Live coding 12
Chapters
0:0 Review of best vision models for fine tuning10:50 Learn export file pth format
12:30 Multi-head deep learning model setup
16:0 Getting a sense of the error rate
20:0 Looking inside the model
22:30 Shape of the model
23:40 Last layer at the end of the head
26:0 Changing the last layer
29:0 Creating a DiseaseAndTypeClassifier subclass
38:0 Debugging the plumbing of the new subclass
46:0 Testing the new learner
49:0 Create a new loss function
52:0 Getting predictions for two different targets
56:0 Create new error function
Transcript
Yeah, so I guess the thing I've kind of learned, I guess I should share my screen and say what I feel like I've learned from this sweet scavit kettle. So on pets. Pets. This is the top 15 after running a few more sweeps to see if there's some better options but basically, I think what's interesting is in the top 15 pets, you have like a bit of everything right, you've got ResNet RS and ResNet B2 distilled.
You know, VIT transformers ones, VIT, SWIN, mobile, VIT. Classic ResNet 2060. Still in there. Actually the fastest of all, which maybe reflects like maybe that's the most well optimized kind of because it's been around a while and videos probably worked hard on that. ResNet GPU memory, like, yeah, it's kind of interesting the way there's all these very different approaches, but they, they all kind of end up in there.
I think, you know, one thing interesting when you look at on the graph is this, these green ones is VIT, which they kind of cut off here at this fit time of 150. And I think that's because the larger vision transformers only work on larger images and I only did 24 pixel images.
So if, if I included larger images, we might see VIT at the very best in terms of error rate. I was pleasantly surprised to see that some of the VITs, you know, didn't actually use much memory. And they were pretty fast. And it's interesting because that was quite a while ago, right, the vision transformers paper came out quite a while ago, and it was kind of like the way I remember it was like just tacking together the first and most obvious thing people thought of when it came to kind of making transformers work on vision and yeah, the fact that it still works so well, it seems that people haven't improved on it much other than perhaps Swin.
So I guess that my takeaways on the like, small and fast models. Yeah, I guess I hadn't really looked much at resident IRS before so it's interesting to see that one's right up there. And then on planet, it doesn't look that different except, you know, it really is just VIT, Swin and Conf Next.
In fact, entirely is VIT, Swin and Conf Next. The whole top 15. Yeah, so I guess that's some of the things I noticed. That's cool. This was able to try so many different kinds of models. Yeah, ran in less than 24 hours on my three GPUs. Something like 1200 runs or something.
Yeah, I thought this was interesting. Look at this one, VIT small patch 32 memory usage is amazing. And speed is fastest. And, yeah, third from the top of the small, faster ones. I have a question. Yeah. Can you hear me. Sure. Yes, hi. Just a small question. So you mentioned small and large does large mean the size of the image.
Sometimes when I was talking about the IT Yes, it does the IT. So I was specifically just doing 224 by 224 pixel images, and pretty much all the transformer based ones are fixed, they can only do a one size. And so the IT models I don't think they have.
So, there's two meetings of larger here this larger as in more bigger models like more layers, wider layers. And I think all the VIT models which are larger or capacity slower, probably more accurate, I think only run on literally on bigger images, which is like doesn't have to be that way that's just what they happen to do.
So that's why. Yeah, the IT only goes this far. There are bigger VIT models that should be more accurate but they don't work on 224 by 224 pixel images, is there like a good threshold to know when is a good time to use large versus this fall one or is it just all experimental larger images.
You basically do everything on a smaller images you can, as long as it gets you reasonable results, because you want to iterate quickly. And then when you're finished and you want to, you know, like it like in the case of Kaggle you want the best accuracy, you can. So you try bigger and bigger images to see what you can get away with and skip doing that, as long as the accuracy improves.
In a production environment, it's kind of similar but you make them bigger and bigger until you the latency of your model is too high, you know, you find the right trade off between model latency and accuracy. Generally speaking, larger images will give you more accurate results. But a bit slower.
