Practical Deep Learning for Coders: Lesson 1
Chapters
0:0 Introduction0:25 What has changed since 2015
1:20 Is it a bird
2:9 Images are made of numbers
3:29 Downloading images
4:25 Creating a DataBlock and Learner
5:18 Training the model and making a prediction
7:20 What can deep learning do now
10:33 Pathways Language Model (PaLM)
15:40 How the course will be taught. Top down learning
19:25 Jeremy Howard’s qualifications
22:38 Comparison between modern deep learning and 2012 machine learning practices
24:31 Visualizing layers of a trained neural network
27:40 Image classification applied to audio
28:8 Image classification applied to time series and fraud
30:16 Pytorch vs Tensorflow
31:43 Example of how Fastai builds off Pytorch (AdamW optimizer)
35:18 Using cloud servers to run your notebooks (Kaggle)
38:45 Bird or not bird? & explaining some Kaggle features
40:15 How to import libraries like Fastai in Python
40:42 Best practice - viewing your data between steps
42:0 Datablocks API overarching explanation
44:40 Datablocks API parameters explanation
48:40 Where to find fastai documentation
49:54 Fastai’s learner (combines model & data)
50:40 Fastai’s available pretrained models
52:2 What’s a pretrained model?
53:48 Testing your model with predict method
55:8 Other applications of computer vision. Segmentation
56:48 Segmentation code explanation
58:32 Tabular analysis with fastai
59:42 show_batch method explanation
61:25 Collaborative filtering (recommendation system) example
65:8 How to turn your notebooks into a presentation tool (RISE)
65:45 What else can you make with notebooks?
68:6 What can deep learning do presently?
70:33 The first neural network - Mark I Perceptron (1957)
72:38 Machine learning models at a high level
78:27 Homework
Transcript
Welcome to practical deep learning for coders lesson one. This is version 5 of this course. And it's the first year one we've done in two years. So we've got a lot of cool things to cover. It's amazing how much has changed. Here is a XKCD from the end of 2015.
Who here has seen XKCD comics before? Pretty much everybody, not surprising. So the basic joke here is I'll let you read it and then I'll come back to it. So it can be hard to tell what's easy and what's nearly impossible. And in 2015 or at the end of 2015, the idea of checking whether something is a photo of a bird was considered nearly impossible.
So impossible it was the basic idea of a joke because everybody knows that that's nearly impossible. We're now going to build exactly that system for free in about two minutes. So let's build an is-it-a-bird system. So we're going to use Python. And so I'm going to run through this really quickly.
You're not expected to run through it with me because we're going to come back to it. OK. But let's go ahead and run that cell. OK. So what we're doing is we're searching DuckDuckGo for images of bird photos and we're just going to grab one. And so here is the URL of the bird that we grabbed.
OK. We'll download it. OK. So there it is. So we've grabbed a bird and so OK. We've now got something that can download pictures of birds. Now we're going to need to build a system that can recognize things that are birds versus things that aren't birds from photos. Now of course computers need numbers to work with.
But luckily images are made of numbers. I actually found this really nice website called PickSpy where I can grab a bird. And if I go over it, let's pick its beak. You'll see here that that part of the beak was 251 brightness of red, 48 of green and 21 of blue.
So that's GB. And so you can see as I wave around those colors are changing those numbers. And so this picture, the thing that we recognize as a picture, is actually 256 by 171 by 3 numbers between 0 and 255 representing the amount of red, green and blue on each pixel.
So that's going to be an input to our program that's going to try and figure out whether this is a picture of a bird or not. OK. So let's go ahead and run this cell. Which is going to go through, and I needed bird and non-bird, but you can't really search Google images or dot dot go images for not a bird.
This doesn't work that way. So I just decided to use forest. I thought, OK, pictures of forest versus pictures of bird sounds like a good starting point. So I go through each of forest and bird and I search for forest photo and bird photo, download images and then resize them to be no bigger than 400 pixels on a side, just because we don't need particularly big ones.
It takes a surprisingly large amount of time just for a computer to open an image. OK, so we've now got 200 of each. I find when I download images, I often get a few broken ones. And if you try and train a model with broken images, it will not work.
So here's something which just verifies each image and unlinks, so deletes the ones that don't work. OK, so now we can create what's called a data block. So after I run this cell, you'll see that basically I go through the details of this later, but a data block gives fast AI, the library, all the information it needs to create a computer vision model.
And so in this case, we're basically telling it get all the image files that we just downloaded. And then we say show me a few up to six. And let's see. Yeah, so we've got some birds, forest, bird, bird, forest. OK, so one of the nice things about doing computer vision models is it's really easy to check your data because you can just look at it, which is not the case for a lot of kinds of models.
OK, so we've now downloaded 200 pictures of birds, 200 pictures of forests. So we'll now press run. And this model is actually running on my laptop. So it's not using a vast data center. It's running on my presentation laptop and it's doing it at the same time as my laptop is streaming video, which is possibly a bad idea.
And so what it's going to do is it's going to run through every photo out of those 400. And for the ones that are forest, it's going to learn a bit more about what forest looks like. And for the ones that are bird, it'll learn a bit more about what bird looks like.
So overall, it took under 30 seconds. And believe it or not, that's enough to finish doing the thing which was in that XKCD comic. Let's check by passing in that bird that we downloaded at the start. This is a bird. Probability, it's a bird. One. Rounded to the nearest four decimal places.
So something pretty extraordinary has happened since late 2015, which is literally something that has gone from so impossible, it's a joke, to so easy that I can run it on my laptop computer in, I don't know how long it was, about two minutes. And so hopefully that gives you a sense that creating really interesting, real working programs with deep learning is something that it doesn't take a lot of code, didn't take any math, didn't take more than my laptop computer.
It's pretty accessible, in fact. So that's really what we're going to be learning about over the next seven weeks. So where have we got to now with deep learning? Well, it moves so fast. But even in the last few weeks, we've taken it up another notch as a community.
You might have seen that something called Dali 2 has been released, which uses deep learning to generate new pictures. And I thought this was an amazing thing that this guy, Nick, did, where he took his friend's Twitter bios and typed them into the Dali 2 input, and it generated these pictures.
So this guy, he typed in commitments, empathetic, psychedelic, philosophical, and it generated these pictures. So I'll just show you a few of these. I'll let you read them. I love that. That one's pretty amazing, I reckon. Actually. I love this. Happy Sushi Fest has actually got a happy rock to move around.
