fastai v2 walk-thru #3
Chapters
0:06:32 Default Device
16:5 Source Links
20:30 Normalization
29:48 Tab Completion
32:10 Tab-Completion on Change Commands
34:18 Add Props
36:15 Daily Loader
36:39 Data Loader
49:57 Non Indexed or Iterable Data Sets
53:40 Infinite Lists
54:12 Itertools
57:10 Create Item
63:37 Worker Init Function
65:54 Create Batch
66:11 Language Model Data Loader
71:5 Retain Types
Transcript
Hey, folks, can you hear me okay? Can you see everything okay? Hello, Pedro, hello, everybody. Okay, so, if you hadn't noticed yet, I just pinned the daily code. And at the top of it, I'm just going to keep the video and notes for each one. And so, special extra big thanks to Elena, again, for notes, and also to Vishnu, so we've got two sets of notes at the moment, which is super helpful, I think.
So let's see. And if anybody has any questions about previous lessons, after they've had a chance to look at them, feel free to ask during the calls as well, of course, or feel free to ask about pretty much anything, although I reserve the right to not answer. But I will certainly answer if I think it might be of general interest to people.
So we were looking at data core yesterday. Before we look at that, I might point out 08. I made some minor changes to one of the 08 versions, which specifically is the Siamese model dataset one. I moved the Siamese image type up to the top, and I then removed the Siamese image.create method, because we weren't really using it for anything.
And instead, I realized, you know, we can actually just make the pipeline say Siamese image. So that's going to call Siamese image as a function at the end. In other words, it's going to pass, it's going to call its constructor, so it's going to create the Siamese image from the tuple.
I also, rather than deriving from tuple transform to create open and resize, this is actually an easier way to do it, is you can just create a tuple transform and pass in a function. So in this case, you just have to make sure that the function resized image is defined to such that the first parameter has a type, if you want your transform to be typed.
Because we're using these kind of mid-level things, it's a little bit more complicated than usual. Normally, you don't have to create a tuple transform. If you create a data source or a transformed list or a transformed dataset, then it will automatically turn any functions into the right kind of transform.
So we're doing more advanced stuff than probably most users would have to worry about. But I think that people who are on this call are interested in learning about the more advanced stuff. But if you look at the versions after that, we didn't have to do anything much in terms of making this all work.
Okay, so yeah, we didn't have to worry about tuple transforms or item transforms or whatever, because these things like tf.ms know how to handle different parts of the pipeline appropriately. Okay, so that's something I thought I would mention. And you can also see that the segmentation, again, we didn't have to do it much at all.
We just defined normal functions and stuff like that. Okay, so we were looking at O5, and I think we did, we finished with MNIST, right? And then we were starting to look at tf.mdl. And so rather than going into the details of tf.mdl, let's just look at some examples of things that can use tf.mdl.
So in data core, we have to find a few more transforms. As you can see, here's an example of a transform, which is CUDA. So CUDA is a transform, which will move a batch to some device, which defaults this is now incorrect documentation. So let's fix it. Default device is what it defaults to.
So this might be interesting to some of you. Default device, as you can see, returns a device. And so I share a server with some other people. So we've each decided like which GPU is going to be our device. So I'm using device number five. You can change the default device by just passing in a device.
So in fact, you can just say forch.cuda.setDevice. And then that will change it. The reason we have a default device function is that you can pass in useCuda true or false. And so it's kind of handy, you can just pass in useCuda equals false. And it will set the default device to CPU.
Otherwise it will set the default device to whatever you put into torch.cuda.setDevice. This is a really nice, easy way to cause all of fast AI to go between CUDA and non-Cuda and also to ensure that the same device is used everywhere, if you wish to be used everywhere. You never have to use the default device.
You can also always just pass in a specific device to the transform. But if you pass in none, then it's going to use the default. So I mentioned transforms look a lot like functions. As you can see here, we're creating the CUDA transform and then we call it just like a function.
And when we do call them like a function, they're going to call in codes. And the reasons that we don't just use a function, there's a couple. The first is that you might want to have some state. So in this case, we wanted some state here. Now, of course, you could do that with a with a partial instead.
But this is just a nice simple way to consistently do it. And then the second reason is because it's nice to have this decodes method. And so this is quite nice that we now have a CUDA method that automatically puts things back on the CPU. When you're done, it's going to really help to avoid memory leaks and stuff like that.
So like a lot of the more advanced functionality in fast AI tends to be stuff which is like pretty optional, right? So you don't have to use a CUDA transform. You could just put in a pipeline to device as a function. And that'll work absolutely fine. But it's not going to do the extra stuff of making sure that you don't have memory leaks and stuff by automatically calling decodes for you.
So most of the kind of more advanced functionality in fast AI is designed to both be optional and also have like intuitive behavior, like do what you would expect it to do. Okay. So that's the CUDA transform. One interesting feature that you might have noticed we've seen before is there's a decorator called at docs that we use quite a lot.
And what does at docs do? Well, you can see it underneath when I say show doc CUDA.decodes. It's returning this doc string. And the doc string is over here. So basically what at docs is going to do is it's going to try and find an attribute called underscore docs, which is going to be a dictionary.