Correct. I mean, a lot slower right because if you know if you increase it from 224 to on one side to 360, then you're going from 224 squared to 360 squared. So you end up with a lot more pixels. So like for for example an application would be like for object detection for video for example like live video, then even if it's a larger size, it will still be good to do small because it's faster.
Certainly for your iterating. There's no need to have a really accurate model for your iterating, because you're trying to find out what data pre processing works best or what architecture works best or whatever so yeah there's no point using large models and large images generally, as long as they're big enough to get the job done recently well.
Okay, thank you very much. Yeah, no worries. You were, you were going to do this in like a business context, let's say, and someone said hey German one to, you know, have a vision model, would you, would you kind of just pick a reasonable one and just kind of go with that and if the results were good, you would just use it or I would do exactly what I'm doing here, you know, which is to try a few things on, you know, small fast models on small images on a small subset of the data.
I would look at what data pre processing to use and what architecture to use. And then I would look at what are the constraints in terms of operationalizing this. How much RAM do we have how much latency can we get away with how's expensive is it going to be to then scale it up to the point at which, you know, we're getting acceptable results using acceptable resources.
I wouldn't look very different at all to, you know, a Kaggle competition in terms of the modeling, but then there'd be a whole piece of analysis around user requirements and costs and stuff like that. I see. I tried doing what you're doing was going from smaller to larger models and mine somehow started out with much lower accuracy.
Is it just a fluke or I mean I had several issues happen that and then you press the wrong buttons somehow. So I will. I think I already have, haven't I shared my notebooks. So if I haven't, I'll certainly share them today. Maybe I haven't yet. So I share my notebooks today.
So what I suggest you do is like, like, you know, go from mine, make sure you can rerun them and then look at yours and see how they're different and then figure out where you went wrong. But also like, yeah, you know, I always tell people when debugging like to look at the inputs and the output.
So what predictions are you making? Are you always predicting zero, for example, you know, did you run the LR find or define what learning rate works well. Yeah, stuff like that. Thank you. No worries. Jeremy, on the question for the production I I tried to after your work for last week, you did mention learn export and then later on we can learn that not know I found that is maybe there's a bug there because when I load and they actually looking for the P suffix is dot PTH.
But when we save and they say to the models folder, and then you can keep whatever name you want. But when you want to load them, they actually have the suffix at the end. So I'm not sure there's some. Yeah. So just to make sure you save it with a dot PTH suffix.
But yeah, it certainly would make sense. You're asked to do that automatically. But in the documentation, it seems it's a safe in pickle. The format is pickle. But the extent but, but this is just PyTorch so PyTorch uses, you know, a variant of the pickle format, and they normally use PTH as their extension.
So, yes, it is pickle and just it does use the PTH extension. Jeremy, when you're opening this window. Yeah, you typed in like something in the in the in the URL bar to get worried. Oh, I just typed my port number because I know that the only thing that has 8888 and that is okay.
