Lesson 1 - Deep Learning for Coders (2020)
Chapters
0:0 Introduction6:44 What you don’t need to do deep learning
8:38 What is the point of learning deep learning
9:52 Neural Nets: a brief history
16:0 Top to bottom learning approach
23:6 The software stack
39:6 Git Repositories
42:20 First practical exercise in Jupyter Notebook
48:0 Interpretation and explanation of the exercise
55:35 Stochastic Gradient Descent (SGD)
61:30 Consider how a model interacts with its environment
67:42 "doc" function and fastai framework documentation
76:20 Image Segmentation
77:34 Classifying a review's sentiment based on IMDB text reviews
78:30 Predicting salary based on tabular data from CSV
80:15 Lesson Summary
Transcript
So, hello everybody, and welcome to Deep Learning for Coders, lesson one. This is the fourth year that we've done this, but it's a very different and very special version for a number of reasons. The first reason it's different is because we are bringing it to you live from day number one of a complete shutdown, or not complete shutdown, but nearly complete shutdown of San Francisco.
We're going to be recording it over the next two months in the midst of this global pandemic. So if things seem a little crazy sometimes in this course, I apologize, but that's why this is happening. The other reason it's special is because we're trying to make this our kind of definitive version, right?
Since we've been doing this for a while now, we've actually finally gotten to the point where we almost feel like we know what we're talking about. To the point that Sylvain and I have actually written a book, and we've actually written a piece of software from scratch called the FastAI Library Version 2.
We've written a peer-reviewed paper about this library. So this is kind of designed to be like the version of the course that is hopefully going to last a while. The syllabus is based very closely on this book, right? So if you want to read along properly as you go, please buy it.
And I say please buy it because actually the whole thing is also available for free in the form of Jupyter Notebooks. And that is thanks to the huge generosity of O'Reilly Media who have let us do that. So you'll be able to see on the website for the course how to kind of access all this.
But here is the fast book repo where you can read the whole damn thing. At the moment, as you see, it's a draft, but by the time you see this, it won't be. So we have a big request here, which is the deal is this. You can read this thing for free as Jupyter Notebooks, but that is not as convenient as reading it on a Kindle or, you know, in a paper book or whatever.
So please don't turn this into a PDF, right? Please don't turn it into a form designed more for reading because kind of the whole point is that we hope, you know, that you'll buy it. Don't take advantage of O'Reilly's generosity by creating the thing that, you know, they're not giving you for free.
And that's actually explicitly the license under which we're providing this as well. So that's a, you know, it's mainly a request to being a decent human being. If you see somebody else not being a decent human being and stealing the book version of the book, please tell them, please don't do that.
It's not nice and don't be that person. So either way, you can read along with the syllabus in the book. There's a couple of different versions of these notebooks, right? Is the full notebook that has the entire prose, pictures, everything. Now we actually wrote a system to turn notebooks into a printed book, and sometimes that looks kind of weird.
For example, here's a weird-looking table, and if you look in the actual book, it actually looks like a proper table, right? So sometimes you'll see like little weird bits, okay? They're not mistakes. They're bits where we kind of add information to help our book turn into a proper, nice book.
So just, just ignore them. Now when I say "we", who is "we"? Well, I mentioned one important part of the "we" is Sylvain. Sylvain is my co-author of the book and the FastAI version 2 library. So he is my partner in crime here. The other key "we" here is Rachel Thomas.
And so maybe Rachel, you can come and say hello. She's the co-founder of FastAI. Hello. Yes, I'm the co-founder of FastAI. I'm also lower, sorry, taller than Jeremy. And I'm the founding director of the Center for Applied Data Ethics at the University of San Francisco. I'm really excited to be a part of this course, and I'll be the voice you hear asking questions from the forums.
Rachel and Sylvain are also the people in this group who actually understand math. I am a mere philosophy graduate. Rachel has a PhD. Sylvain has written 10 books about math. So if math questions come along, it's possible I may pass them along, but it's very nice to have an opportunity to work with people who understand this topic so well.
Yes, Rachel. Sure. Thank you. And as Rachel mentioned, the other area where she has real world-class expertise is data ethics. She is the founding director of the Center for Applied Data Ethics at the University of San Francisco. Thank you. We're going to be talking about data ethics throughout the course, because, well, we happen to think it's very important.
So for those parts, although I'll generally be presenting them, they will be on the whole based on Rachel's work, because she actually knows what she's talking about. Although thanks to her, I kind of know a bit about what I'm talking about, too. Right. So that's that. So should you be here?
Is there any point you're attempting to understand – let me press the right button – understand deep learning? Okay. So what do you – should you be here? Is there any point you're attempting to learn deep learning, or are you too stupid, or you don't have enough vast resources, or whatever?
Because that's what a lot of people are telling us. They're saying, you know, teams of PhDs and massive data centers full of GPUs, otherwise it's pointless. Don't worry, that is not at all true. It couldn't be further from the truth. In fact, the vast majority – so a lot of world-class research and world-class industry projects have come out of fast AI alumni and fast AI library-based projects, and elsewhere, which are created on a single GPU using a few dozen or a few hundred data points from people that have no graduate-level technical expertise, or in my case, I have no undergraduate-level technical expertise, I'm just a philosophy major.
So there is – and we'll see it throughout the course – but there is lots and lots and lots of clear empirical evidence that you don't need lots of math, you don't need lots of data, you don't need lots of expensive computers to do great stuff with deep learning.
So just bear with us, you'll be fine. To do this course, you do need to code. Preferably, you know how to code in Python, but if you've done other languages, you can learn Python. If the only languages you've done is something like Matlab, where you've used it more of kind of like a scripty kind of thing, you might find it a bit – you will find it a bit heavier going, but that's okay, stick with it, you can learn Python as you go.
Is there any point learning, deep learning, is it any good at stuff? If you are hoping to build a brain that is an AGI, I cannot promise we're going to help you with that. And AGI stands for artificial general intelligence. Thank you. What I can tell you though is that in all of these areas, deep learning is the best known approach to at least many versions of all of these things.
So it is not speculative at this point whether this is a useful tool. It's a useful tool in lots and lots and lots of places, extremely useful tool. And in many of these cases, it is equivalent to or better than human performance, at least according to some particular kind of narrow definition of things that humans do in these kinds of areas.
So deep learning is pretty amazing, and if you kind of want to pause the video here and have a look through and try and pick some things out that you think might look interesting, then type that keyword and deep learning into Google and you'll find lots of papers and examples and stuff like that.
