fastai v2 walk-thru #10
Chapters
0:0 Introduction1:25 Core
8:10 Make class
11:40 Multiple inheritance
21:1 Stop
23:10 Trace
25:55 Composition
26:33 LS
28:47 Data augmentation
29:55 Brand transform
32:20 Flip LR
37:0 Filt
43:15 Croppad
Transcript
>> Okay, hi there, everybody. Can you see in here okay? Okay, let me know if anybody has any requests. This will be the last walkthrough, at least for a while, because we've covered most of the main stuff other than what's in learner and optimizer and stuff, which is largely the same as what was in the course in Part 2, Version 3 of the course.
We'll probably do another walkthrough in a couple of weeks or so to cover the little differences, I suspect. We can have a quick look at the Imagenet tutorial today as well. Mainly I was going to look at the data augmentation and finish off a little bit more of the stuff that's in Core.
But yeah, just ask any questions if there's stuff either we haven't covered or you didn't quite follow or you don't quite know how it fits together. In the meantime, we'll get back to Core. And so you can see in Core, other than metaclasses, which we're probably going to be largely getting rid of, so we'll ignore that, there's the kind of decorators and stuff we talked about, there's Gedatra, there's L, and then there's a bunch of stuff.
And a bunch of stuff is, broadly speaking, stuff for collections, types, functions about functions, file and network. So in terms of stuff that's interesting, one thing that's kind of interesting is make class. Make class is a replacement for typing class. So basically, I'll just make sure I've done a poll here.
There we go. So basically this one here, make class TA equals 1, super equals Gedatra, is the same as typing this, class underscore T, Gedatra colon A equals 1. So those are basically two ways of doing the same thing, except that this version has a bit of extra functionality.
Let me think, what does it do? Been a while since I've looked at this one. Ah, yes, okay. So the class that we get back works kind of a bit more like a data class from the Python data classes standard library thing. So you can kind of see, and behind the scenes it calls this thing called get class, which is actually kind of what does the work.
So you can see that we can pass in, for instance, A. It says that we will get something called, as you see here, T dot A. Let's try that. So we could go T equals underscore T. There we go, okay, T dot A. And so you can see that if we just pass in something saying this is a field, so we see we first pass in a list of fields, then we get that as an empty field.
You can pass in a value for it. And so that will mean that the first field listed A will get that value, as you can see. You can pass in keyword argument fields. So in this case, B here, you can initialize like this. There it is. You can also pass in functions that you want to be included.
So for example, define F self print I. And so then we could say, funks equals F. And so now we'll have an underscore F. Oops, what did I do wrong there? Functions, now funks, F, and what did I do wrong? Let's have a look. Maybe I should get rid of the underscore that might be confusing for it, because that's normally hidden to T.
Oh, sorry, I'm being silly. We need to recreate it. So we need to go-- I'm going crazy. So we have to create the class, funks equals F. And we have A. And we had B equals 2. Right. And so now there we go, that's our function. Let's see. We get a rep for free.
Let's try that one. Yep, there we go. So you can see I can just type T. You'll see that the rep for isn't added if you put in a superclass, because the superclass might have its own rep for. So basically, by using this make class, we can quickly create a little-- it's kind of good for tests and stuff.
We can create a quick class, which has some key values that we want, some fields that we want. You can initialize it. It's got a representation. So that's pretty handy little thing that we use quite often in the tests. Let's have a look, actually. See if it's also used in the actual main code base.
So let's look for make class. OK, it's used occasionally. So here's an example. One of usage is inside layers. So let's take a look at that. OK, so here's the example of in layers. It's creating a class called pull type. And it has a bunch of fields in it.
So this is actually a really good example of something that we do occasionally. So let's use that to see how it works. So let's see what does pull type now look like. So we're going through average, max, cat, and creating a dictionary. So if we go to-- well, let's just go pull type.tab, and there you can see average, cat, and max.