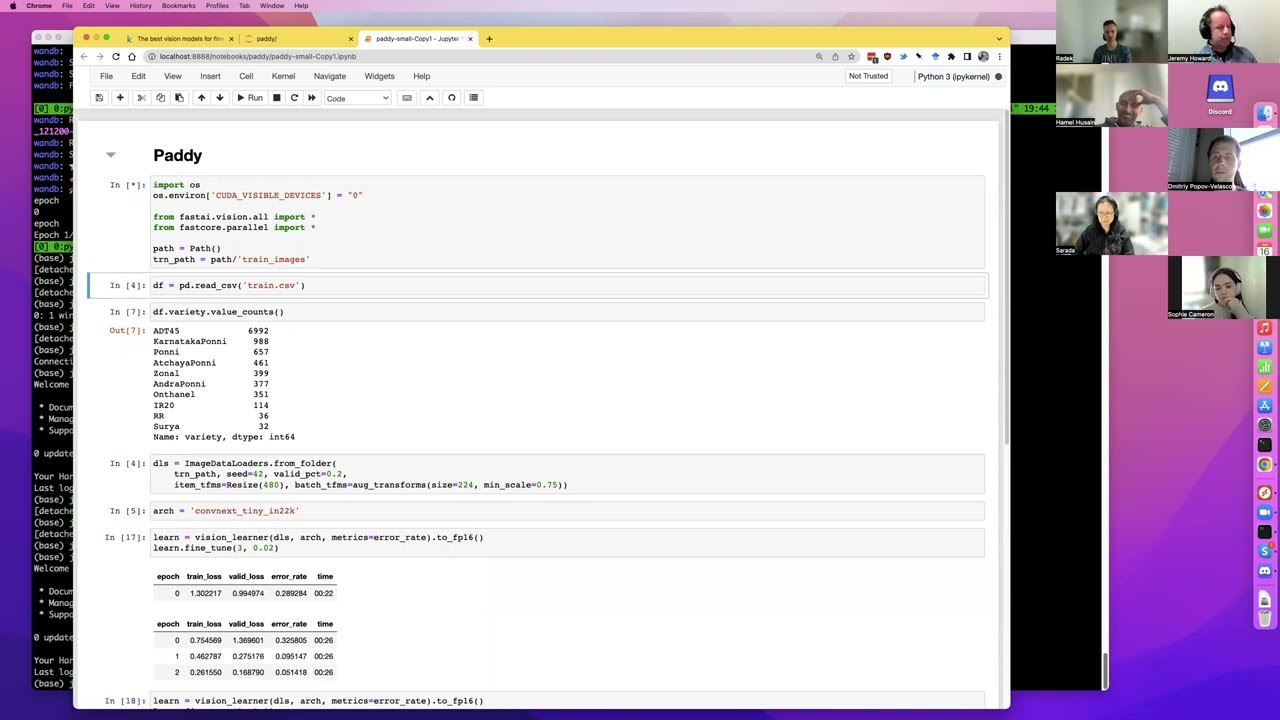
I have some magic going on. Yeah, nothing like that. Let me just shut these down. I did have one more idea about this competition. Which is there was that CSV file, right? Yes. Yeah, train.csv. That's right. And it has this variety thing. Well, and I want for variety, df.variety.
So there's 10,000 rows and 7,000 of them are one variety. But there are 3,000 rows that contain other varieties. So the only, you know, idea I had for this was something which is a bit counter intuitive but those of you that did I can't remember 2017 or 2018 fast AI might remember.
Sometimes if there's two different things just in this case what kind of rice is it, and what kind of disease is it sometimes trying to get your model to predict both of those things makes them better at both. So if we try to get our model to predict what kind of disease is it, and what kind of rice is it.
It might actually get better at predicting the kind of disease, which might sound counter intuitive right the I find it counter intuitive because it sounds like it's got more work to do. But you're also giving it more signal, like there's more things you're teaching it to look for and so maybe if it knows how to recognize different types of rice.
You can use that information to also recognize how different kinds of rice are impacted by different diseases. So, I have no idea if that's going to be useful or not but I thought it would be an interesting exercise to try to, to try to do that. So that's what I thought we might have a go at today.
That sounds of interest, which also is like frankly like a good exercise in delving into models in a way we've never done before. So, this is going to be like, yeah, much more sophisticated than anything we've done with deep learning before, which means it's very much up to you folks to stop me anytime something slightly confusing.
Because I actually want everybody to understand this. And it's a really good test of how well you understand what's going on inside a neural network so if you're not understanding it as a sign I haven't explained it very well. So, let me try. Let's have a look. Okay. So, one thing I just did yesterday afternoon was I just trained a model three times to see what the error rate was, because I wanted to get a sense of like how much variation is there.
