An overview of fastai2
Chapters
0:04:28 An infinitely customizable training loop
10:46 optimizer with pluggable stats and steppers
13:24 Image classification
26:25 provides the basic features needed for working with model inputs
Transcript
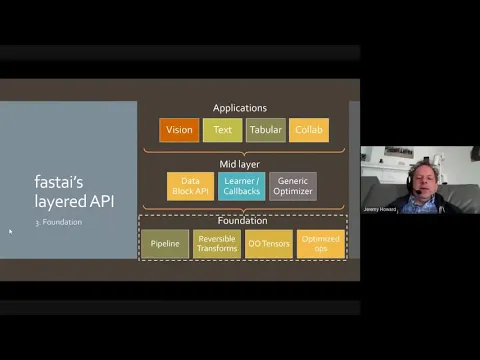
basically every time Sylvain and I found something that didn't quite work the way we wanted it at any part of the stack, we wrote our own. So it's kind of like building something with no particular deadline and trying to do everything the very very best we can. So the layered API of Fast AI v2 starts at the applications layer which is where most beginners will start and it looks a lot like Fast AI v1 which is the released version of the software that people have seen before, but v2 everything is rewritten from scratch, it's totally new, there's no code borrowed, but the top level API looks quite similar.
The idea is that in one, two, three, four lines of code you can create a state-of-the-art computer vision classifier, including transfer learning, with nearly the same one, two, three, four lines of code, oh five lines of code in this case because we're also displaying, you can create a state-of-the-art segmentation model and actually like when I say state-of-the-art like for example this segmentation model is to the best of my knowledge still better than any published result on this particular Canvit data set.
So like these five lines of code are super good, five lines of code and as you can see it includes a line of code which if you say show batch it will display your data in an appropriate format, in this case showing you segmentation, a picture and the color coded pixels overlaid on top of the picture.
The same basic four lines of code will do text classification, so here's the basis of ULMFIT which is a system that we developed and wrote up along with Sebastian Ruder for transfer learning in natural language processing and as you can see in here this is working on IMDB on a single epoch in four minutes, the accuracy here is basically what was the state-of-the-art as of a couple of years ago.
Tabular or time series analysis, same deal, basically a few lines of code, nearly exactly the same lines of code and you'll get a great result from your tabular data and Ditto for collaborative filtering. So the high-level API for fast AIV2 is designed to be something where you know regardless of what application you're working on you can get a great result from it using sensible defaults and carefully selected hyper parameters automatically largely done for you for the most common kinds of problems that people look at and that bit doesn't look that different to V1 but understanding how we get to that is kind of interesting and involves getting deeper and deeper.
This approach though does work super well and partly it's because this is based on quite a few years of research to figure out what are the best ways to solve various problems along the way and when people actually try using fast AI they're often surprised. So this person posted on our forum that they've been working in TF2 for a while and for some reason they couldn't figure out all of their models are suddenly working much better and the answer is basically they're getting all these nice kind of curated best practices and somebody else on Twitter saw that and said yep we found the same thing we were trying TensorFlow spent months tweaking and then we switched to fast AI a couple of days later we were getting better results.
So these kind of carefully curated defaults and algorithms and high-level APIs that do things right for you the first time even for experienced practitioners can give you better results faster but it's actually the other pieces that are more I think interesting for a Swift conversation because as the deeper we go into how we make that work the more stuff you'll see which will be a great fit I think with Swift.
So the mid-layer API is something which is largely new to fast - actually I guess the foundation layer is new. So the mid-layer I guess I'd say is more rewritten for v1 and it contains some of the things that make those high-level APIs easy. One of the bits which is the most interesting is the training loop itself and I thank Sylvain for the set of slides we have for the training loop.
This is what a training loop looks like in PyTorch. We calculate some predictions we get a loss we do a backwards pass to get the gradients we do an optimizer step and then optionally we run time to time we'll zero the gradients based on if we're doing when we're accumulating.
