Claudette source walk-thru - Answer.AI dev chat #1
Transcript
OK, hi, everybody. I'm Jeremy. And this is the first of our Answer.ai developer chats, where I guess we have two audiences. One is our fellow R&D folks at Answer.ai, who hopefully this will be a useful little summary of what we've been working on for them. But we thought we'd also make it public because why not?
That way everybody can see it. So we've got Jono here. We've got Alexis here. We've got Griffin here. Hi, all. Hey. And we're going to be talking about a new library I've been working on called Claudette, which is Claude's friend. And Jono has been helping me a bit with the library, but he's going to, I think, largely feign ignorance about it today in order to be an interviewer to attempt to extract all its secrets out of my head.
Does that sound about right, Jono? I think so, yeah. OK. I'm ready when you are. Cool. Well, maybe we should start with-- do you want to pull up the landing page? And then I think there's a few different directions that I'd love to hear from you. One is the specifics of this library, how does it work?
But maybe also, since especially this is the first developer chat and preview, we can also go into some of the meta questions like, when does something become a library like this? How is it built? What's the motivation? Et cetera, et cetera. Sounds good. All right. So here we are, the landing page.
So it's a GitHub repo. It's a public repo. And in the top right is a link to the documentation. And the documentation that you see here, the index, is identical to the README. But it's better to read it here because it looks a bit better. Cool. Fantastic. And this is a library that people can pip install?
Yep, exactly. Here it is, pip install Claudette. And you can just follow along. Hopefully, when you type the things in here, you'll get the same thing. Or you could-- so that main page is actually also an index.ipynb. So you could also open that up in Colab, for example. And if you don't want to install it locally, it should all work fine.
Cool. So I'll start with the big question, which is, why does this exist? What is the point of this library in a nutshell? OK, so by way of background, I started working on it for a couple of reasons. One is just I feel like-- felt like-- still feel a bit like Claude is a bit underrated and underappreciated.
I think most people use OpenAI because that's kind of what we're used to. And it's pretty good. And with 4.0, it's just got better. But Claude's also pretty good. And the nice thing about some of these models now, with also Google there, is they all have their things they're better at and things that they're worse at.
So for example, I'm pretty interested in Haiku and in Google's Flash. They both seem like pretty capable models that maybe they don't know about much, but they're pretty good at doing stuff. And so they might be good with retrieval, which is where you can help it with not knowing stuff.
So yeah, I was pretty interested, particularly in playing with Haiku. And then a second reason is just I did this video called A Hacker's Guide to LLMs last year. And I just recorded it for a conference, really just to help out a friend, to be honest. And I put it up online publicly because I do that for everything.
And it became, kind of to my surprise, my most popular video ever. It's about to hit 500,000 views. And one of the things I did in that was to say, like, oh, look, you can create something that has the kind of behavior you're used to seeing in things like Constructor and Langchain and whatever else in a dozen lines of code.
So you don't have to always use big, complex frameworks. And a lot of people said to me, like, oh, I would love to be able to use a library that's that small so I don't have to copy and paste yours. And so I thought, like, yeah, OK, I'll try and build something that's super simple, very transparent, minimum number of abstractions that people can use.
And that way, they still don't have to write their own. But they also don't have to feel like it's a mysterious thing. So yeah, so Claudette is designed to be this fairly minimal, like no really very few abstractions or weird new things to learn, take advantage of just Python stuff for Claude, but also to be pretty capable and pretty convenient.
Cool. You think it would be fair to say that this is more replacing the maybe more verbose code that we've copied and pasted from our own implementations a few times versus introducing too many completely new abstractions? Is that the kind of level that it's in? Yeah, I think a lot of people got their start with LLMs using stuff like LangChain, which I think is a really good way to get started in some ways and that you can-- it's got good documentation and good demos.
But a lot of people kind of come away feeling like, I don't really know what it's doing. I don't really know how to improve it. And I don't feel like I'm really learning at this point. And also, I don't really know how to use all my knowledge of Python to build on top of this because it's a whole new set of abstractions.
So partly, it's kind of for those folks to be like, OK, here's how you can do things a bit closer to the bone without doing everything yourself from scratch. And for people who are already reasonably capable Python programmers feel like, OK, I want to leverage that, jump into LLMs and leverage my existing programming knowledge.
This is a path that doesn't involve first learning some big new framework full of lots of abstractions and tens of thousands of lines of code to something with, I don't know what it is, maybe a couple of hundred lines of code, all of which is super clear and documented.
And you can see step-by-step exactly what it's doing. Cool. Well, that sounds good. Do you want to start with a demo of what it does, or do you want to start straight with those hundred lines of code and step us through it? You know what? I'm inclined-- normally, I'd say do the demo, but I'm actually inclined to step through the code because the code's a bit, as you know, weird in that the code is-- so if you click on Claudette's source, we can read the source code.
This is the source code. It doesn't look like most source code. And that's because I tried something slightly different to what I've usually done in the past, which I've tried to create a truly literate program. So the source code of this is something that we can and will read top to bottom.
And you'll see the entire implementation, but it also is designed to teach you about the API it's building on top of and the things that it's doing to build on top of that and so forth. So I think the best way to show you what it does is to also show you how it does it.
So I'm here in a notebook. And so that source code we were viewing was just the thing called Quarto, which is a blogging platform that, amongst other things, can render notebooks. So we're just seeing the rendered version of this notebook. And so the bits that you see in gray are code cells in the notebook.
Here's this code cell. Here's this code cell. And then you'll see some bits that have this little exported source thing here, which you can close and open. You can close them all at once from this menu here, hide all code. And that basically will get rid of all the bits that are actually the source code of the model.
And all you'll be left with is the examples. And if we say show all code, then you can see, yeah, this is actually part of the source code. And so the way that works is these things that they say exports. So this is bits that actually becomes part of the library itself.
OK, so the idea of this notebook is, as I said, as well as being the entire source code of the library, it's also by stepping through it, we'll see how Claude works. And so Claude has three models, Opus, Sonnet, and Haiku. So we just chuck them into a list so that anybody now who's using Claudette can see the models in it.
And so the way we can see how to use it is that the readme and the home page, again, is actually a rendered version of a notebook. And it's called index.ipynb. And so we can import from Claudette. And so you can see, for example, if I say models, it shows me the same models that came from here.
OK, so that's how these work. It ends up as part of this Claudette notebook. So that's the best Claude bottle, middle, worst. But I like using this one, Haiku, because it's really fast and really cheap. And I think it's interesting to experiment with how much more you can do with these fast, cheap models now.
So that's the one I thought would try out. Any questions or comments so far from anybody? I guess, so far, this is-- like, there's no reason you couldn't just write the full name of the model every time, like a lot of people do. And if a new one comes out, you can do that.
But this is just trying to make it as smooth as possible, even to these tiny little details, right? Yeah, I don't want to have to remember these things. And obviously, I wouldn't remember those dates or whatever. So otherwise, I could copy and paste them. But yeah, I find I've been enjoying-- I've been using this for a few weeks now.
Once it got to a reasonably usable point-- and definitely, this tiny minor thing is something I found nice is to not have to think about model names ever again, and also know that it goes, like, best, middle, worst. So I don't even have to-- I can just go straight to, like, OK, worst one.
