Google Gemini and Function Calling
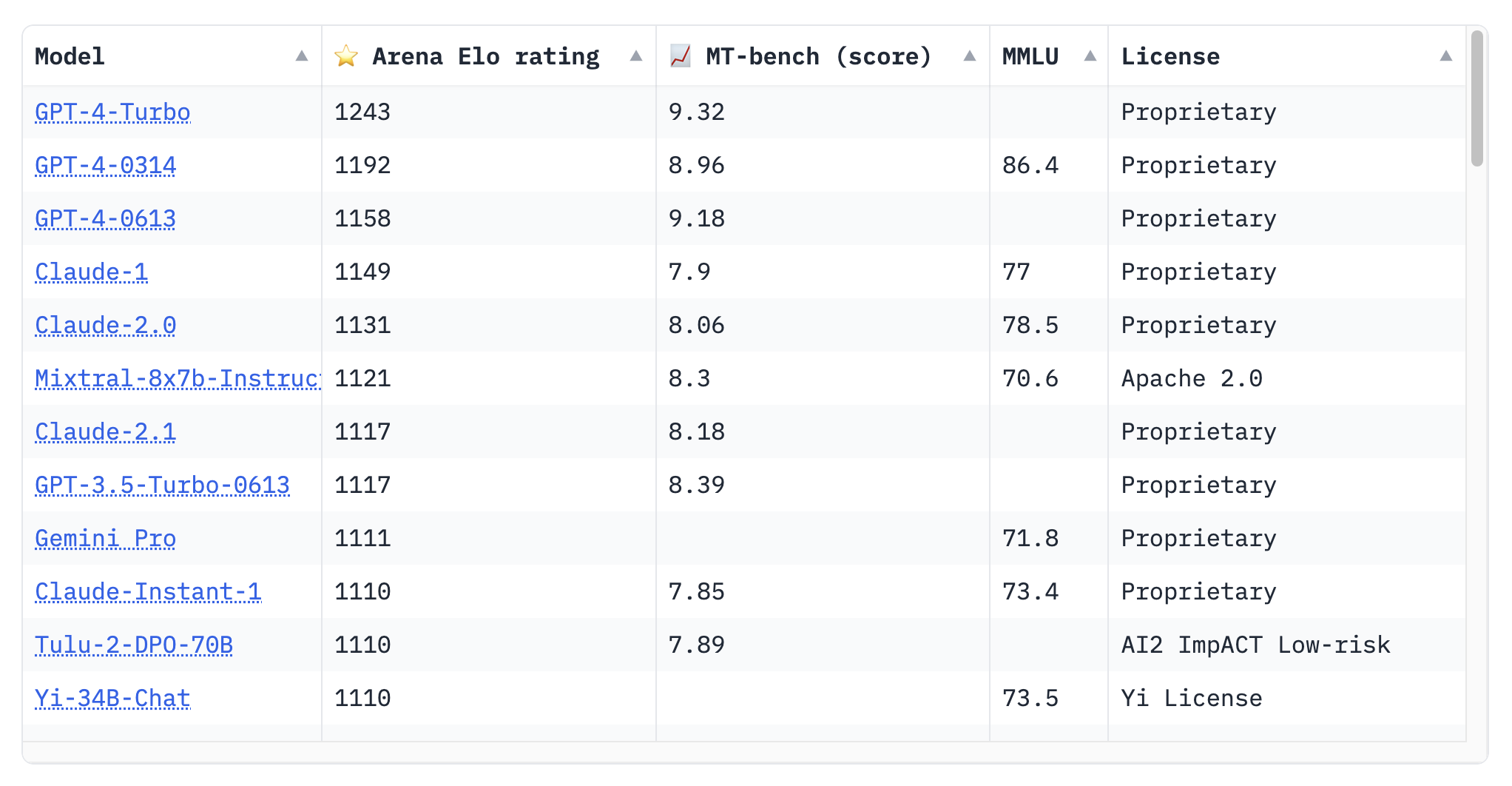
Google’s latest LLM called Gemini was released in December. Google trained three model sizes: Nano, Gemini and Ultra (small, medium and large respectively). Ultra hasn’t been released publicly yet. There are reports that Gemini has similar performance to gpt-3.5-turbo. Based on lmsys’ Chatbot Arena Leaderboard, Gemini Pro’s Elo is 1111 while gpt-3.5-turbo-0613 is a tick higher at 1117 (as of this writing 2023-12-26).
How to Run Gemini Pro with langchain
You’ll need two Python libraries:
google-cloud-aiplatform>=1.38.0
langchain>=0.0.350With those installed, you can run:
from langchain.llms import VertexAI
llm_gemini_pro = VertexAI(
model_name="gemini-pro",
temperature=0.7,
max_output_tokens=1024,
)
llm_gemini_pro.invoke("What's the difference between data science and data engineering?")
# the answer is pretty good
# Data science and data engineering are two closely related but distinct fields that play crucial roles in extracting insights from data. While both involve working with data, they have different objectives, skill sets, and responsibilities. Here are the key differences between data science and data engineering:
# 1. **Objective**:
# - Data Science: The primary objective of data science is to extract insights from data to make informed decisions. Data scientists use statistical and machine learning techniques to uncover patterns, predict outcomes, and develop models to solve business problems.
