The Fastlite DB library - Answer.AI dev chat #2
Transcript
OK, welcome to our dev chat with Jono, Alexis, Luke. We are going to talk about this library that I just created over the weekend called Fastlight. It was meant to be called FastSQLite, but there's already a FastSQLite, so it became Fastlight. I think it just took me a day to write this, which I'm quite pleased with how quickly it went and it's really because it's just pasting together two other people's work on the whole.
So let me describe what this is about. So I'm kind of on a bit of a mission at the moment to make web application programming easy again, like put a PHP file in your home directory kind of easy, or stick a .pl file in your CGI bin directory kind of easy.
So I've been looking into like, OK, where do we stick our data for our web application? And two very popular options at the moment are SQLAlchemy, which is kind of the original ORM, Object Relational Mapping, and the very trendy SQLModel from Sebastian, the amazing author of FastAPI, amongst other things.
And yeah, because I think Sebastian's work tends to be extremely good, I kind of assumed I would go with SQLModel. And I went through the kind of documentation, the original tutorial. And I kind of very quickly early on got to this bit where it's like, oh, OK, you have to create these five different things with different inheritance hierarchies and passing things to constructors and a rather lengthy-- and I was like, wow, that's-- I'm not sure I'm clever enough to remember or do all that.
I think I'm probably too lazy to do it anyway. So I was a bit turned off of that. So then I started-- I've used SQLAlchemy before, but I always forget how to use it, which is never a good sign. And there's been a version 2, so I wanted to use the new version properly.
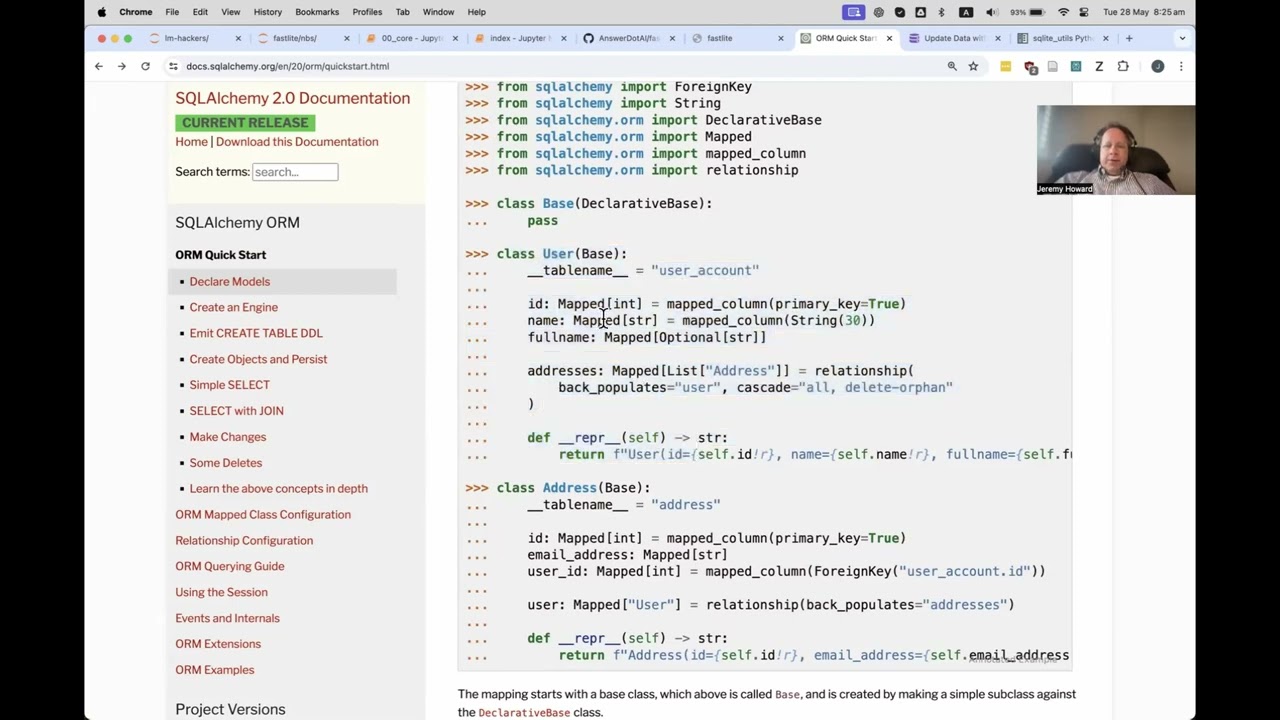
And again, I kind of started looking at their quick start. And you have to have a subclass and then a subclass of that subclass. And magic names in them and both annotations and defaults. And again, I was like, I don't think I can do all that. So also, I know how to write SQL.
