Stanford CS25: V3 I Retrieval Augmented Language Models
Transcript
- Hey guys, welcome to our last lecture of this quarter. And we're very happy to have Dawa here. He's the CEO of Contextual BI, the enterprise LLM company, as well as an adjunct professor in symbolic systems here at Stanford. And previously he was the head of research at ClickBase.
And before that, a research scientist at Facebook AI Research. He received his PhD and master's from the University of Cambridge, as well as a master's in logic from the University of Amsterdam, and studied philosophy and cognitive AI in undergrad. And his work focuses on machine learning as well as NLP, specifically on developing better models for language understanding and generation, and better tools for evaluation and many more.
Yeah, give it up for Adele. - Right, thank you. So I guess I have to sort of stand here in the corner so people can see me on the Zoom as well. Yeah, thanks so much for having me here. So I asked Stephen what I should talk about. There were a couple of things I could talk about, multimodality or evaluation.
And this was the preferred topic, I guess, because the others were already covered. So yeah, I'm very happy to talk to you about everything retrieval augmentation. I think this is really one of the coolest topics right now in our field. So I'll just give you an overview of what's been happening and what I think are the interesting questions to think about.
So first of all, obviously, in case you've missed it, we are in the age of language models. And I just wanted to do a quick poll here in this not super big audience. I guess there's more people on the Zoom, but who invented language models? If you thought OpenAI, then I'm angry with you, right?
So actually, this is a very, very old idea. So the idea is just you take a sequence and you factorize out the token probabilities, right? And so it wasn't invented by OpenAI. It's not like a few years old. It's actually several decades old. So I'm bringing this up because I was talking to someone and they were like, "OpenAI invented language models." And I was like, "You're kidding me, right?" So I went back to the literature and this is the oldest one I could find, actually.
1991, first neural language model. There's a very nice paper from 2003 from Bengio where they actually have word embeddings and everything already in there. So obviously, these are LLMs, not LLMs. And as it turns out, if you make them really big and you parameterize them with these massive neural nets, then you get something really powerful that really shows emergent properties.
And that's why we're all so excited in this stuff. So if we think about this from a classic CS perspective, there's input-output, right? There's this kind of thing in the middle. It's the generator. So we take a sequence, the input sequence, and then the task of the model is to predict the next token.
Very, very simple model. And so that's why it was so easy to come up with this in 1991 already, because the idea is very intuitive. But for a long time, what was really broken with this was the user interface. And this, I think a lot of people kind of misunderstand what ChatGPT was about.
That's really what ChatGPT fixed. So that initially you had to come up with these very weird prompts in order to get your language model to do what you wanted it to do. And humans are terrible at this, right? So we're much better at sort of telling people or things around us what we want, right?
So if we have a dog, we say, "Sit." We don't prompt it in a very weird way so that it sits, right? And it's the same with the language model. If you wanted to generate some rap lyrics in the style of a pirate or Shakespeare or something, then you tell it generate some rap lyrics in the style of a pirate, right?
So that kind of instruction data actually turns out to be super, super rare in just web data. So what you need to do is you need to fix the user interface to the language model. And the classic recipe for doing that is the sequence basically that ChatGPT used. So you prompt the model in a specific way, you instruction finds in the model, and you do some alignment, RLHF, whatever you do on top of that.
So that's the first thing. So now you have a working language model with a working user interface. So are we done then? Obviously we're not, right? So right now language models are kind of taking the world by storm. But if you talk to anyone, especially in an enterprise, for example, where they have very strict accuracy requirements, they will tell you that they can't really productionize this yet.
And the reason is because there are all these familiar problems, probably a bunch of you are working on these problems right now around hallucination. So these models, they kind of make up stuff very often with very high confidence, which is even more scary in a way. Attribution, so we don't really know why these models are saying what they're saying.
Staleness, they go out of date. And so this was a big problem with sort of chat GPT, not knowing anything that happened after a certain cutoff date, and they keep updating it every once in a while. But you want to have a system that's always completely up to date, that never goes stale.
You want to be able to revise the information in the system. So if you're a European organization, you have to worry about GDPR, which means that you need to be able to remove information from the language model or maybe revise facts, which we don't really know how to do.
So again, this is a very interesting area of study for a lot of folks, model editing. But so this is something that we really want to be able to fix. And then there's this big question of how do you customize these models? So different people have different use cases, you have different data, if you're a company, or if you want to have a language model on your own data, how do you make it work on your own data?
So one of the solutions that everybody has started using right now is to couple it to an external memory. So that's really just RAG, right? This whole lecture is basically about RAG, but the way to understand what is going on here is we have this generator just like before, we have the input and the prompt just like before, but now instead of just giving those two things, we give this additional context.
So we contextualize the language model using things we've retrieved. And the retriever is very often pretty simple, it's just a query in a document encoder. And then you get a bunch of documents, you give them as context to the model. So super simple architecture. And I think it's useful to think about it from the perspective of these two separate paradigms.
So if you've ever taken an exam, I'm sure you have, right? You can have a closed book exam where you have to memorize all of this, so you have to cram all the knowledge into your parameters, your neurons, or you have an open book exam where you have all of this information in the book that you can access when you do the exam.
So it's a very similar thing with rank, right? You can just make it an open book setting where you can give it access to this external information, Wikipedia, or something else, or basically the entire internet, and then have the language model do its job without having to memorize all of it in its parameters.
So the other, I think, useful distinction here is that cramming everything into your parameters, that's the parametric approach, right? So what we're doing with RAG is we're adding this non-parametric retrieval component. So you might call this semi-parametric if you want to give this a name. All right, so why does that actually solve these issues?
And so the answer is basically that if you have this separate index, right, this separate retriever, you can swap it in, you can swap it out, you can replace it with a new index, so you can really customize it. And so you can customize your language model system for what the user really wants to see.
And then obviously you can update this index so it doesn't really go still, and you can revise it if everything goes wrong, if anything goes wrong. The other thing you get is grounding, right? So that's initially why I became interested in this kind of architecture, because I was thinking a lot about grounding and multimodality and things like that.
And actually one really nice way to ground things is to find some other information that you can ground your generation in. And so you really want the language model to only say things that it has evidence for in this other piece of text, or even multimodal data that it retrieves separately.
So if you do that, then you get less hallucination, because you can always point back to your source, it's always grounded in your source. And you get attribution because you don't know why the model is saying what it's saying, it's because it found this thing here. Is that clear?
