Qwen Image: SOTA text rendering + 4o-imagegen-level Editing Open Weights MMDiT
Chapters
0:0 Introduction to the Qwen Image Paper Review0:40 Introduction to Qwen Image
1:27 Progressive Training Strategy
1:48 Model Architecture
10:43 Diffusion Process
12:14 Data Collection and Curation
14:51 Seven-Stage Filtering Process
24:27 Data Annotation with Qwen
27:51 Data Synthesis
34:3 Pre-training and Optimization
40:46 Post-training and Reinforcement Learning (RL)
43:38 Multimodal Image Generation
44:6 Performance and Benchmarks
49:19 Live Testing in Other Languages
57:43 Conclusion and Practical Applications
Transcript
Yeah, okay. So, hello everyone. This is the Quint image paper, or technical report rather. So, let's get started. So, wait, wait, wait. We have a volunteer for next week, Venki. Yeah, Venki. Awesome. Let's go. Are you on the Discord? I think I'm on the Discord. If not, I'll ask my friend.
Yeah, I mean, just announce what paper you're going through next week, and just drop the link to the paper so that people can pre-read this. Super excited for you to share, Venki. Looking forward to it. Thank you. Thank you, YouTube. Yeah, cool. Okay. So, yeah. So, we have Quint image.
So, it's a diffusion image generation model. That's pretty nice. And throughout the paper, they talk about how it's a diffusion model, obviously, but they kind of put special emphasis on how the model does well in Chinese. Or, like, logographic languages, including Chinese and others. And also, we kind of get to see how they curate their data, and also how they label it, and the different techniques that they use.
Yeah, I find that pretty interesting. So, let's see. So, it's Quint image. So, it achieves significant advances in complex text rendering and precise image editing. That's pretty cool. They use a progressive training strategy. So, yeah. So, with this, they use, essentially, curriculum learning. Like, for a stage, they train the model on, like, very, very low resolution/quality images, like 256 pixel, or, like, 256 by 256 images.
And they kind of, like, progress. Like, they make the images, like, sharper and sharper, which I find interesting. So, that's a form of curriculum learning. Let's see. English, Chinese. And they also use VAE, like, a variational autoencoder, and also a language model, or, like, a visual language model, to, like, to kind of have, like, a system one, system two thing, where, like, they use the VAE encoder to encode low-level, like, physical or, like, spatial details within the image.
And they use their language model, like, when 2.5 VL to encode, like, the more, like, semantic part of the image. So, I kind of found that interesting also. So, let's see. There's nothing new here. These are a bunch of benchmarks. You guys can read it if you want. But I'll kind of skip them.
A bunch of images. Pretty cool. Yeah, the images are worth looking at at some point later. You can refer to them, or pull it up yourself separately, you know? But, like, it's editing and generation that, and both are, like, to a level I've never seen before. Yeah, and if people are interested, I can just, like, go back after.
I think editing and stuff, it's been done before just in separate models, right? Like, you need, like, a context consistency model. But, yes, very cool. I thought the first page of images was very cool. Like, this one with the whiteboard, you see how, like, the whiteboard is at an angle, and then it has reflections, and the text is at an angle and not directly straight?
I was like, oh, shit, this is pretty cool. Yeah. Yeah. Quen dropped a teaser about edit today. This is an editing model, by the way. It's very heavy on handwriting. Okay, let's just continue to. I think you should read the descriptions of all these as well, for what they show, by the way, for people following along.
Oh, shit. I'll drop the paper as well. Yeah, so let's see. Intro. So here they just talk about the challenges. They talk about, like, allotting model outputs with complex prompts, and also, like, just essentially making the text look nice. That's kind of what they're talking about here. And, like, sometimes they talk about how people have difficulty modifying images.
Like, if someone has, like, a pose, or if they want someone to strike, like, a different pose, they want to edit the image. Like, the person will kind of strike the pose, but the background will kind of, like, lose coherence. So they kind of, like, they talk about that as, like, some of the problems that they're trying to solve with the making of Quen.
So they also put, like, a ton of effort into, like, data engineering right here, which we'll kind of, like, see in the paper. So progressive learning, I already talked about that. Multitask training paradigms, we'll talk about that. And they also talk about, like, how they use GPUs. They have, like, a really interesting structure there.
So let's see. Yeah, we'll get into all of this. Yeah. Okay. So here's the architecture. So for this, this is a diffusion model. So, like, they'll inject noise into it, like, when they're training. When they're training, they'll, like, they'll patch some of the images, and they'll train the model to, like, essentially reconstruct it.
And what they do here is they use, like, well, we'll talk about it here, but they'll use, like, the language model to maintain, like, global coherence. Like, they'll say, like, oh, this image is supposed to be about this image. And their autoencoder kind of encodes the lower-level details. So they have, like, it's composed of 60 of these, like, transformer blocks.
I mean, not transformer. Yeah, the diffusion transformer blocks. And let's see. So there's nothing special here. Or you can look at this. But they use QKNorm. And they also, like, they made their own positional encoding, like, mechanism, which is msrope, which we'll also get into. Okay, so let's see.
So yeah, so they have three components. So they have, like, a multimodal language model. That serves as the condition encoder. And it extracts the feature from the textual inputs. This is, like, the QN 2.5 part that I was talking about. They also have, like, the VAE. So it compresses images.
Like, it just extracts the physical features, quote-unquote, of the image. And they'll also have, like, the multimodal diffusion transformer, which is the actual diffusion part of the diffusion model. Let's see. So they use, they talk about how they use QN 2.5 VL. Let's see. So they say that it has, like, they have three key reasons.
