Stanford CS25: V4 I Aligning Open Language Models
Transcript
Today we're happy to have Nathan Lambert, a research scientist at the Allen Institute for AI, who focuses on RLHF and the author of interconnects.ai. He'll be presenting a really cool talk on aligning open language models today. So thank you for joining us, Nathan. Yeah, thanks for the intro. Okay, this is a long time coming.
This is a brief intro on why I'm doing this. I think generally since ChatGPT you'll see a lot has obviously happened, but I don't think it's been a blur for me as much as anyone else. So kind of taking the time to retell what has happened in this kind of fine-tuning and alignment space since ChatGPT happened is something that I thought was a worthy undertaking.
So this is not really a one-on-one lecture, but it will probably give you a lot of context on why people are mentioning certain things and what still matters and what does not. So hopefully this is fun. I can see the chat. I don't know exactly if questions are going to come to me or if I will see it the whole time.
I think clarifying questions are good, maybe not discussions the whole time, and I'll try to keep sure that there's time for questions at the end. So let's get into it. Generally, we're going to talk about language models. It's what everyone wants to talk about these days. I need to do some of the older history so that I can talk about recent history.
The place that I like to start is actually with Claude Shannon, who kind of had this paper talking about approximating, arranging characters to create language models. That's probably why Anthropic called their models Claude. That's pretty well known. And a lot has happened since these very early papers on predicting sequences of text, and this is largely built on this loss function, which is called the autoregressive loss function.
So if you kind of have this training example where you have something like I saw A, and you're trying to predict what comes after this, the whole idea is that there's going to be one correct token that has the correct label, and their training loss is going to increase the probability of that token and decrease the probability of everything else.
This very simple loss function, classifying which token to use and actually predict, has enabled wild things. And this kind of took another turn in 2017 when this transformer paper was born. Attention was all you need. Everyone here has heard about this. It's a great exercise to actually dig into what the attention mechanism is doing, not the focus of this talk.
We'll quickly kind of keep going. In 2018, there was three main things. These are slightly out of order. ELMo was the earliest one, which was contextualized word embeddings. In the same year, we also had GPT-1 and BERT released, which is kind of the beginning of core ideas on which modern language models and transformers were trending towards.
And just getting these better models, training on large internet-scaled CORPA, BERT was a classifier, GPT-1 was generating text, and we kind of continue along these trends through the years. GPT-2 is when we started learning about scaling laws. And if you use orders of magnitude more compute, the actual test loss will continue to decrease in a linear fashion with respect to the log compute.
These ideas now are commonplace when we talk about language models. GPT-2 also pioneered a lot of discussions on releasing language models. So GPT-2, when it was first announced, they were holding access back because of the risks of language models, and this started a lot of the conversations around what you should or should not release with language models.
They eventually actually released GPT-2, and you could download the models on Hugging Face and use them, but this is where that kind of conversation around release strategies emerged. In 2020 is when language models really started to be noticeably good. So GPT-3 is when a lot of people are like, "Whoa, this can actually do really interesting things if I kind of create a really clever prompt, figure out how to give it my information correctly." And GPT-3 could do a ton of things with kind of this few-shot or multi-shot learning, which is when you give it a few examples in the prompt and then ask it to do another rendition of it.
And with this power came many harms, and this is kind of a discussion of what are the risks of releasing language models, what types of groups will be hurt by this. Very important problems that kind of culminated in 2021 with the Stochastics Parrots paper, which is arguing about whether or not language models can be too big is in the title, but it's really a critique on how we should be thinking about language models, what are the limits of them, are they actually doing the things, like are they actually thinking or doing any of these human things, or are they just kind of following patterns in the data?
And then just the year after, this is kind of like the tragedy of Stochastic Parrots, as no one talks about it now, is that ChattoobeeT came a year later and totally reshaped the whole narrative around language models one more time. And this is really where we start today's talk, is like, how does this idea of alignment emerge in ChattoobeeT, and then what happens after this?
So the question that I ask myself is like, or I tell a lot of people is, can ChattoobeeT exist without RLHF? And what we saw in the release day, so if you go back and read the actual OpenAI blog about RLHF, they list all these limitations, but they say that RLHF was an important tool to launching ChattoobeeT.
And the limitations that they list are really the things that we're still researching and that we're talking about in this talk. It's a great blog post to go back to, but a good way to frame it is that RLHF seems to be necessary, but it's not sufficient. You can't do something like ChattoobeeT or Gemini or Claude with a technique that -- without something like RLHF.
But it's not the thing -- like, pre-training is still most of the work, but the fact that RLHF is needed is really important to kind of contextualize all these improvements that we've seen in the open in the last 14 months or so. Some examples that I like to cite on RLHF being relied upon, you can list many more models here than I have.
This kind of -- this figure from Anthropics Constitutional AI paper is the single one that I go back to all the time, showing how just kind of using RLHF can get these more desirable behaviors from their model in really dramatic ways. So these kind of ELO measurements aren't kind of calibrated, so we don't know how to compare LLAMA3 on this chart compared to Anthropics models, but the level of investment that Anthropics has had in these kind of techniques and showing this kind of wide-ranging improvements of their models with RLHF is a kind of flag that we can follow to try to learn how to do alignment with this much precision and with this much kind of impact as places like Anthropic or OpenAI will have.
One such example is just a simple quote from the LLAMA2 paper, which is kind of like the colloquial way of reading this quote, which I will read, is that, "Whoa, RLHF worked really easily." And what the quote is is, "Meanwhile, reinforcement learning, known for its instability, seemed a somewhat shadowy field for those in the NLP research community.
However, reinforcement learning proved highly effective, particularly given its cost and time effectiveness." So this is one of the biggest endorsements of RLHF, and it's always fun for me because I came from the RL side and then I've been learning NLP. But for NLP researchers to say these things, like, yes, reinforcement learning is known for instability, and given that it is cost-effective and time-effective for an RL person, that's shocking.
It's like RL has never been particularly cost- and time-effective, but for in these language model domain, where we're fine-tuning with it rather than learning from scratch, to have people in NLP that are saying this is just really striking for how much impact it can have. And the timeline of alignment and open alignment is really like, when do we see these benefits?