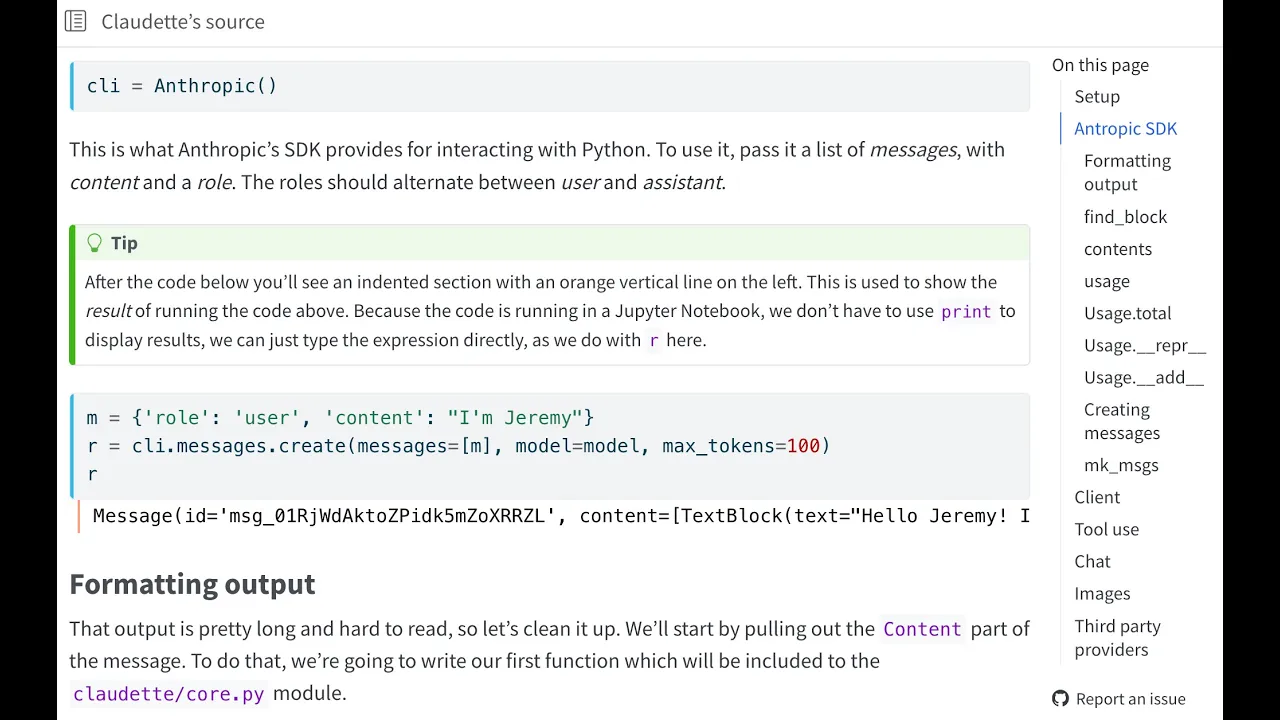
Cool. So they provide an SDK, Anthropic. So their SDK gives you this Anthropic class you could import from. So you can pip install it. If you pip install Claudette, you'll get this for free. So I think it's nice if you're going to show somebody how to use your code, you should, first of all, show how to use the things that your code uses.
So in this case, basically, the thing we use is the Anthropic SDK. So let's use it, right? So the way it works is that you create the client. And then you call messages.create. And then you pass in some messages. So I'm going to pass in a message, I'm Jeremy.
Each message has a role of either user or assistant. And in fact, they always-- this is, like, if you think about it, it's actually unnecessary, because they always have to go user assistant, user assistant, user assistant. So if you pass in the wrong one, you get an error. So strictly speaking, they're kind of redundant.
So in this case, and they're just dictionaries, right? So I'm going to pass in a list of messages. It contains one message. It's a user message. So this is something I've said, whereas the assistant is something the model said. And it says, I'm Jeremy. And then you tell it what model to use.
And then you can pass in various other things. As you can see, there's a number of other things that you can pass in, like a system prompt, stop sequences, and so forth. And you can see here, they actually check for what kind of model you want. So if I go ahead and run that, I get back a message.
And so messages can be dictionaries, or they can also be certain types of object. And on the whole, it doesn't really matter which you choose. When you build them, it's easier just to make them dictionaries. So a message has an ID. I haven't used that for anything, really. And it tells you what model you used.
Now this one's got a role of assistant. And it's a message. And it tells you how many tokens we used. If you're not sure what tokens are and basics like that, then check out this Hacker's Guide to Language Models, where I explain all those kinds of basics. But the main thing is the content.
And the content is text. It could also reply with images, for instance. So this is text. And the text is, that's what it has to say for me. So that's basically how it works. It's a nice, simple API design. I really like it. The OpenAI one is more complicated to work with, because they didn't decide on this basic idea of like, oh, user assistant, user assistant.
OK, so one thing I really like-- Can I ask a question? Yeah, hit me. So one thing I know, and I'm sure lots of other people do as well, is that often when you interact with an assistant, you provide a system message or guidance about how the assistant should see their role.
Here, you didn't. You just started right off with a role from yourself as a user. Is that because the API or this library already starts with the default guidance to the assistants? There's a system prompt here. And the default is not given. So yeah, language models are perfectly happy to talk to you without a system prompt.
Just means they have no extra information. But they went through instruction fine-tuning and RLHF, some of those examples would have had no system prompt. So they know how to have some kind of default personality, if you like. Yeah. Cool, thanks. OK, so I always think, like, my notebook is both where I'm working.
So I want it to be clear and simple to use. And I also know it's going to end up rendered as our documentation and as our kind of rendered source. So I don't really want things to look like this. So the first thing I did was to format the output.
So here is part of the API. This is exported. So the first thing I wanted to do was just, like, find the content in here. And so there's a number-- this is an array, as you can see, of blocks. So the content is the text block. So this is just something that finds the first text block.
I mean, it's tiny. And so that means that now at least I've kind of got down to the bit that has-- the bit I normally care about, because I don't normally care about the ID. I already know what the model is. I know what the role's going to be, et cetera.
And then so from the text block, I want to pull out the text. So this is just something that pulls out the text. And so now from now on, I can always just say contents and get what I care about. So something I really like, though, is like, OK, this is good, but sometimes I want to know the extra information, like the stop sequence or the usage.
So in Jupyter, if you create this particular named method representation in Markdown for an object, then it displays that object using that Markdown. So in this case, I'm going to put the contents of the object followed by the details as a list. And so you can see what that looks like here.
There's the contents, and there's the details. And if you're wondering, like, OK, how did Jeremy add this behavior to Anthropx class? Now, this is a nice little fast core thing called patch, where if you define a function, and you say patch, and you give it one or more types, it changes those existing types to give it this behavior.
So this is now, if we look at tools beta message dot prep for Markdown, there we go. We just put it in there. So that's nice. And so the other-- yeah. - I was going to say, there's like a trade-off in terms of time here, where if you only ever had to look at something once, you just manually type out response dot messages zero dot block whatever dot choices dot text, right?
You type all that up. You have to do it a million times. It's very nice to have these conveniences. - Yeah. Also, for the docs, right? Like, every time I want to show what the response is, this is now free. I think that's nice. Yeah. So I don't-- yeah.
So I actually-- what I'm describing here is not the exact order it happened in in my head. Because, yeah, it wasn't until I did this a couple of times and was trying to find the contents and blah, blah, blah, that I was like, oh, this is annoying me. And I went back, and I added it.
This is probably like 15 minutes later, I went back. And it's like, yeah, I wish that existed. I did know that usage tracking was going to be important, like how much money you're spending depends on input and output tokens. So I decided to make it easy to keep track of that.
So I created a little constructor for usage. I just added a property to the usage class that adds those together. And then I added a representation. This one is used for strings as well. This is part of Python itself. If you add this in-- so now if I say usage, I can see all that information.
So that was nice. And then since we want to be able to track usage, we have to be able to add usage things together. So if you override done to add in Python, it lets you use plus. So that's something else I decided to do. And so at this point, yeah, I felt like all these basic things I'm working with all the time, I should better use them conveniently.
And it only took a few minutes to add those. And then ditto, I noticed a lot of people-- in fact, nearly everybody, including the Anthropic documentation, manually writes these. I mean, again, it doesn't take long. But it doesn't take very long to write this once either. And now if you just-- something as simple as defaulting the role, then it's just a bit shorter.
I can now say makeMessage. And it's just creating that dictionary. OK. So now I can do exactly the same thing. OK. And so then since it always goes user, assistant, user, assistant, user, assistant, I thought, OK, you should be able to just send in a list of strings. And it just figures that out.
So this is just going using i%2 to jump between user and assistant. And makeMessage, I then realized, OK, we should change it slightly. So if it's already a dictionary, we shouldn't change it and stuff like that. But basically, as you can see here, I can now pass in a list of messages a bit more easily.
So my prompt was I'm Jeremy. R is a response. And then I've got another string. So if I pass in something which has a content attribute, then I use that. And so that way, you can see the messages now. I've got I'm Jeremy. And then the assistant contains the response from the assistant.
So it's happy with that as well. It doesn't have to be a string. And so this is how-- and OK, again, from people, if you've watched my LLM Hacker's Guide, you know this. Language models currently have no state. Like when you chat with chatGPT, it looks like it has state.