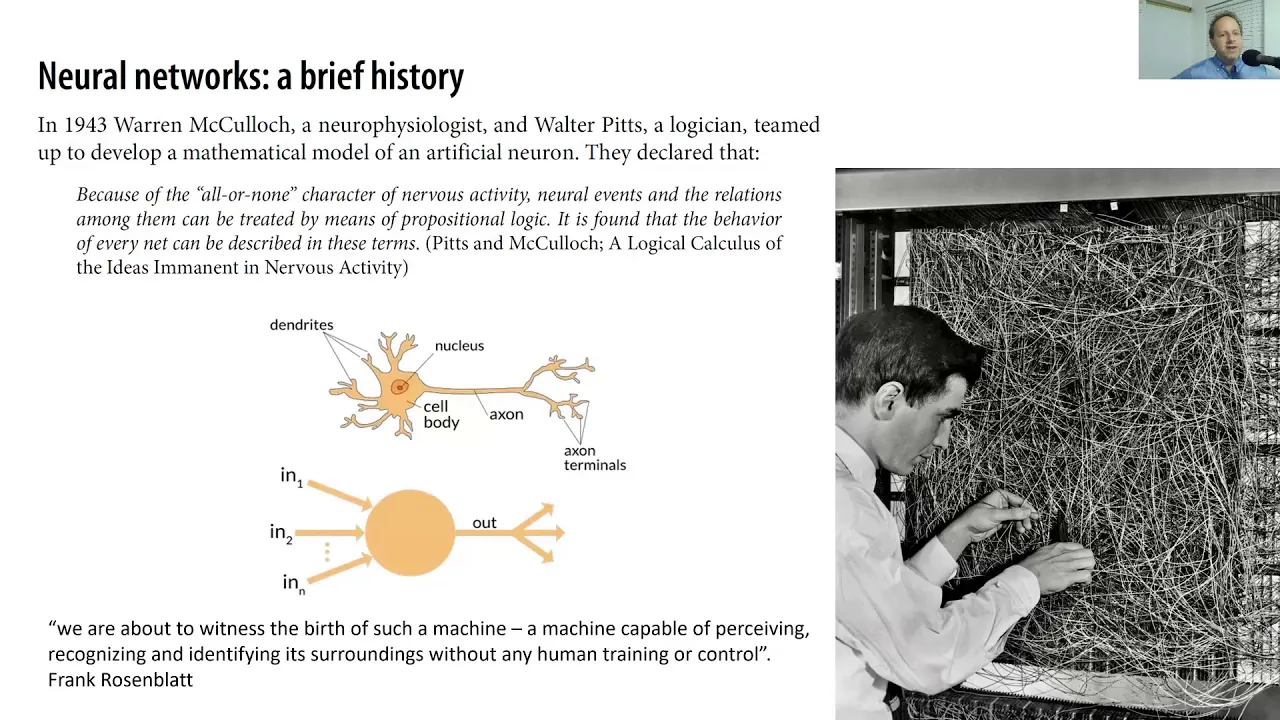
Deep learning comes from a background of neural networks, as you'll see, deep learning is just a type of neural network learning, a deep one, we'll describe exactly what that means later. And neural networks are certainly not a new thing, they go back at least in 1943 when McCulloch and Pitts created a mathematical model of an artificial neuron and got very excited about where that could get to.
And then in the 50s, Frank Rosenblatt then built on top of that, he basically created some subtle changes to that mathematical model, and he thought that with these subtle changes we could witness the birth of a machine that is capable of perceiving, recognizing, and identifying its surroundings without any human training or control.
And he oversaw the building of this extraordinary thing, the Mach 1 Perceptron at Cornell. So that was I think this picture was 1961. Thankfully nowadays we don't have to build neural networks by running the damn wires shown here on to neuron, artificial neuron to artificial neuron, but you can kind of see the idea, a lot of connections going on, and you'll hear the word connection a lot in this course because that's what it's all about.
Then we had the first AI winter as it was known, which really to a strong degree happened because an MIT professor named Marvin Minsky and Papert wrote a book called Perceptrons about Rosenblatt's invention, in which they pointed out that a single layer of these artificial neuron devices actually couldn't learn some critical things, it was like impossible for them to learn something as simple as the Boolean XOR operator.
In the same book, they showed that using multiple layers of the devices actually would fix the problem. People didn't notice that part of the book and only noticed the limitation, and people basically decided that neural networks were going to go nowhere, and they kind of largely disappeared for decades until, in some ways, 1986, a lot happened in the meantime, but there was a big thing in 1986 which is MIT released a thing called a book, a series of two volumes of book called parallel distributed processing, in which they described this thing they call parallel distributed processing, where you have a bunch of processing units that have some state of activation and some output function and some pattern of connectivity and some propagation rule and some activation rule and some learning rule operating in an environment, and then they described how things that met these requirements could, in theory, do all kinds of amazing work.
And this was the result of many, many researchers working together, the whole group involved in this project which resulted in this very, very important book. And so the interesting thing here to me is that as you go through this course, come back and have a look at this picture and you'll see we are doing exactly these things.
Something we're learning about really is how do you do each of these eight things, right? And it's interesting that they include the environment, because that's something which very often data scientists ignore, which is you build a model, you've trained it, it's learned something, what's the context it works in.
We'll be talking about that quite a bit over the next couple of lessons as well. So in the 80s, you know, during and after this was released, people started building in this second layer of neurons avoiding Minsky's problem. And in fact, it was shown that it was mathematically provable that by adding that one extra layer of neurons, it was enough to allow any mathematical model to be approximated to any level of accuracy with these neural networks.
And so that was like the exact opposite of the Minsky thing. That was like, hey, you know, there's nothing we can't do, provably there's nothing we can't do. And so that was kind of when I started getting involved in neural networks. So I was, a little bit later, I guess I was getting involved in the early 90s and they were very widely used in industry.
I was using them for the very boring things like targeted marketing for retail banks. You know, it tended to be big companies with lots of money that were using them. And it certainly though was true that often the networks were too big or slow to be useful. They were certainly useful for some things, but they, you know, they never felt to me like they were living up to the promise for some reason.
Now what I didn't know, and nobody I personally met knew, was that actually there were researchers that had showed 30 years ago that to get practical good performance, you need more layers of neurons. Even though mathematically, theoretically, you can get as accurate as you want with just one extra layer, to do it with good performance, you need more layers.