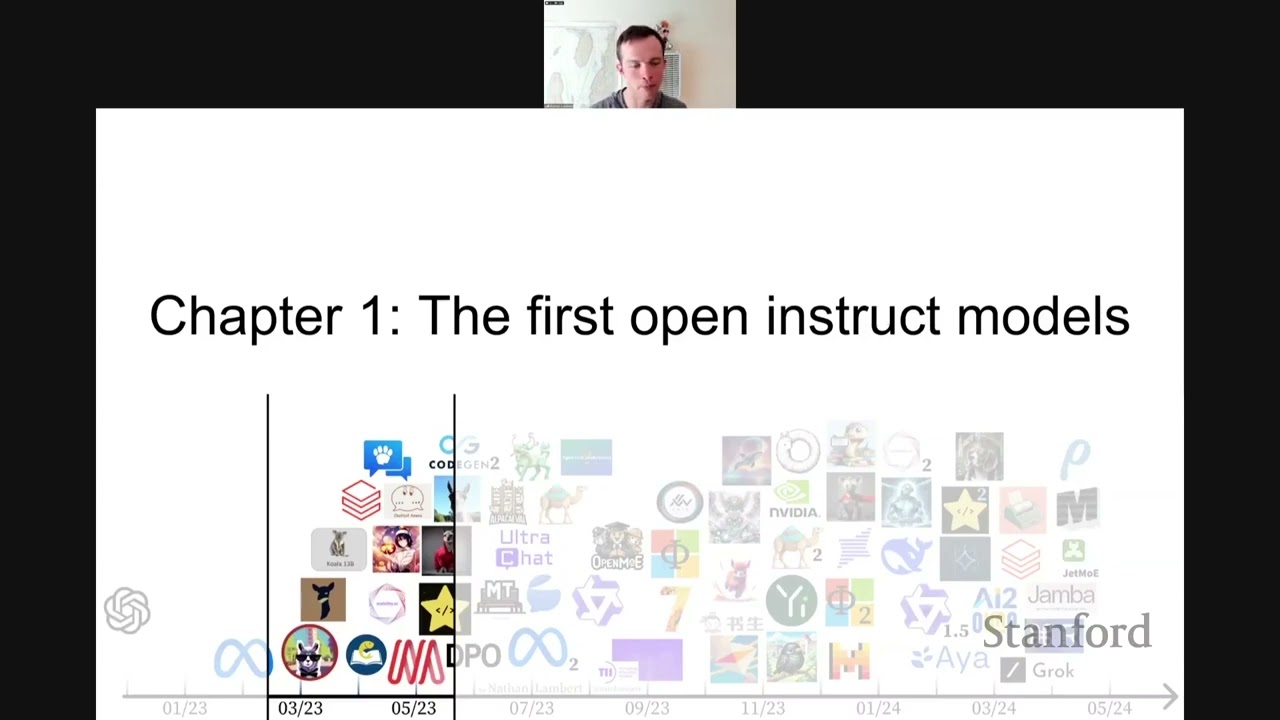
Like, these benefits didn't show up in models that people were playing with for quite a bit of time. So this is kind of a little atlas that I've thrown together. I also made a hugging face collection where I tried to add all the models that I talk about to it, so you can actually click on the models or try to use them if you're so inclined of actually running the models yourself.
It's just kind of another way of documenting the artifacts that I talk about and the artifacts that, for me, this is a good review. I'm like, what mattered? What mattered in this really noisy journey in the last year? Of course, some disclaimers. I'm not covering every model since ChatGPT.
This little plot of model icons could probably look more like an exponential than this kind of capped bar. And there's so much history of NLP that people are building on in the alignment space that is totally swept under the rug here. A lot of academic and infrastructure contributions that I'm not talking about but are really important to kind of this proliferation of fine-tuning models.
So just kind of describing what this image that I have here is. To kind of summarize, some of these are base models. I'm not going to focus on base models as much as fine-tuned models. The base models are extremely important. Like none of this happens without LLAMA. None of this happens without LLAMA2.
The base models are the bedrock of this ecosystem. And then the alignment models are what people -- the aligned models are a lot of times what people can play with and what you could try out, what you could do yourself on much less computing infrastructure and all these things.
So I'm going to talk more about the aligned models, but everything matters. It's one big ecosystem. Another thing that's not fun but I'm going to do for the sake of kind of flag-posting, no one really likes listening to definitions. Here are some things that you'll hear thrown around. This isn't even all of them when talking about "alignment." Here, alignment I've defined as a general notion of training a model to mirror a user's desires, really with any loss function.
It's not restricted. So there's a difference between instruction fine-tuning and supervised fine-tuning. Instruction fine-tuning is about trying to get a model that will respond to queries, format, and instructions, while supervised fine-tuning is more about learning a specific task's capabilities. These get interchanged all the time. Like, that's okay. It's good to know that they're different.
And then two kind of more ones I need to touch on, and we could go on even longer, is reinforcement learning from human feedback. There's this multistage process. It's a specific tool for aligning ML models to human data. It's kind of a class of tools, so it has some sort of -- you learn a preference model and then you extract information from it.
So there are so many different ways to do it. It's really an approach. And then there's a term that I'm kind of trying to grow, which is preference fine-tuning, which could encompass RLHF methods like PPO, but there's the question of how do we differentiate something like direct preference optimization, which doesn't use an RL optimizer, from all of RLHF.
And I'll kind of come back to this, but it's good to have some common rounds to build on because I might be going through some of these things pretty quickly. This is a chapter that I cover in one slide because it's really tapping into a lot of different personal stories.
It's hard to retell how crazy things were when ChatGPT dropped. People were not really losing their mind, but there was a lot of uncertainty on what the future held, especially -- it was clear that language models were important, but it is not clear -- there's a lot of articles on like -- titled "We're Going to Reproduce Open ChatGPT," which you can't really have an open model that does what a closed product does.
There's a difference between model weights and this product that ChatGPT represents. But there's so much excitement that everyone is saying they're going to do these things and trying to figure out the right coalitions for actually doing so. And it's interesting. This delay is kind of this land grab where people are learning the basic things, like what is red teaming?
What is the difference between a dialogue agent and a predictive language model? What tools should we use? And everything kind of follows from here with what people are building. But personally, I just remember multiple meetings where people were like, "Yeah, you should do it. You should go try to build open ChatGPT." And when you look back, that goal is just so wild that so many people are just going like, "We need to build this thing into open source." It doesn't even make sense because you can't open source a whole system that way.
But there are some things that make a bit -- this makes a lot more sense, which is when things start to get grounded in actual models. So the first Llama Suite was released, I think, in February. I have the date in some notes somewhere. And then these instruction-tuned models started to show up on this first Llama model.
The first one to really crack the narrative was this Alpaca model. And it did a bunch of things that still are used today. So this was trained on 52,000 self-instruct style data distilled from text DaVinci 3. There's a lot in the sentence. I'll say what self-instruct means. But this wasn't even data generated from ChatGPT.
It was generated from one of OpenAI's API models. So if we talk about -- this is all on how to apply instruction fine-tuning. And this is this thing I mentioned on the definition slide. But really, it's about making a model that will respond to specific styles of inputs. What often happens at a technical level here is that the model is learning to integrate something called, like, a chat template, the ability to include system prompts.
So you want the model to know it is an agent. You want the model to know what day it is. Excuse me, you can do this in the system prompt, which is something the user doesn't see, but it steers the behavior of the model. And instruction tuning is really where we make the model capable of having these behaviors.
But the question is, like, what data are we training this behavior on? So the most common example is kind of -- you continue training with this autoregressive loss function on question/answer pairs. So it's like, what is a transformer? And then the language model will predict an answer. It could be from stack overflow.
It could be something else. And this example is human data. But what made Alpaca and a lot of these early models, and even today, really popular and accessible, is by using data to answer questions that is generated by an AI. So this is where the kind of idea of self-instruct data comes in.
Self-instruct was a paper from Allen AI and UW in 2022, before ChatGPT, where essentially the idea is, how do we expand on the distribution and instruction data that we have, this training data for fine-tuning a language model, without getting more humans in the loop? So what you really have to do is you start with some high-quality, often human prompts.