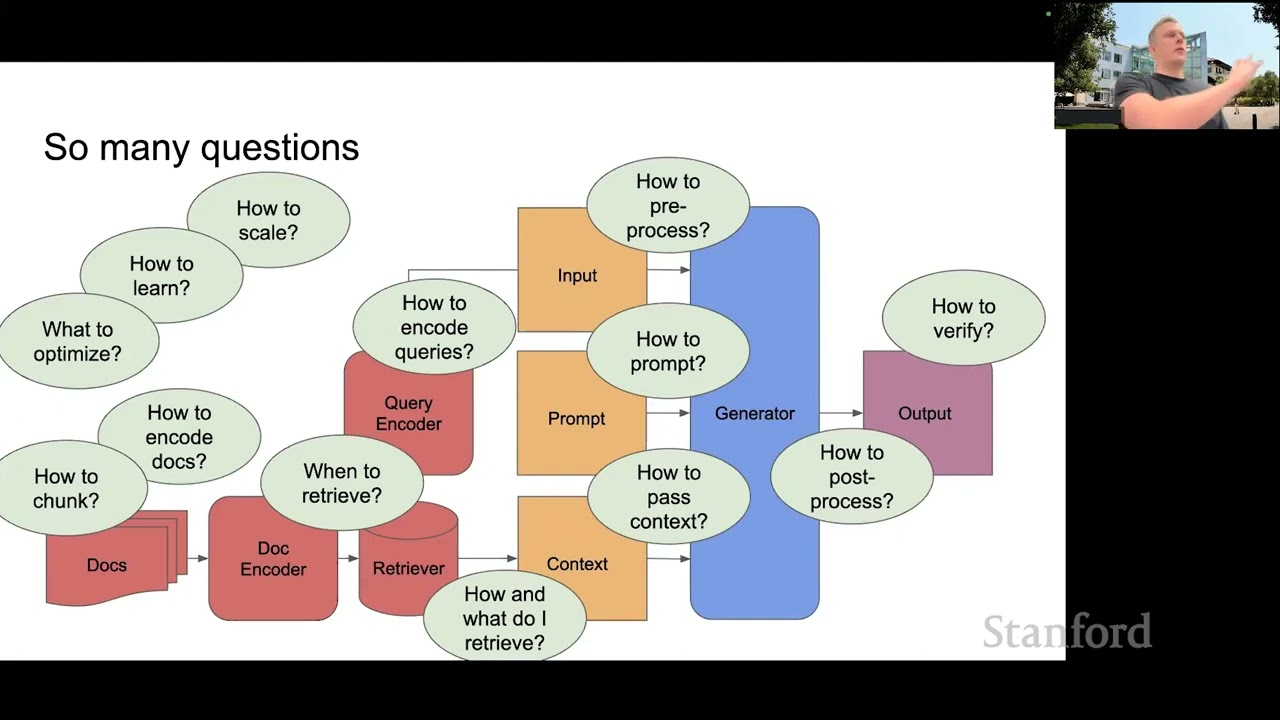
All right, so for the rest of this lecture, we're gonna talk about this basic architecture. And so it kind of looks like a pretty simple thing, right? But there are actually lots and lots of questions you can ask about what this system should really look like. And this doesn't even cover half the questions you can ask.
So it really is about how do we optimize this entire system, right? So we have these separate components, the retriever, the generator, and then there are things like this query encoder, how do we encode queries? How do we do the retrieval? Do we update the documents encoder? How do we actually define a document, right?
Is it like a full document, or is it a paragraph, or a chunk, or a sentence, or a couple of words? So there are lots of questions to ask. And as you'll see, there are lots of possible answers to these questions as well. So this is what we'll cover.
So there are lots of architectures going into these questions. And I think as we go through them, it's useful for you to think about what happens during training time and what happens during test time, right? So during training time, it's really, okay, we have this language model, we have this retriever, which one do we update?
How do we update them? How do we train this entire system? Do we maybe not train it at all? Do we pre-train it from scratch? Do we initialize it with components that were already separately trained? These are the kinds of questions that you have to answer if you wanna design a system like this.
And then during test time, you have this entire system, right, so actually multiple models in a way that are working together. So there's also different things you can do there, right? So give it different indices during test time or manipulate kind of how you're sampling, things like that. So the starting point for all of this stuff, I think if you ask someone now, like, what is RAG, they will think of this thing.
So this is frozen RAG, basically. There's no training here at all. So going back to this question of train time, test time, there's only test time here. Train time happens separately with these kind of black box models that we don't necessarily have control over, right? So there's this document embedding model, whatever is currently at the top of some open source leaderboard.
You use that to, oops, sorry, to get some vectors that you then use to create this vector database. And then the vector database just does search and it gives the information from the search to the language model. And it just passes it as the context, right? So this only works because of in-context learning.
And I think as a machine learner myself, this feels very inelegant. So what this lecture is about is, can we do better than this frozen thing? So let's start from the left side of this. Like, okay, if we want to outperform this frozen thing itself with just the vector database, like, what would that look like from a retrieval perspective?
And the starting point for everything retrieval is TF-IDF. Does everybody know what TF-IDF is? No, okay. So TF-IDF is basically a sparse retrieval method where you have a score function that looks at documents and queries, so D and Q. And then there are basically two terms that matter. One is the TF, the term frequency, and the other is the IDF, the inverse document frequency.
So this inverse document frequency is actually a really nice idea from Karen Spark-Jones, a really underrated researcher. She's done some amazing work. But the basic idea is that you want to look at the words that are very special, so that don't occur in lots of different documents. And so the overlap between the word "the" doesn't really matter, right?
Like, "the" occurs everywhere. So you want to have sort of the special words. So that's what TF-IDF does in a nutshell. It gives you a score for document query overlap. And then you can do all kinds of things here with how you weight it. So there's all these weird, different parameters, like this B and things like that, that allow you to make it better than just having the TF-IDF score.
So there's a couple of tweaks you can do there. So BM25, actually, in case you're wondering, stands for Best Match 25. So I tried to discover, like, where does the 25 actually come from? That's because the prior, sort of the preceding 24 experiments failed, right? So it's literally the 25th one that seemed to work, and that's why it's called BM25.
It's bizarre, right? But so this is sparse retrieval. It's just counting words, right? So you have this massive, massive vector of all these word occurrences. It's sparse because most words never occur, right? So it's sort of like a vector of vocabulary size dimensions. So most of that is obviously zero.
But so that's actually kind of a nice property if you want to do fast search on a CPU, right? Because on a CPU, sparse dot product is very easy to compute. So this is used in the system called DrQA, which is really one of the first neural instances of this open domain, sort of open book question answering paradigm.
So you have a question, like how many of Warsaw's inhabitants, blah, blah. So you want to ask, basically, Wikipedia what the answer is for this. So then you have this document retriever based on the sparse, so BM25, I think, in this case. Retrieval methods, you pass that to, I think this was still by LSTM at the time, a document reader model, and then that model gives you the answer.
So this, I think, is really the first instance of having sort of this separation between a retrieval and a generator system that you use for answering complicated questions based on sort of open domain knowledge. So after the sparse stuff, there was a bunch of work on dense retrieval. And so the advantage of dense retrieval, so this is just like word embeddings, basically vectors, like they're dense now, no longer sparse, so they're much smaller in terms of dimensionality.
And a nice advantage of dense retrieval is that it's not really about specific words, right? So if there are synonyms, you can still find the relevant document, which you couldn't really do with a sparse representation. So that's really the advantage of dense is that you get like semantic similarity.