You can ask follow-up questions. But actually, the entire previous dialogue gets sent each time. So when I say I forgot my name, can you remind me, please? I also have to pass it all of my previous questions and all of its previous answers. And that's how it knows what's happened.
And so then hopefully-- OK, I don't know your name. I referred to you as Jeremy. All right, well, so you do know my name. Thank you. So it turns out my name's Jeremy. OK, so I feel like something as simple as this is already useful for experimenting and playing around.
And for me, I would rather generally use something like a notebook interface for interacting with a model than the kind of default chatGPT thing or Cloud thing. This is where I can save my notebooks. I can go back and experiment. I can do things programmatically. So this was a big kind of thing for me is like, OK, I want to-- I want to make a notebook at least as ergonomic as chatGPT plus all of the additional usability of a notebook.
So these are the little things that I think help. Passing the model each time seems weird because I generally pick the model once per session. So I just created this tiny class to remember what model I'm working with. So that's what this client class does. And the second thing it's going to do is it's going to keep track of my usage.
So maybe the transition that I see happening right now is everything up until this point was like housekeeping of I'm doing exactly the same things as the official API can do, but I'm just making my own convenience functions for that. But then the official API doesn't give you tracking usage over multiple conversations, keeping track of the history and all of that.
So it seems like now we're shifting to like, OK, I can do the same things that the API allows me to do, but now I don't have to type as much. I've got my convenience functions. But now it's like, OK, what else would I like to do? I'd like to start tracking usage-- Yeah, exactly.
--of the persistent model setting. OK. And this is kind of important to me because I don't want to spend all my money unknowingly. So I want it to be really easy. And so what I used to do was to always go back to the OpenAI or whatever web page and check the billing because you can actually blow out things pretty quickly.
So this way, it's just like I just saying like, OK, well, let's just start with a use of 0. And then I just wrote this tiny little private thing here. We'll ignore prefill for now, which just stores what the last result was and adds the usage. So now when I call it a few times, each time I call it, it's just going to remember the usage.
And so again, I was going to ignore stream for a moment. So then I define dunder call. So dunder call is the thing that you basically could create an object, and then you could pretend it's a function. So it's the thing that makes it callable. And so when I call this function, I'll come back to some of the details in a moment.
But the main thing it does is it calls make messages on your messages. And then it calls the messages.create. And then it remembers the result and keeps track of the usage. So basically, the key behavior now is that when I start, it's got zero usage. I do something, and I've now tracked the usage.
And so if I call it again, that 20 should be higher, now 40. So it's still not remembering my chat history or anything. It's just my usage history. So I like to do very little at a time. So you'll see this is like a large function by my standards.
It's like 1, 2, 3, 4, 5, 6, 7, 8 whole lines. I don't want to get much bigger than that because my brain's very small. So I can't keep it all in my head. So that's just a small amount of stuff. So there's a couple of other things we do here.
One is we do something which Anthropic is one of the few companies to officially support, which is called prefill, which is where you can say to Anthropic, OK, this is my question. What's the meaning of life? And you answered with this starting point. You don't say, please answer with this.
It literally has to start its answer with this. That's called prefill. So if I call it, that's my object. With this question, with this prefill, it forces it to start with that answer. So yeah, so basically, when you call this little tracking thing, which takes track of the usage, this is where you also pass in the prefill.
And so if you want some prefill, then as you can see, it just adds it in. And the way it also-- so that's just to the answer because Anthropic doesn't put it in the answer. And the way Anthropic actually implements this is that the messages, it gets appended as an additional assistant message.
So it's the messages plus the prefill. So basically, you pass in an assistant message at the end. And then the assistant's like, oh, that's what I started my answer with. This isn't documented necessarily in their API because it's like, oh, this is how you send a user message and we'll respond with an assistant message.
And you have to kind of dig a little bit more to say, oh, if I send you an assistant message as the last message in the conversation, this is how we'll interpret it. We'll continue on in that message and like-- Yeah, they've got it here. So they've got-- Anthropic's good with this.
They actually understand that prefill is incredibly powerful. Particularly, Claude loves it. Claude does not listen to system prompts much at all. And this is why each different model, you have to learn about its quirks. So Claude ignores system prompts. But if you tell it, oh, this is how you answered the last three questions, it just jumps into that role now.
It's like, oh, this is how I behave. And it'll keep doing that. And you can maintain character consistency. So I use this a lot. And here's a good example. Start your assistant with OpenCurlyBrace. I mean, they support tool calling or whatever. But this is a simple way. So sometimes I will start my response with backtick, backtick, backtick Python.
That forces it to start answering the Python code. So yeah, lots of useful things you can do with prefill. Have you noticed personally that the improvement is significant when you use prefill? I mean, I see they're recommending it. But I'm just curious what your anecdotal impression is. I mean, it answers it with that start.
So yeah, if you want it to answer with that start, then it's perfect. Unfortunately, GPT-4.0 doesn't generally do it properly. Google's Gemini Pro does. And Google's Gemini Flash doesn't. So they're a bit all over the place at the moment. So then, yeah, the other thing you can do is streaming.
Now, streaming is a bit hard to see with a short question. So we'll make a longer one. And so you can see it generally comes out, bop, bop, bop, bop, bop. I don't have any pre-written funny-- that's terrible. Oh, you know why? Because we're using Haiku. And Haiku is not at all creative.
So if we go c.model equals model 0, we can upscale to Opus. Try again. All right. Slow enough. I don't think I want to wait to do the whole thing anyway. Oh. It's just going to keep going, isn't it? Stop. All right. OK. Let's go back to this one.
Yeah. So streaming, it's one of these things I get a bit confused about. It's as simple as calling messages.stream instead of messages.create. But the thing you get back is an iterator, which you have to yield. And then once it's finished doing that, it stores the final message in here.
And that's also got the usage in it. So anyway, this is some little things which, without the framework, would be annoying. So with this little tiny framework, it's automatic. And you see this in the notebook in its final form, right? But this call method was first written without any streaming.
Like, get it working on the regular case first. No prefill first. So then it's three lines. And then it's OK. The original version is that. Yeah. Yeah. And then we can test the stream function by itself and test it out with the smaller primitives first and then put it into a function that then finally gets integrated in.
Yeah. Exactly. And this is like one of these little weird complexities of Python is-- John was asking me yesterday. It's like, oh, we could just refactor this and move this into here. And then we don't need a whole separate method. But actually, we can't. As soon as there's a yield anywhere in a function, the function is no longer a function.
And it's now a coroutine. And it behaves differently. So this is kind of a weird thing where you have to pull your yields out into separate methods. Yeah, it's a minor digression. So yeah, you can see it's nice that it's now tracking our usage across all these things. And we can add the two together, prefill and streaming.
OK. Yeah, any questions or comments so far? Mm-hmm. Yeah. And is there a way to try to reset the counter if you wanted just to be able to start over at some point? I mean, the way I would do it was I would just create a new client, C equals client.
OK. But you could certainly go C.use equals usage 0, 0. In fact, 0, 0 is the default. So actually, now I think about it, we could slightly improve our code to remove three characters, which would be a big benefit because we don't like characters. We could get rid of those.
Well, there you go. So yeah, you could just say C.use equals usage. And in general, I think people don't do this manipulating the attributes of objects directly enough. Why not? You don't have to do everything through-- people would often create some kind of set usage method or something. No, don't do that.
Paranoid Java style that-- Exactly. --emerged like a decade ago for some reason. Oh, more stuff. Speaking of-- Yeah, oh, yeah? Yeah, it was longer. Speaking of directly manipulating properties of objects, so you showed how we can use prefill to predefine the beginning of the assistance response. If I've had a multi-turn exchange with an assistant, can I just go in there and clobber one of the earlier assistant messages to convince the assistant that it said something it didn't?
Because sometimes that's actually useful. Yeah, because we don't have any state in our class, right? OK. So we're passing in-- so here, we're passing in a single string, right? But we could absolutely pass in a list. So I said hi, and the model said hi to you too. OK.
I am Plato. I am Socrates. OK. Tell me about yourself. I don't know what will happen here, but we're just convincing it that this is a conversation that it's occurred. So now Claude is probably going to be slightly confused by the fact that it reported itself not to be Claude.