And I found if a user error learning rate of 0.02 and just train for three epochs I seem to pretty consistently get reasonable results. So, that's something I can now do in two minutes. See how I'm going. So I thought that would be good. So, this is one thing I really like doing people are often very into doing reproducible training where they have like set the seed for their training and run the same thing every time.
And I think that's normally a bad idea, because I actually want to see like what the natural variation is and so if I make a change I don't want to know whether that's, you know, changes. The difference I see in the result is might be just due to natural variation, or it's actually something significant.
So that's why I did the natural variation is really large. Does that every week. Yeah, that's going to be tough to see like, did I improve things but then if the natural variation so large that improvements are invisible and trying to improve it seems pointless right because it sounds like you haven't really found a way to stably train something.
And normally that happens because my learning rates to be. So if you try this yourself and bump the learning rate up to point oh four you'll see like at least for me I got like 5% 6% five and a half percent, you know, it's like all over the place.
So, yeah, trading for more epochs at a lower learning rate will generally give you more stable results. And there's a compromise because doing more epochs is slow so that's why I was trying to find a learning rate and the number of epochs which is fast and stable. You could also try using a smaller subset of the data or, I don't know, like, in the end sometimes things just will be slow and such as life but most of the time I find I can get a compromise and I certainly did here, I think, with six epochs at half the learning rate I certainly can do better, I can get to 4%, you know, rather than five, but that's okay, I just want something for the testing.
I think that was always counterintuitive to me that I think you talk about is like these improvements that you make on a small scale, like, show up on the larger scale, like always. Oh yeah, absolutely. Basically, they pretty much always will. Yeah, because they're the same models with just more layers or wider activations.
Yeah, if you find something that's going to, some pre processing step that works well on a ConfNEXT tiny, it's going to work also well on a ConfNEXT large 99.9% of the time. Most people act as if that's not true, I find, but you know like in academia and stuff.
I feel like you have to do a full suite of everything. Yeah, which, like most people just never think to try, but like intuitively. Of course it's the same, you know, why wouldn't it be the same like it's, it is the same thing just scaled up a bit, they behave very similarly.
I mean it's hard to argue with you because it works. So, I mean, Yeah, you can argue that it's not intuitive, that's fine, but like, I feel like the only reason it would be not intuitive is because everybody's told you for years that it doesn't work that way. Do you know what I mean?
Nobody told you that. I think it'd be like, yeah, of course it works that way. That's fair. Okay, so, okay, let's do something crazy. Let's actually look at a model. So inside our learner, there's basically two main things. There's the data loaders, learner deals, and there's the model, learner model.
Okay, and we've seen these before. And if you've forgotten, then yeah, go back and have a look at the older videos from the, from the course. So the model itself, basically. Yeah, it's got like things in it. And in this case, the first thing in it is called a Tim body.
And the Tim body has things in it. The first thing in it is called model, and then Tim body dot model. It has things in it. The first thing is called the stem and the next thing is called the stages and so forth, right? So you can see how it's this kind of tree.
And we actually want to go all the way to the bottom. So the basic top, the very, there's two things in it at the very top level. There's a Tim body. And there's a thing here, which doesn't actually have a name, but we always call it the head. And so the body is the bit that basically does all the hard work of looking at the pixels and trying to find features and stuff like that.
That's something we call a convolutional neural network. And at the very end of that, it spits out a whole bunch of information about those pixels. And the head is the thing that then tries to make sense of that and make some predictions about what we're looking at. And so this is the head.
And as you can see, the head is pretty simple, whereas the body, which goes from here all the way to here, is not so simple. And we want to predict two things, what kind of rice it is and what disease it has. Now look at the very, very, very last layer.
It's a linear layer. So a linear layer, if you remember, is just something that does a matrix product. And the matrix product is a matrix which takes as input 512 features and spits out 10 features. So it's a 512 by 10 matrix. So let's do a few things. Let's grab the head, right?
