Live coding 17
Chapters
0:0 1 - Setting up Paperspace - Clone fastai/paperspace-setup2:30 pipi fastai & pipi -U fastai
3:43 Installing universal-ctags: mambai universal-ctags
5:0 Next step: Adding a normalization to TIMM models
6:6 Oh! First lets fix pre-run.sh
7:35 Normalization in vision_learner (with same pretrained model statistics)
9:40 Adding TIMM models
13:10 model.default_cfg() to get TIMM model statistics
16:0 Lets go to _add_norm()… adding _timm_norm()
20:30 Test and debugging
28:40 Doing some redesign
32:23 Applying redesign for TIMM
36:20 create_timm_model and TimmBody
38:12 Check default config from a TIMM models
39:5 Making create_unet_model work with TIMM
40:20 Basic idea of U-nets
41:25 Dynamic U-net
Transcript
OK. All right, so this is the repo fastai paper space setup. I've started a machine. I'll see to my home directory. I'll get flown the repo. I'll CD into the thing I get cloned. I'll run dot slash setup dot sh. OK, and it says install complete. Please start a new instance.
So then I'll stop the machine. And then I'll start a machine. And that's going to install a pre run dot sh script, which is going to set up all these things and all these things. And it's going to install a dot bash dot local script, which will set up our path.
It's going to also install things and set up things for installing software pip I for pip install and mamba I for mamba install. So we now have a machine running. And so we should now create a terminal. Just press terminal. Something's happening. Great. Try creating a terminal here then.
Okay, much better. All right, so in theory, if we look at our home directory. Oh, look at that. Well, this stuff is now similar to slash storage. So I should be able to get the latest version. I wonder if I can add a minus you to say upgrade. Yes, I can.
So that's how I get the latest version. And so that should have installed it locally. There it is. And, okay, so now if I create a notebook. Fast AI version. Look, that's a good start. Okay, next question. Can we install binaries. For example, universal CTX member. I remember install universal CTX.
Okay, so you see the nice thing about this is even all this persistent stuff we're installing, you know, all works on the free paper space as well. So we should now be able to check CTX. It works. And which one is it. And that is actually in our storage.
Oh, so I think we've done it. What do you guys think that simple enough. Good. All right. Good. Okay. So, next step is, I thought we might try to fix a. I don't know if you call it fixing a bug or maybe it's probably we could generously call it adding an enhancement to fast AI, which is to add normalization to Tim models.
So. Alright, so let's grab fast AI. Now, this is where. So when I get clone this. So let's get a notebooks. So slash notebooks is persistent on a particular machine. And I think this will not work, because I'm using SSH. Oh, it's already there. That's interesting. Oh, you know, so there's a bug in our script, which is I didn't pop D.
So let's fix that pre run SSH, I did a push D at the start. No pop D at the end. Okay, fixed. All right. No worries. That means. Okay, yes, we're actually in here. No worries. Alright, so let's restart this. And then I'll tell you about the bug we're fixing while we wait for it.
Okay, so. So normalization is where we subtract the means and divide by the standard deviation of each channel for vision. And that goes that's a transform called normalize. And we need to use the same standard deviation and mean that was used in the when the model was pre trained.
Because you don't there is, you know, so some people will normalize. So it's everything's between zero and one someone normalize so it's got a mean of zero and a standard deviation of one. So we need to make sure we use the same. You don't divide by the same thing to track the same thing.
So if you look at vision learner. Vision learner has a normalized parameter. And if it's true, then it will attempt to add the correct normalization. So if it's not a pre trained model, it doesn't do anything because it doesn't know what to normalize by. Otherwise, it's going to try and get the correct statistics from the models metadata.
So the models metadata is here, model underscore meta. And it's just a list of models with with metadata and the metadata. Yeah, stats. ImageNet stats. So the image that stats is the main and standard deviation of ImageNet, which I can't quite remember where that comes from, but that's something we import from somewhere.
