Kimi-K2 Tech Report (Full Breakdown /w Vibhu Sapra)
Transcript
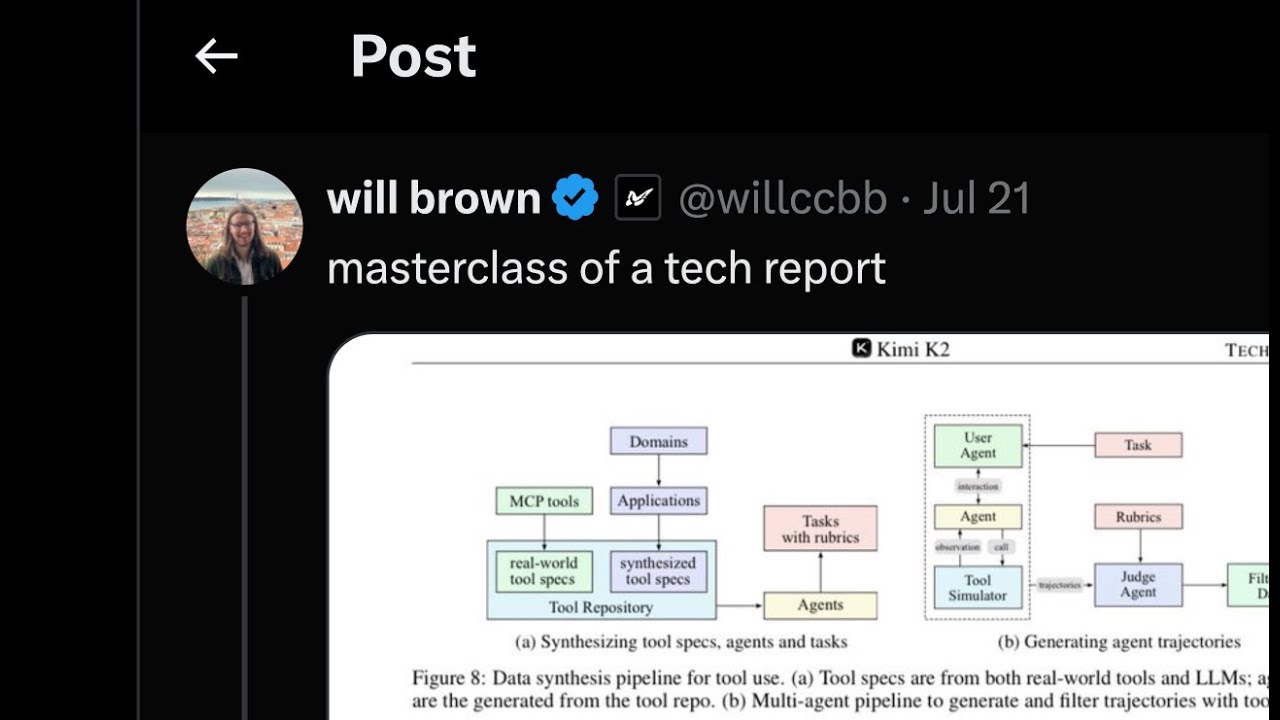
the luma said okay give me k2 um last week we went over the original muon paper so basically the the really cool thing if anyone has seen it or trained models is figure three they have a very very smooth loss curve uh normally when you train there's big spikes big spikes are not good because you have to kind of like intervene see like okay is the model kind of cooked do we have to roll back do we have to go to a new checkpoint do we have to fix stuff that's like kind of where you have to stop your training and like your gpu utilization gets kind of cooked what they did is they have a new optimizer that gives us really really smooth loss curves with like no spikes throughout the entire training process this is kind of crazy um i won't go super into detail on the optimizer since last week we we basically covered it so i think the recording is already up on youtube uh if you're interested watch it but okay give me k2 who's uh who's used it who's heard of it who doesn't know what it is um if anyone wants you know to just interrupt me whenever and we can we can answer questions so basically this is like state of the art open source model it's very very big um i'm gonna check chat real quick okay nothing nothing about this so basically this is a trillion parameters um it's not a thinking model but it's like deep seek v2 moment uh like the second deep seek moment um what they did is basically it's like better than claude on all coding benchmarks better than like anything it's very very state of the art it's not thinking and it's a it's a very good uh non-reasoning model it's very open source they shared um they shared this optimizer that's basically like a better atom w and um this this week we just got out the actual tech report paper it's decent honestly um it's like the first highlight of once again how do you train a very very large model so it's like kind of a pre-training post-training how do you train a large model and then the interesting note here for me was you get to see the problems of using china chips like they have the h-800s right because there was an export restriction so these chips are like different than um you know interconnected nodes and what do they do to come around that i think like two weeks ago we covered we covered the other reasoning paper um magistral the reasoning paper from mistral and they show how they can just like skip some of these issues for full gpu efficiency um but yeah here's kimmy k2 so uh trillion parameter huge huge trillion parameter model with 32 billion active parameters very very sparse uh they talk about the sparsity they talk about like experiments they did for sparseness ratios and all this stuff it's pre-trained on 15 trillion tokens they use a muon clip optimizer this is basically like all the hot news they they put out a separate paper about this before um what this basically leads to is very very good um training stability so uh they have this qk clip technique where they're they're kind of clipping attention gradients and and yeah it's just very smooth smooth training okay so trained on 15 trillion tokens uh trillion total parameters 32 billion active parameters very sparse um and then the big thing here is zero loss spikes which is kind of crazy um during post training there's multi-stage process uh they they do a lot of synthetic data work another fun thing i would recommend about this people paper for people is they do good citations into other work so if you're interested in different um like synthetic data generation pipelines they they cite quite a few cool papers there's a few in there that are like good citations i'm gonna follow up and read uh estimates on the compute used in training this yeah i think they actually say how much compute they used how much how much training compute uh how many gpus and stuff they had now it doesn't that doesn't account for a lot of the experiments they have a lot of like ablations and stuff they have a lot of data generation i don't know if that necessarily ties into how much they used for it right they share a decent amount of numbers but they don't share everything um yeah so large synthetic data synthesis pipeline and a joint oral stage honestly i found this model a little confusing because everyone calls it not a reasoning model and like sure it's not reasoning per se where it's like grpo like rollouts just like proper rl to think but they do have a lot of like rl to think so i don't know where the line blurs and i think this is a discussion we can have later and i'd love to hear people's thoughts but like i would semi call this a reasoning model like it it reasons and it's trying to reason with a like similar grpo with with some um with some changes but yeah it's a state-of-the-art very very good coding model you can plug it into cloud code and stuff um so we bench verified 65.8 it's like right up there with opus 03 all that stuff um and it's very sparse you know it's it's sparse it should be cheap for people that host it for inference um on everything else it's pretty good it's very open source they give base model and post train checkpoints um it's nice they do base model evals as well what's the difference between a reasoning and a thinking model yeah that's a good question mostly we don't call stuff thinking models we just have reasoning models and on reasoning models in this case i would consider this thing to be like a reasoning model but yeah i guess there's just think tokens they just take out the think tokens and they just let it kind of reason um performance pretty good i think we can cover charts later let's just get through the paper for now but if anyone's interested in diving on any of these we can we can kind of look at it um but yeah you know like coding benchmark basically up there with opus um the one that just beat this recently so like the the cool thing with this paper is it beats deep seek in like across the board on everything um as of a week later quen quen reasoning sorry quen coder beats this at coding which is cool so you know stuff is moving fast uh they basically reran a bunch of benchmarks except for opus opus they just took their their numbers i think open hands help them once we've been verified so shout out to them at the end but um opus was expensive to benchmark it's it's crazy how expensive benchmarking is so but good for them to do it uh basically in the introduction they go a little like um you know broader and they want to explain what are these terms so they have this um they have this like vision of agentic intelligence right uh models are no longer static like they don't just do next token prediction they're they need to be agents so they need to like evolve from static understanding of what they know and they need to be able to plan reason act in environments use tools and stuff so a lot of what they want to do and like you know dynamically adapt to these um environments so what they basically want to train a model that's really really good at tool use so um they they train it on a lot of like environments agentic tool use uh they generate a lot of these tools and they wanted to acquire skills beyond training distribution and adapt behavior through experiences so like this is kind of like the motivation for why this exists uh you know this thing should be be able to pick up tools really good and like when i mentioned there's good citations of papers for like synthetic data gen they also have stuff that's like here's what we were influenced by in tool use papers here's like four papers that do really good tool use and here's how we build upon that so you know if you're interested in tool use stuff you should probably read the other four papers um okay achieving agentic intelligence in quite introduces challenges in both pre-training and post-training um pre-training must in endow models with general purpose priors and effective token efficiency learning per signal post-training must transform those