So language individual spaces of QN 2.5 VL have already been aligned. And 2.5 VL retains strong language modeling capabilities without significant degradation compared to other language models. So I tried to, like, look up and, like, I tried to see what they're talking about with this part. I didn't really, I wasn't really able to find what they were talking about.
So if anyone knows, like, I would, I would definitely like to know that. But yeah, so the third reason is that QN 2.5 VL supports multimodal inputs. So just image and text. Let's see. Oh, yeah. And they use, they use a latent space of, or latent of the last layer's hidden state from QN 2.5 VL as the backbone.
So they use that to, like, represent the user's input. So that's pretty interesting. Let's see. So as for the VAE, let's see. So they train an image VAE with 2D convolutions, or that's usually how this works. They usually train a VAE with 2D convolutions on a massive image dataset to obtain a high quality image representation.
But what they do differently is they use a single encoder, dual decoder architecture. So they use a shared encoder. Oh, no. Shared encoder compatible with images and videos alongside separate specialized decoders for each modality. So that's what they do differently. And let's see what they do. Oh, they also, like, they also collected a lot of text-rich images.
Like, they talk about here how it's, like, PDFs, PowerPoints, alongside, like, synthetic graphic, or synthetic paragraphs, and, like, covering different languages. And they use this to essentially to train the model, like, later with post-training on RL. They use that to, like, train the model on how to actually follow instructions.
Like, oh, if I want to make a PowerPoint with, like, this property and this property, they'll, like, use some of those, like, some of those documents. Let's see. They do that. Let's see. Yeah. And for the diffusion part, they, let's see, they use a multimodal diffusion transformer. So they talk about how they have, like, their, like, their MS rope, which is a multimodal scalable rope.
So, like, the reason, well, I'll just read it first. But let's see. So in the traditional, like, diffusion block, text tokens are directly concatenated after the flattened image positional embedding. So they're talking about, like, this. So, like, if your image is, like, if your image is split into nine pieces, then they'll, like, they'll just, like, concatenate the text after.
But what they do is, I'm reading from the blue text now. So they, text inputs are treated as 2D tensors with identical position IDs applied across both dimensions, and they're concatenated along the diagonal of the image. What that actually means is that they have their image here. And they essentially just pretend that the text, like, the text after is, like, concatenated along this dimension.
So they pretend the image is, like, in this case, they pretend the image is, like, a six, a six by six image. So that's what they do. And they say, like, the reason that they use this is because, like, previous 2D ropes, like, with other implementations of their positional embedding, certain rows of positional encodings for text and image, the 0th middle row in figure 8b becomes isomorphic.
So essentially, the model becomes confused. They're talking about this part right here. They say, like, with previous positional encodings, the model kind of becomes confused, and it can, like, confuse these, like, this middle row. So it can become confused as to which, like, which parts of the image correspond to text and which are actual, like, pieces of the image.
Let's see. So this is where they talk about the actual, like, the layers. They talk about, like, the VLM, the VAE, and the transformer. So there's that. So 20 billion parameters for the diffusion model in total. Yeah. So does anyone have any questions so far? I realize I didn't pause for input.
No, we're looking at chat. It seems good. You're doing good on Mark. I actually have a question. In the architecture diagram, up a little above, I don't see any mention of... Maybe I just didn't read it properly. No, sorry. Up in the architectural diagram part. Oh, yeah. Yeah. Like, up in the previous page, I think.
Yeah. So I don't... If I'm not... I don't see... So is the diffusion process... Like, how does diffusion come in here? Is it just that they're adding noise in the autoencoder and then removing the noise progressively on the unpatch, like, using the transformer blocks? Or is there something more complicated there?
Yeah. So someone correct me if I'm wrong here, but, like, I don't see how they actually, like... I don't see which, like, which diffusion objective they use. But, like, to my knowledge, a common diffusion objective is, like, not to reconstruct the image, but usually they'll estimate how much noise was added.
Like, first they'll... Like, with the forward pass, they'll, like, corrupt the data. Like, they'll gradually corrupt the data using a specific amount of noise at each step. And, like, with a backward pass, instead of, like, actually trying to reconstruct the data or reconstruct the image or whatever modality it is, they'll try to estimate how much noise was taken away in that step.
So I don't know if they put it here, but I wasn't able to find it. Yeah, okay. So it seems like it's just in the training regime and adding the noise. Okay. Understood. Thank you. That's helpful. Yeah. Any other questions? All right. Cool. Yeah. So now we go on to the data collection.
So in here, they actually put a lot of effort into data collection and curation. Well, I'm sure all, like, I'm sure all companies/labs put effort into this, but, like, we're able to actually see what they do to actually curate their data. So they annotated, they collected annotated billions of text image pairs.
