Machine Learning 1: Lesson 11
Chapters
0:02:45 Chain Rule
15:5 Adding Regularization
16:25 Weight Decay
16:34 Cross-Entropy
16:55 Example of a Binary Cross-Entropy
22:54 Logistic Regression
32:55 Regularization
57:3 Engrams
71:21 Embeddings
77:6 Multi-Layer Neural Network
78:21 Ng Embeddings
79:24 The Data
81:36 Data Cleaning
94:31 Treating Columns as Categorical Variables Where Possible
Transcript
So let's just yeah, let's start by reviewing Kind of what we've learned about optimizing Multi-layer functions with SGD and so the idea is that we've got some data and Then we do something to that data. For example, we multiply it by a weight matrix And then we do something to that for example, we put it through a softmax or a sigmoid and Then we do something to that such as do a cross entropy loss or a root mean squared error loss Okay, and that's going to like give us some scalar So this is going to have no hidden layers this has got a linear layer A nonlinear activation being a softmax and a loss function being a root mean squared error or a cross entropy All right, and then we've got our input data Put linear nonlinear loss so for example if this was sigmoid or Or softmax and this was cross entropy then that would be logistic regression So it's still yeah Cross entropy.
Yeah, let's do that next sure For now think of it like think of root means great error same thing some loss function. Okay now We'll look at cross entropy again in a moment So How do we calculate the derivative of that with with respect to our weights, right? So really it would probably be better if we said X comma W here because it's really a function of the weights as well.
And so we want the derivative of this With respect to our weights Sorry, I put it in the wrong spot G f of X comma W I just screwed up. That's all that's why that didn't make sense. All right So to do that we just basically we do the chain rule so we just say that this is equal to H of you and you Equals G F of G U equals G of V and V equals F of X So we can just rewrite it like that Right and then we can do the chain rule so we can say that's equal to H - the derivative is H - you by G - V by F - X Happy with all that so far.
Okay, so In order to take the derivative with respect to the weights therefore We just have to calculate that derivative with respect to W using that exact formula So if we had in there Yeah so Yeah, so so D of all that dW would be that yeah So then if if we you know went further here and Had like Another linear layer, right?
Let's give us a bit more room now the linear layer I Cover W2 Right, so we have another linear layer There's no difference to now calculate the derivative with respect to all of the parameters. We can still use the exact same chain rule, right So so don't think of the multi-layer network has been like things that occur at different times it's just a composition of functions and So we just use the chain rule to calculate all the derivatives at once, you know There's a they're just a set of parameters that happen to appear in different parts of the function but the calculus is no No different so to calculate this with respect to W1 and W2, you know, it's it's just you just increase You know W you can just now just call it W and say W1 is all of those weights So the result that's a great question so what you're going to have then is A list of parameters, right?
So Here's W1 and like it's it's it's probably some kind of higher rank tensor, you know, like if it's a convolutional layer It'll you know be like a rec 3 tensor or whatever, but we can flatten it out that we just make it a list of parameters There's W1.
Here's W2 Right. It's just another list of parameters, right And here's our loss Which is a single, you know a single number so therefore our derivative Is just a vector of that same length, right? It's how much does changing that value of W affect the loss how much does changing that value of W affect the loss?
Right, so you can basically think of it as a function like, you know y equals ax 1 plus BX 2 Plus C right and say like oh, what's the derivative of that with respect to A B and C? And you would have three numbers the derivative with respect to A and B and C and that's all this is right It's a derivative with respect to that weight that weight and that weight and that weight and that weight that way To get there inside the chain rule We had to calculate and I'm not going to go into detail here, but we had to calculate like Jacobians so like the derivative when you take a matrix product is you've now got something where you've got like a weight matrix and You've got an input vector.
These are the activations from the previous layer, right and you've got some new output activations, right and so now you've got to say like okay for this particular sorry for this particular weight How does changing this particular weight change? This particular output and how does changing this particular weight change this particular output and so forth so you kind of end up with these Higher dimensional tensors showing like for every weight.
How does it affect? Every output, right? But then by the time you get to the loss function the loss function is going to have like a mean or a sum or something so they're all going to get added up in the end, you know, and so this kind of thing like I don't know it drives me a bit crazy to try and Calculate it out by hand or even think of it step by step because you tend to have like You just have to remember for every input in a layer for every output in the next layer You know, you're going to have to take out for every weight for every output.
You're going to have to have a separate gradient One good way to look at this is to learn to use pytorches like dot grab Attribute and dot backward method manually and like look up the tutorial the pytorch tutorials and so you can actually start setting up some calculations with a vector input and the vector output and then type dot backward and Then say type dot grad and like look at it Right and then do some really small ones with just two or three items in the input and output vectors and like make the make the operation like plus two or something and like See what the shapes are make sure it makes sense Yeah, because it's kind of like this Vector matrix calculus is not like introduces zero new concepts to anything you learned in high school Like strictly speaking but getting a feel for how these shapes Move around I find talk a lot of practice, you know, the good news is you almost never have to worry about it Okay, so We Were Talking about then using this kind of logistic regression For NLP and before we got to that point we were talking about using naive base for NLP And the basic idea was that we could take a document Right a review like this movie is good and turn it into a bag of words Representation consisting of the number of times each word appears All right, and we call this the vocabulary.
This is the unique list of words. Okay, and we used the SK learn count vectorizer to automatically generate both the vocabulary which in SK learn they call they call the features And to call create the bag of words representations and the whole group of them then is called a term document matrix, okay And we kind of realized that we could calculate the probability that a positive review contains the word this by just averaging the number of times this appears in the positive reviews and we could do the same for the Negatives right and then we could take the ratio of them to get something which if it's greater than one was a Word that appeared more often in the positive reviews or less than one was a word that appeared more often in the negative reviews okay, and Then we realized you know using using Bayes rule that and taking the logs That we could basically end up with something where we could add up the logs of these Plus the log of the ratio of the probabilities that things are in class 1 versus class 0 And end up with something we can compare to 0 It's a bit greater than 0 then we can predict a document is Positive or if it's less than 0 we can predict the document is negative and that was our Bayes rule, right?
