Some takeaways from reading Anthropic’s fantastic post on How we built our multi-agent research system. This is Simon Willison’s thoughts on the post too. I can tell it’s written by someone or a team that has spent time in the trenches building and architecting this system.
These two diagrams were helpful. I’ve been seeing these process diagrams more. I wonder if it’s because AI can generate these diagrams easily and so developers are including them in documentation more.
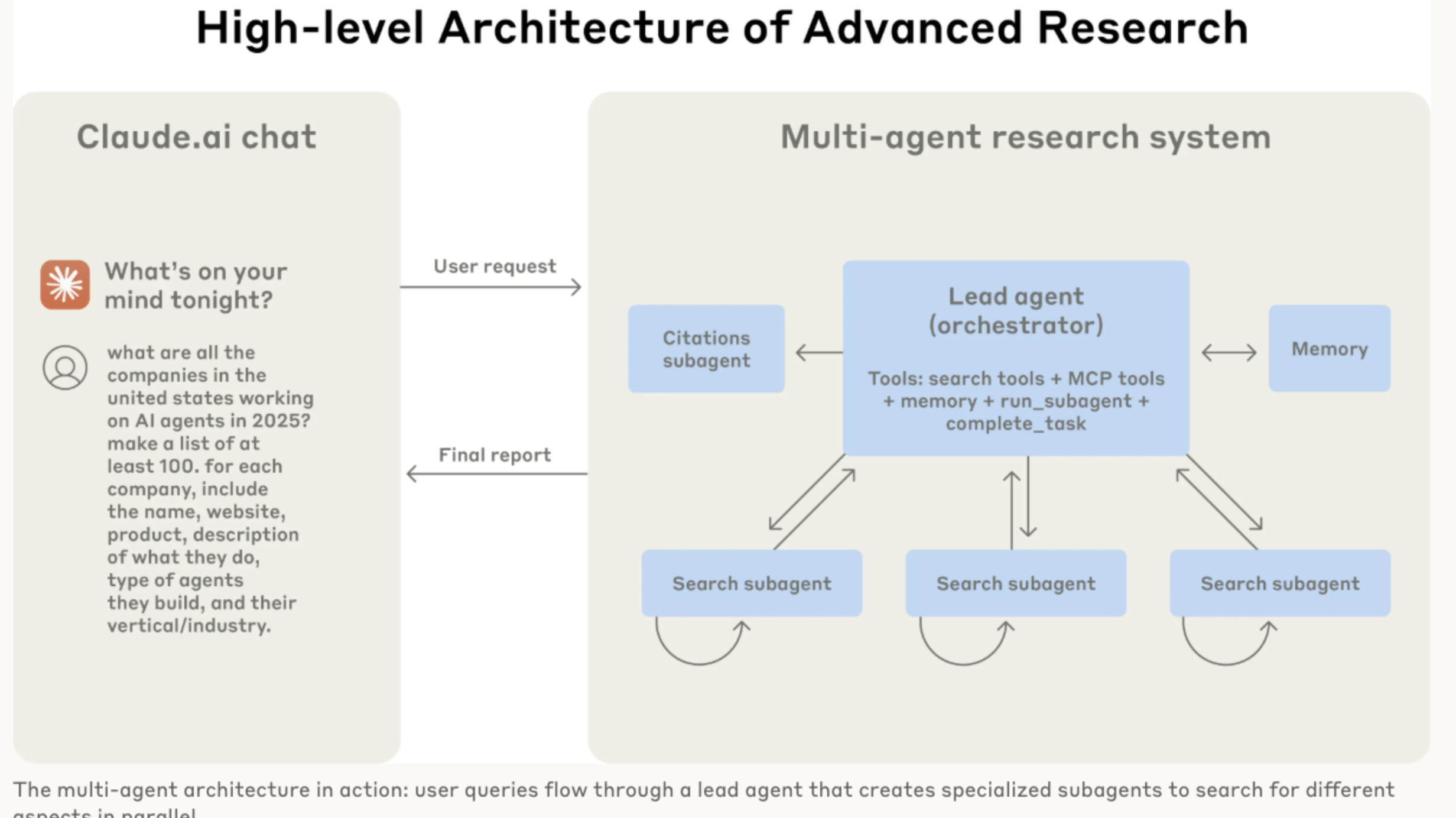
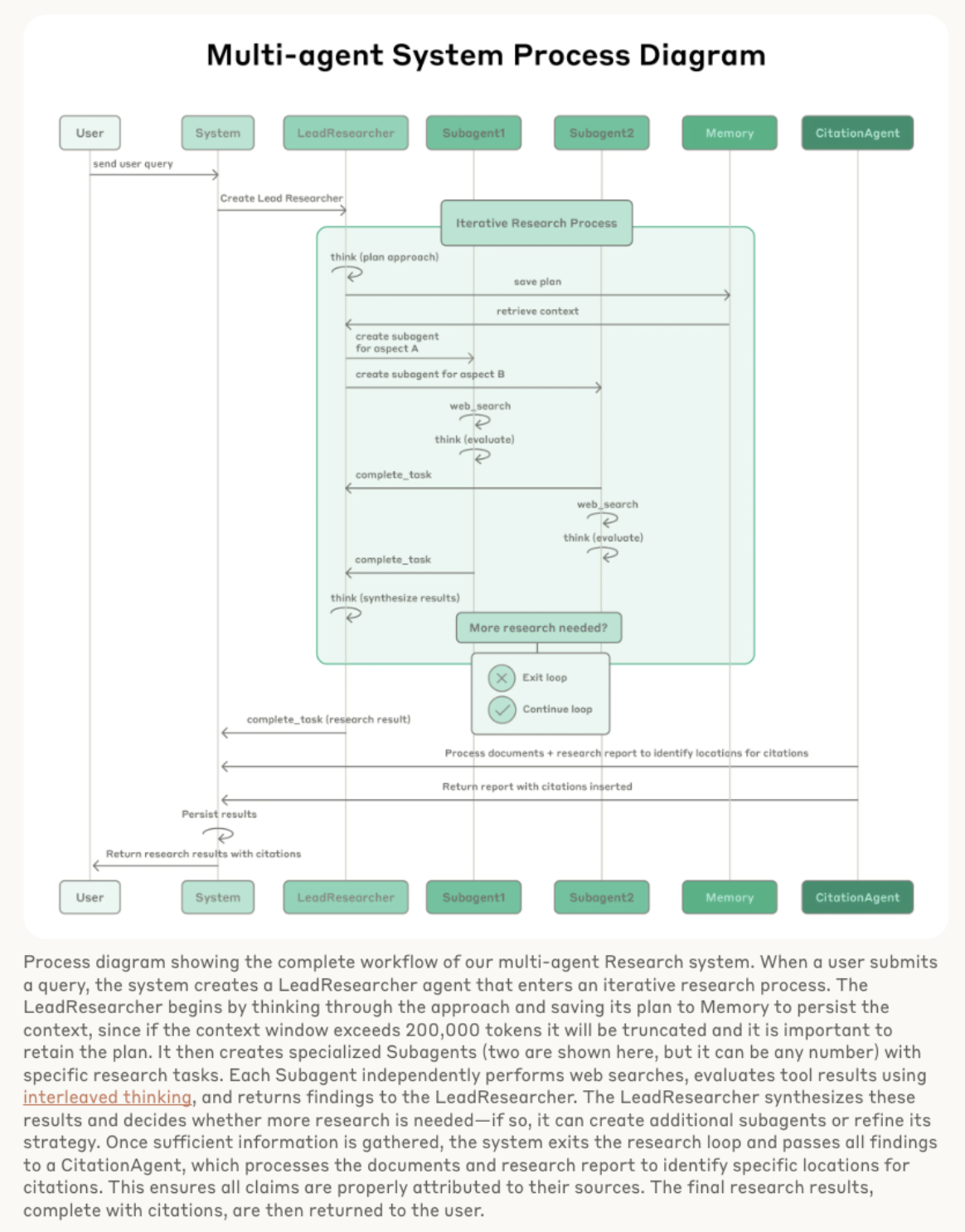
Some learnings: - Multi-Agent Systems (MAS) are good for breadth-first search queries - MAS work because they spend enough tokens to solve the problem - increased token usage explained 80% of the variance - MAS are much more expensive: agents use 4x more tokens than chats and Multi-Agent systems us 15x more tokens than chats - I learned about Interleaved thinking - which enables Claude to think between tool calls and make more sophisticated reasoning after receiving tool results. Google’s Gemini 2.5 models also do this. - Prompt Engineering is still massively important in creating Multi-Agent systems - prompting the orchestrator to delegate well - “Agent-tool interfaces are as critical as human-computer interfaces. Using the right tool is efficient—often, it’s strictly necessary. For instance, an agent searching the web for context that only exists in Slack is doomed from the start. With MCP servers that give the model access to external tools, this problem compounds, as agents encounter unseen tools with descriptions of wildly varying quality. We gave our agents explicit heuristics: for example, examine all available tools first, match tool usage to user intent, search the web for broad external exploration, or prefer specialized tools over generic ones. Bad tool descriptions can send agents down completely wrong paths, so each tool needs a distinct purpose and a clear description.”” - Thought this tool-testing agent was cool “Let agents improve themselves. We found that the Claude 4 models can be excellent prompt engineers. When given a prompt and a failure mode, they are able to diagnose why the agent is failing and suggest improvements. We even created a tool-testing agent—when given a flawed MCP tool, it attempts to use the tool and then rewrites the tool description to avoid failures. By testing the tool dozens of times, this agent found key nuances and bugs. This process for improving tool ergonomics resulted in a 40% decrease in task completion time for future agents using the new description, because they were able to avoid most mistakes.””
They also have a section on Evaluations that was helpful:
- Starting evals with small samples
- “We experimented with multiple judges to evaluate each component, but found that a single LLM call with a single prompt outputting scores from 0.0-1.0 and a pass-fail grade was the most consistent and aligned with human judgements.””
- Still having human evals after implementing automated LLM-as-judge evals