Lesson 16: Deep Learning Foundations to Stable Diffusion
Chapters
0:0 The Learner2:22 Basic Callback Learner
7:57 Exceptions
8:55 Train with Callbacks
12:15 Metrics class: accuracy and loss
14:54 Device Callback
17:28 Metrics Callback
24:41 Flexible Learner: @contextmanager
31:3 Flexible Learner: Train Callback
32:34 Flexible Learner: Progress Callback (fastprogress)
37:31 TrainingLearner subclass, adding momentum
43:37 Learning Rate Finder Callback
49:12 Learning Rate scheduler
53:56 Notebook 10
54:58 set_seed function
55:36 Fashion-MNIST Baseline
57:37 1 - Look inside the Model
62:50 PyThorch hooks
68:52 Hooks class / context managers
72:17 Dummy context manager, Dummy list
74:45 Colorful Dimension: histogram
Transcript
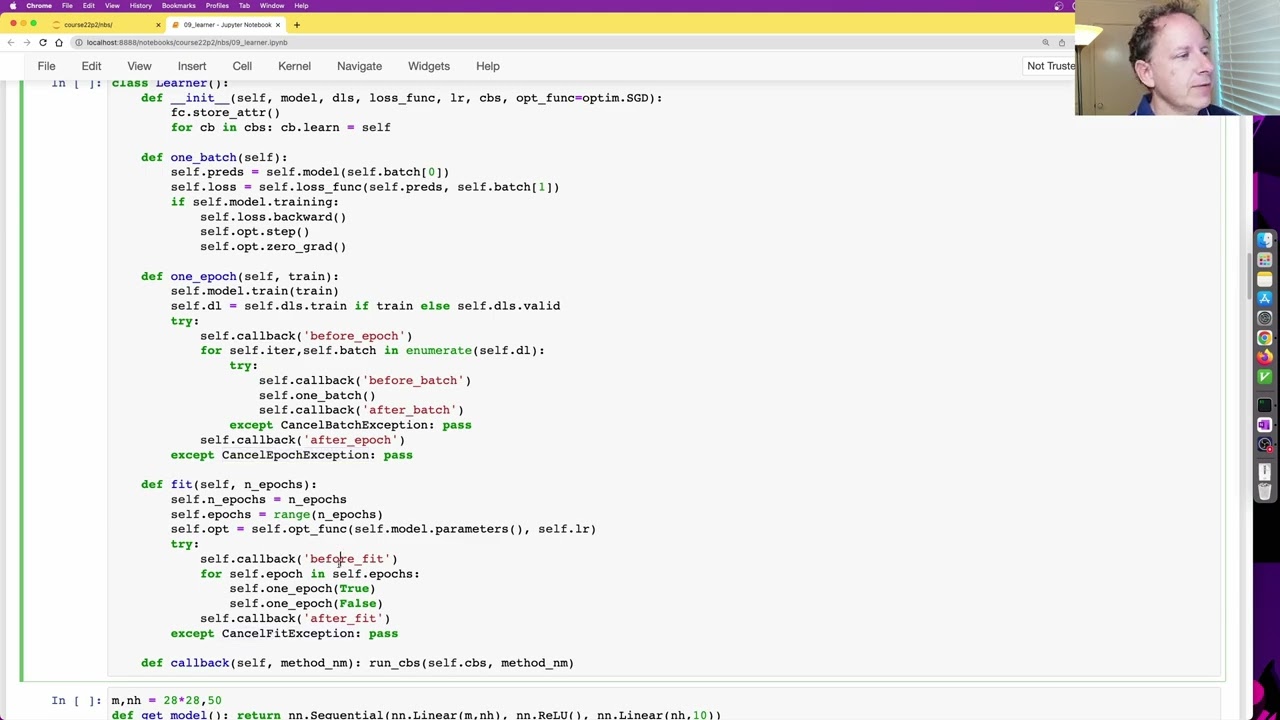
Hi there and welcome to lesson 16 where we are working on building our first flexible training framework the learner and I've got some very good news which is that I have thought of a way of doing it a little bit more gradually and simply actually than last time so that should that should make things a bit easier so we're going to take it a bit more step by step so we're working in the 09 learner notebook today and we've seen already this this basic callbacks learner and so the idea is that we've seen so far this learner which wasn't flexible at all but it had all the basic pieces which is we've got a fit method we hard coding that we can only calculate accuracy and average loss we're hard coding we're putting things on a default device hard coding a single learning rate but the basic idea is here we go through each epoch and call one epoch to train or evaluate depending on this flag and then we loop through each batch in the data loader and one batch is going to grab the X and Y parts of the batch call the model call the loss function and if we're training do the backward pass and then print out we'll calculate the statistics for our accuracy and then at the end of an epoch print that out so it wasn't very flexible but it did do something so that's good so what we're going to do now is we're going to do is an intermediate step we're going to look at a but I'm calling a basic callbacks learner and it actually has nearly all the functionality of the full thing the way we're going to after we look at this basic callbacks learner we're then going to after creating some callbacks and metrics we're going to look at something called the flexible learner so let's go step by step so the basic callbacks learner looks very similar to the previous learner it it's got a fit function which is going to go through each epoch calling one epoch with training on and then training off and then one epoch will go through each batch and call one batch and one batch will call the model the loss function and if we're training it will do the backward step so that's all pretty similar but there's a few more things going on here for example if we have a look at fit you'll see that after creating the optimizer so we call self dot optfunk so optfunk here defaults to SGD so we instantiate an SGD object passing in our models parameters and the requested learning rate and then before we start looping through one epoch at a time now we've set epochs here we first of all call self dot callback and passing in before fit now what does that do self dot callback is here and it takes a method names in this case it's before fit and it calls a function called run callbacks it passes in a list of our callbacks and the method name in this case before fit so run callbacks is something that's going to go for each callback and it's going to sort them in order of their order attribute and so there's a base class through our callbacks which has an order of zero so our callbacks all going to have the same order of zero and which you will ask otherwise so here's an example of a callback so before we look at how callbacks work let's just let's just run a callback so we can create a ridiculously simple callback called completion callback which before we start fitting a new model it will set its count attribute to zero after each batch it will increment that and after completing the fitting process it will print out how many batches we've done so before we even train a model we could just run manually before fit after batch and after fit using this run cbs and you can see it's ended up saying completed one batches so what did that do so it went through each of the cbs in this list there's only one so it's going to look at the one cb and it's going to try to use get atra to find an attribute with this name which is before fit so if we try that manually so this is the kind of thing I want you to do if you find anything difficult to understand is do it all manually so create a callback set it to cbs zero just like you're doing in a loop right and then find out what happens if we call this and pass in this and you'll see it's returned a method and then what happens to that method it gets called so let's try calling it there yeah so that's what happened when we call the before fit which doesn't do anything very interesting but if we then call after batch and then we call after fit there it is right so yeah make sure you don't just run code really nearly but understand it by experimenting with it and I don't always experiment with it myself in these classes often I'm leaving that to you but sometimes I'm trying to give you a sense of how I would experiment with code if I was learning it so then having done that I would then go ahead and delete those cells but you can see I'm using this interactive notebook environment to to explore and learn and understand and so now we've got and if I haven't created a simple example of something to make it really easy to understand you should do that right don't just use what I've already created or what somebody else has already created so we've now got something that works totally independently we can see how it works this is what a callback does so a callback is something which will look at a class a callback is a class where you can define one or more of before after fit before after batch and before after epoch so it's going to go through and run all the callbacks that have a before fit method before we start fitting then it'll go through each epoch and call one epoch with training and one epoch with evaluation and then when that's all done it will call after fit callbacks and one epoch will before it starts on enumerating through the batches it will call before epoch and when it's done it will call after epoch the other thing you'll notice is that there's a try except immediately before every before method and immediately after every after method there's a try and there's an accept and each one has a different thing to look for cancel fit exception cancel epoch exception and cancel batch exception so here's the bit which goes through each batch calls before batch processes the batch calls after batch and if there's an exception that's of type cancel batch exception it gets ignored so what's that for so the reason we have this is that any of our callbacks could call could raise any one of these three exceptions to say I don't want to do this batch please so maybe you'll look an example of that in a moment so we can now train with this so let's call create a little get model function that creates a sequential model with just some linear layers and then we'll call fit and it's not telling us anything interesting because the only callback we added was the completion callback that's fine it's it's training it's doing something and we now have a trained model just didn't print out any metrics or anything because we don't have any callbacks for that that's the basic idea so we could create a maybe we could call it a single batch callback which after batch after a single batch it raises a cancel cancel fit exception so that's a pretty I mean that could be kind of useful actually if you want to just run one battery a model to make sure it works so we could try that so now we're going to add to our list of callbacks the single batch callback let's try it