So none of these are 10 models. And so that means currently 10 models aren't normalized. Now, Tim has its own stats. Not this, not this. One of the stuff in Tim I still haven't looked into, I actually haven't used this transforms factory. Maybe in fast AI 3, we should consider using more of this functionality from Tim.
There's like a configuration for them. I guess we can just try and find it. Actually, we forgot to edit this. Oops. My bad. It's letting me start the machine. Here we go. So we can just do this locally now. All right, so this happens in Vision Learner. And Tim is optional.
You don't have to use it. But if you do, then we have a create Tim model which you don't normally call yourself. Normally you just call Vision Learner and you pass in an architecture as a string, and if it's a string it will create a Tim model for you.
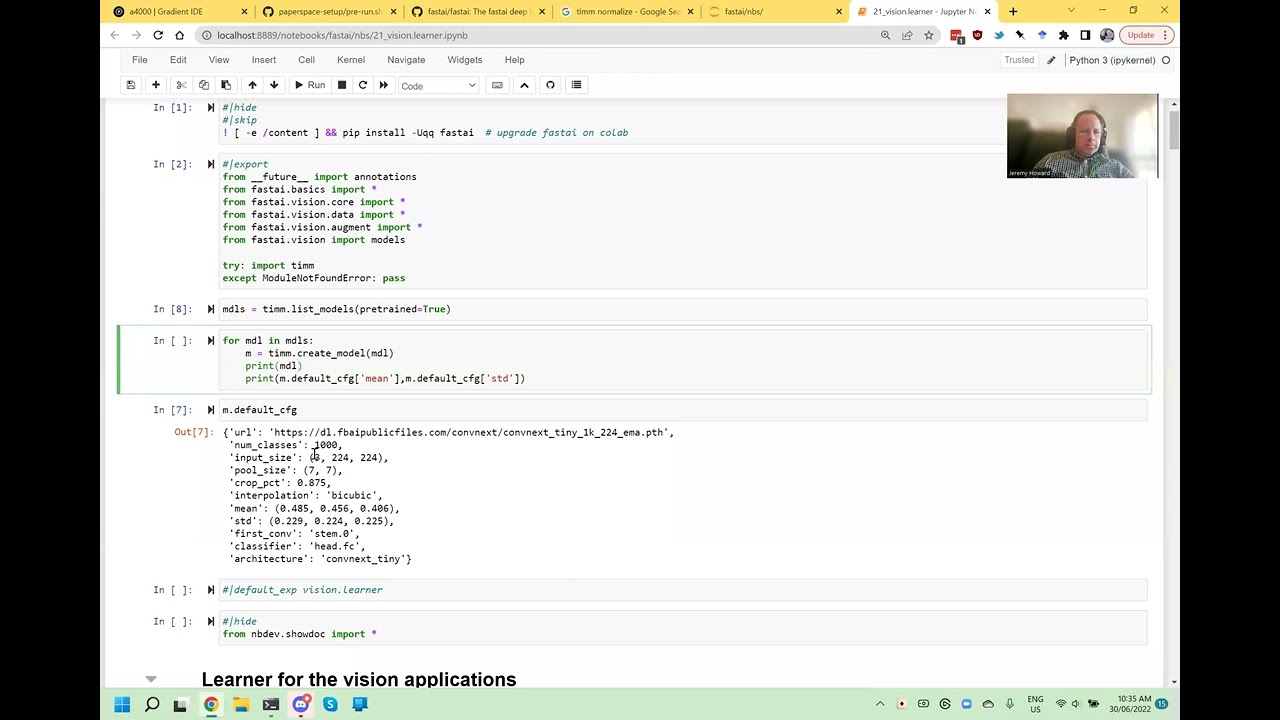
So this is the best models, for example. Let's say conf next or something like that. I don't know what kind of it is never tried that one. Let's do a tiny. So we can create a model using like create model, we pass in a string. And I have a feeling that's yeah, that's got a config.
Here we are. Yeah, see, and it's got a main and a standard deviation. So models equals Tim list models, maybe just to pre trained ones. So I wonder if they all have this for m in models. Create a model and have a look at m dot default config name instead of deviation.