So this is like, yeah, I don't know. When I look at these, I still get pretty blown away that this is a computer algorithm using nothing but this text input to generate these arbitrary pictures, in this case of fairly complex and creative things. So the guy who made those points out, he spends about two minutes or so creating each of these.
He tries a few different prompts, and he tries a few different pictures. And so he's given an example here of when he typed something into the system. Here's an example of 10 different things he gets back when he puts in expressive painting of a man shining rays of justice and transparency on a blue bird Twitter logo.
So it's not just, you know, Dali too, to be clear. There's, you know, a lot of different systems doing something like this now. There's something called Mid Journey, which this Twitter account posted a female scientist with a laptop writing code in a symbolic, meaningful, and vibrant style. This one here is an HD photo of a rare psychedelic pink elephant.
And this one, I think, is the second one here. I never know how to actually pronounce this. This one's pretty cool. A blind bat with big sunglasses holding a walking stick in his hand. And so when actual artists, you know, so this, for example, this guy said he knows nothing about art, you know, he's got no artistic talent, it's just something, you know, he threw together.
This guy is an artist who actually writes his own software based on deep learning and spends, you know, months on building stuff. And as you can see, you can really take it to the next level. It's been really great, actually, to see how a lot of fast AI alumni with backgrounds as artists have gone on to bring deep learning and art together.
And it's a very exciting direction. And it's not just images, to be clear. You know, one of the other interesting thing that's popped up in the last couple of weeks is Google's Pathways language model, which can take any arbitrary English as text question and can create an answer, which not only answers the question, but also explains its thinking, whatever it means for a language model to be thinking.
One of the ones I found pretty amazing was that it can explain a joke. So, I'll let you read this. So, this is actually a joke that probably needs explanations for anybody who's not familiar with TPUs. So, this model just took the text as input and created this text as output.
And so, you can see, you know, again, deep learning models doing things which I think very few, if any of us would have believed would be maybe possible to do by computers even in our lifetime. This means that there is a lot of practical and ethical considerations. We will touch on them during this course, but can't possibly hope to do them justice.
So, I would certainly encourage you to check out ethics.fast.ai to see our whole data ethics course taught by my co-founder, Dr. Rachel Thomas, which goes into these issues in a lot more detail. All right. So, as well as being an AI researcher at the University of Queensland and fast.ai, I am also a homeschooling primary school teacher.
And for that reason, I study education a lot. And one of the people who are live in education is a guy named Dylan Williams. And he has this great approach in his classrooms of figuring out how his students are getting along, which is to put a coloured cup on their desk, green to mean that they're doing fine, yellow cup to mean I'm not quite sure, and a red cup to mean I have no idea what's going on.
Now, since most of you are watching this remotely, I can't look at your cups, and I don't think anybody bought coloured cups with them today. So instead, we have an online version of this. So, what I want you to do is go to cups.fast.ai/fast. That's cups.fast.ai/fast. And don't do this if you're like a fast.ai expert who's done the course five times, because if you're following along, that doesn't really mean much, obviously.
It's really for people who are not already fast.ai experts. And so, click one of these coloured buttons. And what I will do is I will go to the teacher version and see what buttons you're pressing. All right. So, so far, people are feeling we're not going too fast on the whole.
We've got one brief read. Okay. So, hey, Nick, this URL, it's the same thing with teacher on the end. Can you keep that open as well and let me know if it suddenly gets covered in red? If you are somebody who's read, I'm not going to come to you now because there's not enough of you to stop the class.
So, it's up to you to ask on the forum or on the YouTube live chat. And there's a lot of folks, luckily, who will be able to help you. All right. I wanted to do a big shout out to Radik. Radik created cups.fast.ai for me. I said to him last week I need a way of seeing coloured cups on the internet.
And he wrote it in one evening. And I also wanted to shout out that Radik just announced today that he got a job at NVIDIA AI. And I wanted to say, you know, that fast.ai alumni around the world very, very frequently, like every day or two, they may want me to say that they've got their dream job.
And, yeah, if you're looking for inspiration of how to get into the field, I couldn't recommend nothing. Nothing would be better than checking out Radik's work. And he's actually written a book about his journey. It's got a lot of tips in particular about how to take advantage of fast.ai, make the most of these lessons.
And so I would certainly say check that out as well. And if you're here live, he's one of our TAs as well. So you can say hello to him afterwards. He looks exactly like this picture here. So I mentioned I spent a lot of time studying education, both for my home schooling duties and also for my courses.
And you'll see that there's something a bit different, very different about this course, which is that we started by training a model. We didn't start by doing a in-depth review of linear algebra and calculus. That's because two of my favorite writers and researchers on education, Paul Lockhart and David Perkins, and many others talk about how much better people learn when they learn with a context in place.
So the way we learn math at school where we do counting and then adding and then fractions and then decimals and then blah, blah, blah. And 15 years later, we start doing the really interesting stuff at grad school. That is not the way most people learn effectively. The way most people learn effectively is from the way we teach sports.
For example, where we show you a whole game of sports, we show you how much fun it is. You go and start playing sports, simple versions of them. You're not very good. And then you gradually put more and more pieces together. So that's how we do deep learning. You will go into as much depth as the most sophisticated, technically detailed classes you'll find later.
But first, you'll learn to be very, very good at actually building and deploying models. And you will learn why and how things work as you need to to get to the next level. For those of you that have spent a lot of time in technical education, like if you've done a PhD or something, will find this deeply uncomfortable because you'll be wanting to understand why everything works from the start.
Just do your best to go along with it. Those of you who haven't will find this very natural. Oh, and this is Dylan Williams, who I mentioned before, the guy who came up with the really cool cut scene. There'll be a lot of tricks that have come out of the educational research literature scattered through this course.
On the whole, I won't call them out, they'll just be there. But maybe from time to time we'll talk about them. All right, so before we start talking about how we actually built that model and how it works, I guess I should convince you that I'm worth listening to.
I'll try to do that reasonably quickly, because I don't like tooting my own horn, but I know it's important. So the first thing I mentioned about me is that me and my friend Songva wrote this extremely popular book, Deep Learning for Coders, and that book is what this course is quite heavily based on.
We're not going to be using any material from the book directly, and you might be surprised by that. But the reason actually is that the educational research literature shows that people learn things best when they hear the same thing in multiple different ways. So I want you to read the book, and you'll also see the same information presented in a different way in these videos.
So one of the bits of homework after each lesson will be to read a chapter of the book. A lot of people like the book. Peter Norvig, Director of Research, loves the book. In fact, this one's here. One of the best sources for a program to become proficient in deep learning.