And then what we now see as more common practice today, but was very new then, is asking a stronger language model, create a list of prompts that are similar to this, but still diverse. And then once you have a list of prompts, you can use ChatGPT or another model to actually generate completions.
Because then what you have is a really big list of question-answer pairs, but you don't need to go through the bottleneck of getting humans to sit down and write all of them. So what Alpaca was really, why Alpaca worked, is because of realizing this and taking in this better model from OpenAI.
So you can see this figure here on the right is from the Alpaca paper or blog post, one of the two. They took this model from OpenAI and they asked it to generate more tasks. So they had 175 to start, and then they ended up with over 50,000 tasks, and they also generated completions from this OpenAI model.
And then what they did is they took these meta-weights that had just come out and they instruction fine-tuned them, and then you end up with Alpaca. This is kind of a pattern. This is a pattern that we've seen many times with Alpaca, which is essentially you take, you generate some data from a stronger language model and you fine-tune on it.
It sounds so obvious today, but this was the first model to actually release this. I can now see questions coming in. I'll answer the ones that are clarifying and stuff like this, so thanks for asking them, and we can come back to more at the end. Once Alpaca happened, it felt like there was a new model every week.
The second model was Vicuna, and really what they changed was they added new sources of prompts to the distribution. So you can see that I say shared GPT. They also introduced the idea of LLM as a judge, which is now obvious from a lot of their later evaluation work.
But let's talk about why shared GPT was so interesting. So shared GPT was one of the only data sets that got open language model builders, so people like me, prompts, that were similar to what people were asking chat GPT. So what was happening was you would install this browser plug-in, and it would let you share your prompts from chat GPT on Twitter or whatever.
So it was making it easier to share the prompts in your conversations before OpenAI made a tool to do this, and now there's this legal gray area over the data set because most of these data sets are unlicensed, and they were kind of created without consent or they were released without consent.
So there's a legal question of whether or not people should be training on this data, but the fact of the matter is that shared GPT was really important to this kind of acceleration and progress on fine-tuning models because the diversity of data is just so much stronger than what people were going to get from, like, this alpaca self-instruct idea, and it set the bar much higher.
It's only today and in the last, like, few months or six months for some of them that we're getting data sets that can replace these. So you see I mentioned LLM says chat 1M, which is just a million conversations from Chatbot Arena, which took a lot of work to clean out personal information, and then a project from the Allen Institute of AI, which is WildChat, which is really similar to shared GPT, but the users were given consent at the start that their data was going to be collected and released in exchange for using a language model for free.
So there's a lot of happenstance in the story where something like this, which is legally gray, the data is still on Hugging Face, but it looks kind of odd, where these little things helped enable the ecosystem, even though looking back, it's like, "Oh, we don't know if that should have happened." Following Vicuna is one called Koala, also from Berkeley, and, like, if you look at the time frames, it's pretty obvious that a lot of these were developed concurrently, and then the release dates just happened to be slightly different.
Koala is mostly known for having kind of a different diverse set of data sets. They used some from Alpaca. They used some from shared GPT again. They also used enthropic data that has been released, and they had some human evaluation from grad students. So this just added more data diversity, and the evaluations weren't necessarily better, but it was an important model that a lot of people noticed just from these kind of bringing back up these new data sets that had been in the literature from years prior.
Something they might ask looking at these slides is that it's like, "Why weight differences?" I have all these slides like weight diff to Llama7b, weight diff. Essentially, when Llama was released, it was released as research only, and it was distributed to researchers upon request, and the license prohibited people from updating Llama1 to HuggingFace.
So it was kind of this annoying phase where, in order to use a model on HuggingFace, you had to clone it, and then you had to run a script to convert it with this kind of delta into the new model in order to actually use it. So this was kind of a really frustrating phase from a user perspective because it just made experimentation have one more barrier to entry, and thankfully, it was changed with Llama2, but it was really something that many people dealt with at the time, and we now today see different license restrictions on how Llama is used.
I mean, the Llama3 released today, essentially, if I fine-tune a model for my research and I release it at AI2, Llama3 needs to be in the name. So if I wanted to release a new Tulu model, it would have to be Llama3 Tulu4 DPO. It's like the namings are going to be crazy, but there's always been restrictions on using LlamaWeights or how you share them.
And the final model that I kind of group into this batch of this real first swing was Dolly. So Dolly was fine-tuned from a different base model. It was fine-tuned from the Pythia models from Eleuther, which are a suite of early scaling experiments from Eleuther AI, which is still used extensively.
But they added some human-written data to the loop, which is just really important because almost all the projects that I'll mention today talk about synthetic data or data derived from OpenAI, but there's only a few of them that actually added new human data to the loop, and this is what everyone remembered Dolly for.
And a lot of its performance limitations are probably from the base model Pythia, which is trained in a time where this type of inference that people expect wasn't as popular, and it was kind of before the scaling laws were thought of differently. You can kind of see through these where we're going to start with different model sizes and different MTBench scores.
I'll talk about what MTBench is in a few slides. It's an evaluation tool, and this is really just to ground you on how the scores would change over time. So I have these throughout the talk as we kind of go through different models just to show kind of how this -- how the scores continue to progress over time from one small change to another as the community gets better at these things.
While I was talking about human data, so remember, Dolly is all about human data. Probably still the single busiest human coordination project for data generation was OpenAssistant. I think it's easy now, if you get into fine-tuning, to see the OpenAssistant dataset and not realize how important it was to the process of alignment in this whole summer, and it is still used today.
So essentially, there's this quote on the top, but the leaders ran a community project to generate human-written prompts and these kind of like human-written responses in many different languages with rating them so you could use it as preferences. The slide has a bug where it's like it has over 10,000 annotated trees and over 1,000 volunteers.
This is still used extensively today. It will come up again in the talk. They also released models. So the first model used on Hugging Chat, which I don't remember the launch date of, was an OpenAssistant model. So OpenAssistant was probably the first majorly successful project of the era, and the dataset is still used today.
Where I will end this talk is saying that we need more things like this. It's like really one of the most important things is we need more human data in the open. This is a quick aside. It's kind of out of the flow of the talk, but on April 28th of 2023, typo on the slide, of April 28th of 2023, Stable Vicuno was released from Carper AI, which looks now like the style of training models, except for the dataset, which is now popular.
They got PPO to work. They had some human evaluations that were solid. It was a good chat model. It wasn't out of distribution, but Carper AI was really ahead at the time, and then it seems like priorities kind of shifted from stability. But it's important to know the extent by which there were still some players who knew how to do ROHF really early on, even though they were pretty rare.
This is the last slide of this kind of first chapter on instruction tuning, was the idea of QLORA, which was kind of unlocked a whole new bunch of players into actually being able to find two models. So for the quick 60-second overview, LORA stands for low-rank adaptation, which is the idea of you can freeze some model -- you freeze most of the model weights, and you add new weights to specific layers that you can then fine-tune, as if you were fine-tuning the whole model.