and in fact you know we probably want this let's just have a think here oh that's fine let's run it there we go so it ran and nothing happened and the reason nothing happened is because this canceled before this ran so we could make this run second by setting its order to be higher and we could say just order equals 1 because the default order is 0 and we sort in order of the order attribute actually let's use cancel epoch exception there we go that way it'll run the final fit there we are so it did one batch for the it did one batch for the training and one batch for the evaluation so it's a total of two batches so remember callbacks are not a special magic part of like the Python language or anything it's just a name we used refer to these functions or classes or callables more accurately that we that we pass into something that will then call back to that callable at particular times and I think these are kind of interesting kinds of callbacks because these callbacks have multiple methods in them so is each method a callback is each class with all those methods of callback I don't know I tend to think of the class with all the methods in as a single callback I'm not sure if we have great nomenclature for this all right so let's actually try to get this doing something more interesting by not modifying the learner at all but just by adding callbacks because that's the great hope of callbacks right so it would be very nice if it told us the accuracy and the loss so to do that it would be great to have a class that can keep track of a metric so I've created here a metric class and maybe before we look at it we'll see how it works you could create for example an accuracy metric by defining the calculation necessary to calculate the accuracy metric which is the mean of how often do the input sequence targets and the idea is you could then create an accuracy metric object you could add a batch of inputs and targets and add another batch of inputs and targets and get the value and there you would get the point four five accuracy or another way you could do it would be just to create a metric which simply takes gets the weighted average for example of your loss so you could add point six as the loss with a batch size of 32 point nine as a loss in a batch size of two and then that's going to give us a weighted average loss of point six two which is equal to this weighted average calculation so that's like one way we could kind of make it easy to calculate metrics so here's the class basically we're going to keep track of all of the actual values that we're averaging and the number in each mini batch and so when you add a mini batch we call calculate which for example for accuracy remember this is going to override the parent classes calculate so it does the calculation here and then we'll add that to our list of values we will add to our list of batch sizes the current batch size and then when you calculate the value we will calculate the weighted sum sorry the weighted mean weighted average now notice that here value I didn't have to put parentheses after it and that's because it's a property I think we've seen this before so just remind you property just means you don't have to put parentheses after it to get it's to get the calculation to happen all right so just let me know if anybody's got any questions up to here of course so we now need some way to use this metric in a callback to actually print out the first thing I'm going to do those are going to create one more one useful metric first a very simple one just two lines of code called the device callback and that is something which is going to allow us to use CUDA or for the Apple GPU or whatever without the complications we had before of you know how do we have multiple processes and our data loader and also use our device and not have everything fall over so the way we could do it is we could say before fit put the model onto the default device and before each batch is run put that batch onto the device because look what happened in in the this is really really important in the learner absolutely everything is put inside self dot which means it's all modifiable so we go for self dot iteration number comma self dot the batch itself enumerating the data loader and then we call one batch but before it we call the callback so we can modify this now how does the callback get access to the learner well what actually happens is we go through each of our call backs and put set an attribute called learn equal to the learner and so that means in the callback itself we can say self dot learn dot model and actually we could make this a bit better I think so make it like maybe you don't want to use a default device so this is where I would be inclined to add a constructor and set device and we could default it to the default device of course and then we could use that instead and that would give us a bit more flexibility so if you wanted to trade on some different device then you could I think that might be a slight improvement okay so there's a callback we can use to put things included and we could check that it works by just quickly going back to our old learner here remove the single batch CB and replace it with device CB yep still works so that's a good sign okay so now let's do our metrics now of course we couldn't use metrics until we built them by hand the good news is we don't have to write every single metric now by hand because they already exist in a fairly new project called torch eval which is an official PyTorch project and so torch eval is something that gives us actually I came across it after I had created my own metric class but it actually looks pretty similar to the one that I built earlier so you can install it with PEP I'm not sure if it's on Conde yet but it probably will be soon by the time you see the video I think it's pure of Python anyway so it doesn't matter how you install it and yeah it has a pretty similar pretty similar approach where you call dot update and you call dot compute so they're slightly different names but they're basically super similar to the thing that we just built but there's a nice good list of metrics to pick from so because we've already built our own now that means we're allowed to use theirs so we can import the multi-class accuracy metric and the main metric and just to show you they look very very similar if we call multi-class accuracy and we can pass in a mini batch of inputs and targets and compute and that all works nicely now these in fact it's exactly the same as what I wrote we both added this thing called reset which basically well resets it and it's obviously we're going to be wanting to do that probably at the start of each epoch and so if you reset it and then try to compute you'll get NAN because you can't get accuracy accuracies meaningless when you don't have any data yet okay so let's create a metrics callback so we can print out our metrics I've got some ideas to improve this which maybe I do this week but here's a basic working version slightly hacky but it's not too bad so generally speaking one thing I noticed actually is I don't know if this is considered a bug but a lot of the metrics didn't seem to work correctly and torch eval when I had tensors that were on the GPU and had requires grad so I created a little to CPU function which I think is very useful and that's just going to detach the so detach takes the tensor and removes all the gradient history the computation history used to calculate a gradient and puts it on the CPU that'll do the same for dictionaries of tensors lists of tensors and tuples of tensors so our metrics callback basically here's how we're going to use it so let's run it so here we're creating a metrics callback object and saying we want to create a metric called accuracy that's what's going to print out and this is the metrics object we're going to use to calculate accuracy and so then we just pass that in as one of our callbacks and so you can see what it's going to do is it's going to print out the epoch number whether it's training or