So you can do this over word embeddings. That doesn't really work all that well, but at the time that people started thinking about this, BERT was already out there, and BERT is really great for giving you a vector representation for an entire sequence of words. So a sentence representation or a passage representation.
So there are all these cool systems like ORCA and DPR, the Dense Passage Retriever, where they essentially use the retrieval as a kind of latent variable in the system. And the way to get the latent variable to work, to be good enough essentially to train the entire system is to pre-train the retriever on relevant information.
So for ORCA, they do something called inverse close. So they do kind of a close task where you want to find passages that are sort of relevant to the preceding passage. And in DPR, they just train it on a supervised thing. But really the core idea here is that, as you can see in this graph here, you can do better than VM25 if you add lots of documents and the way you compute the score function is much simpler, it's just a dot product.
So the nice thing about dot products is that you can do them very, very efficiently on the GPU as well if you know what you're doing. So what you really want to get at is maximum inner product search, MIPS, right? This is one of the kind of core ideas of a lot of this stuff.
And you can do MIPS with ANN, approximate near neighbor search. And so there's this really brilliant piece of work out of there for my colleagues at the time, called FACE, which really underlies all of these modern vector databases, right? So all the popular ones, they're sort of re-implementations of this FACE idea.
One is in Rust, one is in Go, but it's all basically the same idea, it's just FACE. And so FACE really powers a lot of this stuff. And whenever somebody tells you something about a vector database, just think about FACE, very fast dot product. So obviously, you can go beyond dot product, yes?
- What is it, what is FACE? - What is FACE? So it's an open source library, Facebook AI similarity search. No, so it's just basic off-the-shelf ANN algorithms. Yeah, so there are all kinds of different, I don't know if you, do you know what like product quantization is and things like that?
So there are basically, so you have a bunch of vectors and you can just compute the full dot product, which is sort of inefficient, right? So what you can do is try to compress subspaces of the vector, and then just look at the kind of centroids. So you can quantize sub-vectors of the full vector and then do much faster search over just the centroids.
It's a good question, any other questions? All right, so about this dot product idea. So what we have here is, some people call this a Siamese network, I guess it is, right? So you have two different BERT models or whatever your encoder is here. And then at the end, you get these two vectors and then you just do dot product so you get one single score.
But you can do all kinds of much fancier things if you're willing to give up on this bi-encoder approach, right? So a really nice example from one of your colleagues here at Stanford is Colbert. So what this does is late interaction. So instead of just having this dot product here, you have a kind of more complicated version of computing a score where you aggregate over sort of maximum similarity scores between different words.
So I only recently actually discovered that this is called Colbert because of the late night show, Colbert. So it's sort of Omar's joke, actually, this name, but just so you know, if you run into it. So, but I think if we look at kind of where the state of the art has been going now, one of the nice things about these vector databases is that they're super efficient, right?
So dot product is much more efficient than this late interaction stuff, especially if you do the approximate nearest neighbor search. But there's been some really cool work. So things like SPLADE, they basically have sparse meet dense in a way. So one of the big problems, as I said, with sparse is that you can't really handle synonyms and things like that.
But what you could do is take a dense model, like a bird model, look at kind of this one word in your sequence, try to see which other words fit in the same slot. So that gives you the synonyms. So now you can give all these synonyms to a sparse vector, and then you can just do sparse dot product.
And so I have a much more efficient way to do search without sort of giving up on all the cool stuff that you get from a dense representation. So that's one thing. And this other idea I really like is called DRAGON. So this I think is really the best generalized dense retriever.
So if you want to take something off the shelf right now and just go to Hugging Face or something, then this DRAGON or DRAGON+ is probably the thing you want to use for a dense retriever. And the way they train this is through this progressive data augmentation strategy to make the model better and better over time by sampling very difficult negatives.
And that gives you very good representations. And so the other thing about this, I think this is the only sort of final point about retrieval in general is that what we see happening right now, if you look at sort of the developer community around DRAGON is that they're all doing hybrid search right now.
So you can actually just combine the search results from your sparse BN25 or whatever thing, or SPLADE, and you can combine them with your DRAGON, and then you'll get this ranking that works even better. So then you kind of get best of both worlds, but then you get all these questions about how do you combine the results.
Any questions on this part? - Oh, can you hear me? - Yes. - Oh, sorry. On the earlier slide, has there been any work on benchmark how much less hallucination RAG incurs over a closed book question answering, for example, directly asking the large language model the question, has there been any benchmarking studies in this?
- Yeah, so there's a great paper, if I can say so myself, on the fact that retrieval augmentation reduces hallucination. It's from 2021, I think. So yeah, you can just find, if you literally look for retrieval augmentation reduces hallucination, then you'll find the paper. - Thank you. (indistinct) - Yeah, so very often you want to have very precise word overlap for things where you don't want to have the synonyms or the kind of nearest neighbors, right?
So if there's like a brand name or something like that, then like, let's say the brand is Apple, right? You don't want to find stuff about the pairs, right? So that's what you would do with a dense retriever. So it really kind of depends on what you want to use it for.
That's why hybrid is probably the way to go. It's a good question. - Like with the dense, it's contextualized in that inspection, it realized Apple, the company would be different. - No, so if they were actually contextualized, then yes, but very often it's a frozen retrieval system, right? That's one of the problems with all the frozen rack stuff.
(indistinct) No, so the sort of document and the query, they're the same, right? So they're either sparse or they're dense. So if they're sparse, the components of the vector are literally the other words. (indistinct) So it's literally counts, right? So basically it's a one big matrix of documents as rows and the columns are the words in the documents.
And then you just count how often a word occurs in a document, right? So that's as far as that. (indistinct) Yeah, and so in the field, we call them sparse embeddings or sparse retrieval because most of that vector is zero, right? Because most words don't occur in that document.
Does that make sense? - Yeah. - Cool. So let's talk about doing slightly better. So going back to Stephen's question about, okay, we have this kind of retrieval thing, but how do we actually make this retriever good for the context that is going to be used in, right? So can we contextualize the retriever for the generator, even if it's a generator where we might not have access to the weights?
So it could be a GPT-4 model, we just send it to some API, we get some stuff back. And so one paper I really like is called Replug. So just to kind of explain what this looks like, so you have this context, you have a retriever that we do the standard retrieval step with, this is a dense retriever.
And now, sorry, and now you compute the likelihood. So basically just normalize the scores that you get for the top K documents to get a distribution here. And then you'll give each one of the retreat documents separately to this generator, to your language model. So you can look at the perplexity of the correct answer for that language model, right?
So now we have these two probability distributions or two likelihoods essentially, and we can minimize the KL divergence to make sure that we can actually retrieve the documents that lead to the lowest perplexity on the right answer for the language model. So super simple idea, works really, really well.
And the nice thing about this is completely agnostic of what happens upstream, right? So this will work for any sort of encoder, decoder, for any language model. What you need is a perplexity score, but for most language models, you can get that, not necessarily all of them. So that's one thing.