priors into actionable be actionable behaviors yet agentic capabilities such as multi-step reasoning long-term planning and tool use are rare in natural data and costly to scale so what this is saying is basically um you need a decent enough base model to do all this stuff and for post-training like this data is not really existent and it's like hard to scale right so like we don't really just have a lot of multi-step reasoning long-term planning tool use data so um you know they do a lot of scalable synthetic data gen uh okay paper uh model big big model trillion parameter moe with 32 billion active parameters there's there's a few major major things here uh muon clip which is their new novel optimizer it's basically better than um adam w this was introduced like quite a while ago but it was trained at small scale and it wasn't really scaling very well so in this paper they they show scaling up this optimizer and sort of having uh gradient issues in attention so the way they solve it is this kind of um stability enhancing qk clip where they're they're clipping off a lot of attention um a lot of attention weights so from there um it's kind of crazy they don't have a single loss spike very very beautiful training curve okay then they have a lot of stuff on their data gen so a large scale agentic data synthesis pipeline i thought this was like kind of basic i'm surprised how much it just works but um pretty cool stuff on synthetic data gen basically they generate a lot of tools tool demonstrations tool descriptions and then they have environments for it to use this stuff and they have like verifiers and in the middle step verifiers but it's it's like a cool pipeline that they use for all this uh data gen why why do you think it was basic i mean we'll we'll go into how it is later and how it's evaluated um i i thought it's like like the verification of some of this stuff isn't that crazy you know yeah it's a it's a lot of rubric based i'm surprised it just kind of works you know um especially at the scale and like how they achieve diversity like from the techniques they explain i wouldn't expect the amount of diversity that makes this actually work out but let's we'll dive into it in a bit you know yeah a consistent question i have for folks is that how do you evaluate on non-verifiable reward like essentially things that are not code or software and everyone's just saying rubik base would work and i think it's like an example of hey you know rubik base actually does work uh yeah i'm surprised that that's all you need they they talk about this specifically so for stuff like creative writing and stuff um they you know they share how they how they generate this pipeline is it true they used mcp tool architecture outputs yeah they basically have a whole bunch of mcp stuff so they scrape like a thousand mcp tools and then they they generate it even more so mcp is all you need in this um we'll get into it later and like actually they have a a stator plot of different tools um see t-sne visualization of real mcp tools um colored by their original sources so thousands of mcp tools of course they have crypto but um you know this is their mcp tools then they have synthetic tools which are also you know in different domains i love how they just have an unknown domain but they have crypto where it's it's some of the mcp tools but um that's part of it okay okay continuing on um where were we okay they also talk about their rl framework um it's rl with verifiable rewards this is what eugene was talking about it's it's not um it's not just code in math they have it on um they have it on like general domain so like creative writing and stuff okay so kind of interesting they talk a lot about critiquing outputs instead of like grpo where you do rollouts and reward the best output um they just have a lot of critiquing here which is kind of interesting i found their explanation of how they set up this whole loop to be a little confusing so like their training loop it's a little odd but um i don't know maybe someone else had a better intuition while reading it or broke it down or looked into it more but uh they they do share a lot about that okay pre-training 15 trillion tokens um they talk a lot about token efficiency and how it's important basically rl is very token efficient right so guess what do rl um they they talk about pre-training techniques so uh uh effectively this muon optimizer it's very very much a token efficiency thing as well then they have synthetic data gen um of course their ultra sparse moe is efficient uh it's mla so multi-head latent attention which was derived from deep seek and then they make some modifications they actually show scaling laws for how sparse you want moes there's charts of this later uh muon clip so this is the optimizer and what they do um i was thinking we actually just skip this for now since we basically did this last week but if there's time i think we come back um let's see if there's anything basic to say about it so you you know outperforms adam w better token efficiency um leads to training stability constraint attention logits so attention was having issues we constrain it apply kipping to unshared attention ads yeah i think we go over this later let's just go through the paper first unless anyone wants to ask a specific question or eugene do you want to say anything about it okay let's just move on since we basically did it so if you're interested um why they're covered at the end or check last week's thing okay uh pre-training data improving token utility with rephrasing it's interesting how much they just did rephrasing like they show cool little experiments here of um rephrasing versus uh repeating for multiple epochs and how their their strategy is kind of better so token efficiency refers to how much performance improvement you can get out of each token consumed during training increasing token utility the effective learning signal for each token contributes is pretty important right so that's something that they want to focus on naive approach is basically just do more epochs right um eugene question comment you're muted oh sorry not a question i think you briefly glance at our table we will go through it uh when we go through the table i think the table is absolutely insane where the delta between the second row and the first row essentially almost answers all of the game um but we can talk about it when you get here yeah yeah it's interesting um so basically like you guys know what multiple epochs are right so you you you take your let's say you have a thousand samples you train for 10 epochs you train on the same data 10 times um so that's one naive approach another so they compare to that um you know you do get some gains from doing multiple epochs and it's somewhat common for some some data like for your base pre-trained we don't do multiple epochs anymore we used to um for some higher quality data like some some some high high quality reasoning we'll we'll do it for multiple epochs and do the same data multiple times but here's kind of what they do um a key advancement is synthetic data gen to increase token utility so they have this core rephrasing pipeline um basically instead of just train on the same same data multiple times let's kind of rephrase it a little bit there's two two domain specialized rephrasing techniques that they use for knowledge and math so knowledge data rephrasing a single epoch is insufficient for comprehensive knowledge absorption while multi-epoch repetition yields diminishing returns in the risk of and increases the risk of overfitting so um we'll get to a chart in a bit but let's talk about what they do so first is style and perspective diversity prompting so uh prompting guide is you take an llm to generate free uh faithful rephrasing of the original text in very in various styles from different perspectives then there's uh chunk wise auto regressive generation basically if stuff is very long just do it in chunks so rephrase segment by segment then adopt uh auto