evaluating so training set or validation set and it'll print out our metrics and our current status actually we can simplify that we don't need to print those bits because it's all in the dictionary now let's do that there we go um so let's take a look at how this works so we are going to be creating with for the callback we're going to be passing in the names and object metric objects for the metrics to track and print so here it is here star star metrics so he's seen star star before and as a little shortcut I decided that it might be nice if you didn't want to write accuracy equals you could just remove that and run it and if you do that then it will give it a name and I'll just use the same name as the class and so that's why you can either pass in so star ms will be a tuple well I mean it's got to be pulled out so it's just passing a list of positional arguments which we turn into a tuple or you can pass in named arguments that'll be turned into a dictionary if you pass in positional arguments then I'm going to turn them into named arguments in the dictionary by just grabbing the name from their type so that's where this comes from that's all that's going on here just a little shortcut bit of convenience so we store that away and this is yeah this is a bit I think I can simplify a little bit but I'm just adding manually an additional metric which is I'm going to call the loss and that's just going to be the weighted the weighted average of the losses so before we start fitting we we're going to actually tell the learner that we are the metrics callback and so you'll see later where we're going to actually use this before each epoch we will reset all of our metrics after each epoch we will create a dictionary of the keys and values which are the actual strings that we want to print out and we will call log which for now we'll just print them and then after each batch this is the key thing we're going to actually grab the input and target we're going to put them on the CPU and then we're going to go through each of our metrics and call that update so remember the update in the metric is the thing that actually says here's a batch of data right so we're passing in the batch of data which is the predictions and the targets and then we'll do the same thing for our special loss metric passing in the actual loss and the size of any batch and so that's how we're able to get this yeah this actual running on the Nvidia GPU and showing our metrics and obviously there's a lot of room to improve how this is displayed but all the informations we needed here and it's just a case of changing that function okay so that's our kind of like intermediate complexity learner we can make it more sophisticated but it's still exactly it's still going to fit in a single screen of codes this is kind of my goal here was to keep everything in a single screen of code this first bit is exactly the same as before but you'll see that the one epoch and fit and batch has gone from let's see but what it was before it's gone from quite a lot of code all this to much less code and the trick to doing that is I decided to use a context manager we're going to learn more about context managers in the next notebook but basically I originally last week I was saying I was going to do this as a decorator but I realized a context manager is better basically what we're going to do is we're going to call our before and after callbacks in a try accept block and to say that we want to use the callbacks in the try accept block we're going to use a with statement so in Python a with statement says everything in that block call our context manager before and after it now there's a few ways to do that but one really easy one is using this context manager decorator and everything up and to the up to the yield statement is called before your code where it says yield it then calls your code and then everything after the yield is called after your code so in this case it's going to be try self dot callback before name where name is fit and then it will call for self dot epoch etc because that's where the yield is and then it'll call self dot callback after fit accept okay and now we need to grab the cancel fit exception so all of the variables that you have in Python all live inside a special dictionary called globals so this dictionary contains all of your variables so I can just look up in that dictionary the variable called cancel fit with a capital F exception so this is except cancel fit exception so this is exactly the same then as this code except the nice thing is now I only have to write it once rather than at least three times and I'm probably going to want more of them so you know I tend to think it's worth yeah I tend to think it's worth refactoring a code when you have duplicate code particularly here we had the same code three times so that's going to be more of a maintenance headache we're probably going to want to add callbacks to more things later so by putting it into a context manager just once I think we're going to reduce our maintenance burden I know we do because I've had a similar thing in fast AI for some years now and it's been quite convenient so that's what this context managers about yeah other than that the code's exactly the same so we create our optimizer and then with our callback context manager for fit go through each epoch call one epoch set it to training or non training mode based on the argument we pass in grab the training or validation set based on the argument we trust in and then using the context manager for epoch go through each batch in the data loader and then for each batch in the data loader using the batch context now this is where something gets quite interesting we call predict get lost and if we're training backward step and zero grad but previously we actually called self dot model etc self dot loss function etc so we go through each batch and call before batch do the batch oh they say that's our that's our slow version wait what are we doing oh yes we're gonna be over here okay I'm back where we are yes so previously we were calling yeah calling calling the model calling the loss function calling loss dot backward opt dot step opt dot zero grad but now we are calling instead self dot predict self dot get lost self dot backward and how on earth is that working because they are not defined here at all and so the reason I've decided to do this is it gives us a lot of flexibility we can now actually create our own way of doing predict get lost backward step and zero grad in different situations and we're going to see some of those situations so what happens if we call self dot predict and it doesn't exist well it doesn't necessarily cause an error what actually happens is it calls a special magic method in Python called dunder get atra as we've seen before and what I'm doing here is I'm saying okay well if it's one of these special five things don't raise an attribute error which is this is the default thing it does but instead create a call back or actually I should say call self dot call back passing in that name so it's actually going to call self dot call back quote predict and self dot call back is exactly the same as before and so what that means now is to make this work exactly the same as it did before I need a call back which does these five things and here it is I'm going to call it train call back so here are the five things predict get lost backwards step and zero grad so there are here predict get lost backwards step and zero grad okay so they're almost exactly the same as what they looked like in our intermediate learner except now I just need to have self dot learn in front of everything because we remember this is a callback it's not the learner and so for a callback the callback can access the learner using self dot learn so self dot learn dot preds is self dot learn dot model passing in self dot learn dot batch and just the independent variables ditto for the loss calls the loss function backward step zero grad so that's at this point this isn't doing anything that wasn't