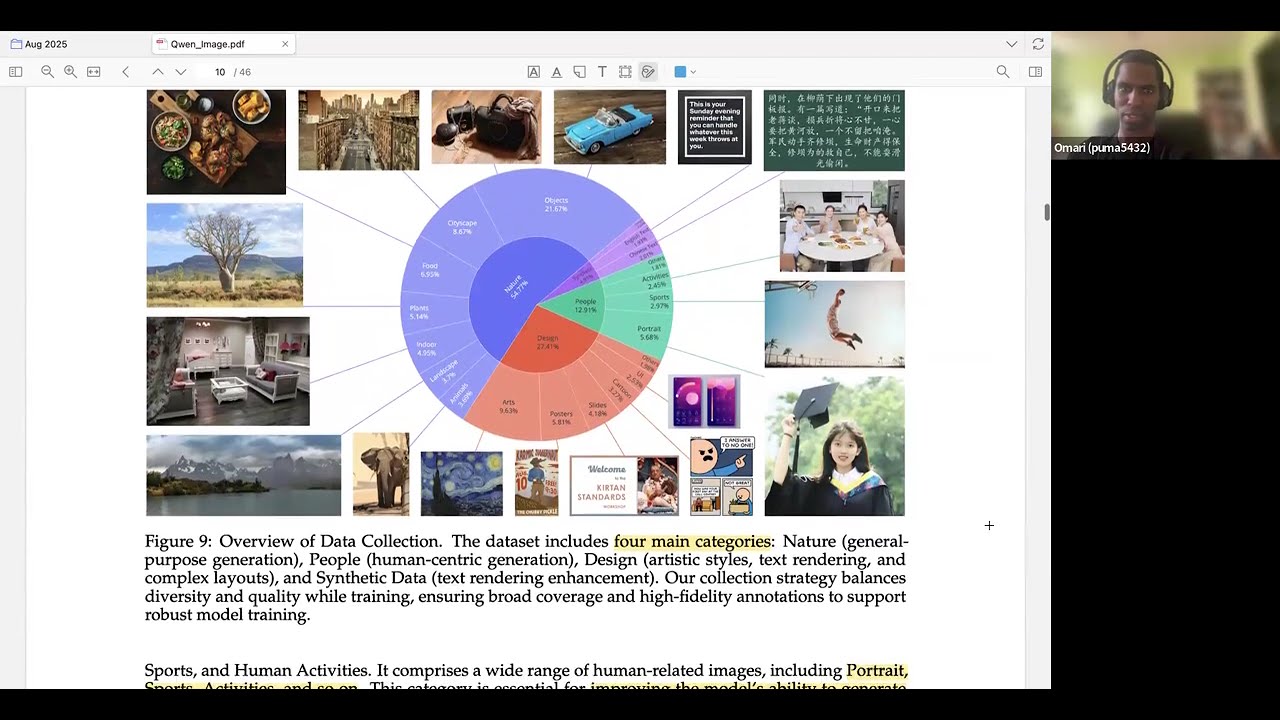
That's cool. And they prioritize data quality and balanced data distribution. So they try to create, like, a well-balanced and representative data set that closely mirrors real-world scenarios. So that's interesting. And they categorize it into, like, four categories. So nature, design, people, and synthetic data. And, like, it's important to note, they say it, like, somewhere here, but it's very important to note that when they say synthetic data, they mean, like, PowerPoints and stuff like that.
They do not mean AI-generated content. They take extra care to not include AI-generated content, like, in their data mix. Yeah. So we'll just go through each of these. So they have their nature category. So it says, like, 55% of the data set. They have, like, their objects, landscape, cityscape, plants, animals, indoor, and food.
So also it has, like, content that doesn't clearly belong to the people or design categories. So that's cool. So with the design category, oh, they also have, like, a graphic here, but I'll look at that later. So they also have, like, their design category. So it's 27% of the data set.
So it's usually, like, posters, UIs, presentation slides, and, like, paintings, sculptures, arts and crafts, and digital arts. So, like, this, they say that this helps the model to form, like, to emulate/replicate different art styles. That was interesting. So they also have the people data set. That's 13% of the data set.
So they pay special attention to this, because that's, like, portraits, sports and activities, and just, like, humans doing different things. So they say that it helps the model to generate realistic and diverse human images. And finally, the synthetic data set. So it's around 5% of the data set. So, again, like I said before, it does not include images generated by other AI models.
But it's, like, data synthesized to control text rendering techniques. So it includes, like, let's see. Let's see. Oh, yeah. So they adopt a conservative stance towards such data as training on low fidelity or misleading images may weaken the model's generalization capabilities. So, yeah. So let's go to the graphic.
So this is, like, a visual representation of, like, of the proportion of, like, the nature of the different classes and the different, like, subclasses, like objects, cityscape, et cetera. Yeah. So that is that. So they have data filtering. They have, like, I think, like, seven to ten stages. How many stages?
They have a lot of stages of, like, filtering and pre-training. So this is kind of, like, I get the gist from reading this section that they had, like, a seven to ten stage filtering process, but they also started doing curriculum learning at the same time while they were filtering the data.
I'm not sure if that's actually the case, but that's kind of what it seems like from here. So let's see. Oh, yeah. They have seven sequential stages. So, yeah, synthetic data is introduced from stage four. Yeah. Yeah. They mention it in the abstract that it's kind of important, right?
So they have a, they adopt a progressive training strategy and then they kind of go through their stages, right? So there's non-text-to-text rendering evolves from simple complex textual inputs, gradually scales up to paragraph level descriptions. So they do have, like, this curriculum learning and it's kind of, um, it builds from simplicity to more advanced stuff to, like, the most niche little synthetic data.
Yeah. They cover it later too, yeah. Okay. Thanks. I appreciate that. Yeah. So I was like, I'm not going to go, like, super in-depth for each stage, but, like, so let's see, they have the initial pre-training data. So, like, this is what I talked about or reference earlier, where they trained on, like, very small images, like 256 by 256 pixels, like, various aspect ratios.
So they kind of list them there. Uh, so they also, like, remove low quality and relevant images. So they make sure they remove duplicates and they remove, like, really, really low quality images right here and also NSFW stuff. Yeah. Let's see. They also, let's see. So onto stage two, they focus on improving the image quality.
So they remove images, like, with significant rotation or flipping. That's this part. Uh, let's see. They describe, like, blurry, out-of-focus images, excessively bright or dark or images, like, with unnaturally high color saturation. They also remove images with, like, low entropy. So that's just, like, only black or only white images or whatever.
And they discard images with overly complex textures or, yeah, which is associated with noise and non-sematic patterns. So this is also a graphic of, um, like, of their filtering process. Yeah. So stage three. Let's see. So this is actually where they do, uh, or where they talk about some of their annotation.