This is actually a really nice little way of creating kind of enum strings or kind of strings that have nice tab completion, so it's a good use of make class. Here you go, doing exactly the same here for pad mode. It's actually the same here for resize method. So other than that-- oh, here's one again that's getting all the events for callbacks.
And then in the Notebox-- oh, in the wrong space, pass the idea of-- in the Notebox, yeah, you can see we use it sometimes to create little quick and dirty things for testing. So we tend to use it instead of data classes, because we find it a bit more convenient sometimes.
So Kevin asked about multiple inheritance. So multiple inheritance is pretty widely covered in Python tutorials, so I won't go into detail, but if you go to Python multiple inheritance, you will find lots of examples. But the answer is, yeah, basically you have multiple base classes. So what will happen is that when you look in super for something, it will first look in here.
If it doesn't find it, then it will look in here. That's basically what multiple inheritance does. So in this case, we wanted this to contain all of the basic collection stuff, and we also wanted it to have the getatra. So this means we now have both. Right. What else have we got here in functions?
Wrap class is something that just takes a function and wraps it into a class by calling make class. So sometimes that's handy for tests where you want to quickly create something that you can test methods on. No worries, Kevin. The collection function is worth knowing about, but they're pretty simple.
So like, toplify to turn something into a tuple, uniquify to get the unique values of something, setify to turn something into a set, group by is super handy. It takes a list like this and groups it by some function. In this case, a, a, a, b, b, b being grouped by item getter zero is going to group by the first letter.
So a is a, a, b, a, b, and b is b, b. That's a very handy function. There's something called iter_tools.groupby in Python standard library. I find this one more convenient and less complicated to understand. Merging dictionaries is often handy. So it just does what it suggests, merges the dictionaries together.
Okay, yeah. We probably will do a walkthrough with the text stuff. But we haven't really gone back over it to see whether the ideas from tabular could be used there. Because we wrote the 30 stuff first before we did tabular, but we might be able to refactor text using in-place transform.
I'm not sure. So if we do end up with two different approaches, we'll explain why. Hopefully we won't, though, because it's nice not to have to have two different approaches. Oh, this is fun. I don't use this very much, but I possibly could use it more as more of an exploration of some functional programming ideas.
This is basically something where I'm creating all of these things as functions, less than greater than, less than equal, greater than equal, et cetera. They are all functions that exist within the operator module in the Python standard library. And these functions work the same way, less than 3,5 is true, greater than 3,5 is false.
But they also allow you to do what's called carrying, as you can see here. And specifically, this is helpful, where you can kind of go f equals lt3. And then I could do f5, so just putting that into two lines. And the reason that's interesting is so I could do stuff like l.range8.
So let's pick those ones. Let's say we had some list. We wanted to grab those which are less than 3, I could go filtered, lt3, like so. And so that's just a lot more convenient than writing the normal way, which would be lambda x, colon, x is less than 3.
So this kind of thing is pretty common, like pretty much all functional languages allow you to do carrying like this. Unfortunately, Python doesn't, but you can kind of create versions that do work that way. And as you can see, the way I'm doing it is I've created this little upper thing, which if you pass in only one thing, then b is none, then it returns a lambda, otherwise it does the actual operation.
And so that is handy with some of this extra stuff that I'm going to show here. For example, I've created an infinite lists class so that you can do things like an infinite count is arranged from 0 to infinity. So I could do, for instance, list, filter, inf.count, comma, less than 10.
Oops, I've got to run those lines, wrong way around, filter in Python first takes a function less than 10, comma, inf.count. Now that's interesting, why isn't that working? Never mind, we can do it this way, zip, range, 5, comma, 15. comma, inf.count, and then list that. OK, there we go.
So you can see that the numbers coming from inf.count are just the numbers counting up. So we could do things like list iter tools.islice inf.count, comma, 10, say, or we could map and x, colon, x times 2, like so, and so forth. You could replace inf.count with inf.zeros, as you can see, or inf.ones.