So the head is the index one thing in the model. So there's our head. Quick question. You know, I've seen these model, sort of, whatever you want to call it x rays, a lot. Have you ever wanted to, like, is there, is there a way that maybe I don't know about to see the shape of the tensors as a flow, the shape of the data as it flows through the model?
You know, like, yeah. There it is. I don't even know about it. You should try watching some fast AI lectures. Yeah, so this will tell you how many parameters there are. And yeah, the shape as it goes through. And so the key thing is since we're predicting 10 probabilities, one probability for each of the 10 possible diseases, we end up with a shape of 64 by 10.
The 64 is because we're using a batch size of 64. And for each image, we're predicting 10 probabilities. It's very thorough and shows the callbacks. Wow. I don't remember this. Yeah, we don't look around, man. Here in fast AI, we're thorough. So, yeah, so I'm back to the question because that's that's a great thing for us to look at.
So, yeah, so in the head, let's create something called the last layer, which is going to be the end of the head and the very end of the head. So our last layer is this linear thing, right? And so this is so we could actually see the the parameters themselves.
Oh, I hope it does that. A lot of these things are generated lazily, right? So when you see this thing saying generator object, it's just it's it's literally the word is lazy. It's too lazy to actually bother calculating what it is. So it doesn't bother until you force it to.
So if you turn it into a list, it actually forces to generate it. OK, so it's a list of one thing, which is not surprising. Right. There it is. And so the last layer parameters. Is a matrix, which is there we go. Ten by five twelve. So it's transposed to what I said, but that's OK.
So we're getting 512 inputs. And when we multiply this by this matrix, we end up with 10 outputs. So. Oh, my daughter's wanting me. Sorry about that. Home schooling transitions always require some input. All right. So. So we're going to basically have to. If we got rid of this, right, then then our last.
Linear layer here would be taking in one thousand five hundred and thirty six features and spitting out 512 features. So what we could do would be to delete this layer. And instead, take those one thousand five hundred and thirty six. So this five hundred twelve features and create two linear layers, one with 10 outputs as before and one with however many.
Varieties there are. Which. Have a look. Hi, Jeremy. Yes. So I was just contemplating whether back in that linear layer where it was the output was ten by five twelve. Not the output. That's the matrix. So the output was ten. The output is sixty four by ten. Yes. So when you want to mix diseases with rice in the output, I was wondering whether that might be like I don't know how many rice types there are.
So there's five or ten. OK, so that ten might be ten by ten matrix output. No, two by ten. So you want one probability of what type of race is it and one probability of what disease does it have. OK. Yeah. So just two by ten. So let's let's go ahead and do the easy thing first, which is to delete the layer we don't want.
So this says sequential. So sequential means like literally PyTorch is going to go through and calculate this and take the output of that and pass it to this and take the output of that and pass it to this and so forth. Right. So if we delete the last layer, that's no problem.
It's just won't ever call it. So I can't quite remember if we can do this in sequential, but let's assume it works like normal Python. We should be able to go to delete. H minus one. That looks hopeful. Yeah, we can. OK, so it's got normal Python list semantics.
So this model will now be returning 512 output. So we want to basically wrap it in a model which instead has two linear layers. So there's a couple of ways we can do this, but let's do it like the most step by step away. We just need to wrap it.
That's the second look. So we're going to create a class. Right. So in PyTorch, modules are classes. Right. So we're going to take a class which includes this model. Right. So let's call this class. Disease and type classifier. Right. Now that is a. PyTorch calls all things that it basically uses as layers in a neural net a module.
So this is a neural net module. Now, if you haven't done any programming in Python before, it would be very helpful to read a tutorial about basic Python programming, because PyTorch assumes that you are pretty familiar with it. If you've done any kind of OO programming before, I'm going to work on the assumption you have.
Then the constructor. There's a lot of weird things in Python. The constructor is called dunder init. So this is this is so dunder means underscores on each side. And it always passes in the object being constructed or the object we're calling it on first. So we'll give that a name.