aggressive like chunking fixer so divide text into segments rephrase them individually stitch them back to back to back together and fix that there's there's like a little pipeline on there's a little diagram on this later um to ensure consistency between original and rewritten content there's fidelity checks that compare the semantic alignment of the rephrase page with its source um yeah cool so basically they do all this then they run a little experiment so let's compare how this performs in the set in the sense of token efficiency so there's three three things that they do one is you take your original data set you train on it for 10 epochs uh risks here are you know you might overfit your data so you might overfit and it might just you're not really adding more quality you're just doing the same thing multiple times two is rephrase the data once and repeat it for 10 epochs so basically you take all your data rephrase it in a different sense and then you train for 10 epochs uh three is rephrase the data 10 times with a single pass of training and here's kind of the results um we extend this method towards larger stuff and you know each corpora is rephrased at most twice so 10 epochs on same data they they test it on simple qa they get 23.
just rephrasing it once and training it for uh sorry rephrasing it once and training it for 10 epochs gets you quite a bit of improvement then there's rephrasing it 10 times and doing one epoch you still get a little bit more improvement but you know the main difference like eugene said is just here rephrasing makes quite a difference am i reading this right when actually the first row and second row each of them are 10 epochs but the difference between the second from the first row is essentially the second row actually does data cleanup by rephrasing it it's not data cleanup it's data augmentation so i think they keep both the original data and rephrase oh i see so they keep both okay i was reading it wrong i thought the first one was raw 10 epochs the second one is only rephrased 10 epochs um we could you could be right here yeah because yeah i read it so what eugene is saying is you know in the the the benefit just comes from rephrasing what i read this as is keeping the original and rephrasing it i think i'm right because if you look at the paragraph it says rephrasing the data once repeating it which i think as it as the rephrase data if you look at the third line which is uh so that is actually cleaning up the data to be better that's all the juice uh so that's pretty that's pretty mind-blowing to me that someone they did this ablation so that's really nice yeah beautiful little um ablation basically rephrasing you get so much data quality improvement but the reason i interpret it the way that i did is because um you know i thought that 10 10 epochs of the same data is basically just the same data um adding in another look and doing it for tiny box gets you better performance but i think we'll dig into it later somewhere at the bottom they have um they have a lot of this in the appendix i wouldn't be surprised if they talk more about it well we'll have to check um this is our kind of chunking for long context diagram basically you know chunk it rewrite and then merge it and check but nothing crazy there i had a question on this actually this diagram um i'm thinking a lot of time but uh in the third column let's say we rephrase partial input one what does it mean to be auto regressive oh like you're adding in the first chunk and the second chunk like you're using the first chunk to write the second chunk i think so um here chunk based auto regressive strategy texts are divided into segments rephrased individually then stitched back together to form complete passages this method mitigates implicit output length limitations um the auto regressive part i think is let's see so so when i read the paragraph i read it as okay we've split in the paragraphs you rephrase it and we just smash it back together but i realized that the first few phrases makes a lot of difference to maintain global coherence i think what they're doing here is they're rephrasing the first paragraph add the first paragraph and the second part at the new first paragraph and the raw second paragraph and ask it to rewrite the second paragraph and i think by doing this it keeps the style of the first paragraph but i want to make sure if i'm understanding this right that's how i'm interpreting it too uh the input is spent to small objects with preserved context rewritten sequentially then concatenated into a fully rewritten but um it could be the other way too which wouldn't be as good if it's the other way then it doesn't have to be sequential right if it's there if you just do everything you can just be parallel the fact that is i yeah anyone also the graph the graph also shows they are feeding the the previous segment into the rewrite step so so like the second rewrite model has like two inputs it has the like original segment and then also the rewritten previous segment i think so so that's it if we are rewriting the last chunk do we pass in everything or do we just need to pass in the last chunk minus one and this is just last minus one right you can see it yeah it looks like partial except two right yeah so okay i think one one one's not going into three but one is kind of already seen this is extremely valuable uh this this diagram itself says a lot about how you can process long context data uh so i think you could do better really basically yeah that's just like yeah you could pass in multiple chunks you could do a better long context rewrite like this is not super efficient yeah you're right it's not super efficient yeah yeah yeah it also depends on how long context documents you have right so like at a certain yeah so i mean there's interesting stuff there but the the interesting note is the majority of the training was done at pretty short context actually um exactly i was so surprised 4k context only so but okay i'll let you get it there i'll stop interrupting i mean no no it makes sense right like it's a trillion tokens it's a trillion sorry trillion parameters it's a big model like um that context really adds up so they do context length extension later i also just don't think that we have 15 trillion like even trillions of tokens of really long context right like that just doesn't exist um and it's so much more exponentially expensive to train at long context um okay so uh basically they rewrite high quality math into learning note style so instead of just question answers you know here's a learning note of how i would solve this uh translate high quality map into other languages this is standard seen in other work as well okay overall they have 15 trillion tokens i thought this was interesting they have web text code math and knowledge um i don't know what knowledge is but they have knowledge for each domain we perform rigorous correctness and quality evals you know standard filtration stuff a lot of rewriting though okay 32 billion active parameters similar to deep seek v3 they use mla um is our attention to external hidden dimension of this okay so scaling law analysis reveals that continued increase in sparsity yields substantial performance improvements which allowed us which motivated us to increase the number of experts to 384 instead of 256 in v3 to reduce computational overhead during inference we can we cut the attention heads to 64 instead of 128 so they do scaling laws to reveal that um you know based on the number of active parameters you want increasing sparsity so um taking the same number of active parameters but increasing total experts is very um is better performance uh and they um so you know they increase experts and they cut the attention heads in half this helps with their training stability so their new optimizer um had issues and they they cut attention heads in half okay this is um you know similar to deep seek so more total parameters less active parameters more experts less attention heads only