No, I mean, I don't-- we haven't set a system message to say it's Claude. So there you go. No, not at all confused. I am Socrates. So as I said, Claude's very happy to be told what it said, and it will go along with it. I'm very fond of Claude.
Claude has good vibes. Oh, you may be surprised to hear that I am actually Australian. This is the point of the video where we get sidetracked and talk to Rupes for a good long time. Oh, not very interesting. What do you say, mate? Fair enough. OK. So yeah, you can tell it anything you like, is the conversation, because it's got no state.
Now it's forgotten everything it's just said. The only thing it remembers is its use. So that's what we've done so far. So remembering-- oh, actually, so before we do that, we'll talk about tool use. So yeah, basically, I wanted to, before we got into multi-turn dialogue automatic stuff, I wanted to have the basic behavior that Anthropic's SDK provides.
I wanted to have it conveniently wrapped. So tool use is officially still in beta, but I'm sure it won't be for long. Can I ask one more pre-tool use case that I think occurs to me right away? And so maybe it'll occur to other people if they're curious. One thing you often find yourself doing when you're experimenting with prompts is going through a lot of variations of the same thing.
So you have your template, and then you want very different parts of it. And before you write code to churn out variations, you're usually doing it a bit ad hoc. So using this API the way it is now, if I had a client and a bit of an exchange already built up, and then I wanted to fork that and create five of them and then continue them in five different ways, can I just duplicate-- would the right way to do that would be to duplicate the client?
Would the right way to do that just to be to extract the list that represents the exchange and create new clients? I'm just getting a sense for what would be the fluid way of doing it with this API? Let's do it. OK. OK. OK. Options equals-- how do you spell Zimbabwean, Johnno?
Zimbab-- Yep. E-W-E, yep. Print contents-- oh, you know what? This is boring again, because I think we've gone back to our old model. C.model equals models 0. No wonder it's got so dull. Haiku is just really doesn't like pretending. Oh, come on. Look what it's doing. All right, anyway, Claude is being a total disappointment.
So the fact that it's reasonable to do this just by slamming a new list into the C function is an indication of what you just said, which is that there's no state hiding inside the C function that we need to worry about mangling when we do that. That's right.
There's no state at all. Got it. So when we recall it, it knows nothing about being Socrates whatsoever. Everyone is a totally independent REST call to a-- there's no session ID. There's no nothing to tie these things together. All right, we probably just spent cents on that question. It's so funny, they're like a few dollars per million tokens or something.
I look at this and like, whoa, all those tokens. I'm like, oh, yeah, it's probably like $0.01 or something less. I've got to get used to not being too scared. OK, so tool use refers to things like this, get the weather in the given location. So there's a tool called getWeather.
And then how would it work? I don't know. It would call some other weather API or something. So both in OpenAI and in Lord, tools are specified using this particular format, which is called JSON schema. And my goal is that you should never have to think about that. For some reason, nearly everything you see in all of their documentation writes this all out manually, which I think is pretty horrible.
So instead, we're going to create a very complicated tool. It's something that adds two things together. And so I think the right way to create a tool is to just create a Python function. So the thing about these tools, as you see from their example, is they really care a lot about descriptions of the tool, descriptions of each parameter.
And they say quite a lot in their documentation about how important all these details are to provide. So luckily, I wrote a thing a couple of years ago called Documents that makes it really easy to add information to your functions. And it basically uses built-in Python stuff. So the names of each parameter is just the name of the parameter.
The type of the parameter is the type. The default of the parameter is the default. And the description of the parameter is the comment that you put after it. Or if you want more room, you can put the comment before it. Documents is happy with either. And you can also put a description of the result.
You can also put a description of the function. And so if you do all those things, then you can see here. I said tools equals getSchema. So this is the thing that creates the JSON schema. So if I say tools, there you go. You can see it's created the JSON schema from that, including the comments have all appeared.
And the return comment ends up in this returns. Yeah. And if you didn't do any of that, like if you just wrote a function sums that took two untyped variables A and B, you would still get something functional. The model would probably still be able to use it. But it just wouldn't be recommended.
Is that right? I think-- well, I mean, my understanding is you have to pass in a JSON schema. So if you don't pass in a JSON schema, so you would have to somehow create that JSON schema. I don't know if it's got some default thing that auto-generates one for you.
Oh, I'm more thinking like if we don't follow the documents format, for example. Oh, yeah. So if we got rid of these, so if we got rid of the documents, yep, you could get rid of the doc string. You could get rid of the types and the defaults. You could do that, in which case the-- OK, so it does at least need types.
So let's add types. Ah, well, that's a bit of a bug in my-- You need to annotate it. Huh? No, yeah. It appears like you have to annotate it there. Well, I'll fix that. It shouldn't be necessary. Description. Oh, OK. It at least wants a doc string. OK, so currently, that's the minimum that it needs.
And I don't know if it actually requires a description. I suspect it probably does, because otherwise, maybe I guess it could guess what it's for from the name. But yeah, it wouldn't be particularly useful. So OK, so now that we've got a tool, when we call Claude, we can tell it what tools there are.
And now we're also going to add a system prompt. And I'm just going to use that system prompt. You don't have to, right? If you don't say you have to use it, then sometimes it'll try to add it itself, but it's not very good at adding. So I would like to-- I also think user-facing, I think it's weird the way Claude tends to say, OK, I will use the sum tool to calculate that sum.
It loves doing that. OpenAI doesn't. I think this is because Anthropic's a bit-- like, they haven't got as much user-facing stuff. They don't have any user-facing tool use yet. So yeah, I don't think their tool use is quite as nicely described. So if we pass in this prompt, what is that plus that?
We get back this. So we don't get back an answer. Instead, we get back a tool use message. The tool use says what tool to use and what parameters to pass it. So I then just wrote this little thing that you pass in your tool use block. So that's this thing.
And it grabs the name of the function to call. And it grabs that function from your symbol table. And it calls that function with the input that was requested. So when I said the symbol table or the namespace, basically, this is just a dictionary from the name of the tool to the definition of the tool.
So if you don't pass one, it uses globals, which, in other words, is every Python function you currently have available. You probably don't want to do that if it's like os.unlink or something. So this little make namespace thing is just something that you just pass in a bunch of functions to.
And it just creates a mapping from the name to the function. So that way, this way, I'm just-- yeah. I'm just going to say, if I'm a somewhat beginner, I'm approaching LLMs. I've seen your Hacker's Guide. This screen full of code is quite a lot of fairly deep Python stuff.
We've got some typing going on. And I might not know what mappings are or callables. There's namespaces and get_atras and dicts and is_instance. How should I approach this code versus maybe the examples that are being interleaved? Because this is the source code of this library. But you're not writing this with lots of comments or explanations.
It's more like the usage. So what should I-- like, if I come to this library and I'm reading the source code, how much should I be focusing on the deep Python internals versus the usage versus like the big picture? That's a good question. So for someone who doesn't particularly want to learn new Python things but just wants to use this library, this probably isn't the video for you.
Instead, just read the docs. And none of that-- like, you can see in the docs, there's nothing weird, right? The docs just use it. And you don't need this video. It's really easy to use. So yeah, the purpose of this discussion is for people who want to go deeper.
And yeah, the fact that I'm skipping over these details isn't because either they're easy or that everybody should understand them or any of that. It's just that they're all things that Google or ChatGPT or whatever will perfectly happily teach you about. So these are all things that are built into Python.
But yeah, that'd probably be part of something called Python Advanced Course or something. So one of the things a lot of intermediate Python programmers tell me is that they like reading my code to learn about bits of Python they didn't know about. And then they use it as jumping off points to study.
And that's also why, like, OK, why do I not have many comments? So my view is that comments should describe why you're doing something, not what you're doing. So for something that you could answer, like, oh, what does isInstanceABC.mapping do? You don't need a comment to tell you that.
You can just Google it. And so in this case, all of the things I'm doing, once you know what the code does, why is it doing it is actually obvious. Like, why do we get the name of the function from the object? Or why do we pass the input to the function?
I mean, that's literally what functions are. They're things you call them, and you pass in the input. Yeah. So I think that's a good question. Let's say, like, yeah, don't be-- you actually don't need to know any of these details. But if you want to learn about them, yeah, the reason I'm using these features of the language is because I think they're useful features of the language.