And then there's this other really nice approach. (indistinct) So in the retriever, you're literally updating the dense representations, right? So you're encoder basically for your dense representation. That's a good question. We'll get into that a little bit more. So there's another paper on in-context retrieval augmented language models, where the whole paper is basically about just doing BM25 and just giving stuff directly to the context of the language model and things kind of work.
So it's sort of frozen rag, but even more primitive in a way where the retriever is this very old sparse algorithm, but it works really, really well. But then they have this really awesome section where they show that you can just have this re-ranker on top of the BM25 results and you can backdrop into this re-ranker.
So now you still keep the language model completely fixed. So that's sort of this part of the loss here. So you have kind of a stop gradient on the parameters data. That's just your language model. But now you have this kind of rank function here that you can backdrop into, right?
So that's your re-ranker. It's basically, it can be a BERT model or anything like that that works on top of the things you initially retrieved from your BM25. And now you have this BERT re-ranker that you can backdrop into. So this also works really, really nice. So we're slowly progressing towards having a system that is much more optimized for being properly retrieval augmented in a way where it's useful and contextualized for what you want to use it for.
So yeah, just to point out kind of what that looks like with this re-ranker. So you just have this extra step essentially, right? So we have our retriever, then we have a re-ranker, then we have our generator and our output. - (indistinct) - No, not necessarily. So for this one you do, yeah.
But so for re-plug you don't, right? - Yeah. - Yeah. Yeah, yeah, yeah. So basically, yeah, you need to get... - (indistinct) - Not all of them. Some of them do, but yeah, there are all kinds of tricks you can do on top of that, yeah. So basically the question is how do we get sort of gradients flowing into this, right?
So if you don't actually have access to the full parameters of the model so that you can backdrop all the way through it, then you can do a reinforce style loss on the retrieval. And then you just pass the kind of log-like view if you have access to that or some other kind of black box function.
All right, so the next thing you can do is to optimize both the retriever and the generator. And so this really starts getting to the proper kind of contextualization of the entire architecture where you want everything to work together, right? So rather than having this frozen thing where everything is basically not aware that the other part exists, right?
It's like two halves of the brain they're not talking to each other. One is your retriever, the other is your language model. There's no connection. They're just like sort of like something is thrown over the fence and then you hope for the best. So instead of that, we have everything much closer and learning together.
So one of the first ways of doing this with a generator was RAG, retrieval augmented generation which we did at FAIR in 2020. And it's very similar to what we've already seen. We basically have this retriever here that works over different documents. You get some score function that gets given to this generator that generates the answer.
And now you want to backdrop all the way and update your generator as well, right? So in the previous two architectures we saw you keep the generator fixed. You backdrop into your retriever but here we update everything. Well, not exactly everything as you'll see but we'll also update the part of the retriever and the generator.
So in this RAG model, we actually have two different ways of doing this. And this is probably something that when we talk about this if you think about this long enough, then you'll think like okay, but when actually do I need to retrieve? Like do I retrieve every time I generate a new token or do I just retrieve once and then generate an entire sequence, right?
Or maybe I want to retrieve every N tokens, right? So these are hyperparameters or maybe I want to learn when to retrieve. As we'll see that's also something people have done. So these are two different ways to do it. And what we do in this paper basically the whole point of the paper is that this frozen thing doesn't really work all that well.
So I think what people call RAG now is usually refers to the frozen thing but the whole paper basically would never have been accepted anywhere if we had just done the frozen thing. The whole point of the paper is that you want to optimize it. And so at my company Contextual we call this frozen thing Frankenstein's monster because it's really like you cobble together these different pieces, right?
You sort of, yeah, it's really like Frankenstein and just put it together and then it sort of walks, you know but it doesn't really have the soul. It doesn't really actually work. It's not the real thing. So that's great for everyone here, I think because there are so many opportunities to do better than what most people are using right now.
So one of the limitations of the original RAG architecture is that it only supports a very small cave, right? So if you have lots and lots of documents then the problem is that you have to fit all of them in the context but how do you really get that to fit, right?
So one thing you can do is you first encode things so that you get one single representation or only the few sort of top level representations then you concatenate those and then you just feed them to the decoder. So this is FID fusion and decoder. And as you can see the skills to a much higher number of passages and that leads to corresponding improvements in the scores that you care about.
So that's a really cool idea. And so we're slowly moving towards more decoder only architectures, right? So in RAG, we have this BART model it's sort of an encoder decoder architecture but here you just have this decoder that does some fancy attention over stuff that you retrieved before. And so another like pure decoder language model architecture is this one KNNLM which I think is very elegant in its simplicity.
So it's basically you just have a normal language model but you interpolate the normal language model weights with things that you retrieved. So basically you have some sort of prompts, right? So like Obama's birthplace is, you go to your big corpus you find similar things. You look at the words that come next to the similar things.
You rank that thing, you sample your top K you renormalize that. So now you have a bunch of scores and now you can just interpolate between your retrieved kind of non-parametric memory scores and your parametric language model scores. So this is very late fusion in a sense, right? At the very end, you combine these two and it allows you to re-weight the pure language model probabilities or likelihoods.
So this works really well and it scales especially well if you have a huge retrieval corpus, right? So if you have trillions and trillions of tokens in there you can have a much smaller language model that does not that much heavy lifting because you can really rely on this big source corpus that you're working from.
And so that idea was exploited by this paper called "Retro Out of Deep Mind" where they showed that you can have a 25 times smaller retrieval augmented language model trained from scratch. So really pre-trained entirely from scratch that outperforms this 25 times bigger language model on the same data in terms of perplexity which is pretty impressive, right?
So this architecture is much more efficient than a parametric model because you can rely on this external memory. So if your external memory is big enough you can get pretty huge gains. So there was a lot of excitement about "Retro" when it was announced, but it's a "Deep Mind" paper.
So there's really no open source, nothing really to validate that this actually works. And so very recently there has been a bit of work from NVIDIA called "Retro++" where they have this hybrid between the "Retro" architecture and then they do basically "Rag" sort of they put the top one or the top K results in the context of the language model after all.
So it's sort of a crossover between "Rag" and "Retro" and they showed some really nice results here but I think it's sort of pointing to this big flaw I think is that why is there still no good open source "Retro" model? That probably tells you something about whether it actually really works.
I spent a lot of time in my career trying to reproduce "Deep Mind" papers that didn't necessarily always work. And so I think the same is true for "Retro" and that's why we need to do this in context "Rag" on top of "Retro" to actually get it to work.
But could it just be a 2.8? There's such a treat on both end. Yeah, but so... So "Deep Mind" and stuff. No, so doing retrieval over that big corpus is not that difficult actually. Yeah, so there are even like distributed face packages you can just do everything yourself. So, yeah.
So in terms of compute it's actually not that hard anymore to reproduce something like this. But I've tried several times and it's not really reproducible. So the only way to get it to work is if you do this in context "Rag" on top of the "Retro" thing. And then as you can see here in the results then it actually gives you a gain over the pure GPT model.