You'd use the same approach of instruction data with question-answering, but it takes much less memory. QLORA was a technique that built upon this by adding very specific quantization and GPU tricks to make it so the memory requirements to fine-tune models was even lower. Tim Detmers and team also released this Guanaco model with it, which was another big step up in performance of these models.
I have a few more slides on it, on the method. So you can kind of see on the right this difference, full fine-tuning, LORA. They look similar, where LORA, you have fewer parameters, is kind of what the smaller shapes mean. In QLORA, they quantize the base model that you're propagating gradients through to save most of the memory.
So this is an approximation of if you're fine-tuning different model sizes on the top, so 7 billion, 13 billion, 30 billion, with full fine-tuning, different amount of bits, but full fine-tuning versus LORA versus QLORA. And you can kind of see, for reference, one A100 GPU has about 80 gigabytes of memory, and these are really hard GPUs to get.
Plenty of consumer GPUs will only have like 24 to 32 gigabytes of memory. So you need to use these QLORA techniques to actually get the ability to fine-tune models at the 7 or 13 billion parameter size. And like Guanaco did this, and they released 33 billion and 65 billion parameter LAMA fine-tunes, which were clear steps up in the kind of state that they are at the time.
And they also figured out ways to filter this Open Assistant data set that I mentioned, and this kind of filtered version of Open Assistant is what is still most popular today. I'm going to kind of pause and skim through the questions and see if there's anything on that section, and if not, I'll save the relevant ones for later.
Anyway, I'm going to keep going. They're great questions, and I appreciate them, but they're mostly not specific enough where it's worth the digression. This Chapter 2 phase is really like where it seemed like things were a little bit slower on the ground, but when we look back at a lot of the things that came out of this time, like the DPO paper was in this era.
Everyone read it, but we didn't know what to do with it yet, and the new evaluations are still really used. Transitioning in, setting the scene for being not sure if things work, a lot of people were continuing to try to build on these LORA methods and QLORA methods. I remember a lot of excitement at Hugging Face where we were setting up our RLHF pipeline where we could do RLHF on 7 billion parameter models, and we could maybe do it on a consumer GPU.
It was really cool to see the loss going down. It was great to bring more people into the space, but weeks and weeks would go by, and you're like, "Why has no one picked up what we released in the blog post and trained a really good model with it?" And the kind of consensus now is that these LORA methods just have some sort of weird limitation in how you use them or how the gradients flow that make it much, much harder to get a really good model out.
If you only have a certain number of GPUs such that LORA is your only option, definitely use it, but for people that have more GPUs, figuring out how to scale is normally a better solution than just using something like LORA that fits and is easier in the short term.
Another defining moment of this era was the LLAMA2 backlash. I'm guessing some people remember this, which is like the famous line was people asked LLAMA how to kill a Python process, and it would say no, and this really started a whole bunch of new discussions around what kind of alignment means or what models should or should not do.
Here's an example from a paper for a safety evaluation test set called XS Test, and it's just like, "Should chat models be safe or should they follow the instructions that I want?" And this is a fundamental question. It'll differ by organization. It'll differ by individual. And this is the point where this became very serious and something that people actually had to reckon with because there were models that were actively disagree-- people were really disagreeing with this specific take.
I don't have any clear solution to it, but one of the things it led to is this idea of uncensored models. It's a really popular category on kind of a hugging face right now where the idea is you remove filtering. So if we're using synthetic data and I ask a language model a question, like if I ask chat GPT how to make a bomb, it's going to say, "I'm sorry.
I'm a language model. I shouldn't make this." And the idea of uncensored models is to remove those points from our kind of-- remove those points from our fine-tuning data set. I think there's a lot of confusion over the name because language models were never-- at this stage really aren't censored to begin with, but it's really that the data set and the method for creating these data sets needed more filtering or they needed some way of becoming unbiased.
So like there's a lot of people now that only build models to try to make them unbiased against any sort of refusal. A refusal is when you ask a language model something and it says no. And this goes on today, and this came out of this LLAMA2 thing. But otherwise, this is a transition period where there's a lot of good, solid models being trained, but either they didn't have a lot of documentation, they didn't have the right release team to splash as big as they should have, the methods were complicated to implement, or something like this.
So I could run through these, and I remember all these models coming out, but none of them were really things that are household names like Alpaca is today. The team from behind WizardLM, where they created this method called InvolInstruct, which is a synthetic data method. All these things were clearly working for them based on the models they were generating, but for whatever reason, the narrative wasn't actually changed.
There's some new datasets, like UltraLM is from OpenBMB in China that is releasing new datasets, more people training on shared GPT. The model called XWinLM was the first one to be a similar ballpark, and it's also trained with RLHF, so not just that Carper model. But for whatever reason, these didn't really splash.
And that was this kind of summer after LLAMA2 where fine-tuning was chugging along, but the narrative wasn't changing all that much, at least from my perspective, but that's why I'm here. But what was happening in the background, while the models weren't seeming that different, is that new evaluation tools were coming out that ended up kind of being the standard of today.
So you can see the dates here, so May 3rd, ChatBot Arena, June 8th, AlpacaEval, June 22nd, MTBench. Sometime in early July, the OpenLLM Leaderboard. All of these things were created about the same time, where there's a desperate need to get some sort of signal on what our fine-tuned models are doing in the open.
Like, we don't have the capability of paying humans to compare our responses like they do at Anthropic, where they're always trying new models on humans. That's way too expensive. We need something that you could sit down as an engineer and get feedback in 10 to 15 minutes. So I kind of run through these in order, and a lot of these are obvious, but it's important to take this from the perspective of what can I use when I'm trying to align models, and what is an immediate feedback versus what is kind of this long-term signal.
So ChatBot Arena is obviously fantastic. Like, everyone looks at this today as something that is defining corporate strategy, as defining the biggest language model players. If Cloud 3 is better than GPT-4. But if I'm an engineer, A, many small providers aren't going to get their models in, and B, it takes -- especially previously, it used to take weeks to get your models rating, but now it takes days.
Like, I need to know what my models are before I decide to actually release it. So that's the biggest thing where, like, I know I need something beyond ChatBot Arena just for my engineering development. And this is where, like, AlpacaEval and MTBench really thrive. So AlpacaEval -- God, the slide formatting got changed, but I'll just kind of keep rolling through this.
AlpacaEval is the idea of you have a list of prompts that you compare to a strong other base model, like OpenAI's DaVinci 3 or GPT-4, and then you ask a language model which is better. And the data set here is compiled from all these popular data sets that I have been talking about so far.
So data sets from OpenAssistant, Vicuna, Koala, Anthropic. Like, all these data sets that people have been using, they took the test sets from those, and that's what AlpacaEval mirrors. It's kind of a known thing. It has some limitations because there's only so many prompts, and it's like asking a language model to provide a rating is going to have some ceiling where we don't know how to compare two really good models.
So it has more samples than MTBench, so there's more -- so there's just kind of smaller error bars, and it's easier to use because it's a single-turn generation. But we've heard about the length bias for a really long time, and it's not clear how to interpret these top results.