And it's going to use that for the doc strings. You don't have to use it for all the doc strings. But we very, very often because our code is so simple, we very, very often have one liners which, you know, if you add a doc string to that, it's going to become a three-liner, which is just going to take up a whole lot of stuff.
So this way, yeah, you can have kind of much more concise little classes. I also kind of quite like having all the documentation in one place, personally. So Joseph asks, what is B? So B is being, so let's look at that from a couple of directions. The first is, what's being passed to encodes.
Encodes is going to be passed whatever you pass to the callable, which in this case would be tensor one, just like in an end module forward, you'll get passed whatever is passed to the callable, specifically B in this case is standing for as Kevin's guest batch. And so basically, if you put this transform into the data loader in after batch, then it's going to get a complete batch and it'll pop it onto whatever device you request, which by default, if you have a GPU will be your first GPU.
You'll see here that the test is passing in a tuple containing a single tensor. And of course, that's normally what batches contain. They contain tuples of tensors, normally that have two tensors, X and Y. And so things like two device and two CPU will work perfectly fine on tuples as well.
They will just move everything in that tuple across to the device or the CPU. The tuples could also contain dictionaries or lists, it just does it recursively. So if we have a look at two device, you'll see that what it does is it sets up a function which calls the .2 function in PyTorch.
And it's going to pass it through to the device, but then it doesn't just call that function, it calls apply that function to that batch. And so what apply does is a super handy function for PyTorch is it's going to apply this function recursively to any lists, dictionaries and tuples inside that argument.
So as you can see, it's basically looking for things that are lists or instances and calling them appropriately. PyTorch has an apply as well, but this is actually a bit different because rather than changing something, it's actually returning the result of applying and it's making every effort to keep all the types consistent as we do everywhere.
So for example, if your list thing is actually some subclass of tuple or list, it'll make sure that it keeps that subclass all the way through. Okay, for those of you that haven't looked at the documentation framework in ClassDiv1, you might not have seen show_doc before, show_doc is a function which returns, as you see, documentation.
So if we go to the documentation, let's take a look at CUDA, here is, you can see CUDA.encodes return batch2_CPU, which is obviously the wrong way around, that should say encodes. Right, nevermind, let's do decodes since I had that the right way around, CUDA.decodes return batch2_CPU. So basically, what show_doc does is it creates the markdown that's going to appear in the documentation.
This is a bit different to how a lot of documentation generators work. I really like it because it basically allows us to auto include the kind of automatic documentation anywhere we like, but then we can add our own markdown and code at any point. So it kind of lets us construct documentation which has auto-generated bits and also manual bits as well, and we find that super handy.
When you export the notebooks to HTML, it will automatically remove the show_doc line. So as you can see, you can't actually see it saying show_doc. The other thing to note is that for classes and functions, you don't have to include the show_doc, it'll automatically add it for you, but for methods, you do have to put it there.
All right, so that's kind of everything there, and you can see in the documentation, the show_doc kind of creates things like these source links, which if you look at the bottom of the screen, you can see that the source link when I'm inside the notebook will link to the notebook that defines the function, whereas in the documentation, the source link will link to the -- actually, this isn't quite working yet.
I think once this is working, this should be linking to the GitHub where that's defined. So that's something I should note down to fix. It's working in first AI v1, so it should be easy to fix. All right. So you can see here our tests, so we create the transform, we call it as if it's a function, we test that it is a tuple that contains this, and we test that the type is something that's now putified, and then we should be able to decode that thing we just created, and now it should be uncutified.
So as I mentioned last time, putting something that's a byte, making it into a float takes a surprisingly long time on the CPU. So by doing this as a PyTorch transform, we can automatically have it run on the GPU if we put it in that part of the pipeline.
And so here you'll see we've got one pair of encodes/decodes for a tensor image, and one pair of encodes/decodes for a tensor mask. And the reason why, as you can see, the tensor mask version converts to a long if you're trying to divide by 255 if you requested it, which makes sense because masks have to be long.
And then the decodes, if you're decoding a tensor image, then sometimes you end up with like 1.00001, so we clamp it to avoid those redundant errors, but for masks we don't have to because it was a long, so we don't have those floating point issues. So this is kind of, yeah, this is where this auto dispatch stuff is super handy.
And again, we don't have to use any of this, but it makes life a lot easier for a lot of things if you do. So Kevin, I think I've answered your question, but let me know if I haven't. I think the answer is it doesn't need it. And the reason it shouldn't need it is that it's got a tensor mask coming in.
And so by default, if you don't have a return type and it returns a superclass of the thing that it gets, it will cast it to the subclass. So yeah, this is all passing without that. Okay. So I think that since it's doing nothing, I don't think we should need a decodes at all because by definition, decodes does nothing.
Okay. Great. That's interesting, there's about a 20-second delay. I think there's an option in YouTube video to say low latency. We could try that. It says that the quality might be a little bit less good. So we'll try that next time. Remind me if I forget and we'll see if the quality is still good enough.