So it starts from a GPT and then they kind of retrofit as they call it the GPT model. So in short, I think there's still a lot of work to be done in pre-training these systems really from scratch. And "Retro" kind of showed that it might be possible but we don't necessarily know exactly how to do it the right way.
And this is really one of the interesting open questions. Any questions on that? Online? No, okay. Then we'll move on. So let's go all the way with the contextualization now. So with "Retro" and with "Rag" what we actually did is we only updated the query encoder. So updating the document encoder is very expensive.
So one of the first papers actually kind of the OG of the non-frozen dense retrieval augmented methods is this paper called "Realm". This is really like visionary work. This was basically the first kind of version that did this properly where they updated it all the way including the document encoder.
So can someone explain to me why it's expensive to update the document encoder? So let's say we have a trillion tokens in our corpus. So now we go all the way. So we basically do a forward pass. We get a gradient at the end. Now we back propagate the gradient through the retriever.
We update the query encoder. Now we have to update the document encoder. So what do we then need to do after we've updated the document encoder? We need to re-encode the entire internet, right? So basically every single gradient update we have to re-encode whatever our index is. Which, and so if this is like trillions of tokens it's like re-encoding the internet after every batch update.
So that's not very efficient. (indistinct) - Yeah. Yeah, that's one way to do it. So there are a bunch of different ways to update the document encoder. So what they do in Realm is they basically do it for T batches. Then they stop, they re-encode the entire internet and then they train again.
So it's sort of asynchronous updates. They have this very fancy sort of sharding mechanisms where they take down certain parts of their entire index and then update them kind of on the fly. So you can do it, it's just very expensive. So one of the things that a lot of people have been thinking about, not exactly the Delora idea but similar versions of that are around like, can you make it more efficient so that you don't have to do this asynchronously?
So one of the downsides of this Realm architecture is that it's really just a BERT model but then you do this retrieval augmentation on a BERT model with other BERT models. So it's not pretty generative. It's not really gen AI in the modern paradigm. But if you wanna read like one paper on this topic like this is a very good one to read.
The other one that is really, really good to read is this paper called Atlas. So Atlas is, so this is out of there with a bunch of folks, the folks who did like RAG and the folks who did FID and really a brilliant set of people. And this is really a comprehensive analysis of everything that's happening in this architecture.
So the first question they really look at is how do we train this retriever? So we've seen a couple of versions of this but which one actually works better? They haven't really been compared in a head to head setting. So one thing is we have this FID style sort of attention distillation.
So that's really too complicated to go into detail here but the others are actually very simple. So one is this loss we've basically seen before, right? So we've seen this, I think with the in-context RAG one, right, so we have a stop gradient on the language model and then we update the retriever.
The other one is what we've seen with Replug. So this is basically exactly the Replug loss, right? So we have the KL divergence of the documents and sort of the improvement that you see when you give it that document. The other thing they have is basically the inverse of that one.
So if I take this one document out, how does that affect my perplexity of the language model? And so this one I think is actually quite elegant because that really gets to like how valuable is this one single document for me answering this question correctly. So they compare all of these different versions and what you can see is that the kind of Replug style loss and this leave one out loss, they perform a lot better than all of these others.
So this fixed retriever or no joint pre-training, these are really kind of the baseline sort of frozen RAG models or closed book. And as you can see, you can do really a lot better if you optimize things. And so this leave one out thing is probably the best I would say.
So then the other question is, how do you actually like train that entire system? Like what data or what tasks do you train this on? So they also experiment with a bunch of different versions. So one is doing prefix LM, if you're familiar with that. So they basically take a chunk that occurs somewhere on the internet and then they predict the next chunk from that chunk.
So it's really like sentence to sentence. So maybe like skip thought back in the day, but now you have this retrieval step where you predict the next sentence. Then they just do T5 style sort of denoising. So that's mass language modeling, if you're familiar with T5. And then they have this title for section generation piece.
So I think the takeaway from this table is basically that whatever you do here, so they're using T5 model. So whatever you do here needs to be the same that your language model expects. So for T5, that's T5 style loss. And then the next sort of final question that they look into going back to what we talked about, how exactly do we update this retriever?
So do we have to update the document encoder or do we maybe have to do some sort of re-ranking or do we maybe just update the query? And quite surprisingly, I think they find that just updating the query, so like in the original RAD paper, is actually already basically good enough in many cases.
So that's nice because it's much more efficient if you don't have to update your documents all the time. I think the real question here though is like, how good is your document representation to begin with? So you need to have a very, very high quality embedding model for this to work.
If you don't have that, then this will not work. But if you do have that, then you get a very nice kind of query side fine-tuning thing. So the Atlas paper is about trying to do few-shot sort of language modeling tasks. So it's how many examples are given in the context.
Yeah, so the main takeaway here is that if you compare like the closed-book equivalent model to the retrieval augmented model, you see very big improvements. That's really the only takeaway of this entire section. But I think that that's really saying something in terms of what we should be thinking about.
How much time do I have until? - There's still time. - Okay, okay. All right, other questions? (indistinct) - Yeah, so they can be different. So in Atlas, Atlas basically tries everything. So they also tried to see what happens if I train this on Wikipedia, but I swap in like a sort of common crawl index.
So in Atlas, but also in Retro, the main finding is just the more, the better. So it's really just like the bigger your index, the more likely you are to find the exact right thing and then make the right prediction. Any other questions on this? - Oh yeah, sorry.
This is a question about the generator in the, I guess, the rack system. So recently I saw a paper on Mistral 7B. So it introduces a lot of these new architectural changes like the sliding window attention to handle longer sequences at a smaller cost and the group query attention for faster inference.
I'd like to like know your thoughts on designing a generator specifically for RAG, leveraging, for example, where Mistral 7B currently is. Because for example, like the sliding window attention, I could see how that could be adapted to the RAG case. - Yeah, so maybe your read on sort of what makes Mistral's special is a bit different from mine.
So I don't think that the sliding attention window thing is actually that interesting. The reason Mistral works so well is because it's trained on a lot of data and you can do that more efficiently because you have sliding window attention so you don't need to attend to everything. But so to answer your question, I guess you're asking sort of about the architecture of the generator if you know that there's gonna be a retriever.
So I think that's basically what Retro tried to do. So Retro actually, some of the people on the Retro paper are at Mistral now. So they have this chunk cross-attention idea here. So you basically have the language model, but the way it does attention over the things you retrieve in your Retro architecture, they kind of get integrated into a model not using the standard attention mechanism, but using this slightly different chunk cross-attention.
- Oh, okay. So I think the sliding window attention point I was trying to get at was that it uses a fixed window so that whenever you're doing the query key computation with the query vectors and the key vectors, you're using a fixed window attention. So I think my idea was to actually, one, use a dynamic window because for example, the rag case, if you use a fixed window when you're doing attention, it is possible that you actually are leaving, you're only looking at a fixed span of information.
So if you could maybe adapt Mistral so that you could make it better for the rag case in, for example, making the fixed window size the dynamic window, yeah. - Yeah, I think it's an interesting idea. So for me, what Mistral is doing with the sliding window, that's basically like a conf net, right?