So this is an older screenshot of Leaderboard, but what does beating a model 95% of the time mean to another language model? That's the questions that we can't really answer in the short term. AlpacaEval 2 came out, which takes steps to this, where it compares to GPT-4 rather than DaVinci 3.
DaVinci 3 was an Instruct GPT variant. But at the end of the day, if, like, GPT-4 is answering these questions in the Alpaca style really well, so what does beating GPT-4 exactly mean? And we need to get more specific in our evaluations because I don't really know if I care too much about a 20% or 30% score in AlpacaEval 2 because I don't know what it means.
And this is the opaqueness of all of our evaluations. We'll see this time and time again where we don't know what an increase in score means. That's, like, the next step after being able to do it easily. This update was pretty recent. MTBench is pretty similar, where instead of comparing to one model, you ask a language model to provide a score to a list of prompts.
So if I have a model I'm training, I generate the completion to 80 diverse prompts, and then I ask GPT-4, "Hey, from 0 to 10, how good were each of those completions?" And this is good, but it runs into the same problem of, like, what if our model is getting really good?
If our model is getting really good, it's just, like, it becomes saturated. Like, GPT-4 only gets to about 9, and there's only about 80 prompts in the evaluation set and all these things. And it's just -- And one of the nuance points is that there's actually a variance. So even if you set the temperature to 0, GPT-4 versions change.
Your own generations from your model you're trying to train can change. And this makes it better where it's like, "Okay, I can tell if a model was really bad, if MTBench and AlpacaEval have really low scores." But it's hard to, like -- It's still -- We have this goal for a precise evaluation.
So, like, in pre-training, we have MTBench and HelloSwag and all of the -- Or, sorry. In pre-training, we have, like, MMLU and HelloSwag and all these things that people can look at and average over 10 tasks. And if you get, like, a 2% improvement on average, you're doing great.
But we don't have this clear indicator in alignment evaluation. The OpenLLM leaderboard was the same, where it's -- This came out of the team I was working on at Hugging Base, where we were just trying to evaluate more models to get more signal, which was that we needed to know what our competitors were doing and get some ballpark estimate.
And what this grew into is this whole kind of, like, ecosystem-supporting discovery tool just because, like, getting any signal is so useful. So, this is where we were starting with evaluation, which was just, like, no signal. And why this leaderboard was so successful is because it gave everyone access to a little bit more signal on the models that they're evaluating, but it didn't really solve any of the fundamental problems.
And it didn't show us that, like, doing RLHF on models would actually make the scores go up. It's starting to get better today, but that's, like, a year on from the launch of this leaderboard. So, this is, like -- These problems are still -- This is talking about a section from July of 2023, and it seems like the things that if I were to go into -- like, go into work and talk to people about what we're going to do with our new models, like, these are the same questions that we're still asking, which is why it's -- These evaluation schools are still so useful, and it's why people still talk about Opaqa Eval, but it shows how much of an opportunity there still is.
So, this is kind of a summary of what I was talking about. It's, like, how easy is it to use these evaluations? Like, Chatbot Arena is everything. Like, Andrej Karpathy tweets about it, and it's great, and you can go there and you can use models, but, like, I don't know how to make sense of that as if I'm trying to sit down every day and write code.
And Opaqa Eval and MTBench mostly solve this by being cheap and pretty accessible, but I really, really think there's a huge opportunity here to come out with more. So, a colleague at AI2 launched WildBench, which is a good tool that kind of fits in. It's like a Chatbot Arena Opaqa Eval hybrid, and you can use it a little bit faster.
It's, like, how are we going to continue to push this along is a great question, and I would love to hear what people think. We'll take another pause. I think we're getting good questions in the chat around RLHF and other things. To what extent do aligned models actually reason about whether user intent is malicious rather than perform target detection to avoid unsafe topics?
This is a question that I wanted to read because it kind of gets at this model versus system topic. So, when ChatGBT was released on day one, it has an output filter that does moderation. The language model that is instruction tuned or RLHF tuned generates a bunch of text, and then a separate model says yes or no, and that's, like, where it actually does detection, and with the release of LLAMA3, there's another model that's called, like, LLAMAGuard, and this is a classifier which will take this text, do the moderation, and say which type of unsafe topic it is.
The actual model that it's generating does no reasoning over kind of what is actually an unsafe topic. So, I'll come back to other ones. I'm going to do some discussions about RLHF right now, so this will kind of give good grounds for where we can continue some of these discussions on.
There's ORPO or REINFORCE. I don't cover all of them in the lecture, but I kind of lead on to why we would talk about them. So, this chapter is when I started to get validation as an RL researcher that being opportunistic and going to work in language models was actually a good idea.
For a lot of this, there was a lot of uncertainty over if people in this kind of open ecosystem were even going to be able to use RLHF at all or if being a "RLHF researcher" for me meant I was going to do instruction fine-tuning and talk about evals and never think about RL again.
It turned out to be wrong. I'm going to review some RL fundamentals just to kind of make sure we're talking the same language as we talk about this, and this will lead into direct preference optimization. So, there's a reason why I'm doing math. I know this is not a normal lecture, but here is the equation where you'll see this in RLHF papers.
This is what we're optimizing when we're optimizing RLHF. It looks kind of nebulous here. I'll break it down. So, on the left side, we're really maximizing with respect to some policy, pi, this reward that is parameterized by a network, phi, and we have a penalty that is this kind of KL term, which is the distance from our policy to some reference.
We want to increase reward, but we want to constrain the model so that this kind of optimization doesn't go too far. And the primary questions when doing this is, how do we implement a good reward function and how do we optimize the reward? This is a really RL-centric way of doing it, which is like, if you give me a reward function, I can optimize it.
And the classic RL idea was I'm in an environment that environment has the reward function built in. In RLHF, we're designing our own reward function. So this adds a lot of weirdness to the actual optimization that we're doing. And what we do is to get this reward function, is we learn what is called a preference or reward model.
And the most popular way to do this is to take a language model that's kind of predicting this separation of two preferences. This is called a Bradley-Terry model, which goes back to some economics. But the key idea is that the reward will be proportional to the probability that the text I have would be chosen over any other arbitrary text.
Quickly sounds really theory-like, but it outputs a scalar, which is now a reward function and is based on this pairwise data. So the idea is with this equation, what if we just use gradient ascent on this equation? And instead of trying to learn a preference model and learn this R, what if we just use gradient ascent directly?
This is really what direct preference optimization is doing. There's a bunch of math in here to get what this R is, but this was released back in May. So we've already moved on months ahead. This chapter starts in kind of late September, October. Back in May, when we're still talking about Open Assistant, this DPO paper came out.
It's a fantastic paper. If you hadn't read it, it's a great way to learn about language model math. It's worth reading, but the core idea is like, why are we spending all this time learning a reward model when we can just use gradient ascent and solve for the loss function?
Some key ideas to think about with DPO is that DPO is extremely simple to implement. On the right here side is the example code from the DPO paper where it's like, as long as you have access to the log probs from a model, which is a very core thing for training language models, you can compute the DPO loss.
Because of this, because the loss function is at a nice abstraction, it scales nicely with existing libraries. And what it's actually doing is training an implicit reward function. So the reward is a function of the log probs. I don't have the equation here because it quickly becomes a rabbit hole.