So here's where they start to focus on text. So they start to focus on improving the alignment between textual description and visual content. So they, I'm reading the blue part here, but they, uh, they have, like, two splits. So they have, like, captions provided by websites as well as metadata, such as titles or tags originally associated with the images.
Uh, so they also have, let's see, captions generated by Quent. So, like, they also use Quent to help in their, like, data annotation process. Um, let's see. So this is just talking about the, how they also combine raw captions and synthesized captions. They also discard, like, trash captions, like, really long captions or, like, generic ones.
That's like, sorry, I cannot provide a caption. I mean, indicating that the caption is broken or something, something else is wrong. So they also talk about, let's see, text rendering. So this is H4, text rendering. They, interestingly, they split their languages into English, Chinese, or other, which I did not expect.
But apparently it worked for them. Uh, let's see. Yeah, they address challenges such as low frequency characters, mixed language scenarios, and font diversity. So they incorporate synthetic text rendering data. And let's see, they also remove images with overly dense or excessively small text. So they do that to increase their text quality.
Oh, and this is also an interesting graphic where they show, uh, like, they show kind of the distributions on some of their, like, their filters. And you can kind of see the examples of some of these images. I kind of found it helpful. Yeah, so stage five. So they talk about how the model transitions to training with, uh, training with images at 640p resolution.
So they're increasing the, like, they're making their images sharper and just increasing the resolution, uh, presumably to make the training more stable. So they also apply more filters. So let's see, they, they try to remove images that have, like, overexposure, underexposure, blur, or compression artifacts, or all poor, or, or composition or visual appeal.
They also remove images containing watermarks to our codes and stuff like that. So stage six, they kind of focus more on portraits. Uh, let's see. Yeah, so they categorize their data set into three categories. So general portrait and text rendering. So that's what it sounds like. Stage seven, this is balanced multi-scale training.
So again, they're increasing their resolution. And they, interestingly, they design a hierarchical taxonomy system for image categorization. So within each category, they retain only images with the highest quality. So here they're, this is essentially, like, data QA. So just making sure that their, that their model, um, doesn't generate really bad images, like, of a certain, like, of a certain type.
So, like, they build a tree of all, you know, of all, like, objects that they have. And they just essentially check, like, oh, are, like, like, when the model generates buildings, do the buildings look good? Etc. Like, like, do the landscapes look good? Do the parks look good? Etc.
They do that. They also, uh, while they're, like, within each category, they retain images with the highest quality. And they also allow, like, they make sure to balance their data so that they allow the model to retain previously learned general knowledge and ensure stable convergence while adapting to higher resolution images.
So presumably, this is to combat, like, catastrophic forgetting, where your model trains on a specific, uh, subset of data, but, like, kind of loses its generality. So that's what they do in stage. Yeah, stage seven? Yeah, I think stage one to seven really shows how much care they put to cleaning the data, whereby they had so many simple filters just to check for resolution, check for cropping, check for flipping, and everything.
Um, and that's what led to this strong model. Actually, then, then the question becomes, hey, if we had left, left that data in, would the model be just as good? It's unknown. I don't know if we would actually train such a model on deliberately train a model on bad data.
Um, but, I mean, their pipeline is actually quite fascinating. I think it might agree. Um, they, they share some stuff with, like, why they don't do synthetic data from, uh, you know, images generated by other models and noisy stuff. And they, they say that that would harm the quality, right?
Yeah, because there's a lot of artifacts, right? Yeah. Exactly. So if you train on poor quality data, you will not get good model, but that's, that's, you know, it seems necessary to need to do all this then. Yeah, that seems so. And if we look at, um, figure 10, right, I think like they shrank their data set maybe by, by two thirds.
So a lot of it is, it's filtering and I, I, I really enjoyed figure 10. So it really just shows you how much care needs to be taken for doing this. Yeah. Yeah. So does anyone else have any other questions or comments? Did they mention, uh, if this is a semi-automatic, uh, filtering because, uh, you know, it's, uh, billions of images and, uh, it's a huge effort to annotate and filter, uh, based on quality and, uh, all of this.
Yeah. So they like in the, in the technical, in the technical report itself, they just talk about, they say like, oh, we applied in entropy filter. So I'm assuming that they programmatically do that. Uh, maybe there's more data in the, what's it called in the appendix. I didn't read the appendix or I don't even know if there is an appendix.
Yeah. It just sounds like they, yeah. No, go for it. Oh yeah. No, I was also, I was just saying like, yeah, I apply, like, I imagine that they just apply, um, they just say like, oh, if the entropy is greater than this in this image, then they just like discard it and do something similar or attempt to do something similar with the other filters.
Yeah. I imagine that pipeline is completely automatic. Developing the filters is not automatic in a sense. They probably need to figure out what the, what, what the right threshold is so that we exclude most of the defects without losing out too much, too much good data. But you can imagine that, you know, you have a team of 20, everyone just takes one of these filters and then you be your evals and figure out how to cut it, get high precision and recall.
And then once it's there, it's just, it's just a very simple, uh, CPU intensive task. Right. That open CV probably has quite a few of these as well. And then once it, I just pass everything through. And I think that will work very well. Yeah. But I'm sure that they also did some quality, uh, control checks on a small sample subsets.
Oh yeah. Yeah. I'm also sure. Yeah. Okay. So let's see. Data annotation. Oh yeah. So they go on to talk about their data annotation, which I think is also really interesting because they, they essentially have Quen generate, uh, a JSON. So I'll actually read some of this. So say we use a capable image captioner.