And so we're basically going to create two linear layers. And one easy way to create the correct kind of layer would be. Self dot one because we could do that. So one question is like I understand this sub classing thing. Yeah. Is there some other way that you could push to two additional layers onto the existing thing or does that make any sense?
Yeah, we could try that. Let's see if we get this one working and then we'll try the other way. How about that? And then we could also try using fast.ai has a create head function as well. So we'll see how we go. So here's here's linear layer number one.
And as you can see, I literally just copied and pasted. It's inside the end sub module. So I just had to add that. But the representation of it is nice and convenient and that I can just copy and paste it. In real life, we never normally write the in features now features.
Everybody kind of knows that the first two things are in and out features. So let's make it look more normal. So then the second layer and, you know, then maybe we'll like just give ourselves a note here. So we'll use this one for rice type and we'll use this one for disease.
OK, so at this point, once we create this is going to be these things are going to be in it. And then we also need to wrap the actual model. Right. So we'll just call that M and we'll just store that away. M equals M. So what happens is when PyTorch calls like basically modules act exactly like functions in Python in Python terms are called callables that act exactly like functions.
But the way PyTorch sets it up is when you call this function, which is actually a module, it will always call a specially named method in your class and the name of that is forward. So you have to create something called forward and it will pass the current set of features to it, which I normally I always call X.
I think most people call it X if I remember correctly. So this is going to contain a 64 by 512 tensor. OK, so. No, it's not going to contain a 64 by 512 tensor. It's going to contain an input tensor. This is going to be a model. So we need to create the 64 by 512 tensor from it by calling the model like so.
So results. In fact, what we often do is we'll go X equals because we're kind of making it like a sequential model going X equals. Oh, you know, another idea is we something else we can try is we can make this whole thing as a sequential model. Let's do that next.
So this is probably going to be the least easy way is what I'm doing it here, the most manual way. So we first of all call the original model and then basically we're going to create two separate outputs. The race type output. And the disease type output. And so then we could return both of them.
So that's so what I would then do is I would say let's create a new model. So disease type classifier. So we'd create it like this. And we need to pass in the existing model, which is this thing here. Right. Oh, yes. And you always have to call the super classes done to in it to construct the object before you do anything else.
There's a lot of. Annoying boilerplate in Python. Oh, I'm afraid. Okay, there we go. Okay, I just wanted to point out how cool it is that you created that the model was not the last layer by doing it on it. Yeah, that is so cool. I didn't know this existed.
Yeah, I had to do something quite difficult because how can you do stuff like that it's not a list and has only functionality to support this. Yeah, yeah, I mean, yeah, I kind of like it's nice. I generally find I can work on the assumption that PyTorch classes are well designed, because it turns out they generally are.
And so to me a world, you know, a well designed collection class would have the exact same behavior as Python. For example, fast course L collection class has the exact same behavior as Python. So, yeah. PyTorch is very nicely, very nicely made. So that thing where you deleted the thing and that's a PyTorch thing that's not fast.
Yeah, it's a PyTorch thing. This is just a regular. This is this is just part of the sequential. Yep. The sequential class. So, yep. Okay, nice. Wow. By the way, I asked if I would explode the model into layers and then reconstruct it using sequential without the layers that I need.
But hey, you can actually do this. This is so nice. Yeah, exactly. So let's create a new learner. Just be a copy of the last one, right. And then let's set the model to our new model. So we've now got a learner that contains our new model. So that's cool.
I guess at this point, I guess we should get some predictions, right? Wait, one. Oh, yeah. So the main thing I'm waiting for is the loss function. Like, yeah, yeah, yeah, yeah, yeah. That's that's we're going to get there. Let's, let's do this first. Okay. I suppose you're doing the predictions just to verify the plumbing is working.
Exactly. Okay. Okay. And it's not. It's stack trace input type. Oh, right, right, right. Floating point 16. Okay. Fair enough. I think to simplify things we're going to remove to FP 16. And we'll worry about that later. Is that some kind of mixed precision? Exactly mixed precision. Yes. So let's just pretend that doesn't exist for a moment.