But whatever the whole DPO versus PPO debate means, or ORPO, I don't remember what the paper title is. We're going to see a lot of these things because it's simple and it scales well. That doesn't necessarily mean the fundamental limits are higher, but sometimes it doesn't matter if the limits are higher if it's easier to make progress on something.
Because it feels better when progress is being made. So that's really a core thing is we'll keep seeing these models and we are. And there's this whole debate that has gone on, kind of crushing a whole bunch of these questions by redirecting them in a very political manner. But it's like, should we use reinforced?
What about PPO? What about other things? They're very different styles of optimization. So in one half, we're using RL update rules, which is ultimately about learning a value function and then learning to update, taking gradient steps with respect to that value function. In DPO, we're taking gradient steps directly from the probabilities of the language model.
They're very different optimization regimes. And there's this great meme where like all of this, like there was a month where the whole NLP Twitter was just arguing about this, but both of them are continuing to progress and that is good. It will not just be one or the other.
So what really made this debate kick into gear was this release of the Zephyr beta model from HuggingFace. It's after I left HuggingFace with the team I was on. And it was the first model to make a splash with DPO and it was a big step up in how models were perceived.
This model was added to like the use search engine. People were using all sorts of crazy things. So it just felt really good to use. It was building on this better base model. Mistral had come out. A new data set, this ultra feedback data set that I mentioned is still one of the core data sets used today when we're kind of practicing alignment.
This was back in September, October that this model came back. One of the core things to getting DPO to work was using really low learning rates like 5E minus 7. There's memes about 3E minus 4 being the only learning rate you need to do deep learning and changing it being kind of a joke.
DPO is the case where that is not even remotely true. And then you can see the MT bench scores again continuing to rise. So this is like a validation proof that DPO works that came four months after the paper was released. That delay is something that nobody expected. We were kind of losing hope on DPO at many times and now look at where it is.
And then when I joined AI2, they were already working on this project and I had just helped to kind of get it across the line. It's like the classic advisor thing where sometimes it's just easier is the first model to scale DPO to 70 billion parameters. The last question was, oh yeah, DPO works on small models.
Will anyone ever use it on a big model? The answer is yes. And it's like built on the same recipe as Zephyr with a little bit different instruction tuning data sets, but scores continued to climb. This model was so close to beating GPT 3.5 on chatbot arena. It was like a couple ELO points below.
So we didn't get the title of being the first ones to do that, but open models were starting to get that kind of chatty behavior that for so long had eluded them because we hadn't figured out scale because we hadn't figured out these data sets. So it was great progress.
Very important and kind of major transition in my career where now it's like, okay, RHF methods really can work. And these weren't just, I was not the only one touching things that did this. A couple other projects that are really important. So NVIDIA had STEER-LM where STEER-LM was collecting feedback data where there was attributes on it, like how helpful the message was, how concise the message was.
And they did a bunch of fine tuning and released good, very solid models. And they also showed that PPO was better than DPO, which is interesting. And then Berkeley came out with this Starling-LM Alpha where they had a new preference data set, Nectar, which is still looked at today.
And then they also used this kind of PPO method after training a reward model. And both of these came out about the same time, and they're like, huh, DPO isn't doing as well for us. The models are really good. Recently, the second Starling model came out. Its reward model is very strong in my testing.
It's a 7b model that's almost reaching GPT levels in chatbot arena. It's crazy how fast these models are going. But we still get a lot of models that are both with PPO or with DPO. It's really not one or the other at this point. Okay. I think this is a reasonable time for me to take a couple of these questions.
I might come back to them in more slides. But someone asked, "Is there a particular alignment method that I use?" This is teasing a paper, but there was a recent paper that came out where -- I don't remember the group. I can find it later. But they did what they called a systematic study of PPO and DPO, and they showed that PPO was better.
I will say that in the experiments that I'm seeing at Allen AI, I'm also seeing PPO to be stronger, and we hope to release this stuff soon. It's not one crushes the other. It's that we're seeing that for some reason, PPO is just getting a bit more performance. And then the logical question is, "Why not reinforce?" which is another one of these questions.
I would love to try it. It's just like we have the code that we have, and we don't want to touch things that are working well, and there's just so few people that are kind of working in this space, which I'm like, "Let's get more people working on these things," because there's so few people that can answer all these questions.
So there's another question that says like, "Some say reinforce can work as well as if not better than PPO." It probably can. It comes down to your infrastructure, carefully fine-tuning it, what people are excited about, and a lot of luck. So we'll see these continue to play out throughout the year, but it's complicated.
I'll come back to the Lama 3 question. I have one slide for that in a little bit, but really this modern ecosystem is how investment in releasing open models that people can use is continuing to grow into 2024. I think there's always been this tenuous period of like, there's only a few people releasing these aligned models.
There's these important people in the ecosystem that are just doing this because they want to, and it's for fun. They might have a day job, and it's like, how long can this go on? What are the limitations on this? But in 2024, we've really seen more companies come into the space, and someone drew Lama 3 on the screen.
It's talking to coworkers, and they're like, "Yeah, you're going to need to keep adding models. You're never going to be able to give this lecture." Yeah, it's a losing battle. I know, but there's just way more types of models. So I get away with not having Lama 3 on this specific slide because I'm talking about diversity of players and models, not just the fact that there are more great models.
So there's interesting models like this one Genstruct from New Research in the last few months where it's like a specifically fine-tuned model for rephrasing any text into instructions. So if you have a book, and you want a model to be able to answer questions about this, why don't we just throw it at this rephrasing question, this rephrasing model?
And the teams that I work on at AI2 are trying to release instruction models where every single thing that we've done to train it is documented and reproducible from data to what compute it was. There's just, these models are getting new features in these little ways other than just being the "best open model." Such as like these corporate entities that are going for really standing out and open.
So there's Databricks DBRX model, Cohere's Command R+ model. I think people are mostly blindsided by Cohere releasing model weights, but it was the first open model to pass GPT-4 on Chatbot Arena. And that has been a long time coming. I think beating GPT-4 on a human evaluation is not easy.
And yes, the open is still like a year behind, but that's fine. As long as we have a functioning ecosystem, it'll continue to grow. Then there's other things like interesting research models like Rho came out, does data weighting. We're finally starting to get multilingual models with AYA, which is also from Cohere.
People are getting more mixture of expert models to train on, which is just a bit more of an efficient pre-training equation. State space models are really taking off. They had this moment in December with Mamba, and now it's kind of continuing in 2024. So there's just a lot going on.
And this makes me feel good because it's like, okay, I just have to keep doing what I'm doing and encouraging people to participate. And we're going to keep being able to do this kind of fun thing and figuring out how to make models and share them with people. This is my slide for LLAMA3.
The reason why I didn't make a lot of slides about this all day is that LLAMA3's release is more about scaling the kind of ecosystem as a whole than it is about alignment. The LLAMA2 paper was extremely detailed about alignment. And we're going to get a LLAMA3 paper soon, if you can believe multiple sources at Meta, which I choose to.