doing before but the nice thing is now if you want to use hugging face accelerate or you want something that works on hugging face data styles dictionary things or whatever you can actually change exactly how it behaves by just call passing by creating a callback for training and if you want everything except one thing to be the same you can inherit from train CB so this is I've I've not tried this before I haven't seen this done anywhere else so it's a bit of an experiment so I would sit here how you go with it and then finally I thought it'd be nice to have a progress bar so let's create a progress callback and the progress bar is going to show on it our current loss and going to put create a plot of it so I'm going to use a project that we created called fast progress mainly created by the wonderful Sylvain and basically fast progress is yeah very nice way to create a very flexible progress bars and so let me show you what it looks like first so let's get the model and train and as you can see it actually in real time updates the graph and everything there you go that's pretty cool so that's the that's the progress bar the metrics callback the device callback and the training callback all in action so before we fit we actually have to set self dot learn dot epochs now that might look a little bit weird but self dot learn dot epochs is the thing that we loop through for self dot epoch in so we can change that so it's not just a normal range but instead it is a progress bar around a range we can then check remember I told you that the learner is going to have the metrics attribute applied we can then say oh if the learner has a metrics attribute then let's replace the underscore log method there with ours and our one instead will write to the progress bar now this is pretty simple it looks very similar to before but we could easily replace this for example with something that creates an HTML table which is another thing fast progress does or other stuff like that so you can see we can modify the nice thing is we can modify how our metrics are displayed so that's a very powerful thing that Python lets us do is actually replace one piece of code with another and that's the whole purpose of why the metrics callback had this underscore log separately so why didn't I just say print here that's because this way classes can replace how the metrics are displayed so we could change that to like send them over to weights and biases for example or you know create visualizations or so forth so before epoch we do a very similar thing the self dot learn dot DL iterator we change it to have a progress bar wrapped around it and then after each bar we set the progress bars comment to be the to be the loss it's going to print just going to show the loss on the progress bar as it goes and if we've asked for a plot then we will append the losses to a list of losses and we will update the graph with the losses and the batch numbers so there we have it we have a yeah nice working learner which is I think the most flexible learner that training loop probably that's I hope has ever been written because I think the fast AI 2 one was the most flexible that had ever been written before and this is more flexible and the nice thing is you can make this your own you know you can you know fully understand this training loop so it's kind of like you can use a framework but it's a framework in which you're totally in control of it and you can make it work exactly how you want to ideally not by changing the change in the learner itself ideally by creating callbacks but if you want to you could certainly like look at that the whole learner fits on a single screen so you could certainly change that we haven't added inference yet although that shouldn't be too much to add I guess we have to do that at some point okay now interestingly I love this about Python it's so flexible when when we said self dot predict self dot get lost I said if they don't exist then it's going to use get atcha and it's going to try to find those in the callbacks and in fact you could have multiple callbacks that define these things and then they would chain them together which would be kind of interesting but there's another way we could make these exist which is which is that we could subclass this so let's not use train CB just to just to show us how this would work and instead we're going to use a subclass so here in a subclass learner and I'm going to override the five well it's not exactly overriding I didn't have any definition of them before so I'm going to define the five directly in the learner subclass so that way it's never going to end up going to get atcha because get atcha is only called if something doesn't exist so here it's basically all these five are exactly the same as in our train callback except we don't need self dot learn anymore we can just use self because we're now in the learner but I've changed zero grad to do something a bit crazy I'm not sure if this has been done before I haven't seen it but maybe it's an old trick that I just haven't come across but it occurred to me zero grad which remember is the thing that we call after we take the optimizer step doesn't actually have to zero the gradients at all what if instead of zeroing the gradients we multiplied them by some number like say 0.85 well what would that do well what it would do is it would mean that your previous gradients would still be there but they would be reduced a bit and remember what happens in PyTorch is PyTorch always adds the gradients to the existing gradients and that's why we normally have to call zero grad but if instead we multiply the gradients by some number I mean we should really make this a parameter let's do that shall we so let's create a parameter so probably the few ways we could do this well let's do it properly we've got a little bit of time so we could say well maybe just copy and paste all those over here and we'll add momentum momentum equals 0.85 self momentum equals momentum and then super so make sure you call the super classes passing in all the stuff we could use delegates for this and quags that would be possibly another great way of doing it but let's just do this for now okay and then so there we wouldn't make it 0.85 we would make it self dot momentum so you'll see now still trains but there's no train CB callback anymore in my list I don't need one because I have to find the five methods in the subclass now this training at the same learning rate for the same time the accuracy it improves by more let's run them all yeah this is a lot like gradient accumulation callback they're kind of cooler I think okay so the let's see the loss has gone from 0.8 to 0.55 and the accuracy is gone from about 0.7 to about 0.8 so they've improved why is that well we're going to be learning a lot more about this pretty shortly but basically what's happening here but basically what's happening here is we have just implemented in a very interesting way which I haven't seen done before something called momentum and basically what momentum does is it say like imagine you are you know you're trying you've got some kind of complex contour lost surface right and you know so imagine these are hills with a marble very similar right and your marbles up here what would normally happen with gradient descent is it would go you know in the direction downhill which is this way so we'll go whoa over here and then whoa over here right very slow what momentum does is it's is the first steps the same and then the second step says oh I wanted to go this way but I'm going to add together the previous direction plus the new direction but reduce the previous direction a bit so that would actually make me end up about here and then the second one does the same thing and so momentum basically makes you much more quickly go to your destination so normally momentum is done it the reason I did it this way partly to show you is just a bit of fun a bit of interest but it's very it's very useful because normally momentum you have to store a complete copy basically of