Yeah, so you can see a lot of them use point five. And then some of these image stats. And I'm guessing they're the only two options. So, okay, so hopefully you get the idea. Jimmy just heard out, usually putting the image in the mean should be zero and standard deviation should be one.
I mean, not necessarily, sometimes people make the minimum zero in the maximum one. But what we need to do is use the same stats that it was pre trained with. Because we want our range to to be the same as the range is pre trained with otherwise our, you know, data has a different meaning.
So, so let's go to add norm. So here's add norm, and it's being passed a meta stats. So, this only works for non team. So how about we put this here, we'll create an else, or I guess really an elif. And here, we'll have for Tim, if normalize, we could have a team normalize and refactor out some duplicate code later.
But basically, for Tim, we're going to be passing in the architecture. We don't need to pass in the architecture we can just pass in the model. And to protect against future like ability to pass in other types that are strings that aren't Tim do you think there's any benefit having like default normalization function that if you pass through, you can actually do your own normalization.
No, because my answer to all of those questions is always, you ain't going to need it. So I very intentionally don't do like, you know, dealing with things that may or may not happen in the future. It'd be simpler just to create your own vision liner, because that looks like there's not much going on there that you can duplicate if you wanted to have support for a different model.
Yeah, yeah, exactly. I mean, it's, you know, this is just a small little wrapper really you can call create Tim model or create vision model, you can call that you can call create head. Yep. Okay, so we'll call that. So the normalize takes a mean and a standard deviation.
So, it should be just those two things I guess like so Okay. Tim normalize using the model and pre trade. I see already had an else there. There we go. And, okay, so let's test this out. So what happens when you add a transform as a transform to each data loader in it.
Okay. So what does that do. What did I do wrong. Oh, it's part of, I see. It's part of Okay, that's a bit confusing. Right. Okay, so let's find sometimes it's just easiest to look at the code. Chuffins. I see. So it's just calling add. I see for this particular event, and we're adding it I see we're adding it to the after batch event.
So, we should find there's a after batch event here we are. I see and there's our transforms. So if we call vision learner. That should change our data loader. Yep. And it's now got normalize using the ImageNet stats. And if we now try it for a string version. No, no, that's interesting.
Okay. Now what happened differently. Oh, I see. We need to recreate the data loaders for this test. So that doesn't have normalize anymore. And that gives us okay that gives us an error. And that's because it says we're passing a sequential object. Okay, that makes sense. Because create Tim model.
Actually. Modifies things. That's why. And it creates a sequential model, because it's got the head and the body in it. So we need to change how we do this. All right, this is Tim body here is the model. Oh, look, here we use default config to get stuff here.
Interesting. So Tim body is called from here. I guess like it would be nice to know how Tim does this exactly. Where does that default config come from. So, when we call Tim create model set layer config. I wonder if we should take a look at the default config, we're going to be a lot is data conflict up high.
So where does it get set. Maybe bottles help us. Your bottle with config. Well, seems like this but it's restructuring. It's not surprising it was originally built not to expect to be doing stuff with Tim. Create vision model. Close create body and create body. Here this is where it creates the model.
So maybe we should change how these work. So let's do so much we think about doing some redesign maybe. And so the idea of the redesign I guess would be that this doesn't instantiate the model. So we would remove that case that's now not going to work of course, so then we're creating body with model.
Okay. And so then we have to instantiate that. So we may as well just do that directly right. Okay. And the function. So it's new on each time. Okay, so in this refactoring. We now passing around models, not architectures. Great head won't change. The model meta stuff doesn't change.
Okay, so this changes. So now we say model equals pre trained passing model. Okay, it looks hopeful. So we're going to do the same thing for Tim. We're going to pass in a model. So it's going to be the same here. Model. Let's see if vision minus still works.
It does. So maybe we should move keep moving this back further and further. So to make Tim work. Do that. And this is kind of like the body. Maybe we'll just call that the Tim model, Tim model. Okay. Problem with that is the keyword arguments. So there's a lot of this is this gets a bit crazy.