And I know how to use GUIs. I really like GUIs for databases. You can kind of see them all there and move things around and-- I thought, like, hmm. I started to link these two together and understand, like, well, why can't I just use SQL? And you can. Like, SQLAlchemy also has this SQLAlchemyCore piece, which is part of this unified tutorial, which is this foundational Alchemy database toolkit, whatever.
So I read quite a bit of that. And I also got an O'Reilly book about SQLAlchemy and read that. I still felt not smart enough to do that either. So I kind of kept looking around a bit and remembered that my friend Simon Willison had created a thing called SQLiteUtils, which I remembered was this command line application for using SQLite for doing stuff like this.
And you could pipe data to it. And you could do CSV files and all this. And I remember when Jono and I were looking at Simon's LLM library, one of the things we discovered was that, like, actually the CLI was just a kind of a thin wrapper for a really nicely designed Python API.
And I thought, like, oh, I wonder if that was the case for this, too. And I looked. I was like, oh, it is also the case here. And I was like, oh, OK. So then I kind of started again. And this is the getting started. I was like, OK, even I can do this.
Database, name of file, table, insert, a list of dictionaries, loop through them like this, get back. And I'm like, OK, I think I'm done. I'm ready to work now. So that's why I leant towards this. So I don't know. Do you guys have any thoughts about should I be-- is this a mistake?
Should I be using an ORM? Or does this seem like a reasonable place to start? So I've had this experience. And it's been mixed for me where I see something and say, that looks way too complicated. I'm sure I can figure out something simpler. And then I either write or find a thing that looks simpler.
And then you hit a point where it's like, oh, it would be really good if it did this or that. And so then you start tacking on those bits. And you end up with something that ends up just as complicated as the end product. But I'm assuming, because you're showing us this thing and you're happy with it, that we're hopefully not going to end up back at the convoluted Jeremy's version of SQLchemy.
No, I mean, I don't think so. Because you just passed SQL, which I guess-- OK, it's a whole other language designed out of a whole area of math called relational algebra to be especially around dealing with relational data. So I don't think you could ever hit a point where it's like, oh, we can't do stuff.
Because this is just like, no. When I say just use SQL, for somebody who doesn't know SQL, that's a huge just. But I don't know. It feels like in the past, when I did a lot of stuff with C#, that's what we wrote Kaggle in. We were always talking about SQL versus ORMs.
And I don't know. They're both fine, I guess. But in this particular case, I think-- I don't know what it was about it. But I guess Python being a dynamic language, ORMs tend to be quite a good fit for more static languages, maybe. But even there, when I used to use F#, F# had this really cool thing called type providers, where it actually looked more like this, which is pretty neat.
So yeah, I don't think-- I'm pretty sure you'd never get to a situation where it's like, oh, we're going to have to add a whole lot of complexity. You might get to a situation where it's like, oh, I would love to add a few more shortcuts to make some of this SQL a bit easier to work with.
But even there, I feel like the way we do SQL is like-- you just pass parameters, you know? Question mark, insert, or do it by name. I quite like the look of it. I agree with your instinct here, because I think it's often a sign of a good taste when something doesn't require you to learn a lot to use it.
So if it doesn't require you to learn its own concepts, its own type names-- Yeah, also, I trust Simon. Simon, he's written lots of stuff in this, and he's been working on this since 2018. So presumably, if it wasn't doing what he needed it to do, he would have noticed by now.
So OK, so that's the background. So then I just started playing with it. And so when I spoke to Sebastian, who writes SQL Model and FastAPI and whatnot, he told me that a big driver of how he writes things and what he writes is he wants autocomplete. And I feel the same way.
And I think this is actually often what's going on here, is why not just use a create table statement? It's like, well, in VS Code or whatever, you need something like this for it to be able to give you autocomplete, because otherwise it doesn't know what fields are in a user and what their types are and so forth.
And it's not just the autocomplete, but also because this is working with identic, which checks things. That's why there's all this extra stuff here to make sure at each time you're validating correctly. And I guess if I was using a static language, maybe that's what I'd be wanting. But in a dynamic language, I feel like I would like to take advantage of the dynamic features of the language.
That's kind of why I use Python to a large degree. So the kind of thing that that means, then, is if you-- I don't know if you guys like Brett Victor. Brett Victor has this idea of never work in a dead environment. He's got this talk called "Stop Drawing Dead Fish." Always work in a live environment.
A live environment is something where you're directly manipulating the information or the content or whatever in real time. You can see it. And yeah, you can't get that in VS Code. I mean, VS Code has notebooks. But if you're not using notebooks, the rest of the notebook, it's a live environment, right?