all the gradients the momentum version of the gradients so that you can kind of keep track of that that that running exponentially weighted moving average but using this trick you're actually using the dot grad themselves to store the exponentially weighted moving average so anyway there's a little bit of fun which hopefully particularly those of you who are interested in accelerated optimizers and memory saving might find a bit inspiring all right there's one more call back I'm going to show before the break which is the wonderful learning ratefinder I'm assuming that anybody who's watching this already is familiar with the learning ratefinder from fast AI if you're not there's lots of videos and tutorials around about it it's an idea that comes from a paper by Leslie Smith from a few years ago and the basic idea is that we will increase the learning rate I should have put titles on this the the x-axis here is learning rate the y-axis here is loss we increase the learning rate gradually over time and we plot the loss against the learning rate and we find how high can we bring the learning rate up before the loss starts getting worse you kind of want roughly where about the steepest slope is so probably here it would be about 0.1 so it'd be nice to create a learning ratefinder so here's a learning ratefinder callback so what a learning ratefinder needs to do well you have to tell it how much to multiply the learning rate by each batch let's say we add 30% to the learning rate each batch and so we'll store that so before we fit we obviously need to keep track of the learning rates and we need to keep track of the losses because those are the things that we put on a plot the other thing we have to do is decide when do we stop training so when is it clearly gone off the rails and I decided that if the loss is three times higher than the minimum loss we've seen then we should stop so we're going to keep track of their minimum loss and so let's just initially set that to infinity it's a nice big number well not quite a number but a number ish like thing so then after every batch first of all let's check that we're training okay if we're not training then we don't want to do anything we don't use the learning rate finder during validation so here's a really handy thing just raise cancel epoch exception and that stops it from doing that epoch entirely so just to see how that works you can see here one epoch does with the call back context manager epoch and that will say oh it's got cancelled so it goes straight to the accept which is going to go all the way to the end of that code and it's going to skip it so it's you can see that we're using exceptions as control structures which is actually a really powerful programming technique that is really underutilized in my opinion like a lot of things I do it's actually somewhat controversial some people think it's a bad idea but I find it actually makes my code more concise and more maintainable and more powerful so I like it so let's see yeah so that's we've got our cancel epoch exception so then we're just going to keep track of our learning rates the learning rates we're going to learn a lot more about optimizers shortly so I won't worry too much about this but basically the learning rates are stored by PyTorch inside the optimizer and they're actually stored in things called param groups parameter groups so don't worry too much about the details but we can grab the learning rate from that dictionary and we'll learn more about that shortly we've got to keep track of the loss appended to our list of losses and if it's less than the minimum we've seen then recorded as the minimum and if it's greater than a three times the minimum then look at this it's really cool cancel fit exception so this will stop everything in a very nice clean way no need for lots of returns and conditionals or and stuff like that just raise the cancel fit exception and yeah and then finally we've got to actually update our learning rate to 1.3 times the previous one and so basically the way you do it in PyTorch is you have to go through each parameter group and grab the learning rate in the dictionary and multiply it by lrmult so yeah you've already seen it run and we can at the end of running you will find that there is now a the callback will now contain an LR's and a losses so for this callback I can't just add it directly to the callback list I need to instantiate it first and the reason I need to instantiate it first is because I need to be able to grab its learning rates and its losses and in fact you know we could grab that whole thing and move it in here there's no reason callbacks only have to have the callback things right so we could do this and now that's just going to become self there we go and so then we can train it again and we could just call LR find dot plot so callbacks can really be you know quite self-contained nice things as you can see so there's a more sophisticated callback and I think it's doing a lot of really nice stuff here you might have come across something in PyTorch called learning rate schedulers and in fact we could implement this whole thing with a learning rate scheduler it won't actually save that much time but I just want to show you when you use stuff in PyTorch like learning rate schedulers you're actually using things that are extremely simple the learning rate scheduler basically does this one line of code for us so I'm going to now create a new LR find a CB and this time I'm going to use the PyTorch's exponential LR scheduler which is here so this is now it's interesting that actually the documentation of this is kind of actually wrong it claims that it decays the learning rate of each parameter group by gamma so gamma is just some number you pass in I don't know why this has to be a Greek letter but it sounds more fancy than multiplying by an LR multiplier it says every epoch but it's not actually done every epoch at all what actually happens is in PyTorch the schedulers have a step method and the decay happens each time you call step and if you set gamma which is actually LR mult to a number bigger than one it's not a decay it's an increase so the difference now I guess I'll copy and paste the previous version okay so the previous versions on the top so the main difference here is that before fit we're going to create something called a self dot shed equal to the scheduler and the scheduler because it's going to be adjusting the learning rates it actually needs access to the optimizer so we pass in the optimizer and the learning rate model player and so then in after batch rather than having this line of code we replace it with this line of code self dot shed dot step so that's the only difference and you know I mean we're not gaining much as I said by using the PyTorch exponential LR scheduler but I mainly wanted to do it so you can see that these things like PyTorch schedulers are not doing anything magic they're just doing that one line of code for us and so I run it again using this new version oopsy dozy oh I forgot to run this line of code there we go and I guess I should also add the nice little plot method maybe we'll just move it to the bottom there lrfind dot plot there we go and put that one back to how it was all right perfect timing so we added a few very important things in here so make sure we export and we'll be able to use them shortly all right let's have an eight minute break it's just have a 10 minute break so I see you back here at um eight past all right welcome back um one suggestion which I lately like is we could rename plot to after fit which I really like because that means we should be able to then just call learn dot fit and delete the next one and let's see it didn't work why not oh no that doesn't work does it because the hmm you know what I think the callback here could go into a finally block actually that would actually allow us to always call the callback even if we've cancelled I think that's reasonable that might have its own confusions anyway we could try it for now because that would let