Eric Topol loves the book. Hal Varian, America's Professor at Berkeley, Chief Congressman at Google, likes the book. Jerome Percenti, who is the Head of AI at Facebook, likes the book. A lot of people like the book. So hopefully you'll find that you like this material as well. I've spent about 30 years of my life working in and around machine learning, including building a number of companies that relied on it, and became the highest ranked competitor in the world on Kaggle in machine learning competitions.
My company in Liddick, which I founded, was the first company to specialize in deep learning for medicine, and MIT voted at one of the 50 smartest companies in 2016, just above Facebook and SpaceX. I started Fast AI with Rachel Thomas, and that was quite a few years ago now, but it's had a big impact on the world already.
Including work we've done with our students has been globally recognized, such as our Wind in the Dawn Bench competition, which showed how we could train big neural networks faster than anybody in the world, and cheaper than anybody in the world. And so that was a really big step in 2018, which actually made a big difference.
Google started using our special approaches in their models, Nvidia started optimizing their stuff using our approaches, so it made quite a big difference there. I'm the inventor of the ULM fit algorithm, which according to the Transformers book was one of the two key foundations behind the modern NLP revolution.
This is the paper here. And actually, you know, interesting point about that, it was actually invented for a fast AI course. So the first time it appeared was not actually in the journal, it was actually in lesson four of the course, I think the 2016 course, if I remember correctly.
And you know, most importantly, of course, I've been teaching this course since version one. And this is actually this, I think this is the very first version of it, which even back then was getting HBR's attention. A lot of people have been watching the course, and it's been, you know, fairly widely used.
YouTube doesn't show likes anymore. So I have to show you our likes for you. You know, it's it's been amazing to see how, yeah, how many alumni have gone from this to, to, you know, to really doing amazing things, you know, and so, for example, Andre Capathy told me that Tesla, I think he said pretty much everybody who joins Tesla in AI is meant to do this course, I believe at OpenAI, they told me that all the residents joining there first do this course.
So this, you know, this course is really widely used in industry and research for people. And they have a lot of success. Okay, so there's a bit of brief information about why you should hopefully get going with this. Alright, so let's get back to what's what's happened here. Why are we able to create a bird recognizer in a minute or two?
And why couldn't we do it before? So I'm going to go back to 2012. And in 2012, this was how image recognition was done. This is the computational pathologist. It was a project done at Stanford, very successful, very famous project that was looking at the five year survival of breast cancer patients by looking at their histopathology images slides.
Now, so this is like what I would call a classic machine learning approach. And I spoke to the senior author of this Daphne Coller. And I asked her why they didn't use deep learning. And she said, Well, it just, you know, it wasn't really on the radar at that point.
So this is like a pre deep learning approach. And so the way they did this was they got a big team of mathematicians and computer scientists and pathologists and so forth to get together and build these ideas for features like relationships between epithelial nuclear neighbors. Thousands and thousands, actually, they created a features and each one required a lot of expertise from a cross disciplinary group of experts at Stanford.
So this project took years, and a lot of people and a lot of code and a lot of math. And then once they had all these features, they then fed them into a machine learning model, in this case, logistic regression to predict survival. As I say, it's very successful, right?
But it's not something that I could create for you in a minute, at the start of a course. The difference with neural networks is neural networks don't require us to build these features. They build them for us. And so what actually happened was, in I think it was 2015, Matt Zyla and Rob Fergus took a trained neural network and they looked inside it to see what it had learned.
So we don't give it features, we ask it to learn features. So when Zyla and Fergus looked inside a neural network, they looked at the actual, the weights in the model, and they draw a picture of them. And this was nine of the sets of weights they found. And this set of weights, for example, finds diagonal edges.
This set of weights finds yellow to blue gradients. And this set of weights finds red to green gradients and so forth, right? And then down here are examples of some bits of photos which closely matched, for example, this feature detector. And deep learning is deep because we can then take these features and combine them to create more advanced features.
So these are some layer two features. So there's a feature, for example, that finds corners and a feature that finds curves and a feature that finds circles. And here are some examples of bits of pictures that the circle finder found. And so remember, with a neural net, which is the basic function used in deep learning, we don't have to hand code any of these or come up with any of these ideas.
You just start with actually a random neural network, and you feed it examples, and you have a learn to recognize things. And it turns out that these are the things that it creates for itself. So you can then combine these features. And when you combine these features, it creates a feature detector, for example, that finds kind of repeating geometric shapes.
And it creates a feature detector, for example, that finds kind of really little things, which it looks like is finding the edges of flowers. And this feature detector here seems to be finding words. And so the deeper you get, the more sophisticated the features it can find are. And so you can imagine that trying to code these things by hand would be insanely difficult, and you wouldn't know even what to encode by hand.
So what we're going to learn is how neural networks do this automatically. But this is the key difference of why we can now do things that previously we just didn't even conceive of as possible, because now we don't have to hand code the features we look for. They can all be learned.
Now, build is important to recognize. We're going to be spending some time learning about building image-based algorithms. And image-based algorithms are not just for images. And in fact, this is going to be a general theme. We're going to show you some foundational techniques. But with creativity, these foundational techniques can be used very widely.
So for example, an image recognizer can also be used to classify sounds. So this was an example from one of our students who posted on the forum and said for their project, they would try classifying sounds. And so they basically took sounds and created pictures from their waveforms. And then they used an image recognizer on that.
And they got a state of the art result, by the way. Another of our students on the forum said that they did something very similar to take time series and turn them into pictures and then use image classifiers. Another of our students created pictures from mouse movements from users of a computer system.
So the clicks became dots and the movements became lines and the speed of the movement became colors. And then use that to create an image classifier. So you can see with some creativity, there's a lot of things you can do with images. There's something else I wanted to point out, which is that as you saw, when we trained a real working bird-recognized image model, we didn't need lots of math.
There wasn't any. We didn't need lots of data. We had 200 pictures. We didn't need lots of expensive computers. We just used my laptop. This is generally the case for the vast majority of deep learning that you'll need in real life. There will be some math that pops up during this course, but we will teach it to you as needed or we'll refer you to external resources as needed.
But it will just be the little bits that you actually need. The myth that deep learning needs lots of data I think is mainly passed along by big companies that want to sell you computers to store lots of data and to process it. We find that most real world projects don't need extraordinary amounts of data at all.
And as you'll see, there's actually a lot of fantastic places you can do state-of-the-art work for free nowadays, which is great news. One of the key reasons for this is because of something called transfer learning, which we'll be learning about a lot during this course, and it's something which very few people are aware of and are aware of.