So if I start writing a few cells here, so I, from sqliteutils, I've imported database. And then this database, Chinook, is something you can download. I've got it in the readme, how to download it. And that's now something I can-- if I hit Tab, I know these are the actual things in DB because it's actually checking dynamically.
It's actually behind the scenes doing that. And the ones that start in underscore, it doesn't show me because they're considered private. So it'll show me these. So you can check that, db.a tab. There they are, right? But having said that, I can do like this to see the tables.
I can do this to get a particular table. Sorry, this to get a particular table. But this particular library isn't designed to take advantage of Python's dynamic features. So I can't hit Tab here or anything and see the tables. So I have to copy and paste or go to tables, find it, double-click it, come back, do this, et cetera.
So I don't like that. So yeah, basically, the main thing I wanted to do is make it so I can use this as easily as I can use files and folders in Bash or ZSH by hitting Tab and seeing all my options and stuff. So I'm going to show you what it looks like to use it.
And yeah, tell me if you think this-- yeah, if any of it doesn't make sense or doesn't seem interesting or whatever. So yeah, so in the-- this is the-- so because this is an nbdev project, that means that the index notebook is the same as the readme, is the same as the documentation.
So yeah, so this is the repo. You can click up here to get to the documentation. And the documentation is the same as the index.ipamd, which is the same as the-- which is the same as the readme. And so it's nice that you can open up that in Jupyter or Colab or whatever and try it.
So my database now with Fastlight-- Fastlight adds a T property. SQLAlchemy has a C property, which is similar. So I'm going to try to borrow some ideas from SQLAlchemy as well, make things not too weird. So db.t. And that has autocomplete. And so I can click it, or I can tab, enter, and I've got the actual thing.
I'm too lazy to press B, full stop. So you can store that in a thing. So that's the database tables. And also, I've tried to-- another thing I think is nice when you're working in a notebook is to make sure things have a nice representation. So when I show the database tables object, which I remember is the thing I've got this tab completion on it, it lists out the tables.
So yeah, so I can grab a particular table. I can store it somewhere. Or I can-- another thing I added is you can grab multiple tables by using an indexer, which I think is quite Pythonic. And yeah, as mentioned, we can also do our tab completion. So that's piece number one of this.
And then, yeah, piece number two is once you've got a table, which remember we got by doing this. So from the database tables, we got the artist table. So from that, we can get the columns with C. And so you won't be surprised to hear that, first of all, that column list has a nice representation and that we can autocomplete it.
So columns are less interesting than tables. Table is actually a particular type that has things like primary keys and various methods and whatever else. Columns are nothing fancy, actually. In SQLite Utils, so the only thing a column basically has of interest is its type and its name. So since my thinking was like, yeah, let's just use SQL, that means I want to have tab completion as I write SQL queries.
So this is kind of nice. If I do an fstring, then I've got tab completion of any tables I've created. Or I could do it this way as well. So in this case, I've already got it in a variable. And ditto-- so for my album columns, I've got completion of that as well.
Now, what's that doing? All it's doing, if I say-- if I stringify that column name, is this is what it appears as. It appears as the artist in double quotes dot name in double quotes, which in SQL-- most dialects of SQL, including SQLite, that's how you represent a name that could have spaces in it, or slashes in it, or whatever else.
So this basically ensures that your names will work correctly. Ditto for your table name here. So it's not doing very much. It's just giving you this convenient tab completion and correct behavior. Can I ask a question? Yeah. So the reason that you were able to get a tab completion on the first field, artist with a lowercase a, that's just because you happened to have defined that variable in the notebook environment, right?
It wasn't-- OK. Exactly. So the things that get tab completed in Jupyter are the keys to this dictionary. This dictionary, called globals in Python, is all the stuff you have access to. So for example, there's a-- so if I go g equals globals, and then I look up, here is all of the things.
So I should find that there's a thing called open, for instance. There it is, right? And that would be exactly the same as saying globals open. So this is just the-- this is what Python's syntax sugar is, you know? So that's the top level-- You could write it with no bare words except the word globals, and for, and if, and def, you know?
So if you, say, were manipulating two SQLite databases, and then you were still just authoring that query string, and you wanted to get autocomplete that was scoped to the tables in this database versus that database, then you'd need to do something like db1.tables. or something, and then it might-- Well, it's not tables, it's t.
But yeah, so you could-- exactly. So you'd have db1 and db2, and you'd have db.t.blah. Or you could have, earlier on, if you're using it multiple times, you would have said, like, visual artists equals db visual.t.artist, or whatever, and then there'd be other artists. And yeah, so you can name them whatever you like.