So this is what that loop looks like run the model get the loss do the gradients step the optimizer do that a bunch of times. But you want to do something interesting you'll need to add something to the loop to do keeping track of your training statistics in in tensorboard or in fast progress or whatever.
You might want to schedule various hyper parameters in various different ways. You might want to add various different kinds of characterization. You may want to do mixed precision training. You may want to do GANs. So this is a problem because either you have to write a new training loop for every time you want to add a different tweak.
Now making all those tweaks work together then becomes incredibly complicated. Or each or you try and write one training loop which does everything you can think of. This is the training loop for fast AI 0.7 which only did a tiny subset of the things I just said that was ridiculous.
Or you can add callbacks at each step. Now the idea of callbacks has been around in deep learning for a long time, APIs. But what's very different about fast AI is that every callback is actually a two-way callback. It can read absolutely everything. It can read gradients, parameters, data, so forth.
And it can write them. So it can actually change anything at any time. So the callbacks we say infinitely flexible. We feel pretty confident in that because the training loop in fast AI has not needed to be modified to do any of the tweaks that I showed you before.
So even the entirety of training GANs can be done in a callback. So basically we switch out our basic training loop and replace it with one with the same five steps but callbacks between every step. So that means for example if you want to do a scheduler you can define a batch begin that sets the optimizer's learning rate to some function.
Or if you want to do early stopping you can write an on epoch end that checks the metrics and stops training. Or you can do parallel training, set up data parallel and happy at the end of training take data parallel off again. Gradient clipping, you have access to the parameters themselves so you can click the gradient norms at the end of the backward step and so forth.
So all of these different things are all things that have been written with fast AI callbacks including for example mixed precision all of NVIDIA's recommendations mixed precision training will be added automatically if you just add a to FP16 at the end of your learn call. And really importantly you know for example all of those mixed precision things can be combined with multi GPU and one cycle training and gradient accumulation and so forth.
And so trying to you know create a state-of-the-art model which involves combining state-of-the-art regularization and mixed precision and distributed training and so forth is a really really really hard job. But with this approach it's actually just a single extra line of code to add each feature and they all explicitly are designed to work with each other and are tested to work with each other.
So for instance here is mixup data augmentation which is a incredibly powerful data augmentation method that has powered lots of state-of-the-art results and as you can see it's well under a screen of code. By comparison here is the version of mixup from the paper not only is it far longer but it only works with one particular data set and one particular optimizer and is full of all kinds of assumptions and only one particular kind of metric and so forth.
So that's an example of these mid-tier APIs. Another one is the optimizer. It turns out that you know it looks like there's been lots and lots of different optimizers appearing in the last year or two. It actually turns out that they're all minor tweaks on each other. Most libraries don't write them this way.
So for example Adam W, also known as decoupled weight decay Adam, was added to PyTorch quite recently in the last month or two and it required writing a whole new class and a whole new step to implement and it took you know it was like two or three years after the paper was released.
On the other hand fast AI's implementation as you can see involves a single extra function containing two lines of code and this little bit of gray here. So it's kind of like two and a half three lines of code to implement the same thing because what we did was we realized let's refactor the idea of an optimizer, see what's different for each of these you know state-of-the-art optimizers that have appeared recently and make it so that each of those things can be added and removed by just changing two things.
Stats and steppers. A stat is something that you measure during training such as the gradients or the gradient squared or you might use dampening or momentum or whatever and then a stepper is something that uses those stats to change the weights in some way and you can combine those things together and by combining these we've been able to implement all these different optimizers.
So for instance the lamb optimizer which came out of Google and was super cool at reducing tree training time from three days to 76 minutes we were able to implement that in this tiny piece of code and one of the nice things is that when you compare it to the math it really looks almost line for line identical except ours is a little bit nicer because we refactored some of the math.