In this course, we'll be using PyTorch. For those of you who are not particularly close to the deep learning world, you might have heard of TensorFlow and not of PyTorch. You might be surprised to hear that TensorFlow has been dying in popularity in recent years, and PyTorch is actually growing rapidly.
And in research repositories amongst the top papers, TensorFlow is a tiny minority now compared to PyTorch. This is also great research that's come out from Ryan O'Connor. He also discovered that the majority of people that were doing TensorFlow in 2018, the majority of now shifted to PyTorch. And I mention this because what people use in research is a very strong leading indicator of what's going to happen in industry because this is where all the new algorithms are going to come out, this is where all the papers are going to be written about.
It's going to be increasingly difficult to use TensorFlow. We've been using PyTorch since before it came out, before the initial release, because we knew just from technical fundamentals, it was far better. So this course has been using PyTorch for a long time. I will say, however, that PyTorch requires a lot of hairy code for relatively simple things.
This is the code required to implement a particular optimizer called AdamW in plain PyTorch. I actually copied this code from the PyTorch repository. So as you can see, there's a lot of it. This gray bit here is the code required to do the same thing with FastAI. FastAI is a library we built on top of PyTorch.
This huge difference is not because PyTorch is bad, it's because PyTorch is designed to be a strong foundation to build things on top of, like FastAI. When you use FastAI, the library, you get access to all the power of PyTorch as well. But you shouldn't be writing all this code if you only need to write this much code.
The problem of writing lots of code is that that's lots of things to make mistakes with, lots of things to not have best practices in, lots of things to maintain. In general, we found particularly with deep learning, less code is better. Particularly with FastAI, the code you don't write is code that we've basically found kind of best practices for you.
So when you use the code that we've provided for you, you're generally fine to get better results. So FastAI has been a really popular library, and it's very widely used in industry, in academia, and in teaching. And as we go through this course, we'll be seeing more and more pure PyTorch as we get deeper and deeper underneath to see exactly how things work.
The FastAI library just won the 2020 Best Paper Award, or the paper about it, in information. So again, you can see it's a very well regarded library. Okay, so okay, we're still green. That's good. So you may have noticed something interesting, which is that I'm actually running code in these slides.
That's because these slides are not in PowerPoint. These slides are in Jupyter Notebook. Jupyter Notebook is the environment in which you will be doing most of your computing. It's a web-based application, which is extremely popular and widely used in industry and in academia and in teaching, and is a very, very, very powerful way to experiment and explore and to build.
Nowadays, I would say most people, at least most students, run Jupyter Notebooks not on their own computers, particularly for data science, but on a cloud server, of which there's quite a few. And as I mentioned earlier, if you go to course.fast.ai, you can see how to use various different cloud servers.
One I'm going to show an example of is Kaggle. So Kaggle doesn't just have competitions, but it also has a cloud notebooks server. And I've got quite a few examples there. So let me give you a quick example of how we use Jupyter Notebooks to build stuff, to experiment, to explore.
So on Kaggle, if you start with somebody else's Notebook, so why don't you start with this one, Jupyter Notebook 101. If it's your own Notebook, you'll see a button called edit. If it's somebody else's, that button will say copy and edit. If you use somebody's Notebook that you like, make sure you click the upvote button to encourage them and to help other people find it before you go ahead and copy and edit.
And once we're in edit mode, we can now use this Notebook. And to use it, we can type in any arbitrary expression in Python and click run. And the very first time we do that, it says session is starting. It's basically launching a virtual computer for us to run our code.
This is all free. In a sense, it's like the world's most powerful calculator. It's a calculator where you have all of the capabilities of the world's, I think, most popular programming language. Certainly, it and JavaScript would be the top two directly at your disposal. So Python does know how to do one plus one.
And so you can see here, it spits out the answer. I hate clicking. I always use keyboard shortcuts. So instead of clicking this little arrow, you just press shift and to do the same thing. And as you can see, there's not just calculations here. There's also pros. And so Jupyter Notebooks are great for explaining to you the version of yourself in six months time, what on earth you are doing or to your coworkers or to people in the open source community, what are people you're blogging for, etc.
And so you just type pros. And as you can see, when we create a new cell, you can create a code cell, which is a cell that lets you type calculations or a markdown cell, which is a cell that lets you create pros. And the pros use this formatting in a little mini language called markdown.
There's so many tutorials around, I won't explain it to you, but it lets you do things like links and so forth. So I'll let you follow through the tutorial in your own time because it really explains to you what to do. One thing to point out is that sometimes you'll see me use cells with an exclamation mark at the start.
That's not Python. That's a bash shell command. Okay, so that's what the exclamation mark means. As you can see, you can put images into notebooks. And so the image I popped in here was the one showing that Jupiter won the 2017 software system award, which is pretty much the biggest award there is for this kind of software.
Okay, so that's the basic idea of how we use notebooks. So let's have a look at how we do our, how we do our bird or not bird model. One thing I always like to do when I'm using something like Colab or Kaggle cloud platforms that I'm not controlling is make sure that I'm using the most recent version of any software.
So my first cell here is exclamation mark pip install minus U that means upgrade Q for quiet fast AI. So that makes sure that we have the latest version of fast AI. And if you always have that at the start of your notebooks, you're never going to have those awkward foreign threads where you say, why isn't this working?
And somebody says to you, oh, you're using an old version of some software. So you'll see here, this notebook is the exact thing that I was showing you at the start of this lesson. So if you haven't done much Python, you might be surprised about how little code there is here.
And so Python is a concise but not too concise language, you'll see that there's less boilerplate than some other languages you might be familiar with. And I'm also taking advantage of a lot of libraries. So fast AI provides a lot of convenient things for you. So I forgot to import.
So to use a external library, we use import to import a symbol from a library. Fast AI has a lot of libraries we provide, they generally start with fast something. So for example, to make it easy to download a URL, fast download has download URL. To make it easy to create a thumbnail, we have image to thumb and so forth.
So we I always like to view as I'm building a model, my data at every step. So that's why I first of all grab one bird, and then I grab one forest photo, and I look at them to make sure they look reasonable. And once I think okay, they look okay, then I go ahead and download.
And so you can see fast AI has a download images, where you just provide a list of URLs. So that's how easy it is. And it does that in parallel. So it does that, you know, surprisingly quickly. One other fast AI thing I'm using here is resize images. You generally will find that for computer vision algorithms, you don't need particularly big images.
So I'm resizing these to a maximum side length of 400. Because it's actually much faster. This GPUs are so quick for big images, most of the time can be taken up just opening it. The neural net itself often takes less time. So that's another good reason to make them smaller.