Okay. So normalization, like here's an example of where the transform stuff is just so, so, so, so, so helpful because it's so annoying in fast AI v1 and every other library having to remember to denormalize stuff when you want to display it. But thanks to decodable transforms, we have state containing the main and standard deviation that we want.
And so now we have decodes. So that is super helpful, right? So here's how it works. Let's see, normalize. So we can create some data loader transform pipeline. It does CUDA, then converts to a float. And then normalizes with some main and standard deviation. So then we can get a transform data loader from that.
So that's our after batch transform pipeline. And so now we can grab a batch and we can decode it. And as you can see, we end up with the right means instead of deviations for everything and we can display it. So that is super great. Okay, so that's a slightly strange test.
I think we're just getting lucky there because X.main -- oh, I see. It's because we're not using a real main and standard deviation. So the main ends up being less than zero, if that makes sense. BroadcastVec is just a minor little convenience function which our main and standard deviation needs to be broadcast over the batch dimension correctly.
So that's what BroadcastVec is doing, is it's broadcasting to create a rank four tensor by broadcasting over the first dimension. And so there's certainly room for us to improve normalize, which we should do I guess by maybe adding a setup method which automatically calculates a main and standard deviation from one batch of data or something like that.
For now, as you can see, it's all pretty manual. Maybe we should make BroadcastVec happen automatically as well. Add that, inside normalize, adding normalize.setup. So remember setup's the thing that is going to be passed the data, the training data that we're using. So we can use that to automatically set things up.
Okay, so that's normalize. So one of the things that sometimes you fast AI users complain about is data bunch as being like an abstraction that gets used quite widely in fast AI and seems like a complex thing to understand. Here is the entire definition of data bunch in fast AI version two.
So hopefully we can all agree that this is not something we're going to have to spend a lot of time getting our heads around. A data bunch quite literally is simply something that contains a training data loader and a validation data loader. So that's literally all it is. And so if you don't want to use our data bunch class, you could literally just go, you know, data bunch equals named tuple train dl equals whatever, valid dl equals whatever, and now you can use that as a data bunch.
But there's no particular reason to because you could just go data bunch equals data bunch and pass in your training data loader and your validation data loader, and again, you're all done. So as long as you've got some kind of object that has a train dl and a valid dl.
But so data bunch is just something which creates that object for you. There's quite a few little tricks, though, to make it nice and concise, and again, you don't need to learn all these tricks if you're not interested in kind of finding ways to write Python in concise ways, but if you are interested, you might like some of these tricks.
The first one is get atra. So get atra is basically a wrapper around thunder get atra, which is part of Python. And it's a really handy thing in Python. What it lets you do is if you define it in a class, and then you call some attribute of that class that doesn't exist, then Python will call get atra.
So you can Google it, there's lots of information online about that if you want to know about it. But defining get atra has a couple of problems. The first problem is that it's going to grab everything that isn't defined, and that can hide errors because you might be calling something that doesn't exist by mistake by some typo or something, and you end up with some like weird exception, or worse still, you might end up with unexpected behavior and not an exception.
The second problem is that you don't get tab completion. Because the stuff that's in thunder get atra, Python doesn't know what can be handled there, so it has no way to do tab completion. So I will show you a couple of cool things, though. If we define use the base class get atra, it's going to give us exactly the same behavior as thunder get atra does in Python, and specifically it's going to look for an attribute called default in your class, and anything that's not understood, it's going to instead look for that attribute in default.
And the reason for that we want that in databunch is it's very handy to be able to say, for example, databunch.traindl, for instance, there's an example of this dataset. But if you just say databunch.dataset, that would be nice to be able to like assume that I'm talking about the training set by default.
And so this is where get atra is super handy rather than having to define, you know, another example would be one batch. You know, this is the same as traindl.one batch. Yes, Pedro, that would be very helpful to add those tasks as GitHub issues. So in this case, they kind of say consider blah, so the issue should say consider blah rather than do it because I'm not quite sure yet if it's a good idea.
The first one is certainly something to fix, but thanks for that suggestion. Okay, so, yeah, we'd love to be able to, you know, not have to write all those different versions. So thunder get atra is super handy for that, but as I said, you know, you have these problems of things like if you pass through some typo, so if I accidentally said not one batch but on batch, I'd get some weird error or it might even give me the wrong behavior.
Get atra, sub class, fixes, all that. So for example, this correctly gives me an attribute error on batch, so it tells me clearly that this is an attribute that doesn't exist. And here's the other cool thing, if I press tab, I get tab completion. Or press tab, I can see all the possible things.
So get atra fixes the sub class, fixes all of the things I mentioned that I'm aware of as problems in thunder get atra in Python. So like this is an example of where we're trying to take stuff that's already in Python and make it better, you know, more self-documenting, harder to make mistakes, stuff like that.
So the way that this works is you both inherit from get atra, you have to add some attribute called default, and that's what any unknown attributes will be passed down to. And then optionally, you can define a special attribute called underscore extra that contains a list of strings, and that will be only those things will be delegated to.