So it like makes it really easy to do research as well because you can kind of quite directly bring the equations across into your code. Then the last of the mid-tier APIs is the data block API which is something we had in version 1 as well but when we were porting that to Swift we had an opportunity to rethink it and actually Alexis Gallagher in particular helped us to rethink it in a more idiomatic Swifty way and it came out really nicely and so then we took the result of that and kind of ported it back into Python and we ended up with something that was quite a bit nicer so there's been a kind of a nice interaction and interplay between fast AI in Python and Swift AI in Swift in terms of helping each other's APIs but basically the data block API is something where you define each of the key things that the program needs to know to flexibly get your data into a form you can put in a model so it needs to know what type of data do you have how do you get that data how do you split it into a training set in the validation set and then put that all together into a data bunch which is just a simple little class it's literally I think four lines of code which just has the validation set and the training set in one place so with a data block you just say okay my types I want to create a black and white pillow image for my X and a category for my Y and to get the list of files for those I need to use this function and to split those files into training and validation use this function which is looking at the grandparent path directory name and to get the labels use this function which is use the parents path name and so with that that's enough to give you a feminist for instance and so once you've done this you end up with a data bunch and as I mentioned before everything has a show batch so one of the nice things is it makes it very easy for you to look at your data regardless of whether it's tabular or collaborative filtering or vision or text or even audio if it was audio would let you show you a spectrogram and let you play play the sound so you can do custom labeling with data blocks by using for example a regular expression labeler you can get your labels from an external file or data frame and they could be model with multi labels so this thing here knows it's a multi label classification task so it's automatically put the semicolon between each label again it's still basically just three lines of code to define the data block so here's a data block for segmentation and you can see really the only thing I had to change here was that my dependent variable has been changed in category to pillow mask and again automatically I show batchworks and we can train a model from that straight away as well you could do key points so here I've just changed my dependent variable to tensor point and so now it knows how to behave with that object detection so now change my dependent variable to bounding box and you can see I've got my bounding boxes here text and so forth so actually going back I have a couple questions if you're if it's okay yeah so it's if you the code you've got sort of the the X's and Y's and these both he sounds like these different data types roughly conform to a protocol yep we're gonna get to that in a moment absolutely that's an excellent way to think of it and actually this is the way it looked about three weeks ago it now it looks even more like a protocol so yes this is where this is what where it all comes from which is the foundation APIs and this is the bit that I think is the most relevant to Swift and a lot of this I think would be a lot easier to write in Swift so the first thing that we added to PyTorch was object-oriented tensors for for too long we've all been satisfied with a data type called tensor which has no semantics to it and so those tensors actually represent something like a sentence or a picture of a cat or recording of somebody saying something so why can't I take one of those tensors and say dot flip or dot rotate or dot resample or dot translate to German well the the answer is you can't because it's just a tensor without a type so we have added types to tensors so you can now have a tensor image tensor point tensor bounding box and you can define a flip left right for each and so this is some of the source code from we've written our own computer vision library so that now you can say flip LR and it flips the puppy and if it was a key points it would fit the key points it was a bounding box it would fit the bounding boxes and so forth so this is an example of how tensors which carry around semantics are nice it's also nice that I didn't just say dot show right so dot show is something that's defined for all fast a IV to tensor types and it will just display that tensor it could even be a tuple containing a tensor and some bounding boxes and some bounding box classes whatever it is it will be able to display it it will be able to convert it into batches for modeling and so forth so you know with with that we can now create for example a random transformation called flip item and we can say that the encoding of that random transformation is defined for a pillow image or any tensor type and in each case the implementation is simply to call X dot flip LR or we could do the dihedral symmetry transforms in the same way before we call grab a random number between zero and seven to the side which of the eight transposes to do and then encodes call X dot let's dihedral with that thing we just got and so now we can call that transform a bunch of times and each time we'll get back a different random augmentation so a lot of these things become nice and easy hey Jeremy some Maxim asked why isn't tensor backing data structure for an image type tensor image is a tensor which is an image type why is it he says why isn't tensor a backing what why not have a different type named image I guess that has a tensor inside of it do you mean why inherit rather than compose apparently yes that yeah so inheritance I mean you can do both and you can create identical API's inheritance just has the benefit that all the normal stuff you can do with a tensor you can do with a tensor that happens to be an image so just because a tensor is an image doesn't mean you now don't want to be able to do fancy indexing to it or do an LU composition of it or stack it with other chances across that axis so basically a tensor image ought to have all the behavior of a tensor plus additional behavior so that's why we used inheritance we have a version that uses composition as well and it uses Python's nice get atra functionality to pass on all of it all of the behavior of tensor but it comes up more nicely in Python when you do inheritance and actually the PyTorch team has decided to officially implement semantic tensor subtypes now and so hopefully in the next version of PyTorch you won't have to use the extremely ugly hacks that we had to use to make this work and hopefully you'll see in TorchVision some of these ideas will be brought over there.