And when the LLAMA3 paper comes out is when we will learn all the interesting alignment things that they have done. That being said, they are very unlikely to release the human preference data that they did. I'm yet to succeed in getting them to release a reward model for LLAMA2 or LLAMA3 from alignment.
So we have more work to do on getting Meta to support this kind of open alignment ecosystem to the same extent that they are supporting the pre-training ecosystem. And this kind of scaling story that I'm saying very much connects to the previous slide where scaling and solving this is very much determined by the markets and like capital incentives.
But so long as scaling is continuing to happen in the open ecosystem, it just means that more players are going to stick around. And in some ways, it kind of feeds back into itself where if this LLAMA3 is rumored to have... Or they're training a 400 billion parameter model, which we're not 100% sure that the weights will be released, but it seems like that's Mark Zuckerberg's intent.
And having that, which is about GPT-4 quality, really changes what you can do to get language models running in your products. So LLAMA3 and how many people are playing in the open space right now goes to show that we have more of the same coming, which is interesting models coming on a weekly basis.
And most people are just kind of accommodated to it now. People don't freak out when there's a new... They like Mistral's model because there's a magnet link and it's funny, but we're used to it. And I still expect that to be the case for the next year or two with this pace just kind of being how it is.
And it's really fun to follow. And I just think that it's like not a time to be worried about being scooped, but to just kind of keep figuring out where you can contribute, whether it's on evaluation or some of these other alignment methods that people have talked about. So I have a quick thing on kind of current directions, which is where I'll come back to some of these data things that I mentioned multiple times, and then we can get to questions.
The thing that people want to know a lot is are open models going to catch up to closed models? My answer is probably not ever completely. There will be some friction in the system by a time delay by which open models are closed. And open model weights are not inherently unsafe.
The open versus closed debate has mostly converged around this. But given the territory that we're going with in AI, where we're uncovering new capabilities we've never seen, I think it's okay that if there's a few months wait before you have open weights so you can run on your laptop as we're discovering what AI can do.
If you look at someone, if you look at Maxime's plot with trend lines showing them, it shows that open models are getting closer, but we're not really sure if open models will stay closer on chatbot arena in the long term. There will always be an open and closed category because there is demand to have models that are tuned to what you want them to do.
So this kind of leans into my current directions. Data is the biggest limitation to alignment, which is we have like two or three data sets that are driving all the research and open alignment. Anthropx HH dataset for my friend Deep got that uploaded back in 2022, I think. Ultrafeedback from OpenBMB and Nectar from Berkeley Next slash Nexus Flow with the Starling models are what most people are focusing on.
We need more, particularly if humans wrote it, to add more diversity to our models and more robustness. DPO is continuing in an academic sense. There is a comedy of papers extending DPO. So this is odds ratio preference optimization, which doesn't need a reference model. Constrained DPO, identity preference optimization.
I don't remember what BCO is. And then I can't pronounce the KTO authors, but like Kowarski something optimization from contextual and Stanford. DNO, SDPO, which is like sequential DPO and self-reward. There are so many, and that's good. And that trend will continue. And at the same time, we're seeing more model sizes.
Most alignment happened at the 7 or 13B scale. I think there's a large drive to make smaller models aligned. Google is releasing 1 billion parameter models, but it's also an opportunity where there aren't that many people playing in the space. But it's something that a lot of people want just because to run these models locally, making them smaller makes it way easier.
And then kind of running back to two themes throughout this lecture is what are specific evaluations? That we should be building and how do we personalize these models? They kind of go hand in hand. These are the things that I'm thinking about. I welcome feedback from them. I kind of identified some people that I'm following to see where new models come out.
So I try to release models at AI2. Hugging face quickly turns around new aligned models under the Zephyr brand. These kind of Berkeley necks and necks of slow people building data sets and straddling models. New research is a kind of -- they started as just a guy. Technium was fine-tuning models and now it's a company for fine-tuning models.
OpenBMB in China has been doing a lot of preference data sets. They've recently released some data sets called UltraInteract, which is some math preference data for doing RLHF and fine-tuning. Argilla is a startup around building tools to annotate data. It's focused on preference data. And there's even just individuals that are driving this narrative.
So Maxime and John, there's just a lot of people. Model merging is something I didn't talk about. But it's kind of like TPO, but taking it even farther, where model merging is so accessible, you don't need a GPU to merge models. It's a for loop. So people are going to try it and there's going to be iteration on it.
So in this alignment space, never bet against people where they can just try things and see what's better. Excuse me. And then eventually learn. That's what model merging is. And it's going to be here to stay. So thanks for listening. Happy to take questions. And thanks to my many teammates at Hugging Face and AI2 that make it look like I did so many of these things.
But there's a lot of great contributors that underlie this. So I'll kind of slow down and drink some water and answer some questions. But thanks for coming again. Yeah, so the top question on scores, please rate them because it's easy for me to see them, was about odds ratio, preference alignment.
I think it being agnostic to the method is the best thing, but you probably need to be good at engineering to get really good at one method to get a specific model out. And kind of getting these deliverables is important to getting recognition. I don't know if people can talk via microphone, which is a much more natural experience, but I'm just going to keep talking to myself.
There's a question around the future of alignment, given simple methods can circumvent fine-tuning. I think that the future of alignment is, like safety is not the only thing that matters. There's a lot of promise showing that alignment helps with how much people like the model. So how much RLHF improves the user experience and how much it improves code and math abilities.
So like while everyone hates Q*, like Q* has some things to guide towards, which are using synthetic data and RL search and stuff to improve the raw capabilities, rather than just talking about safety. Okay, onwards. Yeah, people are asking about the fact that Llama3 uses... Llama3 said that they use instruction fine-tuning, rejection sampling, DPO and PPO for their aligned models, which I was like, I don't know how they're using all of these things, but I think they're shifting the abilities incrementally to provide nice initialization for the next method and to keep being able to use new human data and make the metrics go up.
I think over time, that will become simpler. In the future, Meta will not have this convoluted five-stage multi-method process, and we'll figure out a way to distill that to one algorithm. Pitfalls of synthetic data is repetitiveness and not robust distribution. So most of the synthetic data sets out there are about like, they have very similar things in there, and that is like, the models are going to generalize less well and probably get less boosts from alignment training if there's not this kind of general improvement to capabilities.
So we want to take some in-person questions. Oh, yeah, that's much better. Does anyone have some in-person questions to ask Nathan? Okay, yeah. Hi, thank you so much for the talk. What do you think are the greatest hot spots of research or work in terms of personalized language models, and where do you see them having the most impact?
This is one of the things that I'm excited about, the local LLM community. Like, I'm not particularly ideologically aligned with like the effective accelerationist stuff, but I do think that they have a lot of drive to create a language model that they like to use, so that therefore there's going to be things we learn from them.
And it's kind of a classic, like how to integrate multiple communities. So it's like academics aren't used to looking there, but I'm sure there's a lot to learn there. Yeah. I guess there were multiple questions about advice for the field, whether it's like grad school or... I'll give my advice with the caged advice that is that you should be very wary of listening to people's advice because it's based on their situation.
