when you run the integration tests, you can get all the inputs to functions that are called and their outputs as well.
And so you actually have the true function body. You know what the test output is supposed to be. You know, kind of the ground truth inputs and outputs. And these are kind of like two orthogonal data sets. One kind of helps you with like algorithmic kind of tasks. And one is more kind of like, can I manipulate command line utilities and tasks like that.
So this brings us to the main figure of the codecs paper. So really what we're seeing is a progression of capability. So with GPT-3 on this human eval data set, the pass rate at one is zero. Basically you can generate like one or two lines coherently, never really a whole program coherently.
Now when you fine tune on code, which is codex, this orange line, you start to see some kind of non-noticeable performance on this data set. When you do this additional supervised fine tuning, that's this green line, you get even better pass rates. And then if you kind of generate a hundred samples from this model, re-rank with mean log P, even better pass rates.
And finally, of course, if you have access to an Oracle, it gives you the best pass rates. So I have one question here. So can you actually use a re-ranking to like, like for the, to the model? Can you use it for like as a backdrop signal? Yeah, yeah.
So we've explored that. I don't know if I can say too much about these results. And finally, I don't want to suggest that these, these models are perfect. They have a lot of limitations that human programmers don't run into. So one is like, actually all generative models are autoregressive generative models, kind of, we have some problems with binding.
So when there's like a lot of variables going on, like a lot of operations going on, sometimes it's like hard to figure out which operation is binding to which variable. So you can kind of see some examples of that on the left. And one other kind of counterintuitive behavior is composition.
So we can take a bunch of very simple building blocks, like take a string and reverse it, or, or like delete every third character or something. And assuming like, if you can chain two of these operations, you could probably chain 10 of them, but our models aren't able to do that yet.
Cool. So moving on to the conclusion, we have four main points in today's talk. So first progress in neural language modeling has been fairly rapid. And at GPT, it wasn't the result of a push on language modeling and more of a result of work on pushing unsupervised learning in language.
The third point is that autoregressive modeling is universal and it can yield strong results even when there are strong adaptive biases, like in images or in text. And finally, we can produce strong co-generating models by fine tuning GPT3 on code. And sampling is an unreasonably effective way to improve model performance.
Cool. And to end with some acknowledgments, I want to thank my CodeX primary co-authors, some mentors at OpenAI and the algorithms team, which I have worked very closely with. Great. Thank you guys for your attention. Thanks. Bye.