Okay. So the main thing I wanted to tell you about was this data block command. So the data block is the key thing that you're going to want to get familiar with, as deep learning practitioners at the start of your journey. Because the main thing you're going to be trying to figure out is how do I get this data into my model?
Now that might surprise you. You might be thinking we should be spending all of our time talking about neural network architectures and matrix multiplication and gradients and stuff like that. The truth is very little of that comes up in practice. And the reason is that at this point, the deep learning community has found a reasonably small number of types of model that work for nearly all the main applications you'll need.
And fast AI will create the right type of model for you the vast majority of the time. So all of that stuff about tweaking neural network architectures and stuff, I mean, we'll get to it eventually in this course. But you might be surprised to discover that it almost never comes up.
Kind of like if you ever did like a computer science course or something, and they spent all this time on the details of compilers and operating systems, and then you get to the real world and you never use it again. So this course is called practical deep learning. And so we're going to focus on the stuff that is practically important.
Okay, so our images are finished downloading, and two of them were broken, so we just deleted them. Another thing you'll note, by the way, if you're a keen software engineer is I tend to use a lot of functional style in my programs I find for kind of the kind of work I do that a functional style works very well.
If you're you know a lot of people in Python are less familiar with that it's more it may becomes more from other things. So yeah, that's why you'll see me using stuff like map and stuff quite a lot. Alright, so a data block is the key thing you need to know about if you're going to know how to use different kinds of data sets.
And so these are all of the things basically that you'll be providing. And so what we did when we designed the data block was we actually looked and said, okay, over hundreds of projects, what are all the things that change from project to project to get the data into the right shape.
And we realized we could basically split it down into these five things. So the first thing that we tell fast AI is what kind of input do we have. And so then so there are lots of blocks in fast AI for different kinds of input. So he said, Oh, the input is an image.
What kind of output is there? What kind of label? The outputs are category. So that means it's one of a number of possibilities. So that's enough for fast AI to know what kind of model to build for you. So what are the items in this model? What am I actually going to be looking at to look to train from?
This is a function. In fact, you might have noticed if you were looking carefully that we use this function here. It's a function which returns a list of all of the image files in a path based on extension. So every time it's going to try and find out what things to train from, it's going to use that function.
In this case, we'll get a list of image files. Now, something we'll talk about shortly is that it's critical that you put aside some data for testing the accuracy of your model. And that's called a validation set. It's so critical that fast AI won't let you train a model with that one.
So you actually have to tell it how to create a validation set, how to set aside some data. And in this case, we say randomly set aside 20% of the data. Okay, next question, then you have to tell fast AI is how do we know the correct label of a photo?
How do we know if it's a bird photo or a forest photo? And this is another function. And this function simply returns the parent folder of a path. And so in this case, we saved our images into either forest or bird. So that's where the labels are going to come from.
And then finally, most computer vision architectures need all of your inputs as you train to be the same size. So item transforms are all of the bits of code that are going to run on every item, on every image in this case. And we're saying, okay, we want you to resize each of them to being 192 by 192 pixels.
There's two ways you can resize, you can either crop out a piece in the middle, or you can squish it. And so we're saying, squish it. So that's the data block, that's all that you need. And from there, we create an important class called data loaders. Data loaders are the things that actually PyTorch iterates through to grab a bunch of your data at a time.
The way it can do it so fast is by using a GPU, which is something that can do thousands of things at the same time. And that means it needs thousands of things to do at the same time. So a data loader will feed the training algorithm with a bunch of your images at once.
In fact, we don't call it a bunch, we call it a batch, or a mini batch. And so when we say show batch, that's actually a very specific word in deep learning, it's saying show me an example of a batch of data that you would be passing into the model.
And so you can see show batch gives you tells you two things, the input, which is the picture, and the label. And remember, the label came by calling that function. So when you come to building your own models, you'll be wanting to know what kind of splitters are there and what kinds of labeling functions are there and so forth.
That's wrong button. You'll be wanting to know what kind of labeling functions are there and what kind of splitters are there and so forth. And so docs.fast.ai is where you go to get that information. Often the best place to go is the tutorials. So for example, here's a whole data block tutorial.
And there's lots and lots of examples. So hopefully you can start out by finding something that's similar to what you want to do and see how we did it. But then of course, there's also the underlying API information. So here's data blocks. OK. How are we doing? Still doing good.
All right. So at the end of all this, we've got an object called dls. It stands for data loaders. And that contains iterators that PyTorch can run through to grab batches of randomly split out training images to train the model with and validation images to test the model with.
So now we need a model. The critical concept here in fast.ai is called a learner. A learner is something which combines a model, that is the actual neural network function we'll be training, and the data we use to train it with. And that's why you have to pass in two things.
The data, which is the data loaders object, and a model. And so the model is going to be the actual neural network function that you want to pass in. And as I said, there's a relatively small number that basically work for the vast majority of things you do. If you pass in just a bare symbol like this, it's going to be one of fast.ai's built-in models.
But what's particularly interesting is that we integrate a wonderful library by Ross Whiteman called Tim, the PyTorch image models, which is the largest collection of computer vision models in the world. And at this point, fast.ai is the first and only framework to integrate this. So you can use any one of the PyTorch image models.
And one of our students, Amanomora, was kind enough to create this fantastic documentation where you can find out all about the different models. And if we click on here, you can get lots and lots of information about all the different models that Ross has provided. Having said that, the model family called ResNet are probably going to be fine for nearly all the things you want to do.
But it is fun to try different models out. So you can type in any string here to use any one of those other models. Okay, so if we run that, let's see what happens. Okay, so this is interesting. So when I ran this, so remember on Kaggle, it's creating a new virtual computer for us.
So it doesn't really have anything ready to go. So when I ran this, the first thing it did was it said downloading resnet18.pth. What's that? Well, the reason we can do this so fast is because somebody else has already trained this model to recognize over 1 million images of over 1,000 different types, something called the image net dataset.
And they then made those weights available, those parameters available on the internet for anybody to download. By default, on fast.ai, when you ask for a model, we will download those weights for you so that you don't start with a random network that can't do anything. You actually start with a network that can do an awful lot.
And so then something that fast.ai has that's unique is this fine-tune method, which what it does is it takes those pre-trained weights we downloaded for you and it adjusts them in a really carefully controlled way to just teach the model the differences between your dataset and what it was originally trained for.
That's called fine-tuning. Hence the name. So that's why you'll see this downloading happen first. And so as you can see at the end of it, this is the error rate here. After a few seconds, it's 100% accurate. So we now have a learner. And this learner has started with a pre-trained model.