So they're talking about Quen 2.5 VL that generate, uh, comprehensive image descriptions, but also structured metadata that captures essential image properties and attributes. So like, instead of treating captioning and metadata extraction as independent tasks, the captioner concurrently describes visual content and generates detailed information in a structured format, such as JSON.
So critical details such as like object attributes, spatial relationships, environmental context, and verbatim, uh, translations of visible text are captured. So they capture key image properties and report it in a structured format. So I think that that's really interesting. I don't know how many other like labs do this, but yeah, I just think it's really interesting that like, they, they treated them both as the same like image or is it, uh, image captioning and like metadata extraction to like capture a bunch of different relationships from the image that might not just be captured with the image caption.
Yeah. I also, I thought this was really interesting and that they're actually using the, the vision language model in two ways. One is they're doing it, using it to annotate like this, but then they're also using it to embed the language into the vision, uh, the vision, uh, the vision embedding space, right.
And then there, and then like sort of losing across, uh, across attention to align. I thought that was really interesting that they were sort of using it in two ways. Yeah, I agree. I thought it was pretty cool. The two papers they reference on this, um, siglip 2 and Chinese clip, uh, the siglip 2, I looked into that paper.
It's kind of, it's kind of interesting. It's like a, you know, a very recent 2025 iteration of clip, but it's cool to see how much stuff keeps pushing there. And then, uh, you know, they even mentioned like in that stage three, after you do captioning, how do they, you know, how do they still filter itself?
So like there's token length, you gotta remove stuff, you gotta filter stuff that says I can't caption this image. Um, you know, there's even more filters in this stuff. Yeah. Wait, do you know what Chinese clip did differently than like regular clip? I'm pretty sure that the captions are in Chinese.
I haven't checked, but you know, I would assume Chinese clip is clip in Chinese. I meant like, I meant like they do anything differently in terms of like diffusion. So they, they have two, two, two things that they reference. Uh, sig clip is not Chinese clip. It's, it's, uh, it's a variation that builds on top of clip and that's not specific.
That's not like specific to Chinese. That's from deep mind in like February, 2025. It's, it's just an improvement on clip, but you know, they probably merged that with the Chinese clip. Okay. Cool. Yeah. Right. Okay. So let's say we did that. Okay. Okay. Data synthesis. Uh, let's see. Uh, oh yeah.
So they talk about how apparently this is a problem with, uh, like with Chinese where like there are some characters that are just really, really rare, but are still important. So I say given the long tail distribution of textual context, relying solely on, uh, naturally occurring text is insufficient to ensure adequate exposure to these rare characters during model training.
So to address this, they use like a multi-stage text-aware image synthesis pipeline. It's like, they have three stages and they kind of describe it. Uh, so the most straightforward way it's like to train the model to recognize and generate characters. So like they make text or they extract text paragraphs from large scale, high quality corpora, and they render it onto clean backgrounds.
And so they also like implement QA or quality control. So if any character within a paragraph cannot be rendered due to limitations, the entire paragraph is discarded. So again, like they just really, really care about having like clean data. Uh, yeah. So they maintain a high fidelity. Let's see.
So this is an example of the first one, the paragraph that I just talked about. So they do that. So they also do compositional rendering and contextual scenes. So they just embed a embed synthetic text into realistic visual context. So they use QNVL captioner to generate descriptive captions for each synthesized image, capturing contextual relationships between the text and surrounding visual elements.
So an example of this is like this right here. And the third is, let's see, complex rendering and structured templates. So they follow complex structured prompts involving layout sensitive content. So they propose a synthesis strategy based on programmatic editing of predefined templates, such as PowerPoint slides or user interface mockups.
This is kind of what I was talking about at the very beginning where they, like, they kind of use some of their PowerPoint such like synthetic, quote unquote, synthetic images. Uh, that kind of like teach it to follow instructions or teach it to like how to place different, like how to use graphics or like manipulate graphics.
So like, again, this is an example of that. I thought this section was very interesting, right? Because what they're doing here is they're, they're generating a very different form of synthetic data, right? This is not synthetic data from a diffusion model or like an LLM that's just added. Like you don't, you're not really doing distillation.
Uh, you know, the first one, uh, you know, the first one, the pure rendering is very interesting, right? They're, they're basically writing paragraphs, like they're extracting text and just rendering it onto clean backgrounds. Like, you know, in Photoshop where you can like have text and just paste it into different backgrounds.
Uh, that's, that's a form of a synthetic image, but it's not a generated image, right? So they mentioned this more earlier in the paper as well, where their synthetic data gen is like very different, it's, it's not generated images, it's text that's written and then rendered in synthetic sense.
But yeah, it's like pure, pure text. And then the thing that you mentioned with the random characters. So the, the, the part of that is actually that in, in languages like Chinese, there's tail end characters that don't show up a lot, right? Like you, you just won't see these that often, but you still need to be able to understand them.
So this synthetic text properly brings back in the tail end of distribution that you don't see. So it's like, you know, in English, we have like only so many characters, right? 26 letters, they're pretty distributed, but in, in Chinese there are characters that don't show up and they, they render them and then they synthetically add them back.
But it's a very different type of, uh, synthetic data gen. Yeah. I'm pretty surprised it works as well. Like, yeah, they just have templates of PowerPoints and then they just add in words, you know? Yeah. I'm also kind of surprised because like, I thought that if there were rare characters and they would rarely show up in, um, like in these like pure rendering, like these types of images.
But I mean, maybe they artificially, like maybe they just like manually found which characters are rare and just like ensured that there are more of those available. So that's exactly what they did. Yeah, I can imagine that's what they did. That's, that's not a real image. That's a paragraph of text that exists, and then they just paste that onto a green background.