So it won't delegate to every possible thing. You don't have to define underscore extra. So I'll show you, if I comment it out, right? And then I go data bunch dot, and I press tab, you'll see I've got more things here now. So what it does by default is that underscore extra by default will actually dynamically find all of the attributes inside self.default if underscore extra is not defined, and it will include all of the ones that don't start with an underscore, and they're all going to be included in your tab completion list.
In this case, we didn't really want to include everything, so we kind of try to keep things manageable by saying this is the subset of stuff we expect. Okay. So that's one nice thing. You'll see we're defining at docs, which allows us to add documentation to everything. Ethan's asked a question about Swift.
So it would be best to probably ask that on the Swift forum. So Kevin's asking about tab completion on change commands. No, not really. This is an issue with Jupyter, basically, which is -- it's really an issue with Python. It can't really do tab completion on something that calls a function, because it would need to call the function to know how to tab complete it.
So in Jupyter, you just have to create a separate line that calls each function. But we're doing a lot less change commands in fast.ai version 2, partly for that reason, and partly because of some of the ideas that came out of the Swift work. So you'll find it's less of a problem.
But for things that are properties like this, the tab completion does change correctly. Okay. So that's what underscore extra is. So now you understand what under init is. So important to recognize that a data bunch is super flexible, because you can pass in as many data loaders as you like.
So you can have not just a training and validation set, but the test set, multiple validation sets, and so forth. So then we define done to get item so that you can, as you see, index directly into your data bunch to get the nth data loader out of it.
So as you can see, it's just returning soft.dls. And so now that we've defined get item, we basically want to be able to say at property def train dl self comma I, sorry, self return self zero. And we wanted to be able to do valid dl, and that would be self one.
And so that's a lot of lines of code for not doing very much stuff. So in fastai, there's a thing called add props, which stands for add properties. And that is going to go through numbers from zero to n minus one, which by default is two. And we'll create a new function with this definition, and it will make it into a property.
So here, we're creating those two properties in one go, and the properties are called train dl and valid dl. And they respectively are going to return x zero and x one, but they'll do exactly the same as this. And so here's the same thing for getting x zero and x one, but data set as properties.
So again, these are shortcuts, which come up quite a lot in fastai code, because a lot often we want the train version of something and a validation version of something. Okay, so we end up with a super little concise bit of code, and that's our data bunch. We can grab one batch.
In fact, the train dl, we don't need to say train dl, because we have good atra, which you can see is tested here. And one batch is simply calling, as we saw last time, next, ita, tdl, and so it is making sure that they're all the same, which they are.
And then there's the test of get item, and that method should be there. Okay, all right. So that is data core. If people have requests as to where to go next, feel free to tell me. Otherwise, I think what we'll do is we'll go and have a look at the data loader.
And so we're getting into some deep code now. Stuff that starts with 01 is going to be deep code. And the reason I'm going here now is so that we can actually have an excuse to look at some of the code. The data loader, which is here, is designed to be a replacement for high torch data loader.
Yes, meta classes, I think we will get to Kevin pretty soon. We're kind of heading in that direction, but I want to kind of see examples of them first. So I think we're going to go from here, then we might go to transforms, and we might end up at meta classes.
So this is designed to be a replacement for the pytorch data loader. Why replace the pytorch data loader? There's a few reasons. The biggest one is that I just kept finding that there were things we wanted to do with the pytorch data loader that it didn't provide the hooks to do.
So we had to keep creating our own new classes, and so we just had a lot of complicated code. The second reason is that the pytorch data loader is very -- I really don't like the code in it. It's very awkward. It's hard to understand, and there's lots of different pieces that are all tightly coupled together and make all kinds of assumptions about each other that's really hard to work through and understand and fix issues and add things to it.
So it just -- yeah, I was really pretty dissatisfied with it. So we've created our own. Having said that, pytorch -- the pytorch data loader is based on a very rock-solid, well-tested, fast multiprocessing system, and we wanted to use that. And so the good news is that that multiprocessing system is actually pulled out in pytorch into something called _multiprocessing_data_loader_idder.
So we can just use that so we don't have to rewrite any of that. Unfortunately, as I mentioned, pytorch's classes are all kind of tightly coupled and make lots of assumptions about each other. So to actually use this, we've had to do a little bit of slightly ugly code, but it's not too much.
Specifically, it's these lines of code here, but we'll come back to them later. But the only reason they exist is so that we can kind of sneak our way into the pytorch data loading system. So a data loader, you can use it in much the same way as the normal pytorch data loader.
So if we start with a dataset -- and remember, a dataset is anything that has a length and you can index into. So for example, this list of letters is a dataset. It works as a dataset. So we can say data loader, pass in our dataset, pass in a batch size, say whether or not you want to drop the last batch if it's not in size 4, and say how many multiprocessing workers to do, and then if we take that and we run two epochs of it, grab all the elements in each epoch, and then join each batch together with no separator, and then join each set of batches together with the space between them, we get back that.