So it's often really handy to be able to have quick infinite lists available to you. We use that, for example, in the data loader. So that's basically why this is here. It's actually very challenging in-- I mean, not challenging. It's awkward in Python to be able to create a property like this that behaves this way.
The only way I could try to do it was to make it into a meta class and put the properties in the meta class and then make that meta class the thing I actually want. So it's not too bad, but it's a little more awkward than would be ideal.
It's often useful to be able to do an expression that returns-- that raises an exception. So something like a equals 3, a is greater than 5, or stop. And so you can raise an exception in this way. So I do that quite often. So when you see stop, I particularly use that-- by default, it raises a stop iteration, which is what Python uses when you finish iterating through a list.
But you can do anything you like, and as you can see-- Oh, this is a good example of how to use that. So I've created a generator function that is a lot like a map, but it allows us to do this handle stop iteration nicely. So we can generate from some function over some sequence-- so it's basically like a map-- as long as some condition is true.
So for example, do no-op over count while less than 5, and that's going to be return the same as range 5, for operator.negative over an infinite count, well, it's greater than negative 5. We'll return this. Well, here's an example which does not have a condition, but instead the actual mapping function has a stop in it.
So look over an infinite list, return itself, if o is less than 5, otherwise stop. So this is actually a super nice way of doing functional stuff in Python. Chunk, we briefly saw, because it was in data loader, and the behavior you can see, you start with a range, for example, and chunk into groups of three, and this is how we do batching in the data loader.
In type, we've seen-- I think most of these types we've seen, show title, so that's fine. Trace is super handy if I have-- let me give you an example. So let's say I'm creating, I don't know, some list.mapped lambda o-- o times 2. So I've got something like this, right?
And so I've got a passing a function or lambda into something, and I want to debug something, like something like this. Actually, so a good example would be, what if I was doing this? Whoops, I should say negative. And maybe it's not working the way I expected, so I want to debug it.
You can use trace to turn any function into a traced version of that function, like so. And so now I can step into, if I step, I will be stepping into operator.negative, which it looks like I can't step into, because I guess that's written not in Python. That's annoying.
Let's create our own version then, def, neg, just for this example, return, x, there we go. Step. OK. And there you go. Here we are. We've stepped into neg. So this is really handy for debugging stuff, particularly where you're doing map or something like that, passing in some function that might be from fast.ai or the Python standard library or PyTorch or whatever.
And as you can see, it's very simple. You just stick a set trace and then return the same function. This does function composition, map does the same as map, but you can pass in multiple functions. Yeah, they're all pretty self-explanatory, and then these are the ones we're not really using at the moment, so don't worry about that.
If you look at any of those other things and decide you're interested, feel free to ask in the forums. LS we've looked at. This is interesting. Something like b-unzip. It's interesting to note that the Python standard library has a bzip standard library function, but it doesn't do simple things like unzip something in a path.
So here's a little function that just does that. It just takes a path and unzips it with bzip using the standard library. So you don't have to call out to an external process. So this kind of thing is very useful to create cross-platform compatible code. OK. So as you can see, it's a bit of a mishmash of stuff that we've thrown in there as we've needed it.
The main thing I wanted to show you then was augmentation functionality, and the data augmentation functionality is basically grouped into two phases. You can either do data augmentation on individual items, like an individual image, or you can do data augmentation on a whole batch. And so obviously we would rather do data augmentation on a whole batch, so we can do it on the GPU.
But it's pretty difficult to create data augmentation functions that operate on a batch where the things in a batch are different sizes, because you can't really create a proper tensor of it unless you do padding and stuff. So to deal with that, we suggest you first of all do a data augmentation that resizes things to a consistent size, and then do the rest of your data augmentation on the GPU as a batch.
By the way, as most of you probably know, you need to make sure that if you're doing something like segmentation or object detection, that your independent variables and your dependent variables get augmentation using the same random state, the same, you know, they need to be rotate your, your mask and your image both need to be rotated by the same amount, for example.