one dense layer which they don't talk much about here's their sparsity scaling law um sparse oh one sec don't be right back oh no oh no oh no that's mochi need to get out of the room or that's what you need to get into the room what he has always has needs um mochi's fomo from paper club oh mochi's here no she just needs papers what you can tell with us all right okay sparsity is the ratio of um total experts compared to active experts uh 48 is their magic number but um basically what is this they have uh 384 um 384 total experts and 16 and let's read to this okay sparsity is the ratio of total number of experts compared to a number of factors under so this is the scaling law basically that they find under a fixed number of active parameters uh basically in this case the 32b active parameters that they want to set um increasing the total number of experts in basically making it more sparse consistency consistently lowers both the training and validation laws thereby enhancing overall model performance um they do these experiments um increasing sparsity leads to better performance it also adds infrastructure complexity um there was a semi-analysis paper on like why llama 4 failed and they talk a lot about moe stuff and their expert choice routing versus token choice routing and all these stability issues and infrastructure and how they get and how they changed halfway through but yeah when you make stuff more sparse and you have like uh stuff like that then then you need to you know you need to deal with infrastructure complexity so they have a sparsity of 48 achieving um activating eight out of 384 experts per forward pass um here's kind of their their laws so increased sparsity better performance doubling the number of attention heads they also checked it didn't take much of a hit i think this is the next section uh frankie you have hand up oh yeah i just want to ask um maybe more of an interpretive kind of uh question here so they found that increasing moe is and decreasing number of heads um it is better so could the interpretation be that um the tissue heads are essentially kind of like mixing stuff from your context the moes is kind of figuring out what you do with that mix so i think maybe it's saying that the expressivity of what you should do with the mix is more important than the mixing itself that is you can kind of like get raw stuff from your neighbors but you should be smarter about what you do with it would that be a correct interpretation and it's kind of hard but what do you guys think um two things so one the attention head is not actually it's not necessarily better to cut them they did it for training stability so the the dots here are lower loss but double the attention head so um more attention heads actually helps performance it's just not much like they say it's a doubling the number of attention heads led to a reduction in validation loss of 0.5 to 1.2 percent so it's still better it's not worse to have more attention heads it's just a lot more um it's a lot more complexity so so here's a here's a cool quote so with the sequence length of 128k doubling the attention heads from 64 to 128 while keeping the total expert count fixed leads to an 83 percent increase in inference flops so you're nearly doubling the compute required for inference by doubling your attention heads but the performance increase is very small and uh it it had instability issues with their optimizer this doesn't mean that um adam w with more attention heads isn't stable but you know it's it's a big uh compute cost so something to note there regarding the analogy i think i need to read uh hear it again i don't know if someone else wants to comment or maybe you want to post it in the chat but i i didn't really digest and if someone else wants to comment you know pop in i wanted to ask is it more of the experts or the attention heads that we're you know being optimized for here this is both um so they're keeping it sparse by uh having a lot of experts but only a few active that's one part of the equation that's in their scaling laws better performance so if you have a set of if you have a fixed inference budget like let's say i want to run this thing at 32 billion active parameters uh you'll do better by having more total experts so that's part of it the that's for performance right that will get you better overall performance even though it has training complexity the attention heads is uh inference optimization so you know when you cut attention heads um you have less kvs right each attention head basically has to do kvs and over long sequences kv is quadratic scaling and that's that's a lot of gpu utilization if you can cut half you can kind of cut half of your kv cache which is a lot of gpu usage uh eugene it seems like you have good intuition you wanna wanna you wanna wanna intuit no i i don't know if i have good intuition but my thinking is that attention heads are just like an ensemble and beyond a certain number they found that you know from 68 64 to 128 they say that yes while it does improve validation loss um like it's over there uh only validation loss improved by half a percent to 1.2 percent and okay given that fixed amount of compute they rather not double they rather half the attention hits and have more experts so it's a compute trade-off which makes sense to me i think i think that makes sense no no i think that makes sense the difference here is also just um the architecture right so we're operating on trillion parameter and 384 experts now does this scale to dense models does this scale to a small 24b who knows i think that's um you know we'll have to figure that out but um it's it's verified in their case i don't know if you can take this at face value for for other architectures and other sizes um but you know i highlighted this in green it's important very very useful cutting attention head saves a lot of compute at long context but once again attention is a problem at long context this is like my one concern for like uh transformer alternatives and stuff uh you guys really need to train at long context right because the benefit of your like getting rid of attention and swapping it in with something like recurrence states that's cool but it really only makes a difference at long context at short context it's not that deep and you know train at long context even though you're not very gpu rich do it anyway okay uh training infrastructure this was cool if you care about trade restrictions so basically nvidia didn't allow h100 h200 exports but china had the custom h800 gpu um then this is their training node so uh each node in the h800 cluster contains two bare two terabytes of ram and eight gpus connected with envy link and envy switches within nodes across different nodes eight um g8 400 gig roce interconnect they talk about stuff with like pcie offloading saving to disk uh weight optimization so basically the thing that magistral did was really efficient to just keep rollouts 24/7 uh with this scale of trillion parameters they they did a lot more offloading to dram and stuff um apparently h200s are coming to china soon nvidia is winning um actually like there was a post about this where everyone was like i don't know why deep seek had such a big impact on like nvidia stock because guess what h800 is still nvidia like it's it's all nvidia at the end of the day but um what's she trying to jump off table but you stay this is mochi mochi's the non-expert doggo but she's learning to be expert okay um parallelism for model scaling i don't know if we have that much time left for this so maybe i go through this section quickly and we come back if we have time um i like this i nerded out over this in the magistral paper uh do the rl part i think the rl and data gen stuff is more fun watch you come here okay um i was gonna read a lot of this but let's let's skip it for now um basically there's three things they do uh combination of 16-way pipeline parallelism 16-way expert parallelism and zero one data parallel a lot of this is just