And we'll come back to that. Okay. All right, so let's let's go back even simpler. It's useful to like, if you talk about what's going through your mind when you see this error. Yeah, I want to create like a minimum reproducible example. So, let's just like create a learner and then copy it, and then not change it at all.
I can't even do that. Alright, so this. So then I would be like, okay, let's not even copy it, but instead let's just call it directly. Learn to. Okay, that works. So doing a copy apparently doesn't work. Oh, though, generally speaking, I would be inclined to change copy to deep copy at this point.
So you still got the stack trace in the end. Oh, why are we still getting a half precision somewhere. That's various isn't it. Oh, it's probably because our data loaders got changed somehow let's recreate the data loaders as well. It nearly made it didn't it. Yeah, it looked like it was working.
And then, at the very end, there we go. How are we getting half precision what on earth is making it half precision. That's. That's odd. Do you think resetting your kernel and I think so. I don't see how this would help, but there's never any harm right. And one of the callbacks somehow.
Define. Yeah, maybe. Yep, that's exactly what happened. Okay well that's that shouldn't happen. So that's what a great way you know what happened. I don't know what happened like some like like Alex it's some something has some state. State that's keeping things in half position, which. Yeah, shouldn't be happening.
And so, at some point, we can try to figure out what that is, but not now. Okay, so let's make a copy of the learner. And check this in into it. Actually, before we do, we're just going to use the copy directly. So we just make as few changes each time as possible.
Okay, that worked. What are you looking for in this saying like I'm trying to see why it's returning. I thought that was a decoded thing so I was just wondering why it's being returned. Says here which is decoded equals false. By the targets. That's why. That's why that's why.
So it actually returns preds, targets. That's what it's returning. Okay. Alright, so now it's working quite nicely. And so I would be now inclined to like create a really minimal model, which is like a going to call dummy classifier. And all it does is a call the original model.
And let's see if that works. Because if this works, then we're at a point where we can then try out new models right. It's interesting I would have just gone straight back to the, the full model and tried that next, but you're slowly walking away. Yeah, I probably should have done it that way in the, you know, done it more slowly in the first place, but I got in over enthusiastic.
Okay, great. Let's see, Daisy. We could do this. We could do this inside our model, I guess. This is all pretty hacky but we're just trying to get something working. So the head is the number one thing in the model, the last layer is the end of the head.
Don't need that. Delete that last thing. We don't need that. Okay, so we might as well inline that. It's simple. Okay, so we delete the head and store it away. Okay, so we're going to create a letter. Create a class. This time we call the disease, etc classifier. Set the model to that.
Okay. Cool. Okay, so we're now at the point where it's trying to calculate loss, and it has no way to do that. I'm slightly surprised it's trying to calculate the loss at all. Since with loss is false. That's fine. So, okay, so the loss function to remind you is the thing which is like a number, which says how good is this model.
The loss function that that we were using was designed on something that only returned a single, a single tensor, and we're returning a couple of tenses. And so that's why when it tries to call the loss function, it gets confused, which is fair enough. So the loss function is another thing that is stored inside the learner.
Okay, there it is. So what we could do is we could. What's the best way to do this. One thing would be we could look at the source code for vision learner and see how that creates the loss function. It just passes it to learner. Okay, so let's look at that.
Okay, so it's trying to get it from the training data set. So the training data set knows what function loss function to use, which is pretty nifty. So to start with, we could let's create a loss function. So let's create a really simple loss function. So disease and type classifier loss that we're going to be past some.
We're going to be past predictions and actuals. Okay, so we're going to be past predictions. And what we could do is we could just say like for now, let's say the current loss function is whatever loss function we had before. And let's just try to predict. Let's just try to get it so it's working just on the disease prediction, which is this bit here.