OK, cool. So yeah, that is just a regular variable that happens to contain a symbol of type db.table. And it stringifies like so. And that's why that works. So yeah, so I added a little .q thing, which you just pass a query to, and it just returns the result of executing that query on that database.
So just like t is tables, v is views. So this particular database doesn't come with any views. So I created a very important view, which is all of the albums in the database created by ACDC, or as we call it in Australia, ACADACA. So there is our ACDC. So here, I've created my album variable.
And again, I don't have to do that. I could just write dt.album. And then I've got a SELECT statement here. And if you want to, you could have a look at that. So that's all it's done, right? Again, album just adds the quotes around it. AC.name fully qualifies it.
So that's the view that we created. I don't know how common this is, if it's just a SQLite thing, but this is just a shortcut for saying onAlbum.artistId equals artist.artistId. It's just a convenient way of doing an inner join when they both have the same name. Anyway, the main thing there is to say we created a view.
And then we can query the view. And so now, bump. There's only one thing in db.v, because there's just one view. OK. So this next bit's kind of magic. You can go Diagram, db.tables. And I find this super helpful. I'm a very visual person. I don't really understand a database until I see it.
And so you can see here this Chinook database that we downloaded. There are employees. There's a self join on reports, too. There are artists that have albums. Albums that have-- I should probably join these arrows in the opposite direction, shouldn't I? So it should be an album, one to many has-- yeah, so I might-- I don't know, which way around does it make sense for the-- should it point to the primary key, or should the primary key point to the many side?
What did access do? Oh, they didn't have arrows. That's right. They had to do one indicators and many indicators. That doesn't quite help. Anyway, we'll think about whether we should turn those around. So an artist has album, an album has tracks. A track is-- could be a number of tracks in an invoice line.
So I guess this is a many to many. Invoice has many tracks. Track has many invoices. An invoice is for a customer. A customer has a support rep. A support rep has someone they report to. And tracks can be on playlists. And playlists can have tracks. Anyway, so that's that.
And then this is just a list of tables. And so we can combine that with that convenient indexing thing we saw earlier to pick a subset of tables to diagram if you want to. And you can give it a size and a ratio. Yeah, so that's about it. So I'm planning to-- I think this will make life easier for me as I try to build up my web application from a database.
Yeah, I don't know. Do you guys have any thoughts? It's like watching this, it feels like there's some new libraries that you write that are entirely around some piece of functionality that doesn't exist. I want to create this type of file from that type of file. And then the user interface is like a single command line script or whatever that gets run.
And this is like the complete inverse. A lot of the functionality of-- I haven't got any functionality, except the diagram. But the user interface is what's important. And it's not that Simon's library doesn't have a nice user interface. It has an excellent user interface for the command line, which is where he likes to work.
And it's just a different user interface that works best with-- Just stop for a moment. I just-- let me-- I just saw Vic saying something in Discord. I don't want that to appear in our dev chat. Can you restart your last sentence? And I will edit over it. So it's not that Simon's user interface for this functionality is bad.
It's just that it's very optimized for the command line. It's excellent for the command line, which is where he likes to work. And VS Code, probably. Yeah, and VS Code and others. This is not just basically creating a new UI or translation of that to the type of Jupyter interactive coding that suits you.
Yeah, yeah. And Sebastien's like SQL Model and SQL Acme, in particular, really focused on getting autocomplete and stuff into VS Code. And yeah, that's totally fine. Do you know what I mean? But it does mean that you have to-- at some point, you either have to-- instead of using Create Table in SQL, you have to define it as a class and then have some process that creates the tables from the class.
Or you have to have something that kind of codegens class files that VS Code can read from the database. And SQL Acme provides both of those things. But yeah, I like this kind of dynamic approach where I feel like SQL is a language that I'm quite comfortable with and is-- I can use everywhere.
And I don't have to learn the particular quirks, quirks not in a bad way, but each ORM has its own way of doing things. Yeah, that's why I don't really have to learn that. Yeah. It's funny to think of the-- it almost feels like an oxymoron to have this database interaction in the notebook.
Because the way I often think about it, or at least I have friends who work on companies where you sit and write down the database on paper or in a diagramming software. And it becomes the static thing of this is the types of data that we're committed to using.
We have these rows. We can't change them. This database is this fixed object. And then my code would now use this static definition. And then I'd want to follow that very rigidly. And so then it really makes sense to have, OK, I define my database. Maybe it's in SQL that we write it, or maybe it's in something that spits out SQL.
But then also I have a way to interact with that for my code that's very known in advance and defined. Yeah, I guess that's maybe-- That's our way. But also a lot of DBAs do it a very different way, which is they live in SQL admin applications. And they tend to have auto-completion of column names and table names and stuff.