So we kind of did that from math first principles And I think we agreed that the the naive in naive Bayes was a good description Because it assumes independence when it's definitely not true but it's an interesting starting point and I think it was interesting to observe when we actually got to the point where like Okay, now we've you know calculated the the ratio of the probabilities and Took the log and now rather than multiply them together of course we have to add them up and When when we actually wrote that down we realized like oh that is You know just a standard Weight matrix product plus a bias Right and so then we kind of realized like oh, okay, so like if this is not very good accuracy 80% accuracy Why not improve it by saying hey, we know other ways to calculate a You know a bunch of coefficients and a bunch of biases, which is to Learn them in a logistic regression right so in other words this this is the formula we use for a logistic regression And so why don't we just create a logistic regression and fit it Okay, and it's going to be Give us the same thing, but rather than Coefficients and biases which are theoretically correct based on you know this assumption of independence and based on Bayes rule There'll be the coefficients and biases that are actually the best in this data All right, so that was kind of where we got to and so The kind of key insight here is like Just about everything I find a machine learning ends up being either like a tree or You know a bunch of matrix products and monomerities Right like it's everything seems to end up kind of coming down to the same thing Including as it turns out Bayes rule, right?
And then it turns out that nearly all of the time then whatever the parameters are in that function Nearly all the time it turns out that they're better learned than Calculated based on theory right and indeed that's what happened when we actually tried learning those coefficients We got you know 85 percent So then We noticed that we could also rather than take the whole term document matrix We could instead just take them the you know ones and zeros for presence or absence of a word And you know sometimes it was you know, this equally is good But then we actually tried something else which is we tried adding regularization And with regularization the binarized approach turned out to be a little better.
All right, so then regularization Was where we took the loss function? And again, let's start with RMSE and then we'll talk about cross entropy loss function was Our predictions minus our actuals sum that up take the average Plus a Penalty Okay, and so this specifically is the L2 penalty If this instead was the absolute value of W Then that would be the L1 penalty.
Okay? um We also noted that we don't really care about the loss function per se we only care about its derivatives That's actually the thing that updates the weights so we can because this is a sum we can take the derivative of each part separately and so the derivative of this part was just that Right, and so we kind of learned that even though these are mathematically equivalent They have different names This version is called weight decay and it's kind of what's used that term is used in the neural net picture Okay So cross entropy on the other hand, you know, it's just another loss function like root mean squared error But it's specifically designed for classification And so here's an example of Binary cross entropy.
So let's say this is our you know, is it a cat or a dog? So let's just say is cat one or a zero so cat cat dog dog cat and these are our Predictions this is the output of our final layer of our neural net or a logistic regression or whatever all right, then All we do is we say okay.
Let's take the the actual times the log of the prediction and Then we add to that 1 minus actual times the log of 1 minus the prediction and then take the negative of that whole thing All right So I suggested to you all that you tried to kind of write the if statement version of this So hopefully you've done that by now.
Otherwise, I'm about to spoil it for you. So this was y times log y plus 1 minus y times log 1 minus y Right and negative of that. Okay, so who wants to tell me how to write this is an if statement She hit me. I'll give a try.
So if y equal to Sorry, if y equal to 1 Then return log y. Mm-hmm otherwise Well else return log 1 minus 1. Good. Oh, that's the thing in the brackets and you take C minus Good. So the key insight she's using is that y has two possibilities 1 or 0 Okay, and so very often the math Can hide?
The key insight which I think happens here until you actually think about what the values it can take right, so That's that's all it's doing it's saying either give me that or give me that Right. Could you pass that to the back place tension? If I'm missing something, but do you know the two variables in that statement because you got why?
Shouldn't be like white hot in the way. Oh, yeah. Thank you As usual, it's me missing something Okay Okay, and so then the you know, the multi Category version is just the same thing but you're saying you know it for different more than just y equals 1 or 0 But y equals 0 1 2 3 4 5 6 7 8 9 for instance okay, and So that you know that loss function has a you can figure it out yourself and particularly simple derivative And it also you know another thing you could play with at home if you like is like thinking about how The derivative looks when you add a sigmoid or a softmax before it, you know, it turns out at all Turns out very nicely because you've got an XP thing going into a loggy thing.
So you end up with you know, very well behaved derivatives The reason I guess there's lots of reasons that people use RMSE for aggression and cross entropy for classification But most of it comes back to the statistical idea of a best linear unbiased estimator You know and based on the likelihood function that kind of turns out that these have some nice statistical properties It turns out however in practice Root means grid error in particular the properties are perhaps more theoretical than actual and actually nowadays using the The absolute deviation rather than the sum of squares deviation can often work better So in practice like everything in machine learning I normally try both for a particular data set I'll try both loss functions and see which one works better and us of course It's a Kaggle competition in which case you're told how Kaggle is going to judge it and you should use the same Lost function as Kaggle's evaluation metric Alright So yeah, so this is really the key insight is like hey Let's let's not use theory but instead learn things from the data and you know We hope that we're going to get better results particularly with regularization we do and then I think the key regularization insight here is hey, let's not like try to reduce the number of parameters in our model that instead like use lots of parameters and then use regularization to figure out Which ones are actually useful right and so then we took that a step further by saying hey given we can do that with Regularization let's create lots more features by adding biograms and trigrams You know biograms like by vast and by vengeance and trigrams like by vengeance full stop and by Vera miles Right and you know just to keep things a little faster We limited it to 800,000 features, but you know even with the full 70 million features It works just as well, and it's not a hell of a lot slower So we created a term document matrix again using the full set of n grams for the training set the validation set And so now we can go ahead and say okay our labels is the training set labels as before our independent variables is the Binerized term document matrix as before And then let's fit a logistic regression to that and do some predictions and We get 90% accuracy, so this is looking pretty good Okay So the logistic regression Let's go back to our naive phase right in our naive phase We have this term document matrix, and then for every feature.
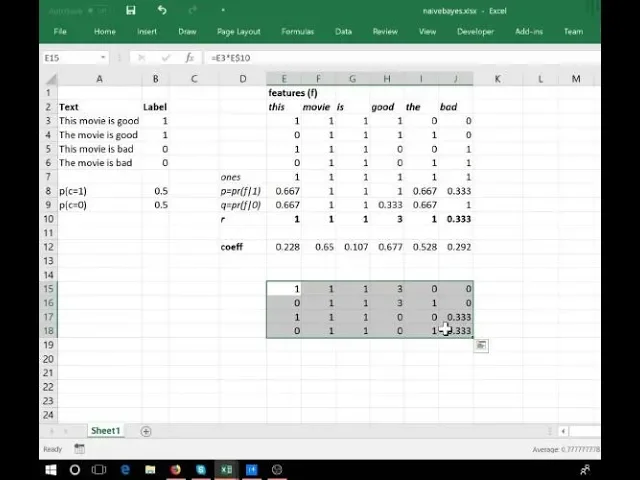
We're calculating the probability of that feature occurring if it's class one that probability of that feature occurring if it's class two and then the ratio of those two Right and in the paper that we're actually lip basing this off. They call this P this Q and this Right, maybe I should just fill that in P Q maybe then we'll say probability to make it more obvious Okay And so then we kind of said hey, let's let's not use these ratios as the coefficients in that in that matrix multiply, but let's instead like Try and learn some coefficients.