So to let that happen, we have a subclass of transform called rand transform. And rand transform overrides dunder call from transform to just add a extra callback called before call. So remember how in our transforms, they will by default operate, they will like get called on each part of your tuple independently.
So we need to make sure that we do any randomization before that happens. So this is our opportunity to do that. And so by default, our rand transform has a P, a probability that the transform is applied. And by default, our before call will set something called do, so do you want to do it or not, which is is some random number less than that P or not.
So that's how we do data augmentation. So for example, we can create a rand transform where the encoder is at one. And so P equals point five means that will be applied half the time. So let's-- I mean, we don't really need to create it there. We can actually probably create it there.
Oh, looks like these got renamed somehow. Oh, I see, it doesn't need to be inside. Ah, yes, I see. So you can see that the do attribute will be set to true about half the time. So if it's set to true, we'll set this thing to say, yep, it was set to true at least once.
Otherwise, we'll set this thing saying it was false at least once. So we'll make sure that both of them got called. That way, we know it is actually randomizing properly. Yeah, that's the basic idea. Now, most of the time, you're not going to create a rand transform by passing an encoder in like this.
Most of the time, you will create a rand transform by-- let's see if I can find an example-- by inheriting from rand transform and defining the for call and encodes. So the encodes is just the usual fast.ai transform encodes. And this is the bit where you get to set things up.
So let's look at some examples. OK. So let's do a flip left right. So before we do, it would be nice if we have a flip left right method, which we can call on pretty much anything, which isn't a random transform, just something where we can just say like this, show image image dot flip left right.
So if I'm going to be able to say image dot flip left right, then the easiest way to do that is with our patch. And I mean, there's no reason for that just to be a PIO image. It could actually be a image dot image. May as well make it as convenient as possible.
There we go. So now we have something called flipLR, which is a method of image, tensor image, tensor point, tensor bbox. And so we can test that by creating a tensor from a PILO image. We can test flipLR, we can create a tensor point, we can create a tensor bbox.
As you can see, we're just checking that our flipLR works correctly. So for the example for the PyTorch case, it already has a dot flip. And you just say which axis to flip on. So that made that one super easy. PILO has something else called transpose. So when you want to now turn that into a random data augmentation, then you inherit from Rantransform.
And actually in the case where everything you want to use it on is going to just be exactly the same line of code, it's going to have the same name. So there's a couple of ways we could do this, right? One would be to say def encodes self, x, colon, tensor image, return x.flipLR, that'd be one way to do it.
We'd like to do it for each different type, but they're all going to have the same code. So another thing we could do would be to actually use a tuple as our dispatch type. And in fastAI, if you use a tuple, it means any of these, but we actually have an even easier way with Rantransform is that the default encodes actually is something which will basically just call a function called self.name.
And so in this case, if I set self.name to flipLR, then it's just going to call that function, which is the function I want to call. But we wouldn't want to like, you might have some types that just so happens to have this function name and we don't want to do data augmentation on.
So the other thing you do is you would add your type to this supports list to say this is something which supports flipping. So if you later on have something else that has a flipLR method and you want it to be added to things that get flipped in data augmentation.
So maybe your class is a, I don't know, a 3D image that might be something called image3D. Then you could say in, you could say flipItem.supports.append.image3D and that's it. Now that's going to get random data augmentation as well, or you can do it in the usual way, which is def encodes, self, comma, x colon, and then you can do it there.
So that's the usual way of adding stuff to a transform. All right. Another interesting point about RAM transforms is that Filt is set to zero and to remind you in transforms, we use this to decide whether or not to call a transform based on what subset it's in. So this says because Filt is zero for this transform, this will be by default only called on your training set and will not be called on your validation or test sets.
You can obviously change that by setting Filt to something else, but that's the default. And so when we then create our flipItem transform to test it out, when we call it, we have to say Filt equals zero because we're not using a data source or anything here to say, hey, we're in the training set.