Oh yeah. But this is not an image that exists, right? That's why it's synthetic. Oh yeah, yeah. It's not telling, it's not telling a model to generate something with this. They actually just purely printed out this paragraph and then overlay it on a green background. And same thing with the ones below.
That's what makes this unique form of synthetic data gen, right? Because it's, yeah, it's just image editing, but it's, it's not generated per se. Yeah. And then they do this, they adjust font, sizing, spacing, all that stuff. And then, you know, when you type out this paragraph, if one character is off, they discard it.
So it's, it's pure clean. Yeah. And this helps with like tiny text too, I think they said. So like, they can super scale it down. And as long as it's correct, you know, synthetic small text. Yeah, that's really useful then. Yeah. Yeah. But the, the, the cool thing is after you do this, like in the second blob there of text being overlaid, sorry, if you go up a little bit, the second one, like, you know, this, I love you too.
So this is text that was thrown on a piece of paper in a background. They still have to pass this back in through their captioner, right? So even though it's like fake image, not synthetically generated, they, they have to still throw it in the captioner and have descriptions without metadata and stuff.
So it's, it's cool. Yeah. Does anyone else want to say anything? Okay, cool. Yeah. So this is, so this is a pre-training. So, so like, first I'll just read some of it. So they adopt a flow matching training objective to pre-train Quen image. So it facilitates stable learning dynamics via ordinary differential equations while preserving occultence to the maximum likelihood objective.
Uh, so this is, this is essentially like the diffusion part of their model. So like, let's see, they have, yeah. So yeah, you can just, you can throw it into chat.tpt if you want, but like essentially they train the data to point towards, I think like that, or they start with noise and they train like the noise to point towards like the actual Bonavilla data.
Uh, let's see. Yeah. Then the model trained to predict the target velocity and the loss function is defined as the mean squared error between the predicted output and the ground truth velocity. So I use like a mean squared error. So I try to get the velocity to match. So essentially you get it to like point in the direction of the real data, uh, like in this distribution.
Yeah. So they also talk about how they optimize, uh, their models for like GPU usage. So they use something called like what they call a producer consumer framework. It decouples data pre-processing from model training. So this design enables both stages to operate asynchronously and add optimal efficiency. So on the producer side, the selected data is encoded into latent representation using MLM models and VAE.
So like they have, uh, two types of GPUs. Like they dedicate some GPUs to like do the producer, like do the producer's work. And they dedicate some GPUs to do the consumer's work. So the consumer GPUs are dedicated exclusively to model training and every data parallel group asynchronously pulled pre-pulls pre-processed batches directly from the producer.
It's like, again, like they have, uh, let's see. Yeah. So they have like their pre-produced GPUs. They encode like the data to relate in representations. And they just like stack them up somewhere in memory or in storage. And when, like whenever the consumer GPUs, uh, like whenever they finish with their previous batch and they're ready, they just like asynchronously pull the data.
Uh, so I think that's interesting. So let's see, so distributed training optimization. So they use like hybrid parallelism strategy. So they combined data parallelism and tensor parallelism to efficiently scale training across large GPU clusters. So this is like less, it's like, I'm less confident, uh, of like what this, or like of the specifics of this part.
So if anyone wants to like jump in, they're like more than welcome to, uh, they also talk about like distributed optimizer and activation checkpointing. Like to alleviate GPU memory pressure with minimal recomputation overhead during that prop. So we experimented with both distributed optimizers and activation checkpointing. However, activation checkpointing introduces substantial computational overhead and backward paths, which can significantly degrade training speed.
So they observed that enabling activation checkpointing reduced per GPU memory consumption by 11%, but like at the cost of increasing per iteration time by essentially almost four times. So from two to seven and a half seconds per iteration. And like they say that based on the trade-off, they ultimately opted to disable activation checkpointing.
So I think that was pretty interesting. I think there's an important point here, right? In the sense that, um, with activation checkpointing, you're like 75% slower. Um, but you only save like 11% GPU memory in, in a sense you could sort of reduce your batch size and actually go away faster and you would actually make up for it.
Um, in some of my experiments, I mean, the default, if you ask Claude to write some code, the default is to enable activation checkpointing. I think because everyone's was fine tuning on very small LLMs. Uh, and you know, I think by in hugging phase, the default is just to enable activation checkpointing.
But when you turn it off, uh, at least I was able to see a 20% speed up with not very much increase in memory either. So I think it's something to observe, uh, something, if you do train your own models or finding your own models, like do consider not using activation checkpointing, uh, just for your, uh, training loop to run faster.
Um, so it's, it's nice to see another data point here in this paper. Yeah. All right. Would it like, would a middle point in that trade off just be to have activation checkpointing, but just to like checkpoint it less frequently? Like wouldn't that work? I, I don't think that that works that way.
I think activation checkpointing is needed every time you do a backward pass and optimization. So you, you, you definitely need to do that. Yeah. Oh, okay. Interesting. Yeah. So, uh, I mean, try it for what's worth if you have extra memory on your GPU, or you can afford to go over a smaller batch size and just do gradient accumulation.
I think it's definitely, I mean, in this case, it's definitely worth the trade off not doing the activation checkpointing. Uh, I found the same thing in my own use case as well. So yeah, something to think about. Okay. Cool. Keep that in mind then. Yeah. So we talked about this kind of earlier with, oh no, there we go.
Yeah. So I kind of talked about this earlier, uh, with their data synthesis or their data curation pipeline. But so onto a training strategy, they adopt a multi-stage re-training strategy aimed at progressively enhancing data quality, image resolution, and model performance. So again, they enhance their resolutions. They go from low to high resolution.
So they go from 256 to 256 pixels up to 1328 by 1328. So they enhance the model. Oh, let's see. Where is it? Yeah. They let the model capture more detailed features leading to better performance. So I'm reading like right here. Richer features, specs, or spaces facilitate improved generalization to unseen data.