Okay, so there's all the letters with the -- as you can see, the last batch disappears. If we do it without dropLast equals true, then we do get the last bit, and we can have more than, you know, as many workers as we like by just passing that in.
You can pass in things that can be turned into tensors, like, for example, ints, and just like the -- this is all the same as the PyTorch data loader, it will turn those into batches of tensors, as you can see. So this is the testing. Test equal type tests that this thing and this thing are the same, and even have exactly the same types.
Normally test equals just checks that collections have the same contents. Okay, so that's kind of the basic behavior that you would expect to see in a normal PyTorch data loader, but we also have some hooks that you can add in. So one of the hooks is after iter, and so after iter is a hook that will run at the end of each iteration, and so this is just something that's going to -- let's see what T3 is.
T3 is just some tensor, and so it's just something that's going to just set T3.f to something, and so after we run this, T3.f equals that thing, so you can add code that runs after an iteration. Then, let's see this one. That's just the same as before. You can also pass a generator to a data loader, and it will work fine as well.
Okay, so that's all kind of normal data loader behavior. Then there's more stuff we can do, and specifically, we can define -- rather than just saying after iter, there's actually a whole list of callbacks that we can, as you can see, that we can define, and we use them all over the place throughout fast.ai.
You've already seen after iter, which runs after each iteration. Sorry, after all the iterations, there's before iter, which will run before all the iterations, and then if you look at the code, you can see here is the iterator, so here's before iter, here's after iter. This is the slightly awkward thing that we need to fit in with the PyTorch multi-processing data loader, but what it's going to do then is it's going to call -- it's going to basically use this thing here, which is going to call sampler to get the samples, which is basically using something very similar to the PyTorch's samplers, and it's going to call create batches for each iteration, and create batches is going to go through everything in the sampler, and it's going to map do item over it, and do item will first call create item, and then it will call after item, and then after that, it will then use a function called chunked, which is basically going to create batches out of our list, but it's all done lazily, and then we're going to call do batch, so just like we had do item to create our items, do batch creates our batches, and so that will call before batch, and then create batch.
This is the thing to retain types, and then finally after batch, and so the idea here is that you can replace any of those things. Things like before batch, after batch, and after item are all things which default to no-op, so all these things default to no operation, so in other words, you can just use them as callbacks, but you can actually change everything, so we'll see examples of that over time, but I'll show you some examples, so example number one is here's a subclass of data loader, and in this subclass of data loader, we override create item, so create item normally grabs the ith element of a dataset, assuming we have some sample that we want, that's what create item normally does, so now we're overriding it to do something else, and specifically it's going to return some random number, and so you can see it's going to return that random number if it's less than 0.95, otherwise it will stop, what is stop?
Stop is simply something that will raise a stop iteration exception, for those of you that don't know, in Python, the way that generators, iterators, stuff like that, say they've finished is they raise a stop iteration exception, so Python actually uses exceptions for control flow, which is really interesting insight, so in this case, we can create, I mean obviously this particular example is not something we do in the real world, but you can imagine creating a create item that keeps reading something from a network stream, for example, and when it gets some, I don't know, end of network stream error, it will stop, so you can kind of easily create streaming data loaders in this way, and so here's an example basically of a simple streaming data loader, so that's pretty fun.
And one of the interesting things about this is you can pass in num workers to be something other than 0, and what that's going to do is it's going to create, in this case, four streaming data loaders, which is a kind of really interesting idea, so as you can see, you end up with more batches than the zero num workers version, because you've got more streaming workers and they're all doing this job, so they're all doing it totally independently.
Okay, so that's pretty interesting, I think. So if you don't set a batch size, so here I've got batch size equals four, if you don't set a batch size, then we don't do any batching, and this is actually something which is also built into the new PyTorch 1.2 data loader, this idea of, you know, you can have a batch size of none, and so if you don't pass a batch size in, so here I remember that letters is all the letters of the alphabet, lowercase, so if I just do a data loader on letters, then if I listify that data loader, I literally am going to end up with exactly the same thing that I started with because it's not turning them into batches at all, so I'll get back 26 things.
I can shuffle a data loader, of course, and if I do that, I should end up with exactly the same thing that I started with, but in a shuffled version, and so we actually have a thing called test shuffled that checks that the two arguments have the same contents in different orders.
For randio, you could pass in a keyword argument whose value can be set to 0.95 or any other number less than 1. I'm not sure I understand that, sorry. Okay, so that's what that is. Something else that you can do is, you can see I'm passing in a data set here to my data loader, which is pretty normal, but sometimes your data set might not be, might not have a done-to-get item, so you might have a data set that only has a next, and so this would be the case if, for example, your data set was some kind of infinite stream, like a network link, or it could be like some coming from a file system containing like hundreds of millions of files, and it's so big you don't want to enumerate the whole lot, or something like that.
And again, this is something that's also in PyTorch 1.2, is the idea of kind of non-indexed or iterable data sets. By default, our data loader will check whether this has a done-to-get item, and if it doesn't, it'll treat it as iterable, if it does, it'll treat it as indexed, but you can override that by saying indexed equals false.