There's a lot of keyword arguments when you create a model and the ones we don't know about we pass on to. So I think actually what we'll do is we'll do it up here. And so Tim body doesn't need quags anymore. And what we might do is we'll say this is the result.
And we'll return the things or even return those two things. So now we've got the config. And so we can pass the config. Like this. Like so. Let's see how much we just broke. Okay, so create Tim model. Yes, we do pass in an architecture after all. It looks hopeful.
So we should find that if we create a config. And check its default config. Yep, that looks good. Now come next tiny on the other hand uses image net stats. Like such. That looks very hopeful. So if somebody feels like an interesting and valuable problem to solve. Making create unit model work with Tim would be super helpful.
All right now create unit model. Needs to do the same thing. As create vision model, which is to actually instantiate the model. Is anybody potentially interested in having a go at doing unit models with Tim. If so, did you want to talk about it. I'd be interested. Okay. So, All right, let's just get this working first.
All right. Are you somewhat familiar with using units. In general and dynamic unit. A little bit. I'm training one at the moment. That's my maximum experience and then I've been through some notebooks to walk through. I wanted everything. Great. So, okay, so the interesting. Okay, so you know the basic idea of a unit is that it has not just the usual kind of Downward sampling path where the image is getting kind of effectively smaller and smaller as it goes through convolutions with strides.
And we end up with, you know, a kind of a very small set of patches and then rather than averaging those to get a vector and using those as our features for our head. Instead we go through reverse convolutions, which are things which make it bigger and bigger. And when we do that, we also don't just take the input from the previous layer of the up sampling, but also the input from the equivalently sized down sampling size down sampling there before fastai all units had to be only handled a fixed size.
So what Karim did was he created this thing called the dynamic unit, which would look to see how big each size was on the downward path and automatically create an appropriate size thing on the upward path. And that's what the dynamic unit does. So fastai has been very aggressive in like using pre trained models everywhere so something we added to this idea is this idea that the downward sampling path can be can have a pre trained model, which is not rocket science.
Obviously it's like this this one line of code. The So to understand like at the moment I'm using say like a ResNet 34 does that mean the down part is a ResNet 34 backbone and then there's a reverse ResNet 34 being automatically generated. It's not a reverse. It's not a reverse ResNet 34.
It's, it is a ResNet 34 backbone. So here's our dynamic unit, the upward sample, the up sampling path is has a fixed architecture, which is they are indeed res blocks. But they're not like if you use as a downward sampling path, you know, down sampling a VIP, the upward sampling is not going to be a reverse VIP.
It's not a mirror. No, exactly. It would there be an advantage in doing that or is it just not really helpful? I don't see why there would be. I'd also don't see why there wouldn't be. Nobody's tried it as far as I know. I don't even know if there's such a thing as an up sampling transformer block.
There may well be without digressing. There's no need to worry about that. The key thing is that in the downward sampling path, what we do is we we have the down sampling bit we call the encoder. OK. And what we do is we do a dummy eval. Now a dummy eval is basically to take a I can't remember like either a zero length batch or a one length batch like a very small batch and pass it through at some image size.
And we use I believe we use hooks, if I remember correctly. What's happened to my screen? My screen's gone crazy. OK. Yeah. So we've got these hooks. That are PyTorch hooks. Yes. OK. So we use fast AI's hook outputs function, which says I want to use PyTorch hooks to grab the outputs of these layers.
And so what is SCCCHG indexes? So this is yeah. OK. So that's a great question. So this is the indices of this is the key thing. This is the indices of the layers where the size changes. And so that's where you want the that's where you want the cross connection.
Right. Either just before that or just after that, you know. So get get get the indices with the size changes. So the sizes here model sizes. So we hook outputs. We do a dummy eval and we find the shape of each thing. And so here you can see dummy eval is using just a single image.
And so, yeah, this just returns the shape of the output of every layer. That's going to be in sizes. And so then this is just a very simple function which just goes through and finds where the size changes. OK. And so this is the indices of those things. So now that we know where the size changes, we know where we want our cross connections to be.