So we had all these convolutional light conf nets where we would have word embeddings and you would do convolutions over it and then pool, and then you would still get the information out. So it's not that the sliding window prohibits you from looking earlier, it's just that that happens higher up in your transformer sort of.
- Yeah, yeah. Okay. So I think that definitely is an interesting direction to think in, yeah. - Yeah, so I think it's like not too crazy to say, are there any architectural changes that we can introduce into these 7 billion parameter models so that they could be better adapted to the rag case?
- Yeah, so there might be, yeah. I think one question is just how do you do the attention over things you've retrieved, which I think is what you're doing. Yeah, thanks. - So just to make sure I understand, so yes, I mean, in this virtual model, you are retrieving each block, and when you talk about putting the retrieval in the context, are you saying that you only do it at the beginning and you don't do it at each block?
- Yeah, so in context, so this is, it's not exactly every layer sort of, so it's every token, right? So every step basically, not every block. So it doesn't make sense. So it's not every layer that you do the retrieval, right? Yeah, so every step, right? So this is kind of like what rag token is.
So you retrieve every token, so you generate and then you can retrieve again. Or in the case of retro, you can generate like a chunk and then you retrieve chunks again. If you look at the in-context case, you retrieve once at the beginning and then you give it. - So that's what you're saying.
You're saying that during the retrieval, nobody has had enough to say. - Yeah, so the in-context thing, so here you don't actually give it as context at all, like directly to the model, right? So here you let the decoder kind of attend over it. - Like cross-attention. - Yeah.
- And that nobody has to do. - So I don't think cross-attention really works, yeah. - Yeah. - Other questions? - Yeah, we did inside that in the case which retrieving on the retriever is not so necessary because of the large loss. So I'm wondering what inside of the cases, like what cases are really necessarily need to do A, B, and X update or any way to update those document or, yeah.
- Yeah, so you do want to update the retriever, right? But only part of the retriever is necessary to be updated for a lot of these cases. But so I think it, so these are very specific data sets, right? Natural questions, Wizard of Wikipedia, and Fever. So they're really very kind of knowledge-intensive tasks.
So in that case, if you already have a very good system like DPR that is specifically pre-trained for those tasks, then you only need to update the query encoder. So I would expect that if you move beyond this to kind of general language modeling things like Retro, then you probably do want to update the document encoder at least in a way where you can scale it.
- So I think that's in the, these tasks are very knowledge-intensive. And actually, we covered for (indistinct) as long as we have a good (indistinct) knowledge of the documents by those good models. - Yeah, but so you need to learn how to kind of query into that index, right?
So if you don't do that, then yeah, you don't get really good performance. So that's sort of like your closed book performance, right? If you just have the language model and you're just like, what does the parametric model on its own without the retriever? What does it actually know?
As you can see, there are pretty big gaps there. Other questions? Otherwise, I will cover other questions. No? - Hello? - Yeah, go for it. - A quick question. Like, so what about like more hierarchical retrieval? Like I suppose there'll be methods trying to not just retrieve a single chunk, but there's some kind of like groups of chunks or something or some right expressions.
- There's been some interesting work on doing that where you first try to find, so you can have multiple indices and they can kind of cascade, right? So first you want to find the relevant document. So you have some document representation and then within that document, you want to find the relevant chunk.
So you can do it sort of that direction. You can also do it in reverse. I think I have something on a slide there where you can find the chunk and then sort of expand the context around it and then give that to the language model. And so I think, yeah, there are all kinds of interesting things you can do there.
- Cool. Thanks. I guess another thing, just like, can you compare RAD versus like long context efforts? So there are lots of things like around just having a really long context and the extreme, it could replace RAD, but I don't know, like if it takes. - Yeah, so everybody understands this question, right?
So there's a trend where we want to have very long context language models so that basically you can like take Harry Potter or something, just put it in the context and then ask a question, like what is the name of like Harry Potter's owl or something, right? And then it can just attend over the entire thing.
So attending over all of Harry Potter to answer that one question is super inefficient, right? So most of Harry Potter has nothing to do with the owl. So, but you are still kind of reading it if you do it with the long context window. So that's why I think doing it the RAG way where you have this non-parametric component is a much more efficient way to solve this problem.
And if you actually look at the literature on long context windows, the way they solve the problem of scaling the attention mechanism is by making it very sparse. So they're basically turning it, so that's a different kind of sparse, but they're turning it into a non-parametric retrieval problem kind of behind the scenes.
So they're not actually all that different. If you want to scale long context, then you're going to move towards a RAG style architecture. - Cool, thanks. - All right. So let's talk about some other interesting questions. So one thing, and I already alluded to this, is when do we actually retrieve?
So if we're doing like, if we want to like retrieve every token, that's also very inefficient because I probably don't have to retrieve to generate the, right? I can probably do that on my own with the language model as sort of a way to go and retrieve stuff. But if I only retrieve once at the beginning of the sequence, that's probably also not great, right?
So what we ideally want to be able to do is to say, okay, sometimes I want to retrieve, sometimes I don't want to retrieve, and I'm going to learn when I want to kind of expend the compute budget on doing the retrieval. So a nice paper where they have a stab at, this is called Flare for Active Retrieval Augmentation, where they basically have the language model decide when it should do a search and what it should do the search for.
So I think this fits in a general trend that you can see in the field around kind of agents, right? So we can talk a little bit more about that too. So this other question that I think we've also kind of covered already here is how do we train this at scale, right?
So we can do these asynchronous updates, we can do re-rankers, we can do query-side only. There's this really nice paper, which is quite close, I think, to the idea you proposed, where you first use VM25 to create a batch, basically, where everything is very similar in terms of what you've retrieved.
And now you have this kind of in-batch update. So it's sort of like a re-ranker where you encode the information that is just in your batch using this other model. And now you can update this model on the fly. So you don't have to worry too much about doing the full kind of document-side update.
And again, here, what really matters is how big is your index? If you have an amazing index, you can basically solve any problem just by looking it up. So rather than cramming it into your parameters, you can just find it. This is a really nice paper called "Silo." So one of the interesting things, I think that's going to happen in the next year or two, around language models is there, and you've seen this already, there's a bunch of lawsuits against OpenAI and other places around where does the data exactly come from.
So one very elegant solution, I think, is to have a RAG system that you train on data that you know is safe. So you can train that thing on Wikipedia, but now during test time, you can give it a data store that has maybe slightly riskier information in it.
So this massive index of all the stuff on the internet, including some things that are maybe higher risk, you can still have them in your index, but your language model, your retrieval augmented language model, I should say, you know that that thing is safe because it was trained on data that is public domain.
So that's what they do in Silo, and they show that that works really well. So that's one possible solution to a lot of the kind of compliance and legal risk around language model deployments. - There's a great paper also from one of your colleagues around context getting lost in the middle.
I think this is also kind of a fascinating phenomenon. This is on a frozen RAG system, but language models are very similar to humans in what things they pay attention to. So if you give them a bunch of things that you've retrieved, what they will look at are the first things you list and the last things you list, and they will sort of ignore the middle.