This was the original intention. SQL was supposed to be human-friendly and interactive. It just ended up being maybe not quite as human-friendly and interactive as we'd all like it to be because of language design failures or just it's a difficult domain. I quite like it. I have one thought and one question.
The thought is, I think, that this interface that you've presented has the same merits as the library assignments that you're building on top of, which is it doesn't require you to learn a new thing because it's working with what's already there. Simon's thing just requires you to know about Python dictionaries and iteration in order to interact with SQL rather than learn a bunch of maybe cockamamie new things that aren't new enough to justify existing.
And here, you're working with the autocomplete that's already in Jupyter. You're not requiring a new Jupyter extension and a new key bind. That's the charm of it. It'll also work in IPython. It'll also work in pretty much any other interactive environment. Yeah, that was my question. Because you're saying, well, this is good for notebooks.
But it's really good for anyone who doesn't want an interactive prompt. So if I'm just using, as I often do, the Python prompt in Emacs where there's tab completion and that's based on read line, I think I'd still get the better-- Could work fine in Emacs as well, yeah.
Yeah. Yeah. Yeah, so let me show you how it's implemented. Yeah, that was my next question. I'm kind of curious how this works because you've emphasized, well, you'd need to use all these static types to get autocomplete in VS Code, but you're getting autocomplete without building a static type superstructure.
So I imagine you're-- And this is like-- the interesting thing is, Alexis, I know a lot of your background has been Swift, which is a static, largely a static language. It has dynamic extensions. And it was created originally as a static language. Python was created as a dynamic language.
And it's funny. People are trying to turn it into a static language. It's almost as if people feel like they're not proper grown-up software engineers unless they have strong typing and all this stuff. But actually, as you'll see, as we dig into how this works, Python is very much designed to have a lot of flexibility for the developer to provide dynamic behavior that works for you.
So in fact, if we look at the actual Python file that gets built, this is it. All of the functionality in this, if you think about how many blank lines there are, it's about 100 lines of code. And it's 15 before we get past the comments and the imports.
So in practice, it might be more like 80 lines of code or less. So yeah, it really is just using the functionality that Python provides, that Guido created when he created Python. And this is functionality that's been in Python pretty much since day one. And it goes back to this basic idea of Python is this very small kernel, which everything else is built with that kernel, really.
So let me show you what I mean. So as with pretty much everything I write, the implementation, the source code of Fastlight is a notebook. And so as I built this, because I'd never used Simon's thing before, I was trying to use Simon's thing. And each time I found myself not having access to something I wanted, I wrote that thing, and then I kept moving on.
So that's kind of how this got built. So what happens when we do db.t? So that is an object with a particular type. And its type is tables getter. So here's the definition of tables getter. Now tables getter derives from getter plus one thing. So it might be easier to pretend that this dir was actually over here, and that this thing was called tables getter.
That's the same thing as what the inheritance does, right? It just sticks it in there. OK. So remembering that basically this can be thought of as all one thing, because that's how inheritance works, what happens when we just write dt on its own? How did it end up with this comma separated list of tables?
So that's because pretty much every part of the behavior of classes in Python is defined by methods of that class. And what is displayed in a notebook, or in IPython, or in lots and lots and lots of places in Python and things around that, is defined by this dunder repra.
So something with two underscores on either side means this is a magic method, which will be called by Python or some other thing in some situation automatically. So this is the thing that will get called-- specifically, it's called when this function called repra is called. And that function called repra is called by Python a lot.
And it's called by Jupyter any time something is displayed. It provides the representation of that item. So when we say dt, it actually calls dunder repra. And that returns commas joining up der self. OK. So obviously, that means we want to know what is der dt. And somehow, that's become a list of the things we wanted to join.
Der is used, again, in lots of places in Python. And specifically, any time you do an autocomplete, it's actually calling der. And when you call der behind the scenes, it actually calls dunder der. So you'll see that is der is exactly the same as me going dt dot der.
OK. Same thing. So here's der. And so that just returns the table names. And that's just part of SQLite utils. So OK, so a getter joins up the table names when you get a representation of it. So that's how that works. Does that make sense so far? Yep. OK.
Makes sense. How come this works? Well, when you square bracket index into something in Python, it calls this special thing, dunder get item. So dunder get item, if you pass a single thing, then this will be just a string. And if you pass a bunch of things, then this will be a tuple.
So if you passed in a single thing, for simplicity, I'll just make it a list with one thing in it. And so then I just want to return that table for each table that you requested. So that's how that works. So we want to do the same thing for columns.
So I created a columns getter. It's got a der. It's got a repre. And this one's got a bit of extra magic, which is that I create-- because SQLiteUtils doesn't have a column class. Columns are just strings. But I wanted each column to remember what table it came from so that I could have it spit out table.name when it's stringified.