So when you add more layers to a neural network, you get deep learning. So deep doesn't mean anything like mystical. It just means more layers, more layers than just adding the one extra one. So thanks to that, neural nets are now living up to their potential as we saw in that like what's deep learning good at thing.
So we could now say that Rosenblatt was right. We have a machine that's capable of perceiving, recognizing and identifying its surroundings without any human training or control. That is, that's definitely true. I don't think there's anything controversial about that statement based on the current technology. So we're going to be learning how to do that.
We're going to be learning how to do that in exactly the opposite way of probably all of the other math and technical education you've had. We are not going to start with a two-hour lesson about the sigmoid function, or a study of linear algebra, or a refresher course on calculus.
And the reason for that is that people who study how to teach and learn have found that is not the right way to do it for most people. For most people, so we work a lot based on the work of Professor David Perkins from Harvard and others who work at similar things, who talk about this idea of playing the whole game.
And so playing the whole game is based on the sports analogy. If you're going to teach somebody baseball, you don't take them out into a classroom and start teaching them about the physics of a parabola and how to stitch a ball and a three-part history of a hundred years of baseball politics.
And then ten years later, you let them watch a game. And then twenty years later, you let them play a game. Which is kind of like how math education is being done. Instead, with baseball, step one is to say, "Hey, let's go and watch some baseball." What do you think?
That was fun, right? See that guy there? He's trying to run there before the other guy throws a ball over there? "Hey, you want to try having a hit?" "Okay, so you're going to hit the ball, and then I have to try and catch it, and then you have to run over there?" And so from step one, you are playing the whole game.
Yeah, and just to add to that, when people start, they're often may not have a full team or be playing a full nine innings, but they still have a sense of what the game is and kind of the big picture idea. Yeah. So there's lots and lots of reasons that this helps most human beings.
Not everybody, right? There's a small percentage of people who like to build things up from the foundations and the principles, and not surprisingly, they are massively overrepresented in a university setting because the people who get to be academics are the people who thrive with the kind of, to me, upside-down way that things are taught.
But outside of universities, most people learn best in this top-down way, where you start with the full context. So step number two in the seven principles, I'm only going to mention the first three, is to make the game worth playing, which is like, if you're playing baseball, you have a competition, you score, you try and win, you bring together teams from around the community and have people try to beat each other, and you have leaderboards of who's got the highest number of runs or whatever, right?
So this is all about making sure that the thing you're doing, you're doing it properly, you know? You're making it the whole thing, you're providing the context and the interest. So for the fast AI approach to learning deep learning, what this means is that today we're going to train models end-to-end, we're going to actually train models, right?
And they won't just be crappy models, they will be state-of-the-art world-class models from today. And we're going to try to have you build your own state-of-the-art world-class models from either today or next lesson, depending on how things go. Then number three in the seven principles from Harvard is work on the hard parts, which is kind of like this idea of practice.
Yeah, deliberate practice, right? Work on the hard parts means that you don't just swing a bat at a ball every time you go out and just muck around, but you train properly. You find the bit that you're the least good at, you figure out where the problems are, you work damn hard at it, right?
So in the deep learning context that means that we do not dumb things down, right? By the end of the course you will have done the calculus, you have done the linear algebra, you will have done the software engineering of the code, right? You will be practicing these things which are hard, so it requires tenacity and commitment, but hopefully you'll understand why it matters because before you start practicing something you'll know why you need that thing because you'll be using it, like to make your model better you'll have to understand that concept first.
So for those of you used to a traditional university environment, this is going to feel pretty weird and a lot of people say that they regret at, you know, after a year of studying fast AI that they spent too much time studying theory and not enough time training models and writing code.
That's the kind of like the number one piece of feedback we get of people who say I wish I had done things differently, it's that. So please try to as best as you can, since you're here, follow along with this approach. We are going to be using a kind of a software stack, sorry Victoria.
I just want to say one more thing about the approach. I think since so many of us spent so many years kind of with a traditional educational approach of bottom up that this can feel very uncomfortable at first, I still feel uncomfortable with it sometimes even though I'm committed to the idea and that some of it is also kind of having to catch yourself and be okay with not knowing the details which I think can feel very unfamiliar or even wrong when you're kind of new to that of like oh wait I'm using something and I don't understand every underlying detail but you kind of have to trust that we're going to get to those details later.
So I can't empathize because I did not spend lots of time doing that but I will tell you this, teaching this way is very, very, very hard. You know I very often find myself jumping back into a foundation's first approach because it's just so easy to be like oh you need to know this, you need to know this, you need to do this and then you can know this.
That's so much easier to teach so I do find this much, much more challenging to teach but hopefully it's worth it. We've spent a long, long time figuring out how to get deep learning into this format. One of the things that helps us here is the software we have available.
If you haven't used Python before it's ridiculously flexible and expressive and easy to use language. We have plenty of bits about it we don't love but on the whole we love the overall thing and we think it's, most importantly the vast, vast, vast majority of deep learning practitioners and researchers are using Python.
On top of Python there are two libraries that most folks are using today PyTorch and TensorFlow. There's been a very rapid change here, TensorFlow was what we were teaching until a couple of years ago, it's what everyone was using until a couple of years ago. It got super bogged down, basically TensorFlow got super bogged down.
There's other software called PyTorch came along that was much easier to use and much more useful to researchers and within the last 12 months the number, the percentage of papers at major conferences that uses PyTorch has gone from 20% to 80% and vice versa. Those that use TensorFlow have gone from 80% to 20%.
So basically all the folks that are actually building the technology we're all using are now using PyTorch and industry moves a bit more slowly but in the next year or two you'll probably see a similar thing in industry. Now the thing about PyTorch is it's super, super flexible and really is designed for flexibility and developer-friendliness, certainly not designed for beginner-friendliness and it's not designed for what we would say, it doesn't have like higher level APIs by which I mean there isn't really things to make it easy to build stuff quickly using PyTorch.
So to deal with that issue we have a library called FastAI that sits on top of PyTorch. FastAI is the most popular higher level API for PyTorch. That's how courses are so popular, some people are under the mistaken impression that FastAI is designed for beginners or for teaching. It is designed for beginners and teaching as well as practitioners in industry and researchers.
The way we do this, make sure that it's the best API for all of those people, is we use something called a layered API and so there's a peer-reviewed paper that Sylvain and I wrote that described how we did that and for those of you that are software engineers it will not be at all unusual or surprising, it's just totally standard software engineering practices but they were practices that were not followed in any deep learning library we had seen, just you know basically lots of refactoring and decoupling.