So if it actually respected the rank function, then this curve would go down all the way, right? But it sort of goes up. So I think that's a very interesting observation, which kind of shows how brittle these systems can be, right? So if you have a frozen RAG system, it can be very, very brittle where like the order of the retrieved context matters a lot in whether you get the right answer or not.
(indistinct) - Yeah, so what I just described, someone asked like, how do you actually, so I said there are other ways to do this, and then the question was, how do you do that? So the way that you do that is using reinforce. So yeah, there has been work on doing that.
So some of the older papers were playing with this, but one of the big problems with, so I think the replug solution is sort of more elegant for solving that problem, because you actually sort of use signal from the language model. And if you just do reinforce, it's very high variance.
So it's gonna be super finicky if you don't want to destroy your index. But people have tried it, yeah. So there's some really nice work from OpenAI where they basically show, and again, we're sort of like thinking more and more about agents here, right? Where they show something very similar to the FLARE results from earlier with active retrieval that doesn't necessarily have to be some index that you only can be just some web search, right?
And obviously in this case, you don't really have access to the web search necessarily. So Bing or whatever they use here is not gonna update its parameters. But I just wanted to kind of put this in your mind, like this is another thing you can do, right? And if we take this really to the general form, then you can think of language models as just tool users.
So rather than just retrieval augmenting language models, we can tool augment language models and retrieval is just one of the many tools that language models have access to. We can have re-rankers and things on top of the outputs of these tools. And so one of the big questions I think is how do you actually get the system to learn stuff, right?
So we're gonna need RL if we want this system to really learn how to take these actions properly. And so, yeah, this has been taken to the extreme in this sort of self-drag architecture where they have this sort of retrieval step and it's active and then you criticize it and then you basically do some natural language inference and all of that just with one language model to answer the questions.
So the other missing piece, so I'm just kind of going through a bunch of open questions that people have looked at, but feel free to interrupt me if there's anything you wanna know. But so instruction tuning, we established at the beginning of the lecture that this is pretty important for getting things to work, so fixing the user interface.
But the instruction tuning has almost always only happened on the language model and not on the entire system. So I think one of the interesting things that people are looking at now with things like RADiT and InstructRetro is how can we instruction fine-tune an entire retrieval augmented system? So all the way into the retrieval step, can we generate data so that that also follows the instructions properly, which currently doesn't happen in any of these model architectures.
And then finally, I think I would be remiss if I didn't really talk about what people call advanced RAG. So like the developer community has been really doing some awesome stuff. So like frameworks like Lama Index and LangChain, and there's all these open source vector databases like Chroma and Weave8, and they're all sort of about making RAG really easy, but this is all frozen RAG, right?
But even with frozen RAG, you can really do incredible things. So we mentioned some of these already, so Child-Parent Recursive Retriever. So you find small parts and then you give the big parts around it to the language model. You can do hybrid search where we use reciprocal rank fusion.
So we have like different search results that we then combine before we give the final thing to the language model. There's ZeroShot, like a large language model re-ranker. So basically the score function is not, it doesn't come from your retrieval. It comes directly from the language model. And then Hypothetical Document Embeddings, which I think is a really cool idea.
So you just, basically you fix hallucination through hallucination. So you get a question, then you let the language model hallucinate a bunch of possible answers. Then you go and search for nearest neighbors to the possible answers, and you give those as context, and then it gives the right answer based on that.
So it was really like hallucinating answers. I think it's a brilliant solution. So there's a lot of stuff happening in the kind of frozen RAG community too, that I think is very interesting to look at. So just to wrap up, kind of looking at the future of this stuff, there are still lots of very interesting open questions.
So if you're a student thinking about how to solve any of these, I think you can have quite a lot of impact. So how exactly do we do like pre-training of this architecture? And do we even need to pre-train? I think even retro kind of shows that you don't necessarily have to pre-train.
So maybe there's something wrong with how we do that. What do scaling laws look like? So I think there's a really interesting question here around if I have a huge index and a very rich encoder of all the information in that index, maybe I can move, so basically decouple all the memorization to this index.
So I have a language model that doesn't know anything. It just speaks English. It just sort of reasons on top, but it has no knowledge because that always comes from this retriever. If you can do something like that, then you get very interesting scaling trade-offs, right? So you can have a tiny language model and do your retrieval to do a lot of the heavy lifting with your retrieval, which is nice because that's a cached computation, right?
So you can just, you already have the embeddings. You just need to do the dot product. So it's much more efficient than kind of self-attention in the language model. Can we move beyond by encoder? So vector databases, I like people who build vector databases, but I'm not sure how long we're gonna keep vector databases because I think re-rankers probably work just as well, and VM25 is much more efficient than a vector database.
So I don't really see why we need dedicated vector databases. And so what we're seeing, but maybe this is a bit of a critique of maybe Silicon Valley investment strategies and things like that, but a lot of these vector database companies are basically becoming database companies now. So they are adding all this sparse stuff because the density is not enough.
And as it turns out, there are a lot of pretty good sparse databases out there already like Postgres and things like that. And they're also all adding vectors to their databases. So I think that's all gonna kind of coalesce into databases. So I think there are some interesting things to look at for kind of the data.
So to this instruction problem, can we generate much better data for training rack systems synthetically? And then I think there's this massive open question around how we actually measure whether the rack system is any good. So right now we just look at downstream performance, which is sort of okay, but if you mess up the retrieval, it's very hard to measure.
But how to measure whether your retrieval is right is also very difficult. So there are some frameworks where they try to take like the harmonic mean of your retrieval accuracy and your language model accuracy. But I think those are also very shoddy because we don't really have very good data sets to measure that on.
So I think that's a very cool problem to work on as well. So the other problem that I personally am always very excited about is multimodality. And so why would we stop with rack systems with just text? So you can do the same thing with images. You can augment language models with vision.
So we did this work on lens where we have a language model enhanced to see where you can just give a kind of a computer vision pipeline just like a retrieval pipeline and give that to a frozen language model and pass it to the context. And that system actually is an amazing visual question answering system.
It's close to state of the art sort of Flamingo from DeepMind, which is also very hard to reproduce because there's no open source version of that. So we've done some early work on this in 2021 where we have this cross-modal retrieval and there's some more recent work out of FAIR where they also look at this.
So I think that's really like, if you look at the trend in the field, multimodality with GPD 4 or V and things like that is really a hot topic. So everything is kind of going in that direction. So it's an interesting thing to think about. So overall, I think it would be nice if everybody sort of moves away from RAG 1.0 to frozen Frankenstein RAG and moves towards this much more optimized version RAG 2.0.
So it's really about systems over models, right? It's not just your language model and your retriever and they're kind of separate. It's about thinking from a systems perspective about the entire thing and the problem you're trying to solve. And so I think that really is the way that in deep learning things have always progressed where if you optimize the system end-to-end, that's always going to win out.