So how does the type propagate? So if you do arithmetic on an image tensor do you get an image tensor back there? So Chris and I had a conversation about this a few months ago and I said I'm banging my head around this issue of types not carrying around their behavior and Chris casually mentioned oh yes that thing is called higher kind of types so I went home and that was one of these phrases that I thought only functional programming dweebs talked about and I would never care about it because it actually matters a lot and it's basically the idea that if you have a tensor image and you add one to it you want to get back a tensor image because it should be an image that's a bit brighter rather than something that loses its type.
So we implemented our own again hacky partial higher kind of type implementation in FastAIV2 so any of these things that you do to a tensor of a subtype you will nearly always get back the correctly sub-typed tensor. I mean I saw the PyTorch recently sort of talking about their named indexing extensions for their tensors as well and I think they have a similar kind of challenge there where when you start doing arithmetic and other things like that on tensor that has named dimensions you want to propagate those along.
Yeah so we haven't started using that yet because it hasn't quite landed as stable but yeah we talked to the PyTorch team at the DevCon and that we certainly are planning to bring these ideas together they're orthog and orbit related concerns. Yeah I just mean that I assume that that feature has the same problem and the same challenge.
I assume so. It would be interesting to see what they do. Yeah it would. Yeah so you know it's kind of nice not only do we get to be able to say .show batch but you can even go .show results and in this case it knows what the independent variables type is it knows what the dependent variables type is and it even knows things like hey for a classification task those two things should be the same and if they're not by default I will highlight them.
So these like lower level foundations are the things that drive our ability to easily add this higher level functionality. So you know this is the kind of ugly stuff we wouldn't have to do in Swift we had to write our own type dispatch system so that we can annotate things with types and those type annotations are actually semantic and so we now have the joyfully modern idea of function overloading in Python which has made life a lot easier and we already have that.
Do you have many users that are using this yet? It's still pre-release it's not even alpha but there is a enthusiastic early adopter community who is using it so for example the user contributed audio library has already been ported to it. I've also built a medical imaging library on top of it and have written a series of five notebooks showing how to do CT scan analysis with it so it's kind of like it works and I was curious what your users think of it because there's this very strongly held conception that Python folks hate types and you're kind of providing a little bit of typing.
Yeah and I'm curious how they react to that. The extremely biased subset of early adopter fast AI enthusiasts who are using it love it and they tend to be people who have gone pretty deep in the past so for example my friend Andrew Shaw who wrote something called music auto bot which is one of the coolest things in the world in case you haven't seen it yet which is something where you can generate music using a neural network you can put in some melodies and some chords and it will auto complete some additional melodies and chords or you can put it in a melody and it will automatically add chords or you can add chords that create melody and so he had to write his own MIDI library fastai.midi he rewrote it in v2 and he said it's just like so so so much easier thanks to those mid-tier APIs so yeah at this stage I was just gonna I was just gonna jump in quick I've been helping with some of the audio stuff and it's been it's been really awesome so it it makes things a lot more flexible than version one so that that's probably my favorite thing about it is everything can be interchanged nothing is like well it's got to be this way because that's how it is.