And if I haven't got a comment on them, it's because I'm using them in a really normal, idiomatic way that isn't worthy of a comment. So that means if you learn about how to use this thing for this reason, that's a perfectly useful thing to learn about. And you can experiment with it.
And I'll add that, like, I'm learning this stuff as we code together on this as well, right? Like, you don't have to know any of this to be a good programmer, but it's really fun as well. And I think, like, some of these things we wrote multiple ways, maybe one that was more verbose first, and then we say, oh, I think we can do this in this more clever way if we condense it down.
So if you are watching this and you are wanting to learn and you're still like, oh, I still don't know what some of these things are, I can't remember what the double-- like, yeah, dig in and find out. But it's also, like, it's totally OK if you're not, like, comfortable at this.
Yeah, the other thing I would say is the way I write all of my code, pretty much, is I don't write it in a function. I write nearly all of it outside of a function in cells. So you can do the same thing, right? So, like, let's set ns to none, so then I can run this.
It's like, oh, what the hell is globals? It's like, oh, wow, everything in Python is a dictionary. Now, this is a really powerful thing, which is well worth knowing about. If I could offer just-- yeah, sorry. But just offer one perspective to maybe make a little bridge from the kind of user point of view to the why these internals might be unfamiliar point of view, just to recap and make sure I understand it right.
From the user point of view here, when we use tools, we get a response back from a plod, in the way we're doing it now, that describes a function that we now want to execute. Correct? That's the function to execute, and that's the input to provide to it. So with this library, I can write a function in Python and then tell clod to call the function that's sitting there on my system, right?
Yeah, if it wants to. For that to work, if it wants to, if it chooses to. But for that to work, this library needs to do the magic of reading a text string that is clod's response, and then in Python, having that not be a text string, but having that become Python code that runs in Python.
And that's a somewhat unfamiliar thing to do in Python. And that's what's called eval in JavaScript, or back in Lisp, where a lot of this stuff got started. And because that's not that sort of-- Well, it's actually not. We're not actually doing an eval, right? OK, that's interesting. Yeah, we're definitely not doing eval.
So in the end, this is the function we want to call. So I can call that, and there's the answer. In Python, this is just syntax sugar, basically, for passing in a dictionary and dereferencing it. So those are the same. Those are literally the same thing, as far as Python is concerned.
So we were never passed a string of code to eval or execute. We were just told, call this tool and pass in these inputs. So to find the tool by string, we look it up in the symbol table. So let's just change fc.name to fc_name. And the name it's giving us is the one that we provided earlier.
Yeah, it's the name that came from our schema, which is this name. Yeah, so if you look back at our tool schema, this tool has a name. And you can give it lots of tools. So later on, we might see one where we've got both sums and multiply. And it can pick.
We'll see this later, can pick and choose. So the flow is, we write our function in Python. The library automatically knows how to interpret the Python and turn it into a structured representation, the JSON schema, that is then fed to Cloud. It's fed to Cloud. We're also feeding it the name for the function that it's going to use when it wants to come back to us and say, hey, now call the function.
When it comes back to us and says, hey, call the function, it uses that name. We look up the original function, and then we execute. Yeah, and so it decides. It knows it's got a function that can do this and that it can return this. And so then if it gets a request that can use that tool, then it will decide of its own accord, OK, I'm going to call the function that Jeremy provided, the tool that Jeremy provided.
Yeah, so we'll see a bunch of examples of this. And this is generally part of what's called the React framework, nothing to do with React, the JavaScript GUI thing, but React was a paper that basically said like, hey, you can have language models or tools. And again, my LLM Hackers video is the best place to go to learn about the React pattern.
And so here we're implementing the React pattern, or at least we're implementing the things necessary for Cloud to implement the React pattern using what it calls tool calling. So we look up the function, which is a string into this dictionary, and we get back the function. And so we can now call the function.
So that's what we're doing. And so I think the key thing here is this idea that all this is in a notebook. The source code here to this whole thing is in a notebook, which means you can play with it, which I think is fantastically powerful because you never have to guess what something does.
You literally can copy and paste it into a cell and experiment. And it's also worth learning these keyboard shortcuts like CV to copy and paste the cell, and like Apple A, Apple left square bracket, control shift hyphen. There's all these nice things worth learning, all these keyboard shortcuts to be able to use this Jupyter tool quickly.
Anyway, the main thing to know is we've now got this thing called call function, which can take the tool use request from Cloud, this function call request, and call it. And it passes back a dictionary with the result of the tool call, and when it asked us to make this call, it included an ID.
So we have to pass back the same ID to say this is the answer to this question. And that's the bit that says this is the answer to this question. That's the answer. And so we can now pass that back to Cloud, and Cloud will say, oh, great, I got the answer, and then it will respond with text.
So I put all that together here and make a tool response where you pass in the tool response request from Cloud, the namespace to search for tools, or an object to search for tools, and we create the message from Cloud. We call that call function for every tool use request.
There can be more than one, and we add that to their response. And so if you have a look now here, when we call that, it calculates the sum, and it's going to pass back the-- going to add in the tool use request and the response to that request.
So we can now go ahead and do that, and you can see Cloud returns the string, the response. So it's turned the result of the tool request into a response. And so this is how stuff like Code Interpreter in ChatGPT works. So it might be easier to see it all in one place, and this is like another demo of how we can use it.
Instead of calling functions, we can also call methods. So here's sums again. But this time it's a method of a class. So we can do the same thing, get schema dummy dot sums. Yeah, so we make the message containing our prompt. So that's the question, what's this plus this?
We pass that along to Cloud. Cloud decides that it wants you to create a tool request. We make the tool request, calculate the answer, add that to the messages, and put it all together. Oops, crazy. And there we go. OK, anything worth adding to that? So if you're not comfortable and familiar with the React framework, this will feel pretty weird.
Definitely worth spending time learning about, because it's an incredibly powerful technique and opens up a lot of opportunities to-- because I think a lot of people, I certainly feel this way, that there's so many things that language models aren't very good at. But they're very good at recognizing when it needs to use some tool.
If you tell it like, oh, you've got access to this proof checking tool, or you've got access to this account creation tool, or whatever, it's good at using those. And those tools could be things like reroute this code or a customer service representative. They don't have to be text generating tools.
They can be anything. And there's also no reason-- you're not under obligation to send the response back to the model, right? It can actually be a useful endpoint. It's like, oh, I tell the model to look at this query from a customer and then respond appropriately. And one of the tools is like escalate.
Well, if it sends a tool response, a tool request for that function, that could be like, oh, I should exit this block, forget about it, throw away the history because now I need to bump this up to some actual human in the loop, or store the result somewhere. It's just a very convenient way to get-- Yeah, we're going to see a bunch more examples in the next section because there's a whole module called tool loop, which has a really nice example, actually, that came from the Anthropic examples of how to use this for customer service interaction.
But for now, yeah, you can put that aside. Don't worry about it because we're going to go on to something much more familiar to everybody, which is chat. So chat is just a class which is going to keep track of the history. So self.h is the history. And it's going to start out as an empty list.
There's no history. And it's also going to contain the client, which is the thing we just made. And so if you ask the chat for its use, it'll just pass it along to the client to get its use. You can give it some tools. And you can give it a system prompt.
OK, so the system prompt, pass it in, no tools, no usage, no history. Again, there's a stream version and a non-stream version. So you can pass in stream as true or false. If you pass in stream, it'll use the stream version. Otherwise, it won't. So again, we patch in, done to call.
Now, of course, we don't need to use patch. We could have put these methods directly in inside here. But I feel like I really prefer to do things much more interactively and step by step. So this way, I can create my class. And then I can just gradually add a little bit to it at a time as I need it.
And I can also document it a little bit as the time, rather than having a big wall of code, which is just, I find, overwhelming. So all right, so there's a prompt. So if you pass in the prompt, then we add that to the history as a message. Now, get our tools.
So I just call get schema for you automatically. And then at the end, we'll add to the history the results, which may include tool use. So now I can just call chat. And then I can call chat again. And as you can see, it's now got state. It knows my name.
And the reason why is because each time it calls the client, it's passing in the entire history. So again, we can also add pre-fill, just like before. We can add streaming, just like before. And that's it, right? So you can see adding chat required almost no code. Really, it's just a case of adding everything to the history, and every time you call the client, passing in the whole history.