You know so maybe start out with some random numbers You know and then try and use stochastic gradient descent to find slightly better ones So you'll notice you know some important features here the the R Vector is a vector of rank 1 and its length is equal to the number of features and Of course our logistic regression coefficient matrix is also Of length 1 sorry rank 1 and length equal to the number of features right and we're you know We're saying like they're kind of two ways of calculating The same kind of thing right one based on theory one based on data So here is like some of the numbers in R right remember.
It's using the log so these numbers Which are less than zero? represent things which are More likely to be negative and these ones that here are more likely Sorry this one here is more likely to be positive and so Here's e to the power of that and so these are the ones we can compare to one rather than to zero So I'm going to do something that hopefully is going to seem weird And so first of all I'm going to talk about I'm going to say what we're going to do and Then I'm going to try and describe why it's weird, and then we'll talk about Why it may not be as weird as we first thought so here's what we're going to do We're going to take our term document matrix And we're going to multiply it by R So what that means is we're going to we can do it here in Excel right so we're going to say let's grab everything in our term document matrix and Multiply it by the equivalent value in the vector of R.
All right, so this is like a broadcasted element wise multiplication not a matrix multiplication Okay And that's what that does Okay, so here is the value of the term document matrix times R in other words everywhere that a zero appears there a zero appears here and Every time a one appears here the equivalent value of R appears here so we haven't really We haven't really changed much Right we've just we've just kind of Changed the ones into something else into the into the R's from that feature Right and so what we're now going to do is we're going to use this as our independent variables Instead in our logistic regression Okay, so here.
We are multiply of X X NB X naive Bayes version is X times R And now let's do a logistic regression fitting using those independent variables and Let's then Do that for the validation set okay and get the predictions and Lo and behold we have a better number Okay, so Let me explain why this hopefully seems surprising Given that we're just multiplying oh I picked out the wrong ones.
I should have said not coeth Okay, that's actually ah I got the wrong number okay So that's our independent variables right and then the the logistic regression has come up with some set of coefficients Let's pretend for a moment that these are the coefficients that it happened to come up with right We could now say well, let's not use this Set let's not use this Set of independent variables, but let's use the original binarized feature matrix right and then divide all of our coefficients by the values in R and We're going to get exactly the same result mathematically, so You know we've got X naive Bayes version of the independent variables, and we've got some Some set of weights some sort of some sort of coefficient so call it W right W 1 let's say Where it's found like this is a good set of coefficients and making our predictions from right, but X and B is simply equal to X times as in element wise times ah Right so in other words.
This is equal to X times ah Times the weights and so like we could just change the weights to be that Right and get the same number so this ought to mean that The change that we made to the dependent variable shouldn't have made any difference Because we can calculate exactly the same thing without making that change So that's the question Why did it make a difference?
So in order to answer this question I'm going to try and get you all to try and think about this in order to answer this question you need to think About like okay. What are the things that aren't? mathematically the same why is why is it not identical? What are the reasons like come up with some hypotheses?
What are some reasons that maybe we've actually ended up with a Better answer and to figure that out. We need to first of all start with like well. Why is it even a different answer? Why is that different to that? This is subtle All right, what do you think I'm just wondering if it was two different kinds of multiplications You said that one is the element wise multiplication.
No they did they do end up mathematically being the same, okay? Pretty much there's a minor wrinkle, but not but it's not that it's not some order operations thing Let's try can she You are on a roll today, so let's see how you go. I feel like the features are less correlated to each other I Mean I've made a claim that these are mathematically equivalent, so So what are you saying really you know why are we getting different answers?
It's good people coming up with hypotheses. We need lots of wrong answers before we start finding. It's the right ones It's like that. You know I'm a warmer hotter colder. You know Ernest you're gonna get us hotter Does it have anything to do with the regularization? Yes, and is it the fact that when you so let's start there, right?
So Ernest point here is like okay Jeremy. You've set their equivalent, but they're equivalent outcomes Right, but you got through you went through a process to get there and that process included regularization, and they're not necessarily equivalent Regularization like our loss function has a penalty so yeah help us think through and as how much that might impact things Well, this is maybe kind of dumb, but I'm just noticing that the numbers are bigger in the ones I've been weighted by the naive phase Mm-hmm are weights and so These are bigger and some are smaller some are bigger But that there are some bigger ones like the variance between the columns is much higher now the variance is bigger Yeah, I think that's a very interesting insight.
Okay. That's all I got okay, so build on that I Prince has been on a roll a month so Hit us I'm not sure that's fine. Is it also considered like considering the dependency of different words? Is that why it is forming better rather than all? What independent of each other not really I mean it's it's you know again fear it You know theoretically these are creating mathematically equivalent outputs So they're not they're not doing something different except as Ernest mentioned They're getting impacted differently by regularization so what's So what's regularization right?
regularization is we start out with our That was the weirdest thing I forgot to go into screenwriting mode, and it just turns out that you can actually write in Excel And I had no idea that was true I still use green writing rows, so I don't skill up my spreadsheet.
I just I never tried So our loss was equal to like our cross entropy loss. You know based on the Predictions of the predictions and the actuals right plus our penalty so If you're If your weights a large Right then that piece Gets bigger Right and it drowns out that piece right, but that's actually the piece we care about right we actually want it to be a good fit So we want to have as little regularization going on as we can get away with we want so we want to have less weights So here's the thing right our value.
Yes, can you pass it over here? We should let less weights do you mean lesser weights I do yeah Yeah, and I kind of use the two words a little equivalently, which is not quite fair I agree, but the idea is that weights that are pretty close to zero are kind of not there So here's the thing our values of are You know and I'm not a Bayesian weenie, but I'm still going to use the word prior right they're kind of like a prior so like we think that the The different levels of importance and positive or negative of these different features Might be something like that right we think that like bad you know might be More correlated with negative than Than good right so our kind of implicit assumption But before was that we have no priors so in other words when we'd said Squared weights we're saying a non zero weight is something.