And so by using that approach it's allowed us to build something which you can do super low-level research, you can do state-of-the-art production models and you can do kind of super easy beginner but beginner world-class models. So that's the basic software stack, there's other pieces of software we'll be learning about along the way but the main thing I think to mention here is it actually doesn't matter.
If you learn this software stack and then at work you need to use TensorFlow and Keras say you'll be able to switch in less than a week, lots and lots of students have done that, it's never been a problem, the important thing is to learn the concepts and so we're going to focus on those concepts and by using an API which minimizes the amount of boilerplate you have to use it means you can focus on the bits that are important, the actual lines of code will correspond much more to the actual concepts you're implementing.
You are going to need a GPU machine, a GPU is a graphics processing unit and specifically you need an Nvidia GPU, other brands of GPU just aren't well supported by any deep learning libraries. Please don't buy one, even if you already have one you probably shouldn't use it, instead you should use one of the platforms that we have already got set up for you.
It's just a huge distraction to be spending your time doing like system administration on a GPU machine and installing drivers and blah blah blah right and run it on Linux please, that's what everybody's doing not just us, everybody's running it on Linux. Make life easy for yourself, it's hard enough to learn deep learning without having to do it in a way that you're learning all kinds of arcane hardware support issues.
There's a lot of free options available and so please use them. If you're using an option that's not free don't forget to shut down your instance. So what's going to be happening is you're going to be spinning up a server that lives somewhere else in the world and you're going to be connecting to it from your computer and training and running and building models.
Just because you close your browser window doesn't mean your server stops running on the whole, so don't forget to shut it down because otherwise you're paying for it. Colab is a great system which is free, there's also a paid subscription version of it. Be careful with Colab, most of the other systems we recommend save your work for you automatically and you can come back to it anytime, Colab doesn't.
So be sure to check out the Colab platform thread on the forums to learn about that. So I mentioned the forums, the forums are really really important because that is where all of the discussion and setup and everything happens. So for example if you want help with setup here you know there's a setup help thread and you can find out you know how to best setup Colab and you can see discussions about it and you can ask questions and please remember to search before you ask your question right because it's probably been asked before unless you're one of the very very earliest people who are doing the course.
So step one is to get your server setup by just following the instructions from the forums or from the course website and the course website will have lots of step-by-step instructions for each platform, they will vary in price, they will vary in speed, they will vary in availability and so forth.
Once you have finished following those instructions the last step of those instructions will end up showing you something like this, the course v4 folder, so version 4 of our course and by the time you see this video this is likely to have more stuff in it but it will have an nbs standing for notebooks folder so you can click on that and that will show you all of the notebooks for the course.
What I want you to do is scroll to the bottom and find the one called AppJupiter and click on that and this is where you can start learning about Jupyter Notebook. What is Jupyter Notebook? Jupyter Notebook is something where you can start typing things and press Shift Enter and it will give you an answer and so the thing you're typing is Python code and the thing that comes out is the result of that code and so you can put in anything in Python x equals 3 times 4 x plus 1 and as you can see it displays the result anytime there's a result to display.
So for those of you that have done a bit of coding before you will recognize this as a REPL, R-E-P-L, read, evaluate, print, look. Most languages have some kind of REPL. The Jupyter Notebook REPL is particularly interesting because it has things like headings, graphical outputs, interactive multimedia, it's a really astonishing piece of software.
It's won some really big awards, you know I would have thought the most widely used REPL outside of shells like bash. It's a very powerful system, we love it, we've written our whole book in it, we've written the entire fastai library with it, we do all our teaching with it.
It's extremely unfamiliar to people who have done most of their work in IDE. You should expect it to feel as awkward as perhaps the first time you moved from a GUI to a command line. It's different, right, so if you're not familiar with kind of REPL based systems it's going to feel super weird, but stick with it because it really is great.
The model going on here is that this web page I'm looking at is letting me type in things for a server to do and show me the results of computations the server is doing. So the server is off somewhere else, it's not running on my computer, right? The only thing running on the computer is this web page.
But as I do things, so for example if I say x=x*3, this is updating the server's state. There's this state, it's like what's currently the value of x, and so I can find out now x is something different. So you can see when I did this line here it didn't change the earlier x+1, right?
So that means that when you look at a Jupyter notebook, it's not showing you the current state of your server, it's just showing you what that state was at the time that you printed that thing out. It's just like if you use a shell like bash, and you type ls, and then you delete a file, that earlier ls you printed doesn't go back and change, right?
That's kind of how REPLs generally work, including this one. Jupyter notebook has two modes. One is edit mode, which is when I click in a cell, and I get a flashing cursor, and I can move left and right and type, right? There's not very many keyboard shortcuts in this mode.
One useful one is control or command slash, which will comment and uncomment. The main one to know is shift enter to actually run the cell. At that point, there's no flashing cursor anymore, and that means that I'm now in command mode, not edit mode. So as I go up and down, I'm selecting different cells.
So in command mode, as we move around, we're now selecting cells, and there are now lots of keyboard shortcuts you can use. So if you hit H, you can get a list of them for example, and you'll see that they're not on the whole like control or command with something, they're just a letter on its own.
So if you use like vim, you'll be more familiar with this idea. So for example, if I hit C to copy, and V to paste, then it copies the cell, or X to cut it, A to add a new cell above, and then I can press the various number keys to create a heading.
So number two will create a heading level two. And as you can see, I can actually type formatted text, not just code. The formatted text I type is in Markdown, like so. And my numbered one work, there you go. So that's in Markdown. If you haven't used Markdown before, it's a super, super useful way to write formatted text that is used very, very, very widely.
So learn it because it's super handy, and you need it for Jupiter. So when you look at our book notebooks, for example, you can see an example of all the kinds of formatting and code and stuff here. So you should go ahead and yeah, go through the app Jupiter.
And you can see here how you can create plots, for example, and create lists of things and import libraries and display pictures and so forth. If you want to create a new notebook, you can just go new Python 3, and that creates a new notebook, which by default is just called untitled, so you can then rename it to give it whatever name you like.
And so then you'll now see that in the list here, new name. The other thing to know about Jupiter is that it's a nice, easy way to jump into a terminal. If you know how to use a terminal, you certainly don't have to for this course, at least for the first bit.
If I go new terminal, you can see here I have a terminal. One thing to note is for the notebooks are attached to a GitHub repository. If you haven't used GitHub before, that's fine. But basically they're attached to a server where from time to time we will update the notebooks on that server.