Now, for each of the cross connections, we need to store the output of the model at that point, because that's that's going to be an input in the up sampling block. So these sfs for each unit block we create. So for each change in the index for each up sampling block, you have to pass in that that those outputs in sampling sides.
This is the index where it happened. And so this will be the actual. So if we go to the unit block and it looks like it's so it's the size of that list minus one. Is that how the unit blocks get created on the other side? So it's going to be past the hook.
Right. Which is and so that that's just the hook that was used. That's the hook that was used on the down sampling side. And from that, we can get the stored activations. And so those stored activations then. So this is the shape of those stored activations. And this is a minor tweak.
So let's just ignore this if block for a moment. Basically, all we then do is we take those activations taken through a batch norm, concatenate them with the previous layers up sampling and chuck that through a ReLU. And then we do some comms. And the comms aren't just comms.
They're first AI comms, which can include all kinds of things like batch norm activation, whatever. So it's it's a some combination of batch norm, activation, convolution. You can you can also do up sampling. So it's transpose, batch norm can go first or last, whatever. So that's quite a, you know, a very rich conv convolutional layer.
Okay, so then this if part here is that it's possible that things didn't quite round off nicely so that the cross connection doesn't quite have the right size. And if that happens, then we'll interpolate the cross connection to be the same shape as the up sampling connection. And again, I don't know if anybody else does this, but this is to try to make it so that the dynamic unit always just works.
That's the basic idea. So to make this work for Tim, you know, this encoder needs to know about the spots, right? Oh, no, in order to text the spots. So honestly, this this might almost just work. Like I don't like I don't think it does. I think somebody tried it and it didn't.
Right. But, yeah, it would, you know, to figure out what doesn't work, you know, you would need to change this line to say, oh, if it's a string create trim model, otherwise do this, you know. And then you like create body would need to be create team team body if it's a string so like at minimum do the same stuff that create vision model does.
And then, yeah, and then see if this works. Right. Well, now, I will say, if you do get it working, Tim does have an API to actually tell you where the feature sizes change. So like you could actually optimize out that dummy eval stuff but I don't even know if I'd bother because it makes the code more complex for no particular benefit.
Yeah, sure. So, look, I think if you know this you commit this is a PR I'll definitely be looking at it. I was actually going to try Conf Next in my unit so I had no idea it wouldn't work actually. So that would have been I would have noticed that already but I just haven't had time.
So I'd love to because I, you know, resident 32 I've got particular results and I'd like to see if we can push it with a different model. Yeah, no, I mean I think there'd be a lot of benefit to that. So, all right. So now we should run the tests.
Just to just to know would that all likely be in the same notebook that you're editing the vision letter is that when most of the source code is unit learners, or is it a different. I don't know I was just using this right now jump jump to whatever automatically in VIM so I was using VMC tags to jump around, so I don't, I have no idea where I was.
I mean, actually. So yeah, so there's a models unit is where the dynamic unit lives. Okay, is there anything unique about the fact that the team model doesn't that's sort of an option there to cut the tail and head off. Does that need to be done with the unit architecture.
Oh, got an error here. Yeah, so yeah, you absolutely have to cut the head off, because it comes with a default classifier head. So you will need, you know. So you know you, once you get it working, you'll probably find you can factor out some duplicate code between the unit and the vision letter.
But yeah, you basically have to cut off the classifier head in the same way that create him body does. And I don't think you'll need to change any input processing as far as I know. The, the vision, create vision model, you know, handles, like, you know, if you've only got one or two or four channel inputs in the models of three channel input it handles that automatically but Tim actually, I think, Ross and I independently could enter this as far as I know we both kind of automatically handle like copying weights if necessary or deleting weights if necessary or whatever but yeah so the same stuff and vision minus should should work there as well.
So interestingly layers, the layers notebook doesn't work because it's, it's actually creating a model, which is curious. That we easily fixed. Yeah, that's interesting. Okay. So, the big question then is, can we still predict race disease. So let's compare. I don't know if it's going to make much difference or not, you know, because we're pretty careful about fine tuning the batch normally is actually interesting to see whether normalization matters as much as it used to.