We don't want to have right, but actually I think what I really want to say is that Differing from the naive Bayes expectation is something. I don't want to do right Like only vary from the naive Bayes prior unless you have good reason to believe otherwise All right, and so that's actually what this ends up doing right we end up saying you know what?
We think this value is probably three Right and so if you're going to like make it a lot bigger or a lot smaller Right that's going to create the kind of variation in weights. That's going to cause that squared term to go up right so so if you can You know just leave all these values about similar to where they are now Right and so that's what the penalty term is now doing right the penalty term when our inputs is already multiplied by R Is saying penalize things where we're varying it from our naive Bayes prior Can you pass that Why multiply only with the R not Constant like R squared or something like that when the variance would be much higher this time because our Our prior comes from an actual theoretical model right so I said like I don't like to rely on theory But I have if I have some theory Then you know maybe we should use that as our starting point rather than starting off by assuming everything's equal So our prior said hey, we've got this model called naive Bayes and the naive Bayes model said If the naive Bayes assumptions were correct Then R is the correct coefficient right in this specific formulation That that's why we pick that because our our prior is based on that that theory Okay, so this is a really interesting insight, which I Never really see covered which is this idea is that we can use these like, you know traditional Machine learning techniques we can imbue them with this kind of Bayesian sense by by starting out You know incorporating our theoretical expectations Into the data that we give our model right and when we do so that then means We don't have to regularize as much and that's good right because if we regularize a lot But let's try it Let's go back to You know here's our Our Remember the way they do it in the sklearn logistic regression is this is the reciprocal of the amount of regularization penalty, so we'll kind of Add lots of regularization by making it small So that's like really hurts That really hurts our accuracy because now It's trying really hard to get those weights down.
The loss function is overwhelmed By the need to reduce the weights and the need to make it predictive is kind of now seems totally unimportant right, so So by kind of starting out and saying you know what don't push the weights down so that you end up ignoring The the terms but instead push them down so that you try to get rid of you know ignore differences from our expectation based on the naive phase formulation So that Ends up giving us a very nice Result which actually was originally this this technique was originally presented.
I think about 2012 Chris Manning who's a terrific NLP researcher up at Stanford and Cedar Wang who I don't know but I assume is awesome because this paper is awesome. They basically came up with this with this idea and What they did was they compared it to a number of other approaches on a number of other Datasets so one of the things they tried is this one is the IMDB data set right and so here's naive Bayes SVM on bigrams And as you can see this approach out performed the other linear based approaches that they looked at and also some Restricted Boltzmann machine kind of neural net based approaches.
They looked at now nowadays There are better ways there You know there are better ways to do this and in fact in the deep learning course We showed a new state-of-the-art result that we just developed at fast AI that gets Well over 94% But still you know like particularly for a linear technique.
That's easy fast and intuitive This is pretty good And you'll notice when they when they did this they only used by grams And I assume that's because they I looked at their code, and it was kind of pretty slow and ugly You know I figured out a way to optimize it a lot more as you saw and so we were able to use Here trigrams, and so we get quite a lot better So we've got 91.8 versus in 91.2, but other than that it's identical Also, I mean they used a support vector machine.
Which is almost identical to a logistic aggression in this case So there's some minor differences right so I think that's a pretty cool result and You know I will mention You know what you get to see here in class is the result of like many Weeks and often many months of research that I do and so I don't want you to think like this stuff is obvious It's not at all like reading this paper There's no description in the paper of like Why they use this model how it's different why they thought it works?
You know it took me a week or two to even realize that it's kind of like mathematically equivalent To a normal logistic regression and then a few more weeks to realize that the difference is actually in the regularization You know like this is kind of like Machine learning as I'm sure you've noticed from the Kaggle competitions you enter you know like you come up with a thousand good ideas 999 of them no matter how confident you are they're going to be great They always turn out to be shit you know and then finally after four weeks one of them finally works and Kind of gives you the enthusiasm to spend another four weeks of misery and frustration This is the norm right and and like For sure that the best Practition as I know in machine learning all share one particular trait in common, which is they're very very tenacious You know also known as stubborn and bloody-minded right which is definitely a reputation.
I seem to have probably fair Along with another thing which is that they're all very good coders. You know they're very good at turning their ideas into into code So yeah So you know this was like a really interesting Experience for me working through this a few months ago to try and like figure out how to how to at least You know how to explain why this at the at the time kind of state-of-the-art result exists And so once I figured that out.
I was actually able to build on top of it and make it quite a bit better And I'll show you what I did and this is where it was very very handy to have high torch at my disposal Because I was able to kind of create something that was Customized just the way that I wanted to be and also very fast by using the GPU So here's the kind of fast AI version of the NB SVM actually my friend Stephen Marity.
Who's a terrific Researcher in NLP has christened this the NB SVM plus plus which I thought was lovely So here is the even though there is no SVM. It's a logistic regression, but as I said nearly exactly the same thing So let me first of all show you like the code So this is like we try to like once I figure out like okay This is like the best way I can come up with to do a linear bag-of-words model I kind of embed it into fast AI so you can just write a couple of lines of code So the code is basically hey, I want to create a data class for text classification I want to create it from a bag of words Right here is my bag of words Here are my labels Here is the same thing for the validation set and use up to 2,000 unique words per review which is plenty So then from that model data Construct a a learner which is kind of the fast AI generalization of a model Which is based on a dot product of naive Bayes and then fit that model And then do a few epochs and After five epochs I was already up to ninety two point two.
All right, so this is now like, you know getting quite well above this this linear baseline So, let me show you the code for for that So the code is like horrifyingly short That's it. Right and it'll also look on the whole Extremely familiar, right? There's if there's a few tweaks here Pretend this thing that says embedding pretend it actually says linear.
Okay, I'm going to show you embedding in a moment Pretend it says linear So we've got basically a linear layer where the number of features coming with the number of features as the rows and remember SK learn features means number of words basically and then for each row we're going to create One weight which makes sense right for like a logistic regression every every so not for each row for each word each word has one weight and Then we're going to be multiplying it by the the R values.
So for each word We have one R value per class. So I actually made this so this can handle like not just Positive versus negative but maybe figuring out like which author created this work. There could be five or six authors Whatever right and basically we kind of use those linear layers to to get the The value of the weight and the value of the R and then we take the weight times the R and Then sum it up.