So transitioning from low resolution to high-res on flower images allows the model to discern finer details such as petal textures. So that's interesting. So they also go from non-text to text. So they progressively introduced images containing like render text. So the model can like learn visual representations and subsequently acquire text rendering capability.
So they also go from massive to refined data. They gradually employ increasingly stringent data filtering mechanisms to select higher quality data. So it ensures that only the most relevant and high quality samples are leveraged to ensure training efficiency. It's cool. They also have balanced data distribution. So from unbalanced to balanced.
So it mitigates the risk of the model overfitting to particular domains or resolutions. And like just let the model generalize better. And lastly, they have synthetic data. So from real world synthetic data. So here they generate supplementary samples enriching the data set and ensuring more comprehensive coverage of diverse visual domains.
They say it enhances the model's ability to generalize and perform robustly across a wider range of scenarios. So it seems pretty useful. So on to post-training and RL. So they have supervised fine-tuning, RL, and DPO, or and GRPR2. So they use hemean annotations to address specific shortcomings. This is in the supervised fine-tuning phase.
So they make the selected images clear, rich in detail, bright, and photorealistic, and like all that good stuff. And they guide the model towards producing content with creative realism. So with RL, they use DPO. DPO, like it excels at the flow matching, which is the diffusion part of the image generation.
And GRPO performs on-policy sampling during training and evaluates each trajectory with a reward model. So let's see. Yeah. So for DPO, it says given the same prompt, multiple images are generated with different random initialization seeds. So like with prompts without reference images, annotators are asked to select the best and worst samples along to gender-oriented images.
So I don't know if selecting the best and worst samples, I don't know if this is new or if people have previously used this. But I thought that was interesting. Because like usually with DPO, I just hear people selecting the best images or like the best, like whatever. Let's see.
So yeah. So DPO, they use that for flow matching and for GRPO. They use it for, what's it called? They use it for like the reverse. I think they also use it for flow matching. I'm not sure of this part. But they use it for like, I'm pretty sure they use it for reconstructing the image.
Like finding the loss. So if anyone wants to like comment, they can jump in here too. But if no one has anything to say, then I'll go on to the next section. Yeah. So let's see. Yeah. So let's see. So in addition to text image, so they let the model explore like multimodal image generation tasks.
So it's not only like giving the model a prompt, which is text only. They also let the user like give it a prompt in an image. So that's cool. So they also find that providing the visual semantic embeddings from the MLM enables better instruction following. So this is kind of like what they talked about like at the very beginning where, or not at the very beginning, but like what they talked about previously where they, they took the last latent representation of Quen, like of their, like their multimodal language model.
They took the last image and they kind of like fed that into the model. And they say here that it helped. So it's pretty good for them. And they also use like the, like they talked about how pixel level VAE embeddings further enhances the model's ability to preserve visual fidelity and maintain structural consistency.
So I was kind of talking about that earlier too. So yeah, so I think like the, I don't know, this really reminds you of like system one and system two and how like different labs have been using that. Like I remember DeepMind used system one and system two for robotics.
And I think like figure AI use that for like, they also use that for robotics. So I don't really have a lot of notes on this. So human evaluation. So let's see. Yeah. These are just evaluation benchmarks. I kind of like put more emphasis on how the model was trained in like that data creation than like the human eval.
Yeah. So they have like this. So there are different benchmarks. So you can read these if you want. Yeah. So let's see. Formants. Formants. Let's see. Yeah. I really just like left the benchmarks alone. And like if people want to read them, I just let, like you can read them if you want.
So they also, let's see. They also have like image editing benchmarks. And they also have like, so in some of their editing benchmarks, or in one of them rather. So they have like very dense PDFs and they like essentially just let the model see. Or like they let the model like try to reconstruct some of the images to like see if it could generate some of it.
And apparently it does pretty well. So like, again, they focus on like English, Chinese, and like multi-object generation and spatial relationship generation. So that's kind of, that's kind of it. That's, that's most of the thing that I, or that's most of what I focused on like in my annotation.
Yeah. So does anyone have any, any questions or anything else or any comments? I think the conclusion is also quite eye opening in the sense that they try to make, they make this claim that a generative model can effectively perform classical understanding tasks. And they say that, uh, uh, the current image model is deliberately does not optimize for photo realism and, or aesthetic quality, but really tries to optimize more for aligning text and image.
I think you sort of tells you where they are trying to bring this model towards, right? Like essentially like creating posters, creating PowerPoints. I essentially, it's more practical instead of just generating images, but images with text. Uh, so I thought the conclusion was quite a worth trying to read and understanding what they mean, what they mean by it as well, uh, especially the last paragraph.
So that's pretty cool. Thank you. Yeah. Okay. Yeah. I'll just like read it, but well, like other people can ask questions. Anyone have any questions? So yeah, yeah. Yeah. Yeah. So they mentioned that, uh, the, uh, model streaming data, uh, pipeline, uh, does include other languages, but, uh, I see that, uh, that most of the benchmarks, uh, were focusing on, uh, English and Chinese.
So I don't know if, uh, uh, uh, in the conclusion that they, they, uh, specified that they can, uh, handle other languages. Yeah. So actually, I'm not sure they don't really, yeah. They don't really talk about like other languages besides English and Chinese. So I'm not really sure. I kind of like, uh, I tested quite.
Mm-hmm. They had a category for other. Yeah. They had, uh, English, Chinese, and other, but I don't think this thing will do, do other languages. Maybe others to exclude them or to further them. No, no, they weren't filtered out. They were filtered in. Okay. But, um, yeah, it's, it's primarily English and Chinese.