us put this after fit in there we go so that automatically runs then so that's an interesting idea I think I quite like it cool so let's now look at notebook 10 so I feel like this is the the next big piece we need so we've got a pretty good system now for training models what I think we're really missing though is a way to identify how our models are training and so try identify how our models are training we need to be able to look inside them and see what's going on while they train we don't currently have any way to do that and therefore it's very hard for us to diagnose and fix problems most people have no way of looking inside their models and so most people have no way to properly diagnose and fix models and that's why most people when they have a problem with training their model randomly try things until something starts hopefully working we're not going to do that we're going to do it properly so we can import the stuff that we just created in the learner and the first thing I'm going to do introduce now is a set seed function we've been using torch manual seed before we know all about RNGs random number generators we've actually got three of them pie torches numpies and pythons let's see all of them and also in python pytorch you can use a flag to ask it to use deterministic algorithms so things should be reproducible as we discussed before you shouldn't always just make things reproducible but for lessons I think this is useful so here's a function that lets you set a reproducible seed all right let's use the same data set as before a fashion MNIST data set will load it up in the same way and let's create a model that looks very similar to our previous models this one might be a bit bigger might not I didn't actually check okay so let's use multiclass accuracy again same callbacks that we used before we'll use the train CB version for no particular reason and generally speaking we want to train as fast as possible not just because we don't like wasting time but actually more importantly because the fact the higher the learning rate you train at the more the more you're able to find a often more generalizable set of weights and also oh training quickly also means that we can look at each batch let each item in the data less often so we're going to have less issues with overfitting and generally speaking being if we can train at a high learning rate then that means that we're learning to train in a stable way and stable training is is very good so let's try setting up a high learning rate of point six and see what happens so here's a function that's just going to create a learner with our callbacks and fit it and return the learner in case we want to use it and it's training oh and then it suddenly fell apart so it's going well for a while and then it stopped training nicely so one nice thing about this graph is that we can immediately see when it stops training well which is very useful so what happened there why did it go badly I mean we can guess that it might have been because of our high learning rate but what's really going on so let's try to look inside it so one way to look inside it would be we could create our own sequential model which just like the sequential model we've built before with do you remember we created one using nn.module list in a previous lesson if you've forgotten go back and check that out and when we call that model we go through each layer and just call the layer and what we could do is though we could add something in addition which is at each layer we could also get the mean of that layer and the standard deviation of that layer and append them to a couple of different lists and activation means and activation standard deviations this is going to contain after we call this model it's going to contain the means and standard deviations for each layer and then we could define dunder iter which makes this into an iterator as being let's say just oh just it when you iterate through this model you can iterate through the layers so we can then train this model in the usual way and this is going to give us exactly the same outcome as before because I'm using the same seed so you can see it looks identical but the difference is instead of using nn.sequential we've now used something that's actually saved the means and standard deviations of each layer and so therefore we can plot them okay so here we've plotted the activation means and notice that we've done it for every batch so that's why along the x-axis here we have batch number and on the y-axis we have the activation means and then we have it for each layer so rather than starting at one because we play from starting at zero so this is the first layer is blue second layer is orange third layer green fourth layer red and fifth layer watch for that like movie kind of color and look what's happened the activations have started pretty small close to zero and have increased at an exponentially increasing rate and then have crashed and then have increased again an exponential rate and crashed again it increased again crashed again and each time they've not gone up they've gone up even higher and they've crashed in this case even lower and what happens well wait what's happening here when our activations are really close to zero well when your activations are really close to zero that means that the inputs to each layer are numbers very close to zero as a result of which of course the outputs are very close to zero because we're doing just matrix multiplies and so this is a disaster when activations are very close to zero you're there there they're dead units they're not able to do anything and you can see for ages here it's not training at all and this is so this is the this is the activation means the standard deviations tell an even stronger story so you want generally speaking you want the means of the activations to be about zero and the standard deviations to be about one mean of zero is fine as long as they're spread around zero but a standard deviation of close to zero is terrible because that means all of the activations are about the same so here after batch 30 all all of the activations are close to zero and all of their standard deviations are close to zero so all the numbers are about the same and they're about zero so nothing's going on and you can see the same things happening with standard deviations we start with not very much variety in the weights it exponentially increases how much variety there is and then it crashes again exponentially increases crashes again this is a classic shape of bad behavior and with these two plots you can really understand what's going on in your model and if you train a model and at the end of it you kind of think well I wonder if this is any good if you haven't looked at this plot you don't know because you haven't checked to see whether it's training nicely maybe it could it could be a lot better if you can get something we'll see some nicer training pictures later but generally speaking you want something where your main is always about zero and your variance is always about one standard deviation is always about one and if you see that then it's a pretty good chance you're training properly if you don't see that you're most certainly not training properly okay so what I'm going to do in the rest of this part of the lesson is explain how to do this in a more elegant way because as I say being able to look inside your models is such a critically important thing to building and debugging models we don't have to do it manually we don't have to create our own sequential model we can actually use a pytorch thing called hooks so as it says here a hook is called when a layer that it's registered to is executed during the forward pass that's quite a forward hook well the backward pass and that's called a backward hook and so the key thing about hooks is we don't have to rewrite the model we can add them to any existing model so we can just use standard nn.sequential passing in our layers which were these ones here and so we're still going to have something to