So this case, it's going to give you exactly the same thing as before, but it's doing it by calling next rather than done-to-get item. But this is useful, as I say, if you've got really, really, really huge data sets, or data sets that are coming over the network, or something like that.
Okay, so that is some of that behavior. Yes, absolutely, you can change it to something that comes as a keyword argument, sure. Okay, so these are kind of more just interesting tests, rather than additional functionality, but in a data loader, when you have multiple workers, one of the things that's difficult is ensuring that everything comes back in the correct order.
So here, I've created a data loader that simply returns the item from a list, so I've overwritten list, that adds a random bit of sleep each time, and so there are just some tests here, as you can see, that check that even if we have multiple workers, that we actually get back the results in the correct order.
And you can also see by running percent time, we can observe that it is actually using additional workers to run more quickly. And so here's a similar example, about this time, I've simulated a queue, so this is an example that only has done to iter, doesn't have done to get item, so if I put this into my data loader, then it's only able to iterate.
So here's a really good example of what it looks like to work with an iterable only queue with variable latency. This is kind of like what something streaming over a network, for example, might look like. And so here's a test that we get back the right thing. And now in this case, because our sleepy queue only has it done to iter, it doesn't have a done to get item, that means there's no guarantee about what order things will come back in.
So we end up with something that's shuffled this time. Which I think answers the question of Juvian 111, which is what would happen if shuffle and index are both false, so it's a great question. So if indexed is false, then shuffle doesn't do anything. And specifically what happens is, in terms of how it's implemented, the sampler -- here is the sampler -- if you have indexed, then it returns an infinite list of integers.
And if it's not indexed, then it returns an infinite list of nones. So when you shuffle, then you're going to end up with an infinite list of nones in shuffled order. So it doesn't actually do anything interesting. And so this is an interesting little class, which we'll get to, but basically for creating infinite lists.
You'll see a lot of the stuff we're doing is much more functional than a lot of normal Python programming, which makes it easier to write, easier to understand, more concise. But we had to create some things to make it easier. So things like infinite lists are things which are pretty important in this style of programming, so that's why we have a little class to easily create these two main types of infinite lists.
And so if you haven't done much more functional style programming in Python, definitely check out the iter tools standard library package, because that contains lots and lots and lots of useful things for this style of programming. And as you can see, for example, it has a way to slice into potentially infinite iterators.
This is how you get the first N things out of a potentially infinitely sized list. In this case, it definitely is an infinitely sized list. Okay. So let's look at some interesting things here. One is that randl doesn't have to be written like this. What we could do is we could create a function called create, or we could say a function called rand item, like so.
So we're now not inheriting from the data loader, we're just creating a function called rand item. And instead of creating a randl, we could create a normal data loader. But then we're going to pass in create item equals underscore randitem, and so that's now not going to take a cell.
Great, okay. So as you can see, this is now doing exactly the same thing. That and that are identical. And the reason why is we've kind of added this really nice functionality that we use all over the place where nearly anywhere that you -- we kind of add callbacks or customise ability through inheritance.
You can also do it by passing in a parameter with the name of the method that you want to override. And we use this quite a lot because, like, if you've just got some simple little function that you want to change, overriding is just, you know, more awkward than we would like you to force you to do, and particularly for newer users to Python, we don't want them to force them to have to understand, you know, inheritance and OO and stuff like that.
So this is kind of much easier for new users for a lot of things. So for a lot of our documentation and lessons and stuff like that, we'll be able to do a lot of stuff without having to first teach OO inheritance and stuff like that. The way it works behind the scenes is super fun.
So let's have a look at create item, and, yes, great question from Haromi. When you do it this way, you don't get to use any state because you don't get passed in self. So if you want state, then you have to inherit. If you don't care about state, then you don't.
So let's see how create item works. Create item is one of the things in this long list of underscore methods. As you can see, it's just a list of strings. Underscore methods is a special name, and it's a special name that is going to be looked at by the funx quags decorator.
The funx quags decorator is going to look for this special name, and it's going to say, "The quags in this init are not actually unknown. The quags is actually this list." And so what it's going to do is it's going to automatically grab any quags with these names, and it's going to replace the methods that we have with the thing that's passed to that quag.
So again, one of the issues with quags, as we've talked about, is that they're terrible for kind of discoverability and documentation, because you don't really know what you can pass to quags. But pretty much everything we use in quags, we make sure that we fix that. So if we look at dataloader and hit Shift+Tab, you'll see that all the methods are listed.
You'll also see that we have here assert not quags. And the reason for that is that @funxquags will remove all of these methods from quags once it processes them. So that way, you can be sure that you haven't accidentally passed in something that wasn't recognized. So if instead of, for example, doing create batch equals, we do create back equals, then we will get that assertion error so we know we've made a mistake.
So again, we're kind of trying to get the best of both worlds, concise, understandable code, but also discoverability and avoiding nasty bugs. Okay, so, all right, another tiny little trick that one that I just find super handy is store atra. Here is something that I do all the time.