So cols getter, when you-- how do I explain this? So let's say, OK, so I go artist.c. That's going to give me a cols getter for the artist table. So here's the list of columns. That's created by calling repre. This is exactly the same as before. Repre joins up the der.
And this time, the der just calls repre on each thing on self parentheses. So when you call a class like a function, it uses this special one, dunder call. So this is actually the list of things. So it's going to go through each column in the table. And it's going to create a _col with the table name and the column name, which it then saves away.
And then it then calls repre on each one of those columns, which calls col.dunderrepre, as you see. And that just returns-- well, that's totally pointless. That is exactly the same as that, I guess. Right. OK. So the representation of a column is just the column name. Yep. So you had the generic getter class above.
Is there a reason this is not using that? Is it because you have to have the special functionality? Yeah, this was for table and view getters. This one doesn't have any ability to pass in a column name. The only thing that's shared is kind of that, I guess. Even that's not quite shared.
Oh, OK. The only thing that's shared is that. So you could put that in a super class. But at that point, it's like you're not really saving it. Yeah, OK. OK. So when you have an f string, and you put something in curly brackets inside it, it calls-- it's the same as calling this function.
And when you call that function, behind the scenes, it calls dunderstr. So this is-- people often get confused about dunderstr versus dunderrepre. So this is called by Jupyter when getting the representation of something. This is called when stringifying it, such as putting it inside an f string. So in that case, we have the table in quotes, and then the dot, and then the column in quotes.
So that's how come this works. And then I think we've probably talked about patch before. But just in case people missed that last time, this is part of FastCore. And it's just going to add this method or property to this class. And since we said as prop, it makes it a property.
So that's how come database now has a dot T. I think this is a lot more ergonomic than having a whole separate fastlite.tables bracket database or something. Generally speaking, the way I think about patches, if there's something which I think to myself, like, oh, I feel like I would have liked this library better if this was built into it, then I use patch.
And now it is built into it. OK. So again, I do the same for table and view, which are both parts of SQLite utils. So I patch in a stru for those. And that's actually exactly the same. And so now I can do the whole SQL statement. OK. So that's not much code, obviously.
But it kind of gets us quite a long way. Now, this is super lazy, of which I'm not ashamed. There's already a dot query in database. And you can pass it a query. And it returns a generator. And doing that is enough to make me sad. So queue is a very common thing for queries.
Like, for example, in URLs, queue is normally the query. So I just thought, OK, let's add queue. So that just does a list of a query. So again, just for interactive use, slight convenience. And if you're someone who prefers the type query, there's nothing wrong with that. You could also patch in a thing called query if you wanted to just do the listing.
The whole thing with this is that it's malleable and flexible. So this is like, oh-- Yeah, and I didn't want to change the behavior that's already there. Because if you want to use a generator, there's good reasons to use generators sometimes. Yeah, so if you want to-- paging through a 1 million row table, then you don't have to put the whole thing in memory.
But that's, like, much less common. Most of the time, I'm not working with million row tables. So I have the short one be the thing which is the thing I want to do most of the time. OK, so this is just doing the view thing, which we've already seen.
So you can see now I've just added views getter, which is exactly the same as tables getter, but it's view names. And so v is just that. OK, so we can now check our Akadeka albums. And there we are. All right. So do we want to move on to diagrams or anything else to discuss there first?
I guess I have a little question. I don't know much about how VS Code autocomplete works. But given that Python does offer dynamic access to namespaces that are associated with objects, what other constraint or goal is causing people not to make use of that when they do autocomplete? The code has to be executed, right?
So if you're in a .py file and you're halfway through, it hasn't executed the code above, which is different to a book order. That makes sense. And in general, you wouldn't want VS Code to automatically execute the code. I mean, I do think there's room to create an extension, which kind of, like, maybe there's some special comments or something, something at the top of a file that describes what objects to create and how to create them so that you then do get dynamic autocomplete.
But yeah, the thing that you're getting autocomplete for in VS Code is classes, not objects on the whole. And so that's why it relies on-- people generally put type annotations in here and return annotations in here, because they don't have that dynamic environment to use. Yeah. OK. So yeah, OK, so I looked around for database schema diagrams, et cetera, et cetera.
And I didn't find great options. Either they were kind of expensive or they were very heavyweight things. And my biggest complaint was that most of them looked like this. And my problem is that in this type of diagram, you can't tell what is joined to what. Like, the lines just go to random places on the boxes.
So what the hell is it? What readings dot what is connected to where in sensors? So I don't know why this is such a common way of doing things. But I grew up on Microsoft Access, which I have always felt like is the best at this stuff. And Microsoft Access has always shown you exactly what field gets mapped to what.