keep track of the activation means and standard deviation so just create an empty list for now for each layer in the model and let's create a little function it's going to be called because a hawk is going to call a function when when during the forward pass for a forward hook or the backward pass or a backward hook so it could have function called a pen stats it's going to be passed the hook number sorry the layer number the module and the input and the output so we're going to be grabbing the outputs mean and putting in in activation means and the output standard deviation and putting it in activation standard deviations so here's how you do it we've got a model you go through each layer of the model and you call on it register forward hook that's part of pytorch and we don't need to write it ourselves because we already did right it's just doing the same thing as this basically and what function is always going to be called the function that's going to be called is the append stats function passing in remember partial is the equivalent of saying a pen stats passing in I as the first element the first argument so if we now fit that model it trains in the usual way but after each after each layer it's going to call this and so you can see we get exactly the same thing as before so one question we get here is what's the difference between a hook and a callback nothing at all hooks and call backs are the same thing it's just that pytorch defines hooks and they call them hooks instead of callbacks they are less flexible than the callbacks that we used in in the learner because you don't have access to all the available states you can't change things but there are you know there are particular kind of callback it's just setting a piece of code that's going to be run for us when we when something happens and in this case there's something that happens is that either layer in the forward pass is called or a layer in the backward pass is called I guess you could describe the function that's being called back as the callback and the thing that's doing the callback has the hook I'm not sure if that level of distinction is important but maybe that's you could do that okay so anyway this is a little bit fussy of kind of like creating globals and depending to them and stuff like that so let's try to simplify this a little bit so what I did here was I created a class called hook so this class when we create it we're going to pass in the module that we're hooking so we call M dot register forward hook and we call the function we pass the function that we want to be given and so here's the pass the function and we're also going to pass in the hook class to the function let's also define a remove because this is actually the thing that this is actually the thing that removes the hook we don't want it sitting around forever this is called the Dell is called by Python when an object is freed so when that happens we should also make sure that we remove this okay so appends that's now we're going to replace it's going to instead get past the hook instead because that's what we asked to be passed and if there's no dot stats attribute in there yet then let's create one and then we're going to be past the activation so put that on the CPU and append the mean and at the standard deviation and now the nice thing is that the stats are actually inside this object which is convenient so now we can do exactly the same thing as before but we don't have to set any of that global stuff or whatever we can just say okay our hooks is a hook with that layer and that function for all those models layers and so we're just calling it has called register forward hook for us so now when we fit that it's going to run with the hooks there we go it trains actually they did do it too okay so then it trains and we get exactly the same shape as usual and we get back the same results as usual but as we can see we're gradually making this more convenient which is nice so we can make it nicer still because generally speaking we're going to be adding multiple hooks and this stuff of you know this list comprehension whatever it's a bit inconvenient so let's create a hooks class so first of all we'll see how the hooks class works in practice so in the hooks class the way we're going to use it is we're going to call with hooks pass in the model pass in the function to use as their hook and then we'll fit the model and that's it it's going to be literally just one extra line of code to set up the whole thing and then when we then you can then go through each hook and plot the main and standard deviation of each layer so that's how that's the hooks class is going to make things much easier so the hooks class as you can see we're using a making it a context manager and we want to be able to loop through it we want to be an index into it so it's quite a lot of behavior we want believe it or not all that behavior is in this tiny little thing and we're going to use the most flexible general way of creating context managers now context managers are things that we can say with the general way of creating a context manager is to create a class and to find two special things done to enter and done to exit done to enter is a function that's going to be called when it hits the with statement and if you add an as blah after it then the contents of this variable will be whatever is returned from done to enter and as you can see we just return the object itself so the the hooks object is going to be stored in hooks now interestingly the hooks class inherits from list you can do this you can actually inherit from stuff like list in python so a hooks the hooks object is a list and therefore we need to call the super classes constructor and we're going to pass in a that list comprehension we saw that list of hooks where it's going to hook into each module in the list of modules we asked to hook into now we're passing in a model here but because the model is an nn dot sequential you can actually loop through an nn dot sequential and it returns each of the layers so this is actually very very nice and concise and convenient so that's the constructor done to enter just returns it done to exit is what's called automatically at the end of the whole block so when this whole thing's finished it's going to remove the hooks and removing the hooks is just going to go through each hook and remove it the reason we can do for H and self is because remember this is a list and then finally we've got a dunder dell like before and I also added a dunder dell item this is the thing that lets you delete a single hook from the list which will remove that one hook and call the list still item so there's our whole thing so this is going to this this this one's optional this is the one that lets us remove a single hook rather than all of them so let's just understand some of what's going on there so here's a dummy context manager as you can see here it's got a dunder enter which is going to return itself and it's going to print something so you can see here I call with dummy context manager and so therefore it prints let's go first the second thing it's going to do is call this code inside the context manager so we've got as DCM so that's itself and so it's gonna call hello which prints hello so here it is and then finally it's going to automatically call exit dunder exit which is all done so here's all done so again if you haven't used context managers before you want to be creating little samples like this yourself and getting them to work so this is your key homework for this week is anything in the lesson where we're using a part of Python you're not a hundred percent familiar with is for you to from scratch to create some simple like kind of dummy version that fully explores what it's doing if you're familiar with all the Python pieces then it's to create your own you know that is to explore do the same thing with the PyTorch pieces like with with hooks and so forth and so I just wanted to show you also what it's like to inherit from list so here I'm here inheriting from a