It's been fine-tuned for the purpose of recognizing bird pictures from forest pictures. So you can now call .predict on it. And .predict, you pass in an image. And so this is how you would then deploy your model. So in the code, you have whatever it needs to do. So in this particular case, this person had some reason that he needs the app to check whether they're in a national park and whether it's a photo of a bird.
So at the bit where they need to know if it's a photo of a bird, it would just call this one line of code, learn.predict. And so that's going to return whether it's a bird or not as a string, whether it's a bird or not as an integer, and the probability that it's a non-bird or a bird.
And so that's why we can print these things out. So that's how we can create a computer vision model. What about other kinds of models? There's a lot more in the world than just computer vision, a lot more than just image recognition. Or even within computer vision, there's a lot more than just image recognition.
For example, there's segmentation. So segmentation, maybe the best way to explain segmentation is to show you the result of this model. Segmentation is where we take photos, in this case of road scenes, and we color in every pixel according to what is it. So in this case, we've got brown as cars, blue as fences, I guess, red as buildings, brown.
And so on the left here, some photos that somebody has already gone through and classified every pixel of every one of these images according to what that pixel is a pixel of. And then on the right is what our model is guessing. And as you can see, it's getting a lot of the pixels correct, and some of them is getting wrong.
It's actually amazing how many is getting correct because this particular model I trained in about 20 seconds using a tiny, tiny, tiny amount of data. So again, you would think this would be a particularly challenging problem to solve, but it took about 20 seconds of training to solve it not amazingly well, but pretty well.
If I'd trained it for another two minutes, it'd probably be close to perfect. So this is called segmentation. Now, you'll see that there's very, very little code required, and the steps are actually going to look quite familiar. In fact, in this case, we're using an even simpler approach. Now, earlier on, we used data blocks.
Data blocks are a kind of intermediate level, very flexible approach that you can take to handling almost any kind of data. But for the kinds of data that occur a lot, you can use these special data loaders classes, which kind of lets you use even less code. So in this case, to create data loaders for segmentation, you can just say, okay, I'm going to pass you in a function for labeling.
And you can see here, it's got pretty similar things that we pass in to what we passed in for data blocks before. So our file names is getImageFiles again, and then our label function is something that grabs this path and the codes, so the code, so like what does each code mean, is going to be this text file.
But you can see the basic information we're providing is very, very similar, regardless of whether we're doing segmentation or object recognition. And then the next steps are pretty much the same. We create a learner for segmentation. We create something called a unit learner, which we'll learn about later. And then again, we call fine-tune.
So that is it. And that's how we create a segmentation model. What about stepping away from computer vision? So perhaps the most widely used kind of model used in industry is tabular analysis. So taking things like spreadsheets and database tables and trying to predict columns of those. So in tabular analysis, it really looks very similar to what we've seen already.
We grab some data, and you'll see when I call this untied data, this is the thing in Fast.ai that downloads some data and decompresses it for you. And there's a whole lot of URLs provided by Fast.ai for all the kind of common data sets that you might want to use, all the ones that are in the book, or lots of data sets that are kind of widely used in learning and research.
So that makes life nice and easy for you. So again, we're going to create data loaders, but this time it's tabular data loaders. But we provide pretty similar kind of information to what we have before. A couple of new things. We have to tell it which of the columns are categorical.
So they can only take one of a few values, and which ones are continuous. So they can take basically any real number. And then again, we can use the exact same show batch that we've seen before to see the data. And so Fast.ai uses a lot of something called type dispatch, which is a system that's particularly popular in a language called Julia, to basically automatically do the right thing for your data, regardless of what kind of data it is.
So if your call show batch on something, you should get back something useful, regardless of what kind of information you provided. So for a table, it shows you the information in that table. This particular data set is a data set of whether people have less than $50,000 or more than $50,000 in salary for different districts based on demographic information in each district.
So to build a model for that data loaders, we do, as always, something_learner. In this case, it's a tabular learner. Now this time we don't say fine-tune. We say fit, specifically fit one cycle. That's because for tabular models, there's not generally going to be a pre-trained model that already does something like what you want, because every table of data is very different, whereas pictures often have a similar theme.
They're all pictures. They all have the same kind of general idea of what pictures are. So that's why it generally doesn't make too much sense to fine-tune a tabular model. So instead, you just fit. So there's one difference there. I'll show another example. Okay, so collaborative filtering. Collaborative filtering is the basis of most recommendation systems today.
It's a system where we basically take data set that says which users liked which products or which users used which products, and then we use that to guess what other products those users might like based on finding similar users and what those similar users liked. The interesting thing about collaborative filtering is that when we say similar users, we're not referring to similar demographically, but similar in the sense of people who liked the same kinds of products.
So for example, if you use any of the music systems like Spotify or Apple Music or whatever, it'll ask you first like what's a few pieces of music you like, and you tell it. And then it says, okay, well, maybe let's start playing this music for you. And that's how it works.
It uses collaborative filtering. So we can create a collaborative filtering data loaders in exactly the same way that we're used to by downloading and decompressing some data, create our collab data loaders. In this case, we can just say from CSV and pass in a CSV. And this is what collaborative filtering data looks like.
It's going to have, generally speaking, a user ID, some kind of product ID, in this case, a movie, and a rating. So in this case, this user gave this movie a rating of 3.5 out of 5. And so again, you can see show batch, right? So use show batch, you should get back some useful visualization of your data regardless of what kind of data it is.
And so again, we create a learner. This time it's a collaborative filtering learner, and you pass in your data. In this case, we give it one extra piece of information, which is because this is not predicting a category, but it's predicting a real number, we tell it what's the possible range.
The actual range is 1 to 5. But for reasons you'll learn about later, it's a good idea to actually go from a little bit lower than the possible minimum to a little bit higher. That's why I say 0.5 to 5.5. And then fine-tune. Now again, we don't really need to fine-tune here because there's not really such a thing as a pre-trained collaborative filtering model.
We could just say fit or fit one cycle. But actually fine-tune works fine as well. So after we train it for a while, this here is the mean squared error. So it's basically that on average, how far off are we for the validation set. And you can see as we train, and it's literally so fast, it's less than a second each epoch, that error goes down and down.
And for any kind of fast AI model, you can... And for any kind of fast AI model, you can always call show results and get something sensible. So in this case, it's going to show a few examples of users and movies. Here's the actual rating that user gave that movie, and here's the rating that the model predicted.