So dihedral, for those of you that remember, is basically the same thing, except it flips also vertically or with transposes, so the eight possible dihedral symmetries. And as you can see, it's doing the same thing. So now we've patched dihedral into all these types. So we can just say name equals dihedral.
And this time, we don't only have a p, but we also need to set our random number between 0 and 7, saying which of these types of flip we'll be doing. Presumably random.randint is inclusive, is it? And int, including both endpoints, OK? That's not what I expected. Yeah, so by doing this with before call, we make sure that that k is available, although how is that going to work?
It's not. That's a bug. So we're testing it only with this image.dihedral approach, but we're not testing it with the function. Ah, that was a mistake, because this k is going to need to be passed in here. All right, so let's-- we have to call that ourselves, which is no problem.
All right, so I think we're going to have to go def ncodes self comma x colon, and then we'll list all the types we support, just all of those. There we go. And so now there's no point passing this name along, because we're not doing the automatic version. And so now we will return x.dihedral self dot k.
And so now we need to make sure that we have a test of that. So what we could do is we could create a transform here, called a dihedral item transform. And let's do it with a p equals 1, OK? So we're going to go, and then we will go show-- we'll go f image.
And we would say built equals 0. There's no need to use the i, because this is random this time. So hopefully we'll see a nice mix of random transforms. Let's see if that works. And that needs a built. And super needs a filter. OK. There we go. So we've got lots of different random versions.
So let's get rid of this one, since we don't really need it twice. And this one we can probably hide, because it's just testing it on TensorPoint as well. OK. So those are transforms that work on a single item at a time. So here is something called CropPad, which will either crop or pad, depending on whatever is necessary to create the size that you ask for, which we've seen in other versions of fast.ai.
So we've done the same idea. There's a CropPad, which calls something called DoCropPad, and then DoCropPad is defined. Let's move everything around so it's easier to see what's going on. There we go. For TensorBbox, for TensorPoint, and for any kind of image. So since we now have that working, we can, in our CropPad transform, simply call, as you see, DoCropPad.
Still some room to refactor this a little bit, but it's on the right check. All right. And as you can see, you can choose what padding mode you want, reflection, border, zeros. So then we can use something you can then inherit from that to create random crop just by changing before call.
So do a random crop, as you can see. So here's some random crops of this doggy. And one of the nice things here is it'll automatically take the-- oh, we should check this is actually working. We want it to take the center crop automatically on the validation set, although I don't know if we actually have that set up.
OK, we can do resizing, similar idea, again, just inheriting from CropPad. The famous random resize crop used in pretty much all ImageNet solutions is just another kind of CropPad. So we don't need to go through all that. And then we start the random transforms that'll work on the GPU.
And there's nothing particularly different about them. These don't need to be refactored a little bit. But yeah, same basic idea. There's a before call, there's encodes for the different types you want. And they're just written so that the matrix math works out with the extra batch dimension automatically. So for example, dihedral is done on the GPU by using an affine transform.