So predictions will be a tuple. So this will be rice predictions. And it will be disease predictions. That'll be what's in our preds. And so just to start with, let's just keep getting this, get this so it keeps your works on disease predictions. So we'll just return whatever the current loss function was and we'll call it on the disease predictions.
Okay, so now we need to go learn to dot loss function is that function we just created. Interesting. Sorry, when you did that, to like, set the current loss, set the gloss function in the learner. Didn't want this mess up your code. I guess like you need to create the learner again.
Nevermind. Sorry. Okay. Jeremy, do you want to go up a little bit back to your loss function? Is it you actually want to pass the predict target disease disease? Okay. No, no, sorry. So I'm just going to ignore the rice type prediction for now. And just try to get it our new thing working to continue to do exactly what it did before, but with this new structure around it.
Do we have to split the targets as well? No, because at the moment, our targets, we haven't included anything other than just the diseases in the targets. So yeah, we're going to have to change our data loading as well to include the rice type as well. But we haven't done that yet.
Okay. Okay. Ah, yes. Okay. So then we've got metrics. So metrics are the things that just get printed out as you go, and we don't yet have a metric that works on this. So a very easy way to fix that is just to remove metrics for now. Great. Now, preds.shape shouldn't work.
Good, it doesn't, because now we've got two sets of predictions. Right, we've got a tuple, because that's the predictions is just whatever's whatever the model creates the model is creating two things, not one. So we've now got rice predictions and disease predictions. That's actually pretty good progress, I think.
But you know, like, for those of you who are involved in fast AI development, you know, it's pretty clear to me and try to do this, that this is far harder than it should be, and it feels like something that should be easy to do. I used to see Andrew using the magic, the percentage and then have a patch, and then just add some little thing on top of it.
Yeah, it's not so much about patching it's about, I feel like there might even be some multi loss thing. If there's not I feel like this is something we should add to fast AI to make it easier. Can you explain a little bit about the why the loss is stored in the data loader like how that is a good thing.
Yeah, sure. So, generally speaking, what is the appropriate loss function to use or at least a reasonable default depends on what kind of data you have. So if your data is, you know, a single continuous output you probably have a regression problems you probably want mean squared error. If it's a single categorical variable you probably want cross entropy loss.
If you have a multi categorical variable, you know, you probably want that log loss without the softmax and so forth. So yeah, basically by having it come from the, the data set means that you can get sensible defaults that ought to work for that data set. So that's why we generally most of the time don't have to specify what loss function to use.
Unless we're doing something kind of non standard. Alright, so we're about to wrap up. The last thing I think I might do is just try to put this back, and we can do it exactly the same way, which is to say DTC error. So, pop this a bit higher.
Oh no, it's okay, we're done here. So, we'll just return error rate on the disease predictions. Learn two dot metrics equals DTC error. Cool. So I guess we should now be able to do things like learn two dot lrfind, for example. And this should, we should be able to just replicate our disease model at this point.
So we're going to think with this extra rice type thing yet, and fine tune. One epoch. 0.05 say 0.01 say. Let's see if I search like fastai multiple loss function or something. 2018 is going to be too long ago. No, nothing there. I gotta go but yeah, that's a lot.
No worries. It looks like this person did something pretty similar. They created their own little multitask loss wrapper. All right, cool. Well, I think we're at a good place to stop that's. We've got back so it's not totally broken. So that's good. And next time we will try and plug this stuff in.
Anybody have any questions or anything before you wrap up. Just a quick question, Jeremy it says the valley is point zero zero one but you use point zero one for the fine tune. Yeah, I'm not sure to see this is pretty, this is it's picked out something pretty early in the curve I thought something down here seems more reasonable.
Despite, you know, it tends to recommend like rather conservative values. So, yeah, I tend to kind of look for the bit that's I kind of look for the bit that's as far to the right as possible but still looks pretty steep gradient. Okay. Thank you. All right. Hey gang.
Thanks.