So that's all a stateful-seeming language model is. So I don't actually have to write anything to get tool use to work, which is nice. I can just pass in my tools. And the nice thing, the kind of interesting thing here is that because the tool use request and response are both added to the history, to do the next step, I don't pass in anything at all.
That's already in the history. So I just run it, and it goes ahead and tells me the answer. OK. Anything to say about that? So I know in chat GPT, it sometimes is, would you like to go ahead with this tool activation? And here, the model is responding with the tool use block, like it would like to use this tool.
Do you have a way of interrupting before it actually runs the code that you gave it? Maybe you want to check the inputs or something like that? So you would need to put that into your function. So I've certainly done that before. So one of the things-- in fact, we'll see it shortly.
I've got a code interpreter. And you don't want to run arbitrary code, so it asks you if you want to complete it. And part of the definition of the tool will be, what is the response that you get, Claude, if the user's declined your request to run the tool?
Cool. OK. So I think people might imagine-- Good question. Yeah. So I had my earlier question before we introduced chat, where we forked a conversation, as it were, just by forcing stuff into earlier exchanges. And at that point, we were talking about how the interface was stateless, because there were no session IDs.
Now that we have these tool interactions with tool IDs, does that change the story? Like, let's say I had a sequence of interactions that involved tool use, and now I want to create three variations to explore different ways I might respond. Is that problematic? No, not at all. I mean, let's do it.
So actually-- OK, let's try it. Actually, I'm not Jeremy. I'm actually Alexis. You might want to zero index there. Thanks. So at this point, it's now going to be very confused, because I'm Alexis. It's nice to meet you, Jeremy. What's my name? Your name is Jeremy. So yeah, let's try.
Poor thing. Lord, really? Does that answer your question, Alexis, if that is your real name? This is abuse of Claude. One day, this will be illegal. Yeah. And so I also had a question, too. Yes. And if Claude returns a tool block, and is that added as a tool block to the history?
Yes. Does it have to be converted to a string? No, no, no. It's just the tool block as part of the history. The history is perfectly-- the messages can be those message objects. They don't have to be dictionaries. The contents don't have to be strings. OK. OK, cool. Yeah.
All right. So I was delighted to discover how straightforward images are to deal with. So yeah, I mean, we can read in our image, and it's just a bunch of bytes. And Anthropx documentation describes how they expect images to come in. Here we are. So yeah, basically, this is just something which takes in the bytes of an image and creates the message that they expect, which is type image.
And the source is a dictionary containing base64, a MIME type, and the data. Anyway, you don't have to worry about any of that because it does it all for you. And so if we have a look at that, that's what it looks like. And so because you could-- and so they're kind of quite like this.
You can have multiple images and multiple pieces of text in a request. They can be interleaved, whatever. So to do that, it means you can't just pass in strings. You have to pass in little dictionaries type text in the string. So here we can say, all right, let's create-- this is a single message containing multiple parts.
So maybe these functions should be called image part and text part. I don't know. But they're not. A single message contains an image and this prompt. And so then we pass that in. And you see I'm passing in a list because it's a list of messages. And the first message contains a list of parts.
And yep, it does contain purple flowers. And then it's like, OK, well, there's no particular reason to have to manually do these things. We can perfectly well just look and see, oh, it's a string. We should make it a text message, or it's bytes. We should make it an image message.
So I just have a little private helper. And then finally, I've changed makeMessage. This is something I remember Jono and I talked about. Jono was saying-- I think you said you feel like this is kind of like part of the Jeremy way of coding is I don't go back and refactor things, but I just redefine them later in my notebook.
And so I previously hadn't exported makeMessage. I don't export it till now. And so here's my final version that's now going to actually call makeContent to automatically handle images as well. And so now we can just pass in-- we can call our client. We can pass in a list of one message.
The list of one message contains a list of parts, as you can see. So behind the scenes, when we then run the last cell, it actually generates a Python file containing all of the exports code. So it's 229 lines, which isn't much, particularly when you look at how much empty space there is.
And these all things say which cell it comes from and so forth. So in terms of actual code, it'll be well under 200 lines of code. OK, so that is the first of two modules to look at. Any thoughts or questions before we move on to the tool loop?
I think it's coming through. Maybe do you want to go into your objective when you started this, if it was beyond what you've already shown, like what was the goal always to keep this a simple self-contained thing? Is there plans for this to grow into a fully stateful chat thing that can offer up different functionality?
What's the journey of, oh, I should write this thing that's going into this? I mean, I imagine I must be a very frustrating person to work with because I'd never have any plans, really. I just have this vague, intuitive feeling that maybe I should do something in this general direction.
And then people ask me, like, oh, why are you doing that? So it's like, I don't know. Just seems like, why not? Seems like a good idea. So yeah, I don't think I had any particular plans to where it would end up. Just a sense of like-- the way I saw things being written, including in the Anthropic documentation for Claude, seemed unfairly difficult.
I didn't think people should have to write stuff like that. And then when I started to write my own thing using the Anthropic client, I didn't find it very ergonomic and nice. I looked at some of the things that are out there, kind of general LLM toolkits, APIs, libraries.
And on the whole, I found them really complicated, too long, too many new abstractions, not really taking advantage of my existing Python knowledge. So I guess that was my high-level hope. Simon Willison has a nice library called LLM, which Jono and I started looking at together. But it was missing a lot of the features that we wanted.
And we did end up adding one as a PR. Not that it's been merged yet. But yeah, in the end, I guess the other thing about-- so the interesting thing about Simon's approach with LLM is it's a general front end to dozens of different LLM backends, open source, and proprietary, and inference services.
And as a result, he kind of has to have this lowest common denominator API of like, oh, they all support this. So that's kind of all we support. So this was a bit of an experiment in being like, OK, I'm going to make this as Claude-friendly as possible. Which is why I even gave it a name based on Claude.
Because I was like, I want this to be-- you know, that's why I said this is Claude's friend. I wanted to make it like something that worked really well with Claude. And I didn't know ahead of time whether that would turn out to be something I could then use elsewhere with slight differences or not.
So that was kind of the goal. So where it's got to-- I think what's happened in the few weeks since I started writing it is there's been a continuing standardization. Like, the platforms are getting-- which is nice, more and more similar. So the plan now, I think, is that there will be GPT's friend and Gemini's friend as well.
GPT's friend is nearly done, actually. Maybe they'll have an entirely consistent API. We'll see, you know, or not. But again, I'm kind of writing each of them to be as good as possible to work with that LLM. And then I'll worry about like, OK, is it possible to make them compatible with each other later?
And I think that's something-- I mean, I'd be interested to hear your thoughts, Jono. But like, when we wrote the GPT version together, and we literally just duplicated the original Baudet notebook, started at the top cell, and just changed the-- and did a search and replace of Anthropic with OpenAI, and of Claude with GPT, and then just went through each cell one at a time to see how do you port that to the OpenAI API.
And I found that it took us, what, a couple of hours? It felt like a very-- It was very quick, yeah. Simple. Didn't have to use my brain much. Yeah. I mean, that's maybe worth highlighting, is that this is not the full and only output of the AnswerAI organization over the last month.
This is like, oh, you saw things Jeremy is tinkering with just on the side. So maybe, yeah, it's good to set expectations appropriately. But also, yeah, it didn't really feel like it was pretty easy, especially because I think they've all been inspired by, is the generous way of saying it, each other.
And OpenAI, I think, maybe led the way with some of the API stuff. So yeah, it's chat.completions.create versus anthropic.client.messages.create or something. In a standard IDE environment, I think I would have found it a lot harder. You know, because it's so sequential, in some ways, it could feel like a bit of a constraint.
But it doesn't mean you can do it from the top and you go all the way through until you get to the bottom. You don't have to jump around the place. Right. And the only part that was even mildly tricky then ended up being a change that we made for the OpenAI one, which instantly got mirrored back to Claude.
And then, again, because they were built in the same way, it was like, oh, we've tweaked the way we do. I think it was streaming. One of the things that-- yeah. Like, OK, we've figured out a nice way to do that in the second rewrite. It was very easy to just go and find the equivalent function, because the two are so close together.
Yeah, so I also-- it's quite a nice way to write software, especially for this kind of like-- it's not going to grow too much in scope beyond what is one or two notebooks of stuff. I don't think it's not-- If it did, I would add another project or another notebook.