like if you're ever interested in how big models are trained you should read this section it's kind of cool here's what they have to go over activation reductions with glue okay fpa for more intensive off but what else cpu offloading training recipe this was interesting so training recipe um they mostly train at 4 000 token context window using their new optimizer um total of 15 trillion tokens the first 10 trillion tokens were you know standard learning rate small warm-up then the last 5.5 trillion tokens they had cosine dk weight dk was set global back size was pretty large 67 million tokens per bat crazy uh figure four is there figure four that i skipped over these figures were very odd um the rewrite takes both previous and the current segment okay that's that's relevant right now okay so uh most of the training was done at short context then towards the end they had an annealing phase followed by long context activation activation stage bat size still 67 million tokens uh learning rate was decayed quite a bit more in this phase we trained 400 billion tokens with a 4k sequence length followed by an additional 60 billion tokens on 32k sequence then they extend with yarn so basically like you know 60 billion out of 15 trillion tokens are at 32k sequence um very very much like the majority of this training is just done at 4k context post training um muon is still used in post training if anyone's fine tuning kimmy k2 you should also still use this muon optimizer don't don't use adam w it's cooked um i think there's a chance so like one of the co-founders of xai is jimmy ba who who worked on the adam w optimizer it's like his big thing um what are the odds that these people get coached to xai because they like optimizers um who else elon is trying to coach carpathy again but that's side t okay uh sft so um there's instruction tuning data set maximizing probability of fire response data gen pipelines for different tasks in different domains so they use kimmy k 1.5 their in-house domain specialized expert model to generate candidate responses for various tasks followed by llm or human judges to perform automated query evaluation and filtering uh for agentic data we create a data synthesis pipeline to teach models tool use capabilities through multi-step interactive reading this stuff is pretty interesting um this is like really the nice meat of this paper i think um okay large-scale agentic data synthesis for tool use um basically we we need llms to be able to autonomously figure out how to use unfamiliar tools uh interact with external environments and iteratively refine their actions to reasoning execution and error correction so here are some papers that you should check out about how to train uh tool use and tool use evaluation so tool lm ac bench and then same thing with um synthetic data so um real world environments rich so difficult to construct at scale complexity privacy accessibility recent work on synthetic data gen agent instruct self-instruct and stable tool bench and zero search i think we covered agent instruct and self-instruct uh two new ones that they talk about here that if you're interested in synthetic data gen you should probably check out uh stable tool bench and zero search they show promise in creating large-scale data training without relying on real-world interactions it's all synthetic they have a pipeline that simulates real-world tool use scenarios at scale uh enabling the generation of tens of thousands of diverse and high-quality training examples okay three stages in uh data synthesis pipeline tool spec generation so step one is you know first construct a large repository of tools from both real-world tools and lm uh synthetic tools agentic and task generation for each tool sampled from the tool repository so they have like thousands of tools by the way by the way generate an agent to use a tool set and some corresponding tasks then trajectory generation for each agent and task generate trajectories where the agent finishes a task by invoking tools um here are some of those tools so they have a bunch of real mcp tools they kind of do a distinguish they kind of like filter them out by category so some search tools database tools uh communication r d then here's their synthetic tools we'll go over this soon um first we directly fetched 3000 plus real mcp tools from github repositories leveraging existing high quality tool specs uh the interesting thing with mcp tools is like they don't really say how they verify that these are high quality tools right you can have non-high quality mcps there's no like great standard over this but they don't mention much filtration over this uh second we systematically evolve synthetic tools through a hierarchical domain generation process we begin with uh key categories so they they have a they have like a they basically have like a categorizer that that categorizes different tools in different domains they start with that so uh then we evolve multiple specific application domains with each category specialized tools are then synthesized for for each domain with clear interfaces description operational semantics so get a bunch of tools classify them in categories um then evolve multiple specific application domains with each category then tools are synthesized they produce over 20 000 synthetic tools across different domains um both mcp and synthetic tools cover complementary regions okay agent diversification seems like generating all these synthetic tool workflows would take a ton of compute yeah there's a lot of inference that goes under this stuff um okay agent diversification so we just casually generate thousands of distinct agents they synthesize various system prompts and equip them with different combinations of tools from our repository when i said that this is kind of basic eugene this is kind of what i meant like i didn't expect stuff like this to just work like sure you can get a bunch of tools um generate different categories and expand them out i didn't expect diversity in these 20 000 tools but this is what i really didn't understand they just generate thousands of distinct agents with different combinations of tools from their repository and you know from this they have rubrics of different stuff that they should be able to solve and all this kind of just work they have varied capabilities areas of expertise behavior patterns ensuring a broad range of uh potential use cases and then before you know this is the last section for each agent config we generate tasks that range from simple to complex operations each task is paired with an explicit rubric that specifies success criteria expected tool use patterns i don't know how they just generate tool use patterns because if you can do inference to you know figure out what are the tool uses you kind of don't have the best quality data right because like you can kind of solve the task i guess but like i get matching a task with tools but not tool use pattern rubrics uh and then evaluation checkpoints rubrics ensure consistent and objective evaluation of agentic performance um this is kind of interesting you know yeah i get that i think um i think of this as like a huge synthetic data etl pipeline where you could be creating a hundred traces and through your quality evaluation and filtering we don't know to what extent how strict they do it but they could be filtering only to the best 10 or the best five even they talk about their filtration actually a bit like in some stuff like in in magistral they talked about like they they get rid of stuff that mr large could solve they have a they have something here that talks about yeah they have something here whereby they actually use an sft model and if the sft model is only when the sft model is not able to solve it then they keep it uh so it's really interesting the data cleaning and data generation that they do yeah it's like it's cool it's there i think this paper could be a bit worded better but it's still cool it's still like nice that they that they explain all