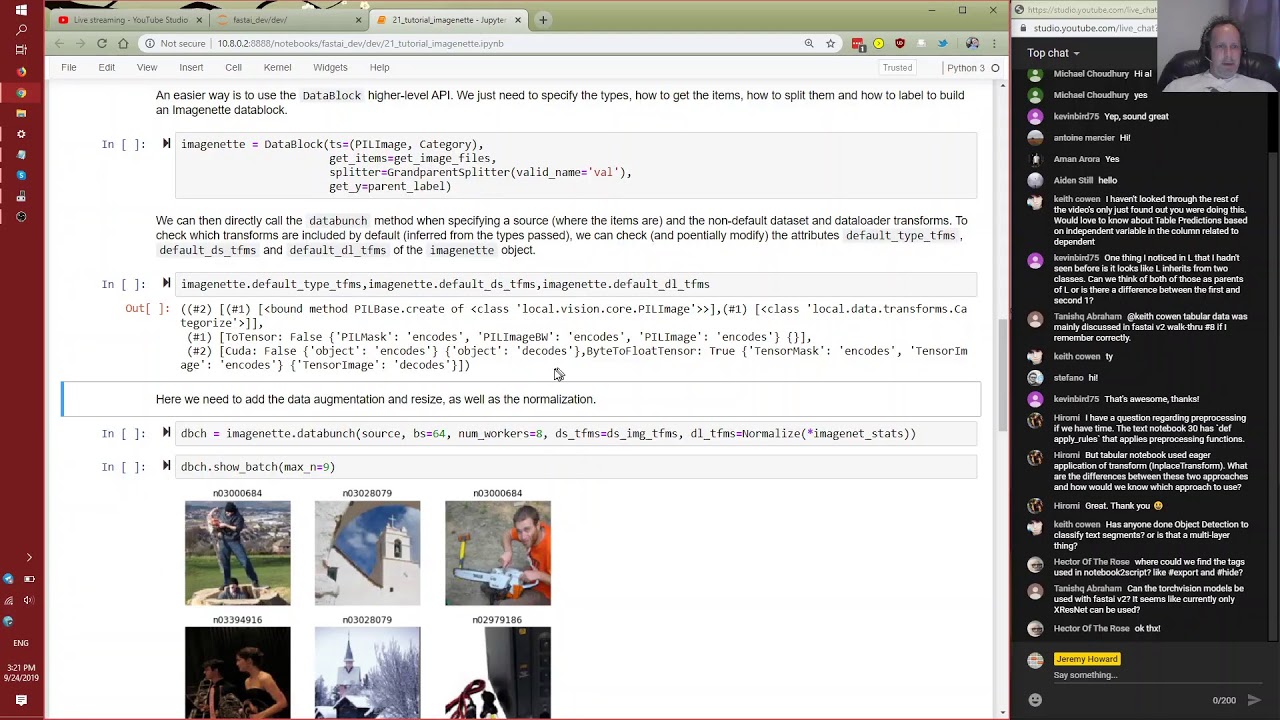
Great. And most of this stuff, the affine transforms and warps and stuff, we did touch on in the last part too. So go check that out. And the lighting transforms also were done there, if you've forgotten. Great. So then finally, you can check out 21. So this is ImageNet, and it looks pretty familiar, untied data, get image files.
So we're not going to use data blocks here. Obviously, you could use data blocks as well, but this is doing it fairly manually. Hector of the rows, these tags are mentioned in the previous code walkthroughs, so check them out. I was just looking at the script starting with the number 9 to see how they're defined.
All right. So transforms for the independent variable will just be create an image for the dependent. It will be for the parent label function, and then categorize. And then for the tuples, we go tensor optionally flip for random resize crop, create a data source, and then on the batch, I should say, put it on the GPU, turn it into a float tensor, normalize it.
And so then we can create a data bunch. There it is. And here's the data block version of the same thing. So you can compare and again, data bunch. So then some of these should need to be exported, but we can create a CNN learner to wrap our learner a bit more conveniently like we did in version 1, label smoothing, and fit.
And we can see if we have any augmentation. Oh, that's it listed. Not sure we might even need to add that in. Actually, we tend not to add much augmentation because we tend to use mixup nowadays if we want to use more epochs. So we tested this on more epochs, and he was getting slightly better results than we were with version 1.
So I thought that was a good sign. All right, I think-- oh, one more question-- torch vision models be used. Yeah, anything should be usable. They're just models. So if you look at xresnet, it's just a normal nn.sequential. So yeah, there shouldn't be any special requirements. If you try using a model and it doesn't work, let us know.
I guess for stuff like transfer learning, maybe that's something we can do in a future walkthrough. Yeah, we should probably do that in a future walkthrough, talk about how that stuff works. All right, thanks for joining, everybody. See you on the forums, and I'll let you know if we're going to do more of these in the future.
Thanks for coming along. Bye.