And so that's just a dot product. Okay, so just just a simple dot product just as we would do for any logistic regression And then do the softmax So the very minor tweak That we add to get the the better result is this the main one really is this here this plus something right the thing I'm adding is It's a parameter, but I pretty much always use this this version this value 0.4 So what does this do?
So what this is doing is it's again kind of changing the prior, right? So if you think about it Even once we use this R times the term document matrix as our independent variables You really want to start with a question? Okay, the penalty terms are still pushing W down to zero, right?
So what did it mean? For W to be 0 right? So what would it mean if we had you know? Coefficient 0 0 0 0 0 Right. So what that would do when we go? Okay this matrix times these coefficients We still get 0 Right. So a weight of 0 still ends up saying I have no opinion on whether this thing is positive or negative On the other hand if they were all 1 Right, then it's basically says my opinion is that the naive phase coefficients are exactly right Okay, and so the idea is that I said 0 is almost certainly not The right prior right we shouldn't really be saying if there's no coefficient.
It means ignore the naive Bayes coefficient One is probably too high Right because we actually think that naive Bayes is only kind of part of the answer All right, and so I played around with a few different data sets where I basically said Take the weights and add to them some constant Right, and so 0 would become in this case 0.4 right, so in other words the the regularization Penalty is pushing the weights not towards 0 but towards this value Right, and I found that across a number of data sets 0.4 Works pretty well that and it's pretty resilient.
All right. So again, this is the basic idea is to kind of like Get the best of both worlds, you know, we're we're we're learning from the data using a simple model But we're incorporating You know our prior knowledge as best as we can and so it turns out when you say, okay Let's let's tell it, you know as weight matrix of zeros Actually means that you should use about you know about half of the R values That ends up that ends up working better than the prior that the weights should all be zero Yes Is the the weights the W is it that the point for the amount of regularization required?
the amount of so we have this term where the we have the term where we reduce the amount of error the prediction error RMSE plus we have the Regularization and is it W the point for denote the amount of realization required? So W are the weights Right, so this is calculating our activations.
Okay, so we calculate our activations as being equal to the weights Times the R Sum all right, so that's just our normal At a normal linear function, right so so the the thing which is being penalized is my weight matrix That's what gets penalized So by saying hey, you know what don't just use W use W plus point four So that's not being penalized It's not part of the weight matrix Okay, so effectively the weight matrix gets 0.4 for free So by doing this even after regularization then every Absolutely Every feature is getting some form of weight some form of minimum weight or something like that Um, not necessarily because it could end up choosing a coefficient of negative point four for a feature And so that would say You know what even though naive Bayes says it's the R should be whatever for this feature.
I think you should totally ignore it Yeah great questions, okay We started at 20 past - okay, let's take a break for about eight minutes or so and start back about 25 to four Okay, so a couple of questions at the break the first was just for a Kind of Reminder or a bit of a summary as to what's going on Yeah, right.
And so here we have W plus I'm writing it out. Yeah plus Adjusted weight a weight adjustment times Right, so so normally what we were doing So normally what we were doing is saying hey logistic regression is basically Wx right. I'm going to ignore the bias Okay, and then we were changing it to be W dot Times x Right, and then we were kind of saying let's do that bit first right Although in this particular case actually now I look at it.
I'm doing it in this code. It doesn't matter obviously in this code I'm actually doing I'm Doing this bit first And so So this thing here actually I could I called it W which is probably pretty bad. It's actually W times X Right, so so instead of W times X times R.
I've got W times X plus a constant times R right So the the key idea here is that regularization Can't draw in yellow that's fair enough Regularization wants the weights to be zero right because we're trying to it's trying to reduce That okay, and so what we're saying is like okay, we want to push the weights towards zero because we're saying like that's our like default starting point expectation is the weights are zero and So we want to be in a situation where if the weights is zero, then we have a model that like Makes theoretical or intuitive sense to us, right?
This model if the weights are zero doesn't make intuitive sense to us Right because it's saying hey multiply everything by zero gets rid of all of that and gets rid of that as well And we were actually saying no we actually think our our is useful. We actually want to keep that right, so So instead we say you know what let's take that piece here and add Zero point four to it Right so now if the regularizer is pushing the weights towards zero Then it's pushing the value of this sum towards zero point four Right and so therefore it's pushing our whole model to zero point four times up Right so in other words Now kind of default starting point if you've regularized all the weights out all together is to say yeah You know let's use a bit of our that's probably a good idea Okay So that's the idea right that's the idea is basically you know what happens when When that's zero right and you and you want that to like be something sensible because otherwise Regularizing the weights to move in that direction wouldn't be such a good idea Second question was about N grams So the N in N gram can be uni by try whatever one two three whatever grounds so for the this movie is good All right, it has four unigrams this movie is good It has three bigrams this movie movie is is good It has two trigrams This movie is Movie is good Okay Can you pass that?
So yeah, do you mind go back to the wad chase down the zero point four stuff? yeah, so I was wondering if this adjustment will harm the predictability of the model because Think of extreme extreme case if it's not zero point four if it's four thousand and or Coefficient will be like right essentially.
So so exactly so so our prior Needs to make sense and so our prior here and you know This is why it's called dot prod MB is our prior is that this is something where we think naive Bayes is a good prior Right and so naive Bayes says that are equals P over That's not how you write P P over Q.
I have not had much sleep P over Q is a good prior and not only do we think it's a good prior But we think our Times X plus B is a good model That's that's the naive Bayes model. So in other words, we expect that You know a coefficient of one is a good coefficient not not four thousand Yeah, so we think specifically we don't think we think zero is probably not a good coefficient All right, but we also think that maybe The naive Bayes version is a little overconfident.
So maybe one's a little high So we're pretty sure that the right number assuming that our model a naive Bayes model is as appropriate is between zero and one No, but what I was thinking is as long as it's not zero you are pushing those Coefficients that are supposed to be zero to something not zero and makes the Like high coefficients less distinctive from the mode coefficients Well, but you see they're not supposed to be zero.
They're supposed to be our Mike that's that's what they're supposed to be. They're supposed to be our right and so and remember This is inside our forward function So this is part of what we're taking the gradient of right? So it's basically Saying okay, we're still gonna you know, you can still set self dot W to anything you like But just the regularizer Wants it to be zero and so all we're saying is okay if you want it to be zero then I'll try to make zero be You know give a sensible answer That's the basic idea and like yeah, nothing says point four is perfect for every data set I've tried a few different data sets and found various numbers between point three and point six that are optimal But I've never found one where point four is Less good than zero which is not surprising and I've also never found one where one is better, right?