And you'll see on the course website in the forum, we tell you how to make sure you have the most recent versions. When you grab our most recent version, you don't want it to conflict with or overwrite your changes. So as you start experimenting, it's not a bad idea to select a notebook and click duplicate and then start doing your work in the copy.
And that way when you get an update of our latest course materials, it's not going to interfere with the experiments that you've been running. So there's two important repositories to know about. One is the fastbook repository, which we saw earlier, which is kind of the full book with all the outputs and pros and everything.
And then the other one is the course v4 repository. And here is the exact same notebook from the course v4 repository. And for this one, we remove all of the pros and all of the pictures and all of the outputs and just leave behind the headings and the code.
In this case, you can see some outputs because I just ran that code. But for most of it, there won't be any, oh no, I guess we have left the outputs. I'm not sure if we'll keep that or not. So you may or may not see the outputs. So the idea with this is, this is probably the version that you want to be experimenting with because it kind of forces you to think about like what's going on as you do each step, you know, rather than just reading it and running it without thinking.
They kind of want you to do it in this more bare environment in which you're thinking about like, oh, what did the book say? Why was this happening? And if you forget, then you can kind of go back to the book. The other thing to mention is both the course v4 version and the fastbook version at the end have a questionnaire.
And quite a few folks have told us that, you know, amongst the reviewers and stuff that they actually read the questionnaire first. We spent many, many weeks writing the questionnaires, Sylvain and I. And the reason for that is because we tried to think about like, what do we want you to take away from each notebook?
So if you kind of read the questionnaire first, you can find out what are the things we think are important. What are the things that you should know before you move on? So rather than having like a summary section at the end saying at the end of this, you should know, blah, blah, blah, we instead have a questionnaire to do the same thing.
So please make sure you do the questionnaire before you move on to the next chapter. You don't have to get everything right. And most of the time answering the questions is as simple as going back to that part of the notebook and reading the prose. But if you've missed something, like do go back and read it because we're assuming these are the things we're assuming you know.
So if you don't know these things before you move on, it could get frustrating. Having said that, if you get stuck after trying a couple of times, do move on to the next chapter. Do two or three more chapters and then come back. Maybe by the time you've done a couple more chapters, you know, you'll get some more perspective.
We try to re-explain things multiple times in different ways. So yeah, it's okay if you've tried and you get stuck, then you can try moving on. All right, so let's try running the first part of the notebook. So here we are in 01 intro. So this is chapter one and here is our first cell.
So I click on the cell and by default actually there will be a header and a toolbar. As you can see, you can turn the one on and off. I always leave them off myself. And so to run this cell, you can either click on the play, you know, the run button, or as I mentioned, you can hit shift enter.
So for this one I'll just click. And as you can see, this star appears, so this says I'm running and now you can see a progress bar popping up. That's going to take a few seconds. And so as it runs, it's going to print out some results. Don't expect to get exactly the same results as us.
There's some randomness involved in training a model and that's okay. Don't expect to get exactly the same time as us. If this first cell takes more than five minutes, unless you have a really old GPU, that's probably a bad sign. You want to hop on the forums and figure out what's going wrong, or maybe you're trying to use Windows, which really doesn't work very well for this at the moment.
Don't worry that we don't know what all the code does yet. We're just making sure that we can train a model. So here we are. It's finished running. And so as you can see, it's printed out some information and in this case, it's showing me that there's an error rate of 0.005 at doing something.
What is the something it's doing? Well, what it's doing here is it's actually grabbing a dataset. We call the pets dataset, which is a dataset of pictures of cats and dogs. And it's trying to figure out which ones are cats and which ones are dogs. And as you can see, after about well less than a minute, it's able to do that with a 0.5% error rate.
So it can do it pretty much perfectly. So we've trained our first model. We have no idea how, we don't know what we were doing, but we have indeed trained a model. So that's a good start. And as you can see, we can train models pretty quickly on a single computer, many of which you can get for free.
One more thing to mention is if you have a Mac, it doesn't matter whether you have Windows or Mac or Linux in terms of what's running in the browser. But if you have a Mac, please don't try to use that GPU. Macs actually, Apple doesn't even support Nvidia GPUs anymore.
So that's really not going to be a great option. So stick with Linux. It'll make life much easier for you. Well, actually, the first thing we should do is actually try it out. So I claim we've trained a model that can pick cats from dogs. Let's make sure we can.
So let's check out this cell. This is interesting, right? We've created a widgets.file_upload object and displayed it. And this is actually showing us a clickable button. So as I mentioned, this is an unusual REPL. We can even create GUIs in this REPL. So if I click on this file upload, and I can pick cat, there we go.
And I can now turn that uploaded data into an image. It's a cat, and now I can do predict, and it's a cat with a 99.96% probability. So we can see we have just uploaded an image that we've picked out. So you should try this, right? Grab a picture of a cat, find one from the internet, or go and take a picture of one yourself and make sure that you get a picture of a cat.
This is something which can recognize photos of cats, not line drawings of cats. And so as we'll see in this course, these kinds of models could only learn from the kinds of information you give it. And so far we've only given it, as you'll discover, photos of cats, not anime cats, not drawn cats, not abstract representations of cats, but just photos.
So we're now going to look at what's actually happened here. And you'll see at the moment, I'm not getting some great information here. If you see this in your notebooks, you have to go file, trust notebook. And that just tells Jupyter that it's allowed to run the code necessary to display things to make sure that there isn't any security problems.
And so you'll now see the outputs. Sometimes you'll actually see some weird code like this. This is code that actually creates outputs. So sometimes we hide that code. Sometimes we show it. So generally speaking, you can just ignore the stuff like that and focus on what comes out. So I'm not going to go through these.
Instead I'm going to have a look at it, the same thing over here on the slides. So what we're doing here is we're doing machine learning. Machine learning is a kind of machine learning. What is machine learning? Machine learning is just like regular programming. It's a way to get computers to do something.
But in this case, like it's pretty hard to understand how you would use regular programming to recognize dog photos from cat photos. How do you kind of create the loops and the variable assignments and the conditionals to create a program that recognizes dogs versus cats in photos? It's super hard, super, super hard.
So hard that until kind of the deep learning era, nobody really had a model that was remotely accurate at this apparently easy task. Because we can't write down the steps necessary. So normally we write down a function that takes some imports and goes through our program and gives us some results.
So this general idea where the program is something that we write the steps doesn't seem to work great for things like recognizing pictures. So back in 1949, somebody named Arthur Samuel started trying to figure out a way to solve problems like recognizing pictures of cats and dogs. And in 1962, he described a way of doing this.