It used to be absolutely critical. Is it possible to create like a layer that learns the normalization sort of thing. Yeah, I mean that's basically what batch norm does, you know, understand it's a those weights in the bachelor layer basically learning the aggregate of that batch that optimally give the best activations for the next.
Yeah, exactly. Yeah, yeah, it's just, it's just, you know, multiply by something and add something. So it's finding what's the best thing to multiply by an ad by. So, let's take a look. So I mean, all right, so this got 47% error. It's got 44% error. Yeah, so I mean, it's a bit disappointing after all that work it doesn't actually.
I mean this is fascinating, like, yeah, when you find you in the way we do. Basically doesn't really matter, you know. And let's just double check it actually is. It actually is working. Would it be fair to say that the one advantage would be if you wanted to use pre trained models without fine tuning you definitely want the statistics in there right.
Yes, absolutely. I mean I don't know if that's an actual thing that people do. Yes, if you did. Alright so we did deals train after batch. Yep, there it is. Groovy. Yeah, it's funny these things that, you know, we've been doing for years and I guess never question. I have a question relating to that because one of the things I wanted to do is get this unit into a mobile app so use the latest torch script, and it works with the demo app to fill around the locks is broken from pytorch.
But of course in there you need to provide the the averaging statistics for the app, so it's like inference mode. So I wonder, I know that at the moment, the first day eyes kind of idea is that you dump everything is like a pickle that conceivably would be helpful if you could maybe extract those new fine tuned statistics or something for your deployment in particular environments, because that, how would I go about doing that.
I mean, they're just parameters and batch nom layers, you know, they're just parameters. So there'll be in the parameters attribute of the model. But like they're not, they're not really parameters that make sense independently of all the other parameters at all. So I don't think you would treat them any differently.
If you use say image nets statistics when you're fine tuning and that's the result of your model right you're going to use that down the track as well. Well, yes and no, like that's what you normalize with, but, but you've got batch norm layers which then, obviously, dividing and subtracting themselves.
So yeah, I mean, you're those normalization stats aren't going to change but there isn't really any reason to, you know, it would only be if you trained a new model from scratch. So I'm going to have a look at this next one. So this is 27 to 18, 24.
Yeah, this is actually kind of what I thought might happen is on a slightly better model, you know, we may be getting slightly better errors initially. And then as it trains a bit. Makes no difference. Cool. All right, so. Yeah, I'd love people to try out fast AI from master because tell me if any of your models look substantially better or even more important substantially worse.
Auto normalize, Tim models. Okay. Sixes 3716. All right, anybody have any questions before we wrap it up. Just with normalize. It's just the initial, it will be a bit more or less than earlier. Yeah, so like that, that, that, you know, well, we have a random head. So at first it doesn't actually matter right it randoms random whether you normalize or not.
So, maybe you know the after 10 batches. It's better or something. But, yeah, I don't know, like, it would be interesting to see if anybody notices a difference. I mean, it's just this used to matter a lot right for a couple of reasons. One is that most people didn't find in models most people train most models and scratch until, until fast AI came along, pretty much.
And then secondly, well we didn't have batch norm. Right, so it was totally critical. And then even when batch norm came along we didn't know how to find your models with batch norm. So we just fine tuned the head. At that point, we didn't realize that you had to fine tune the batch norm layers as well.
So I remember emailing Francois the creator of Keras and I was saying to him like I'm trying to fine tune your Keras model and it's like, bizarrely bad like why why is that well probably doing the wrong thing here's documentation whatever like no I'm pretty sure I'm doing the right thing and I spent like three months trying to answer this question.
Eventually I realized it's like, holy shit, it's the batch norm layers. I sent him an email and said, oh, we can't fine tune Keras models like this actually have to fine tune batch norm layers, which I don't think they changed for years. Actually. Anyway, so those there so those changes is why I guess this whole normalization layer thing is much less interesting than I guess we thought, which is why we hadn't really noticed it wasn't working before.
Because our models are training fine. Anybody else have any questions before we wrap up. Okay. See you. Let's see well, good luck with unit.