So the idea is like this is a reasonable default, but it's another parameter you can play with which I kind of like right? It's another thing you could use Grid search or whatever to figure out for your data set. What's best and you know really the key here being Every model before this one as far as I know has implicitly assumed It should be zero because they just they don't have this parameter right and you know by the way I've actually got a second parameter here as well Which is the same thing I do to our is actually divide our By a parameter Which I'm not going to worry too much about it now But again, it's this is another parameter you can use to kind of adjust what the nature of the regularization is You know and I mean in the end I'm I'm a Empiricist not a theoretician.
You know that I thought this seemed like a good idea Nearly all of my things it seemed like a good idea turn out to be stupid this particular one Dave good results, you know on this data set and a few other ones as well Okay, could you pass that?
Yeah, I'm sure a little bit confused about the W plus W adjusted. Uh-huh So you mentioned that we do W plus W adjusted so that the coefficients don't get set to zero that we place some importance on the priors, but you also said that the Effect of learning can be that W gets set to a negative value which in fact really does W plus W Right zero.
So if if we are we are allowing the learning process to indeed set the priors to zero So why is that in any way different from just having W because yeah, great question because of regularization because we're panelizing it by that Right so in other words We're saying you know what if you if the best thing to do is to ignore the value of R That'll cost you you're going to have to set W to a negative number Right so only do that if that's clearly a good idea unless it's clearly a good idea then you should leave Leave it where it is That's that's the only reason like all of this stuff.
We've done today is basically entirely about You know maximizing the advantage we get from regularization and saying regularization pushes us towards some default assumption and nearly all of the machine learning literature assumes that default assumption is Everything zero and I'm saying like it turns out You know it makes sense theoretically and turns out empirically that actually you should decide what your default assumption is And that'll give you better results.
So would it be right to say that? In a way, you're putting an additional hurdle in the along the way towards getting all coefficients to zero So it will be able to do that if it is really worth it Yeah, exactly. So I'd say like the default hurdle without this is is Making a coefficient non zero is the hook hurdle and now I'm saying no the co-op that the hurdle is making a coefficient Not be equal to point four R So this is sum of W square into C Some of it is some lambda or C penalty constant Yeah, yeah time something.
Yeah, so the weight decay should also depend on the value of C if it is very less Like if C is right by say, do you mean this? Hey, yeah. Yeah. So if a is point one, then the weights might not go Towards you then we might not need great decay.
So well that the whatever this value I mean if the if the value of this is zero, then there is no recurization, right? But if this value is higher than zero then there is some penalty right and and presumably we've set it to non zero because we're overfitting so we want some penalty and so if there is some penalty then Then my assertion is that we should penalize things that are different to our prior Not that we should penalize things that are different to zero And our prior is that things should be you know around about equal to our Okay, let's move on thanks for the great questions, I want to talk about Embedding I Said pretend.
It's linear and indeed we can pretend. It's linear Let me show you how much we can pretend. It's linear as in nn dot linear create a linear layer Here is our Data matrix All right, here are our coefficients if we're doing the our vision here our coefficients are right, so if we were to Put those into a column vector like So right then we could do a matrix multiply of that By that right and so we're going to end up with So here's our matrix is our vector Alright, so we're going to end up with One times one plus one times one one times one one times three Right zero times one zero times point three All right, and then the next one zero times one one times one so forth okay, so like that the matrix multiply you know of this independent Variable matrix By this coefficient matrix is going to give us an answer okay, so that's that is just a matrix multiply So the question is like okay.
Well. Why didn't Jeremy right and n dot linear? Why did Jeremy right and n dot embedding? And the reason is because if you recall we don't actually store it like this Because this is actually of width 800,000 and of height 25,000 right so rather than storing it like this we actually store it as Zero one two three right one two three four zero one two five One two four five Okay That's actually how we store it that is this bag of words contains which word indexes That makes sense okay, so that's like This is like a sparse way of Of storing it right is just list out the indexes in each sentence So given that I Want to now do that matrix multiply that I just showed you to create that same outcome Right, but I want to do it from this representation So if you think about it All this is actually doing is It's saying a one hot you know this is basically one hot encoded right?
It's kind of like a dummy dummy matrix version does it have the word this does it have the word movie? Does it have the word is and so forth? So if we took the simple version of like does it have the word this one? Right and we multiplied that By that Right then that's just going to return the first item That makes sense So in general a One hot encoded vector times a matrix is Identical to to looking up that matrix to find the nth row in it Right so this is identical to saying find the zero first second and fifth coefficients Right so they're they're the same they're exactly the same thing and like it doesn't like in this case.
I only have one Coefficient per feature right but actually the way I did this was to have One coefficient per feature for each class Right so in this case is both positive and negative So I actually had kind of like an R positive and an R negative So negative would be just the opposite right equals that Divided by that right now the binary case obviously it's redundant to have both, but what if it was like?
What's the author of this text is it? Jeremy or Savannah or Terrence right now. We've got three categories. We want three Values of R right so the nice thing is then this sparse version You know you can just look up. You know the zeroth and the first and the second and the fifth Right and again, it's identical mathematically identical to multiplying by a one hot encoded matrix but When you have sparse inputs, it's obviously much much more efficient so this computational trick Which is mathematically identical to not conceptually analogous to mathematically identical to Multiplying by a one hot encoded matrix is called an embedding Right, so I'm sure you've all heard or most of you probably heard about embeddings like word embeddings word to back or glove or whatever and People love to make them sound like there's some Amazing you complex neural net thing right they're not embedding means Make a multiplication by a one hot encoded matrix faster by replacing it with a simple array look up Okay, so that's why I said You can think of this as if it said self dot W equals n n dot linear and F plus 1 by 1 right because it actually does The same thing right it actually is a matrix with those dimensions.
This actually is a matrix with those dimensions All right, it's a linear layer But it's expecting that the input we're going to give it is not actually a one hot encoded matrix But it's actually a list of integers right the indexes for each Word or for each item so you can see that the forward function in fast AI Automatically gets for this learner the feature indexes right so they come from The sparse matrix automatically numpy makes it very easy to just grab those those indexes Okay, so in other words there.