But I think that the most important thing you can do when the field is crazy is just keep trying to develop skills and keep trying to build something that you think matters. 'Cause it's like, at the end of the day, that's what you're making progress on, and you'll never be able to keep track of everything, and that's okay, and I can't keep track of everything, and I'm still trying to train models and build data sets.
So it's just like grad school is about learning to do research, and that still has value, but industry is also fun if you want to do a startup. So there's not like... You just have to think about what you want to do. - I think someone sent me... You can hear me, right?
- Yeah. - Someone sent me a question through Zoom. A quick question. You indicated that making lower methods work with reinforcement learning is tricky. Do you think lower methods work well with DPO or its variants? - I haven't seen it be particularly successful, so that's my general rule of thumb is I really wait to go deep into a method until there's been a model release that's in the relevant ballpark with that method.
So the fact that it's been around for so long and hasn't happened could be a blind spot, but I think that there's some weirdness that's preventing it from happening. - Great. Okay, another one. Thank you for the talk. You mentioned GPT-4 being used as an evaluation method, but it causes data contamination.
What are some ways to mitigate this? - Oh, man. Yeah. I mean, this is why it's nice to have human evaluation, but I don't know if I have an answer. At this point, I'm kind of fried from reading LLAMA-3 stuff and giving this lecture, but that's the fundamental problem is how to disambiguate various biases in evaluation and still get the signal out of them.
- Right. Okay. One more. Give me a second. For stuff like LLAMA-3 training on so many tokens, like 15 trillion, would that actually make it harder to align this model without losing some capabilities? Learn from this over-training. - It's not technically over-trained, but every model will have kind of a different point by which they're released, so that's why you'll need a different learning rate in batch size and data sets for models, so you will need a different kind of way of continuing it, but that is a common confusion on how -- I mean, I don't even have an intuition for it, just to know that I have bought this thing in the past and been proven wrong about it, but it's not that it's over-trained or harder to fine-tune.
It's just that there's more information into the model, and as you continue to do this, the model can keep learning. It just takes more and more data to get marginal improvements, so Meadow is willing to invest more money into the model to make it just a bit better, but that should only help.
That shouldn't hurt. - Right, great. Here's another one. Do you think synthetic data generation, like Cosmopedia, is the way to go for making controlled or trusted domain-specific models? - I think it'll be very good. I also think it's a good way to get around the fact that Google is paying Reddit $60 million a year to use their data so that we can no longer train on the newest Reddit data.
I think that Cosmopedia and synthetic data sets at a large scale can be a way around this, and there are rumors that industry is doing something similar. - Give me a second. I think there's one that I missed. Could you please share some insights on why you are finding PPO better than DPO?
- It's mostly like it ends up extracting more from the data, so it's like the benchmarks end up being a little bit better if we get it set up correctly with the same starting point. It's like you choose a set of evaluations that you care about and you look at them, and through fine-tuning, it's primarily a group of great grad students doing this.
It's just running a ton of models and trainings, and they're seeing that PPO reliably can be doing a little bit better, and it's like this is the fine margins that a lot of AI works on nowadays. - Great. Do you foresee a better evaluation method to be determined by a stronger or more specialized model, which means rule-based metrics are dead forever?
- Maybe. I try not to say no to things. This is becoming philosophical, which is like I'm trying not to say no to things in the language model space with how fast things are progressing. It's like I should try not to bet against progress continuing. This goes for pre-training and alignment, and it's like at multiple stages in the last few months come to benefit me.
So it's like if you just assume that things will get better and they will work, it's like just makes it a little bit easier to wrap your head around things. - One last one here from -- give me a sec. At its core, an LLM is trying to approximate a complex distribution.
Would you say that alignment is the process of squashing specific parts of this distribution according to what humans prefer? - Yeah, I think that's phrased generally enough that I could get behind it. It is. Alignment is about changing the distribution, and it can be multiple tokens. It's like a multi-turn prediction.
RL is not just autoregressive. It can be these kind of multi-string different things that are getting shifted around, and it's a really different loss function. - Here's one from -- how do you envision the usage of watermarks for both open and closed language marks? - I think it a lot of times feels like a losing battle.
I think that a practical solution in the future is that if you want to prove something that is human-made, you can prove that it was generated by a human by having a certain tool rather than trying to understand if a specific content was made by an AI. So the assumption will be that all content was made by an AI unless proven to be human.
It's not what I would consider a sociologically good answer. It just seems like a practical one. - Makes sense. I think we have a few more minutes, so if anybody has any last-minute questions, feel free to send them over to me on the Zoom chat. - Yeah, that was much better than me half-reading the question.
- All right, here's one. What are your thoughts on different optimization functions to train large-language models rather than using MLE? What could be good research directions there? - I think this is the whole idea of what RLHF represents. And that's why, like, if you ask people who have been in NLP longer, one of the most compelling arguments for RLHF for me is, like, you now have extreme flexibility on the loss function while we were kind of limited on what our regressive losses could do.
So there's kind of arguments that it's, like, why is there any limit if we could just keep doing more and more tokens of RL training? It's a really, like, general framing, but, like, RL's loss function, you make it so that the training of a language model can incorporate many different things, and that's very exciting.
That could be, like, the 10-year goal of RLHF. - To what extent is training on adversarial data effective for defending against crescendo and other simple multi-turn attacks? - I haven't spent as much time on safety as I would want to, but I think that it's, like, it'll be this everlasting dance where if you have example data, you can defend against it, but it will not be impossible to generate new data.
So it mostly comes down to the use case that you're looking at protecting. So if you want to protect something really important, you need to have layers on that that are not just sensitive to a new prompting technique, but, like, limit what the model can do. That's kind of--it's, like, a use-focused theme, while the kind of whole, like, security is a very complicated thing otherwise.
- Here's one on quantization. Do you see potential in quantization methods such as BitNet, like 1.58 bit? If so, do you think BitNet will become popular? - I have no idea. I wouldn't--this is what I mean. It's like, okay, sounds cool. Wouldn't rule it out. - You think there's a need or a way to control large-scale data extraction from large language models like Cosmopedia?
- I do think there's a lot of wills and a lot of ways to explore making the synthetic data better. I think it's very early. I have a project that's going on it, and it is one of the few ways that can generate more tokens, which is, like-- like, people are actually running out of tokens, especially if you try not to train on things that you're not supposed to train on.
It's, like, then you can just generate more data, and as we've seen with LLAMA, if you have the compute, more data will help you. - Let's see. Self-play-like things. Any chance you can kind of expand upon or share your opinions on self-play-like things like OpenAI super alignment work? - I think people will keep using language models in the loop of training other language models, but it's a kind of broad field that doesn't have full agreement on how to do it.
- Okay, great. And I think we're pretty much out of time, so if folks want to get in touch or have more questions, can they email you? - Yeah. - Okay, great. But, yeah, thanks so much again for taking the time and giving us such a great talk. So, yeah, give it up for Nathan.
- Thanks, everyone. - And I think the slides, as well as the Hugging Face collection, are all posted on our website as well as Discord, so in case anybody wants to follow along. - Sounds good. Thanks a lot for having me. - Yeah, no worries. Thanks, everyone. - See everyone soon.
- Bye-bye. - Bye-bye.