# - Data Engineering: Data engineers focus on building and maintaining the infrastructure that enables data scientists to access, process, and analyze data effectively. They ensure that data is collected, cleaned, transformed, and stored in a way that makes it accessible and usable for data analysis.
# 2. **Skill Sets**:
# - Data Science: Data scientists typically have a strong background in mathematics, statistics, computer science, and programming languages like Python and R. They are proficient in data mining, machine learning algorithms, and statistical modeling.
# - Data Engineering: Data engineers possess expertise in database management systems, data integration tools, cloud computing platforms, and distributed systems. They are skilled in data modeling, data warehousing, and data pipelines.
# 3. **Responsibilities**:
# - Data Science:
# - Develop and implement machine learning models for predictive analytics, classification, and regression.
# - Analyze large datasets to identify patterns, trends, and anomalies.
# - Build data visualization dashboards and reports to communicate insights to stakeholders.
# - Collaborate with business teams to understand their needs and translate them into actionable insights.
# - Data Engineering:
# - Design and implement data pipelines for data ingestion, transformation, and storage.
# - Ensure data quality and consistency by cleaning, validating, and normalizing data.
# - Develop and maintain data warehouses and data lakes for efficient data storage and retrieval.
# - Collaborate with data scientists to provide them with the necessary data and infrastructure for analysis.
# 4. **Tools and Technologies**:
# - Data Science: Data scientists commonly use tools like Python, R, Jupyter Notebooks, Pandas, NumPy, Scikit-learn, and TensorFlow for data analysis and machine learning.
# - Data Engineering: Data engineers work with tools such as Apache Hadoop, Apache Spark, Apache Hive, Apache Kafka, SQL databases, NoSQL databases, and cloud-based data storage services like Amazon S3 and Google Cloud Storage.
# ...
# - Data Science: Data scientists can progress in their careers by becoming senior data scientists, data science managers, or even chief data scientists. They may also transition into roles such as machine learning engineers or research scientists.
# - Data Engineering: Data engineers can advance to become senior data engineers, data architects, or big data engineers. They may also move into roles in cloud engineering, data governance, or data security.
# In summary, data science focuses on extracting insights from data to make informed decisions, while data engineering focuses on building and maintaining the infrastructure that enables data analysis. Both fields are crucial for organizations to effectively manage and utilize their data, and they often work together to deliver data-driven solutions for businesses.Gemini Pro and Function Calling
- My learnings are only from text based use cases as I haven’t really tried the multi-modal capabilities yet (e.g. vision)
- My “vibe check” of Gemini Pro is it is a much improved model compared to
text-bisonandtext-unicorn. It is able to follow instructions much more reliably than the previous models that were based on PaLM2. - One feature that I was particularly excited to see Google add is function calling.
- Here are some function calling examples from Google’s documentation.
- This intro to function calling Jupyter notebook was very helpful to get started with function calling.
- As of this writing (2023-12-26), langchain doesn’t support Google Gemini’s function calling. I opened an issue and it looks like there’s already a PR to add this feature.
Function Calling Basic Usage
To use function calling with Gemini, you can first define a function:
from vertexai.preview import generative_models
from vertexai.preview.generative_models import GenerativeModel
model = GenerativeModel("gemini-pro")
get_current_weather_func = generative_models.FunctionDeclaration(
name="get_current_weather",
description="Get the current weather in a given location",
parameters={
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": [
"celsius",
"fahrenheit",
]
}
},
"required": [
"location"
]
},
)Then you create a tool with that function
weather_tool = generative_models.Tool(
function_declarations=[get_current_weather_func]
)Then when you call the LLM, you pass the tool to the call:
model_response = model.generate_content(
"What is the weather like in Boston?",
generation_config={"temperature": 0},
tools=[weather_tool],
)
print("model_response\n", model_response)The model will output something like this:
candidates {
content {
role: "model"
parts {
function_call {
name: "get_current_weather"
args {
fields {
key: "location"
value {
string_value: "Boston, MA"
}
}
}
}
}
}
finish_reason: STOP
safety_ratings {
category: HARM_CATEGORY_HARASSMENT
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_HATE_SPEECH
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_SEXUALLY_EXPLICIT
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_DANGEROUS_CONTENT
probability: NEGLIGIBLE
}
}
usage_metadata {
prompt_token_count: 8
total_token_count: 8
}Function Calling & Data Extraction
One very useful use case for function calling is robust semantic data extraction. Without LLM’s that support function calling, you can already do semantic data extraction. With a prompt like “extract name, age and hair color from this block of text and return the data in JSON” and a large enough LLM, this will already get you pretty far. This is an example with gpt-3.5, langchain and one of langchain’s output parsers PydanticOutputParser. However, some issues are:
- the LLM may not always return valid JSON
- the LLM may return keys that are named differently
- the LLM may not return all the keys
The reason I say function calling supports robust semantic data extraction is the LLM will always return valid JSON and a schema that matches the schema you have defined.