this okay so uh multi-turn trajectory generation they simulate real tool use scenarios user simulation so basically um you know lms are personas with communication styles like one might be moody one might be authoritative one might be stupid one might be like phd level smart um and preferences they they have multi-turn dialogues with agents creating naturalistic interaction patterns uh tool execution environments so there's a tool simulator so it's kind of cool they talk about like their sandbox here um a sophisticated tool simulator functionally equivalent to a world model they have ag i guess they have a world model they execute tools and provide realistic feedback simulator maintains an update state after each tool enabling complex multi-step interactions so this is like if you think of like web arena and stuff like that where you kind of have like a fake website and you're shopping through uh instead you have a simulator that might have like tasks and as you make as you interact and do stuff and use a tool the simulator keeps state section by section this is kind of cool i wish you could have talked a bit more about this um it introduces controlled stochasticity to produce varied outcomes including success partial and edge cases so you know you're actually changing an environment a lot of this is like gym motivated style um but you know very cool like they they have all of this um lm-based judge evaluates trajectories against task rubrics only trajectories that meet success criteria are retained for training ensuring high quality data while only allowing natural variation and test completion um interesting little section there yeah i i i yeah i'm sorry jump the gun i thought the hybrid approach uh which is what you're going to talk about nick is amazingly cool because they fine-tune their the judge on verifiable code and then what they say is that from this verifiable code the model is able to learn subjective eval actually wait am i looking at the right section sorry guys what is confusion is this the section yeah i i had a note somewhere uh give me a second let me check it i'm gonna cover this for now so uh yeah go ahead there's inherent limitation to simulation fidelity we complement our simulated environments with real execution sandbox they talk about scraping a lot of like real github issues uh they want real authentic like stuff right so encoding and software engineering uh they have execution sandbox these execution sandbox execute actual code interact with genuine development environments and provide ground truth feedback for objective metrics and test suite pass rates uh this allows them to learn from diversity of simulated scenarios and authenticity of fuel execution significantly strengthening the practical agent capabilities so in this hyper uh pipeline i don't think this is the section you're talking about eugene but you're right sorry it's the section on close loop yeah we get to that when we get to that okay i think i'm gonna go a little fast because we're running short on time but basically uh you know rejection sampling so get rid of the the ones that are easy quality filtration sft has demonstrated improvements for tool use okay oral um better token efficiency than sft this is understood uh they have a gym like extensible framework that facilitates rl across a wide range of scenarios uh tasks with verifiable rewards subjective preferences such as creative writing open-ended question answering we introduce a self-critique reward in which models perform pairwise comparisons to judge its own outputs it's like similar to grpo right grpo you output a bunch of outputs and then you do preference over the group of outputs to what's the best uh this instead is you know you have a self-critique over your output and you judge your own uh output so kind of interesting on how they do rl for creative writing and open-ended questions uh verifiable rewards and gym so i think we can skip some of this for math and stem you know pretty straightforward complex instruction following is this what you're talking about eugene oh no slightly below okay uh we will get it yeah okay so for hybrid rule verification there's um you know evaluation of code interpreters lm is a judge okay multi-sourced instruction generation complex prompts faithfulness uh this was kind of cool they have this um there's this framework of facts grounding there's a sentence level classifier judge that's prompted that's uh useful to perform automated verification basically uh it detects sentences that make factual claims without evidence and context they have this as a bit of the reward in rl so faithfulness coding and software engineering um again this is this part is cool right in the sense that they rephrase the question but they still so care so much about uh factual verification as well as the responses factual verification they are putting so much effort into this as well as the coding as well as they have adversarial prompts for their safety aspects as well safety and faithfulness yeah it's so interesting to see what are the key things and there are some points where they say that the key challenge is faithfulness reducing hallucinations and scaling this so essentially they actually write very clearly these are the challenges we are facing right now um if you if you read between the lines yeah um this was cool basically e2b style or daytona style sandboxing very very robust sandbox infrastructure uh so pr's and issues from github to build software development environments that consist of user prompt issues and executionable unit tests so real github staff has unit tests uh they this environment was built on a robust sandbox infrastructure powered by kubernetes for scalability and security it supports over 10 000 concurrent sandbox instances while with stable performance they just they just cranked that out real quick safety they have uh you know attack model that generates adversarial prompts a target model that produces responses and then a judge that determines if they could bypass the uh safety mechanism each iteration is assessed with a rubric and then it's used in the reward uh 10k concurrent agents it's crazy right okay beyond verification self-critique rubric reward so self-critique rubric reward is what they did uh general rl with self-critique it evaluates its own outputs to generate preference signals um it initializes critique ability in the sft stage since we're kind of out of time i'm gonna like really really quickly do the rest of this and then and then we'll stay for discussion but i guess if anyone has any questions um i guess now's your chance if you have to help or if eugene you want to add in maybe i'll just focus on the the last paragraph in page 12 here um if you read this right the critic model is refined with verifiable signals so they find in the critic model with the verifiable signals they continuously update this critique this transfer learning process grounds so this transfer this transfers subjective judgments allowing the performance gains from verifiable tasks to enhance the critics judgment on complex tasks like explicit reward that's crazy in the sense that you can fine tune essentially you can bootstrap yourself on verifiable reward to train a reward model for non-verifiable reward um how that transfers i don't know i don't know what the intuition is on that but i think there's a lot in this paragraph here on reward modeling and evaluation and the the critique just keeps getting better and better right they update the critiques uh as well and you know it recalibrates its evaluation standards and locks up a policy evaluation so if you if you look at this right right now we are solving verifiable reward like code and software right and the question we always have would this generalize to non-verifiable reward i think this paragraph here says that maybe it would uh in the sense that at least non-verifiable reward is helping non-verifiable reward then our evaluation so we start from there very interesting uh rl has slight modification