Well, first of all, he described the problem. Programming a computer for these kinds of computations is at best a difficult task. Because of the need to spell at every minute step of the process in exasperating detail. Computers are giant morons, which all of us coders totally recognize. So he said, okay, let's not tell the computer the exact steps, but let's give it examples of a problem to solve and figure out how to solve it itself.
And so by 1961, he had built a checkers program that had beaten the Connecticut state champion, not by telling it the steps to take to play checkers, but instead by doing this, which is a range for an automatic means of testing the effectiveness of a weight assignment in terms of actual performance and a mechanism for altering the weight assignment so as to maximize performance.
This sentence is the key thing. And it's a pretty tricky sentence, so we can spend some time on it. The basic idea is this, instead of saying inputs to a program and then outputs, let's have inputs to a, let's call the program now model, but it's the same basic idea, inputs to a model and results.
And then we're going to have a second thing called weights. And so the basic idea is that this model is something that creates outputs based not only on, for example, the state of a checkers board, but also based on some set of weights or parameters that describe how that model is going to work.
So the idea is if we could like enumerate all the possible ways of playing checkers and then kind of describe each of those ways using some set of parameters or what other the Samuel Porter weights, then if we had a way of checking how effective a current weight assignment is in terms of actual performance, in other words, does that particular enumeration of a strategy for playing checkers end up winning or losing games, right?
And then a way to alter the weight assignment so as to maximize the performance. So then, oh, let's try increasing or decreasing each one of those weights one at a time to find out if there's a slightly better way of playing checkers and then do that lots of lots of times, then eventually such a procedure could be made entirely automatic.
And then the machine so programmed wouldn't learn from its experience. So this little paragraph is, it's the thing. This is machine one, right? A way of creating programs such that they learn rather than they're programmed. So if we had such a thing, then we would basically now have something that looks like this.
You have inputs and weights again, going into a model, creating results, i.e. you won or you're lost and then a measurement of performance. So remember that was this key step and then the second key step is a way to update the weights based on the measure of performance. And then you could loop through this process and create a train a machine learning model.
So this is the abstract idea. So after we've run that for a while, right? It's come up with a set of weights that's pretty good, right? We can now forget the way it was trained and we have something that's just like this, right? The word program is now replaced with the word model.
So a trained model can be used just like any other computer program. So the idea is we're building a computer program not by putting out the steps necessary to do the task, but by training it to learn to do the task at the end of which it's just another program.
And so this is what's called inference, right? It's using a trained model as a program to do a task such as playing checkers. So machine learning is training programs developed by allowing a computer to learn from its experience rather than through manually coding. Okay, how would you do this for image recognition?
What is that model and that set of weights such that as we vary them, it could get better and better at recognizing cats versus dogs. I mean, for checkers, it's not too hard to imagine how you could kind of enumerate like depending on different kinds of how far away the opponent's piece is from your piece, what should you do in that situation?
How should you weight defensive versus aggressive strategies, blah, blah, blah. Not at all obvious how you would do that for image recognition. So what we really want is some function in here which is so flexible that there's a set of weights that could cause it to do anything, like the world's most flexible possible function.
And it turns out that there is such a thing. It's a neural network. So we'll be describing exactly what that mathematical function is in the coming lessons. To use it, it actually doesn't really matter what the mathematical function is. It's a function which is we say parameterized by some set of weights by which I mean as I give it a different set of weights, it does a different task and it can actually do any possible task.
Something called the Universal Approximation Theorem tells us that mathematically provable, provably, this functional form can solve any problem that is solvable to any level of accuracy if you just find the right set of weights, which is kind of restating what we described earlier in that like, oh, how do we deal with the Minsky, the Marvin Minsky problem?
So neural networks are so flexible that if you could find the right set of weights, they can solve any problem, including is this a cat or is it a dog? So that means you need to focus your effort on the process of training them, that is finding good weights, good weight assignments to use after Samuel's terminology.
So how do you do that? We want a completely general way to do this, to update the weights based on some measure of performance, such as how good is it at recognizing cats versus dogs? And luckily it turns out such a thing exists, and that thing is called Stochastic Gradient Reset or SGD.
Again, we'll look at exactly how it works, we'll build it from ourselves and scratch, but for now we don't have to worry about it. I will tell you this though, neither SGD nor neural nets are at all mathematically complex, they nearly entirely are addition and multiplication. The trick is it just does a lot of them, like billions of them, so many more than we can like intuitively grasp, but they can do extraordinarily powerful things, but they're not rocket science at all, they're not complex things, then we'll see exactly how they work.
So that's the Arthur Samuel version, nowadays we don't use quite the same terminology. But we use exactly the same idea. So that function that sits in the middle, we call an architecture. An architecture is the function that we're adjusting the weights to get it to do something, so that's the architecture, that's the functional form of the model.
Sometimes people say model to mean architecture, so don't let that confuse you too much, but really the right word is architecture. We don't call them weights, we call them parameters. That has a specific meaning, it's quite a particular kind of parameter. The things that come out of the model, the architecture with the parameters, we call them predictions.
And the predictions are based on two kinds of inputs, independent variables, that's the data, like the pictures of the cats and the dogs, and dependent variables, also known as labels, which is like the thing saying, this is a cat, this is a dog, this is a cat. So that's your inputs.
So the results are predictions. The measure of performance, to use Arthur Samuel's word, is known as the loss, so the loss has been calculated from the labels and the predictions. And then there's the update back to the parameters. So this is the same picture as we saw, but just putting in the words that we use today.
So this picture, if you forget, if I say these are the parameters of this, you know, used for this architecture to create a model, you can go back and remind yourself, what did I mean? What are the parameters? What are the predictions? What is the loss? Okay, the loss is some function that measures the performance of the model in such a way that we can update the parameters.
So it's important to note that deep learning and machine learning are not magic, right? The model can only be created where you have data showing you examples of the thing that you're trying to learn about. It can only learn to operate on the patterns that you've seen in the input used to train it, right?
So if we don't have any line drawings of cats and dogs, then there's never going to be an update to the parameters that makes the architecture, and so the architecture and the parameters together is the model, so to say the model, that makes the model better at predicting line drawings of cats and dogs because they just, they never received those weight updates because they'd never received those inputs.
Notice also that this learning approach only ever creates predictions. It doesn't tell you what to do about it, and that's going to be very important when we think about things like a recommendation system of like, what product do we recommend to somebody? Well, I don't know, we don't do that, right?