Okay, so apparently a lot of people on the forum are asking how I'm turning this notebook into a presentation. So I'd be delighted to show you because I'm very pleased that these people made this thing for free for us to use. It's called Rise. And all I do is it's a notebook extension.
And in your notebook, it gives you an extra little thing on the side where you say which things are slides or which things are fragments. And a fragment just means this is a slide that's a fragment. So if I do that, you'll see it starts with a slide, and then the fragment gets added in.
Yeah, that's about all theories to it, actually. It's pretty great. And it's very well documented. I'll just mention, what do I make with Jupyter Notebooks? This entire book was written entirely in Jupyter Notebooks. Here are the notebooks. So if you go to the Fast.io Fastbook repo, you can read the whole book.
And because it's all in notebooks, every time we say here's how you create this plot or here's how you train this model, you can actually create the plot or you can actually train the model because it's all notebooks. The entire Fast.io library is actually written in notebooks. So you might be surprised to discover that if you go to fast.io/fast.io, the source code for the entire library is notebooks.
And so the nice thing about this is that the source code for the Fast.io library has actual pictures of the actual things that we're building, for example. What else have we done with notebooks? Oh, blogging. I love blogging with notebooks because when I want to explain something, I just write the code and you can just see the outputs.
And it all just works. Another thing you might be surprised by is all of our tests and continuous integration are also all in notebooks. So every time we change one of our notebooks, every time we change one of our notebooks, hundreds of tests get run automatically in parallel. And if there's any issues, we will find out about it.
So notebooks are great. And Rise is a really nice way to do slides in notebooks. All right. So what can deep learning do at present? We're still scratching the tip of the iceberg, even though it's a pretty well-hyped, heavily marketed technology at this point. When we started in 2014 or so, not many people were talking about deep learning.
And really, there was no accessible way to get started with it. There were no pre-trained models you could download. There was just starting to appear some of the first open source software that would run on GPUs. But despite the fact that today there's a lot of people talking about deep learning, we're just scratching the surface.
Every time pretty much somebody says to me, "I work in domain X and I thought I might try deep learning out to see if it can help." And I say to them a few months later and I say, "How did it go?" They nearly always say, "Wow, we just broke the state-of-the-art results in our field." So when I say these are things that it's currently state-of-the-art for, these are kind of the ones that people have tried so far.
But still, most things haven't been tried. So in NLP, deep learning is the state-of-the-art method in all these kinds of things and a lot more. Computer vision, medicine, biology, recommendation systems, playing games, robotics. I've tried elsewhere to make bigger lists and I just end up with pages and pages and pages.
Generally speaking, if it's something that a human can do reasonably quickly, like look at a Go board and decide if it looks like a good Go board or not, even if it needs to be an expert human, then that's probably something that deep learning will be pretty good at.
If it's something that takes a lot of logical thought processes over an extended period of time, particularly if it's not based on much data, maybe not, like who's going to win the next election or something like that. That'd be kind of broadly how I would try to decide, is your thing useful for deep, good for deep learning or not.
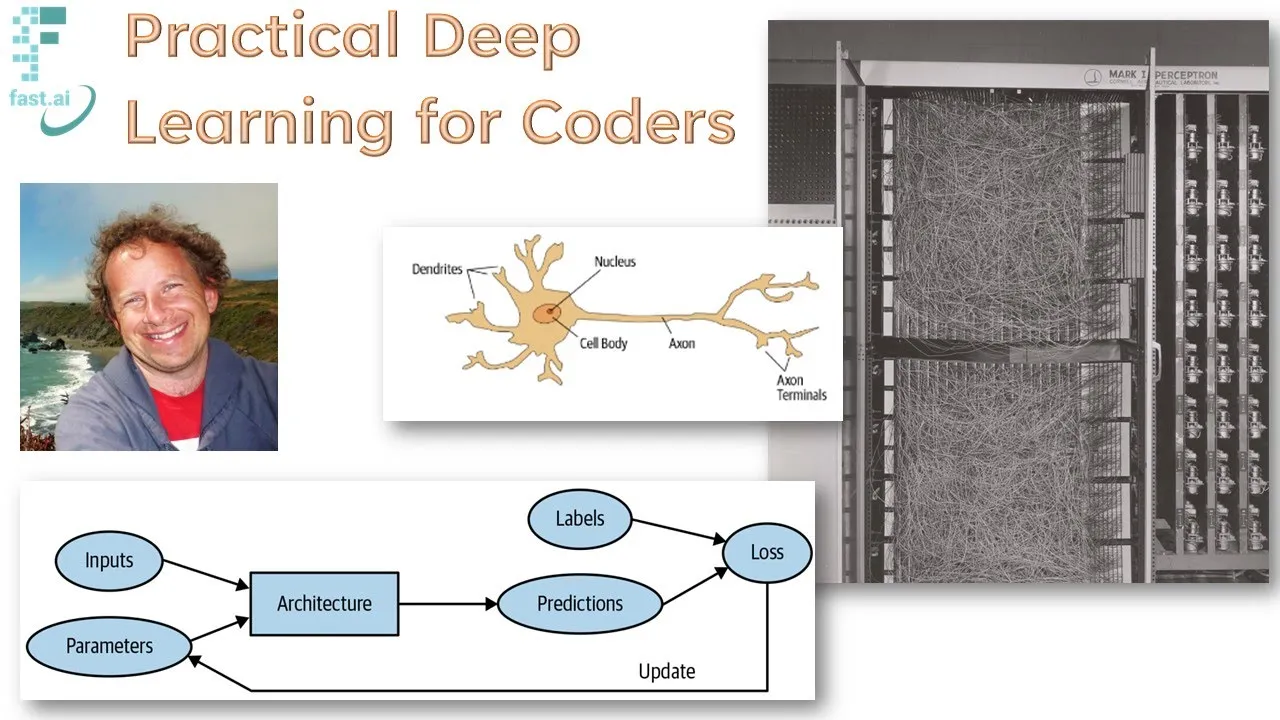
It's been a long time to get to this point. Yes, deep learning is incredibly powerful now, but it's taken decades of work. This was the first neural network. Remember, neural networks are the basis of deep learning. This was back in 1957. The basic ideas have not changed much at all, but we do have things like GPUs now and solid state drives and stuff like that.
Of course, much more data just is available now, but this has been decades of really hard work by a lot of people to get to this point. Let's take a step back and talk about what's going on in these models. I'm going to describe the basic idea of machine learning, largely as it was described by Arthur Samuel in the late '50s when it was invented.