Data Extraction Example
Extracting Person Metadata
I modified langchain’s Function Calling Extraction use case which uses OpenAI to work with Gemini Pro.
First do the necessary imports:
from vertexai.preview.generative_models import (
FunctionDeclaration,
GenerativeModel,
Tool,
)Then define your function and tool:
func_person_extractor = FunctionDeclaration(
name="person_extractor",
description="Extract data about a person from the text",
parameters={
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "Name of a person",
},
"height": {
"type": "integer",
"description": "Height of a person",
},
"hair_color": {
"type": "string",
"description": "Hair Color"
}
},
"required": ["name", "height"]
},
)
tool_person_extractor = Tool(
function_declarations=[func_person_extractor],
)Instantiate the gemini-pro model, pass the tool to the model and call the model with a prompt:
# have to use the model directly from vertexai since function calling not available through langchain
model = GenerativeModel("gemini-pro")
person_example_1 = model.generate_content(
"Alex is 5 feet tall. Claudia is 1 feet taller Alex and jumps higher than him. Claudia is a brunette and Alex is blonde.",
generation_config={"temperature": 0},
tools=[tool_person_extractor],
)
print(person_example_1)candidates {
content {
role: "model"
parts {
function_call {
name: "person_extractor"
args {
fields {
key: "name"
value {
string_value: "Alex"
}
}
fields {
key: "height"
value {
number_value: 5
}
}
fields {
key: "hair_color"
value {
string_value: "blonde"
}
}
...
prompt_token_count: 29
total_token_count: 29
}Extracting “Extra Info”
What’s also powerful about function calling based data extraction like the langchain example documents, “we can ask for things that are not for explicitly enumerated in the schema.” In the following example, we are asking for metadata about a person and a dog. And then by leveraging the LLM’s reasoning capability, we can ask for unspecified additional information about the dogs.
First define another function and wrap it in a tool:
func_person_and_dog_extractor = FunctionDeclaration(
name="person_extractor",
description="Extract data about a person from the text",
parameters={
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "Name of a person",
},
"height": {
"type": "integer",
"description": "Height of a person",
},
"hair_color": {
"type": "string",
"description": "Hair Color"
},
"dog_name": {
"type": "string",
"description": "Name of a dog",
},
"dog_breed": {
"type": "string",
"description": "Breed of dog",
},
"dog_extra_info": {
"type": "string",
"description": "Extra information about the dog"
}
},
"required": ["name", "height", "hair_color", "dog_name", "dog_breed", "dog_extra_info"]
},
)
tool_person_and_dog_extractor = Tool(
function_declarations=[func_person_and_dog_extractor],
)Then call the LLM:
inp = """Alex is 5 feet tall. Claudia is 1 feet taller Alex and jumps higher than him. Claudia is a brunette and Alex is blonde.
Willow is a German Shepherd that likes to play with other dogs and can always be found playing with Milo, a border collie that lives close by."""
example_2_person_and_dog = model.generate_content(
inp,
generation_config={"temperature": 0},
tools=[tool_person_and_dog_extractor],
)
print(example_2_person_and_dog)candidates {
content {
role: "model"
parts {
function_call {
name: "person_extractor"
args {
fields {
key: "name"
value {
string_value: "Willow"
}
}
fields {
key: "height"
value {
null_value: NULL_VALUE
}
}
fields {
key: "hair_color"
value {
null_value: NULL_VALUE
}
}
fields {
key: "dog_name"
value {
string_value: "Milo"
}
}
fields {
key: "dog_extra_info"
value {
string_value: "likes to play with other dogs and can always be found playing with Milo, a border collie that lives close by."
}
}
fields {
key: "dog_breed"
value {
string_value: "German Shepherd"
}
}
}
}
}
}
finish_reason: STOP
safety_ratings {
category: HARM_CATEGORY_HARASSMENT
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_HATE_SPEECH
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_SEXUALLY_EXPLICIT
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_DANGEROUS_CONTENT
probability: NEGLIGIBLE
}
}
usage_metadata {
prompt_token_count: 59
total_token_count: 59
}Gemini does not do as good of a job extracting data from free text. For example, in the trivial example above:
- the person’s height and hair color are null when both those two data points are in the input prompt
- there are two people but Gemini only extracts one person’s info
- Gemini also confuses the names of the dogs and people.
Willowis assigned to name when it is actually the name of a dog. The name of the dog it extracts is correct inMilobut the breed it associates withMilois incorrect, as it should beBorder Collie.
gpt-3-5-turbo does a better job of extracting all the relevant information and not hallucinating:
[{'person_name': 'Alex', 'person_height': 5, 'person_hair_color': 'blonde'},
{'person_name': 'Claudia',
'person_height': 6,
'person_hair_color': 'brunette'},
{'dog_name': 'Willow',
'dog_breed': 'German Shepherd',
'dog_extra_info': 'likes to play with other dogs'},
{'dog_name': 'Milo',
'dog_breed': 'border collie',
'dog_extra_info': 'lives close by'}]Hopefully Google continues to iterate and improve upon Gemini Pro’s function calling capabilities. I imagine Gemini Ultra will do a better job out of the box as well.