We can predict what somebody will say about a product after we've shown them, but we're not creating actions, we're creating predictions. That's a super important difference to recognize. It's not enough just to have examples of input data like pictures of dogs and cats. We can't do anything without labels, and so very often organizations say we don't have enough data.
Most of the time they mean we don't have enough labeled data because if a company is trying to do something with deep learning, often it's because they're trying to automate or improve something they're already doing, which means by definition they have data about that thing or a way to capture data about that thing because they're doing it, right?
But often the tricky part is labeling it. So for example, in medicine, if you're trying to build a model for radiology, you can almost certainly get lots of medical images about just about anything you can think of, but it might be very hard to label them according to malignancy of a tumor or according to whether or not meningioma is present or whatever because these kinds of labels are not necessarily captured in a structured way, at least in the US medical system.
So that's an important distinction that really impacts your kind of strategy here. So then a model, as we saw from the PDP book, a model operates in an environment, right? You roll it out and you do something with it. And so then this piece of that kind of PDP framework is super important, right?
You have a model that's actually doing something, for example, you've built a predictive policing model that predicts, doesn't recommend actions, it predicts where an arrest might be made. This is something a lot of jurisdictions in the US are using. Now it's predicting that based on data and based on labeled data.
And in this case, it's actually going to be using in the US, for example, data where I think depending on whether you're black or white, black people in the US, I think, get arrested something like seven times more often for say marijuana possession than whites, even though the actual underlying amount of marijuana use is about the same in the two populations.
So you start with biased data and you build a predictive policing model, its prediction will say, oh, you will find somebody you can arrest here based on some biased data. So then law enforcement officers might decide to focus their police activity on the areas where those predictions are happening as a result of which they'll find more people to arrest.
And then they'll use that to put it back into the model, which will now find, oh, there's even more people we should be arresting in the black neighborhoods and thus it continues. So this would be an example of modeling interacting with its environment to create something called a positive feedback loop, where the more a model is used, the more biased the data becomes, making the model even more biased and so forth.
So one of the things to be super careful about with machine learning is recognizing how that model is actually being used and what kinds of things might happen as a result of that. I was just going to add that this is also an example of proxies because here arrest is being used as a proxy for crime.
And I think that pretty much in all cases, the data that you actually have is a proxy for some value that you truly care about and that difference between the proxy and the actual value often ends up being significant. Thanks Rachel, that's a really important point. Okay, so let's finish off by looking at what's going on with this code.
So the code we ran is basically one, two, three, four, five, six lines of code. So the first line of code is an import line. So in Python, you can't use an external library until you import from it. Only in Python, people import just the functions and classes that they need from a library.
But Python does provide a convenient facility where you can import everything from a module which is by putting a star there. Most of the time, this is a bad idea because by default, the way Python works is that if you say import star, it doesn't only import the things that are interesting and important in the library you're trying to get something from, but it also imports things from all the libraries it used and all the libraries they used and you end up kind of exploding your namespace in horrible ways and causing all kinds of bugs.
Because fast.ai is designed to be used in this REPL environment where you want to be able to do a lot of quick rapid prototyping, we actually spent a lot of time figuring out how to avoid that problem so that you can import star safely. So whether you do this or not is entirely up to you, but rest assured that if you import star from a fast.ai library, it's actually been explicitly designed in a way that you only get the bits that you actually need.
One thing to mention is in the video, you see it's called fast.ai2. That's because we're recording this video using a pre-release version. By the time you're watching the online MOOC version of this, the two will be gone. Something else to mention is there are, as I speak, four main predefined applications in fast.ai, being vision, text, tabular and collaborative filtering, we'll be learning about all of them and a lot more.
For each one, say here's vision, you can import from the .all kind of meta module, I guess we could call it, and that will give you all the stuff that you need for most common vision applications. So if you're using a REPL system like Jupyter Notebook, it's going to give you all the stuff right there that you need without having to go back and figure it out.
One of the issues with this is a lot of Python users don't, if they look at something like untar data, they would figure out where it comes from by looking at the import line, and so if you import star, you can't do that anymore. But the good news is in a REPL you don't have to.
You can literally just type the symbol, press shift enter, and it will tell you exactly where it came from, as you can see. So that's super handy. So in this case, for example, to do the actual building the dataset, we call image data loaders from namefunk. And I can actually call this special doc function to get the documentation for that.
And as you can see, it tells me exactly everything to pass in, what all the defaults are, and most importantly, not only what it does, but show in docs pops me over to the full documentation, including an example. Everything in the fast.ai documentation has an example, and the cool thing is the entire documentation is written in Jupyter Notebooks.
So that means you can actually open the Jupyter Notebook for this documentation and run the line of code yourself and see it actually working and look at the outputs and so forth. Also in the documentation, you will find there's a bunch of tutorials. So, for example, if you look at the vision tutorial, it'll cover lots of things.
But one of the things it'll cover is, as you can see in this case, pretty much the same kind of stuff we're actually looking at in Lesson 1. So there's a lot of documentation in fast.ai and taking advantage of it is a very good idea and it is fully searchable.
And as I mentioned, perhaps most importantly, that every one of these documentation pages is also a fully interactive Jupyter Notebook. So looking through more of this code, the first line after the import is something that uses untar data that will download a dataset, decompress it and put it on your computer.
If it's already downloaded, it won't download it again. If it's already decompressed, it won't decompress it again. And as you can see, fast.ai already has predefined access to a number of really useful datasets such as this PETS dataset. Datasets are a super important part, as you can imagine, of deep learning.
We'll be seeing lots of them and these are created by lots of heroes who basically spend months or years collating data that we can use to build these models. The next step is to tell fast.ai what this data is and we'll be learning a lot about that. But in this case, we're basically saying, okay, it contains images.
It contains images that are in this path. So untar data returns the path that is whereabouts it's been decompressed to or if it's already decompressed, it tells us where it was previously decompressed to. We have to tell it things like, okay, what images are actually in that path. One of the really interesting ones is label function.
How do you tell for each file, whether it's a cat or a dog? And if you actually look at the README for the original dataset, it uses a slightly quirky thing which is they said, oh, anything where the first letter of the file name is an uppercase is a cat.
That's what they decided. So we just created a little function here called isCat that returns the first letter. Is it uppercase or not? And we tell fast.ai, that's how you tell if it's a cat. We'll come back to these two in a moment. So the next thing, so now we've told it what the data is.