So I don't know if they did evals on the other texts, maybe they're just not equipped to do evals on other languages. Um, they had, they had four categories. They had English, Chinese, other language, and no text. We definitely had a other language, but I don't think it's significant, you know?
And then some of this is also like, um, you know, there's already a vision encoder in there that can do multilingual, but I don't think it can specialize in output for this. Uh, uh, I mean, actually, I tested, like, I tested some other prompts with the, I didn't text, or test any, like, non-English or Chinese languages.
Yeah, I mean, like, Quen, I tested them in Sora, like, Quen and Sora. And like, actually, I think the quality was, like, pretty similar. Or Quen's, like, Quen's text generation was, like, uh, it was a little more clear. Like, the characters were a lot clearer. You could kind of see them.
It was a lot easier to look at them and just, like, see the background, or, like, distinguish between the characters and the background. But, yeah. Live coding, I'm testing it in Spanish. Yeah, I should've. Should we do a different language? Like, should we do Korean? Let's see. Yeah, maybe something that's not Latin.
Yeah. Arabic. I don't know. I don't know if we would even be able to evaluate it. I can try that. May I have? Let's see. I just shut off a generation. We'll see what it outputs. Oh, shit. It's not correct, but it has Korean-looking stuff. Wait, what's your prompt?
Uh, literally in Korean. I went to Google Translate, and I translated the sentence. Yeah. You might want to- You want to share the images I shared in Zoom chat? Yeah. Yeah. Maybe just change it. Well, I mean, it's off, but it does look a little more Korean. Wow. Why did you say it's not correct?
Because look at the- Look at what it's supposed to write. The first character, right? Uh, actually- Maybe it fixed it. I actually don't know. Wow, this is really- Oh, I guess the second line is kind of there. Yeah. Maybe the first line actually- I actually don't know. Maybe it's a ha-ha.
Kind of there. Kind of there. And they actually- They actually fixed it? Oh, it's actually coffee. Oh, okay. But okay, it does something. Wow, this is actually pretty good. Yeah, I don't know if that's right or not. I don't see Korean. It looks similar, actually. Oh my god, it does Korean work.
Okay, I'll do another one. I'm now trying to translate the text it generated. I showed another image if you want to swap to it. Yeah. And then I'm translating this with Korean model. And see if it's coherent or if it's just random stuff. Yep, so it put Korean on the board.
I'm trying to have it. Oh my god. Translate this Korean. It's struggling. Okay, I think this is enough live coding. Oh yeah, as long as the fuzzy background characters don't look Korean. I mean, it could also just be style, right? Like it is also a monkey. That's true. I guess.
So the second image is nonsense, gibberish, according to translations. I guess I did ask it for random text. Yeah, but the font of the main text and the background text do look different. But oh well. Yeah, it's cooked. Oh well, they tried. I'm doing another. Alright, cool. I think next week we have, was it Venki again?
Yeah, Venki will talk us through GLM. Wow, this chalk text actually looks so much like chalk. I'm actually impressed. But I don't deal with a lot of image. I thought the chalk was mid. No, the one that Steve just posted. At least the first character. Yeah, it's pretty good.
It's pretty good. I mean, it's trained specifically on this. I'm impressed for the first character at least. Yeah, so sorry. Maybe a late question here. I was going over that the flow and diffusion model that they had in 4.1. And I just want to make sure that I understand.
So I think that they have a joint latent space of image and text, correct? And so they're applying a noise model on top of that space, right? And I was wondering, typically when you add noise to say latent space of text, it doesn't work very well. That's why we don't have very good diffusion models for text.
So I'm kind of surprised that this kind of works. So I'm not sure what you guys feel about that. So what I'm saying is that their latent space is kind of like a multimodal one, right? It contains both image and text related stuff together. And typically diffusion, as you have here, which is adding noise to that, normally doesn't work well on text-based latent space.
So I was wondering why this would do any better. So one thing that I noticed was that if you look at the architectural diagram, the noise is only added on the image side. Oh, okay. So if you scroll up to the architectural diagram, I might be wrong about that.
It's just from memory, but I think that's what I saw. Yeah. So the noise is only added on the image side. And then you have this cross entropy thing that combines them. So it looks like it's more like conditioning on the text, building the common latent space inside of the transformer blocks.
Okay. So it's like normal diffusion then, right? Like normal image diffusion? Yeah, it seems like. Yeah. Okay. I also think it's because the resulting product of the model will be an image, which is continuous in diffusion space. If the resulting product of the model would be text or something, or something that's inherently discrete, then I feel it could be a lot different.
Like you might have to use a decoder or something. But like, yeah, like with the prompt and the image, both of those get like injected into latent space. And then you can like perform diffusion on that. And like the resulting process will be an image. Well, I think RJ said that it doesn't get injected right on the combined embedding.
It's just on the image embedding. It gets added like on this figure. The noise only added to the image and image latent space, not to the prompt. They get combined later, but the noise is only added to the image side. Oh, yeah. Oh, yeah, yeah, yeah. You're right. You're right.
Yeah. Okay, cool. Sorry. Thanks, RJ. Yeah, cool. So, oh, it's 402 right now. So is that it? Yeah, yeah. Awesome. Thanks for guiding us through it. Next week, we have another volunteer. We'll share the Luma and stuff. But cool. Thanks so much for watching. Yeah, I tested in Arabic as you requested.
So, yeah, of course, it's not right. But there is like the same number of letters and going from right to left. But it's missing a lot. So, completely rubbish. Awesome. Well, I guess it's English and Chinese then. Cool, guys. Take care. See you guys next week. Okay, bye. Bye.
Cool. Bye. Bye. Bye. Any questions, Mr. Calder?