list and I could redefine how dunder Dell item works so now I can create a dummy list and it looks exactly the same as usual but now if I delete an item from the list it's going to call my overridden version and then it will call the original version and so the list is now got removed that item and did this at the same time so you can see you can actually yeah modify how Python works or create your own things that get all the behavior or the convenience of Python classes like this one and add stuff to them so that's what's happening there okay so that's our hooks class so the next bit was developed largely developed the last time I think it was that we did a part 2 course in San Francisco with Stefano so many thanks to him for helping get this next bit looking great we're going to create my favorite single image explanations of what's going on inside a model we call them the colorful dimension which they're histograms we're going to take our same append stats these are all the same as before we're going to add an extra line of code which is to get a histogram of the absolute values of the activations so a histogram a histogram to remind you is something that takes a collection of numbers and tells you how frequent each group of numbers are and we're going to create 50 bins for our histogram so we will use our hooks that we just created and we're going to use this new version of append stats so it's going to train us before but now we're going to in addition have this extra extra thing in stats we're just going to contain a histogram and so with that we're now going to create this amazing plot now what this plot is showing is for the first second third and fourth layers what does the training look like and you can immediately see the basic idea is that we're seeing this same pattern but what is this pattern showing what exactly is going on in these pictures so I think it might be best if we try and draw a picture of this so let's take a normal histogram okay so let's take a normal histogram where what will be where we basically have like have grouped all the data into bins and then we have counts of how much is in each bin so for example this will be like the value of the activations and it might be say from 0 to 10 and then from 10 to 20 and from 20 to 30 and these are generally equally spaced bins okay and then here is the count so that's the number of items with that range of values so this is called a histogram okay so what Stefano and I did was we actually turn that histogram that whole histogram into a single column of pixels so if I take one column of pixels with that's actually one histogram and the way we do it is we take these numbers so let's say let's say it's like 14 that one's like 2 7 9 11 3 2 4 2 say and so then what we do is we turn it into a single column and so in this case we've got 1 2 3 4 5 6 7 8 9 groups right so we would create our nine groups sorry they were meant to be evenly spaced but they were a good job got our nine groups and so we take the first group it's 14 and what we do is we color it with a gradient and a color according to how big that number is so 14 is a real big number so depending on you know what gradient we use maybe reds really really big and the next one's really small which might be like green and then the next one's quite big in the middle which is like blue the next one's getting quite quite bigger still so maybe it's just a little bit sorry we should go back to red go back to more red next one's bigger stills it's even more red and so forth so basically we're taking the histogram and taking it into a color coded single column plot if that makes sense and so what that means is that at the very so let's take layer number two here layer number two we can take the very first column and so in the color scheme that actually map plot lives picked here yellow is the most common and then light green is less common and then light blue is less common and then dark blue is zero so you can see the vast majority is zero and there's a few with slightly bigger numbers which is exactly the same that we saw for index one layer here it is right the average the average is pretty close to zero the standard deviation is pretty small this is giving us more information however so as we train at this point here the at this point here there is quite a few activations that are a lot larger as you can see and still the vast majority of them are very small there's a few big ones they still got a bright yellow bar at the bottom the other thing to notice here is what's happened is we've taken those those stats those histograms we've stacked them all up into a single tensor and then we've taken their log now log 1p is just log of the number plus 1 that's because we've got zeros here and so just taking the log is going to kind of let us see the full range more clearly so that's what the locks for so basically what we'd really ideally like to see here is that this whole thing should be a kind of more like a rectangle you know the maximum should be should be not changing very much there shouldn't be a thick yellow bar at the bottom but instead it should be a nice even gradient matching a normal distribution each single column of pixels wants to be kind of like a normal distribution so you know gradually decreasing the number of activations that's what we're aiming for there's a another really important and actually easier to read version of this which is what if we just took those first two bottom pixels so the the least common five percent and counted up how many were in what's not the foot sorry least common five percent the least cut the not least common either let's try again in the bottom two pixels we've got the smallest two equally sized groups of activations we don't want there to be too many of them because those are basically dead or nearly dead activations they're much much much smaller than the big ones and so taking the ratio between those bottom two groups and the total basically tells us what percentage have zero or near zero or extremely small magnitudes and remember that these are with absolute values so if we plot those you can see how bad this is and in particular for example at the final layer from the you know nearly from the very start really nearly all of the activations are they're entirely just about entirely disabled so this is this is bad news and if you've got a model where most of your model is close to zero then most of your models doing no work and so it's it's really it's really not working so it may look like at the very end things were improving but as you can see from this chart that's not true right there's still the vast majority are still inactive generally speaking I found that if early in training you see this rising crash rising crash at all you should stop and restart training because this your model will probably never recover too many of the activations have gone off the rails so we want it to look kind of like this the whole time but with less of this very thick yellow bar which is showing us most are inactive okay so that's our activations so we've got really now all of the kind of key pieces I think we need to be able to flexibly change how we train models and to understand what's going on inside our models and so from this point we've kind of like drilled down as deep as we need to go and we can now start to come back up again and and put together the pieces building up what are all of the things that are going to help us train models reliably and quickly and then hopefully we're going to be able to yeah successfully create from scratch some really high quality generative models and other models along the way okay I think that's everything for this class but next class we're going to start looking at things like initialization it's a really important topic if you want to do some revision before then just make sure that you're very comfortable with things like standard deviations and stuff like that because we're using that quite a lot for next time and yeah thanks for joining me look forward to the next lesson see you again