I'll go, like, self.dataset, comma, self.bs, comma, et cetera equals data set, comma, bs, et cetera. So like, very, very often when we're setting up a class, we basically store a bunch of parameters inside self. The problem with doing it this way is you have to make sure that the orders match correctly.
If you add or remove stuff from the parameter list, you have to remember to add or remove it here. You have to make sure the names are the same. So there's a lot of repetition and opportunity for bugs. So store atra does exactly what I just described, but you only have to list the things to store once.
So it's a minor convenience, but it definitely avoids a few bugs that I come across and a little bit less typing, a little bit less reading to have to do, but I think that's it. Okay. Let me know if anybody sees anything else here that looks interesting. Because we're doing a lot of stuff lazily, you'll see a lot more yields and yield froms than you're probably used to.
So to understand fast.ai version 2 foundations better, you will need to make sure that you understand how those work in Python pretty well. If anybody has confusions about that, please ask on the forums. But I did find that by kind of using this lazy approach, a function approach, we did end up with something that I found much easier to understand, had much less bugs, and also was just much less code to write.
So it was definitely worth doing. Okay, so then there's this one ugly bit of code, which is basically we create an object of type fake loader, and the reason for that is that PyTorch assumes that it's going to be working with an object which has this specific list of things in it.
So we basically had to create an object with that specific list of things and set them to the values that it expected, and then it calls iter on that object, and so that's where we then pass it back to our data loader. So that's what this little bit of ugly code is.
It does mean, unfortunately, that we have also tied our code to some private things inside PyTorch, which means that from version to version, that might change, and so if you start using master and you get errors on things like, I don't know, underscore autocollation doesn't exist, it probably means they've changed the name of some internal thing.
So we're going to be keeping an eye on that. Maybe we can even encourage the PyTorch team to make stuff a little bit less coupled, but for now, that's a bit of ugliness that we have to deal with. Something else to mention is PyTorch, I think they added it to 1.2, maybe it was earlier, they've added a thing called the worker init function, which is a handy little callback in their data loader infrastructure, which will be called every time a new process is fired off.
So we've written a little function for the worker information function here that calls PyTorch's getWorkerInfo, which basically will tell us what dataset is this process working with, how many workers are there, and what's the ID of this worker into that list of workers, and so we do some, you know, so this way we can ensure that each worker gets a separate random seed, so we're not going to have horrible things with random seeds being duplicated.
We also use this information to parallelize things automatically inside the data loader. As you can see, we've got, yes, we set the offset and the number of workers. And then we use that here in our sampler to ensure that each process handles a contiguous set of things which is different to each other process.
Okay, so PyTorch, by default, calls something called default-collate to take all the items from your datasets and turn them into a batch, if you have a batch size. Otherwise it calls something called default-convert. So we have created our own fastAI-convert and fastAI-collate, which handle a few types which PyTorch does not handle, so it doesn't really change any behavior, but it means more things should work correctly.
So create batch by default simply uses collate or convert as appropriate, depending on whether your batch size is none or not. But again, you can replace that with something else, and later on you'll see a place where we do that. The language model dataloader does that. In fact, that might be an interesting thing just to briefly mention.
For those of you that have looked at language models before, the language model dataloader in fastAI version 1, and most libraries, tends to be big, confusing, horrible things. But look at this. This is the entire language model dataloader in fastAI version 2, and it's because we were able to inherit from our new dataloader and use some of these callbacks.