So I really wanted that. And also, I wanted it in a notebook, like jumping in and out to different programs and kind of annoying. Having said that, this seemed like way too difficult a task for me to bother with, given the amount of time it would save. I thought maybe I'd spend the $200 a year on the license, whatever.
But then I remembered that there's this amazing program called GraphViz, which has been around for 33 years. And it converts a small piece of text into a diagram. I wonder if I've got an easy example. Good lord, they don't make it easy. Just jump straight into the full specification.
I feel like GraphViz is right up there with FFmpeg, where the correct way to use it is something like chatGBT and/or find an example that looks kind of like what you want and then copy it. No one is expected to know it. This is very much the case. And of course, the galleries are ridiculously overcomplicated.
I'm not quite ready for that yet. Thank you. Oh my god, and I never want to be ready for that. Thank you. Oh, look, here we go, finally. A not-too-complicated one. I mean, even easier would be nice. Here we go. So basically, they're called .files. There's a program called dot.
And you create a digraph. You give it a name. Doesn't matter what you call it. And then you have a thing in curly brackets. And the thing in curly brackets has a string, an arrow, and another string. And that creates a picture of a directed graph from string A to string B.
And that's actually it. So we could-- it's nice that we've got a playground now. Hello, Jono. Wow, real time. Hello, Alexis. So you can see that if it's the same word, it's the same node, you know. Bit morbid, never mind. You get the idea. So actually, the basics of GraphViz are super simple.
And I think the problem is people often show overly complex examples. So with that said, let's now look at an overly complex example. So our example is going to create this. Now, what we might do first is we could make it a little bit less complex. That would be crazy.
Let's just do artist and album. Let's run that. OK. So I added a thing to this called render, which if you set it to false, it just returns the string. So then we can print that. OK. So maybe we'll look at the thing that comes out of it as well.
And you know what we could do? We could just grab that and just go s equals and print-- not print, display. OK. So now we can fiddle around a bit and get rid of stuff that's not really needed. There we go. So here we are taking advantage of a quite interesting and curious addition to GraphViz that instead of just having-- so here, this is the thing I just showed you, right?
But if I just had those strings, remember, they just appear like this, right? But you can define ahead of time what a thing is, as we've done here. And in this case, we have defined ahead of time that actually album is a table. And the album table, it's just-- as you can see, it's HTML.
It's an HTML table. It's not really HTML. GraphViz just so happens to have borrowed this HTML-like dialect for describing table nodes. So a table has rows, and a row has cells, data. And they can have attributes. So one of the interesting attributes is port, which is basically giving a name to this row.
So when we say album colon artist ID, it finds the album node, and it finds the artist ID port. And that's going to be the start of its error. And then this is just a Unicode key I put next to each one. And then I also added a-- I believe this is called blanched almond, this color, blanched almond background on each one.
And without this left to right rank direction, you can see it goes top to bottom, which is not great. So I feel like most of the time in GraphViz, I want left to right. I don't know. It's just me. It probably isn't, right? Because our screens are wider than they are tall.
So if it's tough for a screen, you normally want that. You can make it a graph instead of a digraph. Digraph means directed graph. So if it's an undirected graph, then you can't give it an arrow anymore. I don't really know of a reason not to use digraph, because you can add annotations to these edges to say to add an arrow on both sides, or just on one side, or on no sides.
So I think always you just write digraph, g curly, rank to lr, then your definition, and then curly. Well, that's a quick guide to GraphViz. Does that make sense so far? Yep. OK, so we just have to build up this string. So yeah, the way I did it was I just wrote one kind of by hand and tried to make it look nice.
And then once it looked nice, I just did basic string manipulation until the string looked the same. And then once the string looked the same, I tried rendering it. So I'll leave Neato for a moment. So yeah, basically, I'm going to need a list of edges at the bottom.
That's going to be these bits down here. So my edges just go through each of my tables and grab the edges. So an edge is a foreign key. So this is why I don't use auto formatters like Black, by the way. When you've got two things that are doing the same thing, I like everything to line up.
No auto formatter is going to put the extra space in there for you. So edges-- yeah, it calls edge on my table. So that's going to go through all the tables' foreign keys. So you can see up here, I was just checking to see how that worked for myself.
It's like, OK, yeah, it's just a list of foreign key. And that has a definition. So yeah, go through each foreign key. And then I just want an fString that goes from table.column to other table.otherColumn. So it's nice how simple it feels when it comes out. So then my table nodes, which is these bits, basically consist of the table part and the rows part.