I'm going to do it with these graphs, which, by the way, you might find fun. These graphs are themselves created with Jupyter Notebooks. These are graph-fizz descriptions that are going to get turned into these. There's a little sneak peek behind the scenes for you. Let's start with a graph of what does a normal program look like?
In the pre-deep learning, machine learning days, you still have inputs and you still have results. Then you code a program in the middle, which is a bunch of conditionals and loops and setting variables and blah, blah, blah. A machine learning model doesn't look that different, but the program has been replaced with something called a model.
We don't just have inputs now. We now also have weights, which are also called parameters. The key thing is this. The model is not anymore a bunch of conditionals and loops and things. It's a mathematical function. In the case of a neural network, it's a mathematical function that takes the inputs, multiplies them together by one set of weights, and adds them up.
It does that again for a second set of weights and adds them up. It does it again for a third set of weights and adds them up and so forth. It then takes all the negative numbers and replaces them with zeros. Then it takes those as inputs to a next layer.
It does the same thing, multiplies them a bunch of times and adds them up. It does that a few times. That's called a neural network. The model, therefore, is not going to do anything useful, and this leads weights to very carefully chosen. The way it works is that we actually start out with these weights as being random.
Initially, this thing doesn't do anything useful at all. What we do, the way Arthur Samuel described it back in the late 50s, the inventor of machine lighting, is he said, "Okay, let's take the inputs and the weights, put them through our model." He wasn't talking particularly about neural networks.
He's just like, "Whatever model you like. Get the results, and then let's decide how good they are." If, for example, we're trying to decide, "Is this a picture of a bird?" The model said, which initially is random, says, "This isn't a bird." Actually, it is a bird. It would say, "Oh, you're wrong." We then calculate the loss.
The loss is a number that says, "How good were the results?" That's all pretty straightforward. We could, for example, say, "Oh, what's the accuracy?" We could look at 100 photos and say, "Which percentage of them did it get right?" No worries. Now the critical step is this arrow. We need a way of updating the weights that is coming up with a new set of weights that are a bit better than the previous set.
By a bit better, we mean it should make the loss get a little bit better. We've got this number that says, "How good is our model?" Initially, it's terrible, right? It's random. We need some mechanism of making it a little bit better. If we can just do that one thing, then we just need to iterate this a few times because each time we put in some more inputs and put in our weights and get our loss and use it to make it a little bit better, then if we make it a little bit better enough times, eventually it's going to get good, assuming that our model is flexible enough to represent the thing we want to do.
Now remember what I told you earlier about what a neural network is, which is basically multiplying things together and adding them up and replacing the negatives with zeros, and you do that a few times? That is, preferably, an infinitely flexible function. It actually turns out that that incredibly simple sequence of steps, if you repeat it a few times and you do enough of them, can solve any computable function, and something like generate an artwork based off somebody's Twitter bio is an example of a computable function, or translate English to Chinese is an example of a computable function.
They're not the kinds of normal functions you do in Year 8 math, but they are computable functions. Therefore, if we can just create this step and use the neural network as our model, then we're good to go. In theory, we can solve anything given enough time and enough data.
That's exactly what we do. Once we've finished that training procedure, we don't need the loss anymore. Even the weights themselves, we can integrate them into the model. We finish changing them, so we can just say that's now fixed. Once we've done that, we now have something which takes inputs, puts them through a model, and gives us results.
It looks exactly like our original idea of a program. That's why we can do what I described earlier. That is, once we've got that learn.predict for our bird recognizer, we can insert it into any piece of computer code. Once we've got a trained model as just another piece of code, we can call with some inputs and get some outputs.
Deploying machine learning models in practice can come with a lot of little tricky details, but the basic idea in your code is that you're just going to have a line of code that says learn.predict, and then you just fit it in with all the rest of your code in the usual way.
This is why, because a trained model is just another thing that maps inputs to results. As we come to wrap up this first lesson, for those of you that are already familiar with notebooks and Python, this is going to be pretty easy for you. You're just going to be using some stuff that you're already familiar with and some slightly new libraries.
For those of you who are not familiar with Python, you're biting into a big thing here. There's obviously a lot you're going to have to learn. To be clear, I'm not going to be teaching Python in this course, but we do have links to great Python resources in the forum, so check out that thread.
Regardless of where you're at, the most important thing is to experiment. Experimenting could be as simple as just running those Kaggle notebooks that I've shown you just to see them run. You could try changing things a little bit. I'd really love you to try doing the bird or forest exercise, but come up with something else.
Maybe try to use three or four categories rather than two. Have a think about something that you think would be fun to try. Depending on where you're at, push yourself a little bit, but not too much. Make sure you get something finished before the next lesson. Most importantly, read chapter one of the book.
It's got much the same stuff that we've seen today, but presented in a slightly different way. Then come back to the forums and present what you've done in the share your work here thread. After the first time we did this in year one of the course, we got over a thousand replies.
Of those replies, it's amazing how many of them have ended up turning into new startups, scientific papers, job offers. It's been really cool to watch people's journeys. Some of them are just plain fun. This person classified different types of Trinidad and Tobago people. People do stuff based on where they live and what their interests are.
I don't know if this person is particularly interested in zucchini and cucumber, but they made a zucchini and cucumber classifier. I thought this was a really interesting one, classifying satellite imagery into what city it's probably a picture of. Amazingly accurate actually, 85% with 110 classes. Panama City bus classifier, battered cloth classifier.
This one, very practically important, recognizing the state of buildings. We've had quite a few students actually move into disaster resilience based on satellite imagery using exactly this kind of work. We've already actually seen this example, Ethan Sooten, the sound classifier. I mentioned it was state of the art. He actually checked up the data sets website and found that he beat the state of the art for that.
Elena Harley did human normal sequencing. She was at Human Longevity International. She actually did three different really interesting pieces of cancer work during that first course, if I remember correctly. I showed you this picture before. What I didn't mention is actually this student lab was a software developer at Splunk, a big NASDAQ-listed company.
This student project he did turned into a new patented product at Splunk and a big blog post. The whole thing turned out to be really cool. It was basically something to identify fraudsters using image recognition with these pictures we discussed. One of our students built this startup called Envision.
Anyway, there's been lots and lots of examples. All of this is to say, have a go at starting something, create something you think would be fun or interesting, and share it in the forum. If you're a total beginner with Python, then start with something simple, but I think you'll find people very encouraging.
If you've done this a few times before, then try to push yourself a little bit further. Don't forget to look at the quiz questions at the end of the book and see if you can answer them all correctly. Thanks, everybody, so much for coming. Bye. (audience clapping)