Like, I wouldn't change these. These are kind of like the bases which we can build on. Yeah. Yeah. OK, let's keep going then. So there's just one more notebook. And this, hopefully, will be a useful review of React framework. So yeah, Anthropic has this nice example in their documentation of a customer service agent.
And again, there's a lot of this boilerplate. And then it's all a second time, because it's now the functions. And so basically, the idea is here, there's like a little pretend bunch of customers and a pretend bunch of orders. And I made this a bit more-- a little bit more sophisticated.
These customers don't have orders. The orders are not connected to customers. In my version, I have the orders separately. And then each customer has a number of orders. So it's a kind of a relational, but it's more like MongoDB style or whatever, denormalized. Not a relational database. Yeah, so they basically describe this rather long, complex process.
And as you can see, they do absolutely everything manually, which maybe that's fine if you're really trying to show people the very low level details. But I thought it'd be fun to do exactly the same thing, but make it super simple. And also make it more sophisticated by adding some really important features that they never implemented.
So the first feature they implement is getCustomerInfo. You pass in a customer ID, which is a string, and you get back the details. So that's what it is, customers.get. And so you'll see here we've got the documents, we've got the doc string, and we've got the type. So everything necessary to get a schema.
Same thing for order details, orders.get. And then something that they didn't quite implement is a proper cancel order. So if order ID not in orders, so you can see we're returning a bool. So if the order ID is not there, we were not able to cancel it. If it is there, then we'll set the status to cancel and return true.
OK, so this is interesting now. We've got more than one tool. And the only reason that Claude can possibly know what tool to use when, if any, is from their descriptions in the doc string here. So if we now go chat.tools, because we passed it in, you can see all the functions are there.
And so when it calls them, it's going to, behind the scenes, automatically call getSchema on each one. But to see what that looks like, we could just do it here. And so getSchema is actually defined in a different library, which we created called tools.lm. OK, getSchema, oops, O for O in chat.tools, there you go.
So you basically end up with something pretty similar to what Anthropx version had manually. So yeah, we can say, tell me the email address of customer C1. And I mean, Claude doesn't know. So it says, oh, you need to do a tool use. You need to call this function.
You need to pass in this input. And so remember, with our thing, that's already now already got added to the history. So we just call chat. And it automatically calls it on our history. And there it is. And you can see this retrieving customer C1 is because we added a print here.
So you can see, as soon as we got that request, we went ahead and retrieved C1. And so then we call chat. It just passes it back. And there we go. There's our answer. So can I channel my inner-- our dear friend Hamel has a thing about saying, you've got to show me the prompt.
I already want to be able to inspect what's going on. Maybe we could do this at a couple of different levels. But can we see what was fed to the model? What was the history? Or what was the most recent request? Something like that. Yeah, so there's our-- here's our history.
So the first message we passed in was, tell me the email address. It passed back an assistant message, which was a tool use block asking for calling this function with these parameters. And then we passed back-- and that had a particular ID. We passed back saying, oh, that tool ID request, we've answered it for you.
And this was the response we got. And then it told us-- OK, there's-- it's just telling us what we told it. Right. And then if I was really paranoid, like I wanted to see the actual tool definitions and things, and the actual requests, is there a way to dig to that deeper level beyond just looking at the history?
Yeah, so we can do this. It's a bit of fun. So that has to be done before you import Anthropic. So we'll set it to debug. And so now if we call that, OK, it tells us everything that's going on. And so here is the request method post URL, headers, JSON data, HTTP request.
Nice. Yeah. So if we do that here. So now this is including all of that same information again, because the model on Anthropic's side is not stateful. So we pass the full history. We can see, OK, we've still got all of the tools, the definitions in there. We've still got all the previous messages.
Yeah, so this is like, it's a bit of a pain to have all this output all of the time. But if you're playing around with this, I'd recommend turning this on until you can trust that the library does what you want. And it's nice to be able to have-- Thank you, Anthropic, for having that environment variable.
It's very nice. Yeah, because in the end, if you're stuck on something, then all that's happening is that those pieces of text are being passed over an HTTP connection and passed back again. So there is nothing else. So that's a full debug. Thanks. That's a good question, Jono. So yeah, this is an interesting request.
Please cancel all orders for customer C1. So this is interesting, because it can't be done in one go. So the answer it gave us was, OK, tell me about customer C1. But that doesn't finish it. So what actually happens? Well, I mean, we could actually show that. So if we pass it back, then it says, OK, there are two orders.
Let's cancel each one. And it has a tool use request. So it's passed back some text and a tool use request to cancel order A1. It's not being that smart. And I think it's because we're using Haiku. If we are using Opus, it probably would have had both tool use requests in one go.
Well, let's find out. So if we change this model to model 0-- Definitely slower. Definitely slower. Yeah. Oh, you can see here. So this is something interesting that it does. It has these thinking blocks. That's something that Opus, in particular, does. So then-- no, OK, it's still only doing one at a time.
So it's fine. Does it only use those thinking blocks or does it need to use tool use? I haven't seen them before when I do API access. Yes. OK, that's why I haven't seen them. As far as I know. OK, so basically, you can see we're going to have to-- given that it's only doing one at a time, it's going to take at least three goes-- one to get the information about the customer, then to cancel order A1, and then to cancel order A2.
But each time that we get back another tool use request, we should just do it automatically. There's no need to manually do this. So we've added a thing here called tool loop. And for up to 10 steps, it'll check whether it's asked for more tool use. And if so, it just calls self again.
That's it. Just like we just called-- because self is chat, right? Just keeps doing it again and again. Optionally, I added a function that you could just call, for example, trace func equals print. It'll just print out the request each time. And I also added a thing called continuation func, which is whether you want to continue.
So if these are both empty, then nothing happens. It's just doing that again and again and again. So super simple function. So now, if we say, can you tell me the email address for customer C1, we never have to-- we never have to do that. Just does it for us until it's finished.
And it says, sure, there you go. It's like, OK, please cancel all orders for customer C1. Retrieving, canceling. Now, why did it only do O2? Oh, I think we already canceled O1. Let's do that again. There we go. So we are agentic, are we not? Yes, definitely. Yeah, so when people say I've made an agent, it's like, oh, congratulations.
You have a for loop that calls the thing 10 times. It's not very fancy, but it's nice. It's such a simple thing. And so now we can ask it, like, OK, how do we go with O2 again? And remember, it's got the whole history, right? So it now can say, like, oh, yeah, you told me to cancel it.
It is canceled. Cool, cool. So something I never tried is-- great, now cancel order O6. I think it should get back false, and it should know. Yeah, there we go. Not successful, that's good. Nice. So here's a fun example. Let's implement Code Interpreter, just like ChatGPT, because Claude doesn't have the Code Interpreter.
So now it does. So I created this little library called ToolsLM. So we've already used one thing from it, which is GetSchema, which is this little thing here. And it's actually got a little example of a Python Code Interpreter there. Yeah, it's also got this little thing called Shell.
So yeah, we're going to use that. So GetShell is just a little Python Interpreter. So we're going to create a subclass of chat called CodeChat. And CodeChat is going to have one extra method in it, which is to run code. So code to execute in a persistent session. So this is important to tell it all this stuff, like it's a persistent IPython session.
And the result of the expression on the last line is what we get back. If the user declines request to execute, then it's declined. And so you can see here, I have this little confirmation message. So I call input with that message. And if they say no thank you, then I return declined.
And I try to encourage it to actually do complex calculations yourself. And I have a list of imports that I do automatically. So that's part of the system prompt. You've already got these imports done. And just a little reminder, Haiku is not so smart. So I tend to be a little bit more verbose about reminding it about things.
And I wanted to see if it could combine the Python tool with other tools. So I created a simple little thing here called getUser. It just returns my name. So if I do CodeChat-- so I'm going to use Sonnet, which is less stupid than Haiku. So in trying to figure out how to get Haiku to work-- in fact, let's use Haiku.
One thing that I found really helped a lot was to give it more examples of how things ought to work. So I actually just set the history here. So I said, oh, I asked you to do this. So I asked you to do this. And then you gave me this answer.
And then I asked you to do this. And you gave me this answer. So these aren't the actual messages that would include the actual tool calling syntax or anything? That doesn't cause trouble-- No, I didn't bother with that. --in plain text? Yeah. It seems to be enough for it to know what I'm talking about.