So my table nodes is going to be a _tnode applied to each table. So my tnode applied to a table is going to have all my rows in the middle. I'm calling _row. And then around that will be table. And then this is the name of the table at the top in light gray.
And then all my rows. So my row, I'm going to have a row for each column. So if it's a primary key, it's going to have that on the end. Also, if it's a primary key, it's going to have this in there. And so the port's just the code name.
There's that background color. And then there's the actual text that appears. And then there's the primary key bit. That's it. Yeah, so it's just jing manipulation. So that's that. And so then, yeah, so when I export that, that then ends up in the Python file I showed you. And yeah, in this case, to create the home page/readme, all I did was I actually just made a copy of this notebook, deleted all of the actual source code definitions.
And most of it otherwise is basically the same. nbdev uses Quarto behind the scenes. So these screenshots look huge. And that's because of, I think, the retina rendering or whatever they have where it's not pixel for pixel, but it's kind of sub-pixel rendered. So you have to do something special to make that appear correctly, which Jupyter Notebook does not currently do by default.
That'd be a nice thing to add, actually. So I just add manually something to tell Quarto how wide I want it to be, which does not appear correctly here. But it does appear correctly once it's here. So that's fine. And I think that's the first slide. Cool. That's very neat.
Thank you. I mean, it was literally a day's work, I guess. I think because Simon's library was so-- it's one of those things, it's like, oh, there's no other way you could have done this. It's the obvious way. It's the correct way. But it probably took seven years to get to the point that it feels that way, which I think is a good sign.
Yeah, you're getting a lot of leverage out of the fact that his library just works in plain old data, plain old Python data structures. And then you're very familiar with some of the slightly meta stuff around Python that lets you hook into autocomplete using plain old data. There's a great documentation page in the Python docs called the Python Data Model, which lists all of the magic methods.
And it's good reading, because it's actually how Python works. I mean, there's some low-level C bit which makes that all happen. But it's like, given that machinery, here's how all the Python syntax falls out of it. All this Python syntax is a syntax sugar, like a for loop is syntax sugar for calling next on an iterator, stuff like that.
So yeah, I think it's not something everybody needs to know, but it's something that probably more people would find useful than people who actually read that page of the documentation. At least I feel like I've done that. - It's a shame to be using a dynamic language and not leveraging what that gives you.
- I know, right? I know. - Yeah. - Yeah. - Speaking of, the repro function is interesting. I remember once upon a time, I think-- maybe this isn't something people think about anymore-- but encountering the idea that the representation of an object was supposed to be also a representation that could be read later.
- Yeah. - I don't know if that-- - That is true. - It doesn't seem like that's actually observed in Python. - I'm not observing it. Right. And I think that is, strictly speaking, wrong. But it is how Jupyter chooses to display it. And my main purpose of it is to display it.
If I want something I can read back later, I would use Pickle. And Pickle has its own set of magic methods that define how an object serializes and writes itself. So I've, for quite a few years now, quietly ignored that repro rule. I don't think I've been called out before.
So here we are. - Yeah, well, the thing is, before I was a Swift nerd, I was a Lisp nerd. - Isn't there a repro markdown that Jupyter does if it's present, that supersedes it? If you do want to have full-- - Yes, absolutely. There is. And I use that quite a bit.
But then I also want it to look nice in IPython, for example, which doesn't have a markdown wrapper. So yeah. I use repromarkdown quite a bit. - So repromarkdown gives you the representation in markdown. Is that as simple as it sounds? - And so there's a-- yeah, basically, Jupyter has a system by which it decides what to display.
- Which one to use. OK. - And so I think if there's a repromime bundle, it uses that. And if there isn't, it uses repromarkdown. If that doesn't exist, it uses repromarkdown. If that doesn't exist, it uses repromarkdown. - OK. So John was suggesting that, in theory, one could use only the repromarkdown.
I think no one actually observes rep or read compatibility-- - I've never seen it matter. - Yeah. I think it's kind of-- the idea that that should exist is a holdover from another language other times. - Possibly. Anyway, a very interesting point. Well, thank you, Jono. - Well, thanks for sharing that, Jeremy.
I look forward to seeing it in use, seeing it get used maybe to teach some other people how to wrangle data sets and what gets added. - I'm going to use it next to build a web application to show you guys. So hopefully, I'll be able to show you that tomorrow.
- I'm very excited as part of my developing, like rediscovering my affection for Python. And maybe this will line up for the talk I can do on my scripting utility. - Great. Coming back from the lands of Swift. - Python just moved a lot when I wasn't paying attention.
It's much nicer now. And anyway, it's what everyone uses. So you don't want to put yourself in a ghetto. You need to use the real things. - All right, gang. Thank you. - Bye-bye. - Bye-bye.