We've got here. We've got a list of each word index of a of the 800,000 that are in this document and So then this here says look up each of those in our embedding matrix Which is got 800,000 rows and return Each thing that you find Okay so mathematically identical to multiplying by the one hot encoded matrix That makes sense, so that's all an embedding is and so what that means is We can now handle Building any kind of model like a you know whatever kind of neural network Where we have potentially very high cardinality categorical variables as our inputs We can then just turn them into a numeric code between zero and the number of levels and then we can learn a You know a Linear layer from that as if we had one hot encoded it Without ever actually constructing the one hot encoded version And without ever actually doing that matrix multiply okay instead.
We will just store The index version and simply do the array lookup Okay, and so the gradients that are flowing back You know basically in the one hot encoded version everything that was a zero has no gradient So the gradients flowing back is best go to update the particular row of the embedding matrix that we used okay, and so That's fundamentally important for NLP Just like here like you know I wanted to create a pie torch model that would implement this this ridiculously simple little equation right and To do it without this trick would have meant I was beating in a 25,000 by that hatred the 800,000 element array Which would have been kind of crazy right and so this this trick allowed me to write you know You know I just replaced the word linear with embedding replace the thing that feeds the One hot encodings in with something that just feeds the indexes in and that was it that that it kept working And so this now trains You know in about a minute per epoch Okay so What we can now do is we can now take this idea and apply it not just to language But to anything right for example Predicting the sales of items at a grocery Yes, where's the Just a quick question so we are not actually looking up anything right We are just saying that now that array with the indices that is the representation So the represent so we are doing a lookup right the representation That's being stored it for the but for the bag of words is now not 1 1 1 0 0 1 but 0 1 2 5 right and so then We actually have to do our Matrix product right but rather than doing the matrix product we look up The zeroth thing and the first thing and the second thing and the fifth thing So that means we are still retaining the one hot encoded matrix no We didn't there's no one-hot encoded matrix used here.
This is the one-hot encoded matrix, which is not currently highlighted We've currently highlighted the list of indexes and the list of coefficients from the weight matrix That makes sense Okay So what we're going to do now is we're kind of going to go to go a step further and saying like Let's not use a linear model at all Let's use a multi-layer neural network, right and let's have the input to that potentially be Include some categorical variables right and those categorical variables.
We will just have as Numeric indexes And so the first layer for those won't be a normal linear layer. There'll be an embedding layer Which we know behaves exactly like a linear layer mathematically And so then I hope will be that we can now use this to create a neural network for any kind of data right and so There was a competition on Kaggle a few years ago called Rossman, which is a German grocery chain Where they asked to predict the sales of items in?
their stores right and that included the mixture of categorical and continuous variables and In this paper by Gwar and Birkin they described their third place winning entry Which was much simpler than the first place winning entry But nearly as good But much much simpler because they took advantage of this idea of what they call entity embeddings in the paper they they thought I think that they had invented this actually had been written before earlier by Yoshio Benjio and his co-authors in another Kaggle competition, which was predicting taxi destinations although I will say I feel like Gore went a lot further in describing how this can be Used in many other ways And so we'll talk about that as well So the So this one is actually in the is in the deep learning one repo.
Okay deal one Lesson three, okay Because we talk about some of the deep learning specific aspects in the deep learning course where else in this course We're going to be talking mainly about the feature engineering And we're also going to be talking about you know kind of this this embedding idea So Let's start with the data right so the data was you know store number one on the 31st of July 2015 was open They had a promotion going on It was a school holiday.
It was not a state holiday, and they sold five thousand two hundred and sixty three items So That's the key Data they provided and so the goal is obviously to predict sales in a test set that has the same information without sales They also tell you that for each store It's of some particular type It sells some particular assortment of goods Its nearest competitor competitor is some distance away The competitor opened in September 2008 And there's some more information about promos.
I don't know the details of what that means Like in many Kaggle competitions they let you download External data sets if you wish as long as you share them with other competitors So people oh they also told you what state each store is in so people downloaded a list of the names of the different states of Germany They downloaded a file for each state in Germany for each week Some kind of Google trend data.
I don't know what specific Google trend they got but there was that For each date they downloaded a whole bunch of temperature information That's it, and then here's the test set okay, so I Mean one interesting insight here Is that there was probably a mistake in some ways for Rossman to design this competition as being one where you could use external data?
Because in reality you don't actually get to find out next week's weather or next week's Google trends You know But you know when you're competing in Kaggle you don't care about that you just want to win So you use whatever you can get? So let's talk first of all about data cleaning you know that there wasn't really much feature engineering done in this third place Winning entry like bite bite particularly by Kaggle standards where normally every last thing counts This is a great example of how far you can get with with a neural net and it certainly reminds me of the claims prediction competition we talked about yesterday where the winner did no feature engineering and entirely relied on deep learning the Laughter in the room I guess is from people who did a little bit more than no feature engineering in that competition So you know I should mention by the way like I find that bit where like you work hard at a competition and then it closes and You didn't win and the winner comes out and says this is how I won like that's the bit where you learn the most right?
But sometimes that's happened to me, and it's been like oh I've thought of that I thought I tried that and then I go back and I realize I like had a bug there I didn't test properly and I learned like okay like I really need to learn to like test this thing in this different way Sometimes it's like oh, I thought of that, but I assumed it wouldn't work I've really got to remember to check everything before I make any assumptions And you know sometimes it's just like oh, I did not think of that technique Wow now I know it's better than everything I just tried because like otherwise somebody says like hey you know here's a really good technique You're like okay great right, but when you spent months trying to do something and like somebody else did it better by using that technique That's pretty convincing Right and so like it's kind of hard like I'm standing up in front of you saying Here's a bunch of techniques that I've I've used and I've won some Kaggle competitions And I've got some state-of-the-art results, but it's like that's kind of second-hand information by the time it hits you right, so it's really great to Yeah, try things out and and also like it's been kind of nice to see Particularly I've noticed in the deep learning course quite a few of my students have you know I've said like this technique works really well And they've tried it and they've got into the top ten of a Kaggle competition the next day, and they're like Okay, that that counts is working really well, so so yeah Kaggle competitions are Helpful for lots and lots of reasons But you know one of the best ways is what happens after it finishes and so definitely like For the ones that you that are now finishing up make sure you you know watch the forums See what people are sharing in terms of their solutions And you know if you want to learn more about them like feel free to ask The winners like hey, could you tell me more about this so that people are normally pretty pretty good about explaining And then ideally try and replicate it yourself, right and that can turn into a great blog post You know or a great colonel is to be able to say okay such-and-such said that they use this technique Here's a really short explanation of what that technique is and here's a little bit of code showing how it's implemented And you know here's the result showing you you can get the same result that can be a really interesting write-up as well Okay, so You know it's it's always nice to kind of have your data reflect Like I don't know be as kind of easy to understand as possible So in this case the data that came from Kaggle used various you know integers for the holidays We can just use a boolean of like was it a holiday or not?