But this actually has all of the advanced behavior of approximate shuffling and stuff like that, which you want in a modern language model dataloader. We'll look at this in more detail later, but as an example of the huge wins that we get from this new dataloader, things get so, so much easier.
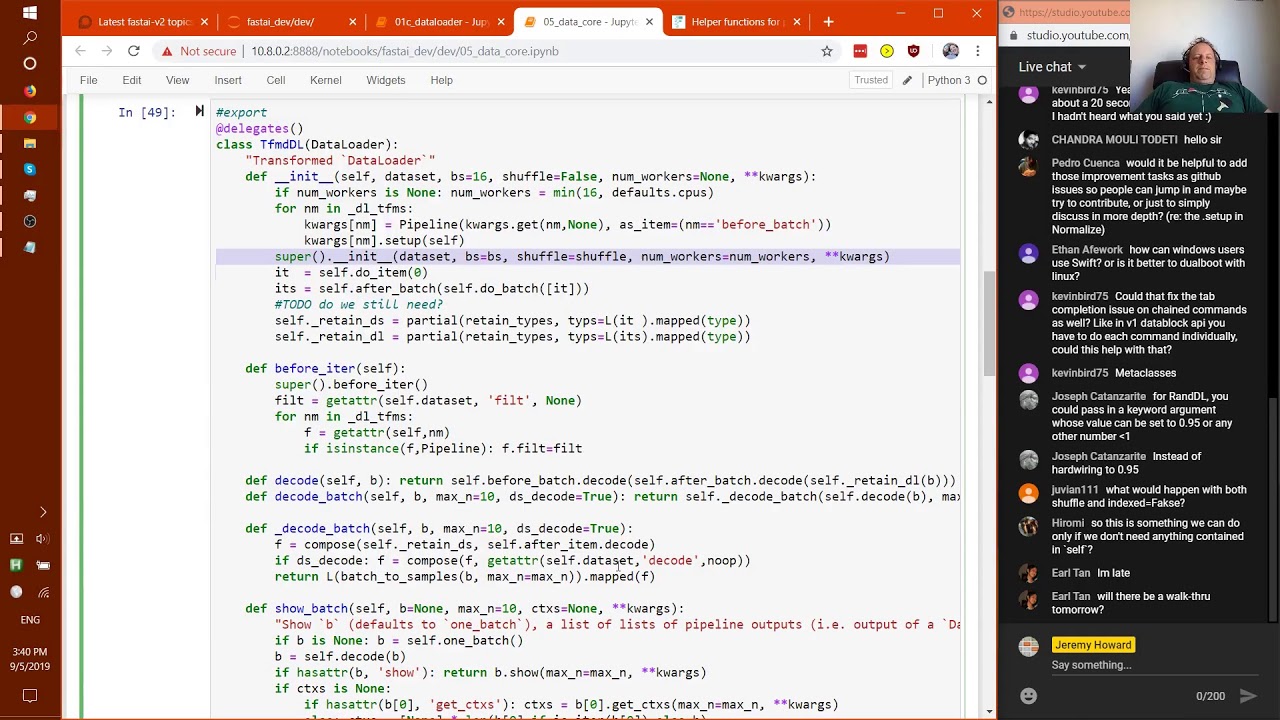
Now I think we can go back and look at what is a transform dataloader in more detail, because a transform dataloader is something which inherits the dataloader. It gets a bunch of quags, which as we mentioned, thanks to @delegates, passed to the dataloader, in this case is the superclass, but they're all going to be correctly documented and they're all going to be tab-completed and everything, thanks to @delegates.
So what's the additional stuff that TufemDL does that dataloader doesn't do? Well, the first thing it does is this specific list of callbacks turned into transform pipelines. So basically after you grab a single item from the dataset, there will be a pipeline. After you've got all of the items together, but before you collate them, there will be this callback, and after everything's been turned into a collated batch, there will be this callback and these are all going to be pipelines.
So you can see here, these are all in _deautofems, so we're going to go through each of those and we're going to turn them into a pipeline, okay? So it's just going to grab it and turn it into a pipeline. Remember how I mentioned before that there are item transforms and tuple transforms, and tuple transforms are the only ones that have the special behavior that it's going to be applied to each element of a tuple.
And I mentioned that kind of stuff, all the TufemDL and TufemDS and everything will handle all that for you, and here it is doing it here, right? Basically before batch is the only one that's going to be done as a whole item and the other ones will be done as tuple transforms.
And then I also mentioned that it handles setup, so this is the place where it's going to call setup for us if you have a setup. We'll be talking more about setup when we look at pipelines in more detail. But the main thing to recognize is that TufemDL is a data loader.
It has the callbacks, these same three callbacks, but these three callbacks are now actual transformation pipelines, which means they handle decodes and all that kind of thing. So a TufemDL we're going to call under init needs to be able to decode things. So how is it going to decode things?
So one of the things it's going to need to know is what types to decode to. And this is tricky for inference, for example, because for inference, in production all you're getting back from your model is a tensor, and that tensor could represent anything. So our TufemDL actually has to remember what types it has.
And so it actually stores them -- the types that come out of the dataset are stored away in retainDS, and the types that come out of the data at the end of the batching is stored away in retainDL. And they're stored as partial functions. And we'll see this function called retain types later, but this is the function that knows how to ensure that things keep their types.
And so we just grab -- so we get one item out of our batch, just in order that we can find out what types it has in it, and then we turn that into a related batch in order to find what types are in that. So that way, when we go decode, we can put back the types that we're meant to have.
So that's what's going on there. So basically what that means, then, is that when we say show batch, we can say decode. Decode will put back the correct types, and then call the decode bits of all of our different pipelines, and then allow us to show it. If we can show the whole batch at once, which would be the case for something like tabular or for things like most other kinds of data sets, we're going to have to display each part of the tuple separately, which is what this is doing here.
So we end up with something where we can show batch, decode batch, et cetera. So L. Tan's asking, will there be a walkthrough tomorrow? Yes, there's a walkthrough every day. You just need to look on the fast.ai version 2 daily code walkthroughs where we will keep the information updated.
Oh, wait. But today's Friday. No, today's Thursday. Yeah. So it's going to be every weekday, so I'm turning tomorrow. So let me know if you have any requests for where you would like me to head next. Is that all of that one? So if I look where we've done, we've kind of, we've done 01c, we've done 08, we've done 05.
So maybe we should look at pipeline. So that's going to be a big rabbit hole. So what I suggest we do is we wrap up for today. And tomorrow, let's look at pipeline, and then that might get us into transforms. And that's going to be a lot of fun.
All right. Thanks, everybody. I will see you all tomorrow. Bye-bye. Bye-bye. Bye-bye. Bye-bye. Bye-bye. Bye-bye. Bye-bye.