We then have to create something called a learner. A learner is the thing that learns, it does the training. So you have to tell it what data to use. Then you have to tell it what architecture to use. I'll be talking a lot about this in the course, but basically there's a lot of predefined neural network architectures that have certain pros and cons.
And for computer vision, the architecture is called ResNet, just a super great starting point. And so we're just going to use a reasonably small one of them. So these are all predefined and set up for you. And then you can tell fast.ai what things you want to print out as it's training.
In this case, it's saying, oh, tell us the error, please, as you train. So then we can call this really important method called fine tune that we'll be learning about in the next lesson, which actually does the training. Valid percent does something very important. It grabs, in this case, 20% of the data, 0.2 proportion, and does not use it for training a model.
Instead it uses for telling you the error rate of the model. So always in fast.ai, this metric, the error rate, will always be calculated on a part of the data, which has not been trained with. And the idea here, and we'll talk a lot more about this in future lessons, but the basic idea here is we want to make sure that we're not overfitting.
Let me explain. Overfitting looks like this. Let's say you're trying to create a function that fits all these dots, right? A nice function would look like that, right? But you could also fit, you could actually fit it much more precisely with this function. Look, this is going much closer to all the dots than this one is, right?
So this is obviously a better function, except as soon as you get outside where the dots are, especially if you go off the edges, it obviously doesn't make any sense. So this is what you'd call an overfit function. So overfitting happens for all kinds of reasons. We use a model that's too big, or we use not enough data, we'll be, we'll be talking all about it, right?
But really, the, the craft of deep learning is all about creating a model that has a proper fit. And the only way you know if a model has a proper fit is by seeing whether it works well on data that was not used to train it. And so we always set aside some of the data to create something called a validation set.
The validation set is the data that we use not to touch it at all when we're training a model, but we're only using it to figure out whether the model's actually working or not. One thing that Sylvain mentioned in the book is that one of the interesting things about studying fast AI is you learn a lot of interesting programming practices.
So I've been programming, I mean, since I was a kid, so like 40 years. And Sylvain and I both work really, really hard to make Python do a lot of work for us and to use, you know, programming practices, which make us very productive and allow us to come back to our code years later and still understand it.
And so you'll see in our code, we'll often do things that you might not have seen before. And so we a lot of students who have gone through previous courses say they learned a lot about coding and Python coding and software engineering from the course. So yeah, check, you know, when you see something new, check it out and feel free to ask on the forums if you're curious about why something was done that way.
One thing to mention is, just like I mentioned, like import star is something most Python programmers don't do because most libraries don't support doing it properly. We do a lot of things like that. We do a lot of things where we don't follow a traditional approach to Python programming because I've used so many languages over the years.
I code not in a way that's specifically Pythonic, but incorporates like ideas from lots of other languages and lots of other notations and heavily customize our approach to Python programming based on what works well for data science. That means that the code you see in fast.ai is not probably not going to fit with the kind of style guides and normal approaches at your workplace if you use Python there.
So obviously you should make sure that you fit in with your organization's programming practices rather than following hours, but perhaps in your own hobby work you can follow hours and see if you find that interesting and helpful or even experiment with that in your company if you're a manager and you're interested in doing so.
Okay, so to finish I'm going to show you something pretty interesting, which is have a look at this code untar data image data loaders from name func learner fine-tune untar data segmentation data loaders from label func learner fine-tune almost the same code and this has built a model that does something whoa totally different it's something which has taken images this is on the left this is the label data it's got images with color codes to tell you whether it's a car or a tree or a building or a sky or a line marking or a road and on the right is our model and our model has successfully figured out for each pixel is that a car a line marking a road now it's only done it in under 20 seconds right so it's a very small quick model so it's made some mistakes like it's missing this line marking and some of these cars it thinks is house right but you can see so if you train this for a few minutes it's nearly perfect but you can see the basic idea is that we can very rapidly with almost exactly the same code create something not that classifies cats and dogs but does what's called segmentation figures out what every pixel image is look here's the same thing from import star text loaders from folder learner learn fine-tune same basic code this is now something where we can give it a sentence and it can figure out whether that is expressing a positive or negative sentiment and this is actually giving a 93% accuracy on that task in about 15 minutes on the IMDB data set which contains thousands of full length movie reviews like 1000 to 3000 word movie reviews and this number here that we got with the same three lines of code would have been the best in the world for this task in a very very very popular academic status set in like 2015 I think so we are creating world-class models in our browser using the same basic code here's the same basic steps again from import star untied data tabular data loaders from CSV learner fit this is now building a model that is predicting let's find out salary based on a CSV table containing these columns so this is tabular data here's the same basic steps from import star untied data collab data loaders from CSV learner learn fine-tune this is now building something which predicts for each combination of a user and a movie what rating do we think that user will give that movie based on what other movies they watched and liked in the past this is called collaborative filtering and used recommendation systems so here you've seen some examples of each of the four applications in fast AI and as you'll see throughout this course the same basic code and also the same basic mathematical and software engineering concepts allow us to do vastly different things using the same basic approach and the reason why is because of Arthur Samuel it's because of this basic description of what it is you can do if only you have a way to parameterize a model and you have an update procedure which can update the weights to make you better at your loss function and in this case we can use neural networks which are totally flexible functions so that's it for this first lesson it's a little bit shorter than other lessons going to be and the reason for that is that we are as I mentioned at the start of a global pandemic here or at least in the West in other countries they are much further into it so we spend some time talking about that at the start of the course and you can find that video elsewhere so in future lessons there will be more time on deep learning so what I suggest you do over the next week before you work on the next lesson is just make sure that you can spin up a GPU server you can shut it down when it's finished that you can run all of the code here and as you go through it see you know is this using Python in a way you recognize use the documentation use that doc function do some searching of the fast AI doc see what it does see if you can actually grab the fast AI documentation notebooks themselves and run them just try to get comfortable that you kind of can know your way around because the most important thing to do with this style of learning this top-down learning is to be able to run experiments and that means you need to be able to run code so my recommendation is don't move on until you can run the code read the chapter of the book and then go through the questionnaire we still got some more work some more stuff to do about validation sets and test sets and transfer learning so you won't be able to do all of it yet but try to do all the parts that you can based on what we've seen in the course so far Rachel anything you wanted to add before we go okay so thanks very much for joining us so lesson one everybody and really looking forward to seeing you next time where we will learn about transfer learning and then we will move on to creating a actual production version of an application that we can actually put out on the internet and you can start building apps that you can show your friends and they can start playing with all right bye everybody