So like just clean that up We've got quite a few different tables. We need to join them all together Right I have a standard way of joining things together with pandas I just use the pandas merge function and specifically I always do a left joint So who wants to tell me what a left join is?
Since it's there once go ahead So you retain all the rows in the left table and you take so you have a key column You match that with the key column in the right side table, and you just merge the rows that are also present in the right side Yeah, that's a great explanation good job.
I don't have much to add to that thick the key reason that I always do a left join is That after I do the join. I always then check if there were things in the right hand side That are now null right because if so it means that I missed some things I haven't shown it here, but I also check that the number of rows Hasn't varied before and after if it has that means that the right hand side table wasn't Unique okay, so Even when I'm sure something's true.
I always also assume that I've screwed it up, so I always check So I could go ahead and merge the state names into the weather I can also If you look at the Google Trends table It's got this weak range which I need to turn into a date in order to join it Right and so the nice thing about doing this in pandas is that pandas gives us access to you know all of Python Right and so for example inside the the series object is a dot str Attribute that gives you access to all the string processing functions Not just like cat gives you access to the categorical functions DT gives you access to the daytime functions so I can now split Everything in that column, and it's really important to try and use these pandas functions Because they you know they're going to be vectorized accelerated through you know often through CMD at least through you know C code So that runs nice and quickly and Then you know as per usual let's add date metadata to our dates In the end we are basically denormalizing all these tables, so we're going to put them all into one table so in the Google trend table There was also though they were mainly trends by state, but there was also trends for the whole of Germany So we kind of put the Germany own you know the whole of Germany ones into a separate data frame so that we can join that So we're going to have like Google trend for this date and Google trend for the whole of Germany And so now we can go ahead and start joining Both for the training set and for the test set and then for both checks that we don't have zeros My merge function I set the suffix if there are two columns that are the same I set the suffix on the left to be nothing at all So it doesn't screw around with the name and the right hand side to be underscore Y and in this case I didn't want any of the duplicate ones, so I just went through and Deleted them okay And then we're gonna in a moment.
We're going to try to Create a competition you know the the main competitor for this store has been open since some date Right and so you can just use pandas to date time passing in the year the month and the day Right and so that's going to give us an error unless they all have years and months So so we're going to fill in the missing ones with the 1900 and a 1 Okay, and then what we really know it we didn't want to know is like how long is this store been open for?
At the time of this particular record all right, so we can just do a date subtract, okay? Now if you think about it sometimes the competition You know opened later than this particular row so sometimes it's going to be negative and it doesn't probably make sense To have negative spending like it's going to open in x days time now having said that I would never Put in something like this Without first of all running a model with it in and without it in right because like our assumptions about About the data very often turn out not to be true now in this case.
I didn't invent any of these pre-processing steps I wrote all the code, but it's all based on the third place winners github repo, right so Knowing what it takes to get third place in the Kaggle competition I'm pretty sure they would have checked every one of these pre-processing steps and made sure it actually improved there their validation set score Okay So what we're going to be doing is creating a neural network where some of the inputs to it are continuous and some of them are categorical and So what that means in the in the neural net that you know we have We're basically going to have you know this kind of initial weight matrix right and we're going to have this This input feature vector right and so some of the inputs are just going to be plain Continuous numbers like you know what's the maximum temperature here, or what's the number of plumbers to the nearest store?
And some of them are going to be One hot encoded Effectively right, but we're not actually going to store it as one hot encoded We're actually going to store it as the index Right and so the neural net model is going to need to know which of these columns Should you should you basically create an embedding for which ones should you treat?
You know as if they were kind of one hot encoded and which ones should you just feed directly into the linear layer? right and so We're going to tell the model when we get there Which is which but we actually need to think ahead of time about like which ones?
Do we want to treat as categorical and which ones are continuous in particular? Things that we're going to treat it as categorical We don't want to create More categories than we need all right, and so let me show you what I mean the The the third place getters in this competition Decided that the number of months that the competition was open was something that they were going to use as a categorical variable Right and so in order to avoid having more categories than they needed They truncated it at 24 months.
They said anything more than 24 months. I'll truncate to 24 So here are the unique values of competition months open, and it's all the numbers from naught to 24 right So what that means is that there's going to be you know an embedding matrix That's going to have basically an embedding vector for things that aren't open yet for things that are open a month So things that are open two months and so forth now They absolutely could have done that as a Continuous variable right they could have just had a number here Which is just a single number of how many months has it been open?
And they could have treated it as continuous and fed it straight into the initial weight matrix what I found though and obviously what these competitors found is Where possible it's best to treat things as categorical variables All right And the reason for that is that like when you feed something through an embedding matrix?
You basically mean it means every level can be treated like totally differently Right and so for example in this case whether something's been open for zero months or one month is Right really different right and so if you fed that in as a continuous variable It would be kind of difficult for the neural net to try and find a functional form that kind of has that that big difference It's possible because neural nets can do anything right, but you're not making it easy for it Where else if you used an embedding treated it as categorical then it'll have a totally different vector for zero versus one Right so it seems like particularly as long as you've got enough data that The treating columns as categorical variables where possible is a better idea And so I say when I say where possible that kind of basically means like Where the cardinality is not too high You know so if this was like You know The sales ID number that was like uniquely different on every row You can't treat that as a categorical variable Right because you know it would be a huge embedding matrix and everything only appears once or ditto for like kilometers away from the nearest store To two decimal places you wouldn't make a categorical variable, right?
So that's kind of the that's kind of the rule of thumb That they both used in this competition in fact if we scroll down to their choices Here is how they did it right they're continuous variables with things that were genuinely Continuous like number of kilometers away to the competitor the temperature stuff Right the number you know the specific number in the Google trend, right?
Where else everything else basically they treat it as categorical Okay, so that's it for today, so yeah next time. We'll We'll finish this off. We'll see we'll see how to turn this into a neural network and Yeah, kind of wrap things up so see you then