Yeah. If you wanted that full thing, I guess you could have this conversation with it, install the history or something like that. Well, I'm going to add it. So for the OpenAI one, I just added today, actually, something called mockToolUse, which is a function you can call because GPT does care.
So we might add the same thing here, mockToolUse. And you just pass in the-- yeah, here's the function you're pretending to call. Here's the result we're pretending that function had. Yeah. OK, so create a one-line-- no, must have broken it at some point. OK, we'll use Sonnet. Create a one-line function for a string s that multiplies together the ASCII values of each character in s using reduce.
Call tool loop with that. And OK, press Enter to execute or N to skip. So that's just coming from this input with this message. So it's actually, if you enter anything at all, it'll stop. We'll press N. OK, so it responded with a tool use request to run this code.
And because it's in the tool loop, it did run that code. And it also responded with some text. So it's responded with both text as well as a tool use request. And this doesn't return anything. The print doesn't return anything. So all that's happened is that behind the scenes, we created this interactive Python shell called a self.shell.
Self.shell ran the code it requested. So that shell should now have in it a function called checksum. So in fact, we can have a look at that. There's the shell. And we can even run code in it. So if I just write checksum, that should show it to me.
Result equals function lambda. Checksum, there you go. So you can play around with the interpreter yourself. So you can see it has the interpreter has now got this function defined. And so this is where it gets quite interesting. Use it to get the checksum of the username of this session.
So it knows that one of the tools it's been told exists is getUser. And in this code chat, I automatically added a setTools, append the self.runCell automatically. So it now knows that it can get the user and it can run a cell. Sorry, it can run a cell. So if I now call that, you can see it's called getUser.
Found out the name's Jeremy. Then asked to get the checksum of Jeremy. There it goes. So you can see this is doing a tool use with multiple tools, including our code interpreter, which I think is a pretty powerful concept, actually. And if you wanted to see the actual code it was writing, you could change the trace function, or look at the history, or inspect that in some other way.
Yeah, so we could change the trace function to print, for example. So we've used showContents, which is specifically just trying to find the interesting bit. If we change it to print, it'll show everything. Or yeah, you can do whatever you like in that trace function. You don't really have to show things.
And of course, we could also set the anthropic lobbying debug thing to see all the requests going through. So yeah, none of this needs to be mysterious. Yeah, so at the end of all this, we end up with a pretty convenient wrapper, where the only thing I bother documenting on the home page is chat, because that's what 99.9% of people use.
You just call chat, you just pass in a system prompt, you pass in messages, you can use tools, and you can use images. So for the user, there's not much to know, really. Right. It's only if you want to mess around making your own code interpreter, or trying something that you'd even look a little bit deeper.
Yeah. Yeah. Exactly. I don't know. I mean, I feel like I'm quite excited about this way of writing code as being something like I feel like I can show you guys. Like, all I did just now was walk through the source code of the module. But in the process, hopefully, you might have done it all already, but if you didn't, you learned something about Claude, and the anthropic API, and the React pattern, and blah, blah, blah.
And I remember I asked you, Jono, when I first wrote it, actually, and I said, oh, could you read this notebook and tell me what you think? And you said the next day, OK, I read the notebook. I now feel ready that I could both use and work on the development of this module.
I was like, OK, that's great. Right, yeah. And I think it definitely depends where you're coming from, how comfortable you are at those different stages. I think using it, it's very nice, very approachable. You get the website with the documentation right there. The examples that you use to develop the pieces are always useful examples.
Yeah, reading through the source code definitely felt like, OK, I think I could grasp where I needed to make changes. I had to add something for a different project we were working on. It was, OK, I think I can see the bits that are important for this. Yeah, so it's quite a fun way to build stuff.
I think it's quite approachable. I think the bits that I'd expect people might find a little tricky if they haven't seen this sort of thing before. There's two bits. One is you have some personal metaprogramming practices that aren't part of normal Python. So patching into classes instead of defining in classes, liberal use of delegates, liberal use of double star keyword arg unpacking, stuff like that.
And then the second is the not exactly eval, but eval-ish metaprogramming around interpreting-- I mean, it's using the symbol table as a dictionary. Yeah, yeah. I mean, these are all things that you would have in an advanced Python course. They're beyond loops and conditionals. And I think they're all things that can help people to create stuff that otherwise might be hard to create or might have otherwise required a lot of boilerplate.
So in general, my approach to coding is to not write stuff that the computer should be able to figure out for me. And you can take the same approach, even if you're not quite the Jeremy, where instead of importing from FastCore and from the tools on library that you've written separately, it's like, oh, often I'll have a utils notebook, right?
Which is like, oh, there's things that are completely orthogonal to what I'm actually doing, which is like a tool loop with a chatbot. It's like, oh, I have a thing for getting a list into a different format or a thing for reading files and changing the image type and resizing it to a maximum size.
You can still have the same idea where, like, here's the main notebook. This is me implementing the pieces one by one. Maybe there's somewhere else where, like, oh, there's a few utility functions that are defined and documented in their own separate place so they don't clutter things up. This more general literate notebook-driven small example of atomic piece-driven development doesn't require that you've written the FastCore library, but it's helped along by having those pieces at hand.
Yeah. And also, in general, FastCore, particularly FastCore.basics, is designed to be the things I feel like maybe could have been in Python. I almost never write any script or notebook without importing from that and without using stuff from that because I'm, like, the things that I just think you use all the time.
I'll say, like, it's something I've definitely noticed. There's two reactions I see to people reading my code, which, as you say, it's kind of like it's got a particular flavor to it. And it's very intentionally not the same as everybody else's. Some people get really angry. And they're like, why don't you just do everything the same way as everybody else?
And some people go, like, wow, there's a bunch of things here I haven't seen before. I'm so excited this is an opportunity to learn those things. And so, like, our friend Hamill, in particular, this happens all the time. He's just like, oh, I was just reading your source code to that thing you did, and I learned about this whole thing.
That's really helpful. So I don't mind. People can react in either way. They've been to the stage in the video. They're likely in the second class. Probably. Otherwise, they would have given up long ago. I think also it helps-- What's this star, star, fuck, dot, args? No. If people can relate it to things in other languages, it doesn't seem so alien.
Like, every time you do patch, I'm just like, OK, it's a Swift extension. Or every time you, you know, a lot of these things have analogies in other languages. Yeah, it's exactly a Swift extension. Or in Ruby, they even call it monkey patching. Yeah. But because it's, like, not built into the standard library, some Python programmers are like, no, you're not allowed to use the dynamic features of this dynamic language that were created to make it dynamic.
Anyhow, yeah. Nice. Cool. Well, thank you, Jeremy. I think this is hopefully-- this is like the ultra in-depth. If you were reading the source code and you wanted more, well, I think you got all the more you could want. Yeah, hopefully we might try and do these for a few other projects as well and work through the backlog of the little side things that haven't really been documented.
But yeah, is there anything else you wanted to add for this or, like, introduce this series, I guess? I mean, series is probably too grand a word, you know? I think it's just like, from my point of view, I wanted an opportunity to-- mainly to hear from other folks at answer.ai more about their work.
And so partly, this is like my cunning plan is to, like, if I do one, maybe other people will feel some social pressure to do the same thing. And I will then get to learn more about their work. And Alexis and I have had a similar conversation. And he's promised to teach me about some of his work soon as well.
So hopefully that will be happening soon. And also, I think, in general, answer.ai is a public benefit corporation. And hopefully this is something that provides some level of public benefit to at least some people is-- there's no real-- like in a normal company, this is probably something that would be a private, secret, password-protected internal series.
And here, it's like, no, there's no need to do that. Other people can benefit, too, if they want to. Did any of you have anything else to add to that? My one thought is I think these are a good idea. And I think we should also explore the full range of durations.
So it's good to do deep dives on something that has depth to it. It's also good to do shallow dives on something that is quick and might be trivial to the person explaining it, but is totally unfamiliar and, therefore, high value to the person who hasn't seen it before.
And we can put those ones on TikTok, too. Yes, there we go. Let's see who achieves the first TikTok-length explainer. Awesome. Thanks, all. Thanks, everybody. Well done. Bye. Sure. Bye. Thanks.