Like back in the day in computer vision or NLP, we had like parsers and scene parsers and all this kind of stuff. And all of that just doesn't exist anymore now because we optimize the system end-to-end. And so that's what's going to happen here too. So if we take that to the extreme, like there's this chunker thing in your documents, right?
Like cutting it up into pieces, like you could back drop into debt. Like, why not? Somebody should really do that. And so, yeah, I think like trading off costs and quality and zero-shot domain generalization, that's really like where this stuff is going to come in. So language models right now, they're amazing, but very often they're way too expensive for being deployed somewhere where you can actually make money from them if you're in a company.
So what you want to do is make it much more efficient and have the right cost quality trade-off. And the easiest way I can think of is to do it through retrieval augmentation. But obviously I'm very biased. So yeah, that was all I had actually. So if you're interested in this, I'm at Stanford.
So I can work with you on research projects on these topics, or if you want, you can also join Contextual because we work on this stuff every day. Thank you. - Well, sorry, I had a question from earlier. Yeah, I think you said something really, I think really super helpful earlier about Mistral 7B.
You talked about, you compared the sliding window attention to convolutional neural networks. And I do see the parallel because with convolutional neural networks, you have several layers of, several different layers of convolutional layers. And the top convolutional layers are able to see a larger receptive field in the bottom convolutional layers.
And with convolutional layers, you're able to tune the filter sizes and the strides. So you're able to see a different receptive field. And I was wondering if you could see that same innovation in Mistral 7B by tuning, because you have different transformer layers and each transformer layer will have a span over a different set of tokens.
And if you can tune, I guess, the transformer architecture, the way you tune those convolution layers, the filter sizes, the receptive field, perhaps we can do some optimization in the transformer realm that we have already done in convolution layers. - Yeah, I think that, so that's a good idea.
There's a great paper on light convolutions, I think from Michael Owley and David Gange and a bunch of people, where it's basically, this came out at exactly the same time as the transformer. And the transformer is slightly more optimized for GPU computation, but the convolutional model was actually slightly better than the transformer.
So it's definitely worth exploring. - Okay, cool, thanks. - It's probably the advantage of the re-branch over VM25, but does that give up a lot of the advantages of this massive search or is it a trade-off of upgrades? - Yeah, so it depends on the problem. I think what you probably want to do is sort of cast a white net with VM25 and then just narrow it down with dense search.
So you often see that kind of as a two-stage process where the first one is kind of noisy, you can add noise actually to your retrieval and then you use the dense one to filter it down. - Yeah, everyone's trying to maybe adapt their large-scale model to almost domain-specific areas.
Like I think there are mainly two ways to approach it. One way is to use the instruction-tuning in a small-type learning way or fine-tuning like QE method. And another way is just, the main topic of this lecture is using virtual-augmented work. So I wonder if you guys know a method of low-cost advantage of virtual-augmented way?
Do you think the capacity or the quality of virtual-augmented way can be matched with those tuning methods, fine-tuning type learning? - Yeah, so I think actually what's gonna happen is that all of this will come together, right? So if you actually train things like end-to-end, React 2.0 style, then you can also fine-tune that system on some use case end-to-end, right?
So why would you just take the retrieval-augmented system if you can also fine-tune it on the thing you care about? So I think in the end, everybody's gonna do all of those things. And then there's questions like, how do you do that efficiently? So that's why you would use it after, sort of things like that.
I think there was another question. - I'm curious about hardware. You said it's gonna become a database kind of thing, like a smart database, but what about retrieval of hardware? And because you've got so much of the learning part, but what about, because it's huge. - Yeah, yeah. - There's trillions of sets.
So do you have any idea it's just a database problem? - So I don't know if I'm allowed to say this exactly, actually. But so one of the biggest chip manufacturers that recently, their stock has done really well, they have some dedicated retrieval hardware coming out. I think sooner it might already be out.
So yeah, very efficient dense retrieval is a very big business. Other questions? - That's the thing. Like, have you been solving the flag that will solve this issue with that? Similar thing in the business? - Yes, I think so, if you take it to the extreme. So one of the big problems right now is that if you contextualize an existing language model that already hallucinates, then it's gonna be kind of hard to get rid of the hallucination, right?
So if you do replug on GPT-4, GPT-4 might still hallucinate. So it could basically just ignore all the stuff you retrieved and just do whatever it wants anyway. So that's one of the reasons why you want to train the system end-to-end. And if you take that to the extreme where, like I said, right, if you can just have the language model only reason and speak, so it knows English and reasoning, but it has no knowledge, which all comes from somewhere else, then you can't hallucinate.
So it's really all grounded in whatever is in your index. But so they're about hallucination. I'm sort of frustrated that a lot of people in the field misunderstand what hallucination even means, right? So a lot of people are conflating hallucination with correctness or incorrectness. So they're like, oh, the model made a mistake.
It hallucinated. It's like, no, we've made a mistake. That's different from hallucination. Hallucination, I think is very specific kind of, I've retrieved something. So I have some sort of counterfactual ground truth. And what I'm saying does not correspond to that ground truth. And so, yeah, I think there's a bunch of folks at Stanford also working on better measurements of hallucination and definitions and things like that.
- If I'm understanding correctly, then your definition of hallucination only makes sense in a context with people. - Yeah, of some ground truth, right? So hallucination is really like, there is something that is true, right? So if we're talking about like hallucination and, yeah, so if we're talking about just general parametric language models, then sort of the ground truth is whatever we consider to be true, right?
But we had to work for like language models making mistakes before it was called making mistakes. - Yeah, on the ground truth, I guess this is solving the hallucination question I was looking for that path. Are you working on ground truth per se? And so, you know, if I generate the building documents saying, "Oh, well, I've never been a president," then everything falls apart.
Are you considering work on that, on this ground truth? - Yeah, so I like the sort of silo mentioned there as well. So I think the whole point is that you can have different indices and different definitions of ground truth, right? So I think you could say, "I only trust the archive," or, "I only trust like peer-reviewed papers "and not just archive." And so you can make decisions in your architecture during test time about what you define as ground truth.
And I also think actually that, and there's a bunch of work, I think, happening on this right now. You can control for how grounded you want it to be in your ground truth. So that's another kind of misconception about hallucinations. Like sometimes hallucinations are actually good, right? If you have a creative writing assistant and you wanted to come up with some cool new ideas, you want the language model to hallucinate.
So I think what you want to have is kind of a tunable knob where you say like, "Oh, now you can hallucinate, "and now maybe you should really tell me the truth only." Anything else? - It has, I think, a lot of gravity that's already on to it, how much you're saying.
(indistinct) - Yeah. So, but the temperature, that's just about how you sample, right? So how flat your distribution is that you sample from. (indistinct) Yeah. Yes. So even if you have a low temperature, it can still come up with random stuff, right? So it just says that then you're very likely to do greedy sampling.
So I think what you want to get at is something more sophisticated than that. - Okay, lots of interesting questions. - Yeah, I like the question. - Thanks, Don, again, for the great talk. - Thank you. (upbeat music)