policy so they have their muon optimizer several additions budget control so they say um properly distributed inference budget we enforce so um they kind of shit on reasoning models rl often results in substantial increase in length model generated outputs um now even though that gives improvement in performance these benefits often do not justify its inference costs in non-reasoning domains so for general stuff you don't want this to encourage the model to properly distribute its inference budget we in first we enforce a per sample maximum token budget draw rl throughout rl training and the budget is determined based on the type of tasks so our task you can reason a little more responses that exceed this token budget are truncated and assigned a penalty this is all done in the formula there watch it um it incentivizes the model to generate solutions within the limit enhances its token efficiency to get concise and effective um solutions ptx loss this just keeps it grounded in previous stuff temperature decay when it starts out you want high temperature so it can explore different stuff then uh you tone it down rl infrastructure um i don't think we have time for a lot of this efficient engine swapping efficient system startup agentic rollout rl infrastructure supports training on long horizon multi-turn agentic tasks tasks present distinct challenges two strategies to play heavy environments okay evals it books um all the evals are done at 4k context yeah um soda very soda i think that's enough red teaming they do some red teaming here limitations um when dealing with hard reasoning tasks or unclear tool definition the model may generate excessive tokens sometimes leading to truncated outputs or incomplete tool calls basically they have it in their rl that if it's too long we just truncate and it's cooked um you know that can lead to it wasting its context and then cutting off at tool calls additionally performance may decline on certain tasks if tool use is unnecessarily enabled when building a complete software project the success rate of one-shot bumping is not as good as k2 and their agent decoding stuff yeah um that's paper sorry um anyone familiar with their rl formula what rl variant is it based on let me check i thought i thought i knew this i think they said it's based on the kimi v 1.5 i haven't had a chance to go through that um okay yeah it is a 1.5 but what is the kimi 1.5 based on uh it's the same the reward model uh so the reward will minus the mean r uh so you can go back so grpo uh it yes it has gpo in it uh but it doesn't go through the partial sequence right so grpo actually go through partial sequence um and this one doesn't just a final okay thank you it looked grpo-esque um any other thoughts questions comments so i was wondering like for the 10 000 agents um it seems like a bit excessive because does it is it the fact that um all these agents are doing something a little bit different like how how does uh uh how does it take yeah do you mean the sandbox execution uh no given that you have so many tools right oh it's 10 000 concurrent sandboxes oh okay i'm sorry which i extrapolated to 10 000 agents running it may be the same agent maybe i think no no i think this is just like when you're training in batch size of like 67 million or whatever you need a way to run your verification and stuff right you need to be able to let this thing talk call tools and like so when you're doing rollouts you're testing how well it can use tools and interact with the environment you have to keep state for these environments now you need a bunch of environments running so this is like you know this is for that it's not it's not 10 000 agents like swarming out to solve stuff maybe more like figure nine right which each dot each dot is like uh a different tool is that correct so basically the synthetic tool right yeah you just had it right there with a bunch of colors yeah right there so yeah figure yes figure nine right so figure nine um they create a lot of synthetic tools and i was wondering like does that diversity really help out that much um of different tools like uh are some of these doing redundant stuff so that's my question yes they're definitely doing redundant stuff right because i mean how many categories do you have here you have 10 000 tools and how many colors do we see i see maybe 30 40 colors so yes tools are doing similar categories of stuff but um it's it's still like even if you have a tool in the same category as long as it has different descriptions different ways to use it different um steps because they don't just look at like their rubric isn't only on full task completion so they have like in the middle uh checks for you know partial partial completion as long as it's using the right tool use like the right steps that's still a good output but i think their sandbox is basically just keeping their environment online and like allowing these tool calls and these different environments to just keep state i guess my question is like are they do they want specifically add so much redundancy because you want the model to better generalize to usage uh because if i was kind of like have this diversity of stuff which does similar things how do i know which tool to even pick right so i'm trying to understand like what's the reasoning there yeah they're pre they're predetermined so in their data gen pipeline they create agents that have um specified what tools they're allowed to use so i think one yes you want diversity and being able to generalize and use different tools but two when they generate the agents themselves they're they're given um different yeah yeah yeah i'll try to find the quote yeah you're saying that they only present a certain number of tools right so that makes sense they're not given everything yeah gotcha so um basically we generate thousands of distinct agents by synthesizing various system prompts and equipping them with different combinations of tools from our repository so it's not like they have access to all 10 000 you probably have an agent that does something that has access to like four tools with varied capabilities areas of expertise and behavioral patterns i know armgard has a hand raised yeah thanks a lot for the amazing walkthrough i just wanted to go back to the point about uh whether this is a reasoning or non-reasoning model i i think this one is non-reasoning because uh one of the reasons i have a gripe with the recent reasoning models is they take too long to give you the answer and there is like an argument about whether we can justify this increase in cost on latency like whether the increase in performance can justify the increasing cost of latency but for this model if you ask it to translate a document from english to french it will give you the french translator translation right away it will not think for 500 or a thousand tokens i i think that's part of it the other approach there is hybrid reasoning and non-reasoning models right like you can you can turn on and off reasoning so like cloud models have thinking and non-thinking modes small lm3 is a specific like recipe to train a hybrid reasoning model basically in that in their rl stage with grpo they mix in stuff that's a subset of reasoning and non-reasoning and they reward them equally but um i do agree like i really think that like they're kind of pushing the cost onto you right like for basic stuff i don't want to pay extra tokens and the the proper like the proper gauge for models right now is no longer priced to um like before it used to be price to intelligence ratio right so how much do i pay for this level of intelligence it's very skewed now right a model can have an intelligence that's very high but it could take twice the cost in the terms of number of tokens to get there the number of tokens to get that intelligence this kind of variable what would be interesting now i think is in some benchmarks if we could include how many tokens were used in reasoning for specific like questions or stuff i don't know