Another piece of the transform is the foundation is the partially reversible composed function pipeline dispatched over collections which really rolls off the tongue we call them transform and pipeline basically the idea is that the way you kind of want function dispatch to work and function composition to work in deep learning is a little different to other places there's a couple of things the first is you often want to dispatch over tuples now what I mean by that is if you have a function called flip left right and you have a tuple representing a mini batch where your independent variable is a picture and your dependent variable is a set of bounding boxes if you say flip left right on that tuple you would expect both the X and the Y to be flipped and to be flipped with the type appropriate method so our transforms will automatically send each element of a tuple to the function separately and or dispatch according to their types automatically we've mentioned type retention so the kind of basic higher type type stuff we need one interesting thing is not only encoding so in other words applying the function you often need to be able to decode which is to kind of de apply the function so for example a categorization transform would take the word dog and convert it to the number one perhaps which is what you need for modeling but then when your predictions come back you need to know what one represents so you need to reverse that transform and turn one back into dog often those transforms also need data driven set up for example in that example of dog becoming one there needs to be something that actually creates that vocab automatically recognizing what are all the possible classes so it can create a different index for each one and then apply that to the validation set and quite often these transforms also have some kind of state such as the vocab so we built this bunch of stuff that builds on top of each other at the lowest level is a class for transform which is a callable which also has a decode does the type retention high kind of type thing and does the dispatch over tuples by default so that the pipeline is something that does function composition over transforms and it knows about for example setting up transforms and like setting up transforms in a pipeline is a bit tricky because you have to make sure that at each level of the pipeline only the previous steps have been applied before you set up the next step so does little things like that and then we have something that applies a pipeline to a collection to give you an indexable lazily transformed collection and then you can do those in parallel to get back you know an independent dependent variable for instance and then finally we've built a data loader which will apply these things in parallel and create collated batches so in the end all this stuff makes a lot of things much easier for example the language model data loader in fast AI v1 was like pages of code in TensorFlow it's pages of code in fast AI v2 it's less than a screen of code by leveraging these it on these powerful abstractions and foundations so then finally and again this is something I think Swift will be great for we worked really hard to make everything extremely well optimized so for example pre-processing and natural language processing we created a parallel generator in in Python which you can then basically pass a class to the define some setup and a call and it can automatically paralyze that so for example tokenization is done in parallel in a pretty memory efficient way but perhaps the thing I'm most excited about both in Python and Swift is the optimized pipeline running on the GPU so all of the pretty much all of the transforms we've done can and and by default do run on the GPU so for example when you do the flip left right I showed you earlier will actually run on the GPU as well warp as well zoom as well even things like crop so one of the basics of this is the affine coordinate transform which uses affine grid and grid sample which are very powerful PyTorch functions which would be great things to actually write in script for TensorFlow's new meta programming because they don't exist in TensorFlow or at least not in any very complete way but with these with these basic ideas we can create this affine coordinate transform that lets us do a very wide range of data augmentations in parallel on the GPU for those of you that know about the DALI library that we've created this provides a lot of the same benefits of DALI it's pretty similar in terms of its performance but the nice thing is all the stuff you write you write it in Python not in CUDA so with DALI if they don't have the exact transformation you want and there's a pretty high chance that they won't then you're stuck or else with fast AI v2 you can write your own in a few lines of Python you can test it out in a Jupyter notebook it makes life super easy so this kind of stuff you know I feel like because Swift is you know a much faster more hackable language than than Python or at least hackable in the sense of performance I guess not as hackable in terms of its type system necessarily you know I feel like we can kind of build even more powerful foundations and pipelines and you know like a real Swift for TensorFlow computer vision library you know leveraging the metaprogramming and leveraging Swift numerics stuff like that I think would be super cool so