a great way to measure this i haven't really thought about it too much but you know what i mean like cost to performance is no longer as relevant because your performance has variable number of thinking for different like models like some models are very verbose in their thinking the deep seek update basically got it for think to think for twice as long which could also mean to you know charge you twice as much but on the other hand like it's a significant performance increase right so like are you really gonna are you really gonna make that trade-off i think in general even though it was forced on people like oh one was the first reasoning model and you didn't have a choice right it's not hybrid like if you want reasoning you're gonna use full reasoning and people were fine waiting an extra minute for performance and the costs always come down but that's just high level thinking in my in my opinion i don't have i haven't given it much more thought yeah that's that's a good argument about cost yeah any other thoughts comments questions anything i missed in this paper sorry i like we yapped too much in the beginning i didn't realize it would take so long i was gonna think it was a quick one it's it's quite a dense paper like lots of stuff to go through yeah um i think they're they're like muon clip stuff is pretty interesting but like there's only a few takeaways right like they do some cool scaling laws basically they do like individual attention head level parameter clipping of optimization and that that leads to really cool scaling the the bigger takeaway of this is like it's very very expensive for labs to do big train runs and like lost spikes are a big detriment because basically if something gets cooked like all your major infrastructure is being useless and you might have to roll back and restart and rechange weights and load weights and like that's a huge delay in a lot of gpus so stability in training is like quite huge but that's like the big takeaway um and then check out check out last week's paper you know we kind of dove into the optimizer frankie you have hand up oh yeah i think just with the comment from eugene on that paragraph on self-critique closed loop so i'm wondering like uh because again like how does it learn from subjective giving subjective rewards right so i'm wondering um does it have to do with the fact that um they're they're critiquing on the verifiable signals right so there's things that are definitely verifiable but because you have things which are not verifiable are they you think that the model is kind of like learning from the steps that were taken right it's kind of like the chain of thought or whatever if you like learning from the steps like if it looks like you're doing good steps then you know i can give reward you better so because you don't have you you don't you don't have a you have a subjective reward on you right so i just wanted to see how you guys thought about that yeah kind of um in their rubric um they have rubrics that are for like potential steps so given um given this like let me try to find it given this prompt or question and these set of tools uh here i think this is it um combine rlvr with the self critique rubric reward the model learns not only from externally defined tasks but also from evaluating its own inputs extending alignment from smell basically in the rubric if you're using the right tools and getting like the right steps um you're you're rewarded for that too but i think we can do a bit of a follow-up on this um for each agent we generate tasks that range from simple to complex each task is paired with an explicit rubric that specifies the success criteria expected tool use and eventuation and evaluation checkpoints this rubric-based approach ensures consistent objective evaluation of agent performance where else is this mentioned expert crafted conditional prompts and rubrics developed by our data team oh this is kind of interesting how they developed this uh agentic instruction augmentation fine tuning okay each iteration is assessed using task specific rubric enabling the judge model to provide binary sex slash success failures uh that's for success beyond verification self-critique self-critique reward with evaluates outputs initial critique is building an sft stage eliminate your word hacking clarity relevance so this is some of it core rubrics for rl um clarity and relevance assess the extent to which the response so this is the rubric used in the rl for the rollout um excess assess the extent to which the response is six is succinct with full addressing the user's intent the focus on eliminating unnecessary details staying aligned central uh with the query efficient formats such as brief paraphrase brief paragraphs or compact lists uh conversation fluency engagement it's coherent so you know basically yeah they have an rl reward for stuff like clarity conciseness staying on topic um objective groundedness like are you objectively answering the step the question perspectives so um so you think that uh these rubrics is kind of guide help it to like decide what's good or bad is that what you're saying yeah um in in the group of outputs because it's based on grpo right you're still giving a reward for like you're now not verifying oh yeah in a sense you are verifying right because in a group of rollouts you're giving reward to the ones that match these right so you give a reward for stuff that's clear give us stuff a reward for stuff that's fluent give a reward for stuff that's objective um as justification and you know you're you're explicitly adding that in your rl policy so it's not verifying on stuff like okay and output is like verified and boxed math answer or code that compiles uh you do have a rubric that verifies for this i think the interesting thing is that they have a policy model that iteratively learns better critiquing and can self-critique that makes this possible because otherwise it's like okay yeah this is essentially just an llm as a judge as your rl on output and we know that um rl is very very um what's the term i'm looking for it's it's um it has to it's like very sam i'm blanking on the word it has it's uh i've blanked on the word but it has to be concise right like you can't have noise in your rl policy otherwise you won't generalize there's a term for this that i'm blanking on and you would assume that just having a basic um lm as a judge for your output for non-verifiable stuff like is this good is this concise wouldn't work but this kind of shows that if you keep your um okay come here okay um yes read this section okay but but what what is your what um what makes you think that it is kind of improving its critique capability as it progresses it says it it says it in one section that section that eugene highlighted is literally about keeping it improving uh where is it as a self-closed loop one right yeah yeah the closed loop thing so yeah that's that's how i know it's yeah okay thanks cool um any other stuff yeah closed loop uh our critique model is refined using verifiable signal on policy rollouts generated from verifiable rewards continuously update the critique the critic a crucial step that distills objective performance signals from rl vr directly they even talk about this in the infrastructure section about loading moving these weights and stuff uh this closed loop process ensures that the critique continuously recalibrates its evaluation standards in lockstep with policy evaluation so this is like what eugene was saying right this closed loop stuff lets you do rl and verify about rewards um basically you have a good rubric and you iteratively get better thank you cool guys we're 20 minutes over so i think that's where i call it if anyone wants to volunteer for next week that would be sick find a cool paper we share a bunch of papers in um discord i have like four or five that i'd recommend but you know if anyone wants to present would be would be sick thanks fix you're speaking but muted all right next week guys i'll see you